 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Continuous emission ultrasound: a new paradigm to ultrafast ultrasound imaging
Mar 04, 2024
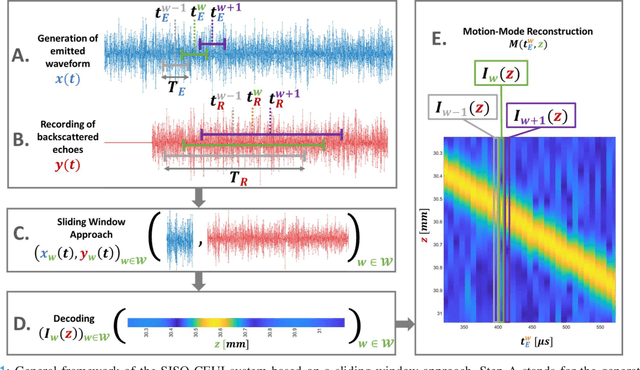
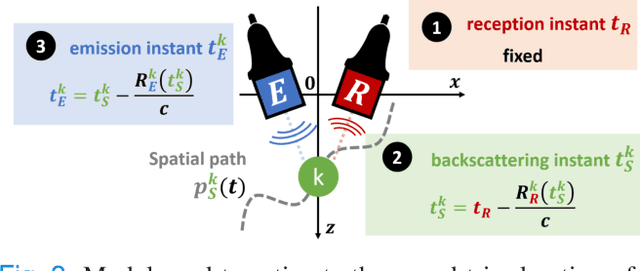
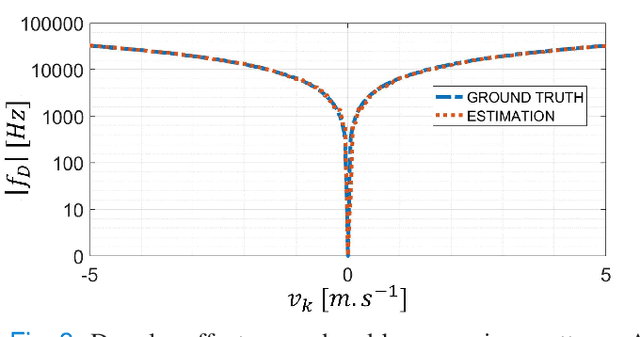

Current imaging techniques in echography rely on the pulse-echo (PE) paradigm which provides a straight-forward access to the in-depth structure of tissues. They inherently face two major challenges: the limitation of the pulse repetition frequency, directly linked to the imaging framerate, and, due to the emission scheme, their blindness to the phenomena that happen in the medium during the majority of the acquisition time. To overcome these limitations, we propose a new paradigm for ultrasound imaging, denoted by continuous emission ultrasound imaging (CUEI) \cite{CEUIpatent2023}, for a single input single output (SISO) device. A continuous insonification of the medium is done by the probe using a coded waveform inspired from the radar and sonar literature. A framework coupling a sliding window approach (SWA) and pulse compression methods processes the recorded echoes to rebuild a motion-mode (M-mode) image from the medium with a high temporal resolution compared to state-of-the-art ultrafast imaging methods. A study on realistic simulated data, with regards to the motion of the medium, has been carried out and, achieved results assess an unequivocal improvement of the slow time frequency up to, at least, two orders of magnitude compared to ultrafast US imaging methods. This enhancement leads, therefore, to a ten times improvement in the temporal separability of the imaging system. In addition, it demonstrates the capability of CEUI to catch relatively short and quick events, in comparison to the imaging period of PE methods, at any instant of the acquisition.
