 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Separable Quaternion Matrix Factorization for Polarization Images
Jul 28, 2022
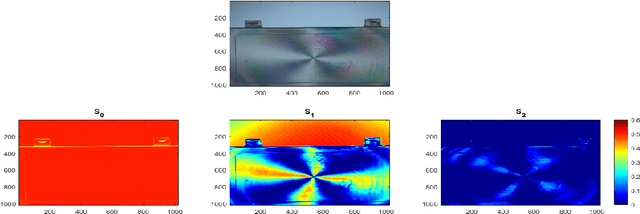
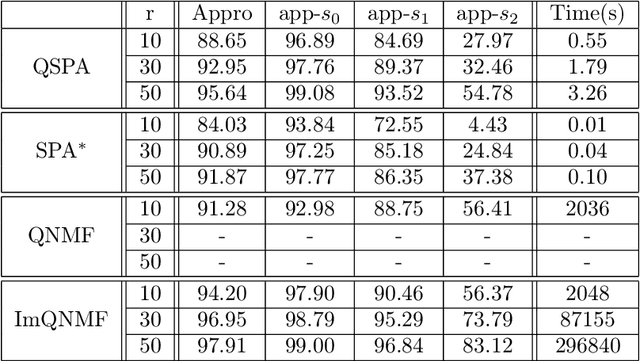
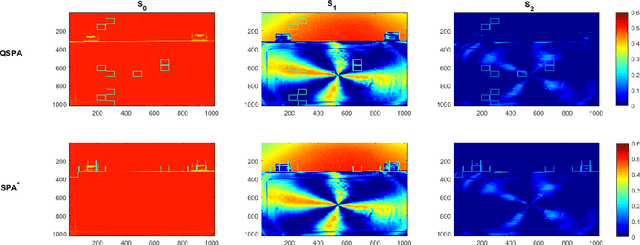
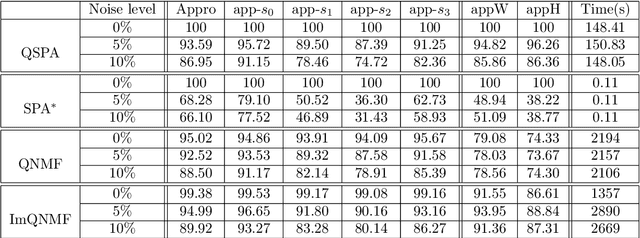
Polarization is a unique characteristic of transverse wave and is represented by Stokes parameters. Analysis of polarization states can reveal valuable information about the sources. In this paper, we propose a separable low-rank quaternion linear mixing model to polarized signals: we assume each column of the source factor matrix equals a column of polarized data matrix and refer to the corresponding problem as separable quaternion matrix factorization (SQMF). We discuss some properties of the matrix that can be decomposed by SQMF. To determine the source factor matrix in quaternion space, we propose a heuristic algorithm called quaternion successive projection algorithm (QSPA) inspired by the successive projection algorithm. To guarantee the effectiveness of QSPA, a new normalization operator is proposed for the quaternion matrix. We use a block coordinate descent algorithm to compute nonnegative factor activation matrix in real number space. We test our method on the applications of polarization image representation and spectro-polarimetric imaging unmixing to verify its effectiveness.
