 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Faster hyperspectral image classification based on selective kernel mechanism using deep convolutional networks
Feb 14, 2022
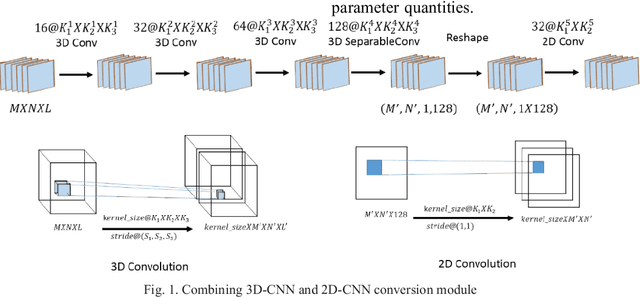
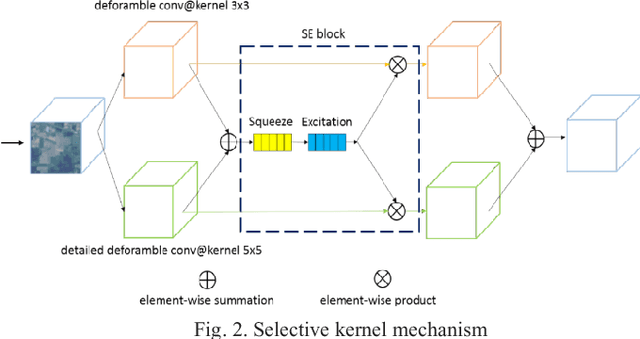
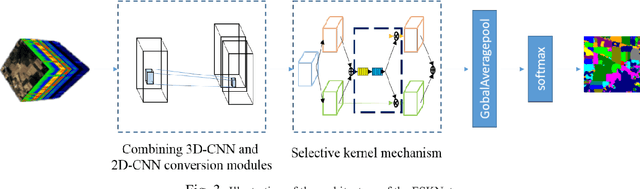

Hyperspectral imagery is rich in spatial and spectral information. Using 3D-CNN can simultaneously acquire features of spatial and spectral dimensions to facilitate classification of features, but hyperspectral image information spectral dimensional information redundancy. The use of continuous 3D-CNN will result in a high amount of parameters, and the computational power requirements of the device are high, and the training takes too long. This letter designed the Faster selective kernel mechanism network (FSKNet), FSKNet can balance this problem. It designs 3D-CNN and 2D-CNN conversion modules, using 3D-CNN to complete feature extraction while reducing the dimensionality of spatial and spectrum. However, such a model is not lightweight enough. In the converted 2D-CNN, a selective kernel mechanism is proposed, which allows each neuron to adjust the receptive field size based on the two-way input information scale. Under the Selective kernel mechanism, it mainly includes two components, se module and variable convolution. Se acquires channel dimensional attention and variable convolution to obtain spatial dimension deformation information of ground objects. The model is more accurate, faster, and less computationally intensive. FSKNet achieves high accuracy on the IN, UP, Salinas, and Botswana data sets with very small parameters.
Learning Object Placement via Dual-path Graph Completion
Jul 23, 2022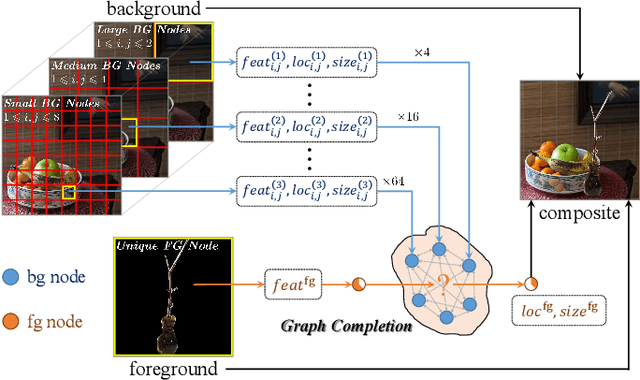
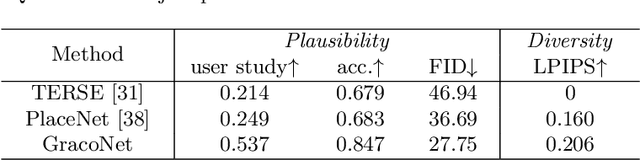
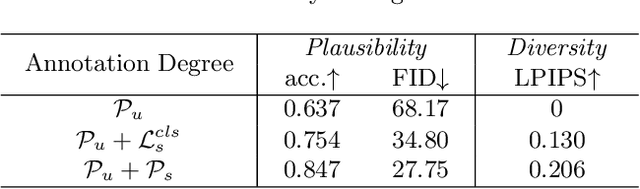

Object placement aims to place a foreground object over a background image with a suitable location and size. In this work, we treat object placement as a graph completion problem and propose a novel graph completion module (GCM). The background scene is represented by a graph with multiple nodes at different spatial locations with various receptive fields. The foreground object is encoded as a special node that should be inserted at a reasonable place in this graph. We also design a dual-path framework upon the structure of GCM to fully exploit annotated composite images. With extensive experiments on OPA dataset, our method proves to significantly outperform existing methods in generating plausible object placement without loss of diversity.
