 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Jointformer: Single-Frame Lifting Transformer with Error Prediction and Refinement for 3D Human Pose Estimation
Aug 07, 2022
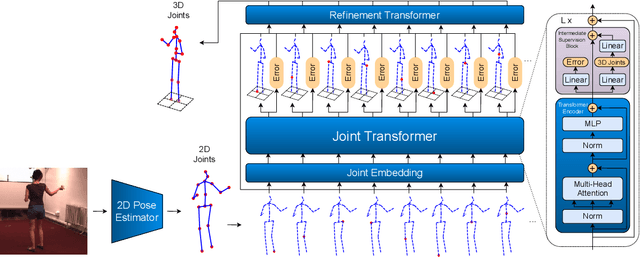
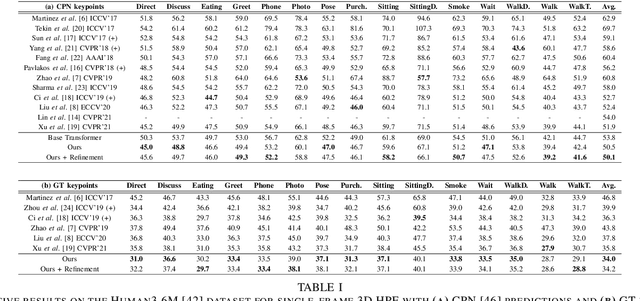
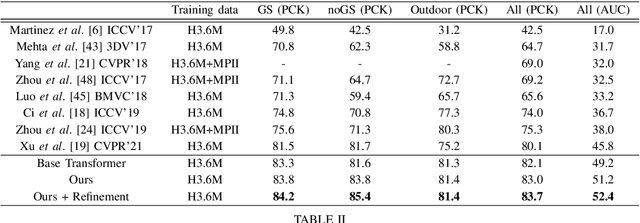
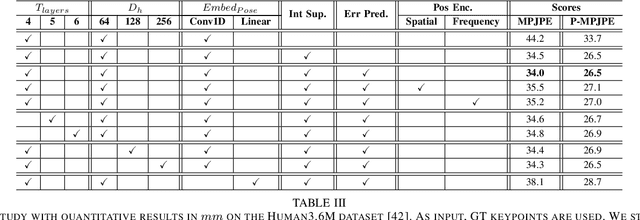
Monocular 3D human pose estimation technologies have the potential to greatly increase the availability of human movement data. The best-performing models for single-image 2D-3D lifting use graph convolutional networks (GCNs) that typically require some manual input to define the relationships between different body joints. We propose a novel transformer-based approach that uses the more generalised self-attention mechanism to learn these relationships within a sequence of tokens representing joints. We find that the use of intermediate supervision, as well as residual connections between the stacked encoders benefits performance. We also suggest that using error prediction as part of a multi-task learning framework improves performance by allowing the network to compensate for its confidence level. We perform extensive ablation studies to show that each of our contributions increases performance. Furthermore, we show that our approach outperforms the recent state of the art for single-frame 3D human pose estimation by a large margin. Our code and trained models are made publicly available on Github.
