 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Variable-Rate Deep Image Compression through Spatially-Adaptive Feature Transform
Aug 21, 2021
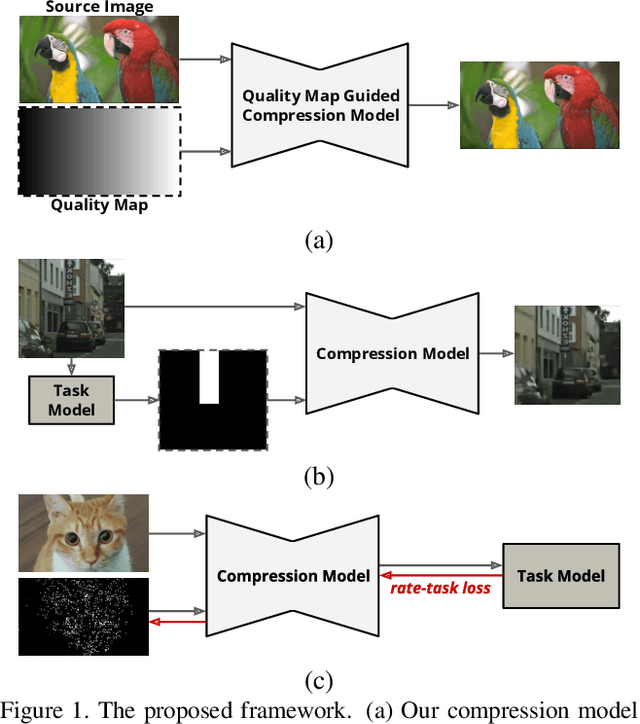


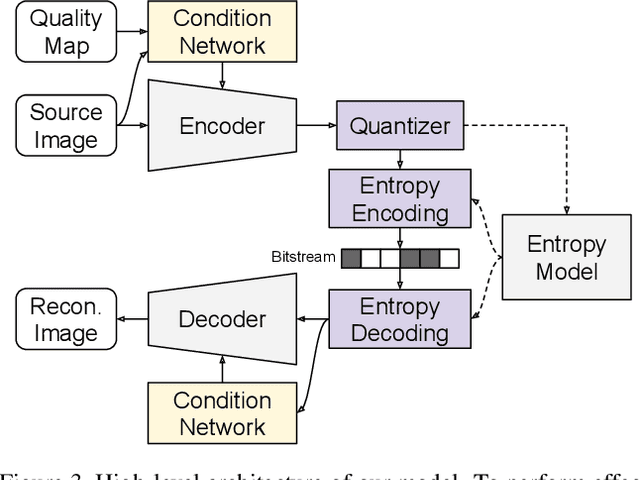
We propose a versatile deep image compression network based on Spatial Feature Transform (SFT arXiv:1804.02815), which takes a source image and a corresponding quality map as inputs and produce a compressed image with variable rates. Our model covers a wide range of compression rates using a single model, which is controlled by arbitrary pixel-wise quality maps. In addition, the proposed framework allows us to perform task-aware image compressions for various tasks, e.g., classification, by efficiently estimating optimized quality maps specific to target tasks for our encoding network. This is even possible with a pretrained network without learning separate models for individual tasks. Our algorithm achieves outstanding rate-distortion trade-off compared to the approaches based on multiple models that are optimized separately for several different target rates. At the same level of compression, the proposed approach successfully improves performance on image classification and text region quality preservation via task-aware quality map estimation without additional model training. The code is available at the project website: https://github.com/micmic123/QmapCompression
Aug-NeRF: Training Stronger Neural Radiance Fields with Triple-Level Physically-Grounded Augmentations
Jul 04, 2022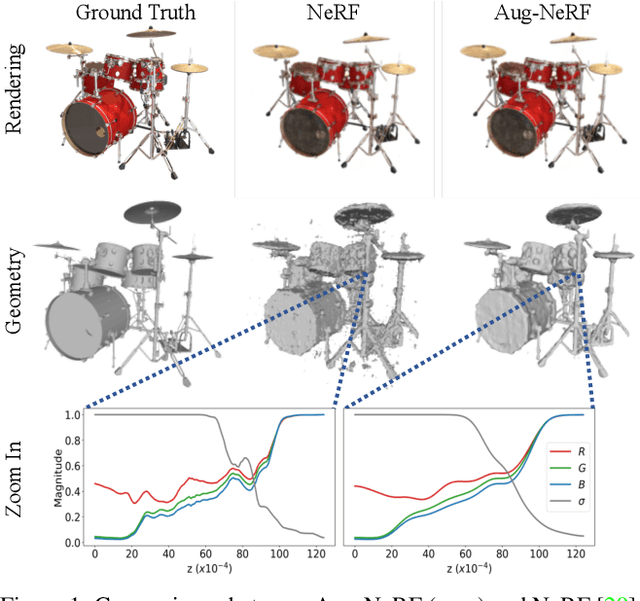
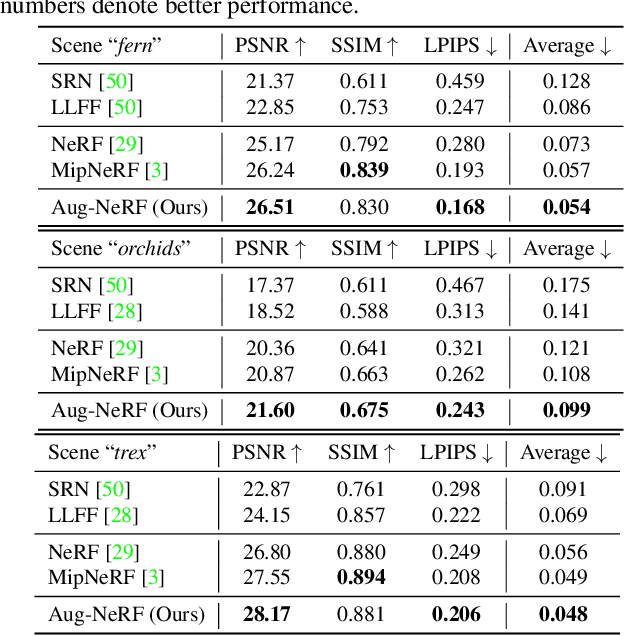
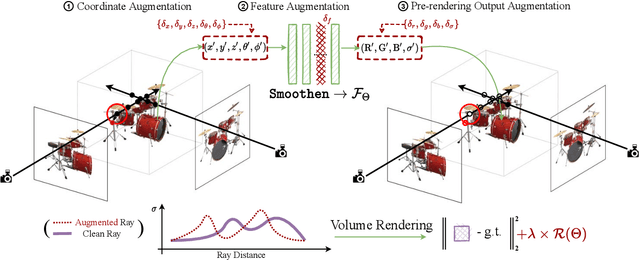
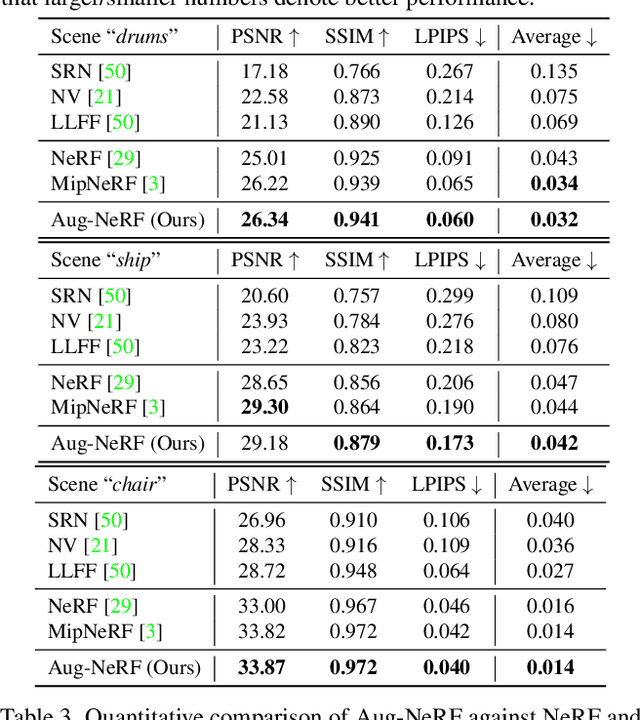