Speech Enhancement and Dereverberation with Diffusion-based Generative Models
Aug 11, 2022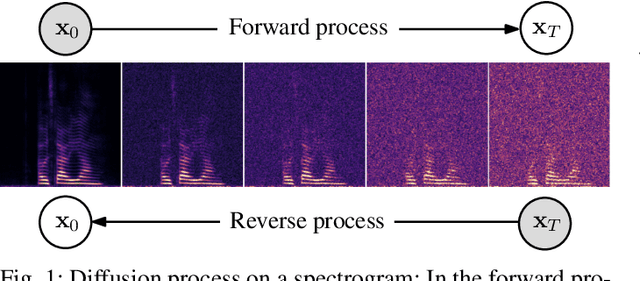
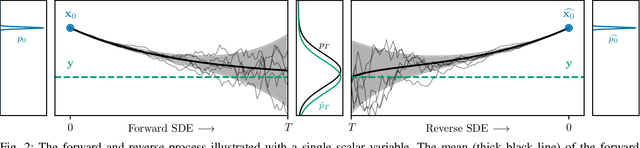
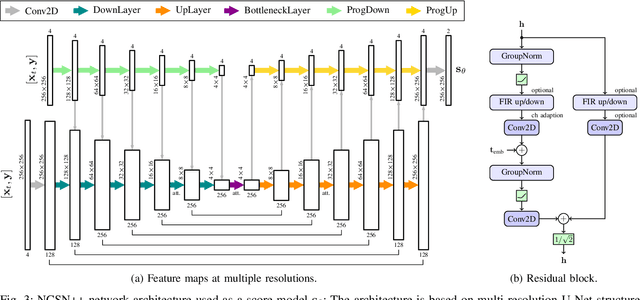
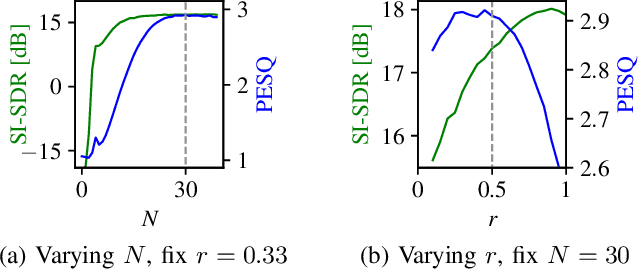
Recently, diffusion-based generative models have been introduced to the task of speech enhancement. The corruption of clean speech is modeled as a fixed forward process in which increasing amounts of noise are gradually added. By learning to reverse this process in an iterative fashion conditioned on the noisy input, clean speech is generated. We build upon our previous work and derive the training task within the formalism of stochastic differential equations. We present a detailed theoretical review of the underlying score matching objective and explore different sampler configurations for solving the reverse process at test time. By using a sophisticated network architecture from natural image generation literature, we significantly improve performance compared to our previous publication. We also show that we can compete with recent discriminative models and achieve better generalization when evaluating on a different corpus than used for training. We complement the evaluation results with a subjective listening test, in which our proposed method is rated best. Furthermore, we show that the proposed method achieves remarkable state-of-the-art performance in single-channel speech dereverberation. Our code and audio examples are available online, see https://uhh.de/inf-sp-sgmse
FlowNAS: Neural Architecture Search for Optical Flow Estimation
Jul 04, 2022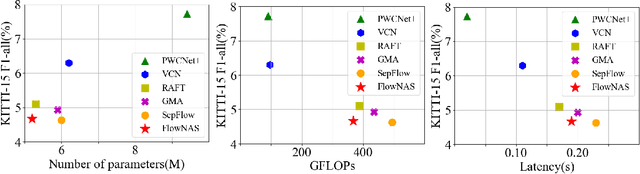
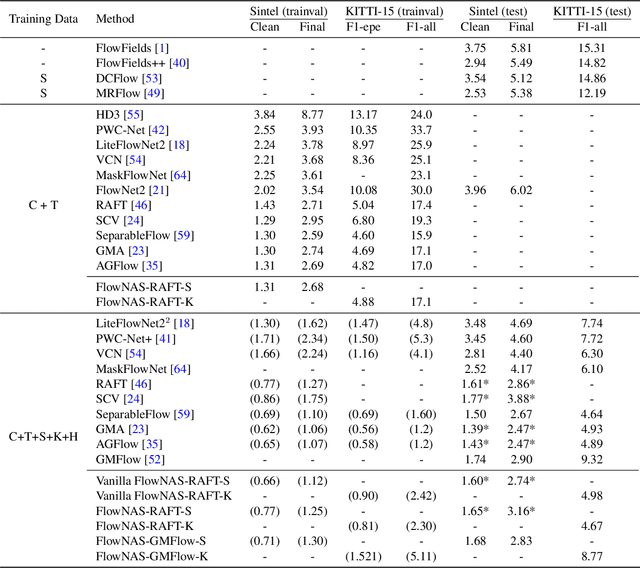
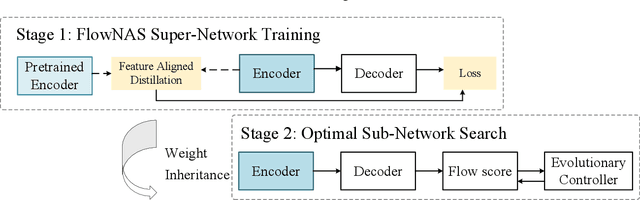
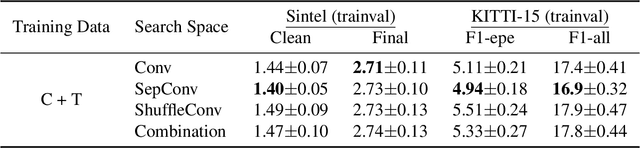
Existing optical flow estimators usually employ the network architectures typically designed for image classification as the encoder to extract per-pixel features. However, due to the natural difference between the tasks, the architectures designed for image classification may be sub-optimal for flow estimation. To address this issue, we propose a neural architecture search method named FlowNAS to automatically find the better