 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Data Stealing Attack on Medical Images: Is it Safe to Export Networks from Data Lakes?
Jun 07, 2022
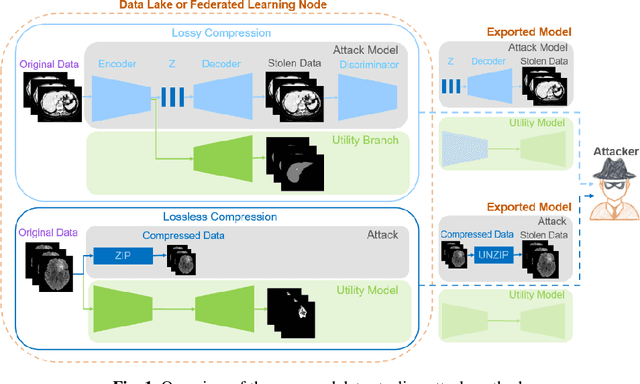
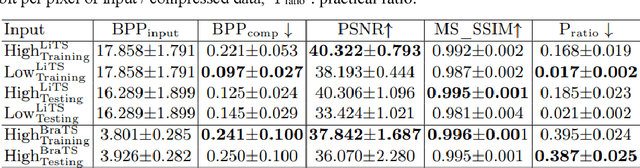
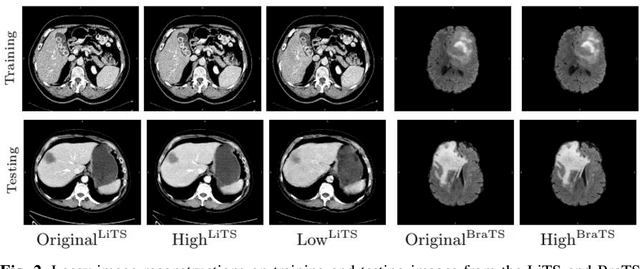

In privacy-preserving machine learning, it is common that the owner of the learned model does not have any physical access to the data. Instead, only a secured remote access to a data lake is granted to the model owner without any ability to retrieve data from the data lake. Yet, the model owner may want to export the trained model periodically from the remote repository and a question arises whether this may cause is a risk of data leakage. In this paper, we introduce the concept of data stealing attack during the export of neural networks. It consists in hiding some information in the exported network that allows the reconstruction outside the data lake of images initially stored in that data lake. More precisely, we show that it is possible to train a network that can perform lossy image compression and at the same time solve some utility tasks such as image segmentation. The attack then proceeds by exporting the compression decoder network together with some image codes that leads to the image reconstruction outside the data lake. We explore the feasibility of such attacks on databases of CT and MR images, showing that it is possible to obtain perceptually meaningful reconstructions of the target dataset, and that the stolen dataset can be used in turns to solve a broad range of tasks. Comprehensive experiments and analyses show that data stealing attacks should be considered as a threat for sensitive imaging data sources.
Tree species classification from hyperspectral data using graph-regularized neural networks
Aug 18, 2022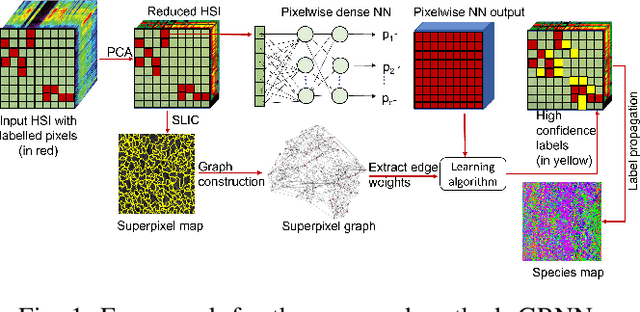
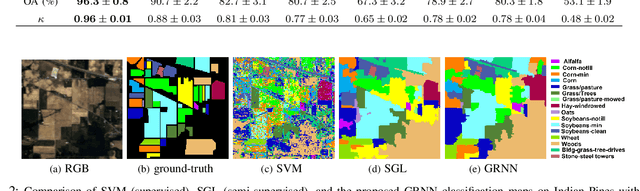
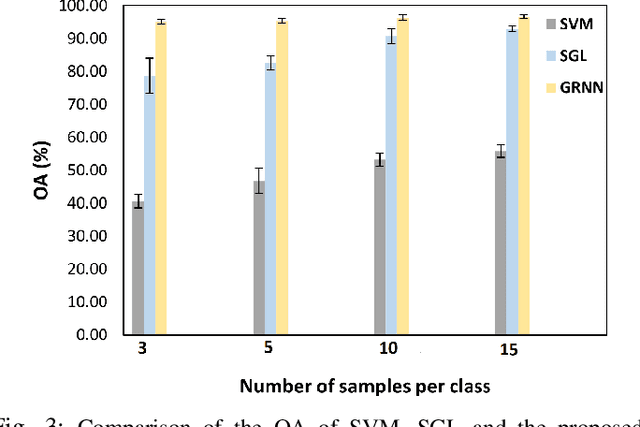
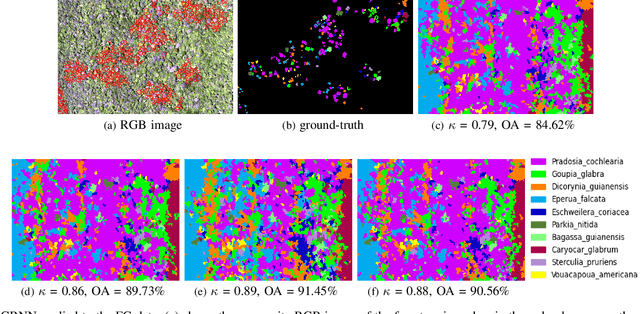
Manual labeling of tree species remains a challenging task, especially in tropical regions, owing to inaccessibility and labor-intensive ground-based surveys. Hyperspectral images (HSIs), through their narrow and contiguous bands, can assist in distinguishing tree species based on their spectral properties. Therefore, automated classification algorithms on HSI images can help augment the limited labeled information and generate a real-time classification map for various tree species. Achieving high classification accuracy with a limited