 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Correlation between image quality metrics of magnetic resonance images and the neural network segmentation accuracy
Nov 01, 2021
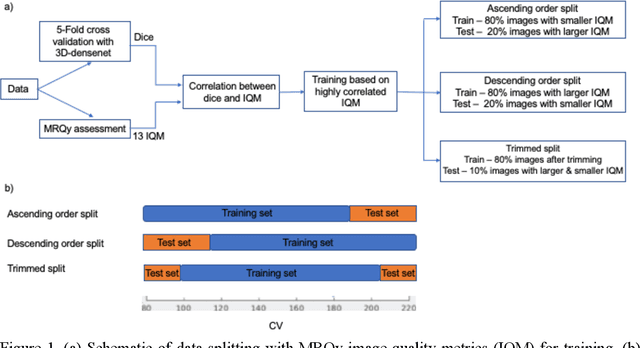
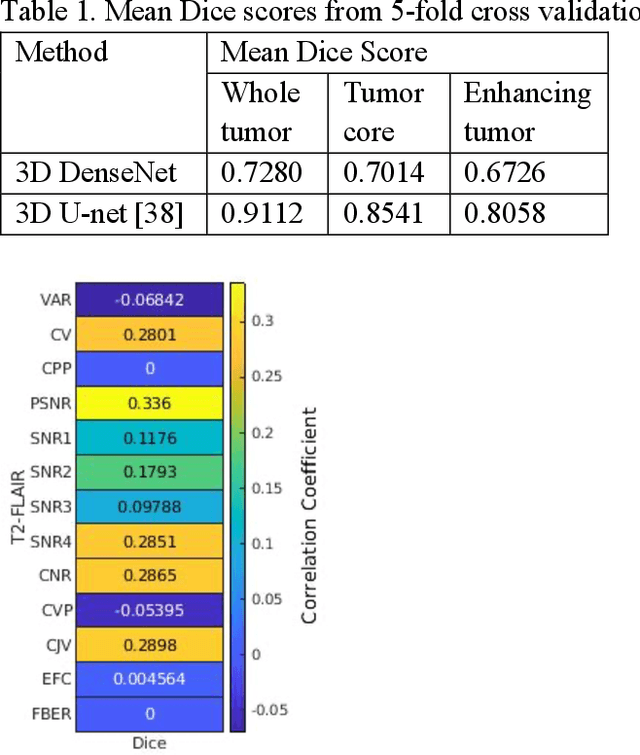
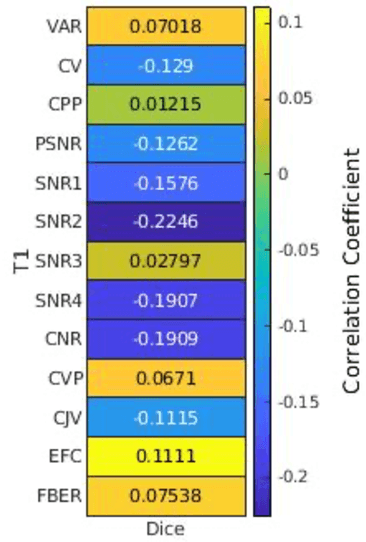
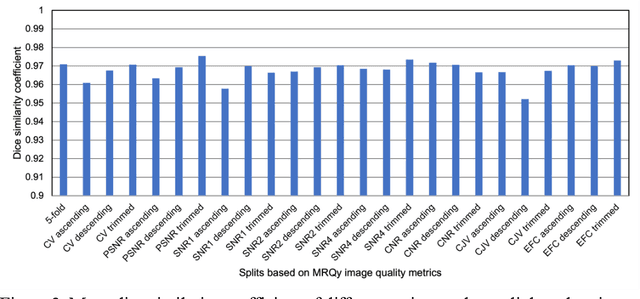
Deep neural networks with multilevel connections process input data in complex ways to learn the information.A networks learning efficiency depends not only on the complex neural network architecture but also on the input training images.Medical image segmentation with deep neural networks for skull stripping or tumor segmentation from magnetic resonance images enables learning both global and local features of the images.Though medical images are collected in a controlled environment,there may be artifacts or equipment based variance that cause inherent bias in the input set.In this study, we investigated the correlation between the image quality metrics of MR images with the neural network segmentation accuracy.For that we have used the 3D DenseNet architecture and let the network trained on the same input but applying different methodologies to select the training data set based on the IQM values.The difference in the segmentation accuracy between models based on the random training inputs with IQM based training inputs shed light on the role of image quality metrics on segmentation accuracy.By running the image quality metrics to choose the training inputs,further we may tune the learning efficiency of the network and the segmentation accuracy.