Two-dimensional total absorption spectroscopy with conditional generative adversarial networks
Jun 23, 2022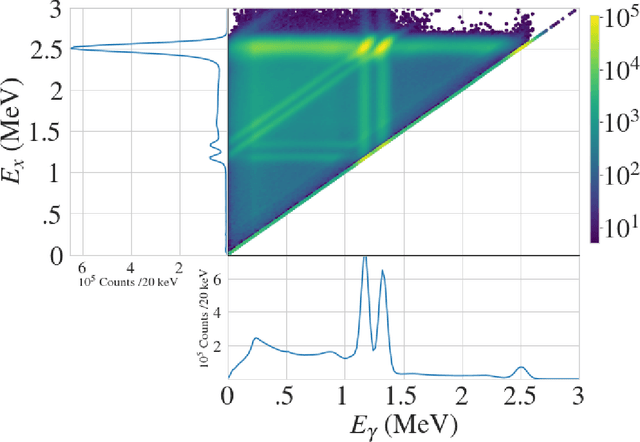
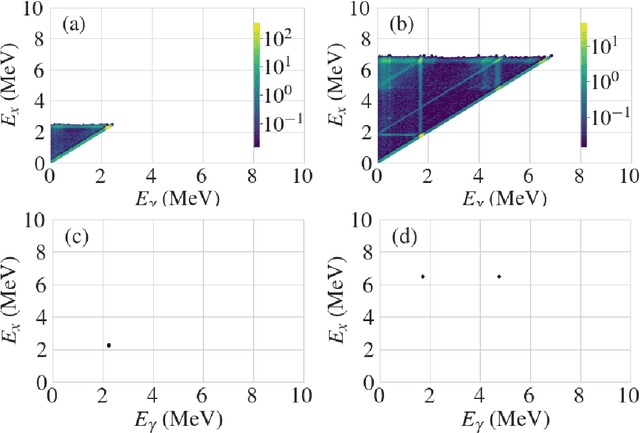
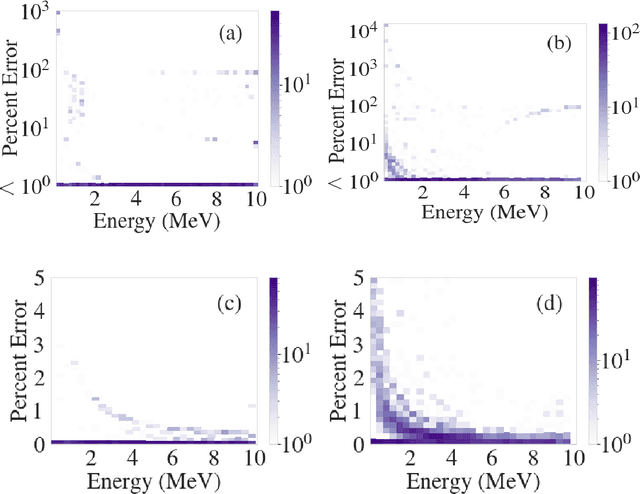
We explore the use of machine learning techniques to remove the response of large volume $\gamma$-ray detectors from experimental spectra. Segmented $\gamma$-ray total absorption spectrometers (TAS) allow for the simultaneous measurement of individual $\gamma$-ray energy (E$_\gamma$) and total excitation energy (E$_x$). Analysis of TAS detector data is complicated by the fact that the E$_x$ and E$_\gamma$ quantities are correlated, and therefore, techniques that simply unfold using E$_x$ and E$_\gamma$ response functions independently are not as accurate. In this work, we investigate the use of conditional generative adversarial networks (cGANs) to simultaneously unfold $E_{x}$ and $E_{\gamma}$ data in TAS detectors. Specifically, we employ a Pix2Pix cGAN, a generative modeling technique based on recent advances in deep learning, to treat $(E_x, E_{\gamma})$ matrix unfolding as an image-to-image translation problem. We present results for simulated and experimental matrices of single-$\gamma$ and double-$\gamma$ decay cascades. Our model demonstrates characterization capabilities within detector resolution limits for upwards of $90\%$ of simulated test cases.
An Image Classifier Can Suffice For Video Understanding
Jun 30, 2021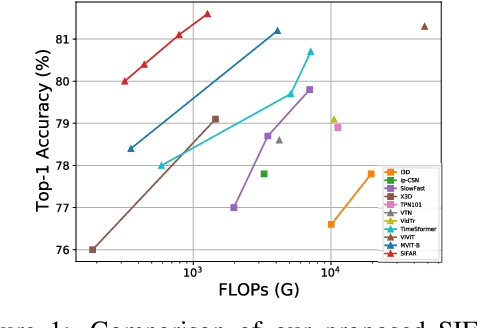
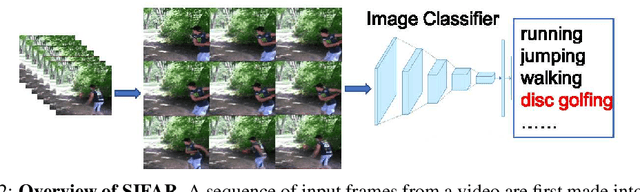
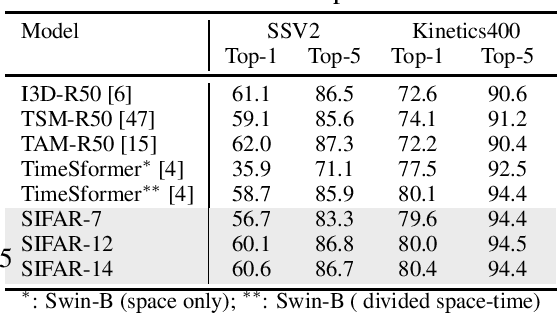
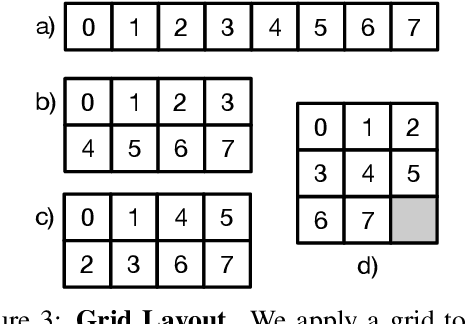
We propose a new perspective on video understanding by casting the video recognition problem as an image recognition task. We show that an image classifier alone can suffice for video understanding without temporal modeling. Our approach is simple and universal. It composes input frames into a super image to train an image classifier to fulfill the task of action recognition, in exactly the same way as classifying an image. We prove the viability of such an idea by demonstrating strong and promising performance on four public datasets including Kinetics400, Something-to-something (V2), MiT and Jester, using a recently developed vision transformer. We also experiment with the prevalent ResNet image classifiers in computer vision to further validate our idea. The results on Kinetics400 are comparable to some of the best-performed CNN approaches based on spatio-temporal modeling. our code and models will be made available at https://github.com/IBM/sifar-pytorch.
