 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Inverse Airborne Optical Sectioning
Jul 27, 2022

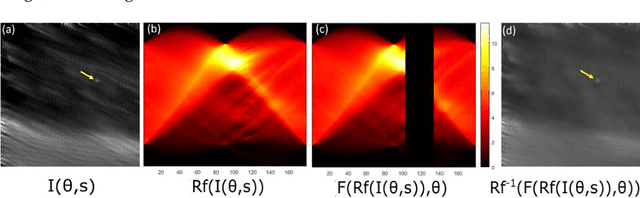
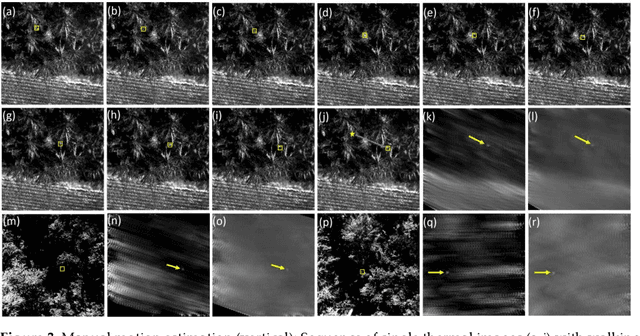

We present Inverse Airborne Optical Sectioning (IAOS) an optical analogy to Inverse Synthetic Aperture Radar (ISAR). Moving targets, such as walking people, that are heavily occluded by vegetation can be made visible and tracked with a stationary optical sensor (e.g., a hovering camera drone above forest). We introduce the principles of IAOS (i.e., inverse synthetic aperture imaging), explain how the signal of occluders can be further suppressed by filtering the Radon transform of the image integral, and present how targets motion parameters can be estimated manually and automatically. Finally, we show that while tracking occluded targets in conventional aerial images is infeasible, it becomes efficiently possible in integral images that result from IAOS.
Visualizing and Alleviating the Effect of Radial Distortion on Camera Calibration Using Principal Lines
Jun 28, 2022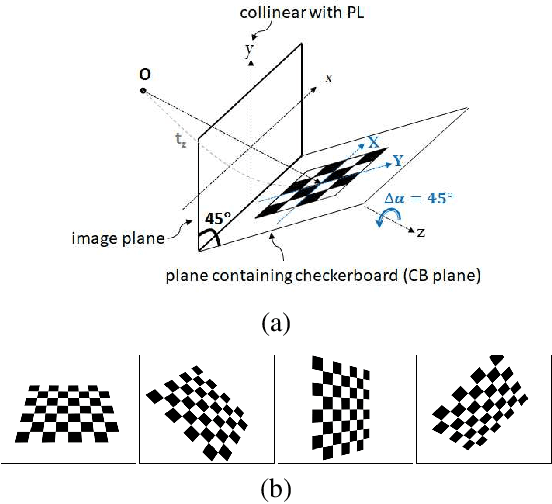
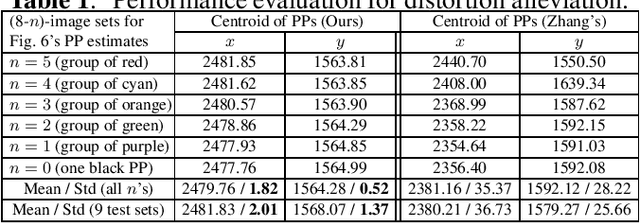
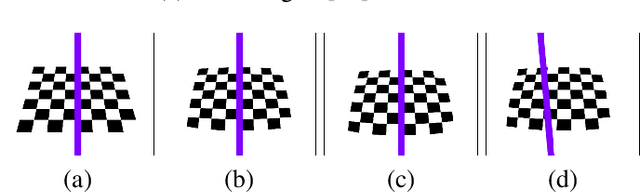
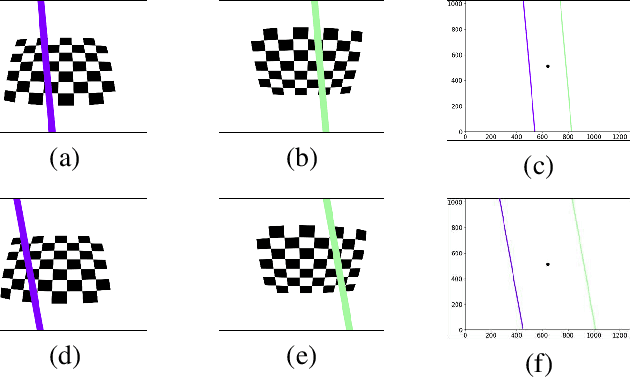
Preparing appropriate images for camera calibration is crucial to obtain accurate results. In this paper, new suggestions for preparing such data to alleviate the adverse effect of radial distortion for a calibration procedure using principal lines are developed through the investigations of: (i) identifying directions of checkerboard movements in an image which will result in maximum (and minimum) influence on the calibration results, and (ii) inspecting symmetry and monotonicity of such effect in (i) using the above principal lines. Accordingly, it is suggested that the estimation of principal point should based on linearly independent pairs of nearly parallel principal lines, with a member in each pair corresponds to a near 180-degree rotation (in the image plane) of the other. Experimental results show that more robust and consistent calibration results for the foregoing estimation can actually be obtained, compared with the renowned algebraic methods which estimate distortion parameters explicitly.
