 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
UniToBrain dataset: a Brain Perfusion Dataset
Aug 01, 2022
The CT perfusion (CTP) is a medical exam for measuring the passage of a bolus of contrast solution through the brain on a pixel-by-pixel basis. The objective is to draw "perfusion maps" (namely cerebral blood volume, cerebral blood flow and time to peak) very rapidly for ischemic lesions, and to be able to distinguish between core and penumubra regions. A precise and quick diagnosis, in a context of ischemic stroke, can determine the fate of the brain tissues and guide the intervention and treatment in emergency conditions. In this work we present UniToBrain dataset, the very first open-source dataset for CTP. It comprises a cohort of more than a hundred of patients, and it is accompanied by patients metadata and ground truth maps obtained with state-of-the-art algorithms. We also propose a novel neural networks-based algorithm, using the European library ECVL and EDDL for the image processing and developing deep learning models respectively. The results obtained by the neural network models match the ground truth and open the road towards potential sub-sampling of the required number of CT maps, which impose heavy radiation doses to the patients.
Hand-Assisted Expression Recognition Method from Synthetic Images at the Fourth ABAW Challenge
Jul 20, 2022
Learning from synthetic images plays an important role in facial expression recognition task due to the difficulties of labeling the real images, and it is challenging because of the gap between the synthetic images and real images. The fourth Affective Behavior Analysis in-the-wild Competition raises the challenge and provides the synthetic images generated from Aff-Wild2 dataset. In this paper, we propose a hand-assisted expression recognition method to reduce the gap between the synthetic data and real data. Our method consists of two parts: expression recognition module and hand prediction module. Expression recognition module extracts expression information and hand prediction module predicts whether the image contains hands. Decision mode is used to combine the results of two modules, and post-pruning is used to improve the result. F1 score is used to verify the effectiveness of our method.
Detecting COVID-19 from digitized ECG printouts using 1D convolutional neural networks
Aug 10, 2022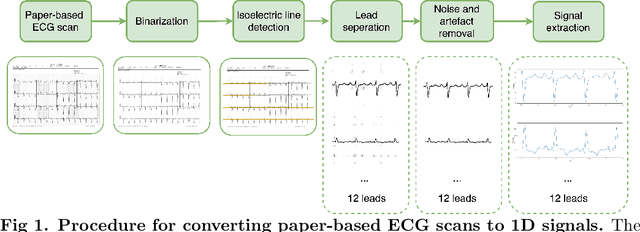

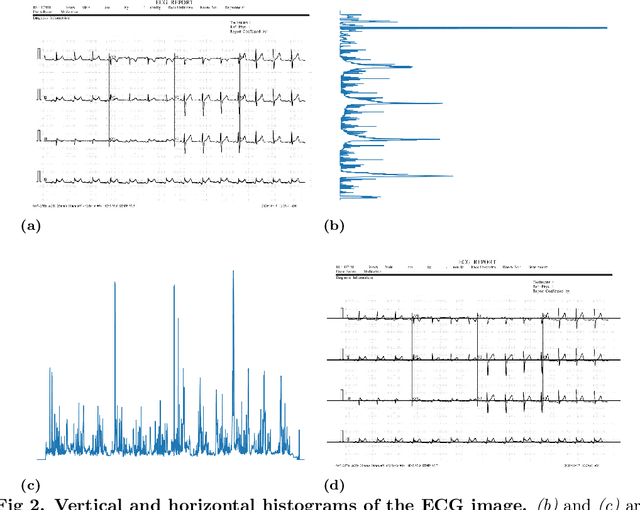
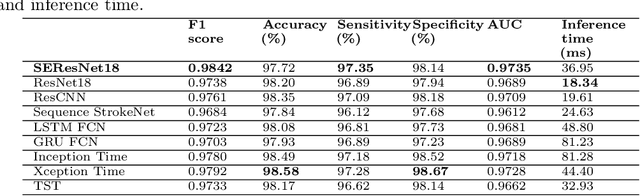