GRIT-VLP: Grouped Mini-batch Sampling for Efficient Vision and Language Pre-training
Aug 08, 2022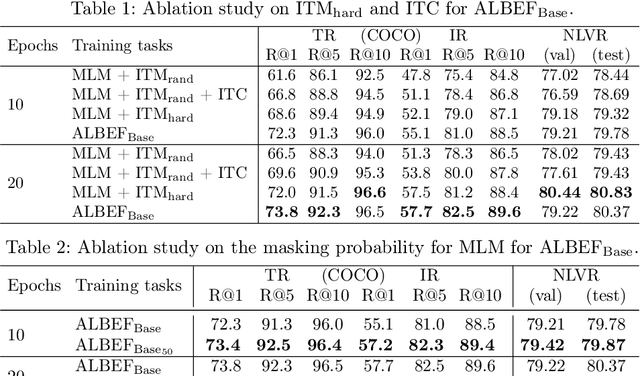
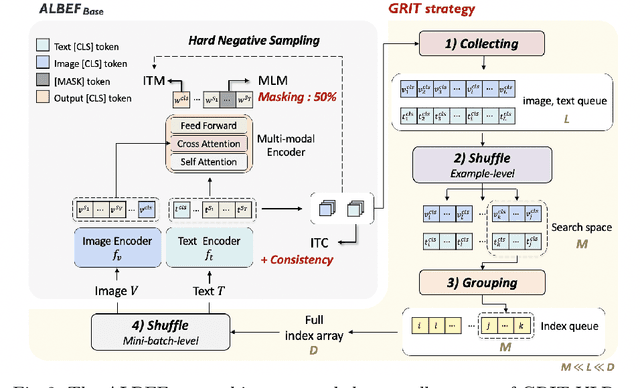
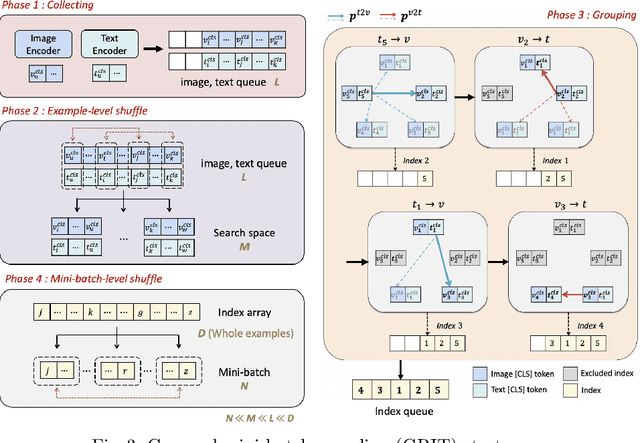
Most of the currently existing vision and language pre-training (VLP) methods have mainly focused on how to extract and align vision and text features. In contrast to the mainstream VLP methods, we highlight that two routinely applied steps during pre-training have crucial impact on the performance of the pre-trained model: in-batch hard negative sampling for image-text matching (ITM) and assigning the large masking probability for the masked language modeling (MLM). After empirically showing the unexpected effectiveness of above two steps, we systematically devise our GRIT-VLP, which adaptively samples mini-batches for more effective mining of hard negative samples for ITM while maintaining the computational cost for pre-training. Our method consists of three components: 1) GRouped mIni-baTch sampling (GRIT) strategy that collects similar examples in a mini-batch, 2) ITC consistency loss for improving the mining ability, and 3) enlarged masking probability for MLM. Consequently, we show our GRIT-VLP achieves a new state-of-the-art performance on various downstream tasks with much less computational cost. Furthermore, we demonstrate that our model is essentially in par with ALBEF, the previous state-of-the-art, only with one-third of training epochs on the same training data. Code is available at https://github.com/jaeseokbyun/GRIT-VLP.
