 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SDWNet: A Straight Dilated Network with Wavelet Transformation for Image Deblurring
Oct 12, 2021
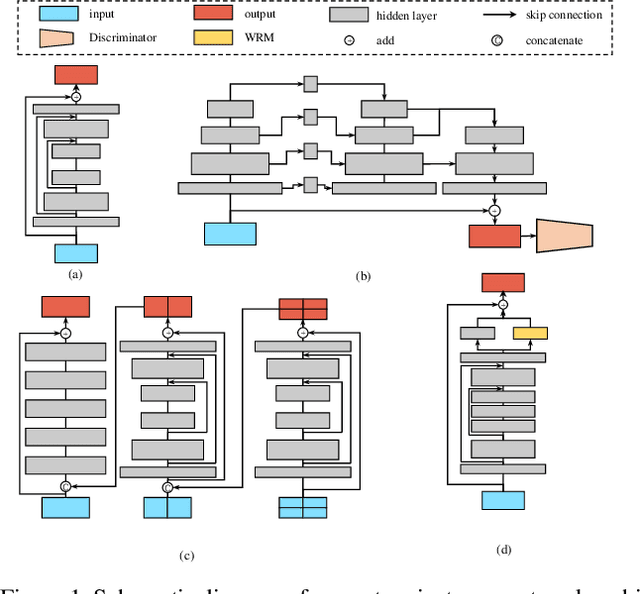
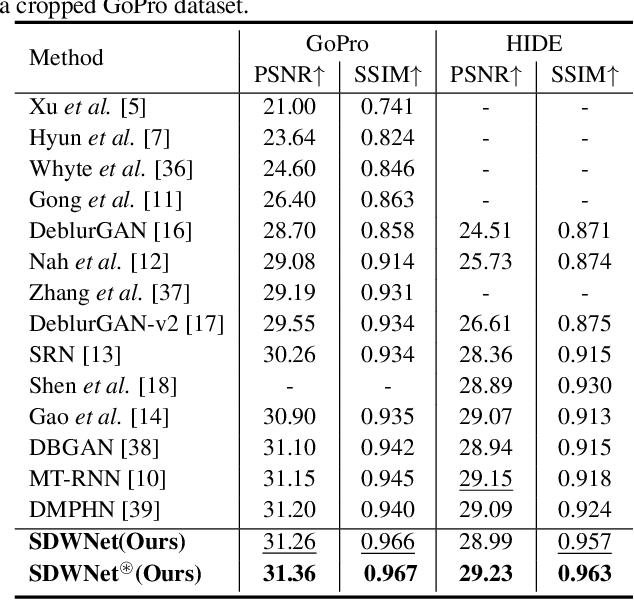
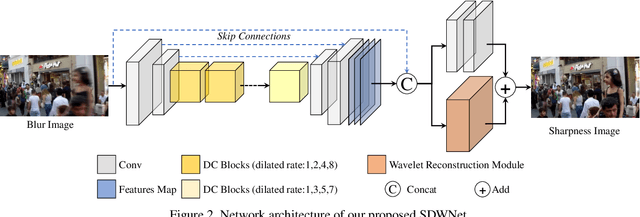
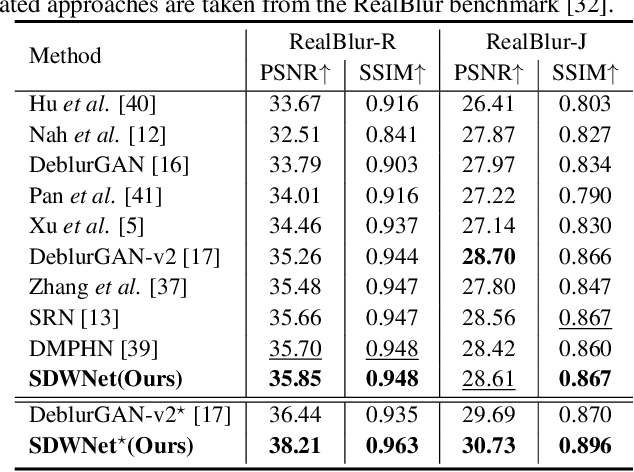
Image deblurring is a classical computer vision problem that aims to recover a sharp image from a blurred image. To solve this problem, existing methods apply the Encode-Decode architecture to design the complex networks to make a good performance. However, most of these methods use repeated up-sampling and down-sampling structures to expand the receptive field, which results in texture information loss during the sampling process and some of them design the multiple stages that lead to difficulties with convergence. Therefore, our model uses dilated convolution to enable the obtainment of the large receptive field with high spatial resolution. Through making full use of the different receptive fields, our method can achieve better performance. On this basis, we reduce the number of up-sampling and down-sampling and design a simple network structure. Besides, we propose a novel module using the wavelet transform, which effectively helps the network to recover clear high-frequency texture details. Qualitative and quantitative evaluations of real and synthetic datasets show that our deblurring method is comparable to existing algorithms in terms of performance with much lower training requirements. The source code and pre-trained models are available at https://github.com/FlyEgle/SDWNet.