amount of labeled information in an image is one of the key challenges that researchers have started addressing in recent years. We propose a novel graph-regularized neural network (GRNN) algorithm that encompasses the superpixel-based segmentation for graph construction, a pixel-wise neural network classifier, and the label propagation technique to generate an accurate classification map. GRNN outperforms several state-of-the-art techniques not only for the standard Indian Pines HSI but also achieves a high classification accuracy (approx. 92%) on a new HSI data set collected over the forests of French Guiana (FG) even when less than 1% of the pixels are labeled. We show that GRNN is not only competitive with the state-of-the-art semi-supervised methods, but also exhibits lower variance in accuracy for different number of training samples and over different independent random sampling of the labeled pixels for training.
Adaptive Joint Optimization for 3D Reconstruction with Differentiable Rendering
Aug 15, 2022

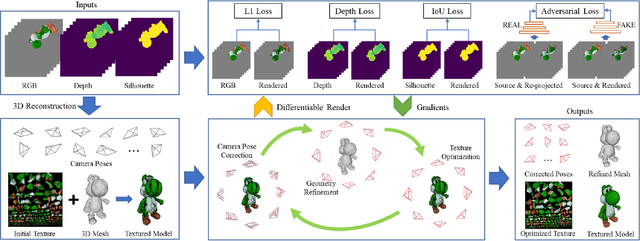
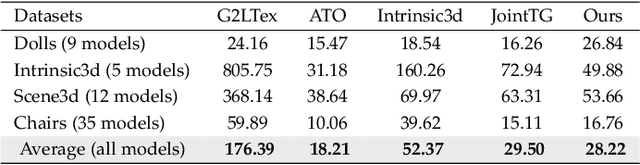
Due to inevitable noises introduced during scanning and quantization, 3D reconstruction via RGB-D sensors suffers from errors both in geometry and texture, leading to artifacts such as camera drifting, mesh distortion, texture ghosting, and blurriness. Given an imperfect reconstructed 3D model, most previous methods have focused on the refinement of either geometry, texture, or camera pose. Or different optimization schemes and objectives for optimizing each component have been used in previous joint optimization methods, forming a complicated system. In this paper, we propose a novel optimization approach based on differentiable rendering, which integrates the optimization of camera pose, geometry, and texture into a unified framework by enforcing consistency between the rendered results and the corresponding RGB-D inputs. Based on the unified framework, we introduce a joint optimization approach to fully exploit the inter-relationships between geometry, texture, and camera pose, and describe an adaptive interleaving strategy to improve optimization stability and efficiency. Using differentiable rendering, an image-level adversarial loss is applied to further improve the 3D model, making it more photorealistic. Experiments on synthetic and real data using quantitative and qualitative evaluation demonstrated the superiority of our approach in recovering both fine-scale geometry and high-fidelity texture.
