 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Weighted Concordance Index Loss-based Multimodal Survival Modeling for Radiation Encephalopathy Assessment in Nasopharyngeal Carcinoma Radiotherapy
Jun 23, 2022
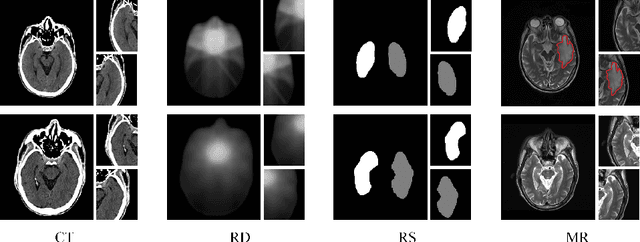
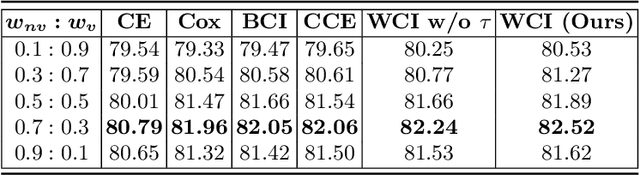
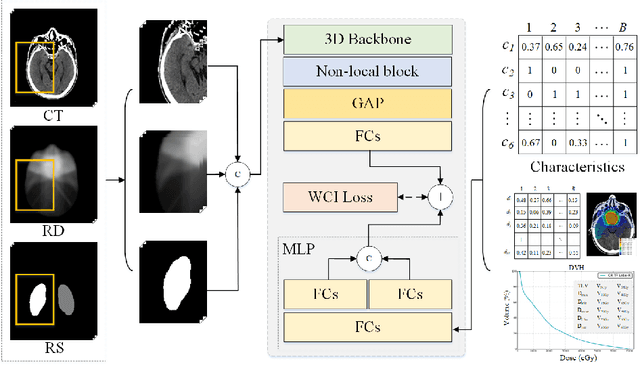
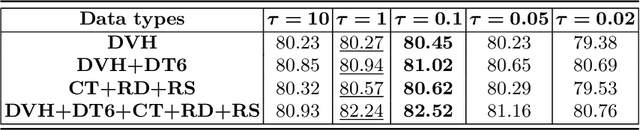
Radiation encephalopathy (REP) is the most common complication for nasopharyngeal carcinoma (NPC) radiotherapy. It is highly desirable to assist clinicians in optimizing the NPC radiotherapy regimen to reduce radiotherapy-induced temporal lobe injury (RTLI) according to the probability of REP onset. To the best of our knowledge, it is the first exploration of predicting radiotherapy-induced REP by jointly exploiting image and non-image data in NPC radiotherapy regimen. We cast REP prediction as a survival analysis task and evaluate the predictive accuracy in terms of the concordance index (CI). We design a deep multimodal survival network (MSN) with two feature extractors to learn discriminative features from multimodal data. One feature extractor imposes feature selection on non-image data, and the other learns visual features from images. Because the priorly balanced CI (BCI) loss function directly maximizing the CI is sensitive to uneven sampling per batch. Hence, we propose a novel weighted CI (WCI) loss function to leverage all REP samples effectively by assigning their different weights with a dual average operation. We further introduce a temperature hyper-parameter for our WCI to sharpen the risk difference of sample pairs to help model convergence. We extensively evaluate our WCI on a private dataset to demonstrate its favourability against its counterparts. The experimental results also show multimodal data of NPC radiotherapy can bring more gains for REP risk prediction.