Wavelet Prior Attention Learning in Axial Inpainting Network
Jun 07, 2022

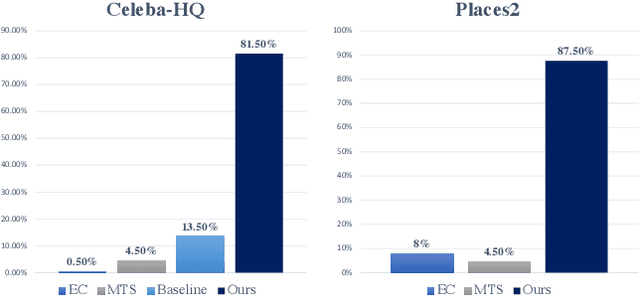
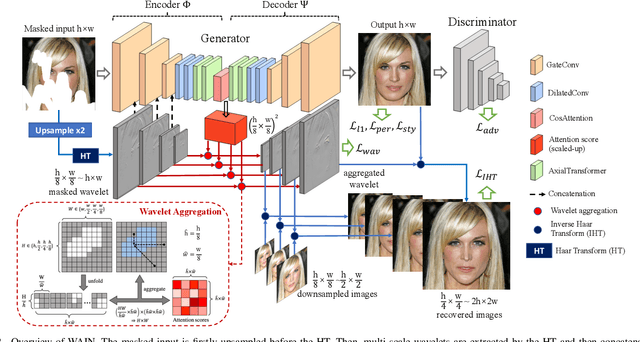
Image inpainting is the task of filling masked or unknown regions of an image with visually realistic contents, which has been remarkably improved by Deep Neural Networks (DNNs) recently. Essentially, as an inverse problem, the inpainting has the underlying challenges of reconstructing semantically coherent results without texture artifacts. Many previous efforts have been made via exploiting attention mechanisms and prior knowledge, such as edges and semantic segmentation. However, these works are still limited in practice by an avalanche of learnable prior parameters and prohibitive computational burden. To this end, we propose a novel model -- Wavelet prior attention learning in Axial Inpainting Network (WAIN), whose generator contains the encoder, decoder, as well as two key components of Wavelet image Prior Attention (WPA) and stacked multi-layer Axial-Transformers (ATs). Particularly, the WPA guides the high-level feature aggregation in the multi-scale frequency domain, alleviating the textual artifacts. Stacked ATs employ unmasked clues to help model reasonable features along with low-level features of horizontal and vertical axes, improving the semantic coherence. Extensive quantitative and qualitative experiments on Celeba-HQ and Places2 datasets are conducted to validate that our WAIN can achieve state-of-the-art performance over the competitors. The codes and models will be released.