FaceOff: A Video-to-Video Face Swapping System
Aug 21, 2022

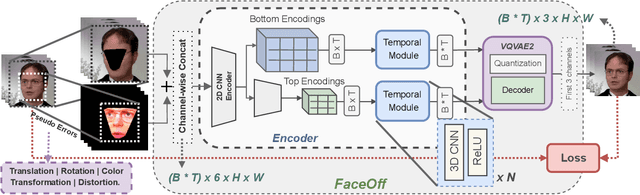
Doubles play an indispensable role in the movie industry. They take the place of the actors in dangerous stunt scenes or in scenes where the same actor plays multiple characters. The double's face is later replaced with the actor's face and expressions manually using expensive CGI technology, costing millions of dollars and taking months to complete. An automated, inexpensive, and fast way can be to use face-swapping techniques that aim to swap an identity from a source face video (or an image) to a target face video. However, such methods can not preserve the source expressions of the actor important for the scene's context. % essential for the scene. % that are essential in cinemas. To tackle this challenge, we introduce video-to-video (V2V) face-swapping, a novel task of face-swapping that can preserve (1) the identity and expressions of the source (actor) face video and (2) the background and pose of the target (double) video. We propose FaceOff, a V2V face-swapping system that operates by learning a robust blending operation to merge two face videos following the constraints above. It first reduces the videos to a quantized latent space and then blends them in the reduced space. FaceOff is trained in a self-supervised manner and robustly tackles the non-trivial challenges of V2V face-swapping. As shown in the experimental section, FaceOff significantly outperforms alternate approaches qualitatively and quantitatively.