Fast-Vid2Vid: Spatial-Temporal Compression for Video-to-Video Synthesis
Jul 11, 2022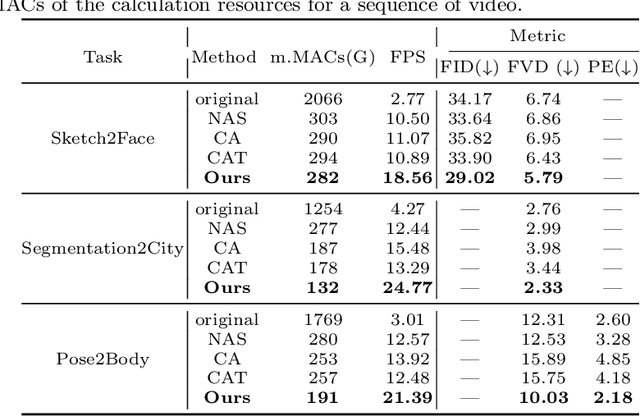
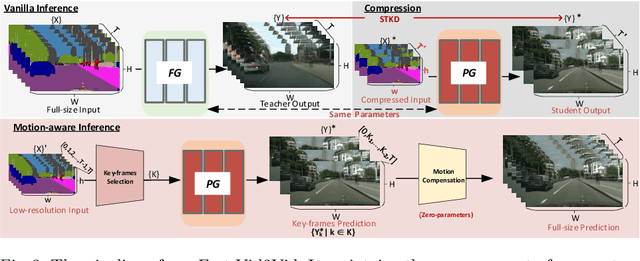
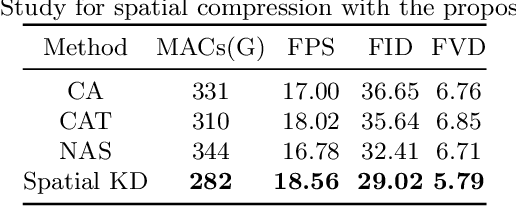
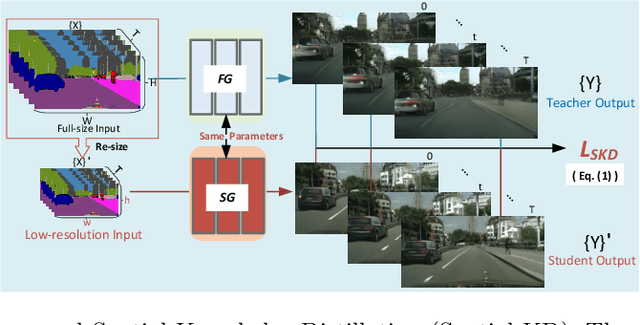
Video-to-Video synthesis (Vid2Vid) has achieved remarkable results in generating a photo-realistic video from a sequence of semantic maps. However, this pipeline suffers from high computational cost and long inference latency, which largely depends on two essential factors: 1) network architecture parameters, 2) sequential data stream. Recently, the parameters of image-based generative models have been significantly compressed via more efficient network architectures. Nevertheless, existing methods mainly focus on slimming network architectures and ignore the size of the sequential data stream. Moreover, due to the lack of temporal coherence, image-based compression is not sufficient for the compression of the video task. In this paper, we present a spatial-temporal compression framework, \textbf{Fast-Vid2Vid}, which focuses on data aspects of generative models. It makes the first attempt at time dimension to reduce computational resources and accelerate inference. Specifically, we compress the input data stream spatially and reduce the temporal redundancy. After the proposed spatial-temporal knowledge distillation, our model can synthesize key-frames using the low-resolution data stream. Finally, Fast-Vid2Vid interpolates intermediate frames by motion compensation with slight latency. On standard benchmarks, Fast-Vid2Vid achieves around real-time performance as 20 FPS and saves around 8x computational cost on a single V100 GPU.
Symbolic Replay: Scene Graph as Prompt for Continual Learning on VQA Task
Aug 29, 2022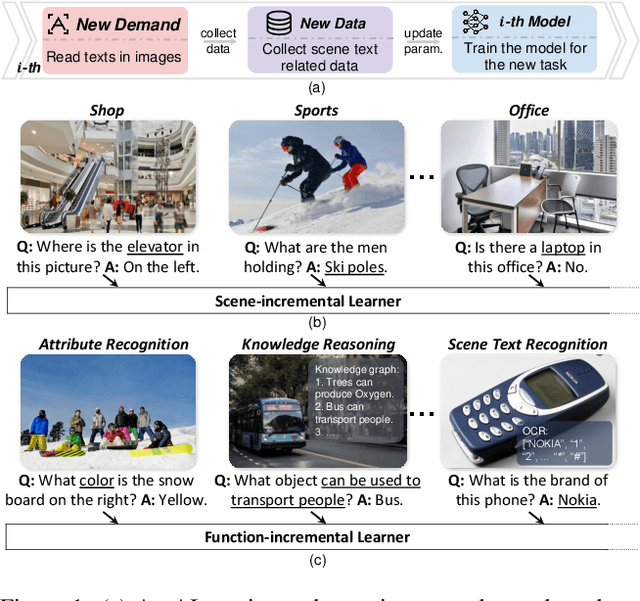
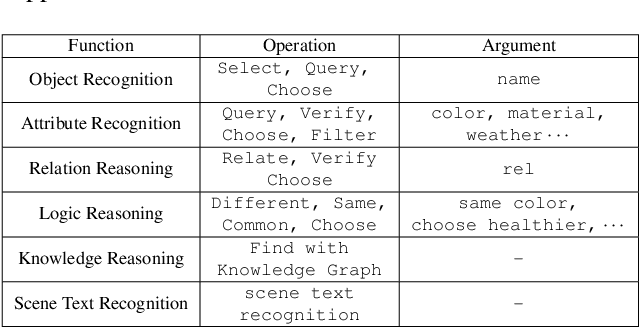
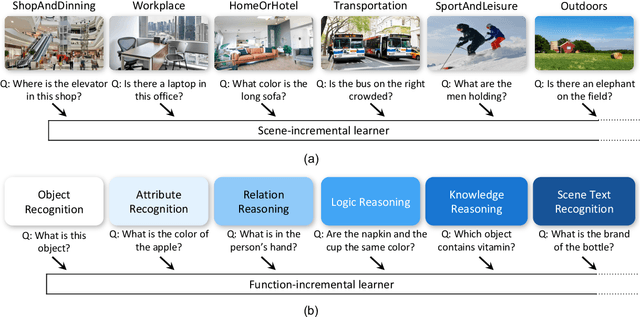
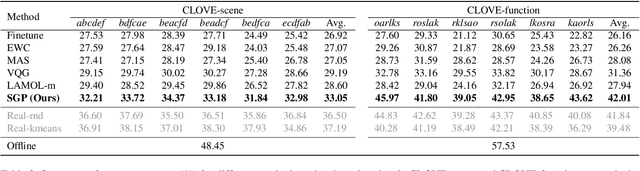
VQA is an ambitious task aiming to answer any image-related question. However, in reality, it is hard to build such a system once for all since the needs of users are continuously updated, and the system has to implement new functions. Thus, Continual Learning (CL) ability is a must in developing advanced VQA systems. Recently, a pioneer work split a VQA dataset into disjoint answer sets to study this topic. However, CL on VQA involves not only the expansion of label sets (new Answer sets). It is crucial to study how to answer questions when