The COVID-19 pandemic has exposed the vulnerability of healthcare services worldwide, raising the need to develop novel tools to provide rapid and cost-effective screening and diagnosis. Clinical reports indicated that COVID-19 infection may cause cardiac injury, and electrocardiograms (ECG) may serve as a diagnostic biomarker for COVID-19. This study aims to utilize ECG signals to detect COVID-19 automatically. We propose a novel method to extract ECG signals from ECG paper records, which are then fed into a one-dimensional convolution neural network (1D-CNN) to learn and diagnose the disease. To evaluate the quality of digitized signals, R peaks in the paper-based ECG images are labeled. Afterward, RR intervals calculated from each image are compared to RR intervals of the corresponding digitized signal. Experiments on the COVID-19 ECG images dataset demonstrate that the proposed digitization method is able to capture correctly the original signals, with a mean absolute error of 28.11 ms. Our proposed 1D-CNN model, which is trained on the digitized ECG signals, allows identifying individuals with COVID-19 and other subjects accurately, with classification accuracies of 98.42%, 95.63%, and 98.50% for classifying COVID-19 vs. Normal, COVID-19 vs. Abnormal Heartbeats, and COVID-19 vs. other classes, respectively. Furthermore, the proposed method also achieves a high-level of performance for the multi-classification task. Our findings indicate that a deep learning system trained on digitized ECG signals can serve as a potential tool for diagnosing COVID-19.
Augment to Detect Anomalies with Continuous Labelling
Jul 03, 2022
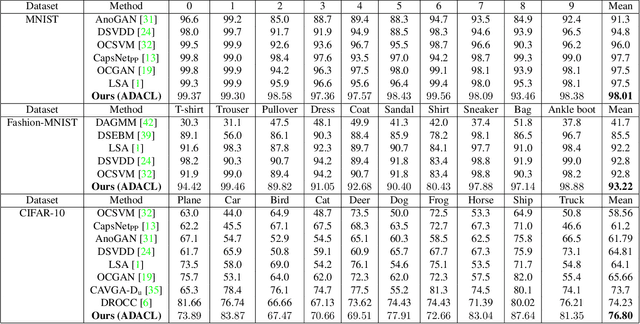

Anomaly detection is to recognize samples that differ in some respect from the training observations. These samples which do not conform to the distribution of normal data are called outliers or anomalies. In real-world anomaly detection problems, the outliers are absent, not well defined, or have a very limited number of instances. Recent state-of-the-art deep learning-based anomaly detection methods suffer from high computational cost, complexity, unstable training procedures, and non-trivial implementation, making them difficult to deploy in real-world applications. To combat this problem, we leverage a simple learning procedure that trains a lightweight convolutional neural network, reaching state-of-the-art performance in anomaly detection. In this paper, we propose to solve anomaly detection as a supervised regression problem. We label normal and anomalous data using two separable distributions of continuous values. To compensate for the unavailability of anomalous samples during training time, we utilize straightforward image augmentation techniques to create a distinct set of samples as anomalies. The distribution of the augmented set is similar but slightly deviated from the normal data, whereas real anomalies are expected to have an even further distribution. Therefore, training a regressor on these augmented samples will result in more separable distributions of labels for normal and real anomalous data points. Anomaly detection experiments on image and video datasets show the superiority of the proposed method over the state-of-the-art approaches.
