 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
BEiT: BERT Pre-Training of Image Transformers
Jun 15, 2021
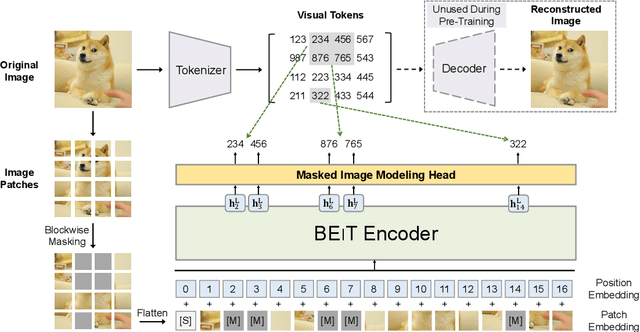
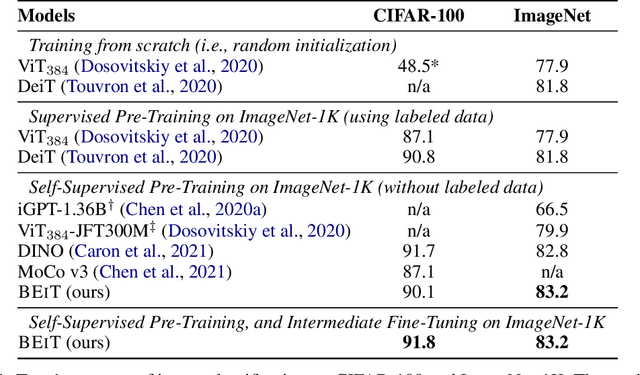
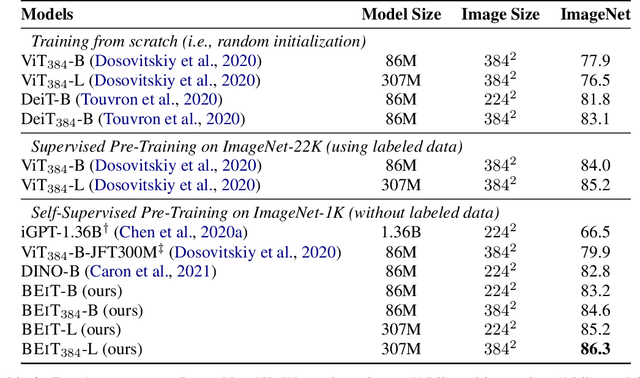
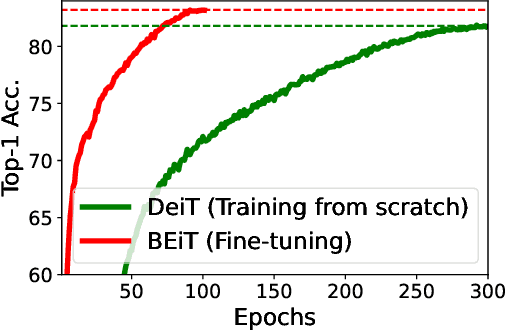
We introduce a self-supervised vision representation model BEiT, which stands for Bidirectional Encoder representation from Image Transformers. Following BERT developed in the natural language processing area, we propose a masked image modeling task to pretrain vision Transformers. Specifically, each image has two views in our pre-training, i.e, image patches (such as 16x16 pixels), and visual tokens (i.e., discrete tokens). We first "tokenize" the original image into visual tokens. Then we randomly mask some image patches and fed them into the backbone Transformer. The pre-training objective is to recover the original visual tokens based on the corrupted image patches. After pre-training BEiT, we directly fine-tune the model parameters on downstream tasks by appending task layers upon the pretrained encoder. Experimental results on image classification and semantic segmentation show that our model achieves competitive results with previous pre-training methods. For example, base-size BEiT achieves 83.2% top-1 accuracy on ImageNet-1K, significantly outperforming from-scratch DeiT training (81.8%) with the same setup. Moreover, large-size BEiT obtains 86.3% only using ImageNet-1K, even outperforming ViT-L with supervised pre-training on ImageNet-22K (85.2%). The code and pretrained models are available at https://aka.ms/beit.