deploying VQA systems to new environments (new Visual scenes) and how to answer questions requiring new functions (new Question types). Thus, we propose CLOVE, a benchmark for Continual Learning On Visual quEstion answering, which contains scene- and function-incremental settings for the two aforementioned CL scenarios. In terms of methodology, the main difference between CL on VQA and classification is that the former additionally involves expanding and preventing forgetting of reasoning mechanisms, while the latter focusing on class representation. Thus, we propose a real-data-free replay-based method tailored for CL on VQA, named Scene Graph as Prompt for Symbolic Replay. Using a piece of scene graph as a prompt, it replays pseudo scene graphs to represent the past images, along with correlated QA pairs. A unified VQA model is also proposed to utilize the current and replayed data to enhance its QA ability. Finally, experimental results reveal challenges in CLOVE and demonstrate the effectiveness of our method. The dataset and code will be available at https://github.com/showlab/CLVQA.
Is Image-to-Image Translation the Panacea for Multimodal Image Registration? A Comparative Study
Mar 30, 2021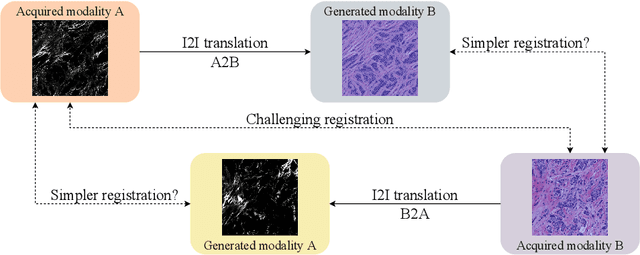
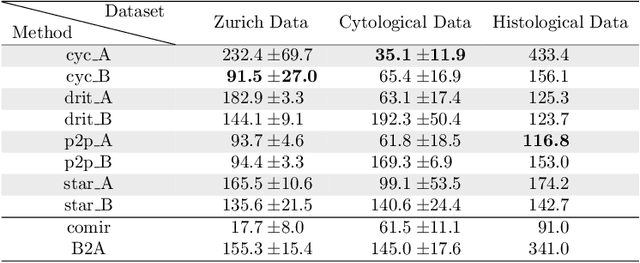

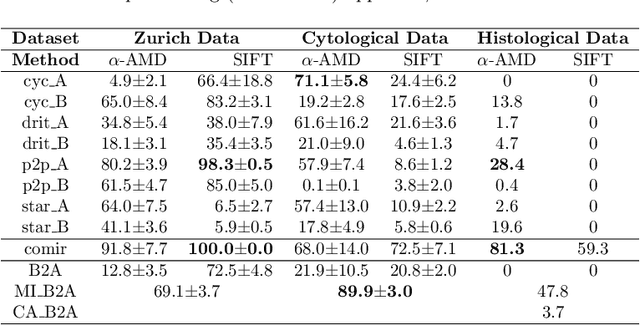
Despite current advancement in the field of biomedical image processing, propelled by the deep learning revolution, multimodal image registration, due to its several challenges, is still often performed manually by specialists. The recent success of image-to-image (I2I) translation in computer vision applications and its growing use in biomedical areas provide a tempting possibility of transforming the multimodal registration problem into a, potentially easier, monomodal one. We conduct an empirical study of the applicability of modern I2I translation methods for the task of multimodal biomedical image registration. We compare the performance of four Generative Adversarial Network (GAN)-based methods and one contrastive representation learning method, subsequently combined with two representative monomodal registration methods, to judge the effectiveness of modality translation for multimodal image registration. We evaluate these method combinations on three publicly available multimodal datasets of increasing difficulty, and compare with the performance of registration by Mutual Information maximisation and one modern data-specific multimodal