NeRP: Implicit Neural Representation Learning with Prior Embedding for Sparsely Sampled Image Reconstruction
Aug 24, 2021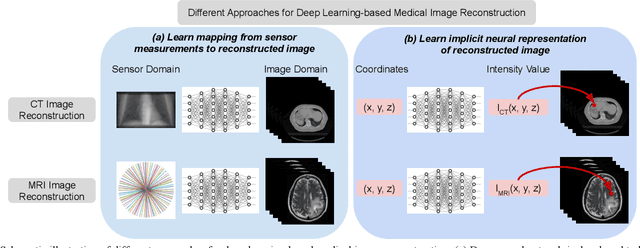
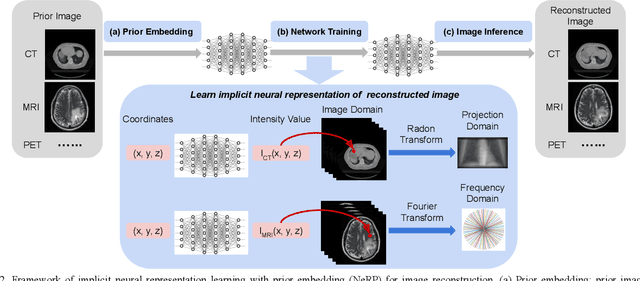
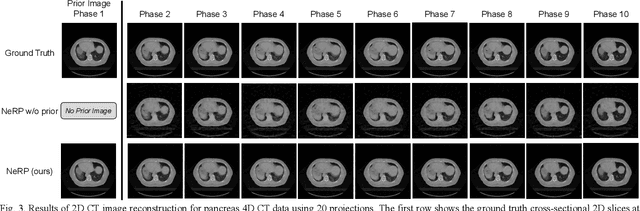
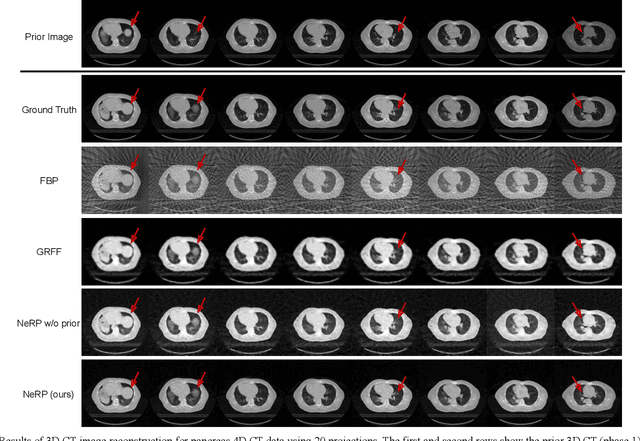
Image reconstruction is an inverse problem that solves for a computational image based on sampled sensor measurement. Sparsely sampled image reconstruction poses addition challenges due to limited measurements. In this work, we propose an implicit Neural Representation learning methodology with Prior embedding (NeRP) to reconstruct a computational image from sparsely sampled measurements. The method differs fundamentally from previous deep learning-based image reconstruction approaches in that NeRP exploits the internal information in an image prior, and the physics of the sparsely sampled measurements to produce a representation of the unknown subject. No large-scale data is required to train the NeRP except for a prior image and sparsely sampled measurements. In addition, we demonstrate that NeRP is a general methodology that generalizes to different imaging modalities such as CT and MRI. We also show that NeRP can robustly capture the subtle yet significant image changes required for assessing tumor progression.