Mining Discriminative Food Regions for Accurate Food Recognition
Jul 08, 2022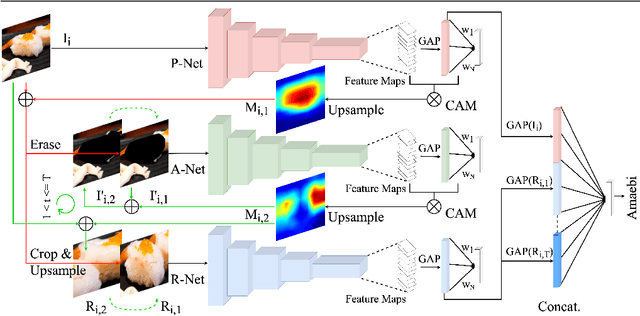
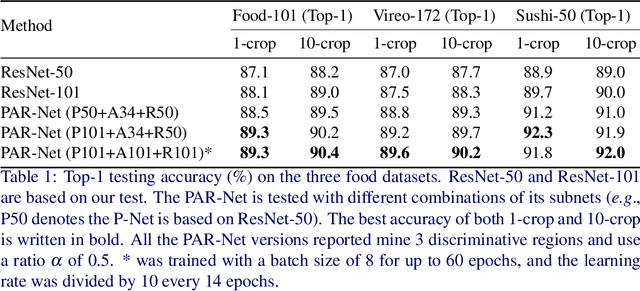

Automatic food recognition is the very first step towards passive dietary monitoring. In this paper, we address the problem of food recognition by mining discriminative food regions. Taking inspiration from Adversarial Erasing, a strategy that progressively discovers discriminative object regions for weakly supervised semantic segmentation, we propose a novel network architecture in which a primary network maintains the base accuracy of classifying an input image, an auxiliary network adversarially mines discriminative food regions, and a region network classifies the resulting mined regions. The global (the original input image) and the local (the mined regions) representations are then integrated for the final prediction. The proposed architecture denoted as PAR-Net is end-to-end trainable, and highlights discriminative regions in an online fashion. In addition, we introduce a new fine-grained food dataset named as Sushi-50, which consists of 50 different sushi categories. Extensive experiments have been conducted to evaluate the proposed approach. On three food datasets chosen (Food-101, Vireo-172, and Sushi-50), our approach performs consistently and achieves state-of-the-art results (top-1 testing accuracy of $90.4\%$, $90.2\%$, $92.0\%$, respectively) compared with other existing approaches. Dataset and code are available at https://github.com/Jianing-Qiu/PARNet