Bringing Image Scene Structure to Video via Frame-Clip Consistency of Object Tokens
Jun 15, 2022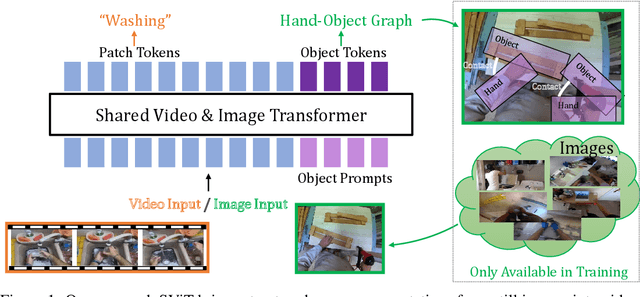
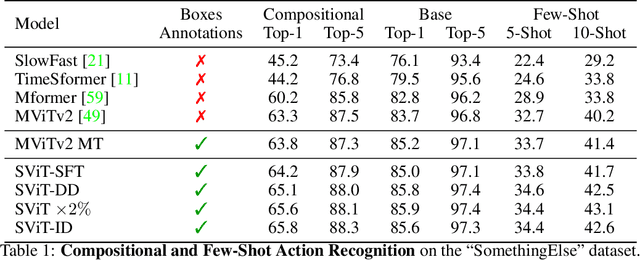
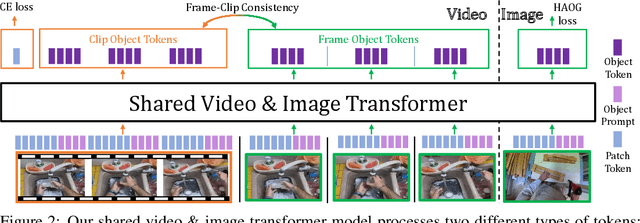
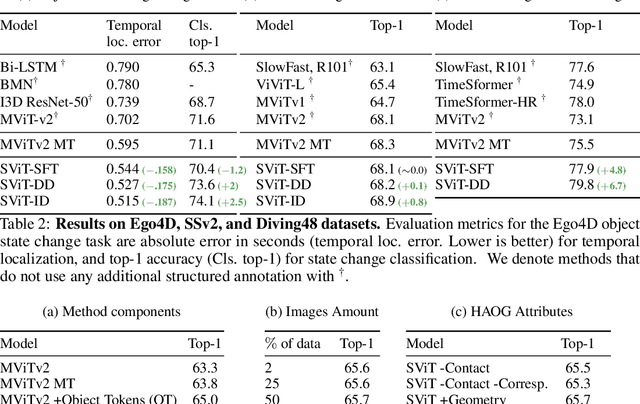
Recent action recognition models have achieved impressive results by integrating objects, their locations and interactions. However, obtaining dense structured annotations for each frame is tedious and time-consuming, making these methods expensive to train and less scalable. At the same time, if a small set of annotated images is available, either within or outside the domain of interest, how could we leverage these for a video downstream task? We propose a learning framework StructureViT (SViT for short), which demonstrates how utilizing the structure of a small number of images only available during training can improve a video model. SViT relies on two key insights. First, as both images and videos contain structured information, we enrich a transformer model with a set of \emph{object tokens} that can be used across images and videos. Second, the scene representations of individual frames in video should "align" with those of still images. This is achieved via a \emph{Frame-Clip Consistency} loss, which ensures the flow of structured information between images and videos. We explore a particular instantiation of scene structure, namely a \emph{Hand-Object Graph}, consisting of hands and objects with their locations as nodes, and physical relations of contact/no-contact as edges. SViT shows strong performance improvements on multiple video understanding tasks and datasets. Furthermore, it won in the Ego4D CVPR'22 Object State Localization challenge. For code and pretrained models, visit the project page at \url{https://eladb3.github.io/SViT/}
Towards Lightweight Super-Resolution with Dual Regression Learning
Jul 21, 2022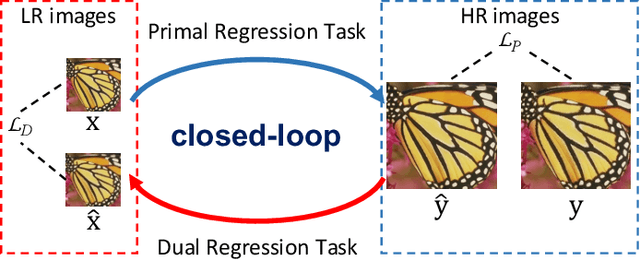
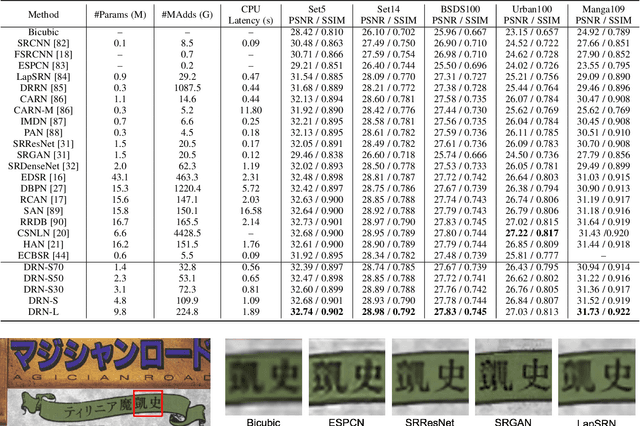
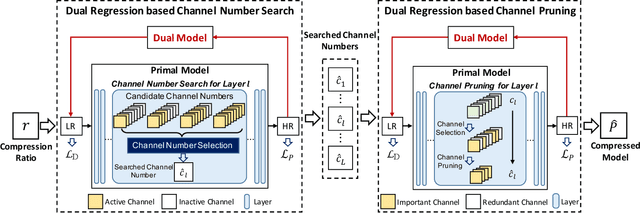
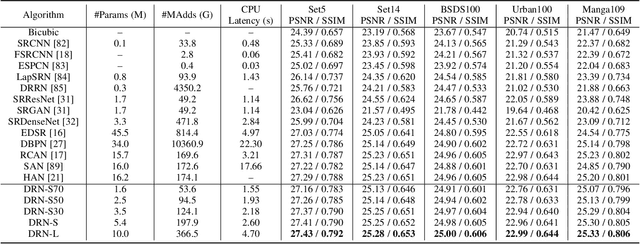