Empirical Advocacy of Bio-inspired Models for Robust Image Recognition
May 18, 2022
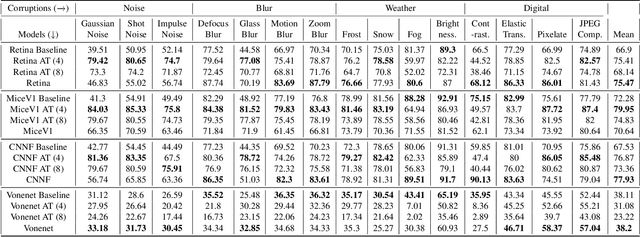
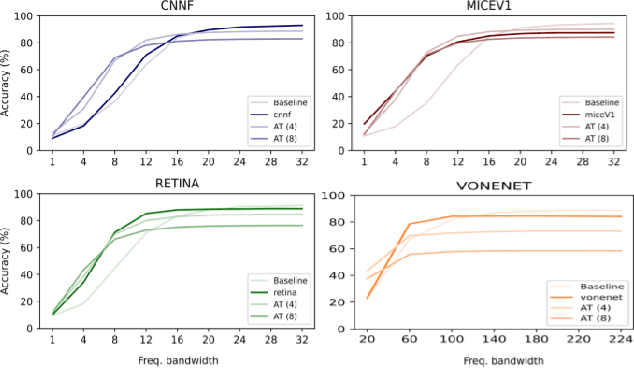
Deep convolutional neural networks (DCNNs) have revolutionized computer vision and are often advocated as good models of the human visual system. However, there are currently many shortcomings of DCNNs, which preclude them as a model of human vision. There are continuous attempts to use features of the human visual system to improve the robustness of neural networks to data perturbations. We provide a detailed analysis of such bio-inspired models and their properties. To this end, we benchmark the robustness of several bio-inspired models against their most comparable baseline DCNN models. We find that bio-inspired models tend to be adversarially robust without requiring any special data augmentation. Additionally, we find that bio-inspired models beat adversarially trained models in the presence of more real-world common corruptions. Interestingly, we also find that bio-inspired models tend to use both low and mid-frequency information, in contrast to other DCNN models. We find that this mix of frequency information makes them robust to both adversarial perturbations and common corruptions.
Guiding the retraining of convolutional neural networks against adversarial inputs
Jul 12, 2022
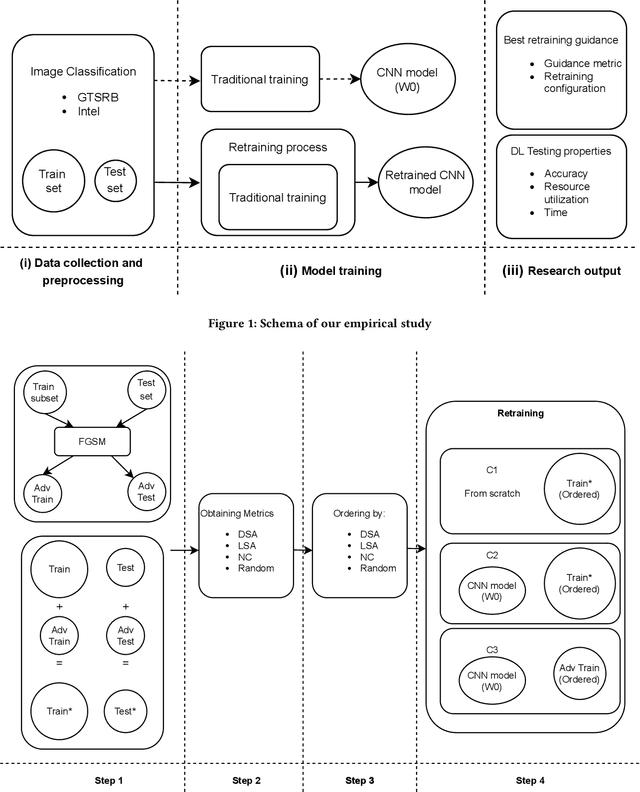

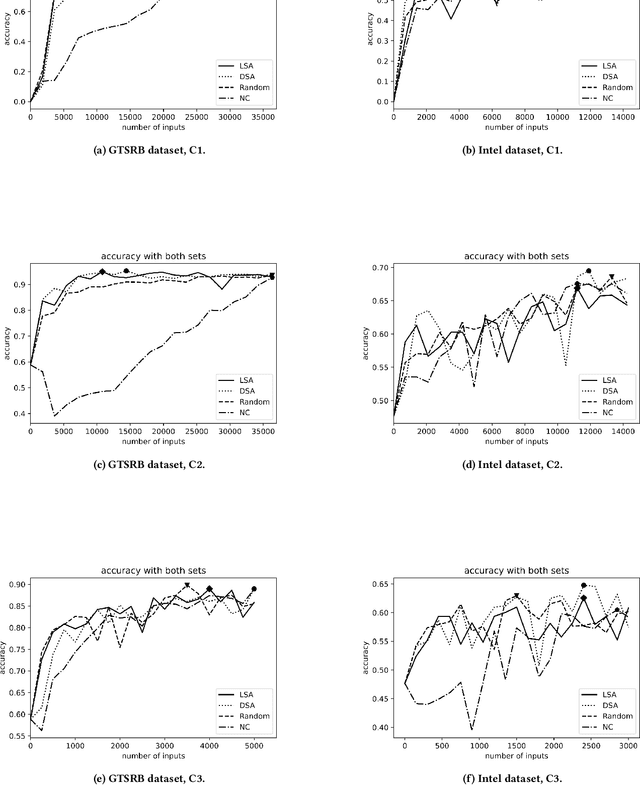
Background: When using deep learning models, there are many possible vulnerabilities and some of the most worrying are the adversarial inputs, which can cause wrong decisions with minor perturbations. Therefore, it becomes necessary to retrain these models against adversarial inputs, as part of the software testing process addressing the vulnerability to these inputs. Furthermore, for an energy efficient testing and retraining, data scientists need support on which are the best guidance metrics and optimal dataset configurations. Aims: We examined four guidance metrics for retraining convolutional neural networks and three retraining