ROSE: A RObust and SEcure DNN Watermarking
Jun 22, 2022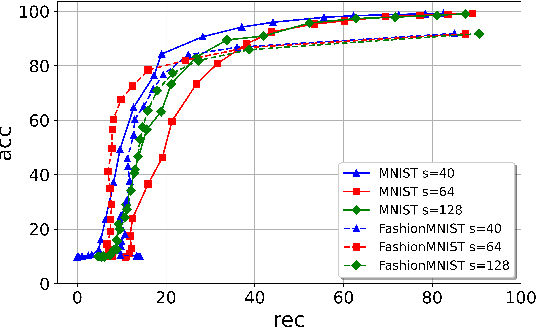
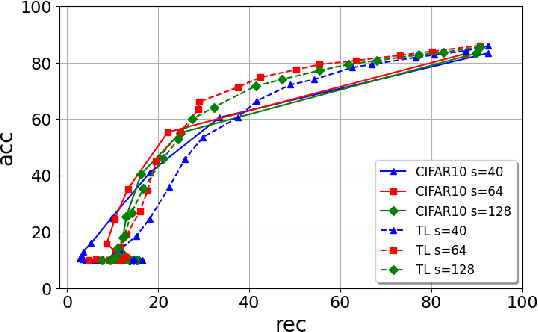
Protecting the Intellectual Property rights of DNN models is of primary importance prior to their deployment. So far, the proposed methods either necessitate changes to internal model parameters or the machine learning pipeline, or they fail to meet both the security and robustness requirements. This paper proposes a lightweight, robust, and secure black-box DNN watermarking protocol that takes advantage of cryptographic one-way functions as well as the injection of in-task key image-label pairs during the training process. These pairs are later used to prove DNN model ownership during testing. The main feature is that the value of the proof and its security are measurable. The extensive experiments watermarking image classification models for various datasets as well as exposing them to a variety of attacks, show that it provides protection while maintaining an adequate level of security and robustness.
LineCap: Line Charts for Data Visualization Captioning Models
Jul 15, 2022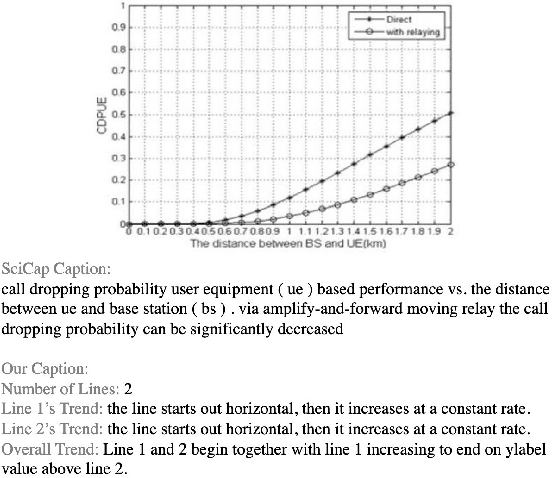
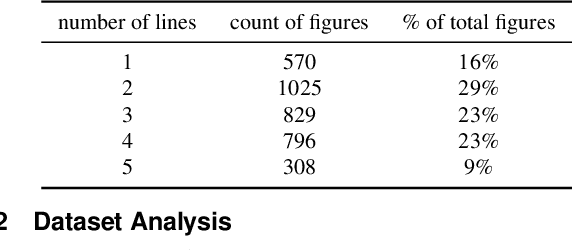
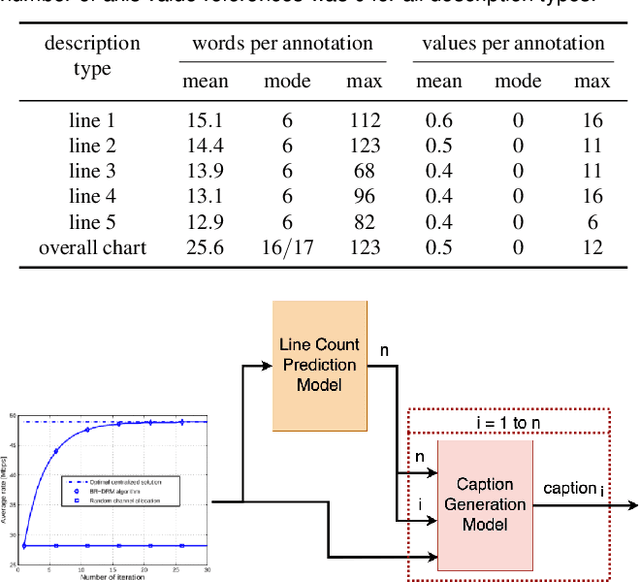
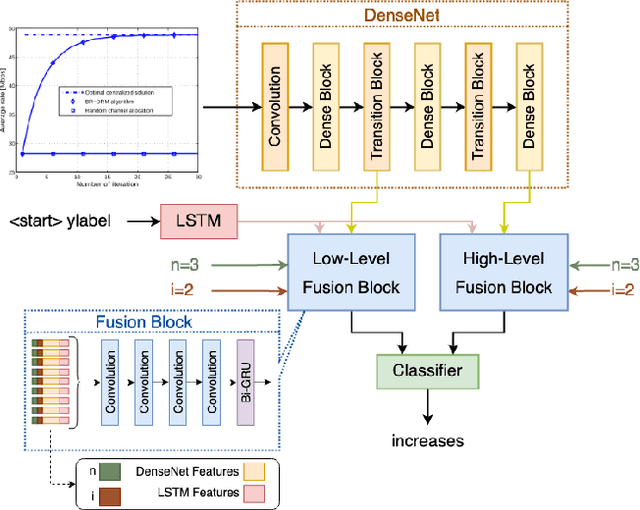
Data visualization captions help readers understand the purpose of a visualization and are crucial for individuals with visual impairments. The prevalence of poor figure captions and the successful application of deep learning approaches to image captioning