Image-to-image Translation via Hierarchical Style Disentanglement
Mar 02, 2021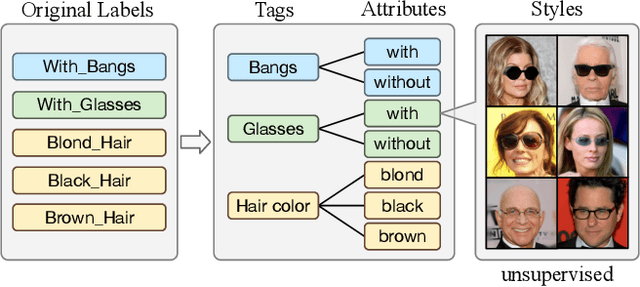


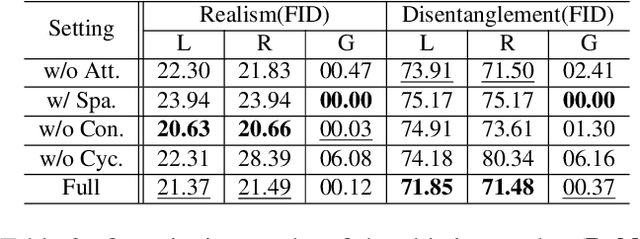
Recently, image-to-image translation has made significant progress in achieving both multi-label (\ie, translation conditioned on different labels) and multi-style (\ie, generation with diverse styles) tasks. However, due to the unexplored independence and exclusiveness in the labels, existing endeavors are defeated by involving uncontrolled manipulations to the translation results. In this paper, we propose Hierarchical Style Disentanglement (HiSD) to address this issue. Specifically, we organize the labels into a hierarchical tree structure, in which independent tags, exclusive attributes, and disentangled styles are allocated from top to bottom. Correspondingly, a new translation process is designed to adapt the above structure, in which the styles are identified for controllable translations. Both qualitative and quantitative results on the CelebA-HQ dataset verify the ability of the proposed HiSD. We hope our method will serve as a solid baseline and provide fresh insights with the hierarchically organized annotations for future research in image-to-image translation. The code has been released at https://github.com/imlixinyang/HiSD.
Label Semantic Knowledge Distillation for Unbiased Scene Graph Generation
Aug 07, 2022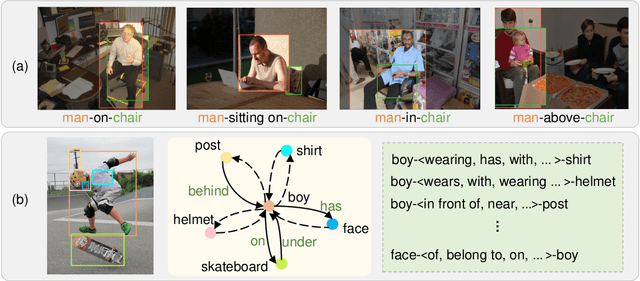
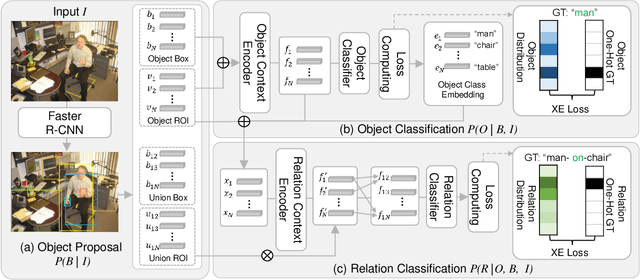
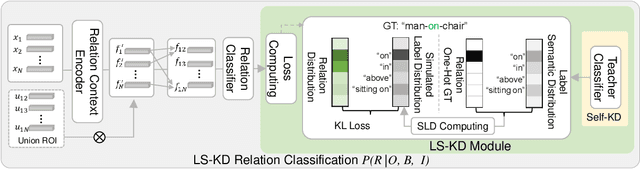

The Scene Graph Generation (SGG) task aims to detect all the objects and their pairwise visual relationships in a given image. Although SGG has achieved remarkable progress over the last few years, almost all existing SGG models follow the same training paradigm: they treat both object and predicate classification in SGG as a single-label classification problem, and the ground-truths are one-hot target labels. However, this prevalent training paradigm has overlooked two characteristics of current SGG datasets: 1) For positive samples, some specific subject-object instances may have multiple reasonable predicates. 2) For negative samples, there are numerous missing annotations. Regardless of the two characteristics, SGG models are easy to be confused and make wrong predictions. To this end, we propose a novel model-agnostic Label Semantic Knowledge Distillation (LS-KD) for unbiased SGG. Specifically, LS-KD dynamically generates a soft label for each subject-object instance by fusing a predicted Label Semantic Distribution (LSD) with its original one-hot target label. LSD reflects the correlations between this instance and multiple predicate categories. Meanwhile, we propose two different strategies to predict LSD: iterative self-KD and synchronous self-KD. Extensive ablations and results on three SGG tasks have attested to the superiority and generality of our proposed LS-KD, which can consistently achieve decent trade-off performance between different predicate categories.