DyCE: Dynamic Configurable Exiting for Deep Learning Compression and Scaling
Mar 04, 2024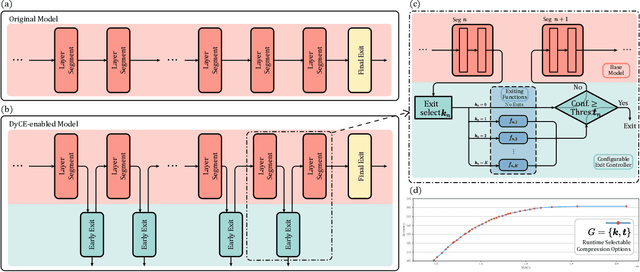
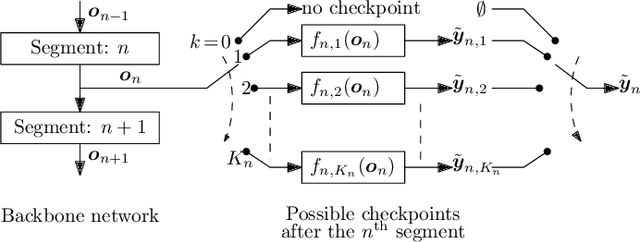
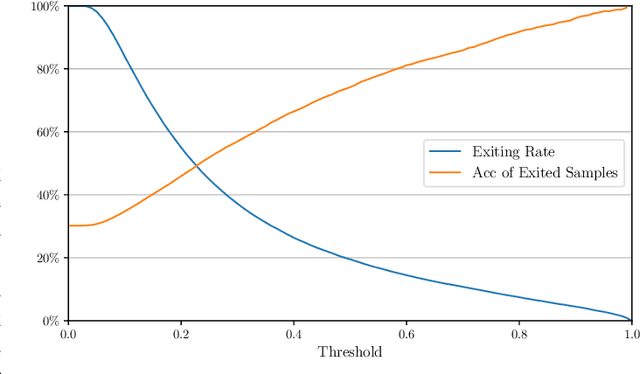
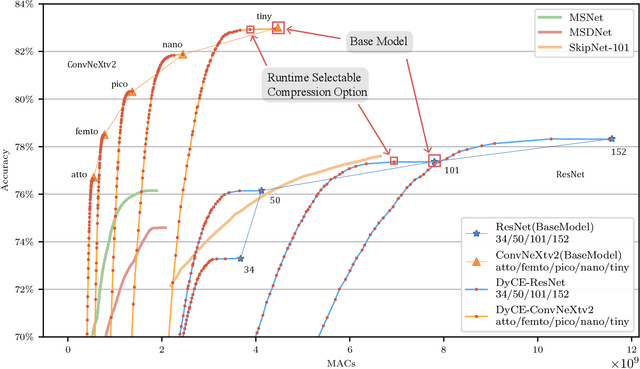
Modern deep learning (DL) models necessitate the employment of scaling and compression techniques for effective deployment in resource-constrained environments. Most existing techniques, such as pruning and quantization are generally static. On the other hand, dynamic compression methods, such as early exits, reduce complexity by recognizing the difficulty of input samples and allocating computation as needed. Dynamic methods, despite their superior flexibility and potential for co-existing with static methods, pose significant challenges in terms of implementation due to any changes in dynamic parts will influence subsequent processes. Moreover, most current dynamic compression designs are monolithic and tightly integrated with base models, thereby complicating the adaptation to novel base models. This paper introduces DyCE, an dynamic configurable early-exit framework that decouples design considerations from each other and from the base model. Utilizing this framework, various types and positions of exits can be organized according to predefined configurations, which can be dynamically switched in real-time to accommodate evolving performance-complexity requirements. We also propose techniques for generating optimized configurations based on any desired trade-off between performance and computational complexity. This empowers future researchers to focus on the improvement of individual exits without latent compromise of overall system performance. The efficacy of this approach is demonstrated through image classification tasks with deep CNNs. DyCE significantly reduces the computational complexity by 23.5% of ResNet152 and 25.9% of ConvNextv2-tiny on ImageNet, with accuracy reductions of less than 0.5%. Furthermore, DyCE offers advantages over existing dynamic methods in terms of real-time configuration and fine-grained performance tuning.