Deep neural networks have exhibited remarkable performance in image super-resolution (SR) tasks by learning a mapping from low-resolution (LR) images to high-resolution (HR) images. However, the SR problem is typically an ill-posed problem and existing methods would come with several limitations. First, the possible mapping space of SR can be extremely large since there may exist many different HR images that can be downsampled to the same LR image. As a result, it is hard to directly learn a promising SR mapping from such a large space. Second, it is often inevitable to develop very large models with extremely high computational cost to yield promising SR performance. In practice, one can use model compression techniques to obtain compact models by reducing model redundancy. Nevertheless, it is hard for existing model compression methods to accurately identify the redundant components due to the extremely large SR mapping space. To alleviate the first challenge, we propose a dual regression learning scheme to reduce the space of possible SR mappings. Specifically, in addition to the mapping from LR to HR images, we learn an additional dual regression mapping to estimate the downsampling kernel and reconstruct LR images. In this way, the dual mapping acts as a constraint to reduce the space of possible mappings. To address the second challenge, we propose a lightweight dual regression compression method to reduce model redundancy in both layer-level and channel-level based on channel pruning. Specifically, we first develop a channel number search method that minimizes the dual regression loss to determine the redundancy of each layer. Given the searched channel numbers, we further exploit the dual regression manner to evaluate the importance of channels and prune the redundant ones. Extensive experiments show the effectiveness of our method in obtaining accurate and efficient SR models.
Symbolic Replay: Scene Graph as Prompt for Continual Learning on VQA Task
Aug 24, 2022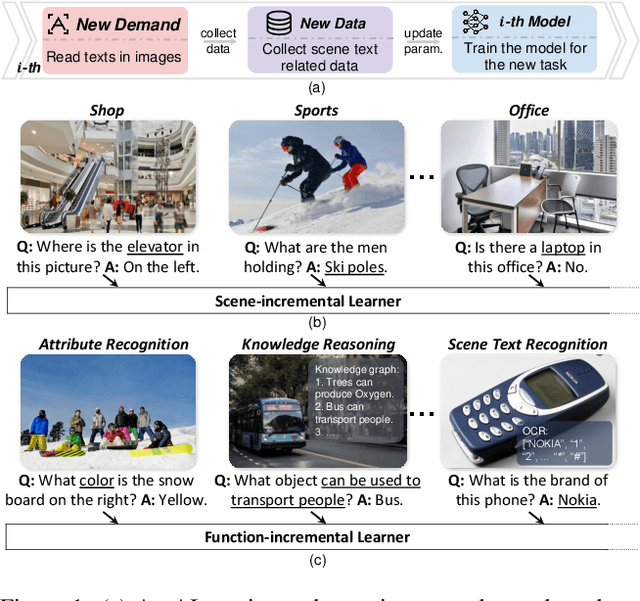
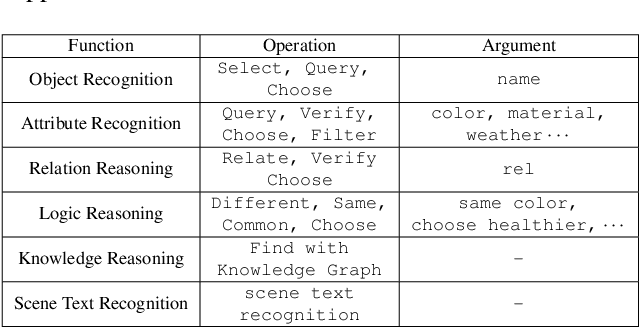
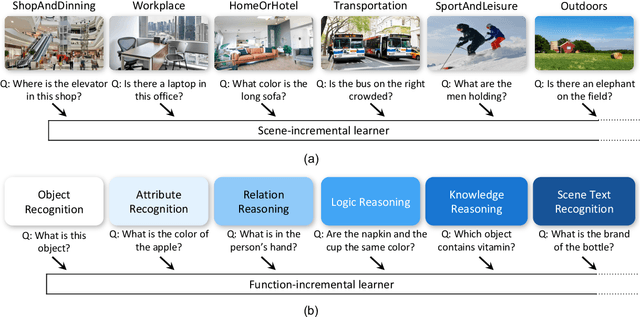
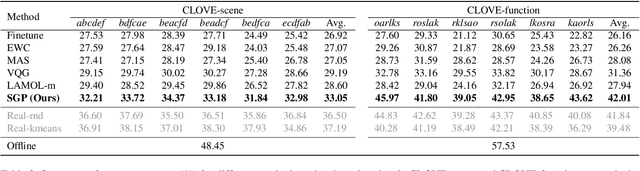