Predictive Angular Potential Field-based Obstacle Avoidance for Dynamic UAV Flights
Aug 11, 2022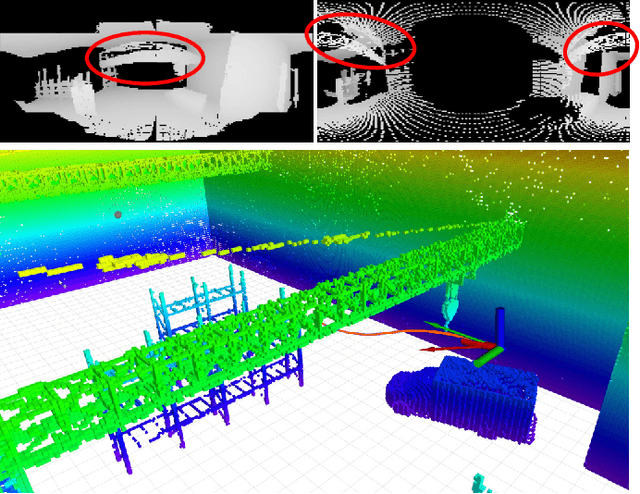
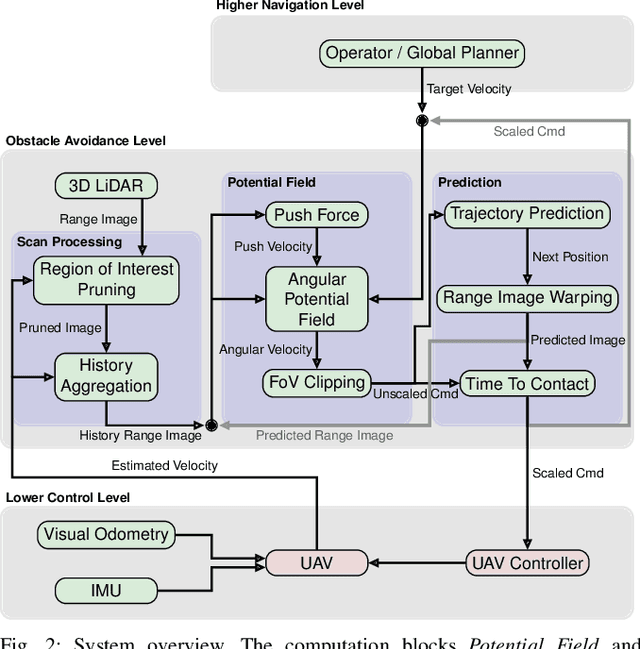
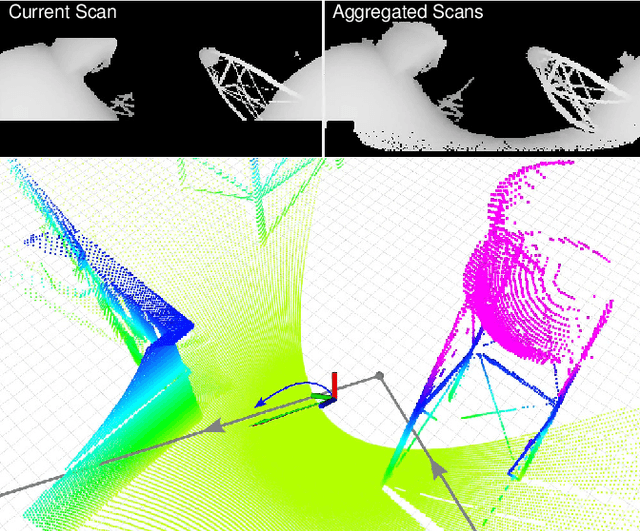

In recent years, unmanned aerial vehicles (UAVs) are used for numerous inspection and video capture tasks. Manually controlling UAVs in the vicinity of obstacles is challenging, however, and poses a high risk of collisions. Even for autonomous flight, global navigation planning might be too slow to react to newly perceived obstacles. Disturbances such as wind might lead to deviations from the planned trajectories. In this work, we present a fast predictive obstacle avoidance method that does not depend on higher-level localization or mapping and maintains the dynamic flight capabilities of UAVs. It directly operates on LiDAR range images in real time and adjusts the current flight direction by computing angular potential fields within the range image. The velocity magnitude is subsequently determined based on a trajectory prediction and time-to-contact estimation. Our method is evaluated using Hardware-in-the-Loop simulations. It keeps the UAV at a safe distance to obstacles, while allowing higher flight velocities than previous reactive obstacle avoidance methods that directly operate on sensor data.
RepParser: End-to-End Multiple Human Parsing with Representative Parts
Aug 27, 2022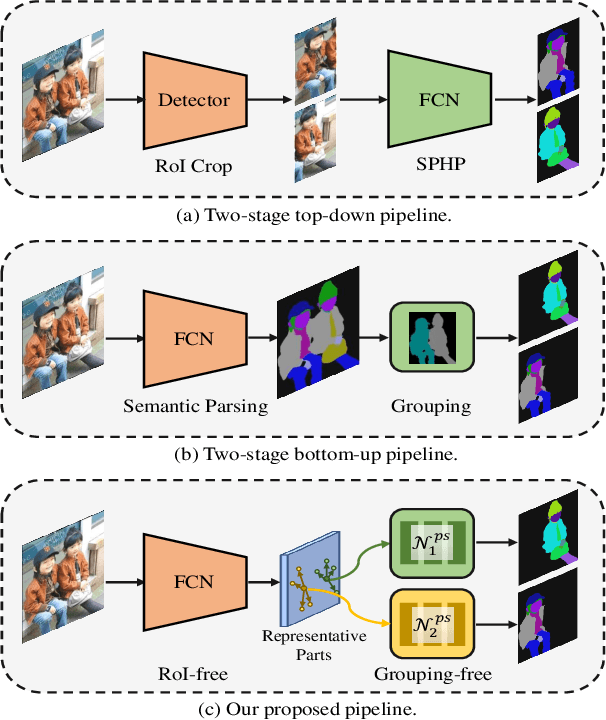
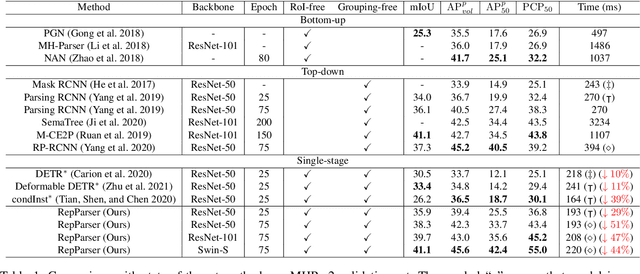
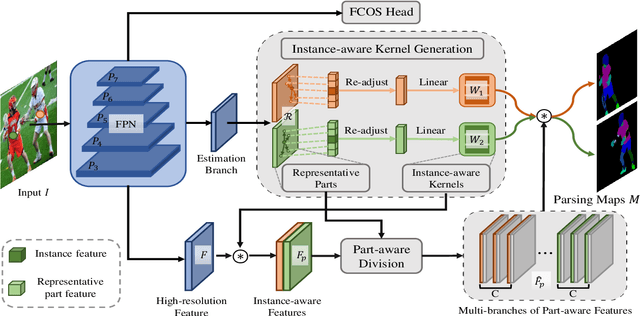
