 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
OmniMAE: Single Model Masked Pretraining on Images and Videos
Jun 16, 2022
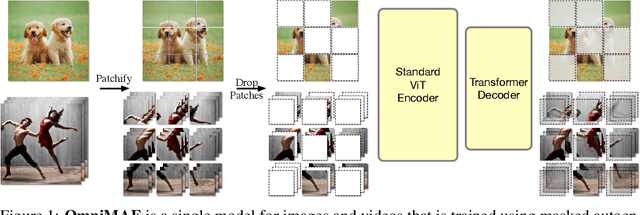

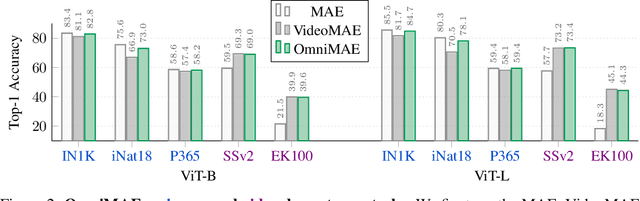
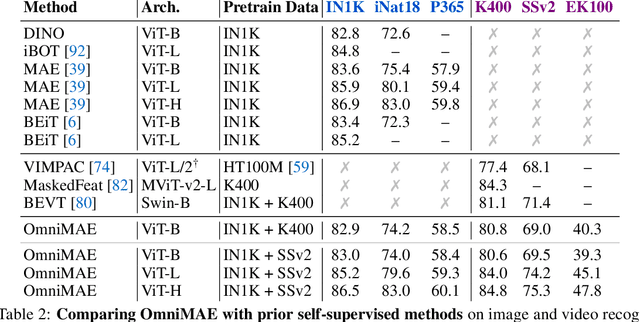
Transformer-based architectures have become competitive across a variety of visual domains, most notably images and videos. While prior work has studied these modalities in isolation, having a common architecture suggests that one can train a single unified model for multiple visual modalities. Prior attempts at unified modeling typically use architectures tailored for vision tasks, or obtain worse performance compared to single modality models. In this work, we show that masked autoencoding can be used to train a simple Vision Transformer on images and videos, without requiring any labeled data. This single model learns visual representations that are comparable to or better than single-modality representations on both image and video benchmarks, while using a much simpler architecture. In particular, our single pretrained model can be finetuned to achieve 86.5% on ImageNet and 75.3% on the challenging Something Something-v2 video benchmark. Furthermore, this model can be learned by dropping 90% of the image and 95% of the video patches, enabling extremely fast training.
Evaluating histopathology transfer learning with ChampKit
Jun 14, 2022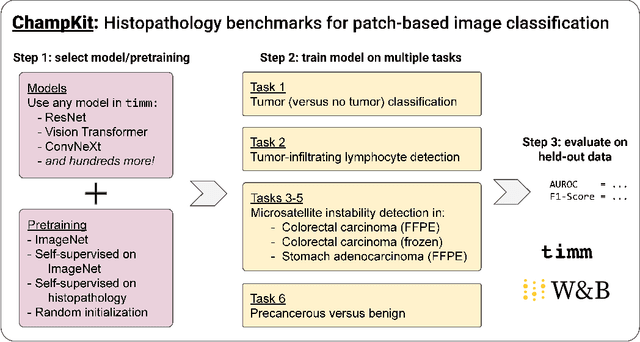
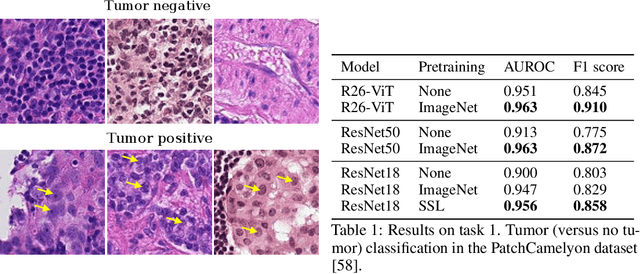
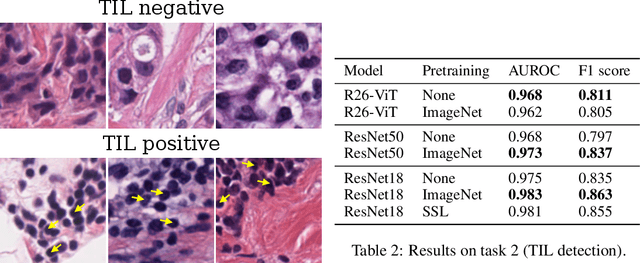
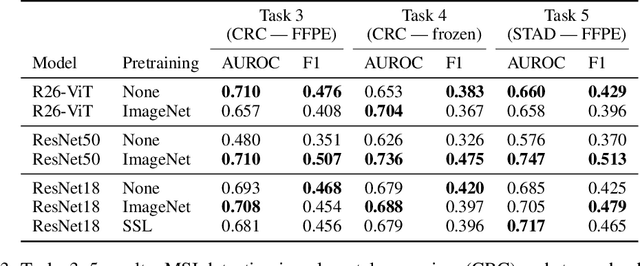
Histopathology remains the gold standard for diagnosis of various cancers. Recent advances in computer vision, specifically deep learning, have facilitated the analysis of histopathology images for various tasks, including immune cell detection and microsatellite instability classification. The state-of-the-art for each task often employs base architectures that have been pretrained for image classification on ImageNet. The standard approach to develop classifiers in histopathology tends to focus narrowly on optimizing models for a single task, not considering the aspects of modeling innovations that improve generalization across tasks. Here we present ChampKit (Comprehensive Histopathology Assessment of Model Predictions toolKit): an extensible, fully reproducible benchmarking toolkit that consists of a broad collection of patch-level image classification tasks across different cancers. ChampKit enables a way to systematically document the performance impact of proposed improvements in models and methodology. ChampKit source code and data are freely accessible at https://github.com/kaczmarj/champkit .