Vision Language Model-based Caption Evaluation Method Leveraging Visual Context Extraction
Feb 28, 2024Given the accelerating progress of vision and language modeling, accurate evaluation of machine-generated image captions remains critical. In order to evaluate captions more closely to human preferences, metrics need to discriminate between captions of varying quality and content. However, conventional metrics fail short of comparing beyond superficial matches of words or embedding similarities; thus, they still need improvement. This paper presents VisCE$^2$, a vision language model-based caption evaluation method. Our method focuses on visual context, which refers to the detailed content of images, including objects, attributes, and relationships. By extracting and organizing them into a structured format, we replace the human-written references with visual contexts and help VLMs better understand the image, enhancing evaluation performance. Through meta-evaluation on multiple datasets, we validated that VisCE$^2$ outperforms the conventional pre-trained metrics in capturing caption quality and demonstrates superior consistency with human judgment.
ViTaL: An Advanced Framework for Automated Plant Disease Identification in Leaf Images Using Vision Transformers and Linear Projection For Feature Reduction
Feb 28, 2024Our paper introduces a robust framework for the automated identification of diseases in plant leaf images. The framework incorporates several key stages to enhance disease recognition accuracy. In the pre-processing phase, a thumbnail resizing technique is employed to resize images, minimizing the loss of critical image details while ensuring computational efficiency. Normalization procedures are applied to standardize image data before feature extraction. Feature extraction is facilitated through a novel framework built upon Vision Transformers, a state-of-the-art approach in image analysis. Additionally, alternative versions of the framework with an added layer of linear projection and blockwise linear projections are explored. This comparative analysis allows for the evaluation of the impact of linear projection on feature extraction and overall model performance. To assess the effectiveness of the proposed framework, various Convolutional Neural Network (CNN) architectures are utilized, enabling a comprehensive evaluation of linear projection's influence on key evaluation metrics. The findings demonstrate the efficacy of the proposed framework, with the top-performing model achieving a Hamming loss of 0.054. Furthermore, we propose a novel hardware design specifically tailored for scanning diseased leaves in an omnidirectional fashion. The hardware implementation utilizes a Raspberry Pi Compute Module to address low-memory configurations, ensuring practicality and affordability. This innovative hardware solution enhances the overall feasibility and accessibility of the proposed automated disease identification system. This research contributes to the field of agriculture by offering valuable insights and tools for the early detection and management of plant diseases, potentially leading to improved crop yields and enhanced food security.
NocPlace: Nocturnal Visual Place Recognition Using Generative and Inherited Knowledge Transfer
Feb 27, 2024Visual Place Recognition (VPR) is crucial in computer vision, aiming to retrieve database images similar to a query image from an extensive collection of known images. However, like many vision-related tasks, learning-based VPR often experiences a decline in performance during nighttime due to the scarcity of nighttime images. Specifically, VPR needs to address the cross-domain problem of night-to-day rather than just the issue of a single nighttime domain. In response to these issues, we present NocPlace, which leverages a generated large-scale, multi-view, nighttime VPR dataset to embed resilience against dazzling lights and extreme darkness in the learned global descriptor. Firstly, we establish a day-night urban scene dataset called NightCities, capturing diverse nighttime scenarios and lighting variations across 60 cities globally. Following this, an unpaired image-to-image translation network is trained on this dataset. Using this trained translation network, we process an existing VPR dataset, thereby obtaining its nighttime version. The NocPlace is then fine-tuned using night-style images, the original labels, and descriptors inherited from the Daytime VPR model. Comprehensive experiments on various nighttime VPR test sets reveal that NocPlace considerably surpasses previous state-of-the-art methods.