encoder architecture for flow estimation task. We first design a suitable search space including various convolutional operators and construct a weight-sharing super-network for efficiently evaluating the candidate architectures. Then, for better training the super-network, we propose Feature Alignment Distillation, which utilizes a well-trained flow estimator to guide the training of super-network. Finally, a resource-constrained evolutionary algorithm is exploited to find an optimal architecture (i.e., sub-network). Experimental results show that the discovered architecture with the weights inherited from the super-network achieves 4.67\% F1-all error on KITTI, an 8.4\% reduction of RAFT baseline, surpassing state-of-the-art handcrafted models GMA and AGFlow, while reducing the model complexity and latency. The source code and trained models will be released in https://github.com/VDIGPKU/FlowNAS.
Histogram Equalization Of The Image
Aug 29, 2021


The relevance and impact of probability distributions on image processing are the subject of this study.It may be characterized as a probability distribution function of brightness for a certain area, which might be a whole picture. To generate a histogram, the probability density function of the brightness is frequently calculated by counting how many times each brightness occurs in the picture region. The brightness average is defined as the sample mean of the brightness of pixels in a certain region. The frequency is shown by the histogram. The histogram has a wide range of uses in image processing. It could, for starters, be used for picture analysis. Second, the functions of an image's brightness and contrast, as well as the final two uses of equalizing and thresholding. Normalizing a histogram is one technique to convert the intensities of discrete distributions to the probability of discrete distribution functions. The technique to equalize the histogram is to control the image's contrast by altering their intensity distribution functions. The major goal of this procedure is to give the cumulative probability function a linear trend (CDF).A method of segmentation is to divide a section of the picture into constituent areas or objects.
