 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Comprehensive Study of Real-Time Object Detection Networks Across Multiple Domains: A Survey
Aug 23, 2022

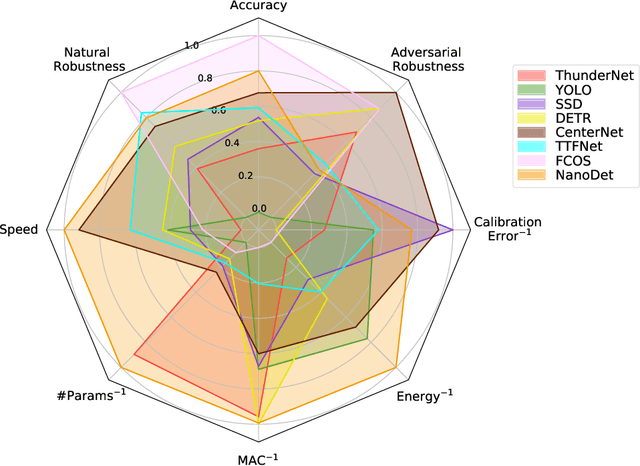
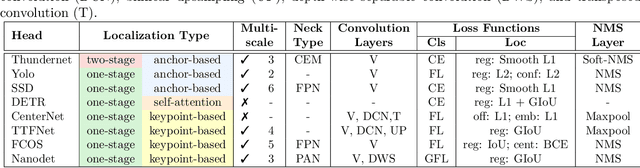
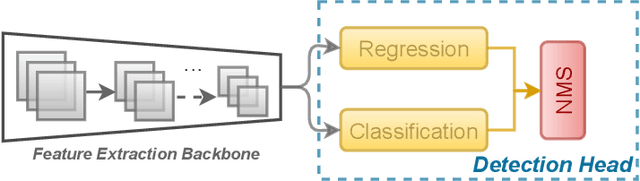
Deep neural network based object detectors are continuously evolving and are used in a multitude of applications, each having its own set of requirements. While safety-critical applications need high accuracy and reliability, low-latency tasks need resource and energy-efficient networks. Real-time detectors, which are a necessity in high-impact real-world applications, are continuously proposed, but they overemphasize the improvements in accuracy and speed while other capabilities such as versatility, robustness, resource and energy efficiency are omitted. A reference benchmark for existing networks does not exist, nor does a standard evaluation guideline for designing new networks, which results in ambiguous and inconsistent comparisons. We, thus, conduct a comprehensive study on multiple real-time detectors (anchor-, keypoint-, and transformer-based) on a wide range of datasets and report results on an extensive set of metrics. We also study the impact of variables such as image size, anchor dimensions, confidence thresholds, and architecture layers on the overall performance. We analyze the robustness of detection networks against distribution shifts, natural corruptions, and adversarial attacks. Also, we provide a calibration analysis to gauge the reliability of the predictions. Finally, to highlight the real-world impact, we conduct two unique case studies, on autonomous driving and healthcare applications. To further gauge the capability of networks in critical real-time applications, we report the performance after deploying the detection networks on edge devices. Our extensive empirical study can act as a guideline for the industrial community to make an informed choice on the existing networks. We also hope to inspire the research community towards a new direction in the design and evaluation of networks that focuses on a bigger and holistic overview for a far-reaching impact.