configurations. Our goal is to improve the models against adversarial inputs regarding accuracy, resource utilization and time from the point of view of a data scientist in the context of image classification. Method: We conducted an empirical study in two datasets for image classification. We explore: (a) the accuracy, resource utilization and time of retraining convolutional neural networks by ordering new training set by four different guidance metrics (neuron coverage, likelihood-based surprise adequacy, distance-based surprise adequacy and random), (b) the accuracy and resource utilization of retraining convolutional neural networks with three different configurations (from scratch and augmented dataset, using weights and augmented dataset, and using weights and only adversarial inputs). Results: We reveal that retraining with adversarial inputs from original weights and by ordering with surprise adequacy metrics gives the best model w.r.t. the used metrics. Conclusions: Although more studies are necessary, we recommend data scientists to use the above configuration and metrics to deal with the vulnerability to adversarial inputs of deep learning models, as they can improve their models against adversarial inputs without using many inputs.
EXTERN: Leveraging Endo-Temporal Regularization for Black-box Video Domain Adaptation
Aug 10, 2022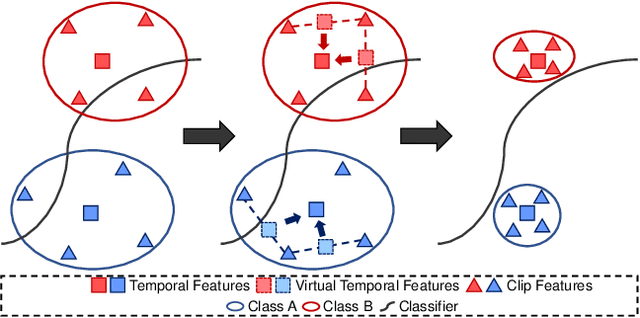
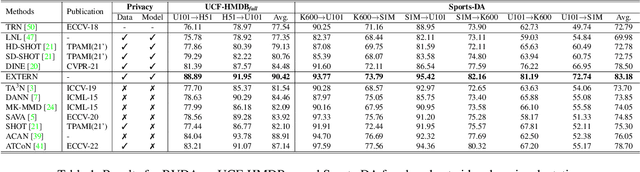
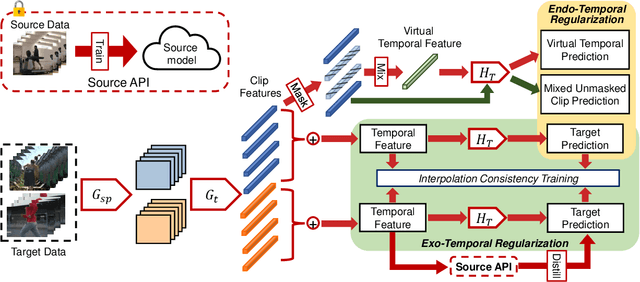
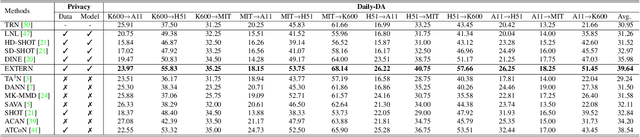
To enable video models to be applied seamlessly across video tasks in different environments, various Video Unsupervised Domain Adaptation (VUDA) methods have been proposed to improve the robustness and transferability of video models. Despite improvements made in model robustness, these VUDA methods require access to both source data and source model parameters for adaptation, raising serious data privacy and model portability issues. To cope with the above concerns, this paper firstly formulates Black-box Video Domain Adaptation (BVDA) as a more realistic yet