 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MAFNet: A Multi-Attention Fusion Network for RGB-T Crowd Counting
Aug 14, 2022

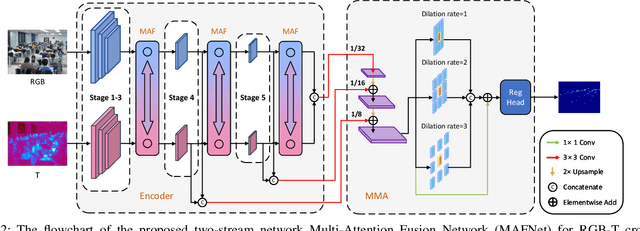
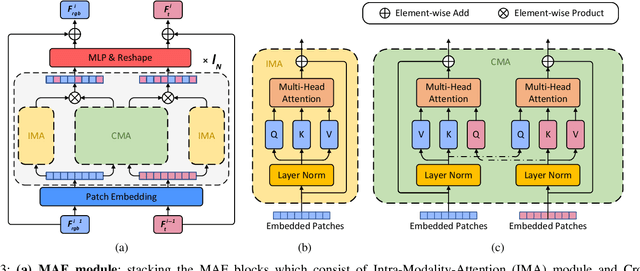
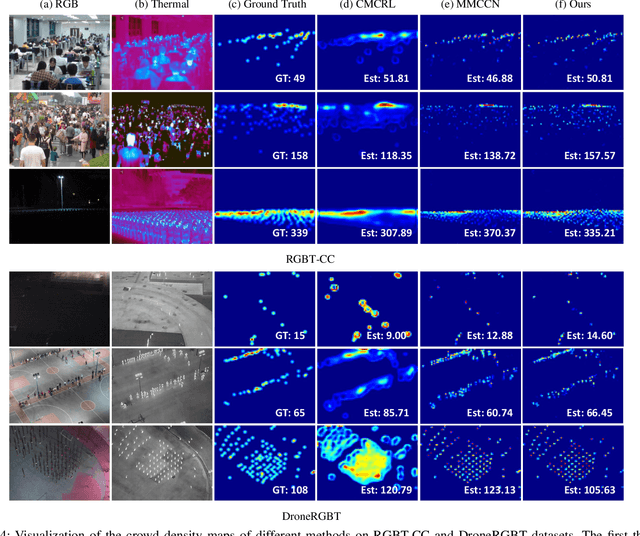
RGB-Thermal (RGB-T) crowd counting is a challenging task, which uses thermal images as complementary information to RGB images to deal with the decreased performance of unimodal RGB-based methods in scenes with low-illumination or similar backgrounds. Most existing methods propose well-designed structures for cross-modal fusion in RGB-T crowd counting. However, these methods have difficulty in encoding cross-modal contextual semantic information in RGB-T image pairs. Considering the aforementioned problem, we propose a two-stream RGB-T crowd counting network called Multi-Attention Fusion Network (MAFNet), which aims to fully capture long-range contextual information from the RGB and thermal modalities based on the attention mechanism. Specifically, in the encoder part, a Multi-Attention Fusion (MAF) module is embedded into different stages of the two modality-specific branches for cross-modal fusion at the global level. In addition, a Multi-modal Multi-scale Aggregation (MMA) regression head is introduced to make full use of the multi-scale and contextual information across modalities to generate high-quality crowd density maps. Extensive experiments on two popular datasets show that the proposed MAFNet is effective for RGB-T crowd counting and achieves the state-of-the-art performance.