* Published in Transactions on Machine Learning Research (TMLR) with Survey Certification
A comprehensive survey on computer-aided diagnostic systems in diabetic retinopathy screening
Aug 03, 2022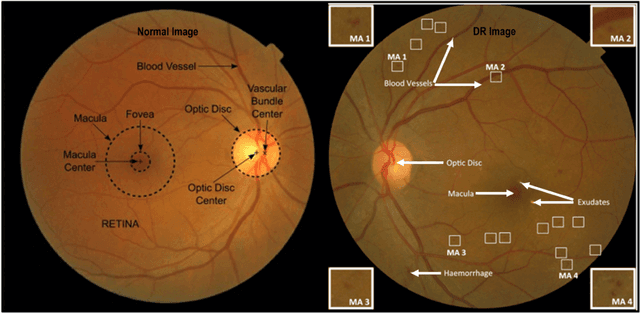

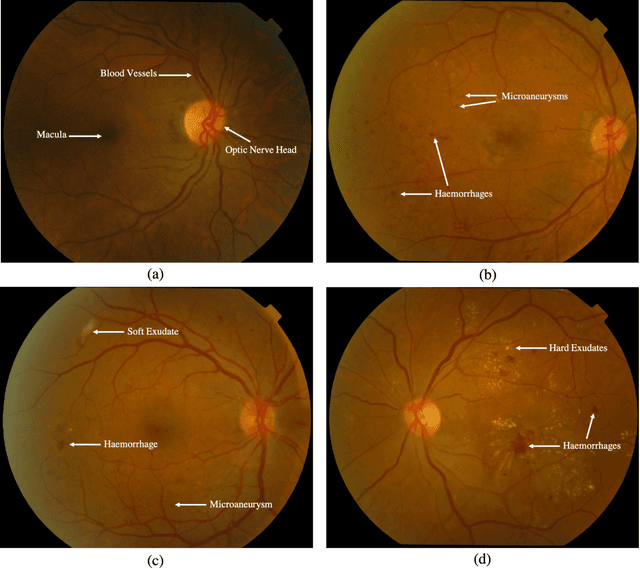
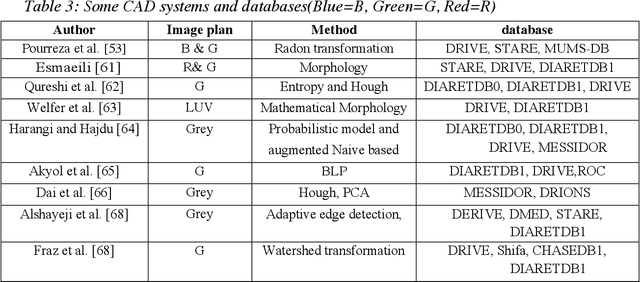
Diabetes Mellitus (DM) can lead to significant microvasculature disruptions that eventually causes diabetic retinopathy (DR), or complications in the eye due to diabetes. If left unchecked, this disease can increase over time and eventually cause complete vision loss. The general method to detect such optical developments is through examining the vessels, optic nerve head, microaneurysms, haemorrhage, exudates, etc. from retinal images. Ultimately this is limited by the number of experienced ophthalmologists and the vastly growing number of DM cases. To enable earlier and efficient DR diagnosis, the field of ophthalmology requires robust computer aided diagnosis (CAD) systems. Our review is intended for anyone, from student to established researcher, who wants to understand what can be accomplished with CAD systems and their algorithms to modeling and where the field of retinal image processing in computer vision and pattern recognition is headed. For someone just getting started, we place a special emphasis on the logic, strengths and shortcomings of different databases and algorithms frameworks with a focus on very recent approaches.