Conditional Vector Graphics Generation for Music Cover Images
May 15, 2022
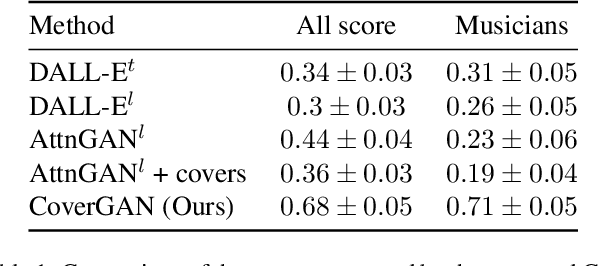

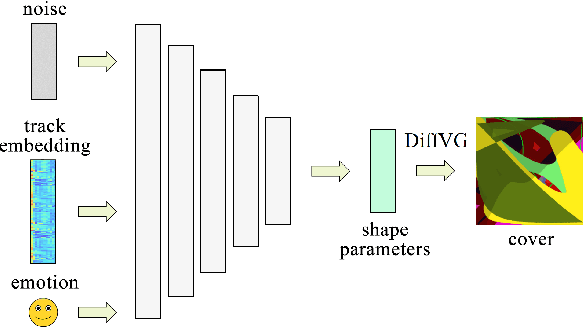
Generative Adversarial Networks (GAN) have motivated a rapid growth of the domain of computer image synthesis. As almost all the existing image synthesis algorithms consider an image as a pixel matrix, the high-resolution image synthesis is complicated.A good alternative can be vector images. However, they belong to the highly sophisticated parametric space, which is a restriction for solving the task of synthesizing vector graphics by GANs. In this paper, we consider a specific application domain that softens this restriction dramatically allowing the usage of vector image synthesis. Music cover images should meet the requirements of Internet streaming services and printing standards, which imply high resolution of graphic materials without any additional requirements on the content of such images. Existing music cover image generation services do not analyze tracks themselves; however, some services mostly consider only genre tags. To generate music covers as vector images that reflect the music and consist of simple geometric objects, we suggest a GAN-based algorithm called CoverGAN. The assessment of resulting images is based on their correspondence to the music compared with AttnGAN and DALL-E text-to-image generation according to title or lyrics. Moreover, the significance of the patterns found by CoverGAN has been evaluated in terms of the correspondence of the generated cover images to the musical tracks. Listeners evaluate the music covers generated by the proposed algorithm as quite satisfactory and corresponding to the tracks. Music cover images generation code and demo are available at https://github.com/IzhanVarsky/CoverGAN.
Learning Primitive-aware Discriminative Representations for FSL
Aug 20, 2022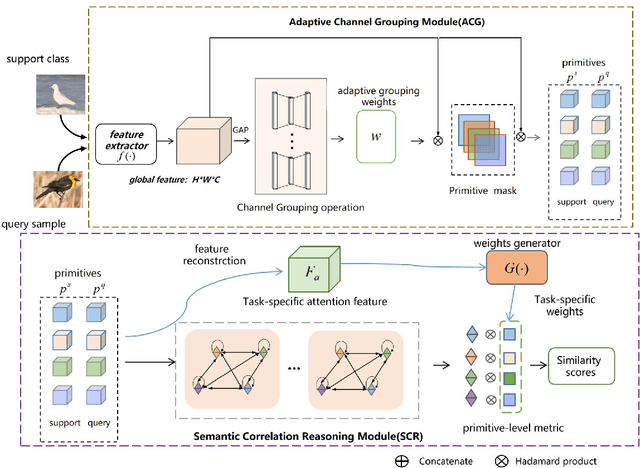
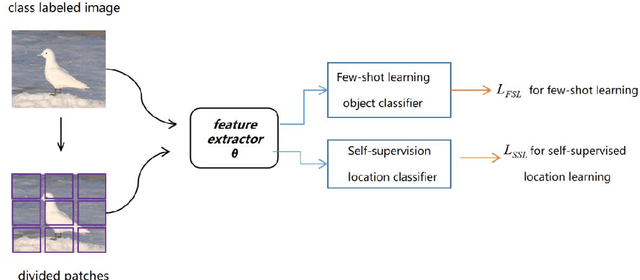
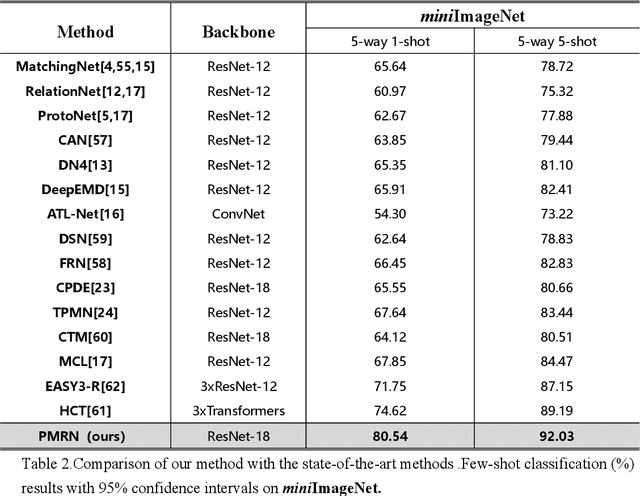
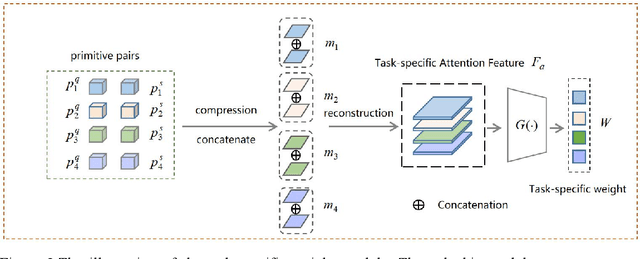
Few-shot learning (FSL) aims to learn a classifier that can be easily adapted to recognize novel classes,given only a few labeled examples per class.Limited data keep this task challenging for deep learning.Recent metric-based methods has achieved promising performance based on image-level features.However,these global features ignore abundant local and structural information that is transferable and consistent between seen and unseen classes.Some study in cognitive science argue that humans can recognize novel classes with