Faster Diffusion Cardiac MRI with Deep Learning-based breath hold reduction
Jun 21, 2022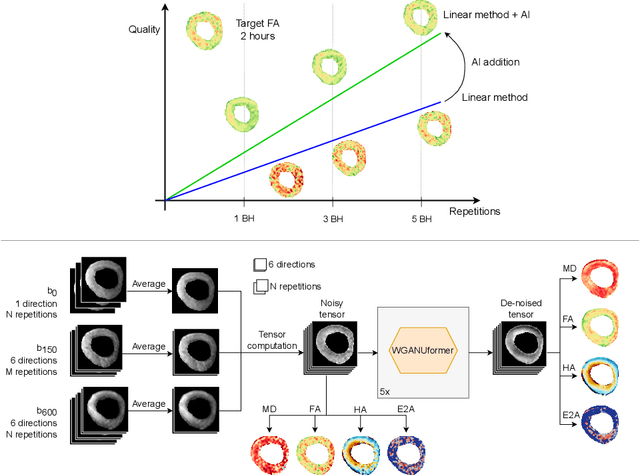
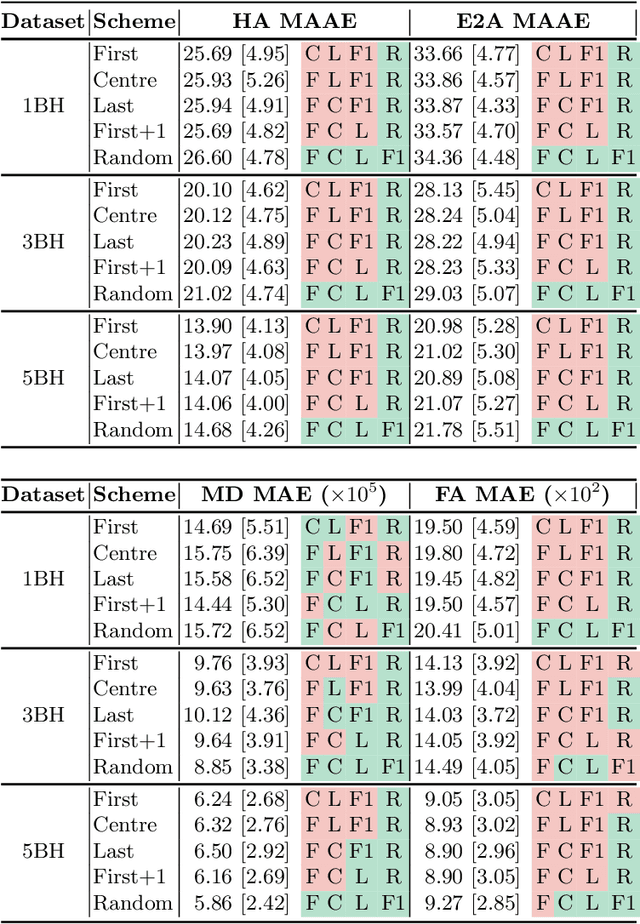
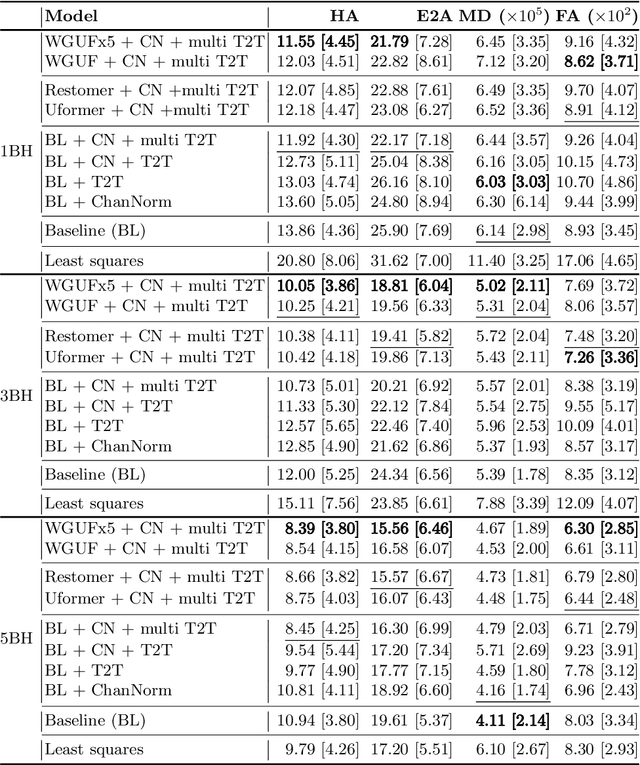
Diffusion Tensor Cardiac Magnetic Resonance (DT-CMR) enables us to probe the microstructural arrangement of cardiomyocytes within the myocardium in vivo and non-invasively, which no other imaging modality allows. This innovative technology could revolutionise the ability to perform cardiac clinical diagnosis, risk stratification, prognosis and therapy follow-up. However, DT-CMR is currently inefficient with over six minutes needed to acquire a single 2D static image. Therefore, DT-CMR is currently confined to research but not used clinically. We propose to reduce the number of repetitions needed to produce DT-CMR datasets and subsequently de-noise them, decreasing the acquisition time by a linear factor while maintaining acceptable image quality. Our proposed approach, based on Generative Adversarial Networks, Vision Transformers, and Ensemble Learning, performs significantly and considerably better than previous proposed approaches, bringing single breath-hold DT-CMR closer to reality.