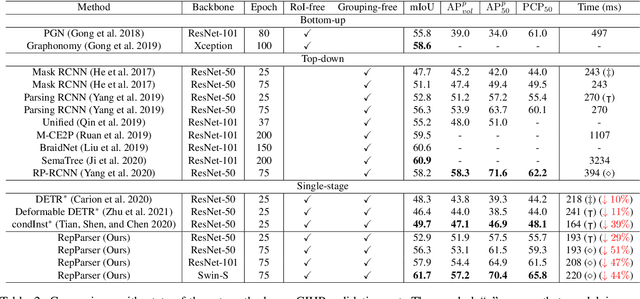
Existing methods of multiple human parsing usually adopt a two-stage strategy (typically top-down and bottom-up), which suffers from either strong dependence on prior detection or highly computational redundancy during post-grouping. In this work, we present an end-to-end multiple human parsing framework using representative parts, termed RepParser. Different from mainstream methods, RepParser solves the multiple human parsing in a new single-stage manner without resorting to person detection or post-grouping.To this end, RepParser decouples the parsing pipeline into instance-aware kernel generation and part-aware human parsing, which are responsible for instance separation and instance-specific part segmentation, respectively. In particular, we empower the parsing pipeline by representative parts, since they are characterized by instance-aware keypoints and can be utilized to dynamically parse each person instance. Specifically, representative parts are obtained by jointly localizing centers of instances and estimating keypoints of body part regions. After that, we dynamically predict instance-aware convolution kernels through representative parts, thus encoding person-part context into each kernel responsible for casting an image feature as an instance-specific representation.Furthermore, a multi-branch structure is adopted to divide each instance-specific representation into several part-aware representations for separate part segmentation.In