AMOS: A Large-Scale Abdominal Multi-Organ Benchmark for Versatile Medical Image Segmentation
Jun 16, 2022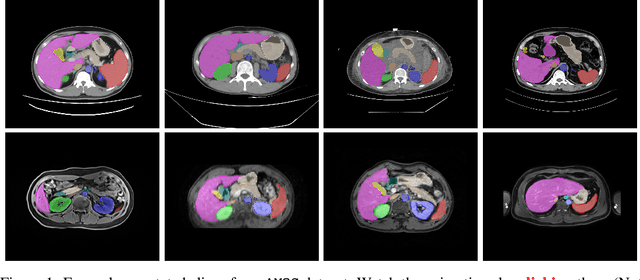
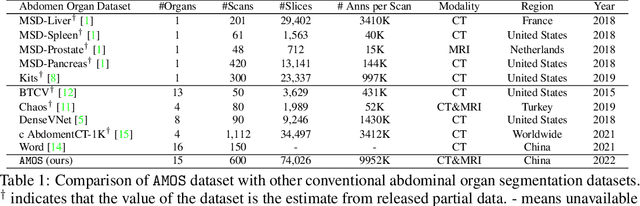
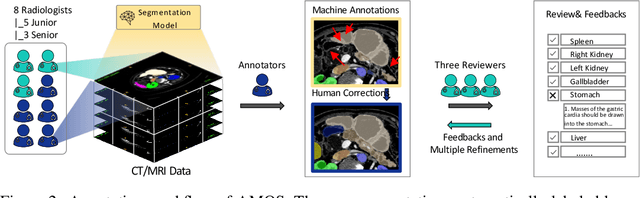
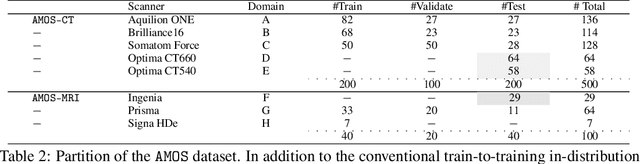
Despite the considerable progress in automatic abdominal multi-organ segmentation from CT/MRI scans in recent years, a comprehensive evaluation of the models' capabilities is hampered by the lack of a large-scale benchmark from diverse clinical scenarios. Constraint by the high cost of collecting and labeling 3D medical data, most of the deep learning models to date are driven by datasets with a limited number of organs of interest or samples, which still limits the power of modern deep models and makes it difficult to provide a fully comprehensive and fair estimate of various methods. To mitigate the limitations, we present AMOS, a large-scale, diverse, clinical dataset for abdominal organ segmentation. AMOS provides 500 CT and 100 MRI scans collected from multi-center, multi-vendor, multi-modality, multi-phase, multi-disease patients, each with voxel-level annotations of 15 abdominal organs, providing challenging examples and test-bed for studying robust segmentation algorithms under diverse targets and scenarios. We further benchmark several state-of-the-art medical segmentation models to evaluate the status of the existing methods on this new challenging dataset. We have made our datasets, benchmark servers, and baselines publicly available, and hope to inspire future research. Information can be found at https://amos22.grand-challenge.org.
Beta Generalized Normal Distribution with an Application for SAR Image Processing
Jun 03, 2022We introduce the beta generalized normal distribution which is obtained by compounding the beta and generalized normal [Nadarajah, S., A generalized normal distribution, \emph{Journal of Applied Statistics}. 32, 685--694, 2005] distributions. The new model includes as sub-models the beta normal, beta Laplace, normal, and Laplace distributions. The shape of the new distribution is quite flexible, specially the skewness and the tail weights, due to two additional parameters. We obtain general expansions for the moments. The estimation of the parameters is investigated by maximum likelihood. We also proposed a random number generator for the new distribution. Actual synthetic aperture radar were analyzed and modeled after the new distribution. Results could outperform the $\mathcal{G}^0$, $\mathcal{K}$, and $\Gamma$ distributions in several scenarios.
