 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Enforcing connectivity of 3D linear structures using their 2D projections
Jul 14, 2022
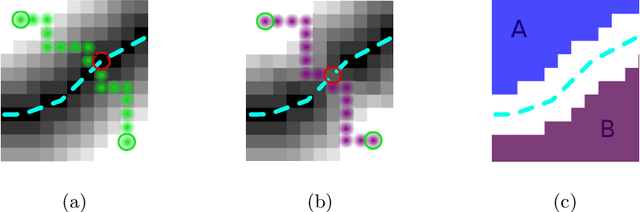
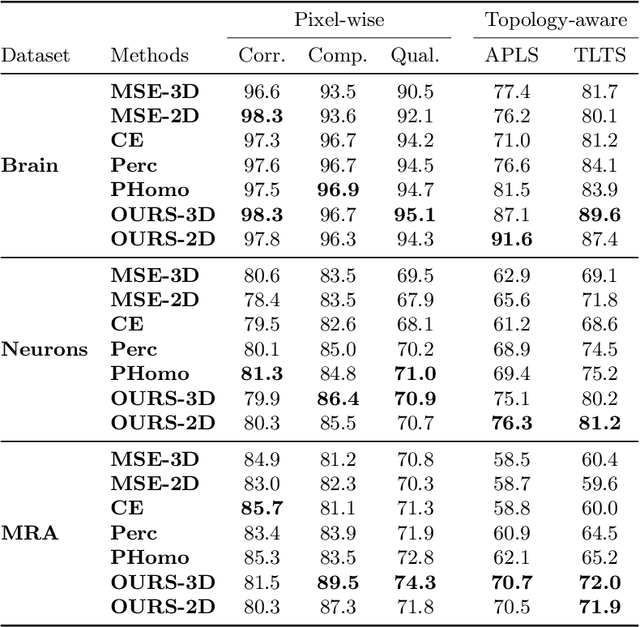
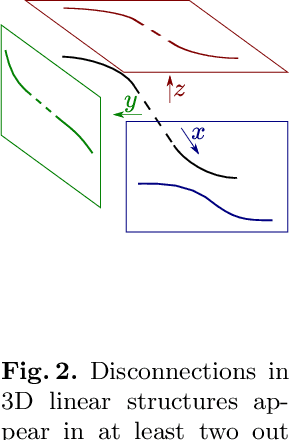
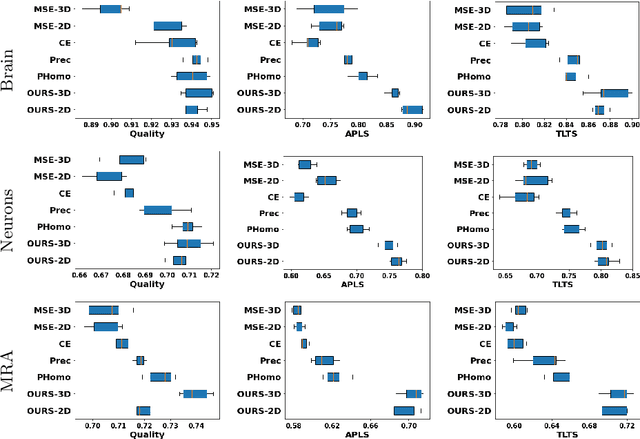
Many biological and medical tasks require the delineation of 3D curvilinear structures such as blood vessels and neurites from image volumes. This is typically done using neural networks trained by minimizing voxel-wise loss functions that do not capture the topological properties of these structures. As a result, the connectivity of the recovered structures is often wrong, which lessens their usefulness. In this paper, we propose to improve the 3D connectivity of our results by minimizing a sum of topology-aware losses on their 2D projections. This suffices to increase the accuracy and to reduce the annotation effort required to provide the required annotated training data.