Computer Vision Methods for the Microstructural Analysis of Materials: The State-of-the-art and Future Perspectives
Jul 29, 2022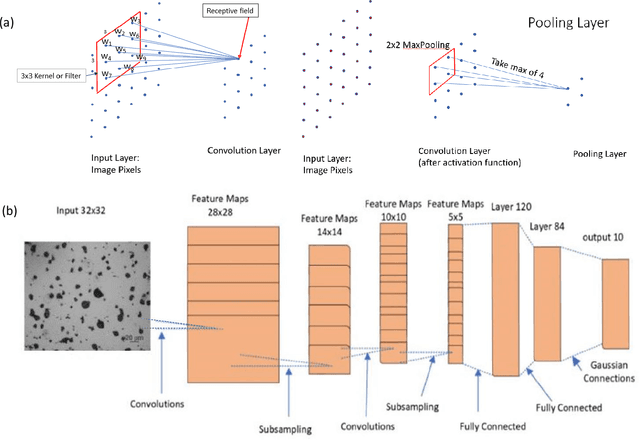
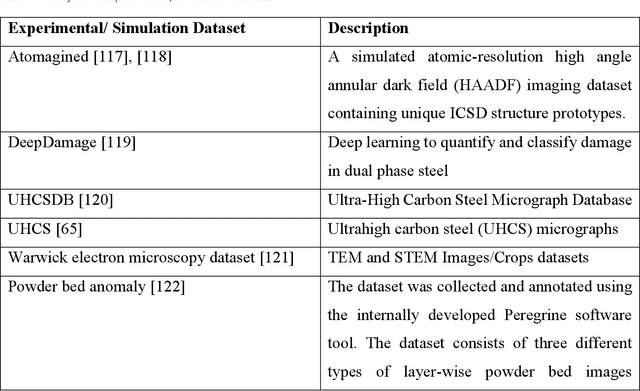
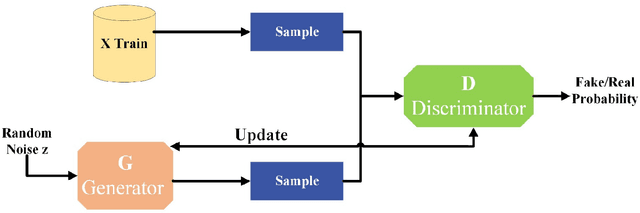
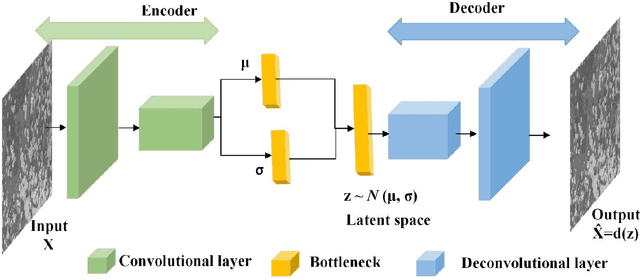
Finding quantitative descriptors representing the microstructural features of a given material is an ongoing research area in the paradigm of Materials-by-Design. Historically, microstructural analysis mostly relies on qualitative descriptions. However, to build a robust and accurate process-structure-properties relationship, which is required for designing new advanced high-performance materials, the extraction of quantitative and meaningful statistical data from the microstructural analysis is a critical step. In recent years, computer vision (CV) methods, especially those which are centered around convolutional neural network (CNN) algorithms have shown promising results for this purpose. This review paper focuses on the state-of-the-art CNN-based techniques that have been applied to various multi-scale microstructural image analysis tasks, including classification, object detection, segmentation, feature extraction, and reconstruction. Additionally, we identified the main challenges with regard to the application of these methods to materials science research. Finally, we discussed some possible future directions of research in this area. In particular, we emphasized the application of transformer-based models and their capabilities to improve the microstructural analysis of materials.