registration method. Our results suggest that, although I2I translation may be helpful when the modalities to register are clearly correlated, registration of modalities which express distinctly different properties of the sample are not well handled by the I2I translation approach. When less information is shared between the modalities, the I2I translation methods struggle to provide good predictions, which impairs the registration performance. The evaluated representation learning method, which aims to find an in-between representation, manages better, and so does the Mutual Information maximisation approach. We share our complete experimental setup as open-source (https://github.com/Noodles-321/Registration).
VQA-GNN: Reasoning with Multimodal Semantic Graph for Visual Question Answering
May 23, 2022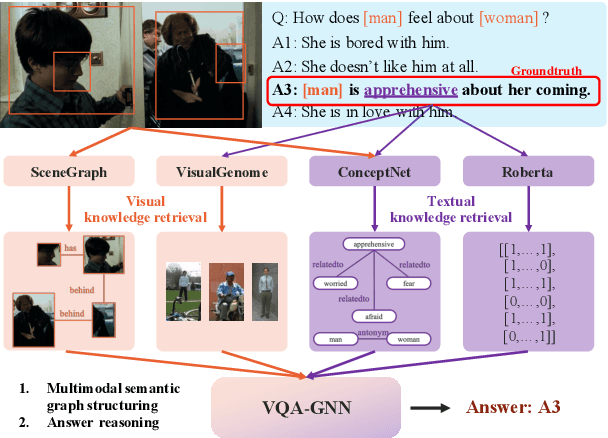
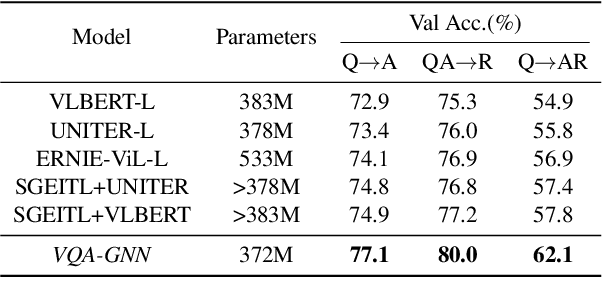
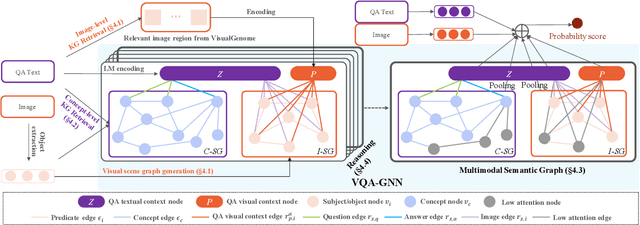

Visual understanding requires seamless integration between recognition and reasoning: beyond image-level recognition (e.g., detecting objects), systems must perform concept-level reasoning (e.g., inferring the context of objects and intents of people). However, existing methods only model the image-level features, and do not ground them and reason with background concepts such as knowledge graphs (KGs). In this work, we propose a novel visual question answering method, VQA-GNN, which unifies the image-level information and conceptual knowledge to perform joint reasoning of the scene. Specifically, given a question-image pair, we build a scene graph from the image, retrieve a relevant linguistic subgraph from ConceptNet and visual subgraph from VisualGenome, and unify these three graphs and the question into one joint graph, multimodal semantic graph. Our VQA-GNN then learns to aggregate messages and reason across different modalities captured by the multimodal semantic graph. In the evaluation on the VCR task, our method outperforms the previous scene graph-based Trans-VL models by over 4%, and VQA-GNN-Large, our model that fuses a Trans-VL further improves the state of the art by 2%, attaining the top of the VCR leaderboard at the time of submission. This result suggests the efficacy of our model in performing conceptual reasoning beyond image-level recognition for visual understanding. Finally, we demonstrate that our model is the first work to provide interpretability across visual and textual knowledge domains for the VQA task.