Progress and limitations of deep networks to recognize objects in unusual poses
Jul 16, 2022
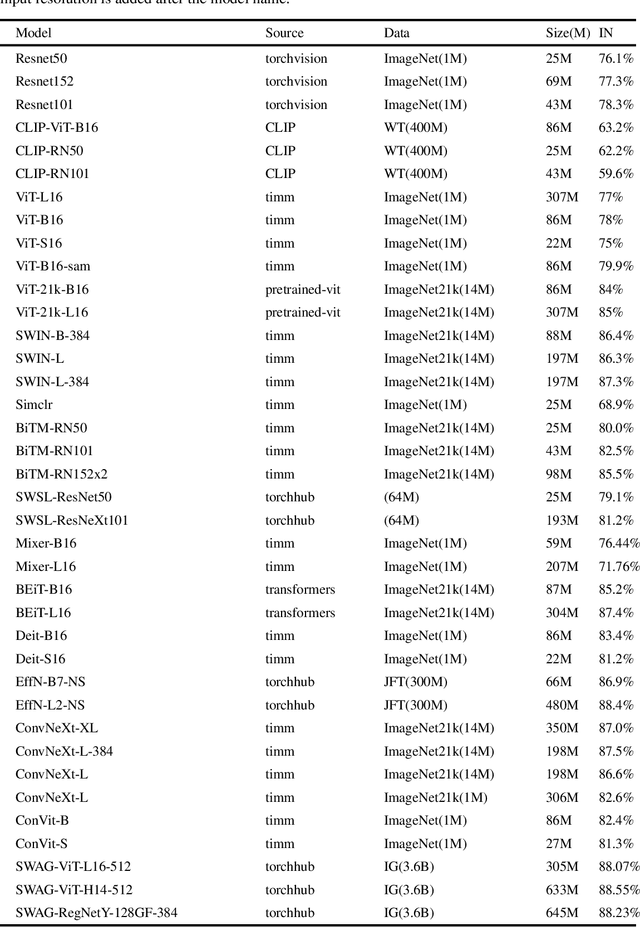
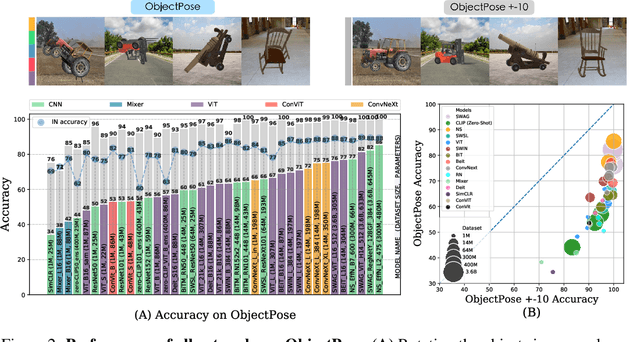
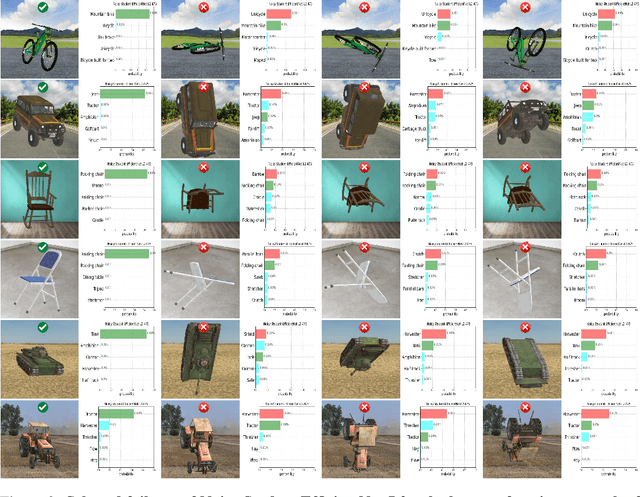
Deep networks should be robust to rare events if they are to be successfully deployed in high-stakes real-world applications (e.g., self-driving cars). Here we study the capability of deep networks to recognize objects in unusual poses. We create a synthetic dataset of images of objects in unusual orientations, and evaluate the robustness of a collection of 38 recent and competitive deep networks for image classification. We show that classifying these images is still a challenge for all networks tested, with an average accuracy drop of 29.5% compared to when the objects are presented upright. This brittleness is largely unaffected by various network design choices, such as training losses (e.g., supervised vs. self-supervised), architectures (e.g., convolutional networks vs. transformers), dataset modalities (e.g., images vs. image-text pairs), and data-augmentation schemes. However, networks trained on very large datasets substantially outperform others, with the best network tested$\unicode{x2014}$Noisy Student EfficentNet-L2 trained on JFT-300M$\unicode{x2014}$showing a relatively small accuracy drop of only 14.5% on unusual poses. Nevertheless, a visual inspection of the failures of Noisy Student reveals a remaining gap in robustness with the human visual system. Furthermore, combining multiple object transformations$\unicode{x2014}$3D-rotations and scaling$\unicode{x2014}$further degrades the performance of all networks. Altogether, our results provide another measurement of the robustness of deep networks that is important to consider when using them in the real world. Code and datasets are available at https://github.com/amro-kamal/ObjectPose.