Saliency-aware End-to-end Learned Variable-Bitrate 360-degree Image Compression
Feb 14, 2024Effective compression of 360$^\circ$ images, also referred to as omnidirectional images (ODIs), is of high interest for various virtual reality (VR) and related applications. 2D image compression methods ignore the equator-biased nature of ODIs and fail to address oversampling near the poles, leading to inefficient compression when applied to ODI. We present a new learned saliency-aware 360$^\circ$ image compression architecture that prioritizes bit allocation to more significant regions, considering the unique properties of ODIs. By assigning fewer bits to less important regions, significant data size reduction can be achieved while maintaining high visual quality in the significant regions. To the best of our knowledge, this is the first study that proposes an end-to-end variable-rate model to compress 360$^\circ$ images leveraging saliency information. The results show significant bit-rate savings over the state-of-the-art learned and traditional ODI compression methods at similar perceptual visual quality.
UB-FineNet: Urban Building Fine-grained Classification Network for Open-access Satellite Images
Mar 04, 2024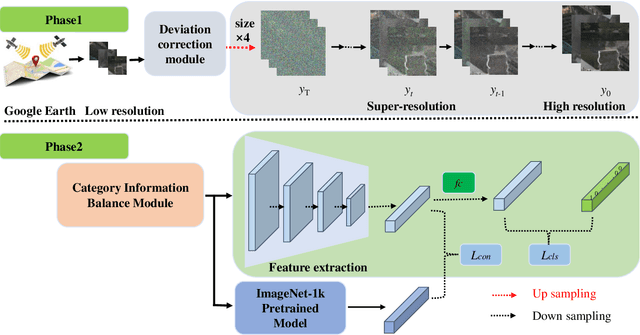
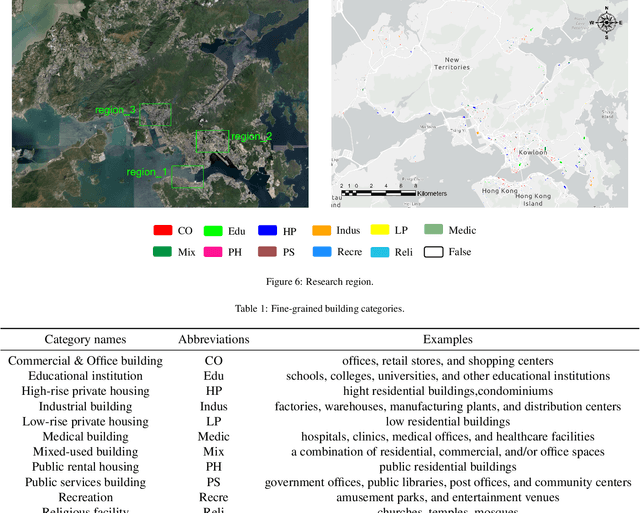
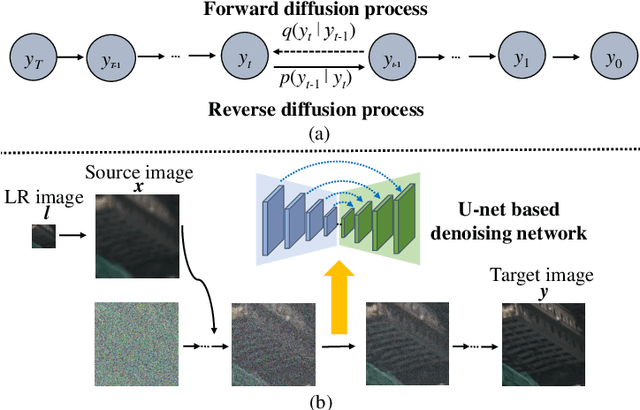
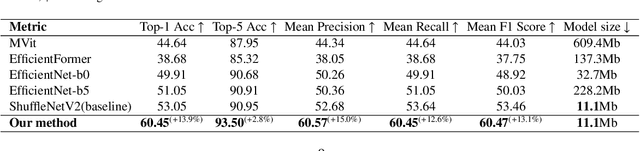
Fine classification of city-scale buildings from satellite remote sensing imagery is a crucial research area with significant implications for urban planning, infrastructure development, and population distribution analysis. However, the task faces big challenges due to low-resolution overhead images acquired from high altitude space-borne platforms and the long-tail sample distribution of fine-grained urban building categories, leading to severe class imbalance problem. To address these issues, we propose a deep network approach to fine-grained classification of urban buildings using open-access satellite images. A Denoising Diffusion Probabilistic Model (DDPM) based super-resolution method is first introduced to enhance the spatial resolution of satellite images, which benefits from domain-adaptive knowledge distillation. Then, a new fine-grained classification network with Category Information Balancing Module (CIBM) and Contrastive Supervision (CS) technique is proposed to mitigate the problem of class imbalance and improve the classification robustness and accuracy. Experiments on Hong Kong data set with 11 fine building types revealed promising classification results with a mean Top-1 accuracy of 60.45\%, which is on par with street-view image based approaches. Extensive ablation study shows that CIBM and CS improve Top-1 accuracy by 2.6\% and 3.5\% compared to the baseline method, respectively. And both modules can be easily inserted into other classification networks and similar enhancements have been achieved. Our research contributes to the field of urban analysis by providing a practical solution for fine classification of buildings in challenging mega city scenarios solely using open-access satellite images. The proposed method can serve as a valuable tool for urban planners, aiding in the understanding of economic, industrial, and population distribution.