Image coding for machines: an end-to-end learned approach
Aug 30, 2021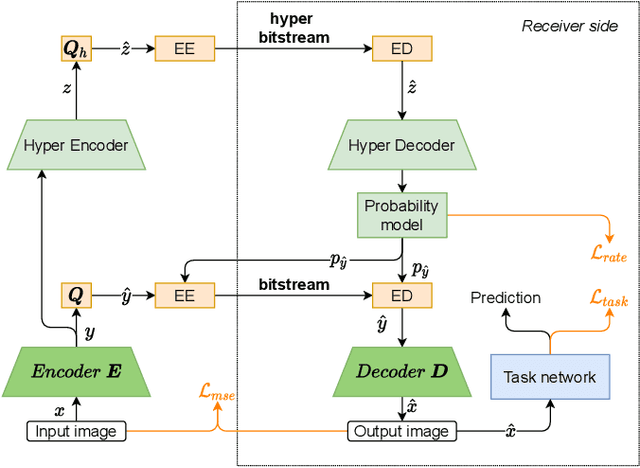

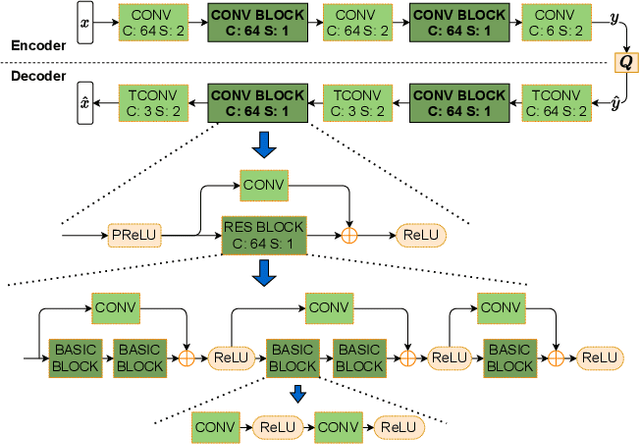
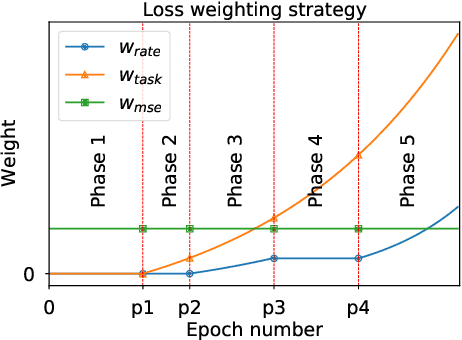
Over recent years, deep learning-based computer vision systems have been applied to images at an ever-increasing pace, oftentimes representing the only type of consumption for those images. Given the dramatic explosion in the number of images generated per day, a question arises: how much better would an image codec targeting machine-consumption perform against state-of-the-art codecs targeting human-consumption? In this paper, we propose an image codec for machines which is neural network (NN) based and end-to-end learned. In particular, we propose a set of training strategies that address the delicate problem of balancing competing loss functions, such as computer vision task losses, image distortion losses, and rate loss. Our experimental results show that our NN-based codec outperforms the state-of-the-art Versa-tile Video Coding (VVC) standard on the object detection and instance segmentation tasks, achieving -37.87% and -32.90% of BD-rate gain, respectively, while being fast thanks to its compact size. To the best of our knowledge, this is the first end-to-end learned machine-targeted image codec.