* 17 pages, 2 tables, 6 figures
Memory-guided Unsupervised Image-to-image Translation
Apr 12, 2021
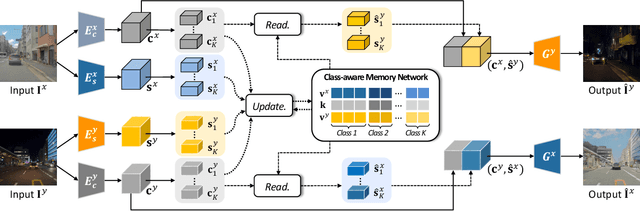
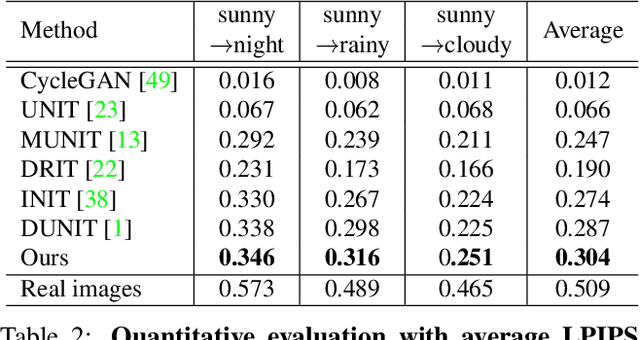
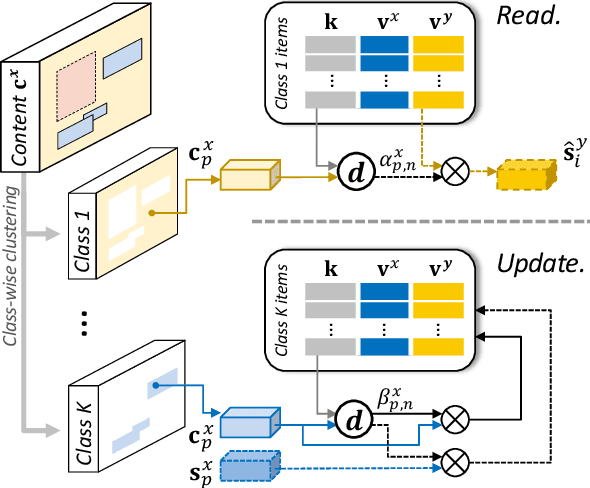
We present a novel unsupervised framework for instance-level image-to-image translation. Although recent advances have been made by incorporating additional object annotations, existing methods often fail to handle images with multiple disparate objects. The main cause is that, during inference, they apply a global style to the whole image and do not consider the large style discrepancy between instance and background, or within instances. To address this problem, we propose a class-aware memory network that explicitly reasons about local style variations. A key-values memory structure, with a set of read/update operations, is introduced to record class-wise style variations and access them without requiring an object detector at the test time. The key stores a domain-agnostic content representation for allocating memory items, while the values encode domain-specific style representations. We also present a feature contrastive loss to boost the discriminative power of memory items. We show that by incorporating our memory, we can transfer class-aware and accurate style representations across domains. Experimental results demonstrate that our model outperforms recent instance-level methods and achieves state-of-the-art performance.
Supervision Exists Everywhere: A Data Efficient Contrastive Language-Image Pre-training Paradigm
Oct 11, 2021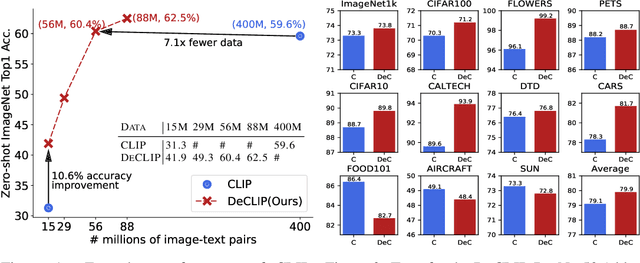
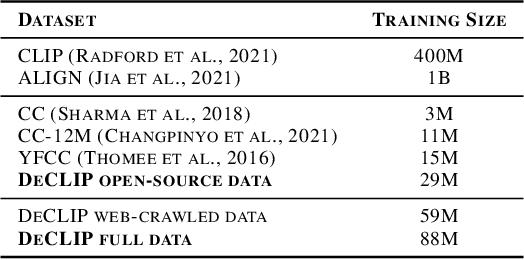
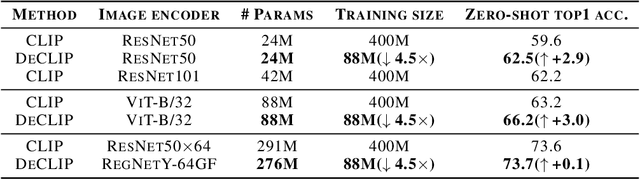
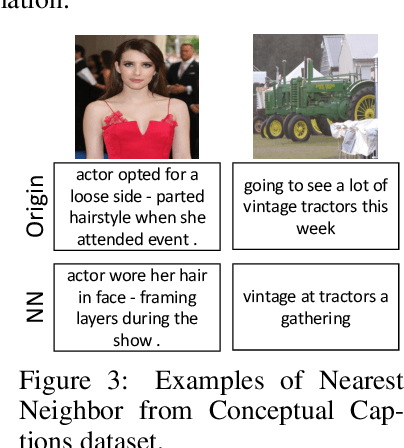
Recently, large-scale Contrastive Language-Image Pre-training (CLIP) has attracted unprecedented attention for its impressive zero-shot recognition ability and excellent transferability to downstream tasks. However, CLIP is quite data-hungry and requires 400M image-text pairs for pre-training, thereby restricting its adoption. This work proposes a novel training paradigm, Data efficient CLIP (DeCLIP), to alleviate this limitation. We demonstrate that by