Cascade Decoders-Based Autoencoders for Image Reconstruction
Jun 29, 2021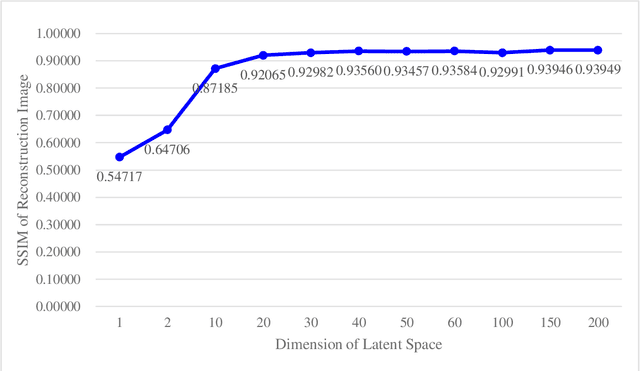
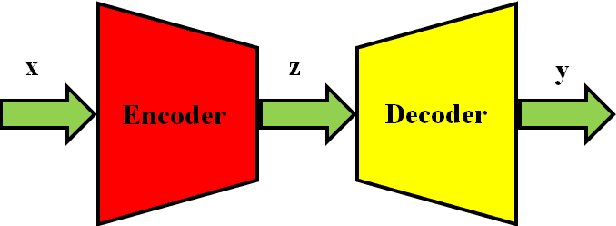
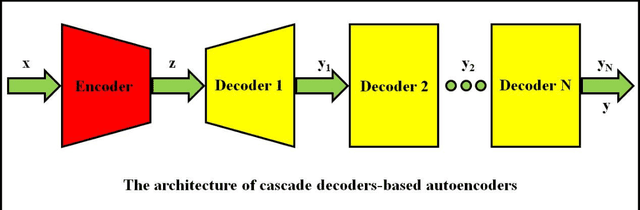
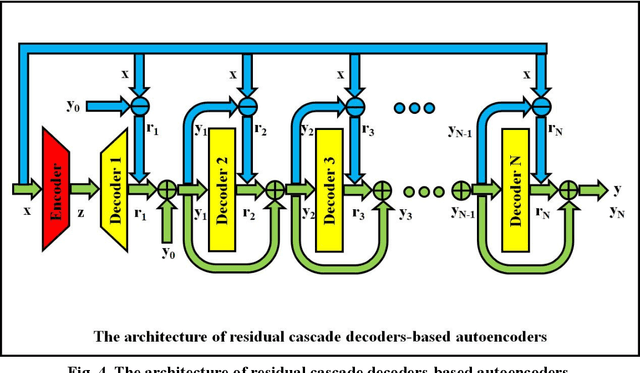
Autoencoders are composed of coding and decoding units, hence they hold the inherent potential of high-performance data compression and signal compressed sensing. The main disadvantages of current autoencoders comprise the following several aspects: the research objective is not data reconstruction but feature representation; the performance evaluation of data recovery is neglected; it is hard to achieve lossless data reconstruction by pure autoencoders, even by pure deep learning. This paper aims for image reconstruction of autoencoders, employs cascade decoders-based autoencoders, perfects the performance of image reconstruction, approaches gradually lossless image recovery, and provides solid theory and application basis for autoencoders-based image compression and compressed sensing. The proposed serial decoders-based autoencoders include the architectures of multi-level decoders and the related optimization algorithms. The cascade decoders consist of general decoders, residual decoders, adversarial decoders and their combinations. It is evaluated by the experimental results that the proposed autoencoders outperform the classical autoencoders in the performance of image reconstruction.