Learning to Re-weight Examples with Optimal Transport for Imbalanced Classification
Aug 05, 2022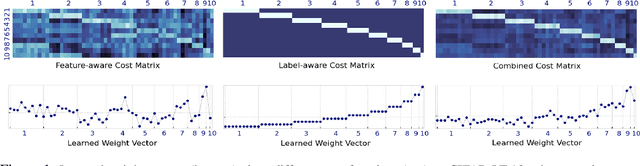
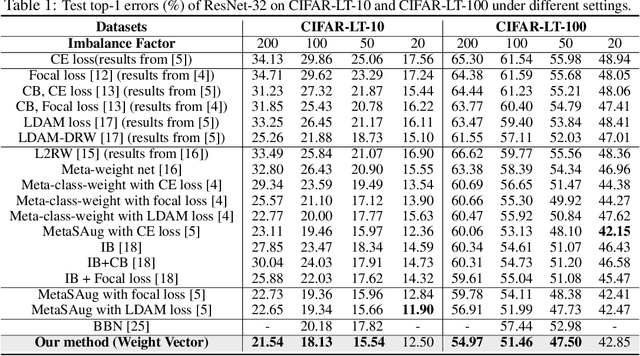
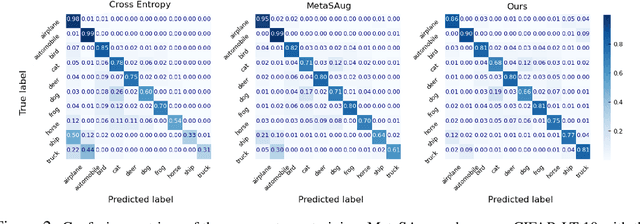
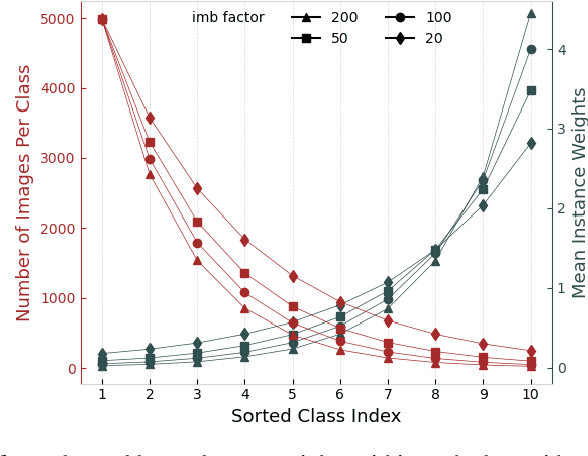
Imbalanced data pose challenges for deep learning based classification models. One of the most widely-used approaches for tackling imbalanced data is re-weighting, where training samples are associated with different weights in the loss function. Most of existing re-weighting approaches treat the example weights as the learnable parameter and optimize the weights on the meta set, entailing expensive bilevel optimization. In this paper, we propose a novel re-weighting method based on optimal transport (OT) from a distributional point of view. Specifically, we view the training set as an imbalanced distribution over its samples, which is transported by OT to a balanced distribution obtained from the meta set. The weights of the training samples are the probability mass of the imbalanced distribution and learned by minimizing the OT distance between the two distributions. Compared with existing methods, our proposed one disengages the dependence of the weight learning on the concerned classifier at each iteration. Experiments on image, text and point cloud datasets demonstrate that our proposed re-weighting method has excellent performance, achieving state-of-the-art results in many cases and providing a promising tool for addressing the imbalanced classification issue.