challenging scenario where the source video model is provided only as a black-box predictor. While a few methods for Black-box Domain Adaptation (BDA) are proposed in image domain, these methods cannot apply to video domain since video modality has more complicated temporal features that are harder to align. To address BVDA, we propose a novel Endo and eXo-TEmporal Regularized Network (EXTERN) by applying mask-to-mix strategies and video-tailored regularizations: endo-temporal regularization and exo-temporal regularization, performed across both clip and temporal features, while distilling knowledge from the predictions obtained from the black-box predictor. Empirical results demonstrate the state-of-the-art performance of EXTERN across various cross-domain closed-set and partial-set action recognition benchmarks, which even surpassed most existing video domain adaptation methods with source data accessibility.
InfiniteNature-Zero: Learning Perpetual View Generation of Natural Scenes from Single Images
Jul 22, 2022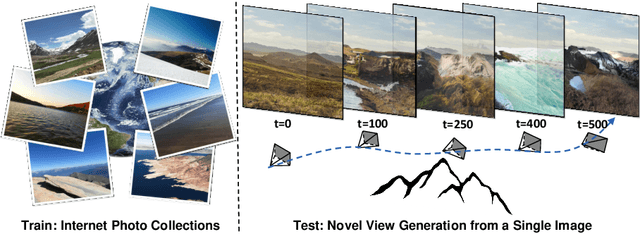
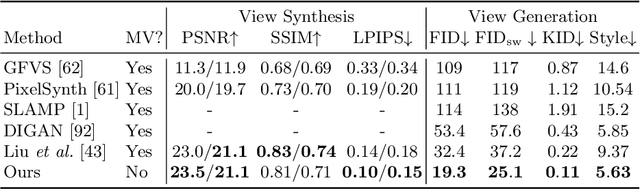
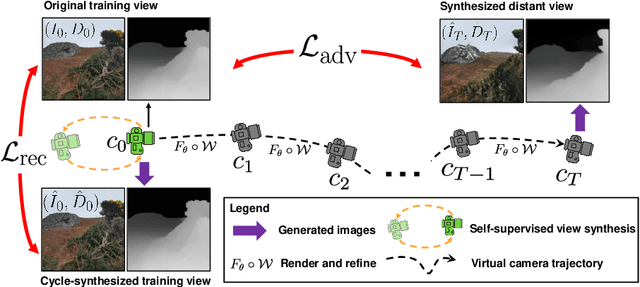
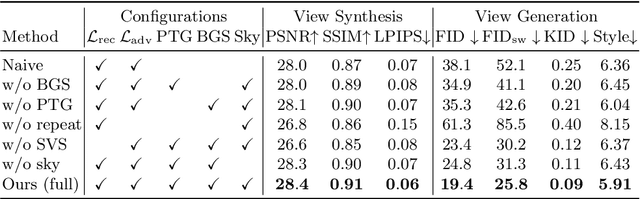
We present a method for learning to generate unbounded flythrough videos of natural scenes starting from a single view, where this capability is learned from a collection of single photographs, without requiring camera poses or even multiple views of each scene. To achieve this, we propose a novel self-supervised view generation training paradigm, where we sample and rendering virtual camera trajectories, including cyclic ones, allowing our model to learn stable view generation from a collection of single views. At test time, despite never seeing a video during training, our approach can take a single image and generate long camera trajectories comprised of hundreds of new views with realistic and diverse content. We compare our approach with recent state-of-the-art supervised view generation methods that require posed multi-view videos and demonstrate superior performance and synthesis quality.