Learning from Noisy Labels with Coarse-to-Fine Sample Credibility Modeling
Aug 23, 2022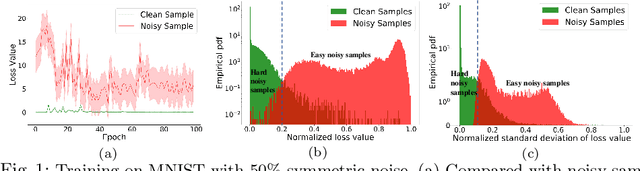
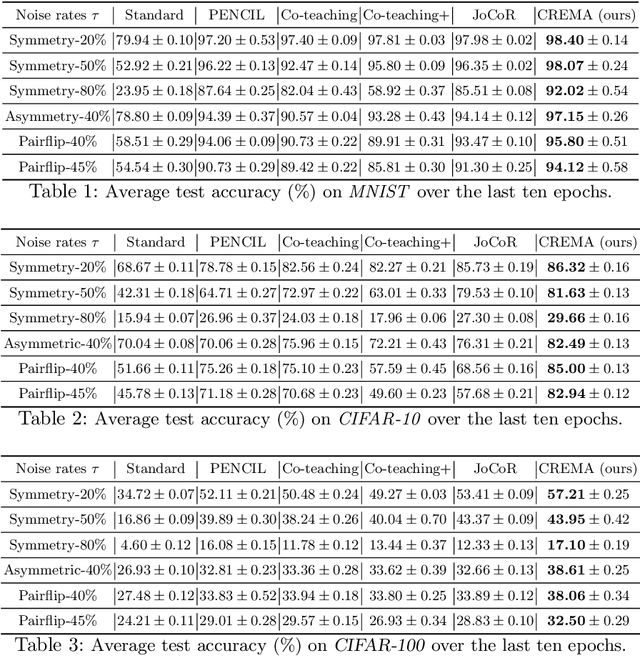
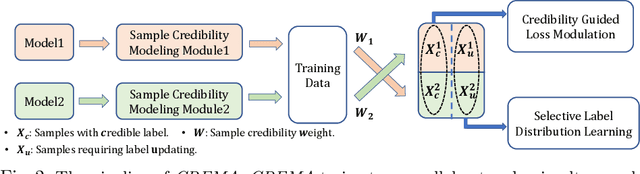
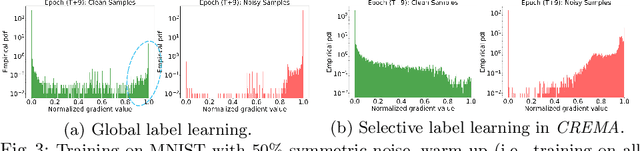
Training deep neural network (DNN) with noisy labels is practically challenging since inaccurate labels severely degrade the generalization ability of DNN. Previous efforts tend to handle part or full data in a unified denoising flow via identifying noisy data with a coarse small-loss criterion to mitigate the interference from noisy labels, ignoring the fact that the difficulties of noisy samples are different, thus a rigid and unified data selection pipeline cannot tackle this problem well. In this paper, we first propose a coarse-to-fine robust learning method called CREMA, to handle noisy data in a divide-and-conquer manner. In coarse-level, clean and noisy sets are firstly separated in terms of credibility in a statistical sense. Since it is practically impossible to categorize all noisy samples correctly, we further process them in a fine-grained manner via modeling the credibility of each sample. Specifically, for the clean set, we deliberately design a memory-based modulation scheme to dynamically adjust the contribution of each sample in terms of its historical credibility sequence during training, thus alleviating the effect from noisy samples incorrectly grouped into the clean set. Meanwhile, for samples categorized into the noisy set, a selective label update strategy is proposed to correct noisy labels while mitigating the problem of correction error. Extensive experiments are conducted on benchmarks of different modalities, including image classification (CIFAR, Clothing1M etc) and text recognition (IMDB), with either synthetic or natural semantic noises, demonstrating the superiority and generality of CREMA.
GAUDI: A Neural Architect for Immersive 3D Scene Generation
Jul 27, 2022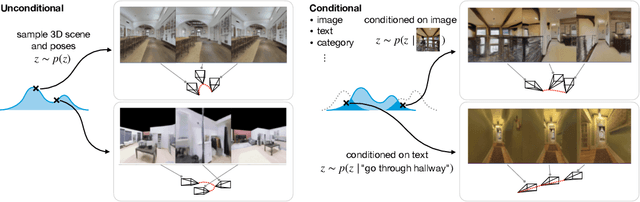
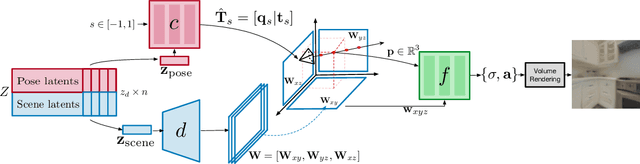

We introduce GAUDI, a generative model capable of capturing the distribution of complex and realistic 3D scenes that can be rendered immersively from a moving camera. We tackle this challenging problem with a scalable yet powerful approach, where we first optimize a latent representation that disentangles radiance fields and camera poses. This latent representation is then used to learn a generative model that enables both unconditional and conditional generation of 3D scenes. Our model generalizes previous works that focus on single objects by removing the assumption that the camera pose distribution can be shared across samples. We show that GAUDI obtains state-of-the-art performance in the unconditional generative setting across multiple datasets and allows for conditional generation of 3D scenes given conditioning variables like sparse image observations or text that describes the scene.