carefully utilizing the widespread supervision among the image-text pairs, our De-CLIP can learn generic visual features more efficiently. Instead of using the single image-text contrastive supervision, we fully exploit data potential through the use of (1) self-supervision within each modality; (2) multi-view supervision across modalities; (3) nearest-neighbor supervision from other similar pairs. Benefiting from intrinsic supervision, our DeCLIP-ResNet50 can achieve 60.4% zero-shot top1 accuracy on ImageNet, which is 0.8% above the CLIP-ResNet50 while using 7.1 x fewer data. Our DeCLIP-ResNet50 outperforms its counterpart in 8 out of 11 visual datasets when transferred to downstream tasks. Moreover, Scaling up the model and computing also works well in our framework.Our code, dataset and models are released at: https://github.com/Sense-GVT/DeCLIP
DP-Image: Differential Privacy for Image Data in Feature Space
Mar 12, 2021
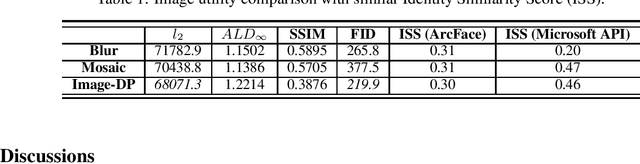
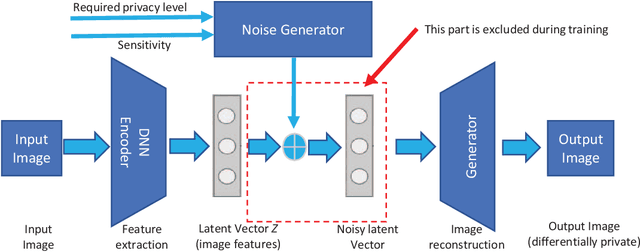
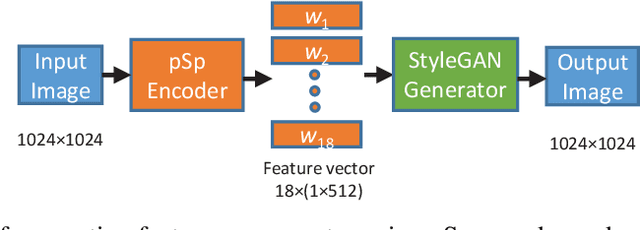
The excessive use of images in social networks, government databases, and industrial applications has posed great privacy risks and raised serious concerns from the public. Even though differential privacy (DP) is a widely accepted criterion that can provide a provable privacy guarantee, the application of DP on unstructured data such as images is not trivial due to the lack of a clear qualification on the meaningful difference between any two images. In this paper, for the first time, we introduce a novel notion of image-aware differential privacy, referred to as DP-image, that can protect user's personal information in images, from both human and AI adversaries. The DP-Image definition is formulated as an extended version of traditional differential privacy, considering the distance measurements between feature space vectors of images. Then we propose a mechanism to achieve DP-Image by adding noise to an image feature vector. Finally, we conduct experiments with a case study on face image privacy. Our results show that the proposed DP-Image method provides excellent DP protection on images, with a controllable distortion to faces.