Neural Radiance Field (NeRF) regresses a neural parameterized scene by differentially rendering multi-view images with ground-truth supervision. However, when interpolating novel views, NeRF often yields inconsistent and visually non-smooth geometric results, which we consider as a generalization gap between seen and unseen views. Recent advances in convolutional neural networks have demonstrated the promise of advanced robust data augmentations, either random or learned, in enhancing both in-distribution and out-of-distribution generalization. Inspired by that, we propose Augmented NeRF (Aug-NeRF), which for the first time brings the power of robust data augmentations into regularizing the NeRF training. Particularly, our proposal learns to seamlessly blend worst-case perturbations into three distinct levels of the NeRF pipeline with physical grounds, including (1) the input coordinates, to simulate imprecise camera parameters at image capture; (2) intermediate features, to smoothen the intrinsic feature manifold; and (3) pre-rendering output, to account for the potential degradation factors in the multi-view image supervision. Extensive results demonstrate that Aug-NeRF effectively boosts NeRF performance in both novel view synthesis (up to 1.5dB PSNR gain) and underlying geometry reconstruction. Furthermore, thanks to the implicit smooth prior injected by the triple-level augmentations, Aug-NeRF can even recover scenes from heavily corrupted images, a highly challenging setting untackled before. Our codes are available in https://github.com/VITA-Group/Aug-NeRF.
Real Time Object Detection System with YOLO and CNN Models: A Review
Jul 23, 2022The field of artificial intelligence is built on object detection techniques. YOU ONLY LOOK ONCE (YOLO) algorithm and it's more evolved versions are briefly described in this research survey. This survey is all about YOLO and convolution neural networks (CNN)in the direction of real time object detection.YOLO does generalized object representation more effectively without