Efficient entity-based reinforcement learning
Jun 06, 2022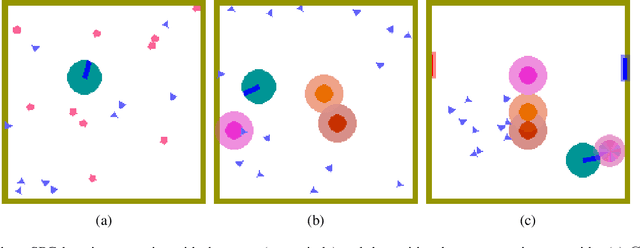
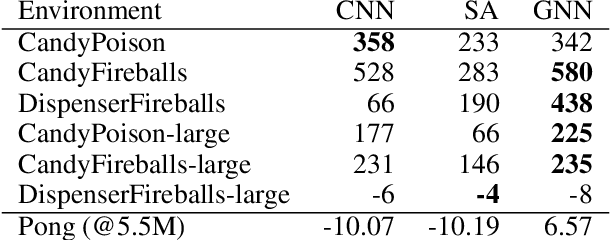
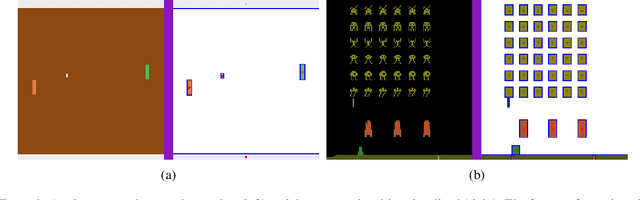
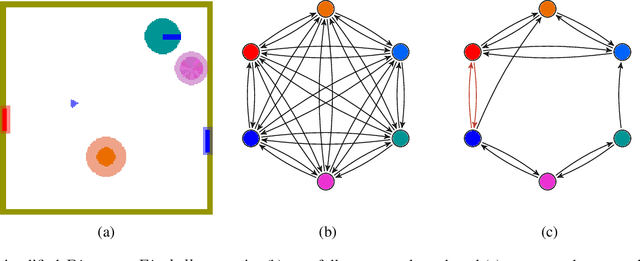
Recent deep reinforcement learning (DRL) successes rely on end-to-end learning from fixed-size observational inputs (e.g. image, state-variables). However, many challenging and interesting problems in decision making involve observations or intermediary representations which are best described as a set of entities: either the image-based approach would miss small but important details in the observations (e.g. ojects on a radar, vehicles on satellite images, etc.), the number of sensed objects is not fixed (e.g. robotic manipulation), or the problem simply cannot be represented in a meaningful way as an image (e.g. power grid control, or logistics). This type of structured representations is not directly compatible with current DRL architectures, however, there has been an increase in machine learning techniques directly targeting structured information, potentially addressing this issue. We propose to combine recent advances in set representations with slot attention and graph neural networks to process structured data, broadening the range of applications of DRL algorithms. This approach allows to address entity-based problems in an efficient and scalable way. We show that it can improve training time and robustness significantly, and demonstrate their potential to handle structured as well as purely visual domains, on multiple environments from the Atari Learning Environment and Simple Playgrounds.