An Empirical Analysis of Recurrent Learning Algorithms In Neural Lossy Image Compression Systems
Jan 27, 2022Recent advances in deep learning have resulted in image compression algorithms that outperform JPEG and JPEG 2000 on the standard Kodak benchmark. However, they are slow to train (due to backprop-through-time) and, to the best of our knowledge, have not been systematically evaluated on a large variety of datasets. In this paper, we perform the first large-scale comparison of recent state-of-the-art hybrid neural compression algorithms, while exploring the effects of alternative training strategies (when applicable). The hybrid recurrent neural decoder is a former state-of-the-art model (recently overtaken by a Google model) that can be trained using backprop-through-time (BPTT) or with alternative algorithms like sparse attentive backtracking (SAB), unbiased online recurrent optimization (UORO), and real-time recurrent learning (RTRL). We compare these training alternatives along with the Google models (GOOG and E2E) on 6 benchmark datasets. Surprisingly, we found that the model trained with SAB performs better (outperforming even BPTT), resulting in faster convergence and a better peak signal-to-noise ratio.
Deep Laparoscopic Stereo Matching with Transformers
Jul 25, 2022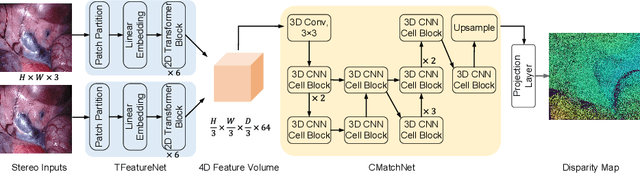

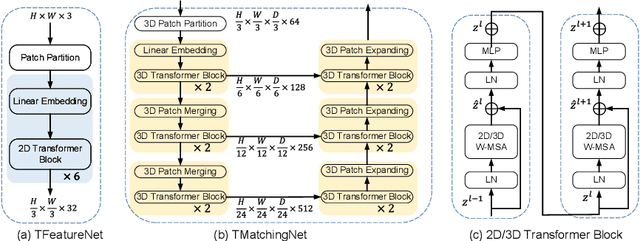
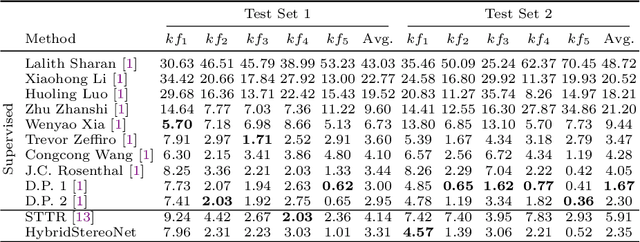
The self-attention mechanism, successfully employed with the transformer structure is shown promise in many computer vision tasks including image recognition, and object detection. Despite the surge, the use of the transformer for the problem of stereo matching remains relatively unexplored. In this paper, we comprehensively investigate the use of the transformer for the problem of stereo matching, especially for laparoscopic videos, and propose a new hybrid deep stereo matching framework (HybridStereoNet) that combines the best of the CNN and the transformer in a unified design. To be specific, we investigate several ways to introduce transformers to volumetric stereo matching pipelines by analyzing the loss landscape of the designs and in-domain/cross-domain accuracy. Our analysis suggests that employing transformers for feature representation learning, while using CNNs for cost aggregation will lead to faster convergence, higher accuracy and better generalization than other options. Our extensive experiments on Sceneflow, SCARED2019 and dVPN datasets demonstrate the superior performance of our HybridStereoNet.