RedCaps: web-curated image-text data created by the people, for the people
Nov 22, 2021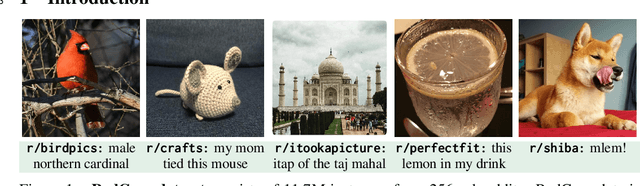


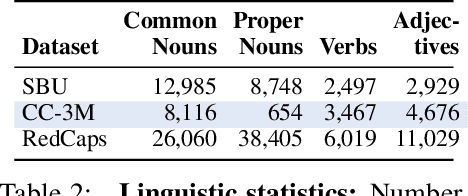
Large datasets of paired images and text have become increasingly popular for learning generic representations for vision and vision-and-language tasks. Such datasets have been built by querying search engines or collecting HTML alt-text -- since web data is noisy, they require complex filtering pipelines to maintain quality. We explore alternate data sources to collect high quality data with minimal filtering. We introduce RedCaps -- a large-scale dataset of 12M image-text pairs collected from Reddit. Images and captions from Reddit depict and describe a wide variety of objects and scenes. We collect data from a manually curated set of subreddits, which give coarse image labels and allow us to steer the dataset composition without labeling individual instances. We show that captioning models trained on RedCaps produce rich and varied captions preferred by humans, and learn visual representations that transfer to many downstream tasks.
NPB-REC: Non-parametric Assessment of Uncertainty in Deep-learning-based MRI Reconstruction from Undersampled Data
Aug 08, 2022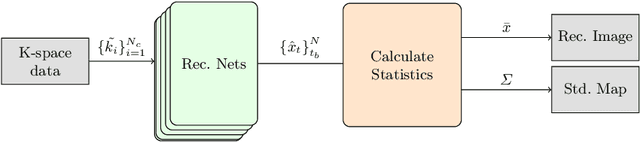
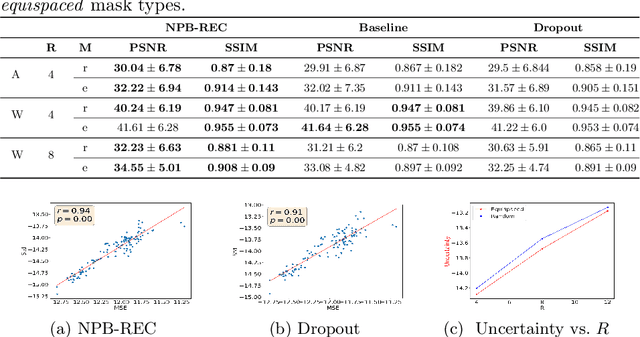
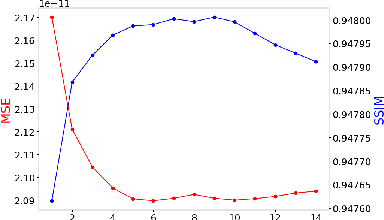
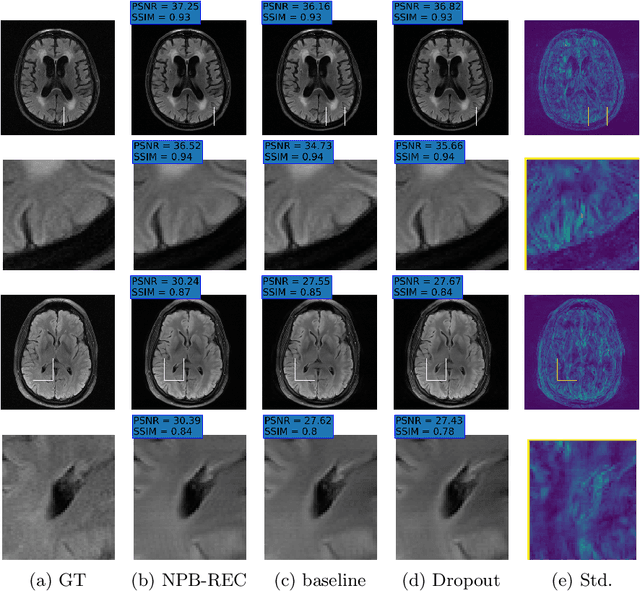
Uncertainty quantification in deep-learning (DL) based image reconstruction models is critical for reliable clinical decision making based on the reconstructed images. We introduce "NPB-REC", a non-parametric fully Bayesian framework for uncertainty assessment in MRI reconstruction from undersampled "k-space" data. We use Stochastic gradient Langevin dynamics (SGLD) during the training phase to characterize the posterior distribution of the network weights. We demonstrated the added-value of our approach on the multi-coil brain MRI dataset, from the fastmri challenge, in comparison to the baseline E2E-VarNet with and without inference-time dropout. Our experiments show that NPB-REC outperforms the baseline by means of reconstruction accuracy (PSNR and SSIM of $34.55$, $0.908$ vs. $33.08$, $0.897$, $p<0.01$) in high acceleration rates ($R=8$). This is also measured in regions of clinical annotations. More significantly, it provides a more accurate estimate of the uncertainty that correlates with the reconstruction error, compared to the Monte-Carlo inference time Dropout method (Pearson correlation coefficient of $R=0.94$ vs. $R=0.91$). The proposed approach has the potential to facilitate safe utilization of DL based methods for MRI reconstruction from undersampled data. Code and trained models are available in \url{https://github.com/samahkh/NPB-REC}.