Adaptive DropBlock Enhanced Generative Adversarial Networks for Hyperspectral Image Classification
Jan 22, 2022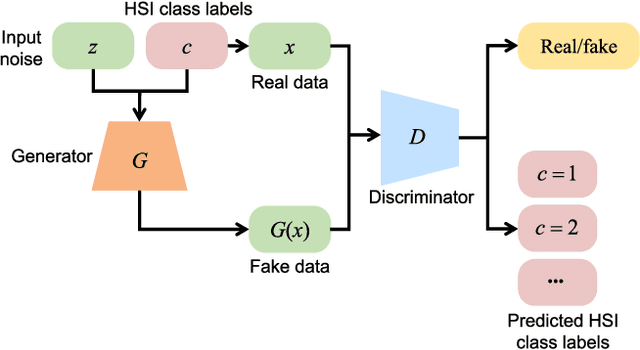
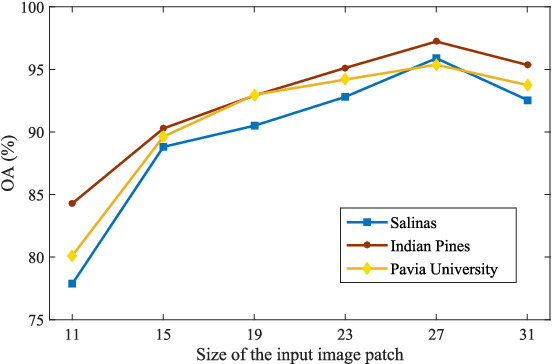
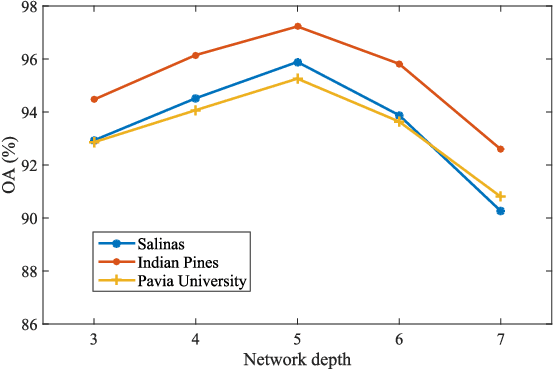
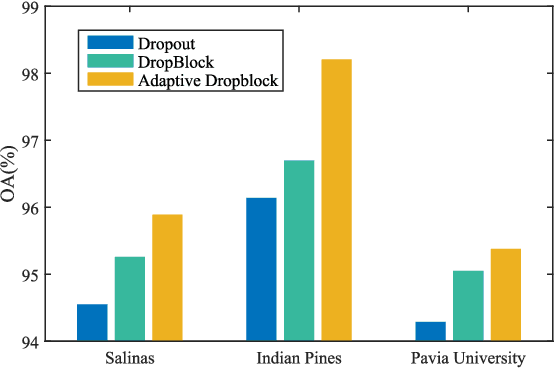
In recent years, hyperspectral image (HSI) classification based on generative adversarial networks (GAN) has achieved great progress. GAN-based classification methods can mitigate the limited training sample dilemma to some extent. However, several studies have pointed out that existing GAN-based HSI classification methods are heavily affected by the imbalanced training data problem. The discriminator in GAN always contradicts itself and tries to associate fake labels to the minority-class samples, and thus impair the classification performance. Another critical issue is the mode collapse in GAN-based methods. The generator is only capable of producing samples within a narrow scope of the data space, which severely hinders the advancement of GAN-based HSI classification methods. In this paper, we proposed an Adaptive DropBlock-enhanced Generative Adversarial Networks (ADGAN) for HSI classification. First, to solve the imbalanced training data problem, we adjust the discriminator to be a single classifier, and it will not contradict itself. Second, an adaptive DropBlock (AdapDrop) is proposed as a regularization method employed in the generator and discriminator to alleviate the mode collapse issue. The AdapDrop generated drop masks with adaptive shapes instead of a fixed size region, and it alleviates the limitations of DropBlock in dealing with ground objects with various shapes. Experimental results on three HSI datasets demonstrated that the proposed ADGAN achieved superior performance over state-of-the-art GAN-based methods. Our codes are available at https://github.com/summitgao/HC_ADGAN
Blended Latent Diffusion
Jun 06, 2022
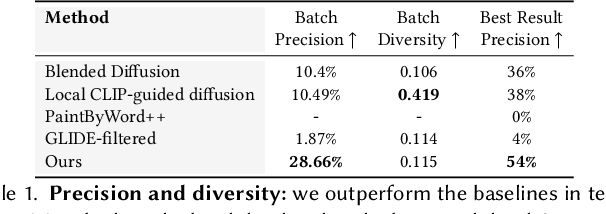

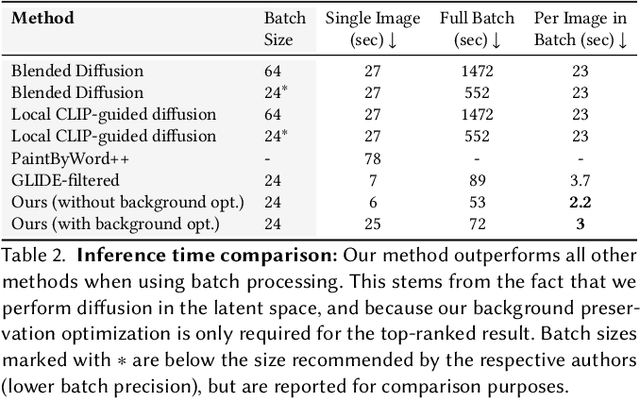