Knowing Where and What: Unified Word Block Pretraining for Document Understanding
Jul 29, 2022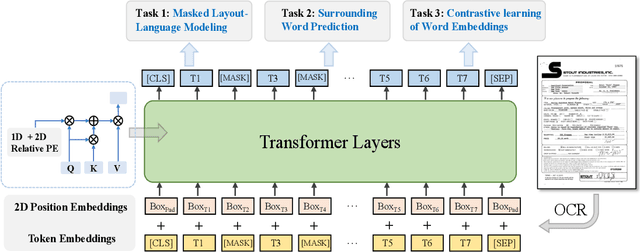
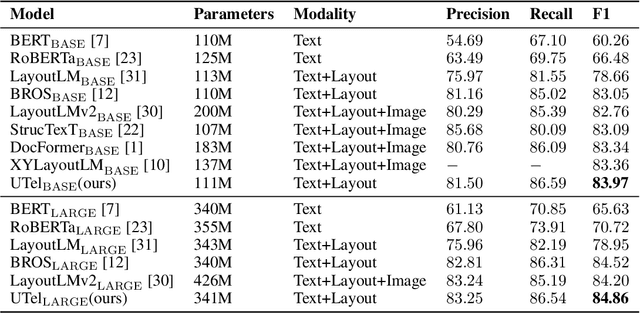
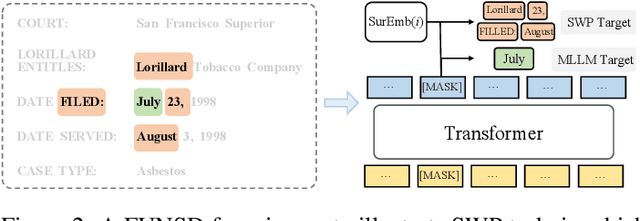

Due to the complex layouts of documents, it is challenging to extract information for documents. Most previous studies develop multimodal pre-trained models in a self-supervised way. In this paper, we focus on the embedding learning of word blocks containing text and layout information, and propose UTel, a language model with Unified TExt and Layout pre-training. Specifically, we propose two pre-training tasks: Surrounding Word Prediction (SWP) for the layout learning, and Contrastive learning of Word Embeddings (CWE) for identifying different word blocks. Moreover, we replace the commonly used 1D position embedding with a 1D clipped relative position embedding. In this way, the joint training of Masked Layout-Language Modeling (MLLM) and two newly proposed tasks enables the interaction between semantic and spatial features in a unified way. Additionally, the proposed UTel can process arbitrary-length sequences by removing the 1D position embedding, while maintaining competitive performance. Extensive experimental results show UTel learns better joint representations and achieves superior performance than previous methods on various downstream tasks, though requiring no image modality. Code is available at \url{https://github.com/taosong2019/UTel}.