Image-to-image Translation via Hierarchical Style Disentanglement
Mar 02, 2021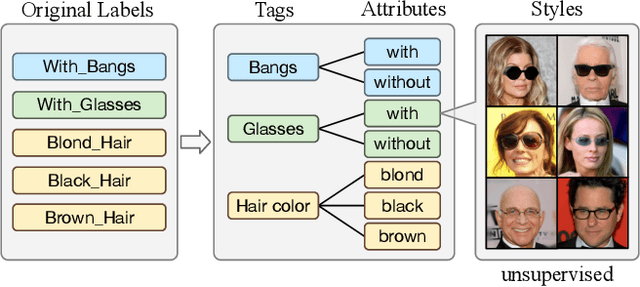


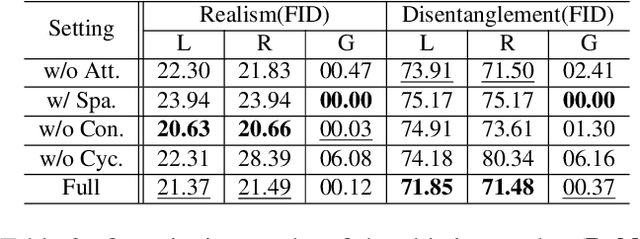
Recently, image-to-image translation has made significant progress in achieving both multi-label (\ie, translation conditioned on different labels) and multi-style (\ie, generation with diverse styles) tasks. However, due to the unexplored independence and exclusiveness in the labels, existing endeavors are defeated by involving uncontrolled manipulations to the translation results. In this paper, we propose Hierarchical Style Disentanglement (HiSD) to address this issue. Specifically, we organize the labels into a hierarchical tree structure, in which independent tags, exclusive attributes, and disentangled styles are allocated from top to bottom. Correspondingly, a new translation process is designed to adapt the above structure, in which the styles are identified for controllable translations. Both qualitative and quantitative results on the CelebA-HQ dataset verify the ability of the proposed HiSD. We hope our method will serve as a solid baseline and provide fresh insights with the hierarchically organized annotations for future research in image-to-image translation. The code has been released at https://github.com/imlixinyang/HiSD.
CLIP-CLOP: CLIP-Guided Collage and Photomontage
May 19, 2022
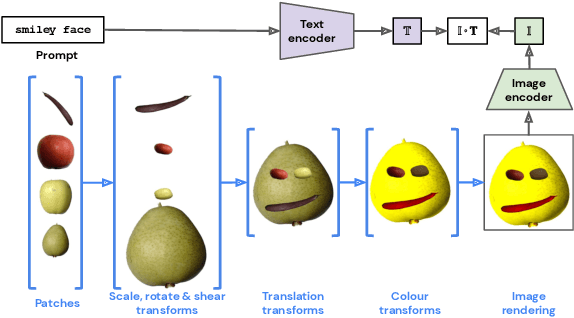
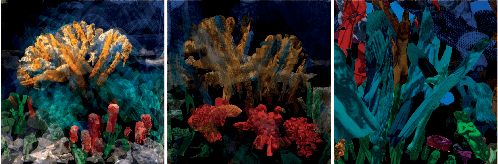
The unabated mystique of large-scale neural networks, such as the CLIP dual image-and-text encoder, popularized automatically generated art. Increasingly more sophisticated generators enhanced the artworks' realism and visual appearance, and creative prompt engineering enabled stylistic expression. Guided by an artist-in-the-loop ideal, we design a gradient-based generator to produce collages. It requires the human artist to curate libraries of image patches and to describe (with prompts) the whole image composition, with the option to manually adjust the patches' positions during generation, thereby allowing humans to reclaim some control of the process and achieve greater creative freedom. We explore the aesthetic potentials of high-resolution collages, and provide an open-source Google Colab as an artistic tool.