WeightMom: Learning Sparse Networks using Iterative Momentum-based pruning
Aug 11, 2022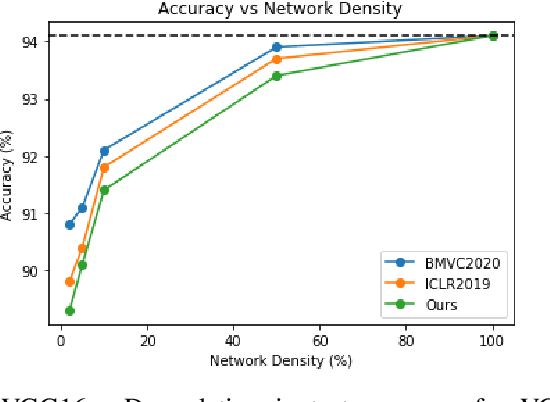
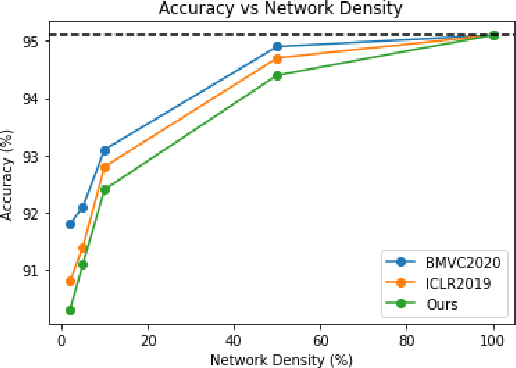
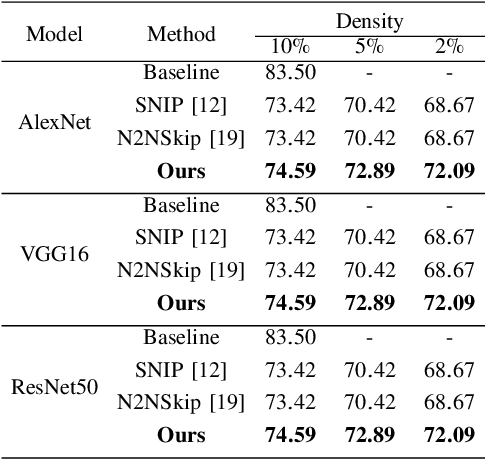
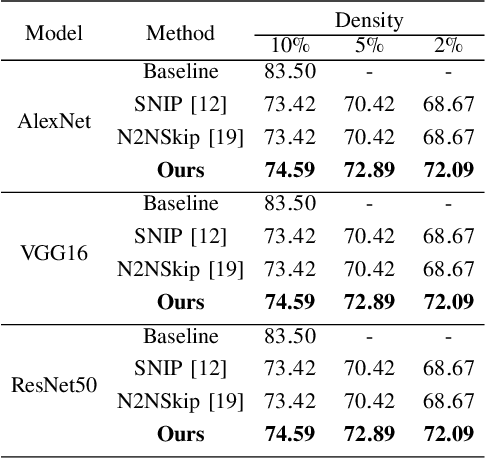
Deep Neural Networks have been used in a wide variety of applications with significant success. However, their highly complex nature owing to comprising millions of parameters has lead to problems during deployment in pipelines with low latency requirements. As a result, it is more desirable to obtain lightweight neural networks which have the same performance during inference time. In this work, we propose a weight based pruning approach in which the weights are pruned gradually based on their momentum of the previous iterations. Each layer of the neural network is assigned an importance value based on their relative sparsity, followed by the magnitude of the weight in the previous iterations. We evaluate our approach on networks such as AlexNet, VGG16 and ResNet50 with image classification datasets such as CIFAR-10 and CIFAR-100. We found that the results outperformed the previous approaches with respect to accuracy and compression ratio. Our method is able to obtain a compression of 15% for the same degradation in accuracy on both the datasets.