Surrogate-assisted Multi-objective Neural Architecture Search for Real-time Semantic Segmentation
Aug 14, 2022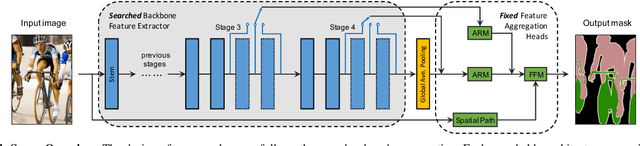
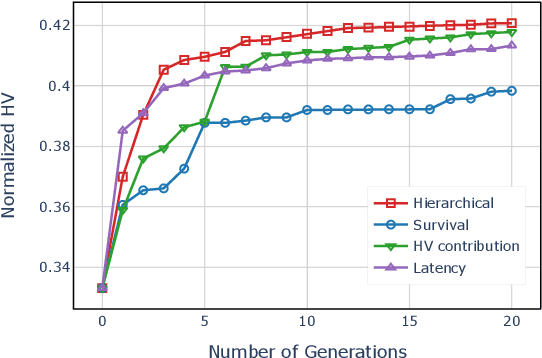
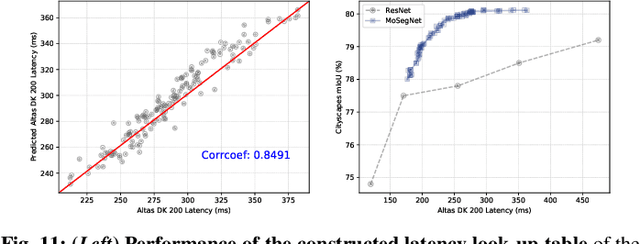
The architectural advancements in deep neural networks have led to remarkable leap-forwards across a broad array of computer vision tasks. Instead of relying on human expertise, neural architecture search (NAS) has emerged as a promising avenue toward automating the design of architectures. While recent achievements in image classification have suggested opportunities, the promises of NAS have yet to be thoroughly assessed on more challenging tasks of semantic segmentation. The main challenges of applying NAS to semantic segmentation arise from two aspects: (i) high-resolution images to be processed; (ii) additional requirement of real-time inference speed (i.e., real-time semantic segmentation) for applications such as autonomous driving. To meet such challenges, we propose a surrogate-assisted multi-objective method in this paper. Through a series of customized prediction models, our method effectively transforms the original NAS task into an ordinary multi-objective optimization problem. Followed by a hierarchical pre-screening criterion for in-fill selection, our method progressively achieves a set of efficient architectures trading-off between segmentation accuracy and inference speed. Empirical evaluations on three benchmark datasets together with an application using Huawei Atlas 200 DK suggest that our method can identify architectures significantly outperforming existing state-of-the-art architectures designed both manually by human experts and automatically by other NAS methods.
One Model to Unite Them All: Personalized Federated Learning of Multi-Contrast MRI Synthesis
Jul 13, 2022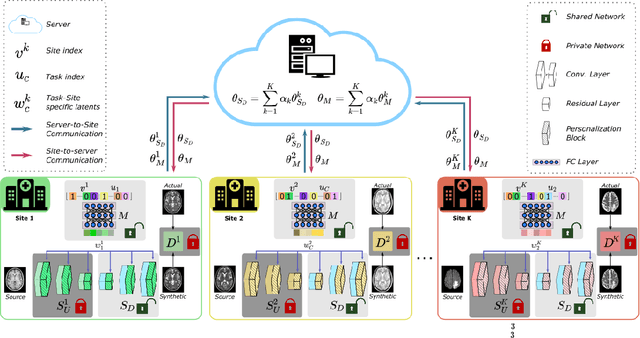