The tremendous progress in neural image generation, coupled with the emergence of seemingly omnipotent vision-language models has finally enabled text-based interfaces for creating and editing images. Handling generic images requires a diverse underlying generative model, hence the latest works utilize diffusion models, which were shown to surpass GANs in terms of diversity. One major drawback of diffusion models, however, is their relatively slow inference time. In this paper, we present an accelerated solution to the task of local text-driven editing of generic images, where the desired edits are confined to a user-provided mask. Our solution leverages a recent text-to-image Latent Diffusion Model (LDM), which speeds up diffusion by operating in a lower-dimensional latent space. We first convert the LDM into a local image editor by incorporating Blended Diffusion into it. Next we propose an optimization-based solution for the inherent inability of this LDM to accurately reconstruct images. Finally, we address the scenario of performing local edits using thin masks. We evaluate our method against the available baselines both qualitatively and quantitatively and demonstrate that in addition to being faster, our method achieves better precision than the baselines while mitigating some of their artifacts. Project page is available at https://omriavrahami.com/blended-latent-diffusion-page/
Needle In A Haystack, Fast: Benchmarking Image Perceptual Similarity Metrics At Scale
Jun 01, 2022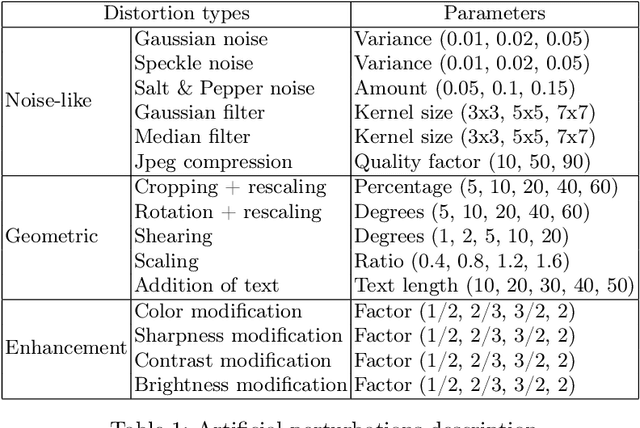

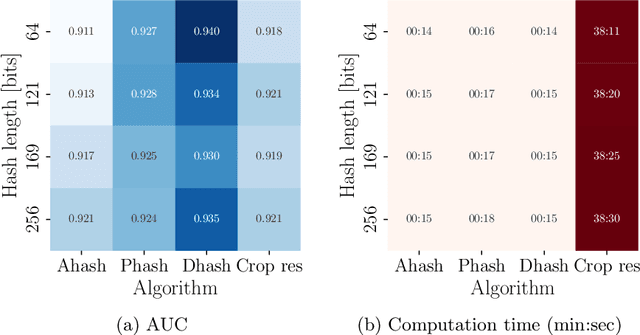
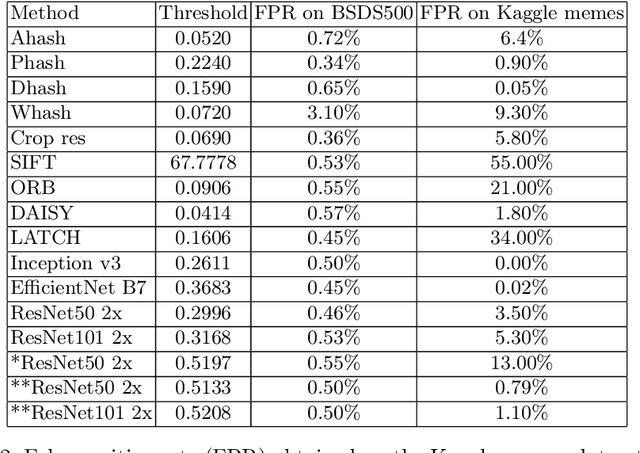
The advent of the internet, followed shortly by the social media made it ubiquitous in consuming and sharing information between anyone with access to it. The evolution in the consumption of media driven by this change, led to the emergence of images as means to express oneself, convey information and convince others efficiently. With computer vision algorithms progressing radically over the last decade, it is become easier and easier to study at scale the role of images in the flow of information online. While the research questions and overall pipelines differ radically, almost all start with a crucial first step - evaluation of global perceptual similarity between different images. That initial