Depth Field Networks for Generalizable Multi-view Scene Representation
Jul 28, 2022
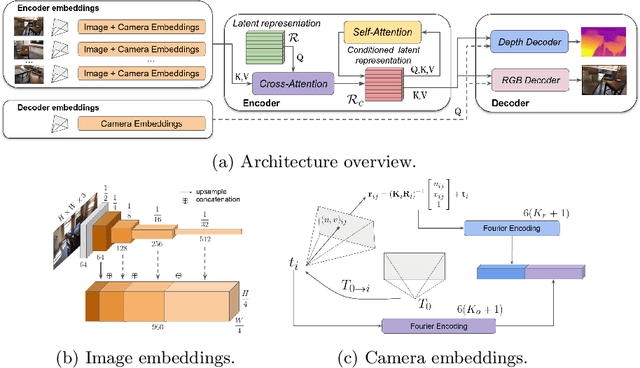

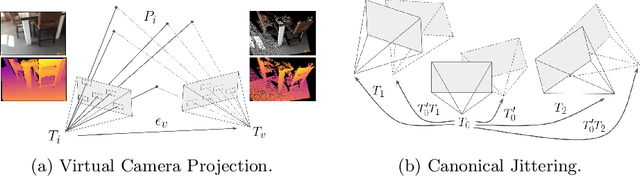
Modern 3D computer vision leverages learning to boost geometric reasoning, mapping image data to classical structures such as cost volumes or epipolar constraints to improve matching. These architectures are specialized according to the particular problem, and thus require significant task-specific tuning, often leading to poor domain generalization performance. Recently, generalist Transformer architectures have achieved impressive results in tasks such as optical flow and depth estimation by encoding geometric priors as inputs rather than as enforced constraints. In this paper, we extend this idea and propose to learn an implicit, multi-view consistent scene representation, introducing a series of 3D data augmentation techniques as a geometric inductive prior to increase view diversity. We also show that introducing view synthesis as an auxiliary task further improves depth estimation. Our Depth Field Networks (DeFiNe) achieve state-of-the-art results in stereo and video depth estimation without explicit geometric constraints, and improve on zero-shot domain generalization by a wide margin.
Automatically Discovering Novel Visual Categories with Self-supervised Prototype Learning
Aug 01, 2022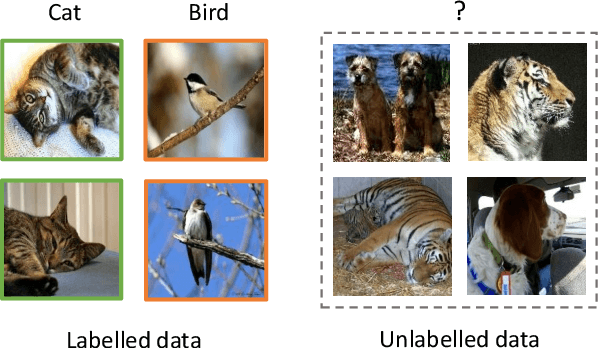
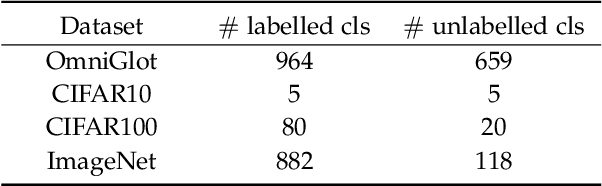
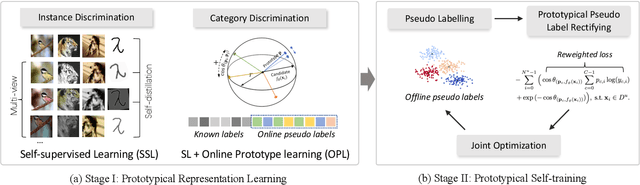
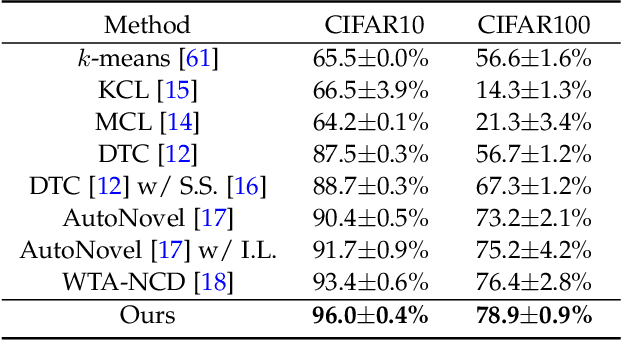
This paper tackles the problem of novel category discovery (NCD), which aims to discriminate unknown categories in large-scale image collections. The NCD task is challenging due to the closeness to the real-world scenarios, where we have only encountered some partial classes and images. Unlike other works on the NCD, we leverage the prototypes to emphasize the importance of category discrimination and alleviate the issue of missing annotations of novel classes. Concretely, we propose a novel adaptive prototype learning method consisting of two main stages: prototypical representation learning and prototypical self-training. In the first stage, we obtain a robust feature extractor, which could serve for all images with base and novel categories. This ability of instance and category discrimination of the feature extractor is boosted by self-supervised learning and adaptive prototypes. In the second stage, we utilize the prototypes again to rectify offline pseudo labels and train a final parametric classifier for category clustering. We conduct extensive experiments on four benchmark datasets and demonstrate the effectiveness and robustness of the proposed method with state-of-the-art performance.