* Fixed a couple of mistakes since the version accepted in IEEE ICASSP2021
HRFuser: A Multi-resolution Sensor Fusion Architecture for 2D Object Detection
Jun 30, 2022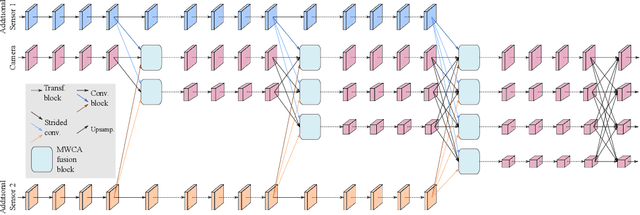
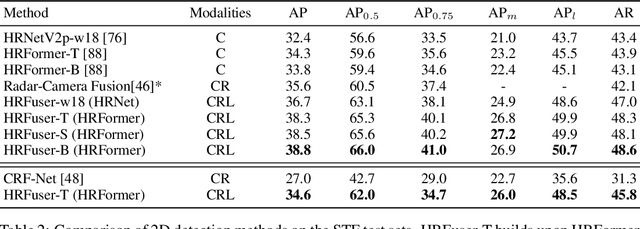
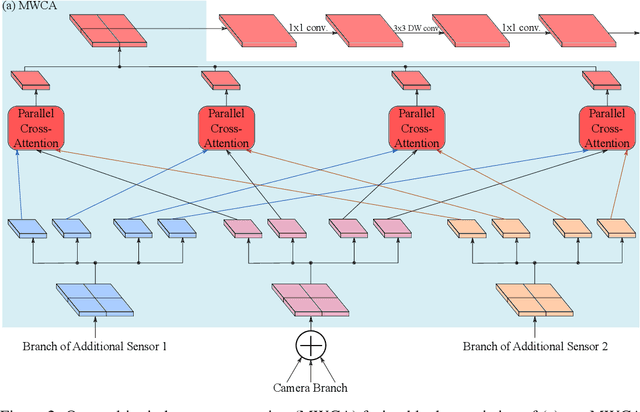

Besides standard cameras, autonomous vehicles typically include multiple additional sensors, such as lidars and radars, which help acquire richer information for perceiving the content of the driving scene. While several recent works focus on fusing certain pairs of sensors - such as camera and lidar or camera and radar - by using architectural components specific to the examined setting, a generic and modular sensor fusion architecture is missing from the literature. In this work, we focus on 2D object detection, a fundamental high-level task which is defined on the 2D image domain, and propose HRFuser, a multi-resolution sensor fusion architecture that scales straightforwardly to an arbitrary number of input modalities. The design of HRFuser is based on state-of-the-art high-resolution networks for image-only dense prediction and incorporates a novel multi-window cross-attention block as the means to perform fusion of multiple modalities at multiple resolutions. Even though cameras alone provide very informative features for 2D detection, we demonstrate via extensive experiments on the nuScenes and Seeing Through Fog datasets that our model effectively leverages complementary features from additional modalities, substantially improving upon camera-only performance and consistently outperforming state-of-the-art fusion methods for 2D detection both in normal and adverse conditions. The source code will be made publicly available.