Image enhancement in acoustic-resolution photoacoustic microscopy enabled by a novel directional algorithm
Nov 19, 2021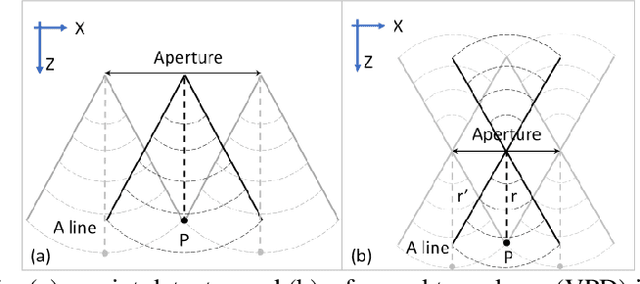
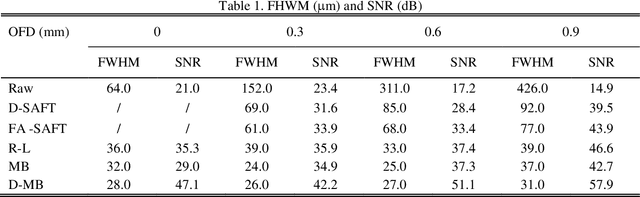

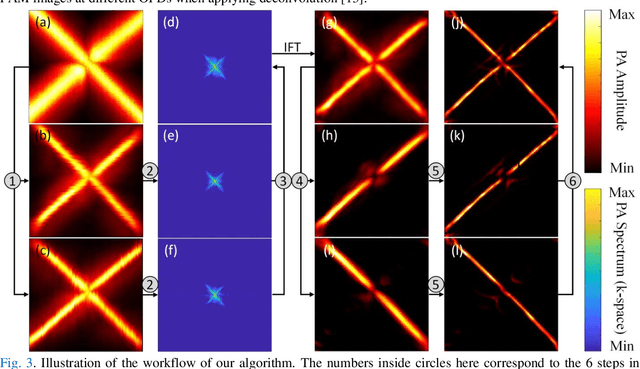
Acoustic-resolution photoacoustic microscopy (AR-PAM) is a promising tool for microvascular imaging. In the focal region, resolution of AR-PAM is determined by the ultrasound transducer and ultimately limited by acoustic diffraction. In the out-of-focus region, resolution deteriorates with increasing distance from the focal plane, which restricts depth of focus (DOF). Besides, a trade-off exists between resolution and DOF. Previously, synthetic aperture focusing technique (SAFT) and/or deconvolution methods have been demonstrated to enhance AR-PAM images. However, they suffer from issues in low resolution, low signal-to-noise ratio (SNR), and/or poor image fidelity. Here, we propose a novel algorithm for AR-PAM to enhance image resolution, SNR, and fidelity. The algorithm consists of a Fourier accumulation SAFT (FA-SAFT) and a directional model-based (D-MB) deconvolution method. Inspired from Fourier denoising technique and directional SAFT, FA-SAFT mainly compensates for the defocusing effect. Besides, D-MB deconvolution enhances the resolution as well as preserves the image fidelity, especially for the objects with line patterns such as microvasculature. Full width at half maximum of 26-31 um over DOF of 1.8 mm and minimum resolvable distance of 46-49 um are experimentally achieved by imaging tungsten wire phantom. Moreover, imaging of leaf skeleton phantom and in vivo imaging of mouse blood vessels also prove that our algorithm is capable of providing high-resolution, high-SNR, and good-fidelity results for complex structures and for in vivo applications.