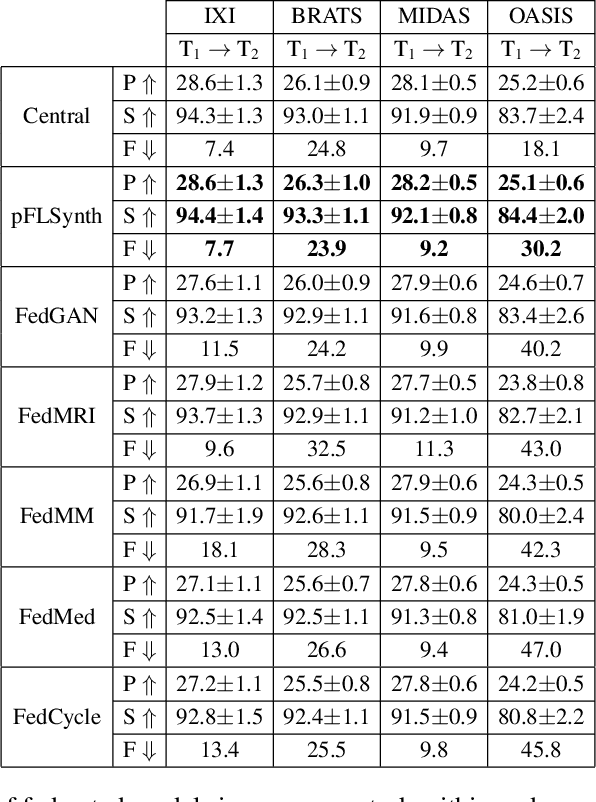
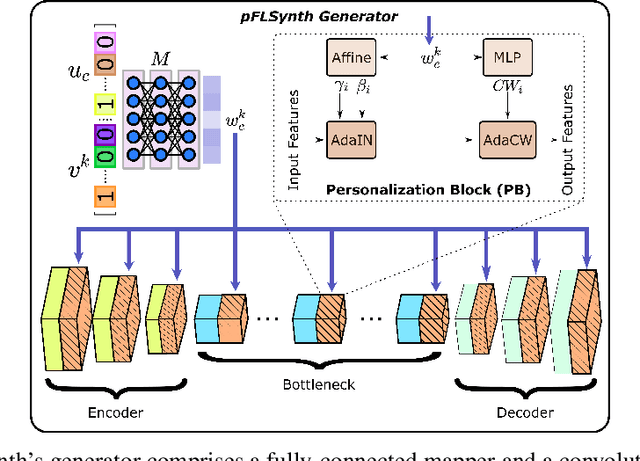
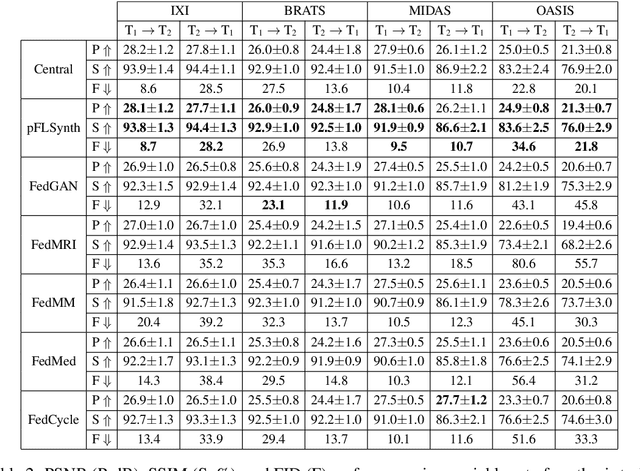
Learning-based MRI translation involves a synthesis model that maps a source-contrast onto a target-contrast image. Multi-institutional collaborations are key to training synthesis models across broad datasets, yet centralized training involves privacy risks. Federated learning (FL) is a collaboration framework that instead adopts decentralized training to avoid sharing imaging data and mitigate privacy concerns. However, FL-trained models can be impaired by the inherent heterogeneity in the distribution of imaging data. On the one hand, implicit shifts in image distribution are evident across sites, even for a common translation task with fixed source-target configuration. Conversely, explicit shifts arise within and across sites when diverse translation tasks with varying source-target configurations are prescribed. To improve reliability against domain shifts, here we introduce the first personalized FL method for MRI Synthesis (pFLSynth). pFLSynth is based on an adversarial model equipped with a mapper that produces latents specific to individual sites and source-target contrasts. It leverages novel personalization blocks that adaptively tune the statistics and weighting of feature maps across the generator based on these latents. To further promote site-specificity, partial model aggregation is employed over downstream layers of the generator while upstream layers are retained locally. As such, pFLSynth enables training of a unified synthesis model that can reliably generalize across multiple sites and translation tasks. Comprehensive experiments on multi-site datasets clearly demonstrate the enhanced performance of pFLSynth against prior federated methods in multi-contrast MRI synthesis.