VQA is an ambitious task aiming to answer any image-related question. However, in reality, it is hard to build such a system once for all since the needs of users are continuously updated, and the system has to implement new functions. Thus, Continual Learning (CL) ability is a must in developing advanced VQA systems. Recently, a pioneer work split a VQA dataset into disjoint answer sets to study this topic. However, CL on VQA involves not only the expansion of label sets (new Answer sets). It is crucial to study how to answer questions when deploying VQA systems to new environments (new Visual scenes) and how to answer questions requiring new functions (new Question types). Thus, we propose CLOVE, a benchmark for Continual Learning On Visual quEstion answering, which contains scene- and function-incremental settings for the two aforementioned CL scenarios. In terms of methodology, the main difference between CL on VQA and classification is that the former additionally involves expanding and preventing forgetting of reasoning mechanisms, while the latter focusing on class representation. Thus, we propose a real-data-free replay-based method tailored for CL on VQA, named Scene Graph as Prompt for Symbolic Replay. Using a piece of scene graph as a prompt, it replays pseudo scene graphs to represent the past images, along with correlated QA pairs. A unified VQA model is also proposed to utilize the current and replayed data to enhance its QA ability. Finally, experimental results reveal challenges in CLOVE and demonstrate the effectiveness of our method. The dataset and code will be available at https://github.com/showlab/CLVQA.
PEDENet: Image Anomaly Localization via Patch Embedding and Density Estimation
Oct 29, 2021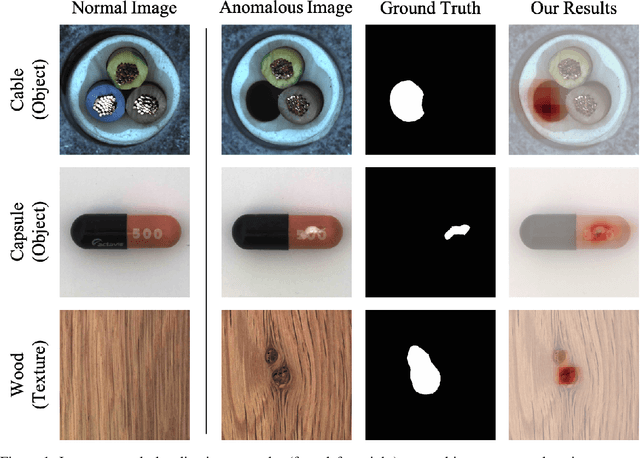
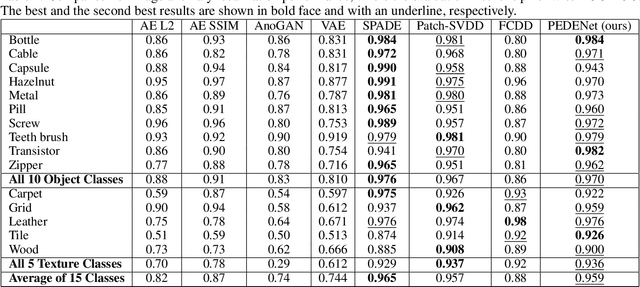
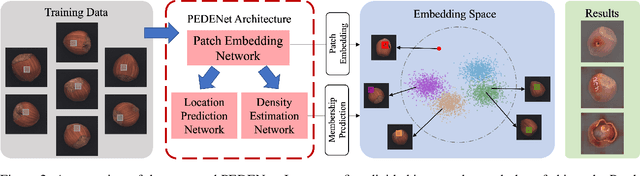
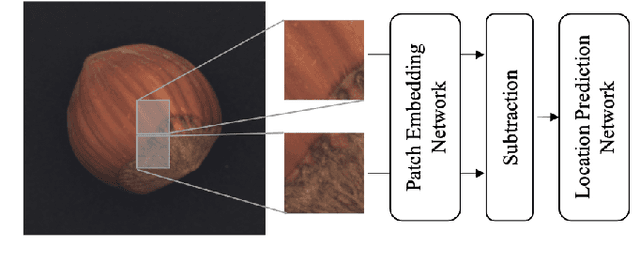
A neural network targeting at unsupervised image anomaly localization, called the PEDENet, is proposed in this work. PEDENet contains a patch embedding (PE) network, a density estimation (DE) network, and an auxiliary network called the location prediction (LP) network. The PE network takes local image patches as input and performs dimension reduction to get low-dimensional patch embeddings via a