precision losses than other object detection models.CNN architecture models have the ability to eliminate highlights and identify objects in any given image. When implemented appropriately, CNN models can address issues like deformity diagnosis, creating educational or instructive application, etc. This article reached atnumber of observations and perspective findings through the analysis.Also it provides support for the focused visual information and feature extraction in the financial and other industries, highlights the method of target detection and feature selection, and briefly describe the development process of YOLO algorithm.
Feather-Light Fourier Domain Adaptation in Magnetic Resonance Imaging
Jul 31, 2022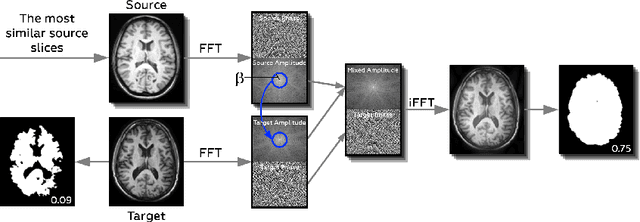

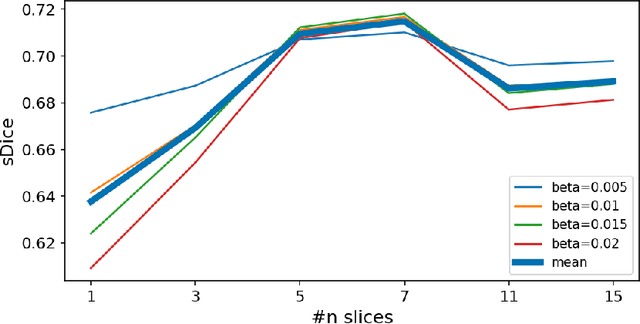
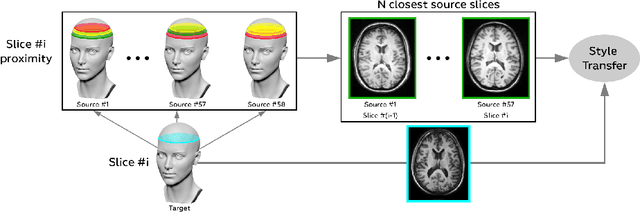
Generalizability of deep learning models may be severely affected by the difference in the distributions of the train (source domain) and the test (target domain) sets, e.g., when the sets are produced by different hardware. As a consequence of this domain shift, a certain model might perform well on data from one clinic, and then fail when deployed in another. We propose a very light and transparent approach to perform test-time domain adaptation. The idea is to substitute the target low-frequency Fourier space components that are deemed to reflect the style of an image. To maximize the performance, we implement the "optimal style donor" selection technique, and use a number of source data points for altering a single target scan appearance (Multi-Source Transferring). We study the effect of severity of domain shift on the performance of the method, and show that our training-free approach reaches the state-of-the-art level of complicated deep domain adaptation models. The code for our experiments is released.