Fast Two-step Blind Optical Aberration Correction
Aug 01, 2022

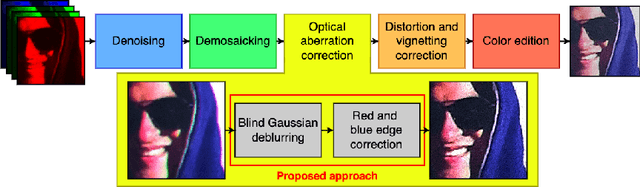

The optics of any camera degrades the sharpness of photographs, which is a key visual quality criterion. This degradation is characterized by the point-spread function (PSF), which depends on the wavelengths of light and is variable across the imaging field. In this paper, we propose a two-step scheme to correct optical aberrations in a single raw or JPEG image, i.e., without any prior information on the camera or lens. First, we estimate local Gaussian blur kernels for overlapping patches and sharpen them with a non-blind deblurring technique. Based on the measurements of the PSFs of dozens of lenses, these blur kernels are modeled as RGB Gaussians defined by seven parameters. Second, we remove the remaining lateral chromatic aberrations (not contemplated in the first step) with a convolutional neural network, trained to minimize the red/green and blue/green residual images. Experiments on both synthetic and real images show that the combination of these two stages yields a fast state-of-the-art blind optical aberration compensation technique that competes with commercial non-blind algorithms.
Transformers as Meta-Learners for Implicit Neural Representations
Aug 05, 2022



Implicit Neural Representations (INRs) have emerged and shown their benefits over discrete representations in recent years. However, fitting an INR to the given observations usually requires optimization with gradient descent from scratch, which is inefficient and does not generalize well with sparse observations. To address this problem, most of the prior works train a hypernetwork that generates a single vector to modulate the INR weights, where the single vector becomes an information bottleneck that limits the reconstruction precision of the output INR. Recent work shows that the whole set of weights in INR can be precisely inferred without the single-vector bottleneck by gradient-based meta-learning. Motivated by a generalized formulation of gradient-based meta-learning, we propose a formulation that uses Transformers as hypernetworks for INRs, where it can directly build the whole set of INR weights with Transformers specialized as set-to-set mapping. We demonstrate the effectiveness of our method for building INRs in different tasks and domains, including 2D image regression and view synthesis for 3D objects. Our work draws connections between the Transformer hypernetworks and gradient-based meta-learning algorithms and we provide further analysis for understanding the generated INRs.