the learned primitives.We expect to mine both transferable and discriminative representation from base classes and adopt them to recognize novel classes.Building on the episodic training mechanism,We propose a Primitive Mining and Reasoning Network(PMRN) to learn primitive-aware representation in an end-to-end manner for metric-based FSL model.We first add self-supervision auxiliary task,forcing feature extractor to learn tvisual pattern corresponding to primitives.To further mine and produce transferable primitive-aware representations,we design an Adaptive Channel Grouping(ACG)module to synthesize a set of visual primitives from object embedding by enhancing informative channel maps while suppressing useless ones. Based on the learned primitive feature,a Semantic Correlation Reasoning (SCR) module is proposed to capture internal relations among them.Finally,we learn the task-specific importance of primitives and conduct primitive-level metric based on the task-specific attention feature.Extensive experiments show that our method achieves state-of-the-art results on six standard benchmarks.
SSH: A Self-Supervised Framework for Image Harmonization
Aug 15, 2021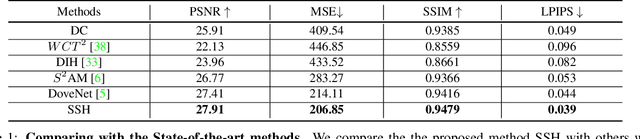
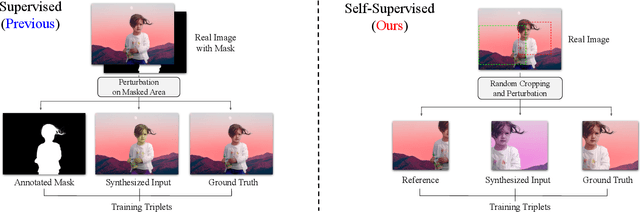
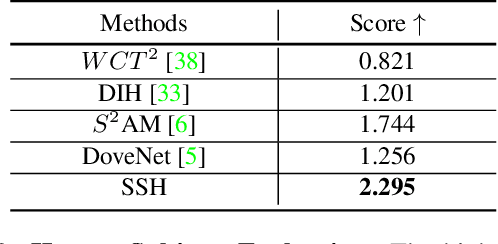
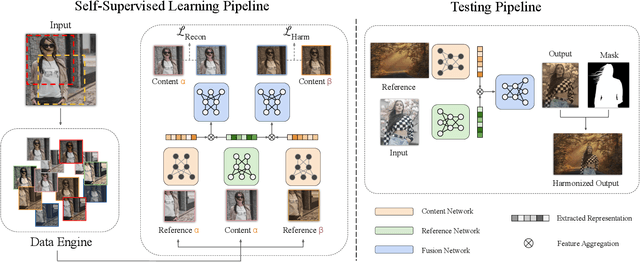
Image harmonization aims to improve the quality of image compositing by matching the "appearance" (\eg, color tone, brightness and contrast) between foreground and background images. However, collecting large-scale annotated datasets for this task requires complex professional retouching. Instead, we propose a novel Self-Supervised Harmonization framework (SSH) that can be trained using just "free" natural images without being edited. We reformulate the image harmonization problem from a representation fusion perspective, which separately processes the foreground and background examples, to address the background occlusion issue. This framework design allows for a dual data augmentation method, where diverse [foreground, background, pseudo GT] triplets can be generated by cropping an image with perturbations using 3D color lookup tables (LUTs). In addition, we build a real-world harmonization dataset as carefully created by expert users, for evaluation and benchmarking purposes. Our results show that the proposed self-supervised method outperforms previous state-of-the-art methods in terms of reference metrics, visual quality, and subject user study. Code and dataset are available at \url{https://github.com/VITA-Group/SSHarmonization}.