this way, RepParser accordingly focuses on person instances with the guidance of representative parts and directly outputs parsing results for each person instance, thus eliminating the requirement of the prior detection or post-grouping.Extensive experiments on two challenging benchmarks demonstrate that our proposed RepParser is a simple yet effective framework and achieves very competitive performance.
Extending CLIP for Category-to-image Retrieval in E-commerce
Jan 04, 2022
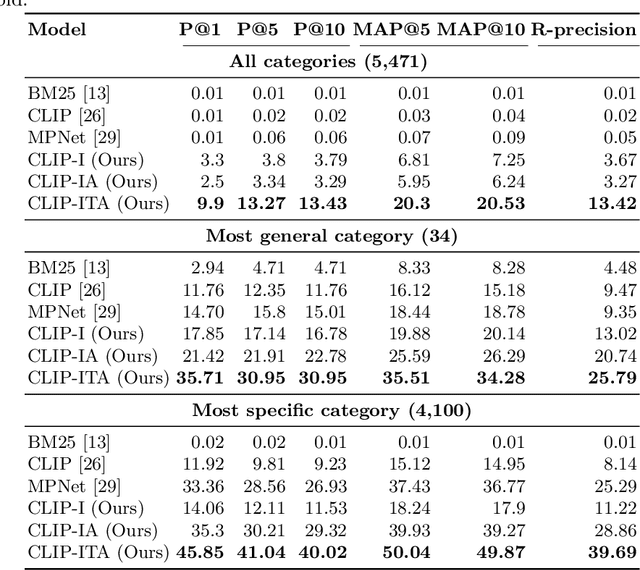
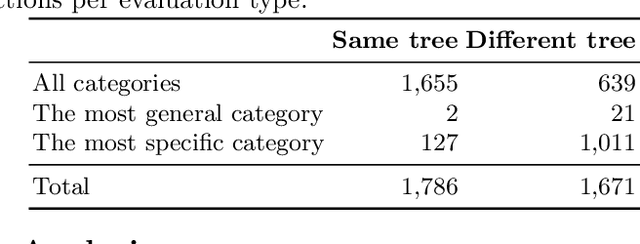
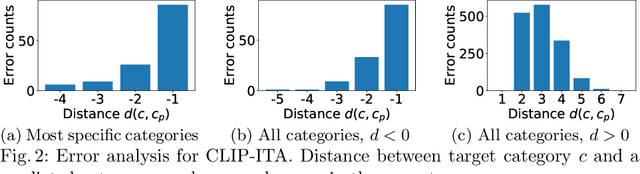
E-commerce provides rich multimodal data that is barely leveraged in practice. One aspect of this data is a category tree that is being used in search and recommendation. However, in practice, during a user's session there is often a mismatch between a textual and a visual representation of a given category. Motivated by the problem, we introduce the task of category-to-image retrieval in e-commerce and propose a model for the task, CLIP-ITA. The model leverages information from multiple modalities (textual, visual, and attribute modality) to create product representations. We explore how adding information from multiple modalities (textual, visual, and attribute modality) impacts the model's performance. In particular, we observe that CLIP-ITA significantly outperforms a comparable model that leverages only the visual modality and a comparable model that leverages the visual and attribute modality.