Revisiting lp-constrained Softmax Loss: A Comprehensive Study
Jun 20, 2022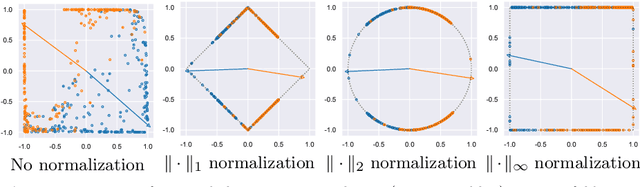
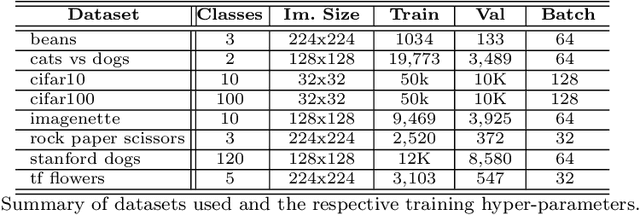

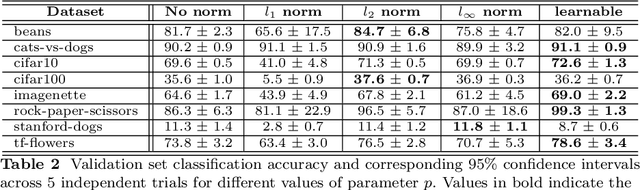
Normalization is a vital process for any machine learning task as it controls the properties of data and affects model performance at large. The impact of particular forms of normalization, however, has so far been investigated in limited domain-specific classification tasks and not in a general fashion. Motivated by the lack of such a comprehensive study, in this paper we investigate the performance of lp-constrained softmax loss classifiers across different norm orders, magnitudes, and data dimensions in both proof-of-concept classification problems and real-world popular image classification tasks. Experimental results suggest collectively that lp-constrained softmax loss classifiers not only can achieve more accurate classification results but, at the same time, appear to be less prone to overfitting. The core findings hold across the three popular deep learning architectures tested and eight datasets examined, and suggest that lp normalization is a recommended data representation practice for image classification in terms of performance and convergence, and against overfitting.
Implicit Channel Learning for Machine Learning Applications in 6G Wireless Networks
Jun 24, 2022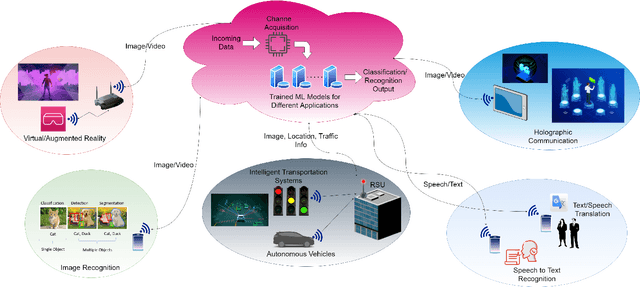
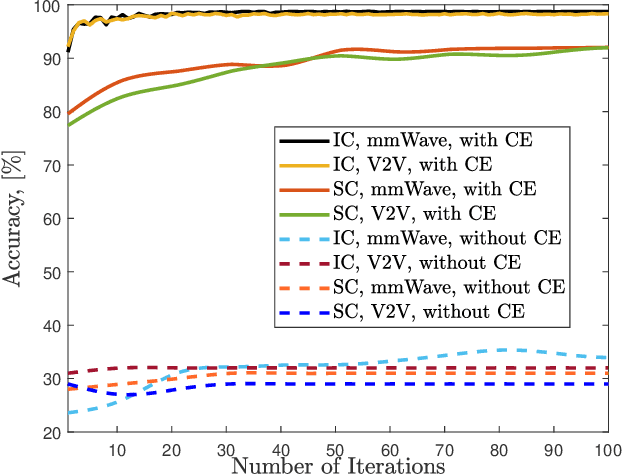
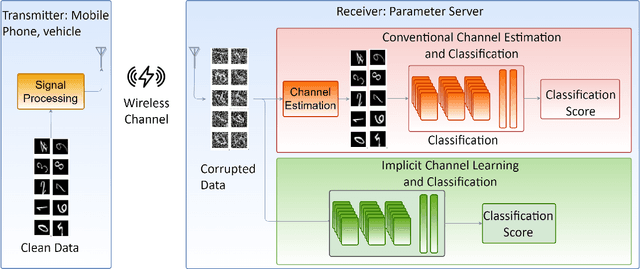
With the deployment of the fifth generation (5G) wireless systems gathering momentum across the world, possible technologies for 6G are under active research discussions. In particular, the role of machine learning (ML) in 6G is expected to enhance and aid emerging applications such as virtual and augmented reality, vehicular autonomy, and computer vision. This will result in large segments of wireless data traffic comprising image, video and speech. The ML algorithms process these for classification/recognition/estimation through the learning models located on cloud servers. This requires wireless transmission of data from edge devices to the cloud server. Channel estimation, handled separately from recognition step, is critical for accurate learning performance. Toward combining the learning for both channel and the ML data, we introduce implicit channel learning to perform the ML tasks without estimating the wireless channel. Here, the ML models are trained with channel-corrupted datasets in place of nominal data. Without channel estimation, the proposed approach exhibits approximately 60% improvement in image and speech classification tasks for diverse scenarios such as millimeter wave and IEEE 802.11p vehicular channels.