QU-net++: Image Quality Detection Framework for Segmentation of 3D Medical Image Stacks
Oct 27, 2021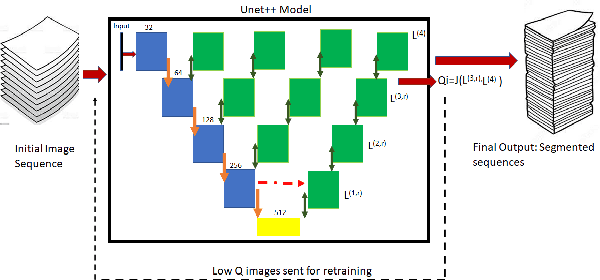
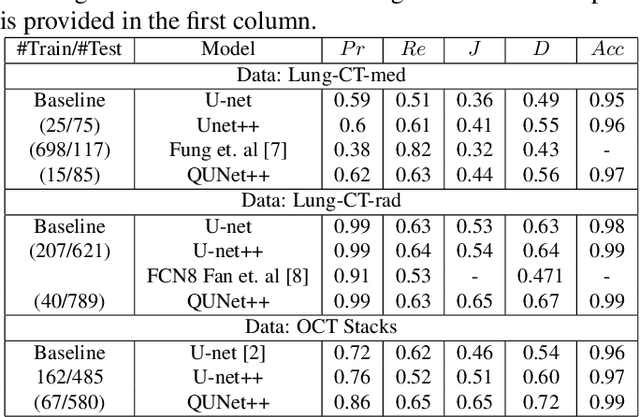
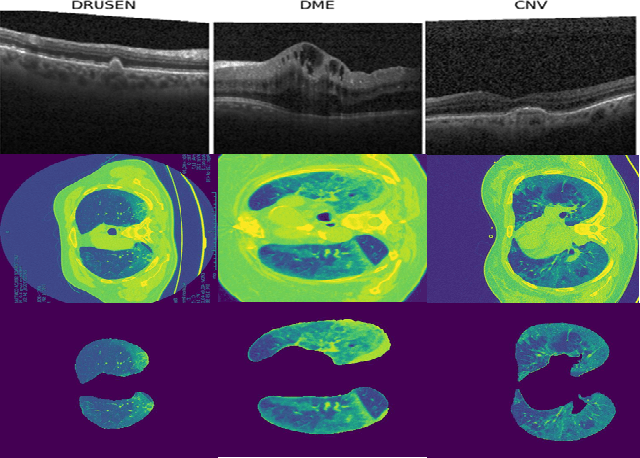
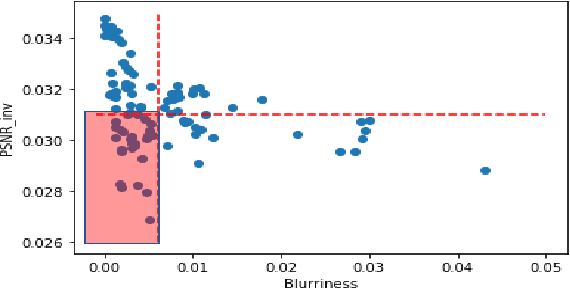
Automated segmentation of pathological regions of interest has been shown to aid prognosis and follow up treatment. However, accurate pathological segmentations require high quality of annotated data that can be both cost and time intensive to generate. In this work, we propose an automated two-step method that evaluates the quality of medical images from 3D image stacks using a U-net++ model, such that images that can aid further training of the U-net++ model can be detected based on the disagreement in segmentations produced from the final two layers. Images thus detected can then be used to further fine tune the U-net++ model for semantic segmentation. The proposed QU-net++ model isolates around 10\% of images per 3D stack and can scale across imaging modalities to segment cysts in OCT images and ground glass opacity in Lung CT images with Dice cores in the range 0.56-0.72. Thus, the proposed method can be applied for multi-modal binary segmentation of pathology.