deep encoder structure. Being inspired by the Gaussian Mixture Model (GMM), the DE network takes those patch embeddings and then predicts the cluster membership of an embedded patch. The sum of membership probabilities is used as a loss term to guide the learning process. The LP network is a Multi-layer Perception (MLP), which takes embeddings from two neighboring patches as input and predicts their relative location. The performance of the proposed PEDENet is evaluated extensively and benchmarked with that of state-of-the-art methods.
AFTer-UNet: Axial Fusion Transformer UNet for Medical Image Segmentation
Oct 20, 2021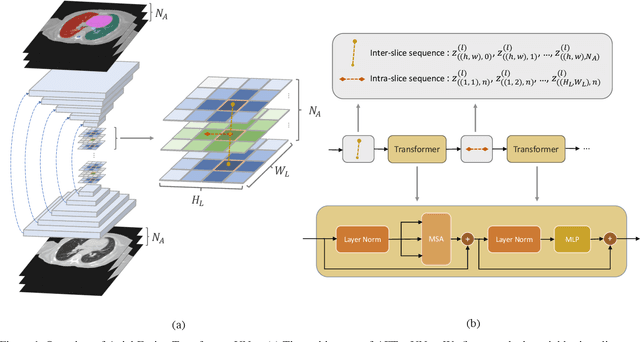
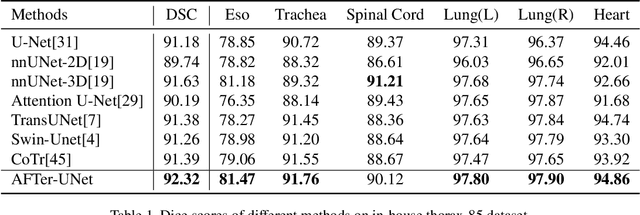

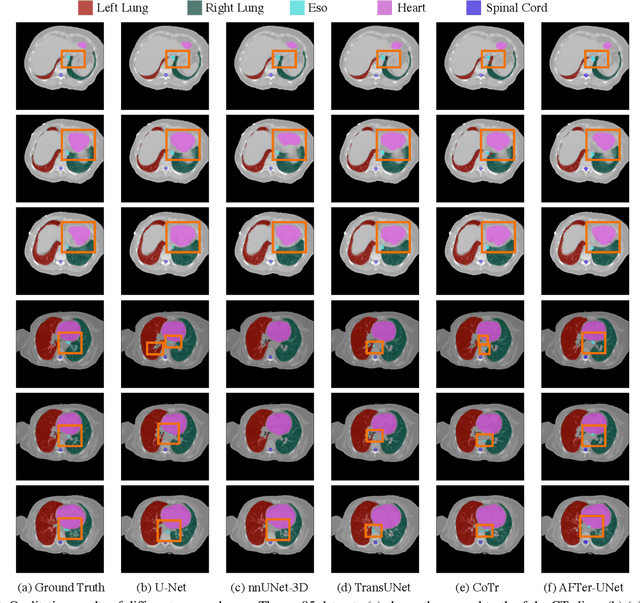
Recent advances in transformer-based models have drawn attention to exploring these techniques in medical image segmentation, especially in conjunction with the U-Net model (or its variants), which has shown great success in medical image segmentation, under both 2D and 3D settings. Current 2D based methods either directly replace convolutional layers with pure transformers or consider a transformer as an additional intermediate encoder between the encoder and decoder of U-Net. However, these approaches only consider the attention encoding within one single slice and do not utilize the axial-axis information naturally provided by a 3D volume. In the 3D setting, convolution on volumetric data and transformers both consume large GPU memory. One has to either downsample the image or use cropped local patches to reduce GPU memory usage, which limits its performance. In this paper, we propose Axial Fusion Transformer UNet (AFTer-UNet), which takes both advantages of convolutional layers' capability of extracting detailed features and transformers' strength on long sequence modeling. It considers both intra-slice and inter-slice long-range cues to guide the segmentation. Meanwhile, it has fewer parameters and takes less GPU memory to train than the previous transformer-based models. Extensive experiments on three multi-organ segmentation datasets demonstrate that our method outperforms current state-of-the-art methods.