Automatic reorientation by deep learning to generate short axis SPECT myocardial perfusion images
Aug 07, 2022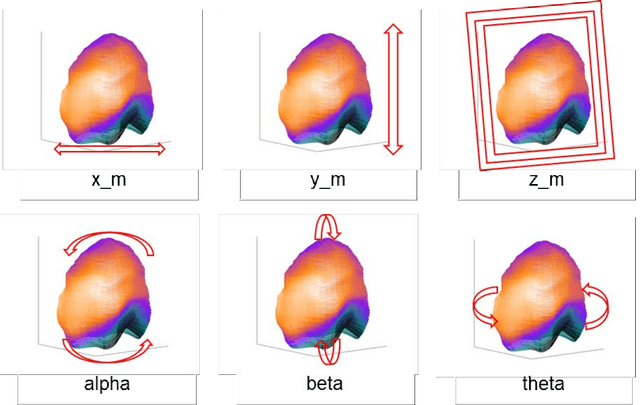
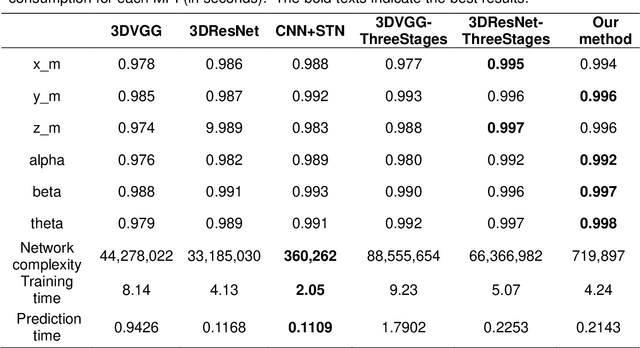
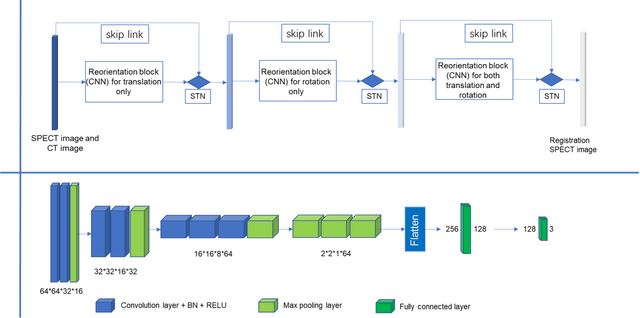
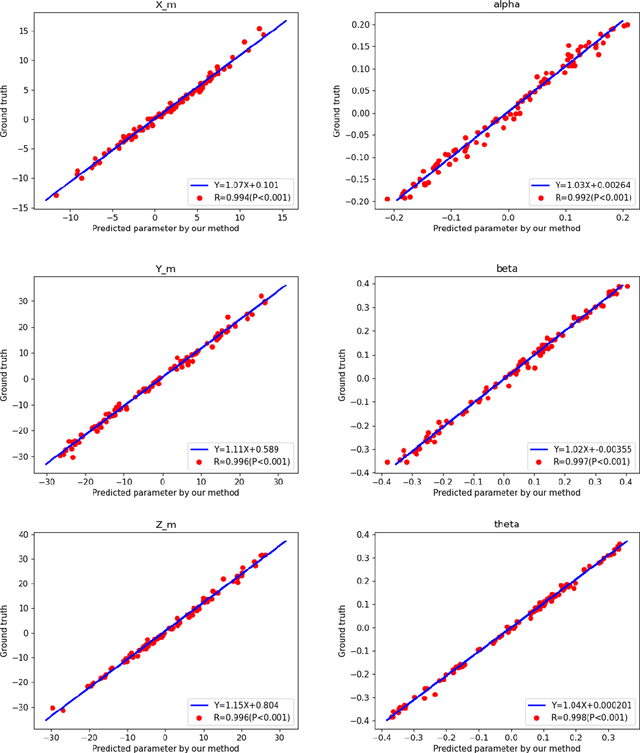
Single photon emission computed tomography (SPECT) myocardial perfusion images (MPI) can be displayed both in traditional short-axis (SA) cardiac planes and polar maps for interpretation and quantification. It is essential to reorient the reconstructed transaxial SPECT MPI into standard SA slices. This study is aimed to develop a deep-learning-based approach for automatic reorientation of MPI. Methods: A total of 254 patients were enrolled, including 228 stress SPECT MPIs and 248 rest SPECT MPIs. Five-fold cross-validation with 180 stress and 201 rest MPIs was used for training and internal validation; the remaining images were used for testing. The rigid transformation parameters (translation and rotation) from manual reorientation were annotated by an experienced operator and used as the ground truth. A convolutional neural network (CNN) was designed to predict the transformation parameters. Then, the derived transform was applied to the grid generator and sampler in spatial transformer network (STN) to generate the reoriented image. A loss function containing mean absolute errors for translation and mean square errors for rotation was employed. A three-stage optimization strategy was adopted for model optimization: 1) optimize the translation parameters while fixing the rotation parameters; 2) optimize rotation parameters while fixing the translation parameters; 3) optimize both translation and rotation parameters together.