* 65 pages, 7 figures, 9 tables
Forest and Water Bodies Segmentation Through Satellite Images Using U-Net
Jul 12, 2022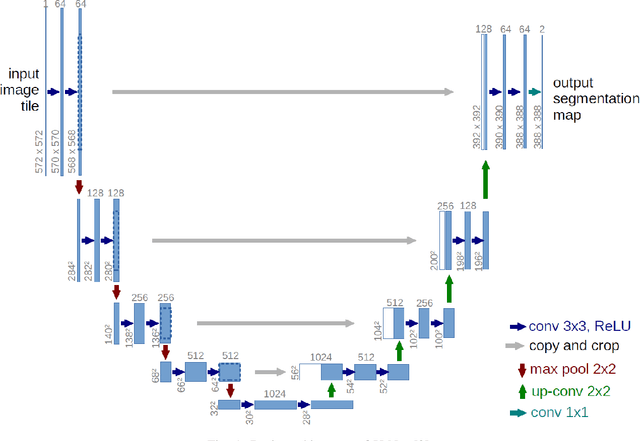
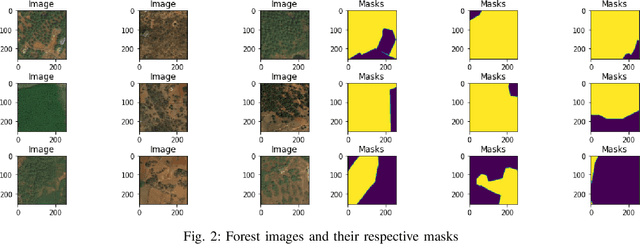

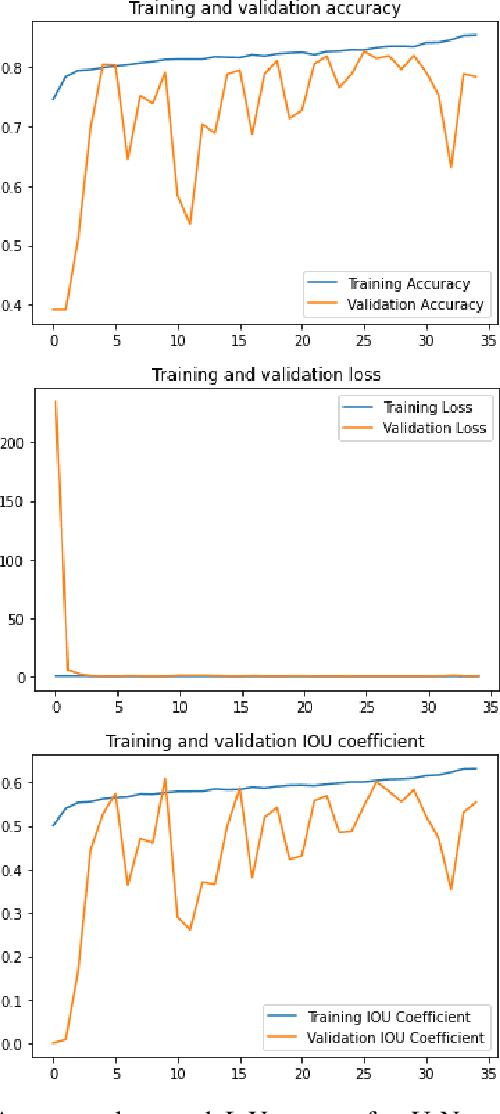
Global environment monitoring is a task that requires additional attention in the contemporary rapid climate change environment. This includes monitoring the rate of deforestation and areas affected by flooding. Satellite imaging has greatly helped monitor the earth, and deep learning techniques have helped to automate this monitoring process. This paper proposes a solution for observing the area covered by the forest and water. To achieve this task UNet model has been proposed, which is an image segmentation model. The model achieved a validation accuracy of 82.55% and 82.92% for the segmentation of areas covered by forest and water, respectively.
Mutually improved endoscopic image synthesis and landmark detection in unpaired image-to-image translation
Jul 14, 2021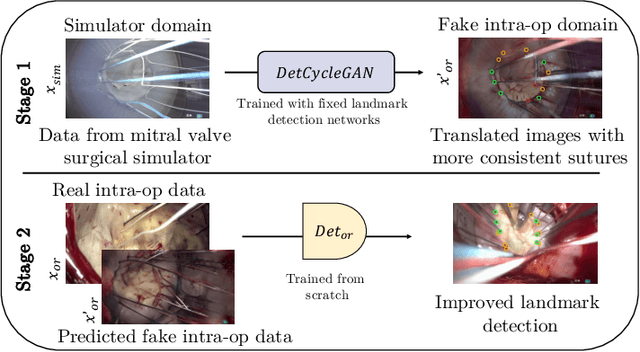
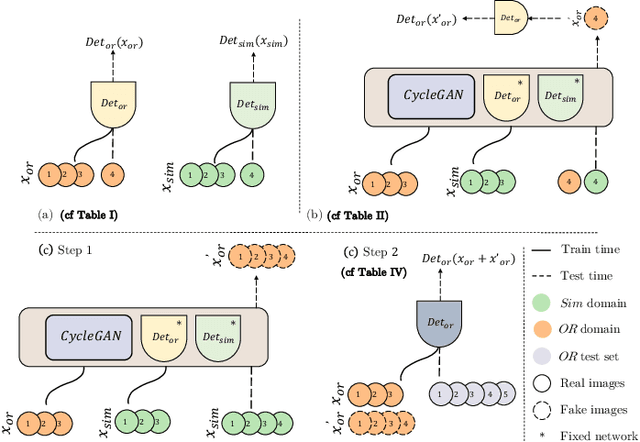
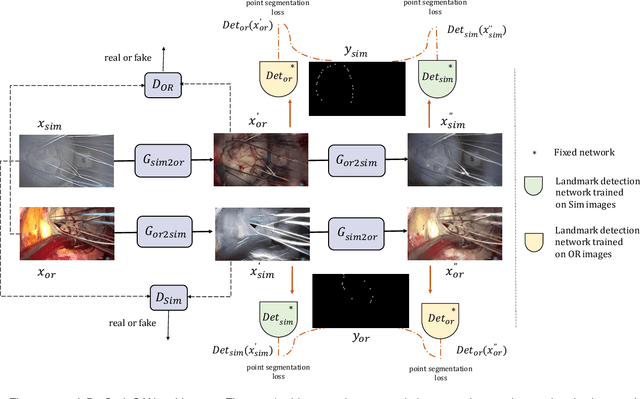
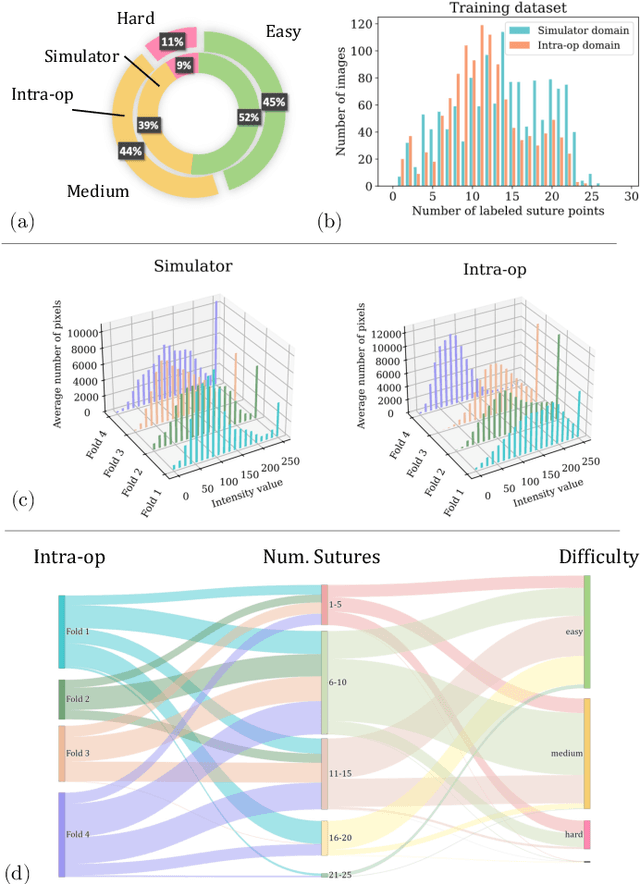
The CycleGAN framework allows for unsupervised image-to-image translation of unpaired data. In a scenario of surgical training on a physical surgical simulator, this method can be used to transform endoscopic images of phantoms into images which more closely resemble the intra-operative appearance of the same surgical target structure. This can be viewed as a novel augmented reality approach, which we coined Hyperrealism in previous work. In this use case, it is of paramount importance to display objects like needles, sutures or instruments consistent in both domains while altering the style to a more tissue-like appearance. Segmentation of these objects would allow for a direct transfer, however, contouring of these, partly tiny and thin foreground objects is cumbersome and perhaps inaccurate. Instead, we propose to use landmark detection on the points when sutures pass into the tissue. This objective is directly incorporated into a CycleGAN framework by treating the performance of pre-trained detector models as an additional optimization goal. We show that a task defined on these sparse landmark labels improves consistency of synthesis by the generator network in both domains. Comparing a baseline CycleGAN architecture to our proposed extension (DetCycleGAN), mean precision (PPV) improved by +61.32, mean sensitivity (TPR) by +37.91, and mean F1 score by +0.4743. Furthermore, it could be shown that by dataset fusion, generated intra-operative images can be leveraged as additional training data for the detection network itself. The data is released within the scope of the AdaptOR MICCAI Challenge 2021 at https://adaptor2021.github.io/, and code at https://github.com/Cardio-AI/detcyclegan_pytorch.