Semi-Autoregressive Transformer for Image Captioning
Jun 17, 2021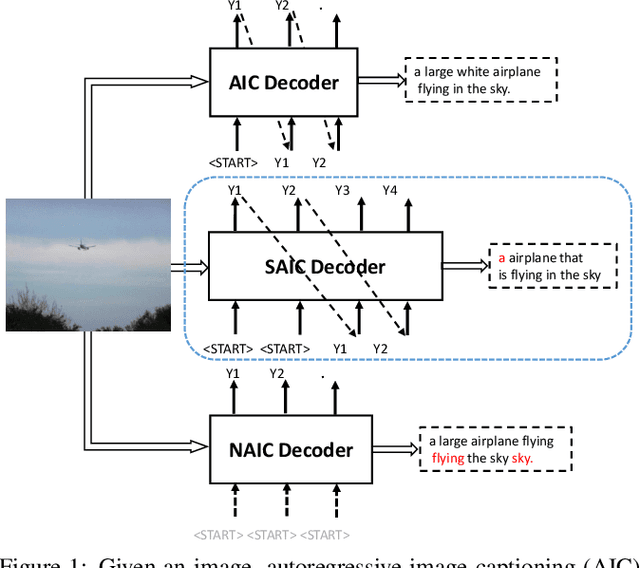
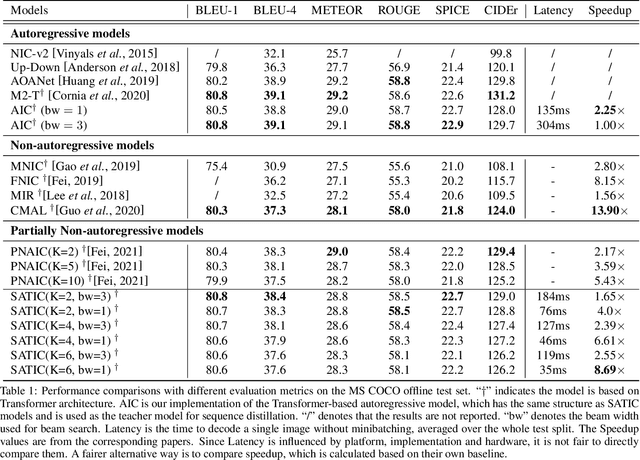
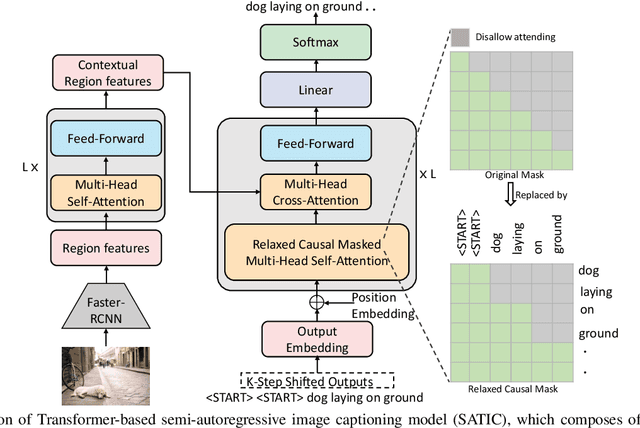
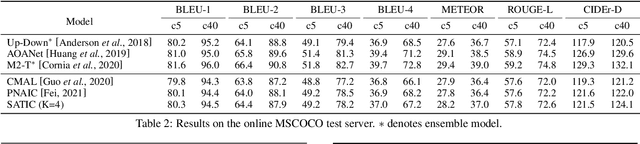
Current state-of-the-art image captioning models adopt autoregressive decoders, \ie they generate each word by conditioning on previously generated words, which leads to heavy latency during inference. To tackle this issue, non-autoregressive image captioning models have recently been proposed to significantly accelerate the speed of inference by generating all words in parallel. However, these non-autoregressive models inevitably suffer from large generation quality degradation since they remove words dependence excessively. To make a better trade-off between speed and quality, we introduce a semi-autoregressive model for image captioning~(dubbed as SATIC), which keeps the autoregressive property in global but generates words parallelly in local. Based on Transformer, there are only a few modifications needed to implement SATIC. Extensive experiments on the MSCOCO image captioning benchmark show that SATIC can achieve a better trade-off without bells and whistles. Code is available at {\color{magenta}\url{https://github.com/YuanEZhou/satic}}.