Unifying Visual Perception by Dispersible Points Learning
Aug 18, 2022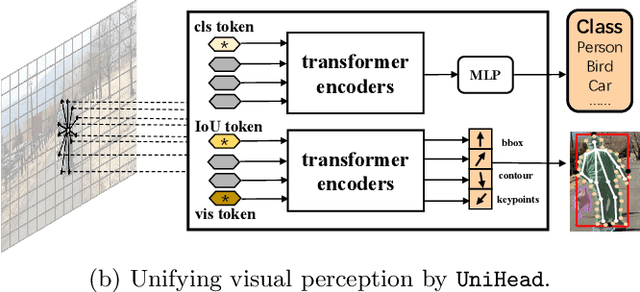
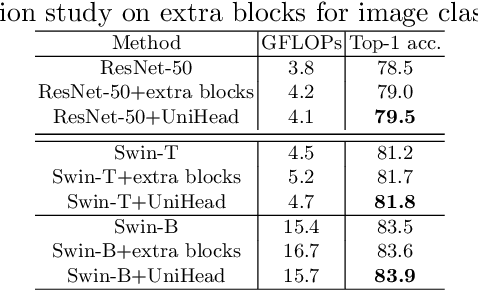
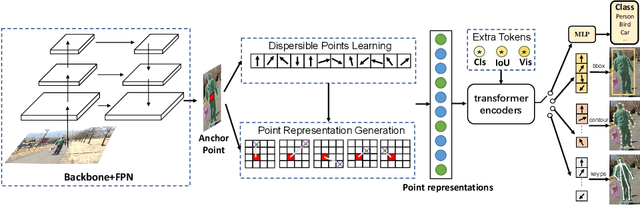
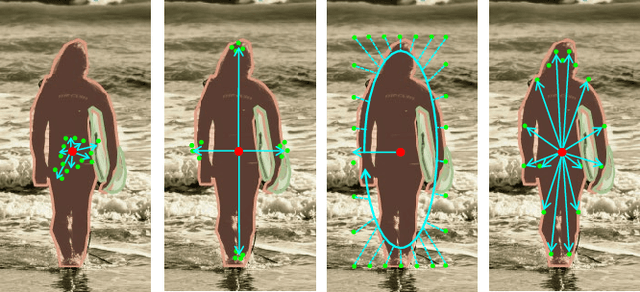
We present a conceptually simple, flexible, and universal visual perception head for variant visual tasks, e.g., classification, object detection, instance segmentation and pose estimation, and different frameworks, such as one-stage or two-stage pipelines. Our approach effectively identifies an object in an image while simultaneously generating a high-quality bounding box or contour-based segmentation mask or set of keypoints. The method, called UniHead, views different visual perception tasks as the dispersible points learning via the transformer encoder architecture. Given a fixed spatial coordinate, UniHead adaptively scatters it to different spatial points and reasons about their relations by transformer encoder. It directly outputs the final set of predictions in the form of multiple points, allowing us to perform different visual tasks in different frameworks with the same head design. We show extensive evaluations on ImageNet classification and all three tracks of the COCO suite of challenges, including object detection, instance segmentation and pose estimation. Without bells and whistles, UniHead can unify these visual tasks via a single visual head design and achieve comparable performance compared to expert models developed for each task.We hope our simple and universal UniHead will serve as a solid baseline and help promote universal visual perception research. Code and models are available at https://github.com/Sense-X/UniHead.
Diverse Generative Adversarial Perturbations on Attention Space for Transferable Adversarial Attacks
Aug 11, 2022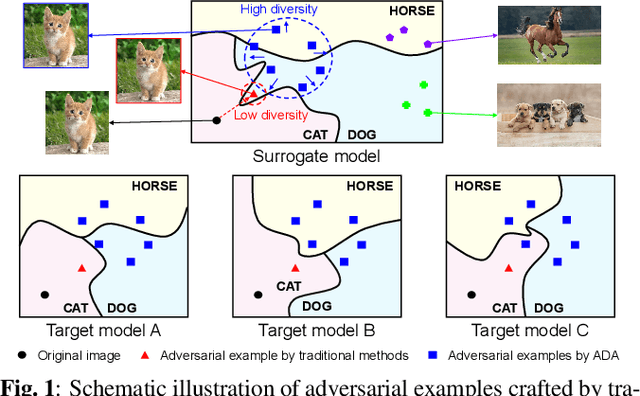
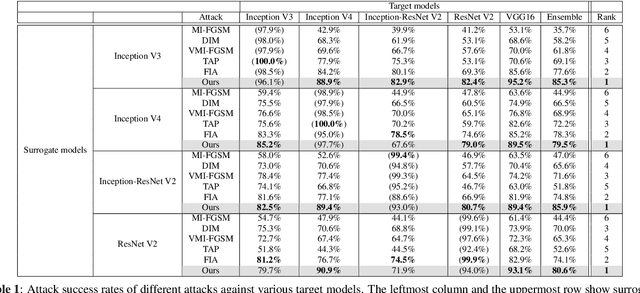
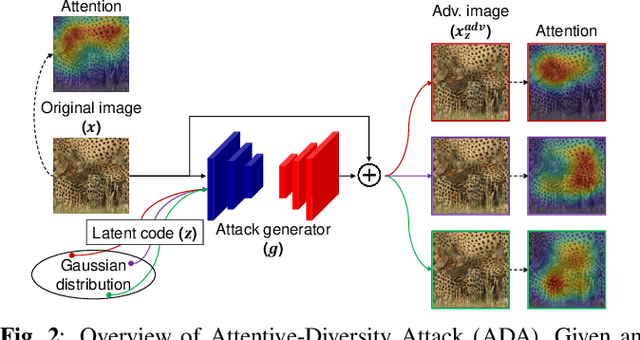
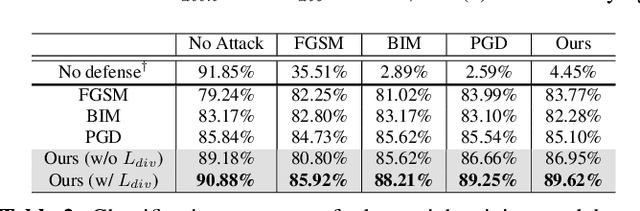