Image-to-Image Translation: Methods and Applications
Jan 21, 2021

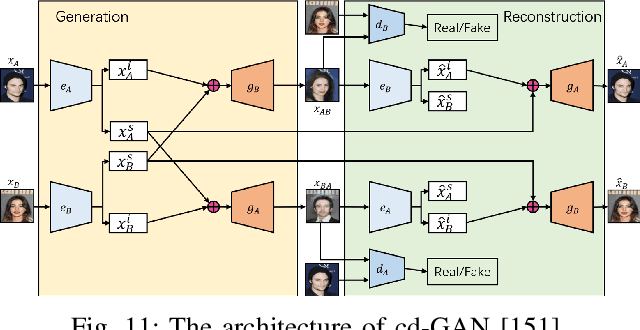
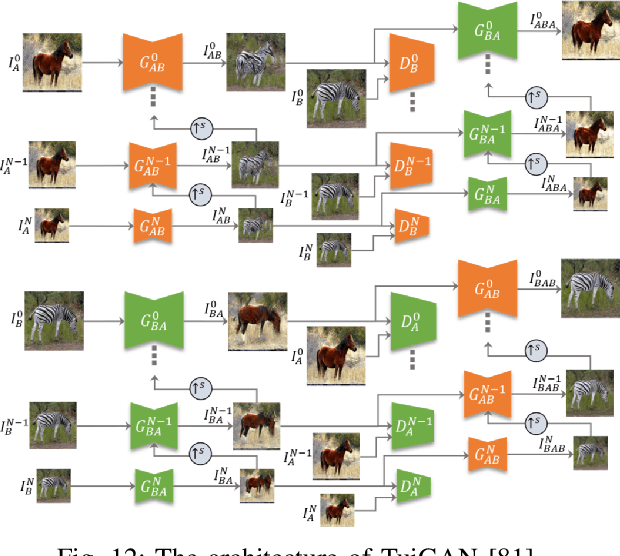
Image-to-image translation (I2I) aims to transfer images from a source domain to a target domain while preserving the content representations. I2I has drawn increasing attention and made tremendous progress in recent years because of its wide range of applications in many computer vision and image processing problems, such as image synthesis, segmentation, style transfer, restoration, and pose estimation. In this paper, we provide an overview of the I2I works developed in recent years. We will analyze the key techniques of the existing I2I works and clarify the main progress the community has made. Additionally, we will elaborate on the effect of I2I on the research and industry community and point out remaining challenges in related fields.
A Comprehensive Analysis of AI Biases in DeepFake Detection With Massively Annotated Databases
Aug 11, 2022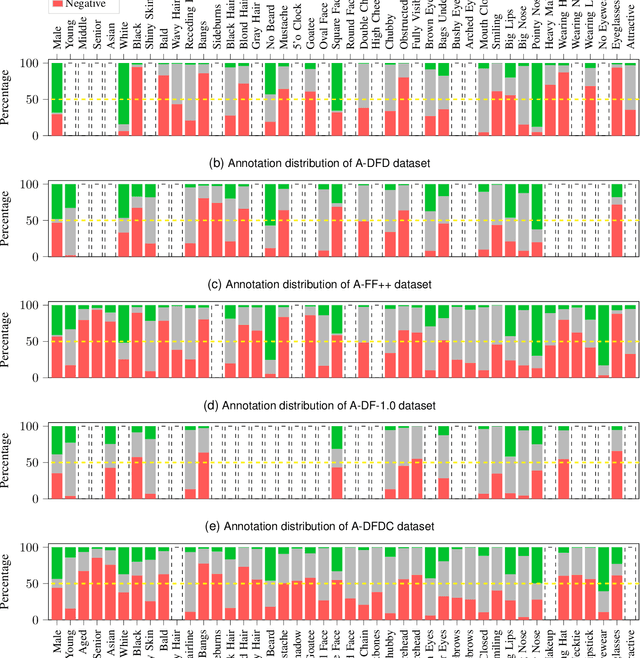
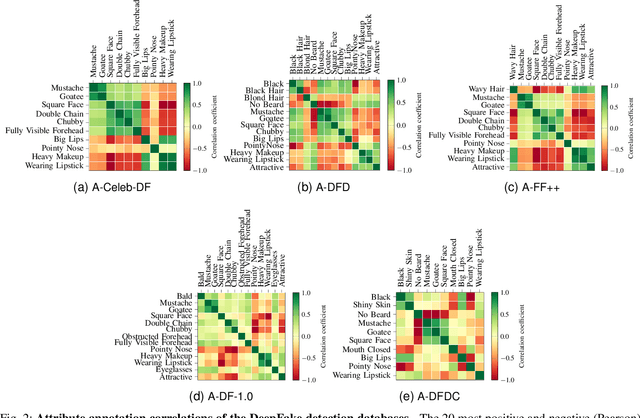
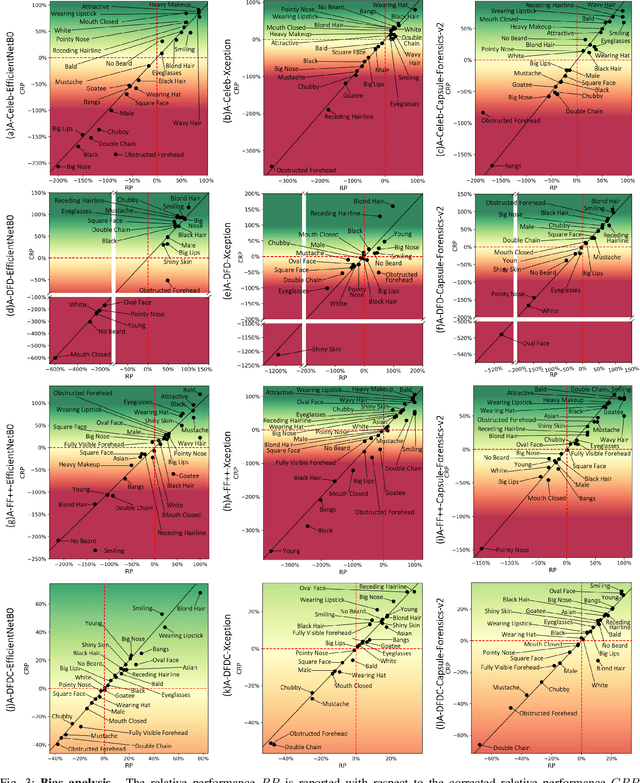
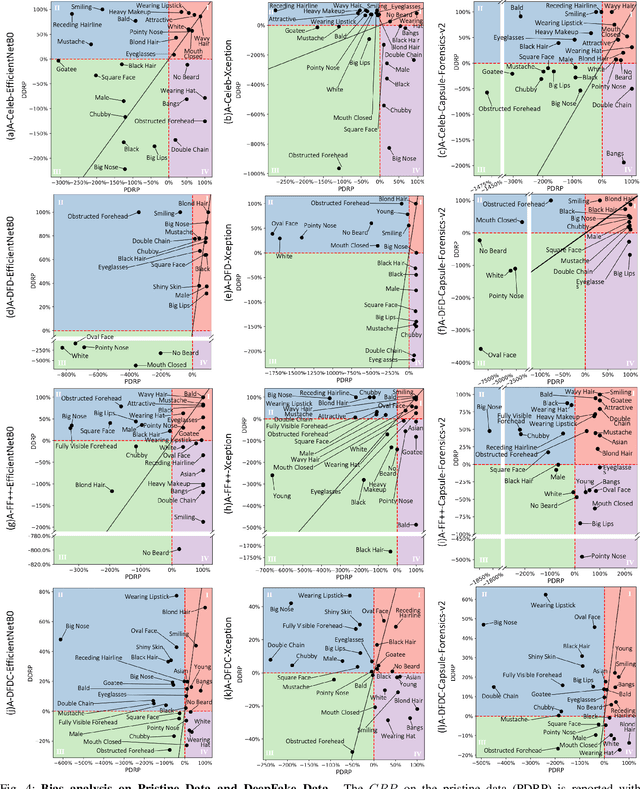
In recent years, image and video manipulations with DeepFake have become a severe concern for security and society. Therefore, many detection models and databases have been proposed to detect DeepFake data reliably. However, there is an increased concern that these models and training databases might be biased and thus, cause DeepFake detectors to fail. In this work, we tackle these issues by (a) providing large-scale demographic and non-demographic attribute annotations of 41 different attributes for five popular DeepFake datasets and (b) comprehensively analysing AI-bias of multiple state-of-the-art DeepFake detection models on these databases. The investigation analyses the influence of a large variety of distinctive attributes (from over 65M labels) on the detection performance, including demographic (age, gender, ethnicity) and non-demographic (hair, skin, accessories, etc.) information. The results indicate that investigated databases lack diversity and, more importantly, show that the utilised DeepFake detection models are strongly biased towards many investigated attributes. Moreover, the results show that the models' decision-making might be based on several questionable (biased) assumptions, such if a person is smiling or wearing a hat. Depending on the application of such DeepFake detection methods, these biases can lead to generalizability, fairness, and security issues. We hope that the findings of this study and the annotation databases will help to evaluate and mitigate bias in future DeepFake detection techniques. Our annotation datasets are made publicly available.