An Enhanced Deep Learning Technique for Prostate Cancer Identification Based on MRI Scans
Aug 01, 2022
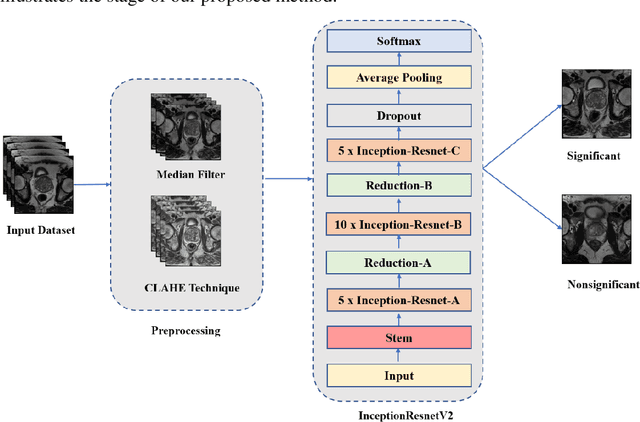
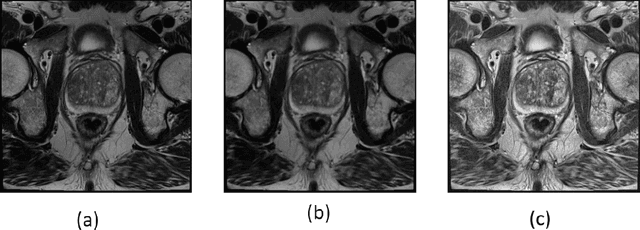
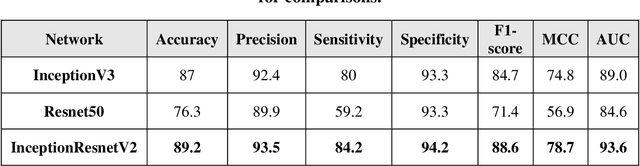
Prostate cancer is the most dangerous cancer diagnosed in men worldwide. Prostate diagnosis has been affected by many factors, such as lesion complexity, observer visibility, and variability. Many techniques based on Magnetic Resonance Imaging (MRI) have been used for prostate cancer identification and classification in the last few decades. Developing these techniques is crucial and has a great medical effect because they improve the treatment benefits and the chance of patients' survival. A new technique that depends on MRI has been proposed to improve the diagnosis. This technique consists of two stages. First, the MRI images have been preprocessed to make the medical image more suitable for the detection step. Second, prostate cancer identification has been performed based on a pre-trained deep learning model, InceptionResNetV2, that has many advantages and achieves effective results. In this paper, the InceptionResNetV2 deep learning model used for this purpose has average accuracy equals to 89.20%, and the area under the curve (AUC) equals to 93.6%. The experimental results of this proposed new deep learning technique represent promising and effective results compared to other previous techniques.
Aug-NeRF: Training Stronger Neural Radiance Fields with Triple-Level Physically-Grounded Augmentations
Jul 04, 2022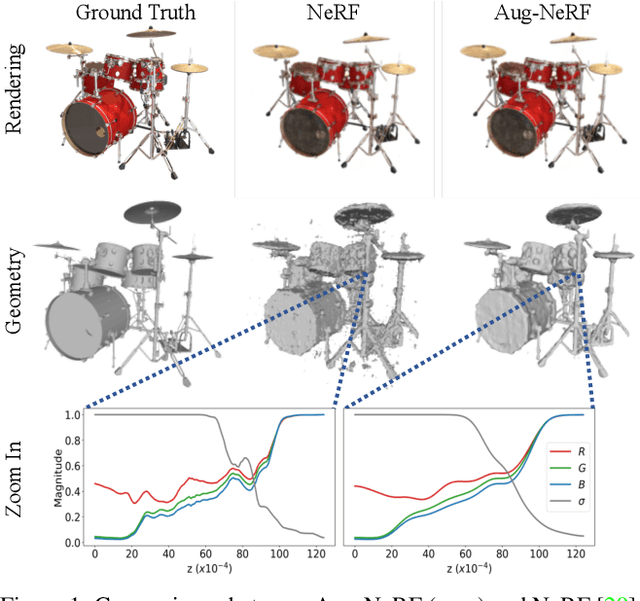
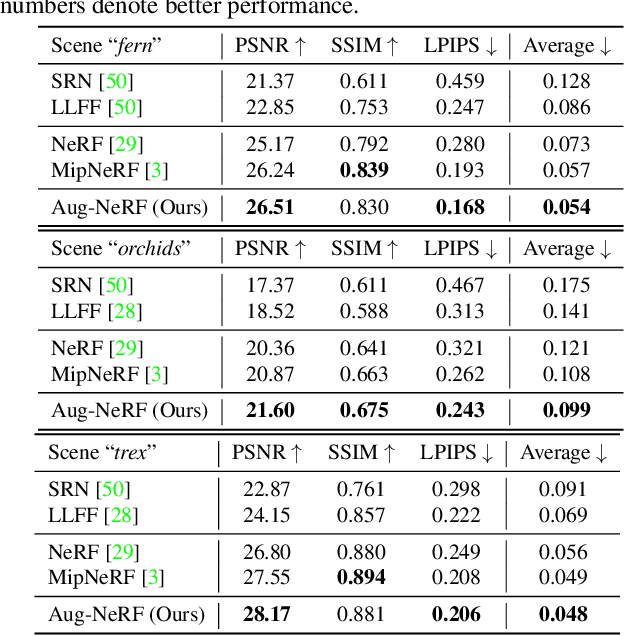