Predict, Prevent, and Evaluate: Disentangled Text-Driven Image Manipulation Empowered by Pre-Trained Vision-Language Model
Nov 26, 2021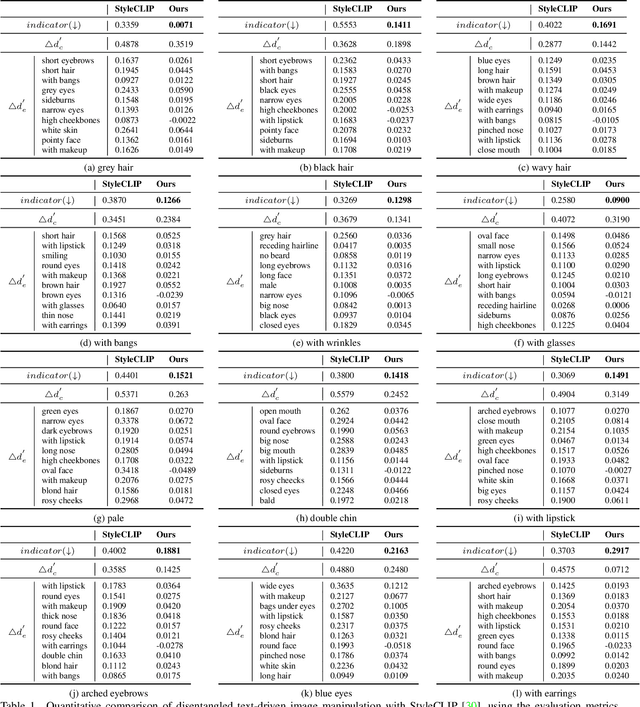
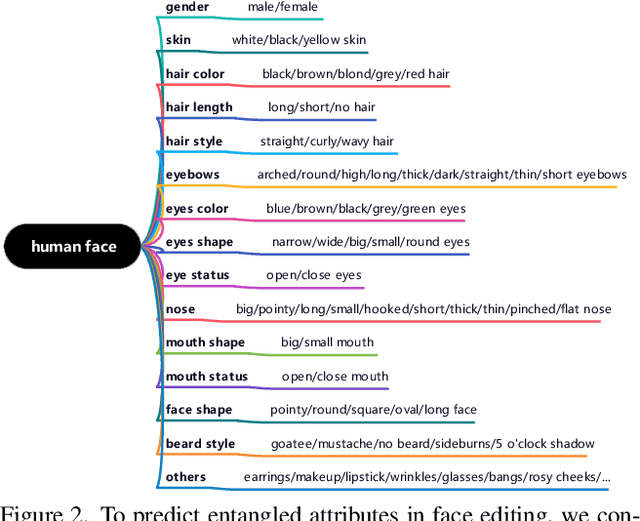
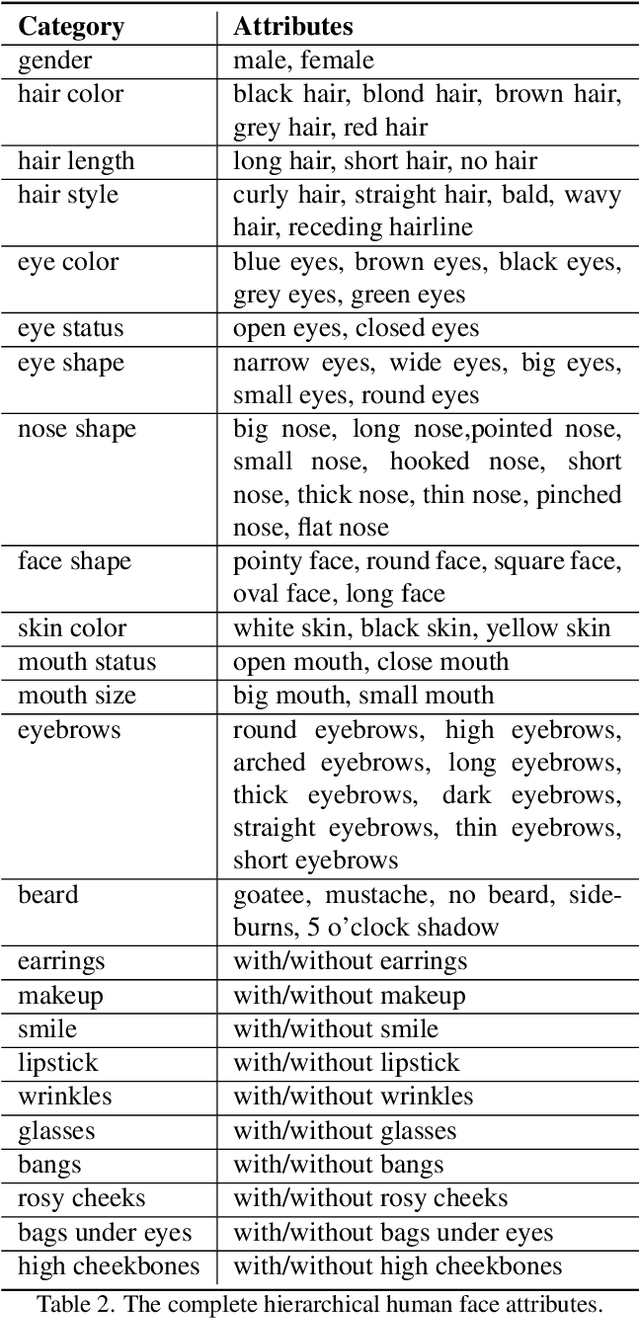

To achieve disentangled image manipulation, previous works depend heavily on manual annotation. Meanwhile, the available manipulations are limited to a pre-defined set the models were trained for. In this paper, we propose a novel framework, i.e., Predict, Prevent, and Evaluate (PPE), for disentangled text-driven image manipulation, which does not need manual annotation and thus is not limited to fixed manipulations. Our method approaches the targets by deeply exploiting the power of the large scale pre-trained vision-language model CLIP. Concretely, we firstly Predict the possibly entangled attributes for a given text command. Then, based on the predicted attributes, we introduce an entanglement loss to Prevent entanglements during training. Finally, we propose a new evaluation metric to Evaluate the disentangled image manipulation. We verify the effectiveness of our method on the challenging face editing task. Extensive experiments show that the proposed PPE framework achieves much better quantitative and qualitative results than the up-to-date StyleCLIP baseline.