Open-Set Recognition with Gradient-Based Representations
Jun 16, 2022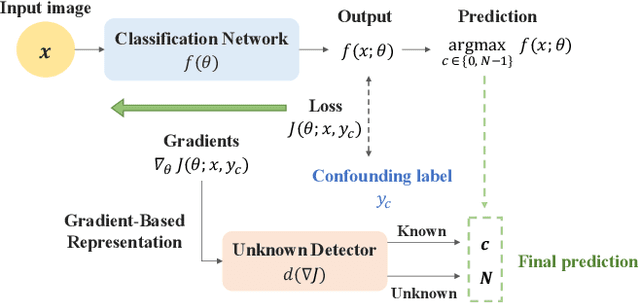
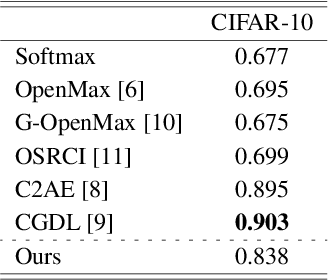
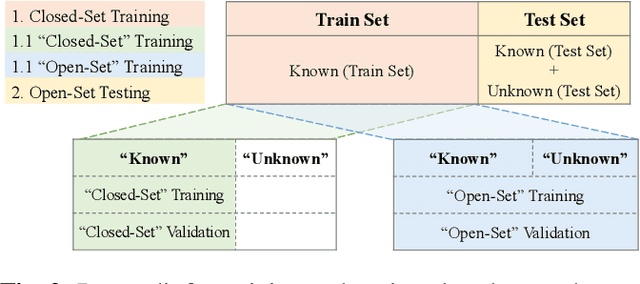
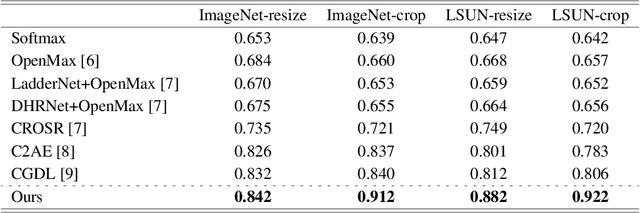
Neural networks for image classification tasks assume that any given image during inference belongs to one of the training classes. This closed-set assumption is challenged in real-world applications where models may encounter inputs of unknown classes. Open-set recognition aims to solve this problem by rejecting unknown classes while classifying known classes correctly. In this paper, we propose to utilize gradient-based representations obtained from a known classifier to train an unknown detector with instances of known classes only. Gradients correspond to the amount of model updates required to properly represent a given sample, which we exploit to understand the model's capability to characterize inputs with its learned features. Our approach can be utilized with any classifier trained in a supervised manner on known classes without the need to model the distribution of unknown samples explicitly. We show that our gradient-based approach outperforms state-of-the-art methods by up to 11.6% in open-set classification.