motivate the use of similar techniques for automated figure captioning. However, research in this field has been stunted by the lack of suitable datasets. We introduce LineCap, a novel figure captioning dataset of 3,528 figures, and we provide insights from curating this dataset and using end-to-end deep learning models for automated figure captioning.
Vehicle Trajectory Prediction on Highways Using Bird Eye View Representations and Deep Learning
Jul 04, 2022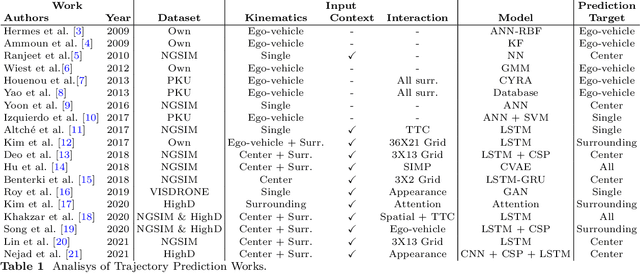
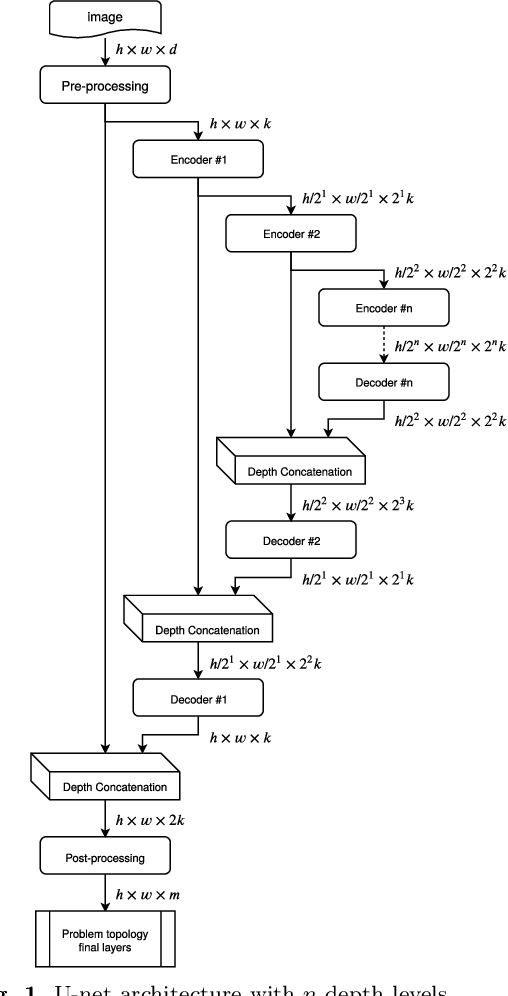


This work presents a novel method for predicting vehicle trajectories in highway scenarios using efficient bird's eye view representations and convolutional neural networks. Vehicle positions, motion histories, road configuration, and vehicle interactions are easily included in the prediction model using basic visual representations. The U-net model has been selected as the prediction kernel to generate future visual representations of the scene using an image-to-image regression approach. A method has been implemented to extract vehicle positions from the generated graphical representations to achieve subpixel resolution. The method has been trained and evaluated using the PREVENTION dataset, an on-board sensor dataset. Different network configurations and scene representations have been evaluated. This study found that U-net with 6 depth levels using a linear terminal layer and a Gaussian representation of the vehicles is the best performing configuration. The use of lane markings was