Adversarial attacks with improved transferability - the ability of an adversarial example crafted on a known model to also fool unknown models - have recently received much attention due to their practicality. Nevertheless, existing transferable attacks craft perturbations in a deterministic manner and often fail to fully explore the loss surface, thus falling into a poor local optimum and suffering from low transferability. To solve this problem, we propose Attentive-Diversity Attack (ADA), which disrupts diverse salient features in a stochastic manner to improve transferability. Primarily, we perturb the image attention to disrupt universal features shared by different models. Then, to effectively avoid poor local optima, we disrupt these features in a stochastic manner and explore the search space of transferable perturbations more exhaustively. More specifically, we use a generator to produce adversarial perturbations that each disturbs features in different ways depending on an input latent code. Extensive experimental evaluations demonstrate the effectiveness of our method, outperforming the transferability of state-of-the-art methods. Codes are available at https://github.com/wkim97/ADA.
Multimodal Knowledge Alignment with Reinforcement Learning
May 25, 2022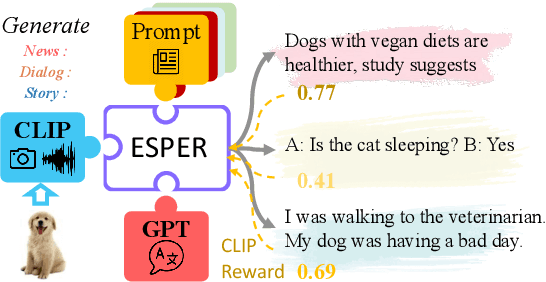
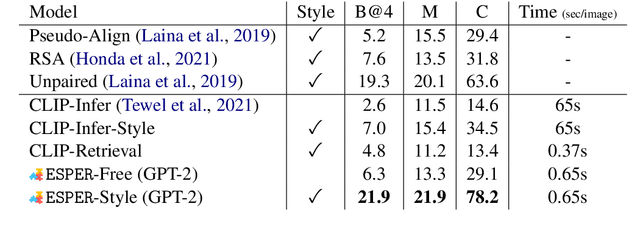
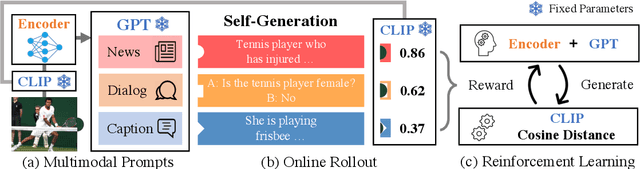
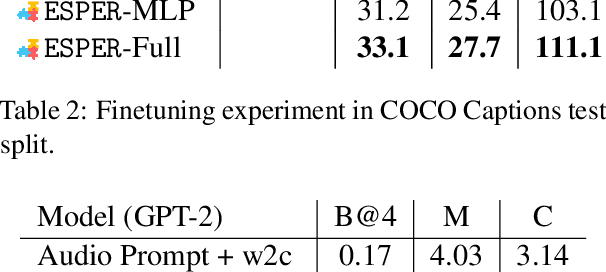
Large language models readily adapt to novel settings, even without task-specific training data. Can their zero-shot capacity be extended to multimodal inputs? In this work, we propose ESPER which extends language-only zero-shot models to unseen multimodal tasks, like image and audio captioning. Our key novelty is to use reinforcement learning to align multimodal inputs to language model generations without direct supervision: for example, in the image case our reward optimization relies only on cosine similarity derived from CLIP, and thus requires no additional explicitly paired (image, caption) data. Because the parameters of the language model are left unchanged, the model maintains its capacity for zero-shot generalization. Experiments demonstrate that ESPER outperforms baselines and prior work on a variety of zero-shot tasks; these include a new benchmark we collect+release, ESP dataset, which tasks models with generating several diversely-styled captions for each image.