Joint Implicit Image Function for Guided Depth Super-Resolution
Jul 23, 2021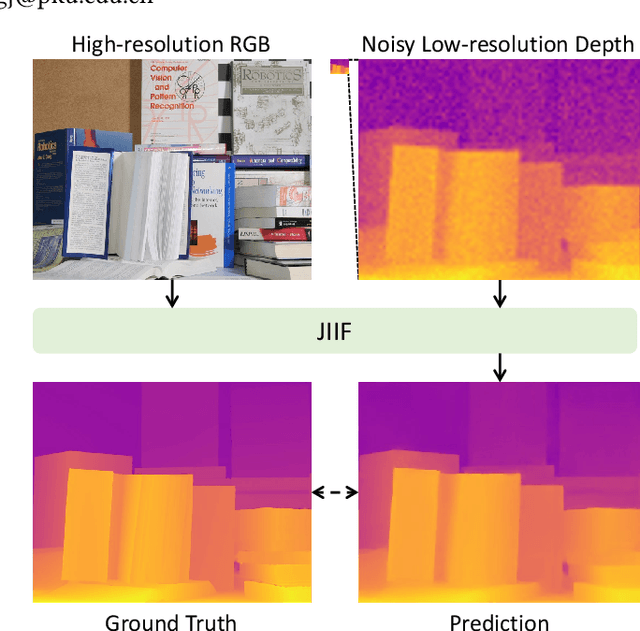
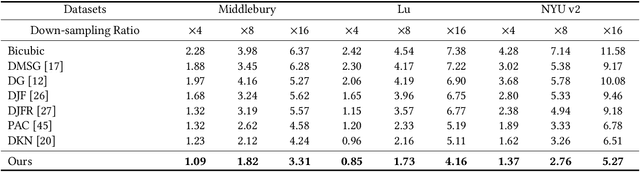
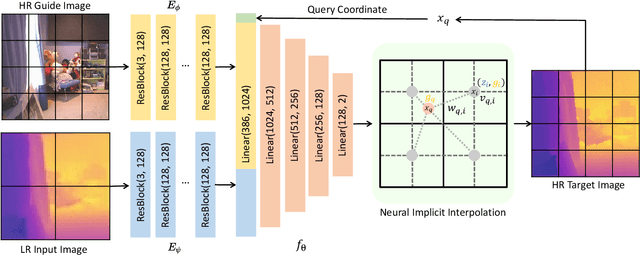
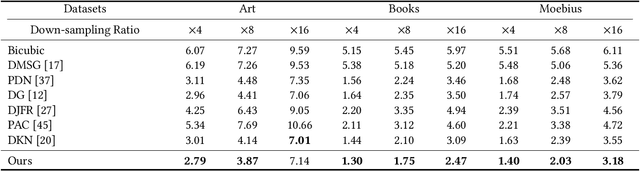
Guided depth super-resolution is a practical task where a low-resolution and noisy input depth map is restored to a high-resolution version, with the help of a high-resolution RGB guide image. Existing methods usually view this task as a generalized guided filtering problem that relies on designing explicit filters and objective functions, or a dense regression problem that directly predicts the target image via deep neural networks. These methods suffer from either model capability or interpretability. Inspired by the recent progress in implicit neural representation, we propose to formulate the guided super-resolution as a neural implicit image interpolation problem, where we take the form of a general image interpolation but use a novel Joint Implicit Image Function (JIIF) representation to learn both the interpolation weights and values. JIIF represents the target image domain with spatially distributed local latent codes extracted from the input image and the guide image, and uses a graph attention mechanism to learn the interpolation weights at the same time in one unified deep implicit function. We demonstrate the effectiveness of our JIIF representation on guided depth super-resolution task, significantly outperforming state-of-the-art methods on three public benchmarks. Code can be found at \url{https://git.io/JC2sU}.
N-RPN: Hard Example Learning for Region Proposal Networks
Aug 03, 2022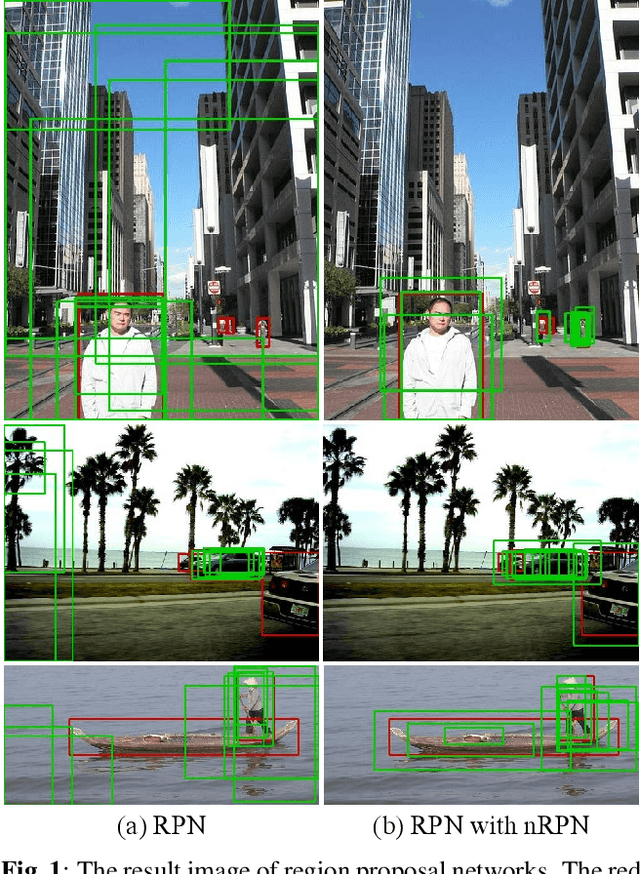

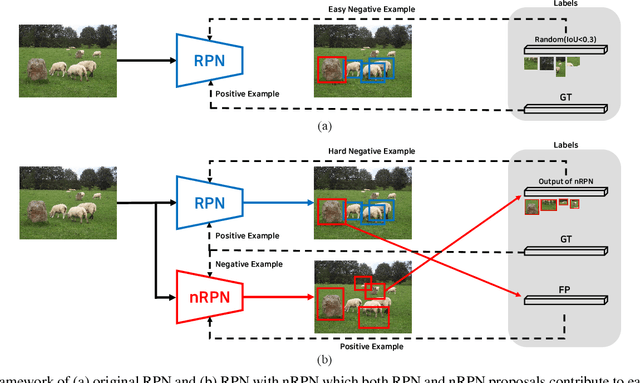
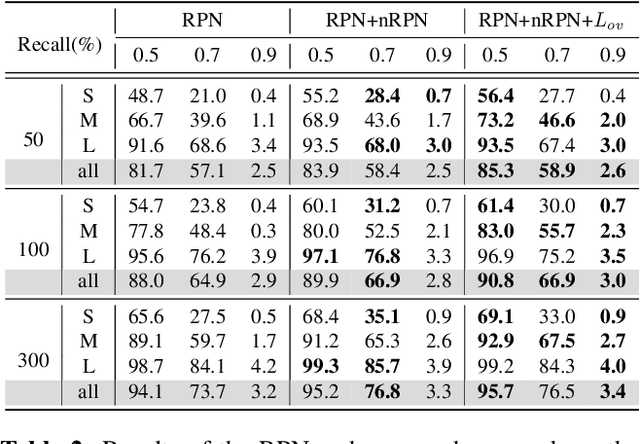
The region proposal task is to generate a set of candidate regions that contain an object. In this task, it is most important to propose as many candidates of ground-truth as possible in a fixed number of proposals. In a typical image, however, there are too few hard negative examples compared to the vast number of easy negatives, so region proposal networks