Computer vision-based analysis of buildings and built environments: A systematic review of current approaches
Aug 01, 2022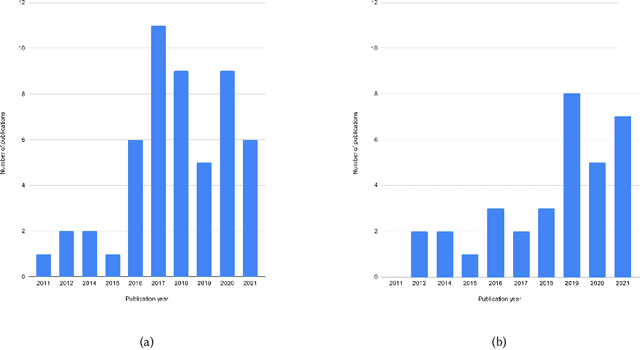
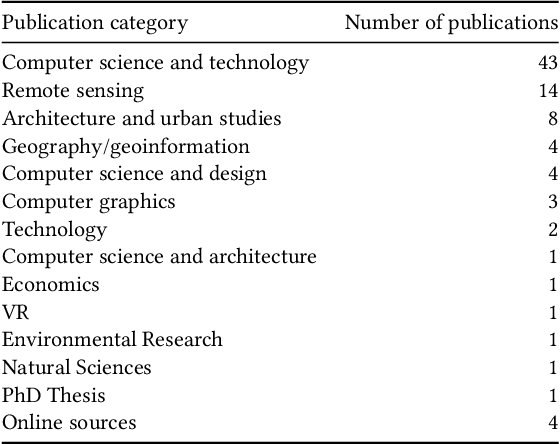
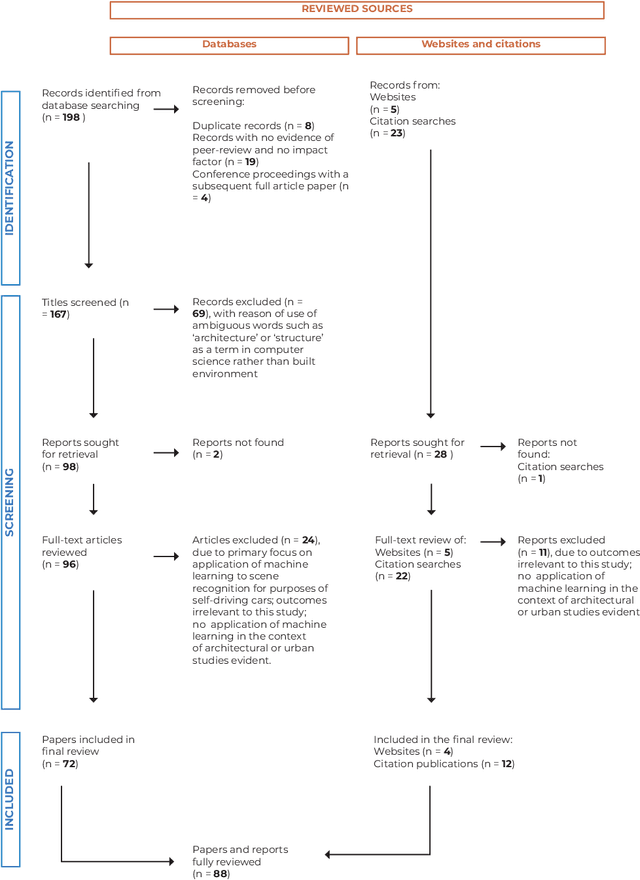
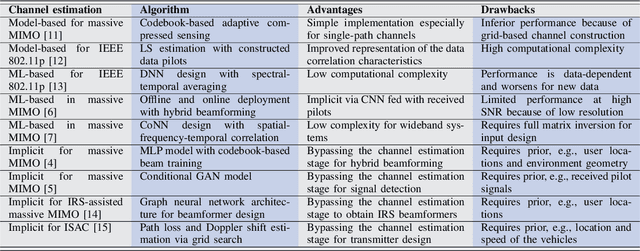
Analysing 88 sources published from 2011 to 2021, this paper presents a first systematic review of the computer vision-based analysis of buildings and the built environments to assess its value to architectural and urban design studies. Following a multi-stage selection process, the types of algorithms and data sources used are discussed in respect to architectural applications such as a building classification, detail classification, qualitative environmental analysis, building condition survey, and building value estimation. This reveals current research gaps and trends, and highlights two main categories of research aims. First, to use or optimise computer vision methods for architectural image data, which can then help automate time-consuming, labour-intensive, or complex tasks of visual analysis. Second, to explore the methodological benefits of machine learning approaches to investigate