4D Real-Time GRASP MRI at Sub-Second Temporal Resolution
Aug 10, 2022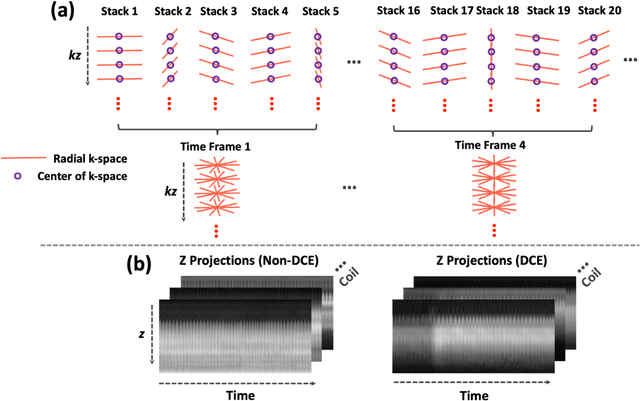
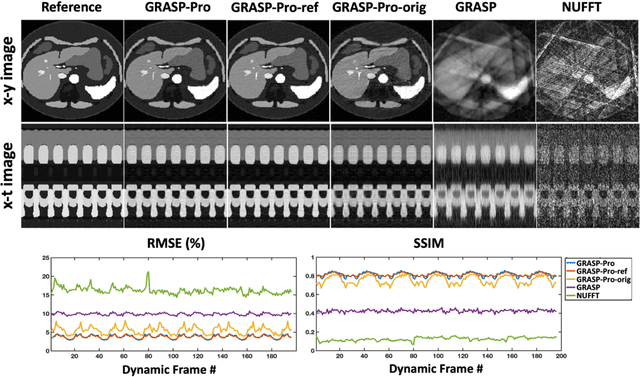
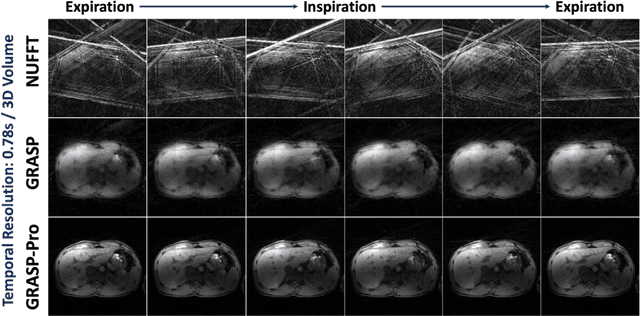
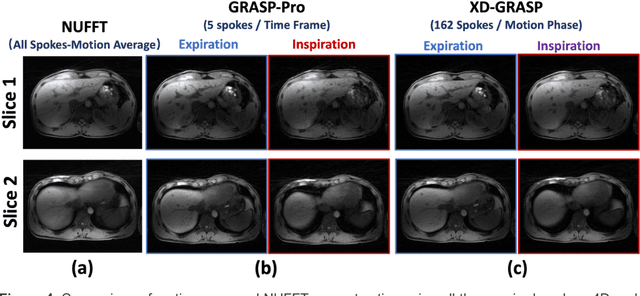
Intra-frame motion blurring, as a major challenge in free-breathing dynamic MRI, can be reduced if high temporal resolution can be achieved. To address this challenge, this work proposes a highly-accelerated 4D (3D+time) real-time MRI framework with sub-second temporal resolution combining standard stack-of-stars golden-angle radial sampling and tailored GRASP-Pro (Golden-angle RAdial Sparse Parallel) reconstruction. Specifically, 4D real-time MRI acquisition is performed continuously without motion gating or sorting. The k-space centers in stack-of-stars radial data are organized to guide estimation of a temporal basis, with which GRASP-Pro reconstruction is employed to enforce joint low-rank subspace and sparsity constraints. This new basis estimation strategy is the new feature proposed for subspace-based reconstruction in this work to achieve high temporal resolution (e.g., sub-second/3D volume). It does not require sequence modification to acquire additional navigation data, is compatible with commercially available stack-of-stars sequences, and does not need an intermediate reconstruction step. The proposed 4D real-time MRI approach was tested in abdominal motion phantom, free-breathing abdominal MRI, and dynamic contrast-enhanced MRI (DCE-MRI). With the ability to acquire each 3D image in less than one second, intra-frame respiratory blurring can be intrinsically reduced for body applications with our approach, which also eliminates the need for motion detection and motion compensation.