AdaCat: Adaptive Categorical Discretization for Autoregressive Models
Aug 03, 2022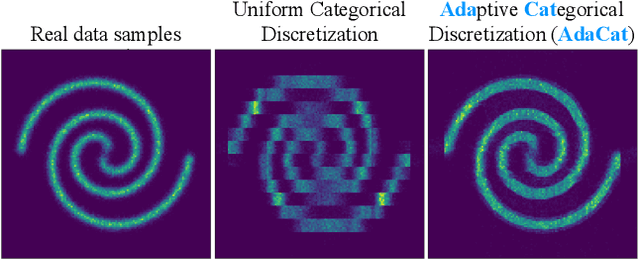
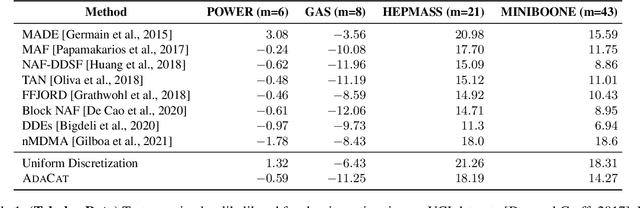
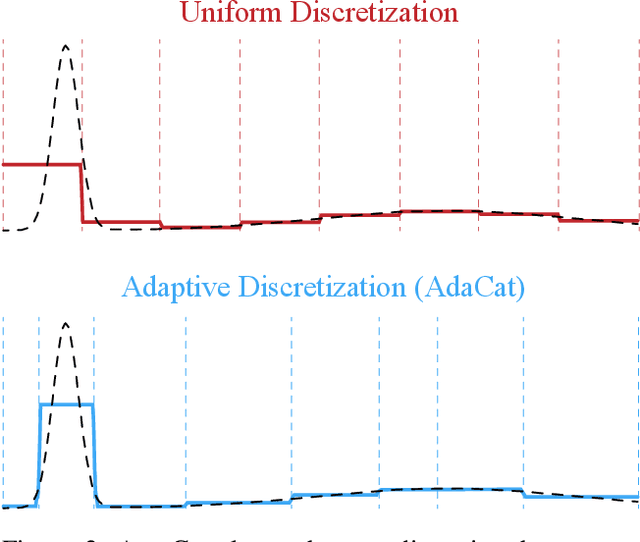
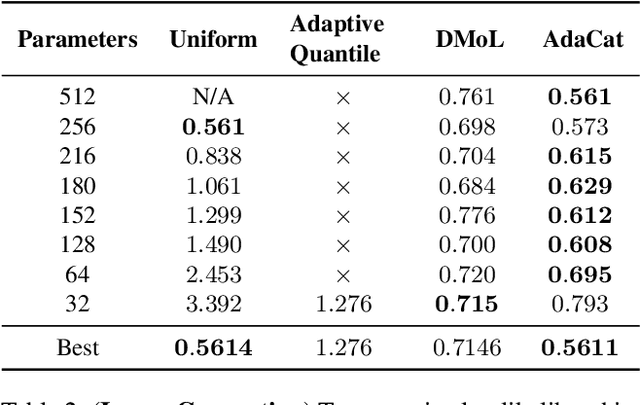
Autoregressive generative models can estimate complex continuous data distributions, like trajectory rollouts in an RL environment, image intensities, and audio. Most state-of-the-art models discretize continuous data into several bins and use categorical distributions over the bins to approximate the continuous data distribution. The advantage is that the categorical distribution can easily express multiple modes and are straightforward to optimize. However, such approximation cannot express sharp changes in density without using significantly more bins, making it parameter inefficient. We propose an efficient, expressive, multimodal parameterization called Adaptive Categorical Discretization (AdaCat). AdaCat discretizes each dimension of an autoregressive model adaptively, which allows the model to allocate density to fine intervals of interest, improving parameter efficiency. AdaCat generalizes both categoricals and quantile-based regression. AdaCat is a simple add-on to any discretization-based distribution estimator. In experiments, AdaCat improves density estimation for real-world tabular data, images, audio, and trajectories, and improves planning in model-based offline RL.