new questions about the built environment by finding patterns and relationships between visual, statistical, and qualitative data, which can overcome limitations of conventional manual analysis. The growing body of research offers new methods to architectural and design studies, with the paper identifying future challenges and directions of research.
Fingerprint Liveness Detection Based on Quality Measures
Jul 11, 2022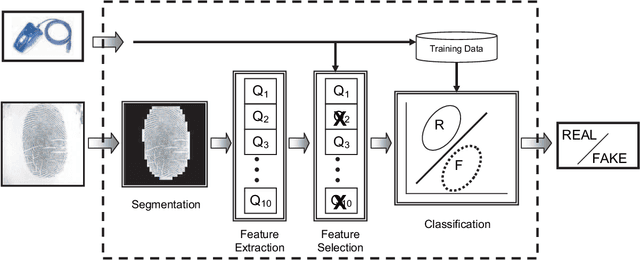
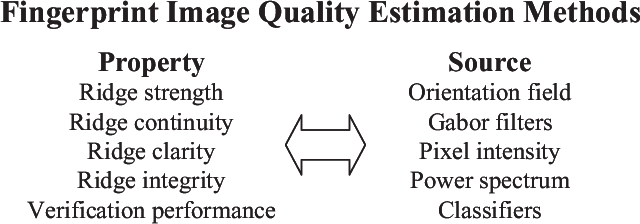

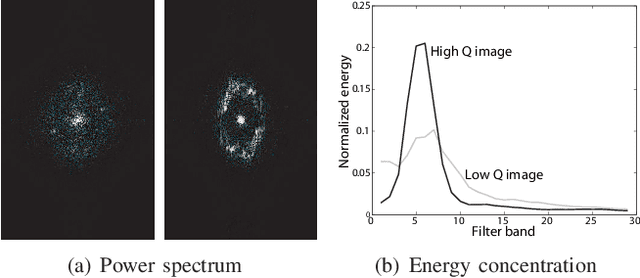
A new fingerprint parameterization for liveness detection based on quality measures is presented. The novel feature set is used in a complete liveness detection system and tested on the development set of the LivDET competition, comprising over 4,500 real and fake images acquired with three different optical sensors. The proposed solution proves to be robust to the multi-sensor scenario, and presents an overall rate of 93% of correctly classified samples. Furthermore, the liveness detection method presented has the added advantage over previously studied techniques of needing just one image from a finger to decide whether it is real or fake.