step is crucial for overall pipeline performance and processes most images. A number of algorithms are available and currently used to perform it, but so far no comprehensive review was available to guide the choice of researchers as to the choice of an algorithm best suited to their question, assumptions and computational resources. With this paper we aim to fill this gap, showing that classical computer vision methods are not necessarily the best approach, whereas a pair of relatively little used methods - Dhash perceptual hash and SimCLR v2 ResNets achieve excellent performance, scale well and are computationally efficient.
RAZE: Region Guided Self-Supervised Gaze Representation Learning
Aug 05, 2022
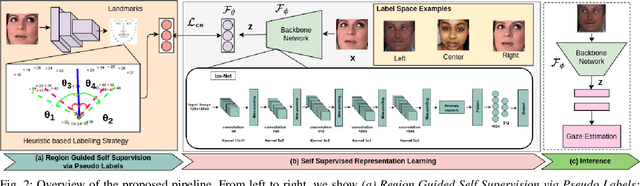


Automatic eye gaze estimation is an important problem in vision based assistive technology with use cases in different emerging topics such as augmented reality, virtual reality and human-computer interaction. Over the past few years, there has been an increasing interest in unsupervised and self-supervised learning paradigms as it overcomes the requirement of large scale annotated data. In this paper, we propose RAZE, a Region guided self-supervised gAZE representation learning framework which leverage from non-annotated facial image data. RAZE learns gaze representation via auxiliary supervision i.e. pseudo-gaze zone classification where the objective is to classify visual field into different gaze zones (i.e. left, right and center) by leveraging the relative position of pupil-centers. Thus, we automatically annotate pseudo gaze zone labels of 154K web-crawled images and learn feature representations via `Ize-Net' framework. `Ize-Net' is a capsule layer based CNN architecture which can efficiently capture rich eye representation. The discriminative behaviour of the feature representation is evaluated on four benchmark datasets: CAVE, TabletGaze, MPII and RT-GENE. Additionally, we evaluate the generalizability of the proposed network on two other downstream task (i.e. driver gaze estimation and visual attention estimation) which demonstrate the effectiveness of the learnt eye gaze representation.