Where are my Neighbors? Exploiting Patches Relations in Self-Supervised Vision Transformer
Jun 01, 2022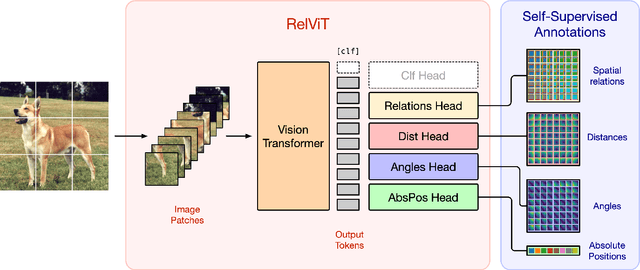
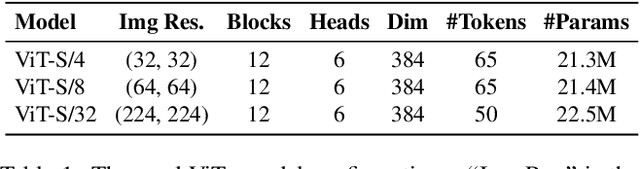
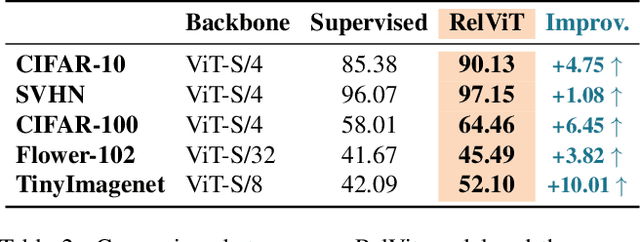
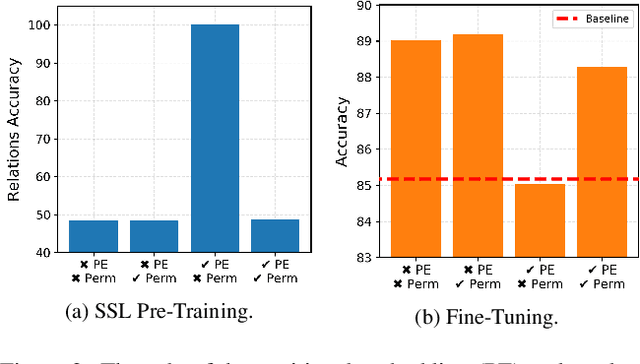
Vision Transformers (ViTs) enabled the use of transformer architecture on vision tasks showing impressive performances when trained on big datasets. However, on relatively small datasets, ViTs are less accurate given their lack of inductive bias. To this end, we propose a simple but still effective self-supervised learning (SSL) strategy to train ViTs, that without any external annotation, can significantly improve the results. Specifically, we define a set of SSL tasks based on relations of image patches that the model has to solve before or jointly during the downstream training. Differently from ViT, our RelViT model optimizes all the output tokens of the transformer encoder that are related to the image patches, thus exploiting more training signal at each training step. We investigated our proposed methods on several image benchmarks finding that RelViT improves the SSL state-of-the-art methods by a large margin, especially on small datasets.