SVBRDF Recovery From a Single Image With Highlights using a Pretrained Generative Adversarial Network
Oct 29, 2021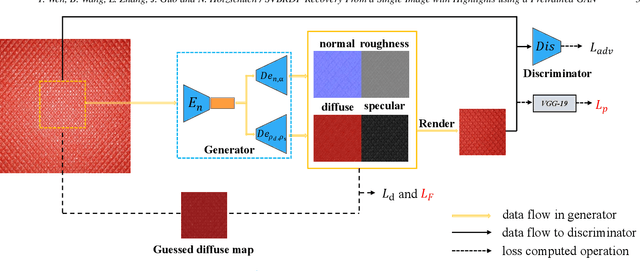
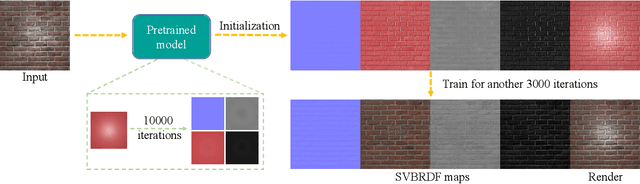
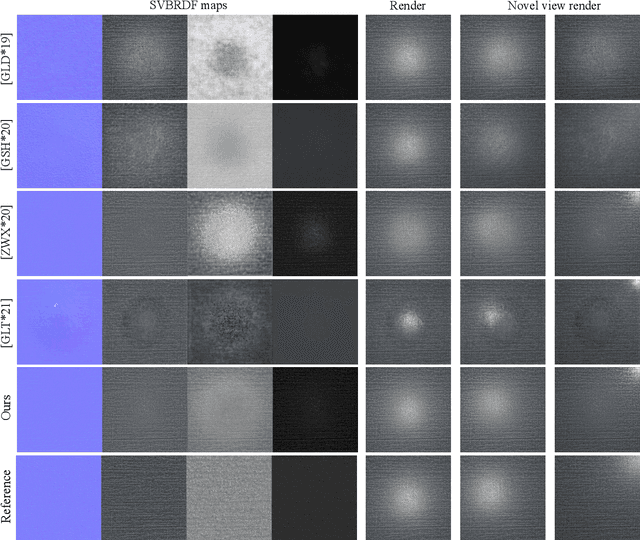

Spatially-varying bi-directional reflectance distribution functions (SVBRDFs) are crucial for designers to incorporate new materials in virtual scenes, making them look more realistic. Reconstruction of SVBRDFs is a long-standing problem. Existing methods either rely on extensive acquisition system or require huge datasets which are nontrivial to acquire. We aim to recover SVBRDFs from a single image, without any datasets. A single image contains incomplete information about the SVBRDF, making the reconstruction task highly ill-posed. It is also difficult to separate between the changes in color that are caused by the material and those caused by the illumination, without the prior knowledge learned from the dataset. In this paper, we use an unsupervised generative adversarial neural network (GAN) to recover SVBRDFs maps with a single image as input. To better separate the effects due to illumination from the effects due to the material, we add the hypothesis that the material is stationary and introduce a new loss function based on Fourier coefficients to enforce this stationarity. For efficiency, we train the network in two stages: reusing a trained model to initialize the SVBRDFs and fine-tune it based on the input image. Our method generates high-quality SVBRDFs maps from a single input photograph, and provides more vivid rendering results compared to previous work. The two-stage training boosts runtime performance, making it 8 times faster than previous work.
RAZE: Region Guided Self-Supervised Gaze Representation Learning
Aug 05, 2022
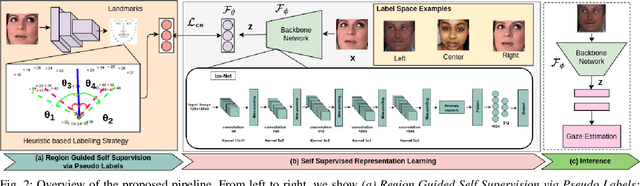


Automatic eye gaze estimation is an important problem in vision based assistive technology with use cases in different emerging topics such as augmented reality, virtual reality and human-computer interaction. Over the past few years, there has been an increasing interest in unsupervised and self-supervised learning paradigms as it overcomes the requirement of large scale annotated data. In this paper, we propose RAZE, a Region guided self-supervised gAZE representation learning framework which leverage from non-annotated facial image data. RAZE learns gaze representation via auxiliary supervision i.e. pseudo-gaze zone classification where the objective is to classify visual field into different gaze zones (i.e. left, right and center) by leveraging the relative position of pupil-centers. Thus, we automatically annotate pseudo gaze zone labels of 154K web-crawled images and learn feature representations via `Ize-Net' framework. `Ize-Net' is a capsule layer based CNN architecture which can efficiently capture rich eye representation. The discriminative behaviour of the feature representation is evaluated on four benchmark datasets: CAVE, TabletGaze, MPII and RT-GENE. Additionally, we evaluate the generalizability of the proposed network on two other downstream task (i.e. driver gaze estimation and visual attention estimation) which demonstrate the effectiveness of the learnt eye gaze representation.