Joint reconstruction-segmentation on graphs
Aug 11, 2022
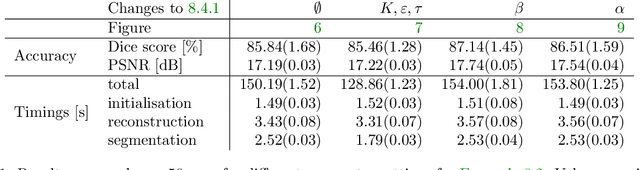

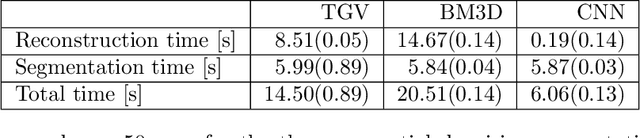
Practical image segmentation tasks concern images which must be reconstructed from noisy, distorted, and/or incomplete observations. A recent approach for solving such tasks is to perform this reconstruction jointly with the segmentation, using each to guide the other. However, this work has so far employed relatively simple segmentation methods, such as the Chan--Vese algorithm. In this paper, we present a method for joint reconstruction-segmentation using graph-based segmentation methods, which have been seeing increasing recent interest. Complications arise due to the large size of the matrices involved, and we show how these complications can be managed. We then analyse the convergence properties of our scheme. Finally, we apply this scheme to distorted versions of ``two cows'' images familiar from previous graph-based segmentation literature, first to a highly noised version and second to a blurred version, achieving highly accurate segmentations in both cases. We compare these results to those obtained by sequential reconstruction-segmentation approaches, finding that our method competes with, or even outperforms, those approaches in terms of reconstruction and segmentation accuracy.
On a Mechanism Framework of Autoencoders
Aug 15, 2022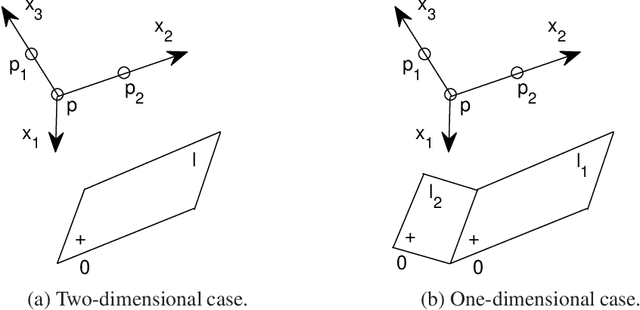
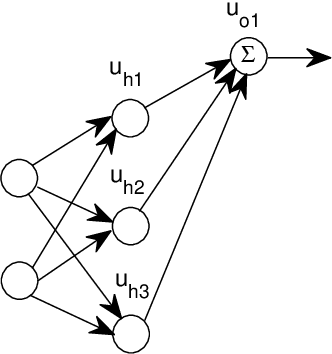
This paper proposes a theoretical framework on the mechanism of autoencoders. To the encoder part, under the main use of dimensionality reduction, we investigate its two fundamental properties: bijective maps and data disentangling. The general construction methods of an encoder that satisfies either or both of the above two properties are given. To the decoder part, as a consequence of the encoder constructions, we present a new basic principle of the solution, without using affine transforms. The generalization mechanism of autoencoders is modeled. The results of ReLU autoencoders are generalized to some non-ReLU cases, particularly for the sigmoid-unit autoencoder. Based on the theoretical framework above, we explain some experimental results of variational autoencoders, denoising autoencoders, and linear-unit autoencoders, with emphasis on the interpretation of the lower-dimensional representation of data via encoders; and the mechanism of image restoration through autoencoders is natural to be understood by those explanations. Compared to PCA and decision trees, the advantages of (generalized) autoencoders on dimensionality reduction and classification are demonstrated, respectively. Convolutional neural networks and randomly weighted neural networks are also interpreted by this framework.