Entropy Induced Pruning Framework for Convolutional Neural Networks
Aug 13, 2022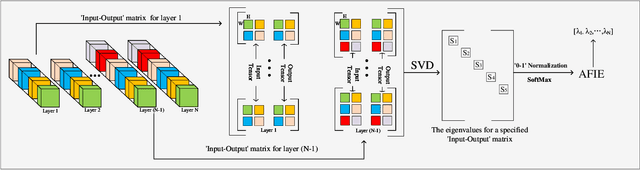
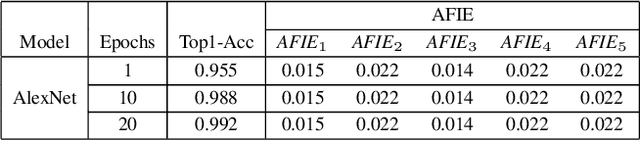
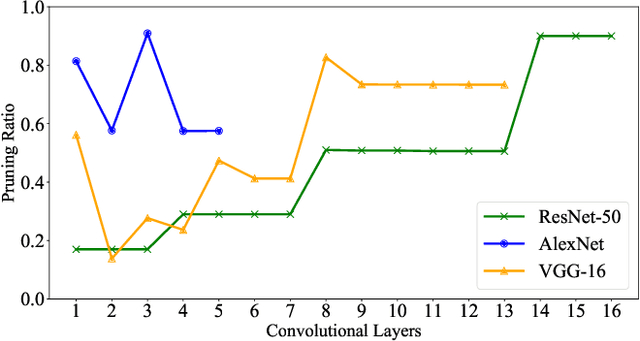

Structured pruning techniques have achieved great compression performance on convolutional neural networks for image classification task. However, the majority of existing methods are weight-oriented, and their pruning results may be unsatisfactory when the original model is trained poorly. That is, a fully-trained model is required to provide useful weight information. This may be time-consuming, and the pruning results are sensitive to the updating process of model parameters. In this paper, we propose a metric named Average Filter Information Entropy (AFIE) to measure the importance of each filter. It is calculated by three major steps, i.e., low-rank decomposition of the "input-output" matrix of each convolutional layer, normalization of the obtained eigenvalues, and calculation of filter importance based on information entropy. By leveraging the proposed AFIE, the proposed framework is able to yield a stable importance evaluation of each filter no matter whether the original model is trained fully. We implement our AFIE based on AlexNet, VGG-16, and ResNet-50, and test them on MNIST, CIFAR-10, and ImageNet, respectively. The experimental results are encouraging. We surprisingly observe that for our methods, even when the original model is only trained with one epoch, the importance evaluation of each filter keeps identical to the results when the model is fully-trained. This indicates that the proposed pruning strategy can perform effectively at the beginning stage of the training process for the original model.