found to produce no improvement in prediction performance. The average prediction error is 0.47 and 0.38 meters and the final prediction error is 0.76 and 0.53 meters for longitudinal and lateral coordinates, respectively, for a predicted trajectory length of 2.0 seconds. The prediction error is up to 50% lower compared to the baseline method.
Multi-scale alignment and Spatial ROI Module for COVID-19 Diagnosis
Jul 04, 2022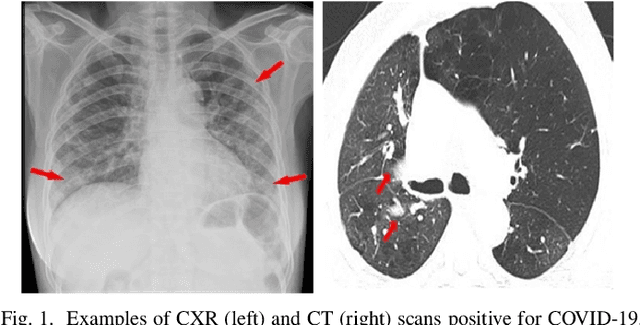
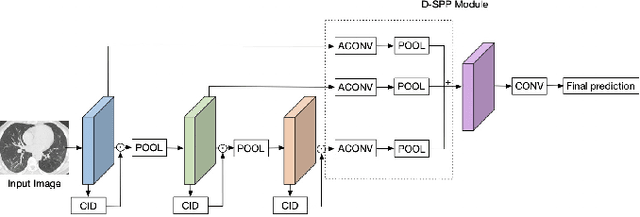
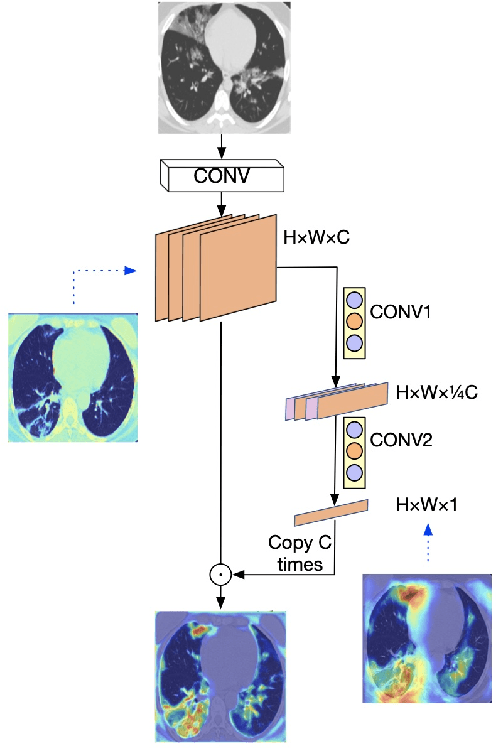
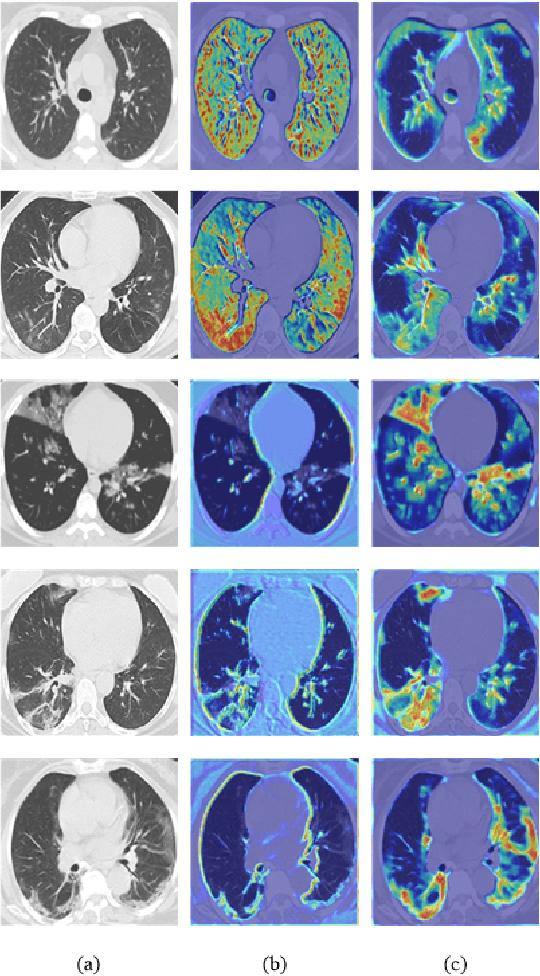
Coronavirus Disease 2019 (COVID-19) has spread globally and become a health crisis faced by humanity since first reported. Radiology imaging technologies such as computer tomography (CT) and chest X-ray imaging (CXR) are effective tools for diagnosing COVID-19. However, in CT and CXR images, the infected area occupies only a small part of the image. Some common deep learning methods that integrate large-scale receptive fields may cause the loss of image detail, resulting in the omission of the region of interest (ROI) in COVID-19 images and are therefore not suitable for further processing. To this end, we propose a deep spatial pyramid pooling (D-SPP) module to integrate contextual information over different resolutions, aiming to extract information under different scales of COVID-19 images effectively. Besides, we propose a COVID-19 infection detection (CID) module to draw attention to the lesion area and remove interference from irrelevant