Lightweight Encoder-Decoder Architecture for Foot Ulcer Segmentation
Jul 06, 2022Continuous monitoring of foot ulcer healing is needed to ensure the efficacy of a given treatment and to avoid any possibility of deterioration. Foot ulcer segmentation is an essential step in wound diagnosis. We developed a model that is similar in spirit to the well-established encoder-decoder and residual convolution neural networks. Our model includes a residual connection along with a channel and spatial attention integrated within each convolution block. A simple patch-based approach for model training, test time augmentations, and majority voting on the obtained predictions resulted in superior performance. Our model did not leverage any readily available backbone architecture, pre-training on a similar external dataset, or any of the transfer learning techniques. The total number of network parameters being around 5 million made it a significantly lightweight model as compared with the available state-of-the-art models used for the foot ulcer segmentation task. Our experiments presented results at the patch-level and image-level. Applied on publicly available Foot Ulcer Segmentation (FUSeg) Challenge dataset from MICCAI 2021, our model achieved state-of-the-art image-level performance of 88.22% in terms of Dice similarity score and ranked second in the official challenge leaderboard. We also showed an extremely simple solution that could be compared against the more advanced architectures.
* Published version of this article is available at https://link.springer.com/chapter/10.1007/978-3-031-06381-7_17
SDEdit: Image Synthesis and Editing with Stochastic Differential Equations
Aug 02, 2021
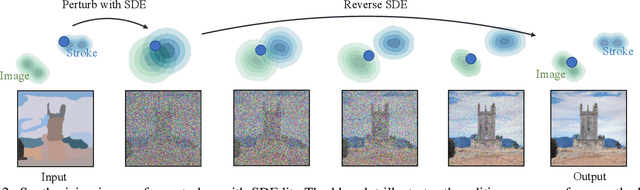
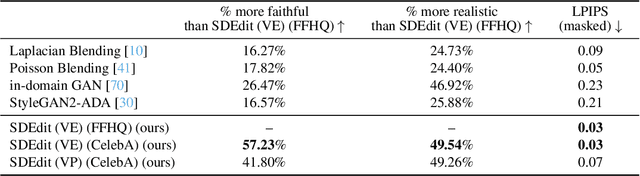

We introduce a new image editing and synthesis framework, Stochastic Differential Editing (SDEdit), based on a recent generative model using stochastic differential equations (SDEs). Given an input image with user edits (e.g., hand-drawn color strokes), we first add noise to the input according to an SDE, and subsequently denoise it by simulating the reverse SDE to gradually increase its likelihood under the prior. Our method does not require task-specific loss function designs, which are critical components for recent image editing methods based on GAN inversion. Compared to conditional GANs, we do not need to collect new datasets of original and edited images for new applications. Therefore, our method can quickly adapt to various editing tasks at test time without re-training models. Our approach achieves strong performance on a wide range of applications, including image synthesis and editing guided by stroke paintings and image compositing.