Patch-based medical image segmentation using Quantum Tensor Networks
Sep 15, 2021
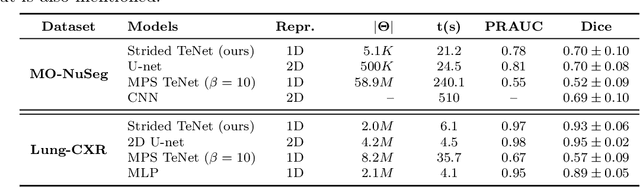
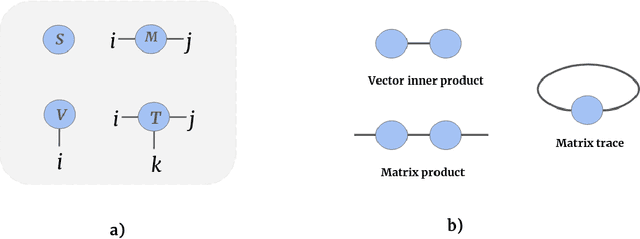
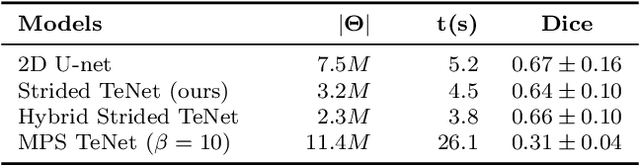
Tensor networks are efficient factorisations of high dimensional tensors into a network of lower order tensors. They have been most commonly used to model entanglement in quantum many-body systems and more recently are witnessing increased applications in supervised machine learning. In this work, we formulate image segmentation in a supervised setting with tensor networks. The key idea is to first lift the pixels in image patches to exponentially high dimensional feature spaces and using a linear decision hyper-plane to classify the input pixels into foreground and background classes. The high dimensional linear model itself is approximated using the matrix product state (MPS) tensor network. The MPS is weight-shared between the non-overlapping image patches resulting in our strided tensor network model. The performance of the proposed model is evaluated on three 2D- and one 3D- biomedical imaging datasets. The performance of the proposed tensor network segmentation model is compared with relevant baseline methods. In the 2D experiments, the tensor network model yeilds competitive performance compared to the baseline methods while being more resource efficient.
Splicing Detection and Localization In Satellite Imagery Using Conditional GANs
May 03, 2022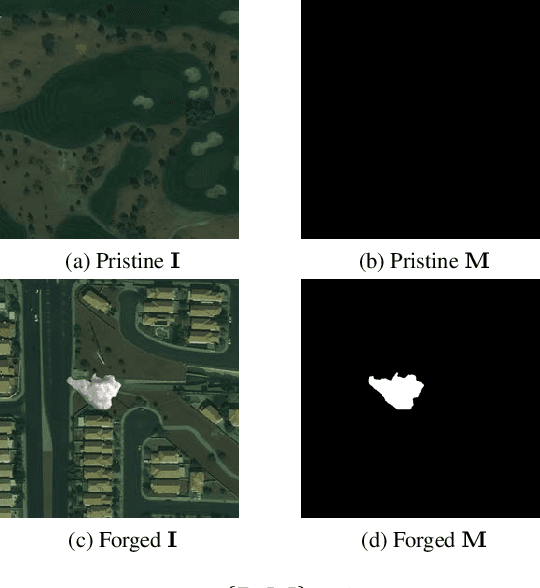
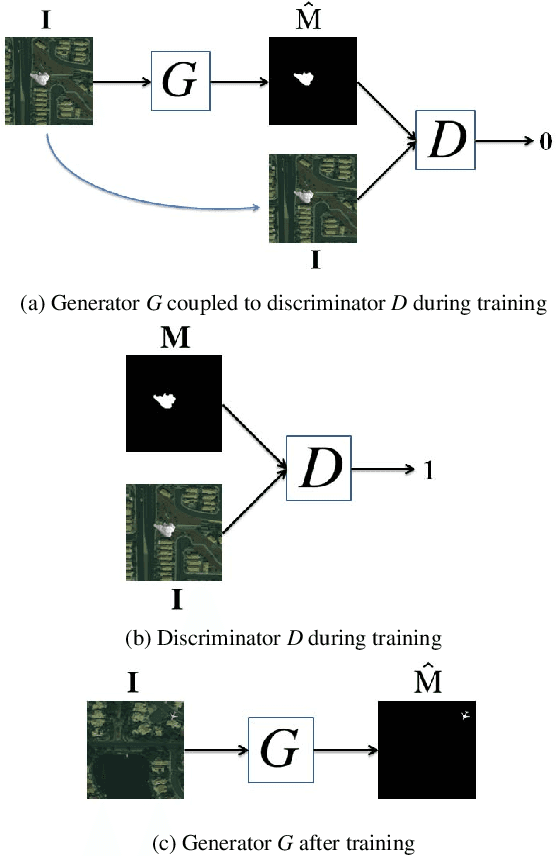

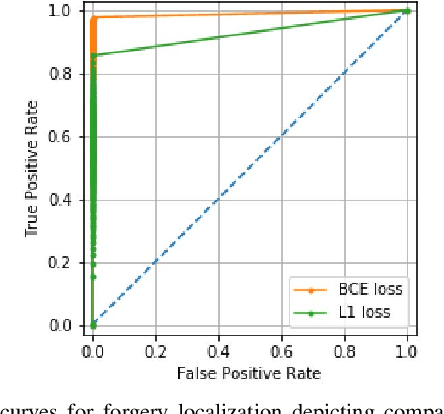