E2V-SDE: From Asynchronous Events to Fast and Continuous Video Reconstruction via Neural Stochastic Differential Equations
Jun 15, 2022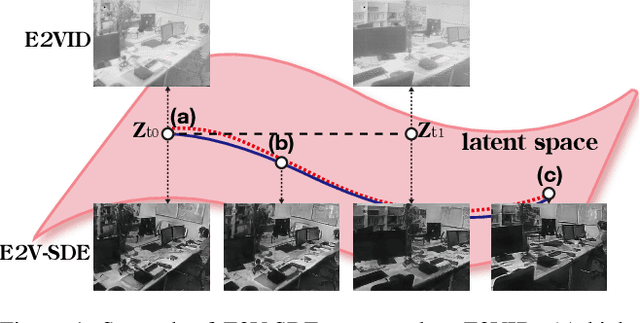
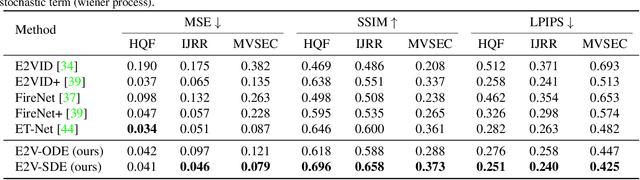
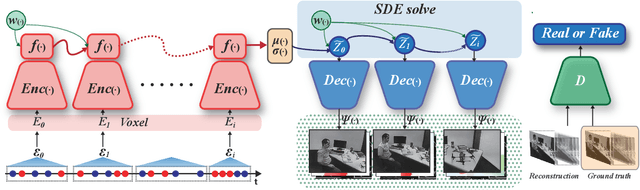
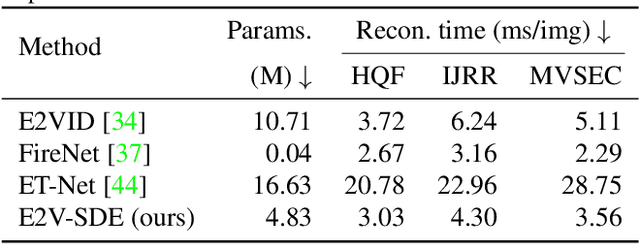
Event cameras respond to brightness changes in the scene asynchronously and independently for every pixel. Due to the properties, these cameras have distinct features: high dynamic range (HDR), high temporal resolution, and low power consumption. However, the results of event cameras should be processed into an alternative representation for computer vision tasks. Also, they are usually noisy and cause poor performance in areas with few events. In recent years, numerous researchers have attempted to reconstruct videos from events. However, they do not provide good quality videos due to a lack of temporal information from irregular and discontinuous data. To overcome these difficulties, we introduce an E2V-SDE whose dynamics are governed in a latent space by Stochastic differential equations (SDE). Therefore, E2V-SDE can rapidly reconstruct images at arbitrary time steps and make realistic predictions on unseen data. In addition, we successfully adopted a variety of image composition techniques for improving image clarity and temporal consistency. By conducting extensive experiments on simulated and real-scene datasets, we verify that our model outperforms state-of-the-art approaches under various video reconstruction settings. In terms of image quality, the LPIPS score improves by up to 12% and the reconstruction speed is 87% higher than that of ET-Net.
* 2022 CVPR oral