Hierarchical Multimodal Pre-training for Visually Rich Webpage Understanding
Feb 28, 2024The growing prevalence of visually rich documents, such as webpages and scanned/digital-born documents (images, PDFs, etc.), has led to increased interest in automatic document understanding and information extraction across academia and industry. Although various document modalities, including image, text, layout, and structure, facilitate human information retrieval, the interconnected nature of these modalities presents challenges for neural networks. In this paper, we introduce WebLM, a multimodal pre-training network designed to address the limitations of solely modeling text and structure modalities of HTML in webpages. Instead of processing document images as unified natural images, WebLM integrates the hierarchical structure of document images to enhance the understanding of markup-language-based documents. Additionally, we propose several pre-training tasks to model the interaction among text, structure, and image modalities effectively. Empirical results demonstrate that the pre-trained WebLM significantly surpasses previous state-of-the-art pre-trained models across several webpage understanding tasks. The pre-trained models and code are available at https://github.com/X-LANCE/weblm.
Reflection Removal Using Recurrent Polarization-to-Polarization Network
Feb 28, 2024This paper addresses reflection removal, which is the task of separating reflection components from a captured image and deriving the image with only transmission components. Considering that the existence of the reflection changes the polarization state of a scene, some existing methods have exploited polarized images for reflection removal. While these methods apply polarized images as the inputs, they predict the reflection and the transmission directly as non-polarized intensity images. In contrast, we propose a polarization-to-polarization approach that applies polarized images as the inputs and predicts "polarized" reflection and transmission images using two sequential networks to facilitate the separation task by utilizing the interrelated polarization information between the reflection and the transmission. We further adopt a recurrent framework, where the predicted reflection and transmission images are used to iteratively refine each other. Experimental results on a public dataset demonstrate that our method outperforms other state-of-the-art methods.
Multimodal Learning To Improve Cardiac Late Mechanical Activation Detection From Cine MR Images
Feb 28, 2024This paper presents a multimodal deep learning framework that utilizes advanced image techniques to improve the performance of clinical analysis heavily dependent on routinely acquired standard images. More specifically, we develop a joint learning network that for the first time leverages the accuracy and reproducibility of myocardial strains obtained from Displacement Encoding with Stimulated Echo (DENSE) to guide the analysis of cine cardiac magnetic resonance (CMR) imaging in late mechanical activation (LMA) detection. An image registration network is utilized to acquire the knowledge of cardiac motions, an important feature estimator of strain values, from standard cine CMRs. Our framework consists of two major components: (i) a DENSE-supervised strain network leveraging latent motion features learned from a registration network to predict myocardial strains; and (ii) a LMA network taking advantage of the predicted strain for effective LMA detection. Experimental results show that our proposed work substantially improves the performance of strain analysis and LMA detection from cine CMR images, aligning more closely with the achievements of DENSE.