The widespread availability of image editing tools and improvements in image processing techniques allow image manipulation to be very easy. Oftentimes, easy-to-use yet sophisticated image manipulation tools yields distortions/changes imperceptible to the human observer. Distribution of forged images can have drastic ramifications, especially when coupled with the speed and vastness of the Internet. Therefore, verifying image integrity poses an immense and important challenge to the digital forensic community. Satellite images specifically can be modified in a number of ways, including the insertion of objects to hide existing scenes and structures. In this paper, we describe the use of a Conditional Generative Adversarial Network (cGAN) to identify the presence of such spliced forgeries within satellite images. Additionally, we identify their locations and shapes. Trained on pristine and falsified images, our method achieves high success on these detection and localization objectives.
* Accepted to the 2019 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR)
Progressive Scene Text Erasing with Self-Supervision
Jul 23, 2022


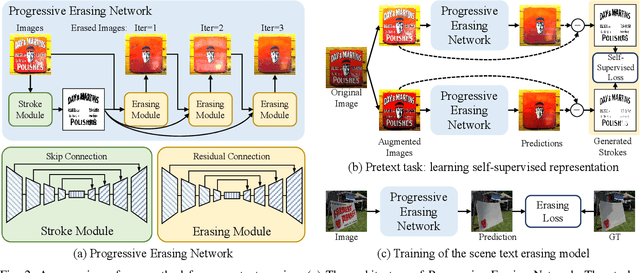
Scene text erasing seeks to erase text contents from scene images and current state-of-the-art text erasing models are trained on large-scale synthetic data. Although data synthetic engines can provide vast amounts of annotated training samples, there are differences between synthetic and real-world data. In this paper, we employ self-supervision for feature representation on unlabeled real-world scene text images. A novel pretext task is designed to keep consistent among text stroke masks of image variants. We design the Progressive Erasing Network in order to remove residual texts. The scene text is erased progressively by leveraging the intermediate generated results which provide the foundation for subsequent higher quality results. Experiments show that our method significantly improves the generalization of the text erasing task and achieves state-of-the-art performance on public benchmarks.