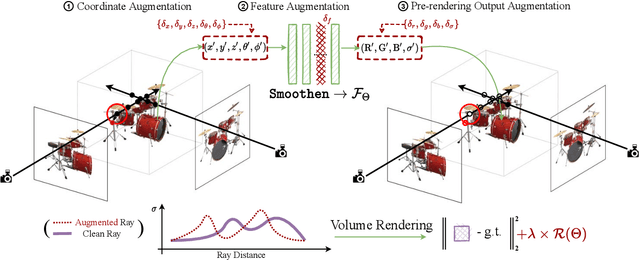
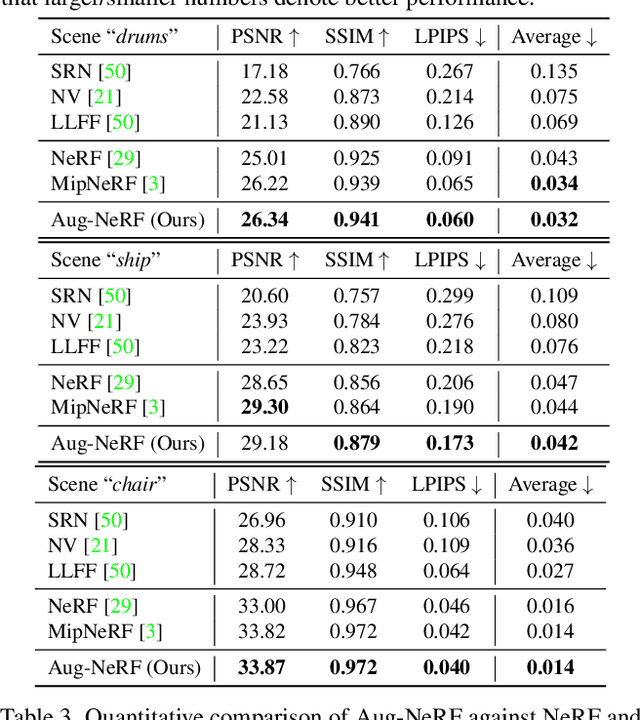
Neural Radiance Field (NeRF) regresses a neural parameterized scene by differentially rendering multi-view images with ground-truth supervision. However, when interpolating novel views, NeRF often yields inconsistent and visually non-smooth geometric results, which we consider as a generalization gap between seen and unseen views. Recent advances in convolutional neural networks have demonstrated the promise of advanced robust data augmentations, either random or learned, in enhancing both in-distribution and out-of-distribution generalization. Inspired by that, we propose Augmented NeRF (Aug-NeRF), which for the first time brings the power of robust data augmentations into regularizing the NeRF training. Particularly, our proposal learns to seamlessly blend worst-case perturbations into three distinct levels of the NeRF pipeline with physical grounds, including (1) the input coordinates, to simulate imprecise camera parameters at image capture; (2) intermediate features, to smoothen the intrinsic feature manifold; and (3) pre-rendering output, to account for the potential degradation factors in the multi-view image supervision. Extensive results demonstrate that Aug-NeRF effectively boosts NeRF performance in both novel view synthesis (up to 1.5dB PSNR gain) and underlying geometry reconstruction. Furthermore, thanks to the implicit smooth prior injected by the triple-level augmentations, Aug-NeRF can even recover scenes from heavily corrupted images, a highly challenging setting untackled before. Our codes are available in https://github.com/VITA-Group/Aug-NeRF.