information. Extensive experiments on four CT and CXR datasets have shown that our method produces higher accuracy of detecting COVID-19 lesions in CT and CXR images. It can be used as a computer-aided diagnosis tool to help doctors effectively diagnose and screen for COVID-19.
Two-step adversarial debiasing with partial learning -- medical image case-studies
Nov 16, 2021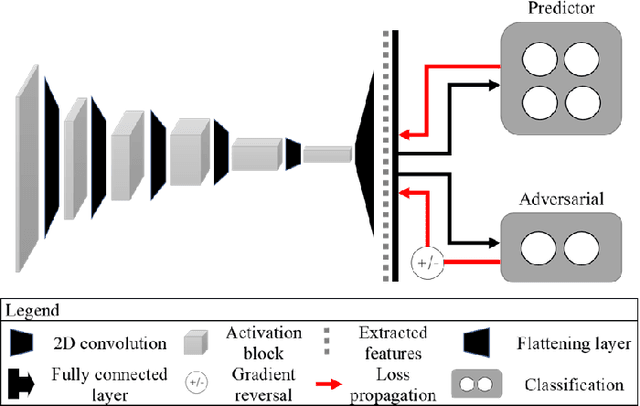
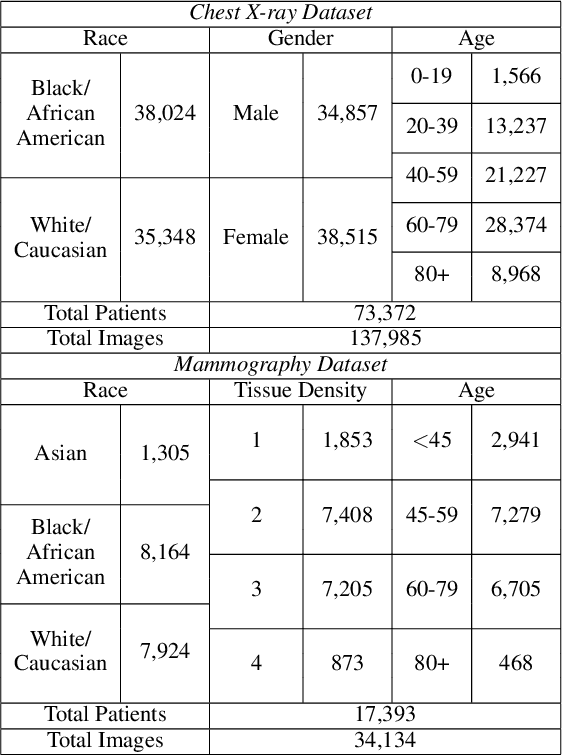
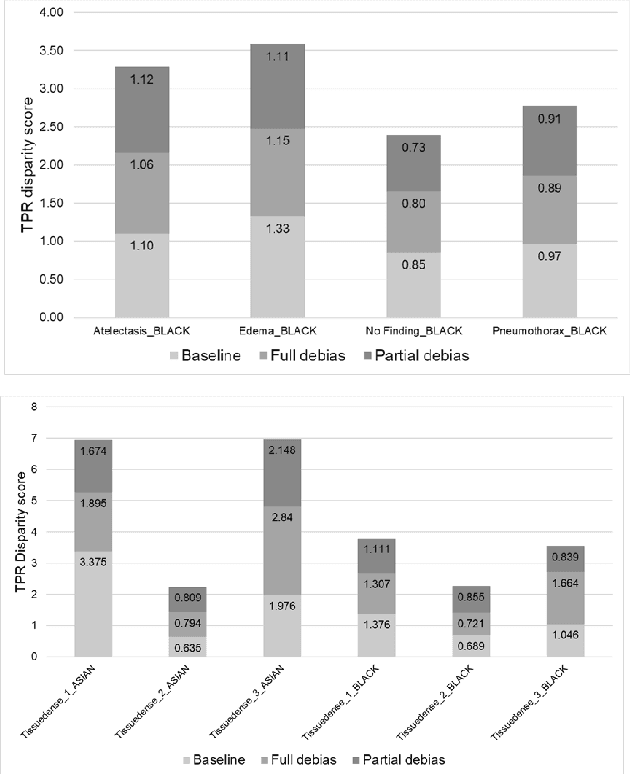
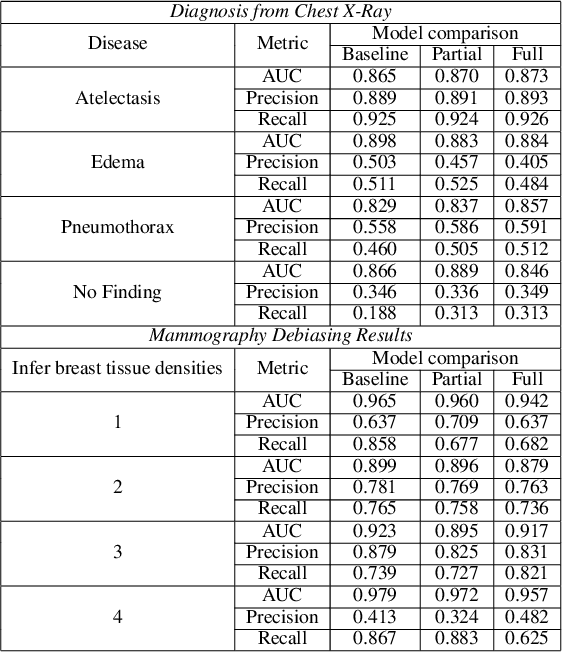
The use of artificial intelligence (AI) in healthcare has become a very active research area in the last few years. While significant progress has been made in image classification tasks, only a few AI methods are actually being deployed in hospitals. A major hurdle in actively using clinical AI models currently is the trustworthiness of these models. More often than not, these complex models are black boxes in which promising results are generated. However, when scrutinized, these models begin to reveal implicit biases during the decision making, such as detecting race and having bias towards ethnic groups and subpopulations. In our ongoing study, we develop a two-step adversarial debiasing approach with partial learning that can reduce the racial disparity while preserving the performance of the targeted task. The methodology has been evaluated on two independent medical image case-studies - chest X-ray and mammograms, and showed promises in bias reduction while preserving the targeted performance.