Self-Supervised Object Detection via Generative Image Synthesis
Oct 19, 2021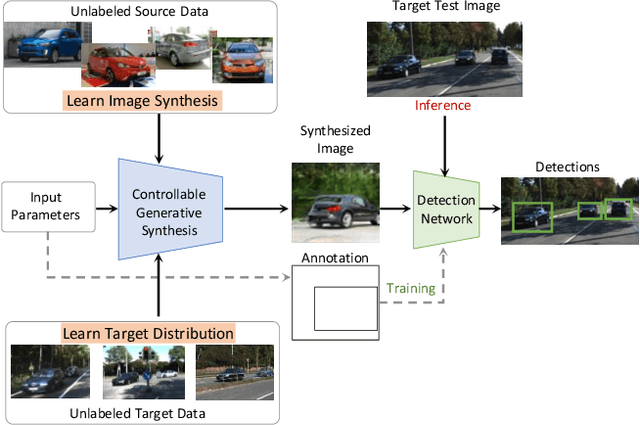
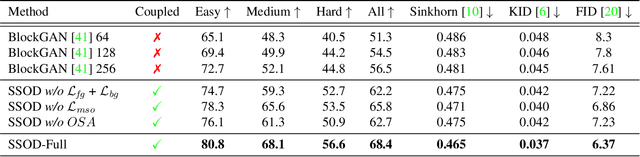
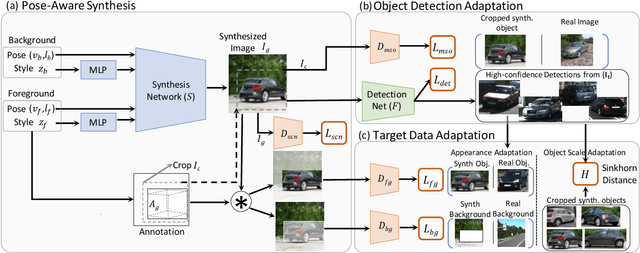
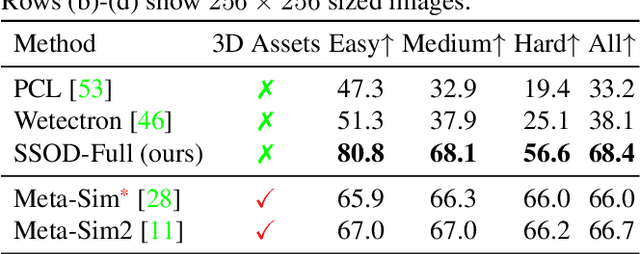
We present SSOD, the first end-to-end analysis-by synthesis framework with controllable GANs for the task of self-supervised object detection. We use collections of real world images without bounding box annotations to learn to synthesize and detect objects. We leverage controllable GANs to synthesize images with pre-defined object properties and use them to train object detectors. We propose a tight end-to-end coupling of the synthesis and detection networks to optimally train our system. Finally, we also propose a method to optimally adapt SSOD to an intended target data without requiring labels for it. For the task of car detection, on the challenging KITTI and Cityscapes datasets, we show that SSOD outperforms the prior state-of-the-art purely image-based self-supervised object detection method Wetectron. Even without requiring any 3D CAD assets, it also surpasses the state-of-the-art rendering based method Meta-Sim2. Our work advances the field of self-supervised object detection by introducing a successful new paradigm of using controllable GAN-based image synthesis for it and by significantly improving the baseline accuracy of the task. We open-source our code at https://github.com/NVlabs/SSOD.
Towards the Use of Saliency Maps for Explaining Low-Quality Electrocardiograms to End Users
Jul 06, 2022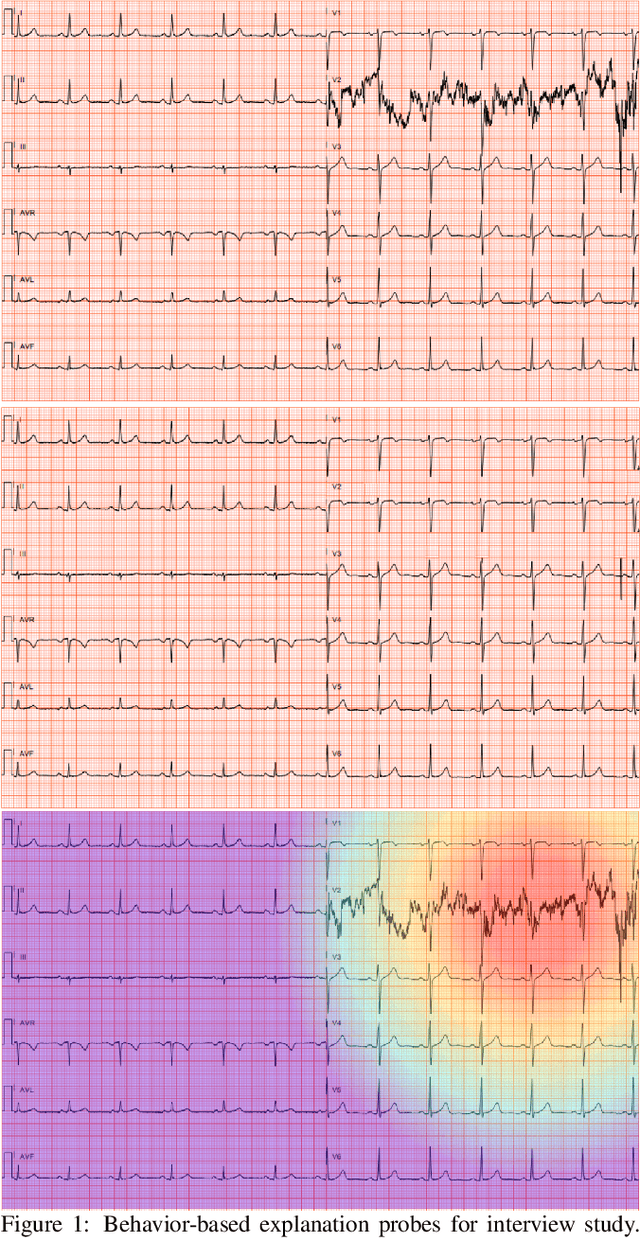

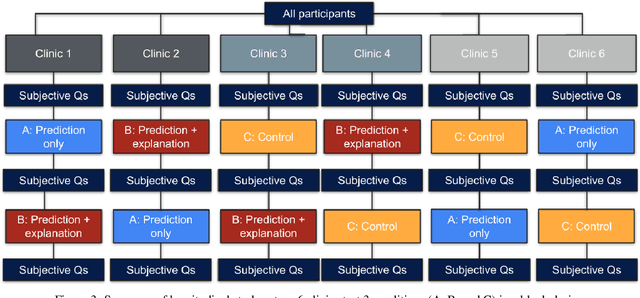
When using medical images for diagnosis, either by clinicians or artificial intelligence (AI) systems, it is important that the images are of high quality. When an image is of low quality, the medical exam that produced the image often needs to be redone. In telemedicine, a common problem is that the quality issue is only flagged once the patient has left the clinic, meaning they must return in order to have the exam redone. This can be especially difficult for people living in remote