BioFors: A Large Biomedical Image Forensics Dataset
Aug 30, 2021
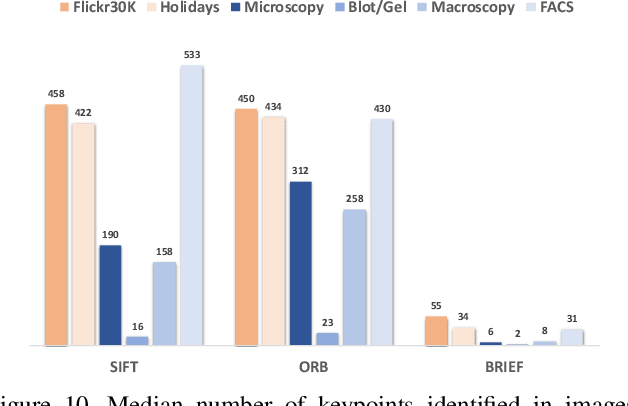

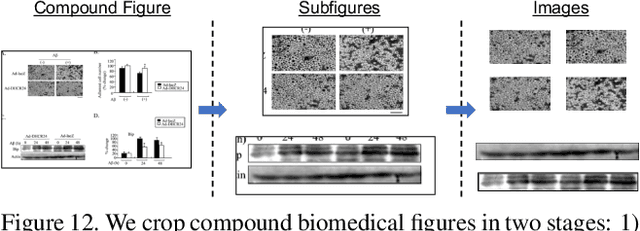
Research in media forensics has gained traction to combat the spread of misinformation. However, most of this research has been directed towards content generated on social media. Biomedical image forensics is a related problem, where manipulation or misuse of images reported in biomedical research documents is of serious concern. The problem has failed to gain momentum beyond an academic discussion due to an absence of benchmark datasets and standardized tasks. In this paper we present BioFors -- the first dataset for benchmarking common biomedical image manipulations. BioFors comprises 47,805 images extracted from 1,031 open-source research papers. Images in BioFors are divided into four categories -- Microscopy, Blot/Gel, FACS and Macroscopy. We also propose three tasks for forensic analysis -- external duplication detection, internal duplication detection and cut/sharp-transition detection. We benchmark BioFors on all tasks with suitable state-of-the-art algorithms. Our results and analysis show that existing algorithms developed on common computer vision datasets are not robust when applied to biomedical images, validating that more research is required to address the unique challenges of biomedical image forensics.
Model Inspired Autoencoder for Unsupervised Hyperspectral Image Super-Resolution
Oct 22, 2021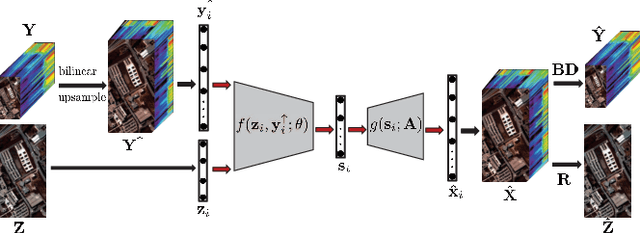
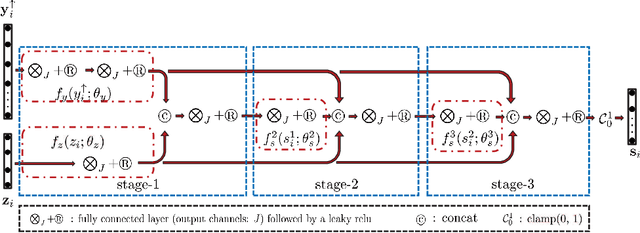
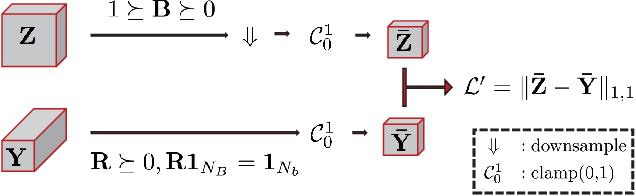
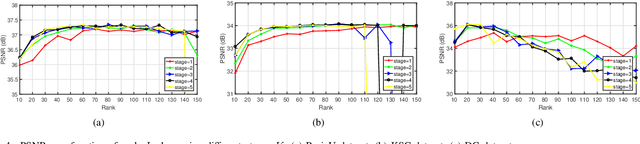
This paper focuses on hyperspectral image (HSI) super-resolution that aims to fuse a low-spatial-resolution HSI and a high-spatial-resolution multispectral image to form a high-spatial-resolution HSI (HR-HSI). Existing deep learning-based approaches are mostly supervised that rely on a large number of labeled training samples, which is unrealistic. The commonly used model-based approaches are unsupervised and flexible but rely on hand-craft priors. Inspired by the specific properties of model, we make the first attempt to design a model inspired deep network for HSI super-resolution in an unsupervised manner. This approach consists of an implicit autoencoder network built on