struggle to train on hard negatives. Because of this problem, networks tend to propose hard negatives as candidates, while failing to propose ground-truth candidates, which leads to poor performance. In this paper, we propose a Negative Region Proposal Network(nRPN) to improve Region Proposal Network(RPN). The nRPN learns from the RPN's false positives and provide hard negative examples to the RPN. Our proposed nRPN leads to a reduction in false positives and better RPN performance. An RPN trained with an nRPN achieves performance improvements on the PASCAL VOC 2007 dataset.
Human Eyes Inspired Recurrent Neural Networks are More Robust Against Adversarial Noises
Jun 15, 2022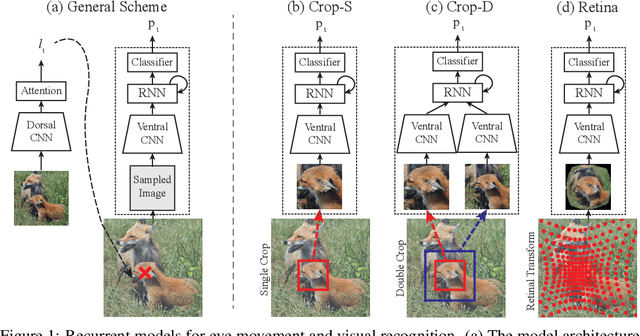

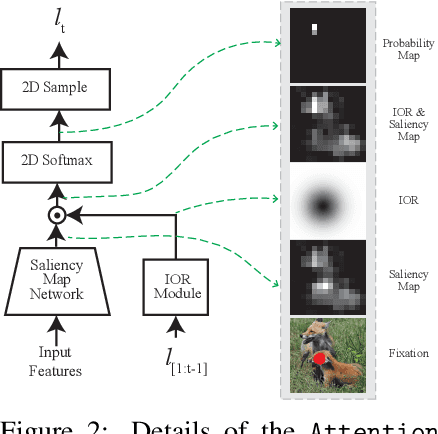

Compared to human vision, computer vision based on convolutional neural networks (CNN) are more vulnerable to adversarial noises. This difference is likely attributable to how the eyes sample visual input and how the brain processes retinal samples through its dorsal and ventral visual pathways, which are under-explored for computer vision. Inspired by the brain, we design recurrent neural networks, including an input sampler that mimics the human retina, a dorsal network that guides where to look next, and a ventral network that represents the retinal samples. Taking these modules together, the models learn to take multiple glances at an image, attend to a salient part at each glance, and accumulate the representation over time to recognize the image. We test such models for their robustness against a varying level of adversarial noises with a special focus on the effect of different input sampling strategies. Our findings suggest that retinal foveation and sampling renders a model more robust against adversarial noises, and the model may correct itself from an attack when it is given a longer time to take more glances at an image. In conclusion, robust visual recognition can benefit from the combined use of three brain-inspired mechanisms: retinal transformation, attention guided eye movement, and recurrent processing, as opposed to feedforward-only CNNs.