regions, who make up a substantial portion of the patients at Portal Telemedicina, a digital healthcare organization based in Brazil. In this paper, we report on ongoing work regarding (i) the development of an AI system for flagging and explaining low-quality medical images in real-time, (ii) an interview study to understand the explanation needs of stakeholders using the AI system at OurCompany, and, (iii) a longitudinal user study design to examine the effect of including explanations on the workflow of the technicians in our clinics. To the best of our knowledge, this would be the first longitudinal study on evaluating the effects of XAI methods on end-users -- stakeholders that use AI systems but do not have AI-specific expertise. We welcome feedback and suggestions on our experimental setup.
Inpainting at Modern Camera Resolution by Guided PatchMatch with Auto-Curation
Aug 06, 2022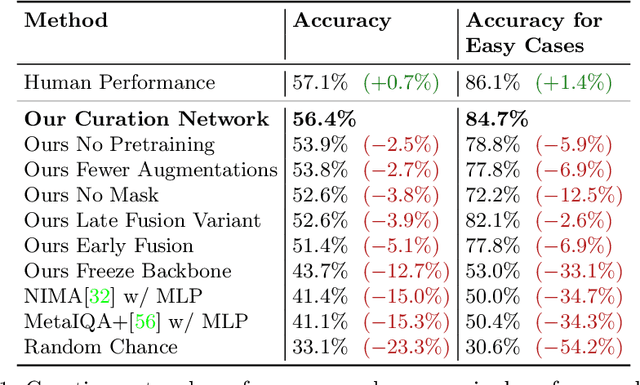

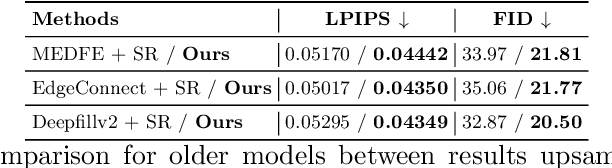

Recently, deep models have established SOTA performance for low-resolution image inpainting, but they lack fidelity at resolutions associated with modern cameras such as 4K or more, and for large holes. We contribute an inpainting benchmark dataset of photos at 4K and above representative of modern sensors. We demonstrate a novel framework that combines deep learning and traditional methods. We use an existing deep inpainting model LaMa to fill the hole plausibly, establish three guide images consisting of structure, segmentation, depth, and apply a multiply-guided PatchMatch to produce eight candidate upsampled inpainted images. Next, we feed all candidate inpaintings through a novel curation module that chooses a good inpainting by column summation on an 8x8 antisymmetric pairwise preference matrix. Our framework's results are overwhelmingly preferred by users over 8 strong baselines, with improvements of quantitative metrics up to 7.4 over the best baseline LaMa, and our technique when paired with 4 different SOTA inpainting backbones improves each such that ours is overwhelmingly preferred by users over a strong super-res baseline.