Inferring Prototypes for Multi-Label Few-Shot Image Classification with Word Vector Guided Attention
Dec 07, 2021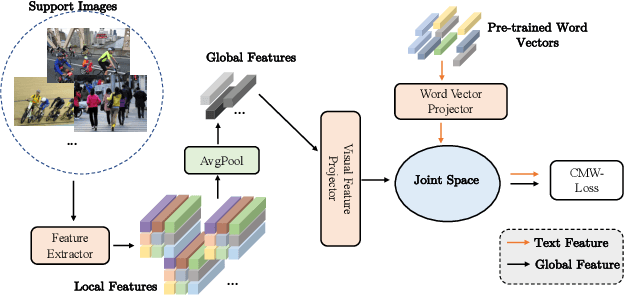
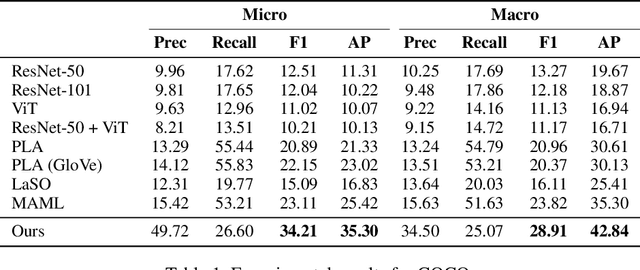
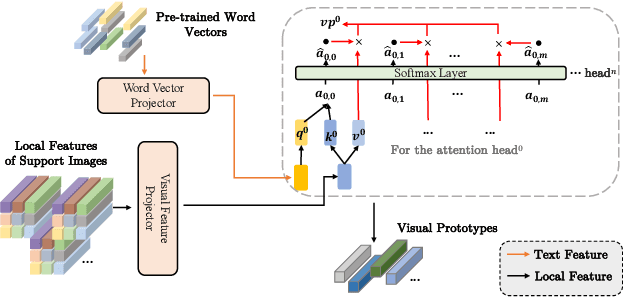
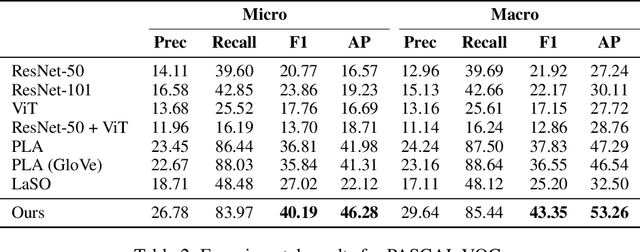
Multi-label few-shot image classification (ML-FSIC) is the task of assigning descriptive labels to previously unseen images, based on a small number of training examples. A key feature of the multi-label setting is that images often have multiple labels, which typically refer to different regions of the image. When estimating prototypes, in a metric-based setting, it is thus important to determine which regions are relevant for which labels, but the limited amount of training data makes this highly challenging. As a solution, in this paper we propose to use word embeddings as a form of prior knowledge about the meaning of the labels. In particular, visual prototypes are obtained by aggregating the local feature maps of the support images, using an attention mechanism that relies on the label embeddings. As an important advantage, our model can infer prototypes for unseen labels without the need for fine-tuning any model parameters, which demonstrates its strong generalization abilities. Experiments on COCO and PASCAL VOC furthermore show that our model substantially improves the current state-of-the-art.
On Advances in Text Generation from Images Beyond Captioning: A Case Study in Self-Rationalization
May 24, 2022


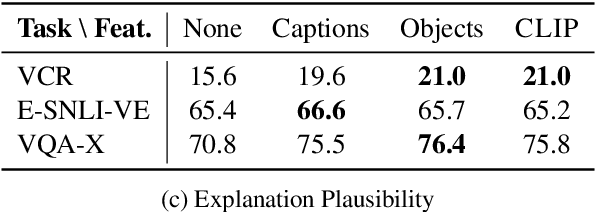
Integrating vision and language has gained notable attention following the success of pretrained language models. Despite that, a fraction of emerging multimodal models is suitable for text generation conditioned on images. This minority is typically developed and evaluated for image captioning, a text generation task conditioned solely on images with the goal to describe what is explicitly visible in an image. In this paper, we take a step back and ask: How do these models work for more complex generative tasks, conditioned on both text and images? Are models based on joint multimodal pretraining, visually adapted pretrained language models, or models that combine these two approaches, more promising for such tasks? We address these questions in the context of self-rationalization (jointly generating task labels/answers and free-text explanations) of three tasks: (i) visual question answering in VQA-X, (ii) visual commonsense reasoning in VCR, and (iii) visual-textual entailment in E-SNLI-VE. We show that recent advances in each modality, CLIP image representations and scaling of language models, do not consistently improve multimodal self-rationalization of tasks with multimodal inputs. We also observe that no model type works universally the best across tasks/datasets and finetuning data sizes. Our findings call for a backbone modelling approach that can be built on to advance text generation from images and text beyond image captioning.