SVBRDF Recovery From a Single Image With Highlights using a Pretrained Generative Adversarial Network
Oct 29, 2021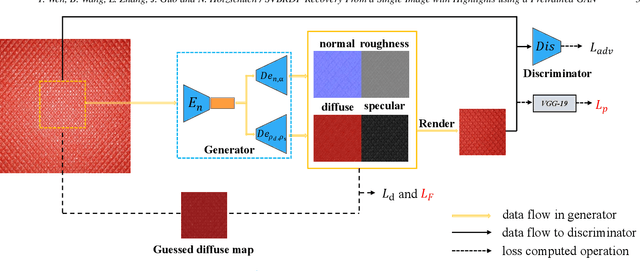
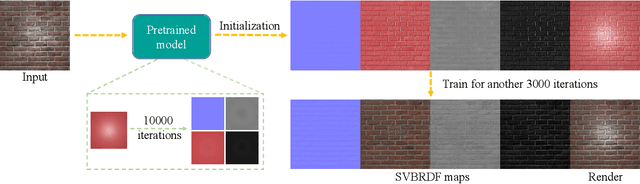
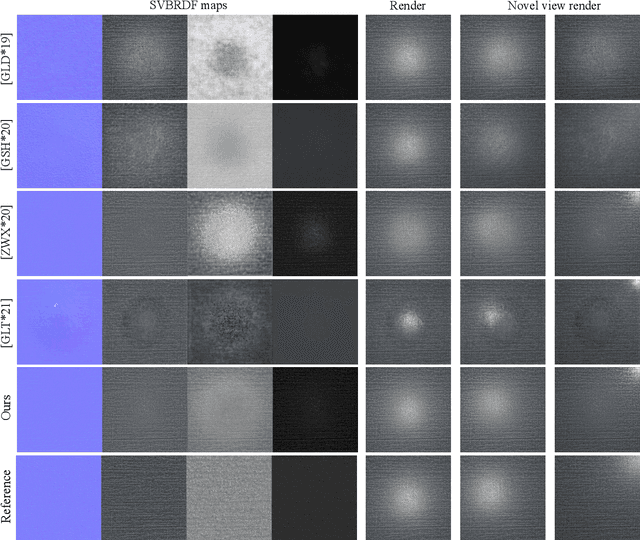

Spatially-varying bi-directional reflectance distribution functions (SVBRDFs) are crucial for designers to incorporate new materials in virtual scenes, making them look more realistic. Reconstruction of SVBRDFs is a long-standing problem. Existing methods either rely on extensive acquisition system or require huge datasets which are nontrivial to acquire. We aim to recover SVBRDFs from a single image, without any datasets. A single image contains incomplete information about the SVBRDF, making the reconstruction task highly ill-posed. It is also difficult to separate between the changes in color that are caused by the material and those caused by the illumination, without the prior knowledge learned from the dataset. In this paper, we use an unsupervised generative adversarial neural network (GAN) to recover SVBRDFs maps with a single image as input. To better separate the effects due to illumination from the effects due to the material, we add the hypothesis that the material is stationary and introduce a new loss function based on Fourier coefficients to enforce this stationarity. For efficiency, we train the network in two stages: reusing a trained model to initialize the SVBRDFs and fine-tune it based on the input image. Our method generates high-quality SVBRDFs maps from a single input photograph, and provides more vivid rendering results compared to previous work. The two-stage training boosts runtime performance, making it 8 times faster than previous work.