Scalable Reverse Image Search Engine for NASAWorldview
Aug 10, 2021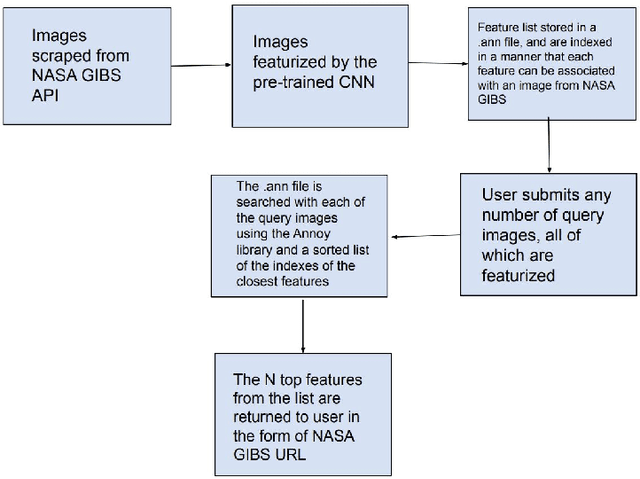
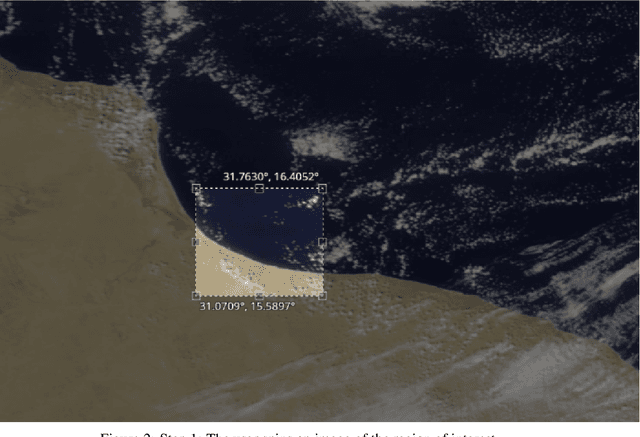


Researchers often spend weeks sifting through decades of unlabeled satellite imagery(on NASA Worldview) in order to develop datasets on which they can start conducting research. We developed an interactive, scalable and fast image similarity search engine (which can take one or more images as the query image) that automatically sifts through the unlabeled dataset reducing dataset generation time from weeks to minutes. In this work, we describe key components of the end to end pipeline. Our similarity search system was created to be able to identify similar images from a potentially petabyte scale database that are similar to an input image, and for this we had to break down each query image into its features, which were generated by a classification layer stripped CNN trained in a supervised manner. To store and search these features efficiently, we had to make several scalability improvements. To improve the speed, reduce the storage, and shrink memory requirements for embedding search, we add a fully connected layer to our CNN make all images into a 128 length vector before entering the classification layers. This helped us compress the size of our image features from 2048 (for ResNet, which was initially tried as our featurizer) to 128 for our new custom model. Additionally, we utilize existing approximate nearest neighbor search libraries to significantly speed up embedding search. Our system currently searches over our entire database of images at 5 seconds per query on a single virtual machine in the cloud. In the future, we would like to incorporate a SimCLR based featurizing model which could be trained without any labelling by a human (since the classification aspect of the model is irrelevant to this use case).