Level Set-Based Camera Pose Estimation From Multiple 2D/3D Ellipse-Ellipsoid Correspondences
Jul 16, 2022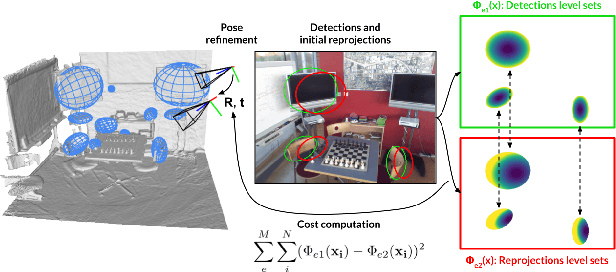

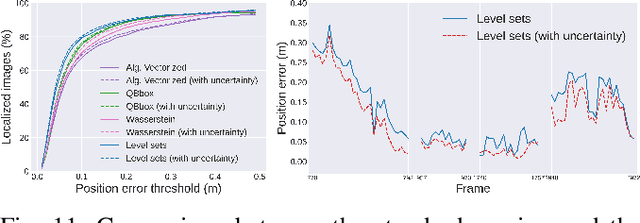

In this paper, we propose an object-based camera pose estimation from a single RGB image and a pre-built map of objects, represented with ellipsoidal models. We show that contrary to point correspondences, the definition of a cost function characterizing the projection of a 3D object onto a 2D object detection is not straightforward. We develop an ellipse-ellipse cost based on level sets sampling, demonstrate its nice properties for handling partially visible objects and compare its performance with other common metrics. Finally, we show that the use of a predictive uncertainty on the detected ellipses allows a fair weighting of the contribution of the correspondences which improves the computed pose. The code is released at https://gitlab.inria.fr/tangram/level-set-based-camera-pose-estimation.
From Shallow to Deep: Compositional Reasoning over Graphs for Visual Question Answering
Jun 25, 2022
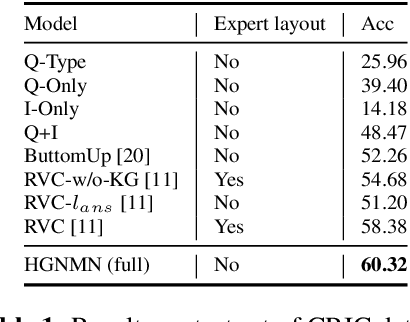
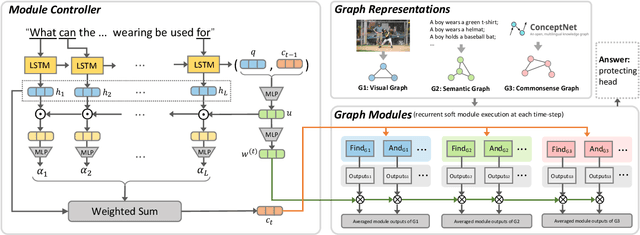
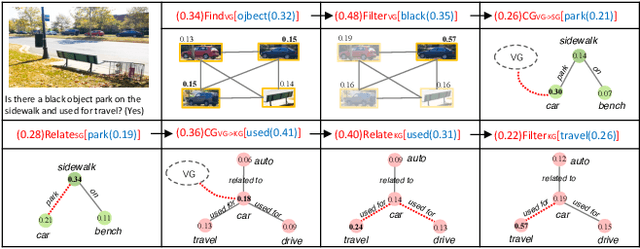
In order to achieve a general visual question answering (VQA) system, it is essential to learn to answer deeper questions that require compositional reasoning on the image and external knowledge. Meanwhile, the reasoning process should be explicit and explainable to understand the working mechanism of the model. It is effortless for human but challenging for machines. In this paper, we propose a Hierarchical Graph Neural Module Network (HGNMN) that reasons over multi-layer graphs with neural modules to address the above issues. Specifically, we first encode the image by multi-layer graphs from the visual, semantic and commonsense views since the clues that support the answer may exist in different modalities. Our model consists of several well-designed neural modules that perform specific functions over graphs, which can be used to conduct multi-step reasoning within and between different graphs. Compared to existing modular networks, we extend visual reasoning from one graph to more graphs. We can explicitly trace the reasoning process according to module weights and graph attentions. Experiments show that our model not only achieves state-of-the-art performance on the CRIC dataset but also obtains explicit and explainable reasoning procedures.