Robust and Decomposable Average Precision for Image Retrieval
Oct 01, 2021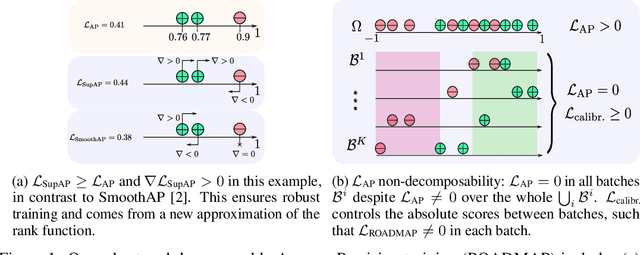
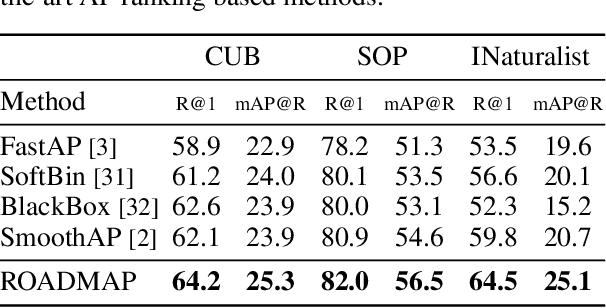
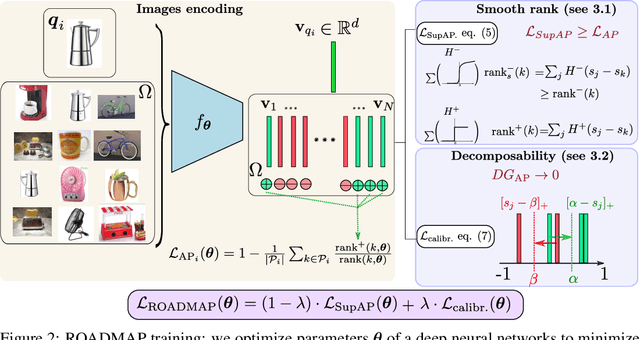
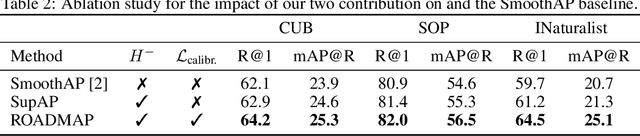
In image retrieval, standard evaluation metrics rely on score ranking, e.g. average precision (AP). In this paper, we introduce a method for robust and decomposable average precision (ROADMAP) addressing two major challenges for end-to-end training of deep neural networks with AP: non-differentiability and non-decomposability. Firstly, we propose a new differentiable approximation of the rank function, which provides an upper bound of the AP loss and ensures robust training. Secondly, we design a simple yet effective loss function to reduce the decomposability gap between the AP in the whole training set and its averaged batch approximation, for which we provide theoretical guarantees. Extensive experiments conducted on three image retrieval datasets show that ROADMAP outperforms several recent AP approximation methods and highlight the importance of our two contributions. Finally, using ROADMAP for training deep models yields very good performances, outperforming state-of-the-art results on the three datasets.
On the Study of Sample Complexity for Polynomial Neural Networks
Jul 18, 2022
As a general type of machine learning approach, artificial neural networks have established state-of-art benchmarks in many pattern recognition and data analysis tasks. Among various kinds of neural networks architectures, polynomial neural networks (PNNs) have been recently shown to be analyzable by spectrum analysis via neural tangent kernel, and particularly effective at image generation and face recognition. However, acquiring theoretical insight into the computation and sample complexity of PNNs remains an open problem. In this paper, we extend the analysis in previous literature to PNNs and obtain novel results on sample complexity of PNNs, which provides some insights in explaining the generalization ability of PNNs.