the target HR-HSI that treats each pixel as an individual sample. The nonnegative matrix factorization (NMF) of the target HR-HSI is integrated into the autoencoder network, where the two NMF parts, spectral and spatial matrices, are treated as decoder parameters and hidden outputs respectively. In the encoding stage, we present a pixel-wise fusion model to estimate hidden outputs directly, and then reformulate and unfold the model's algorithm to form the encoder network. With the specific architecture, the proposed network is similar to a manifold prior-based model, and can be trained patch by patch rather than the entire image. Moreover, we propose an additional unsupervised network to estimate the point spread function and spectral response function. Experimental results conducted on both synthetic and real datasets demonstrate the effectiveness of the proposed approach.
Evaluating Continual Test-Time Adaptation for Contextual and Semantic Domain Shifts
Aug 18, 2022
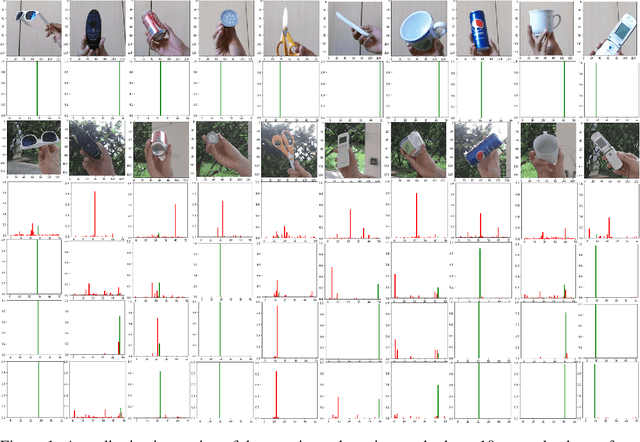

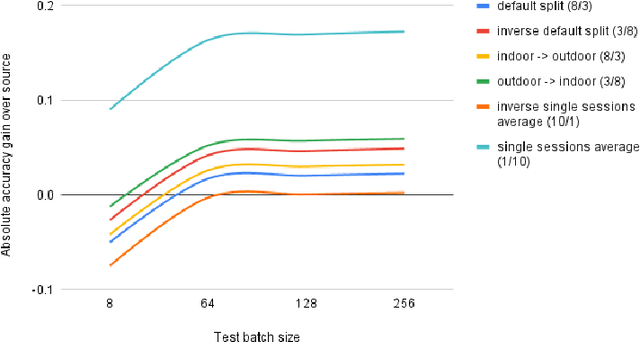
In this paper, our goal is to adapt a pre-trained Convolutional Neural Network to domain shifts at test time. We do so continually with the incoming stream of test batches, without labels. Existing literature mostly operates on artificial shifts obtained via adversarial perturbations of a test image. Motivated by this, we evaluate the state of the art on two realistic and challenging sources of domain shifts, namely contextual and semantic shifts. Contextual shifts correspond to the environment types, for example a model pre-trained on indoor context has to adapt to the outdoor context on CORe-50 [7]. Semantic shifts correspond to the capture types, for example a model pre-trained on natural images has to adapt to cliparts, sketches and paintings on DomainNet [10]. We include in our analysis recent techniques such as Prediction-Time Batch Normalization (BN) [8], Test Entropy Minimization (TENT) [16] and Continual Test-Time Adaptation (CoTTA) [17]. Our findings are three-fold: i) Test-time adaptation methods perform better and forget less on contextual shifts compared to semantic shifts, ii) TENT outperforms other methods on short-term adaptation, whereas CoTTA outpeforms other methods on long-term adaptation, iii) BN is most reliable and robust.