Revisiting Hotels-50K and Hotel-ID
Jul 20, 2022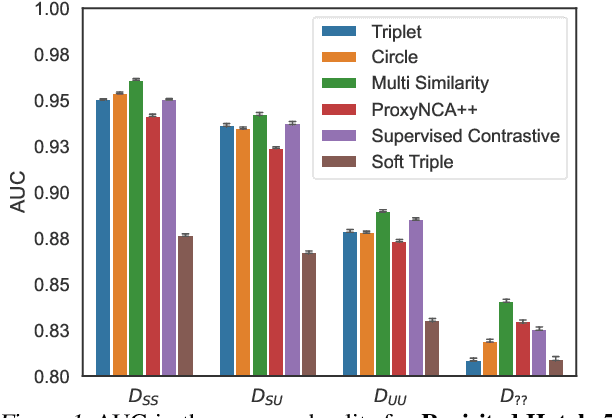
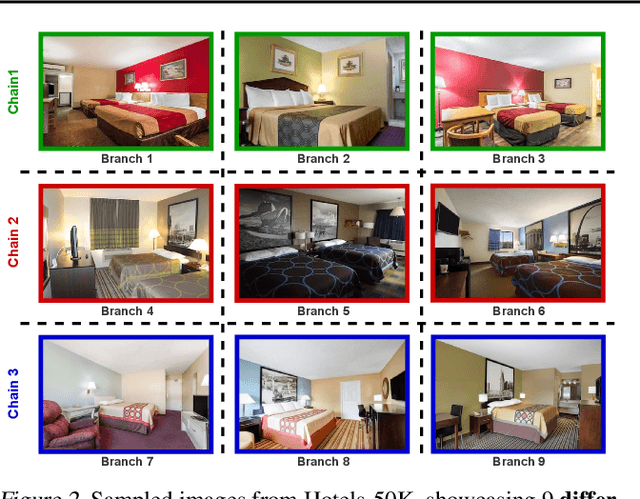
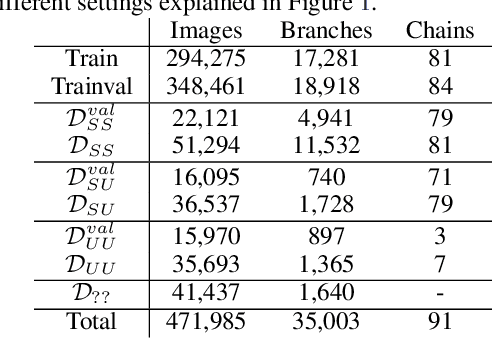
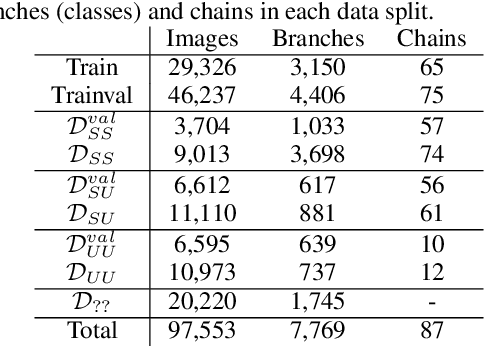
In this paper, we propose revisited versions for two recent hotel recognition datasets: Hotels50K and Hotel-ID. The revisited versions provide evaluation setups with different levels of difficulty to better align with the intended real-world application, i.e. countering human trafficking. Real-world scenarios involve hotels and locations that are not captured in the current data sets, therefore it is important to consider evaluation settings where classes are truly unseen. We test this setup using multiple state-of-the-art image retrieval models and show that as expected, the models' performances decrease as the evaluation gets closer to the real-world unseen settings. The rankings of the best performing models also change across the different evaluation settings, which further motivates using the proposed revisited datasets.
Instance-weighted Central Similarity for Multi-label Image Retrieval
Aug 14, 2021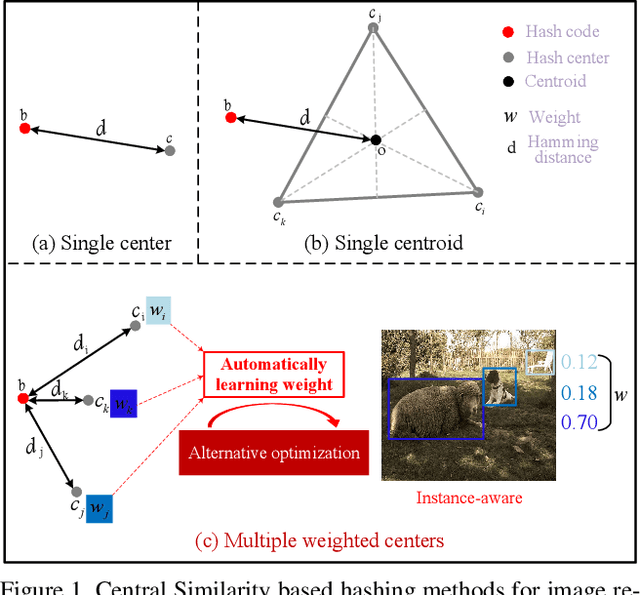

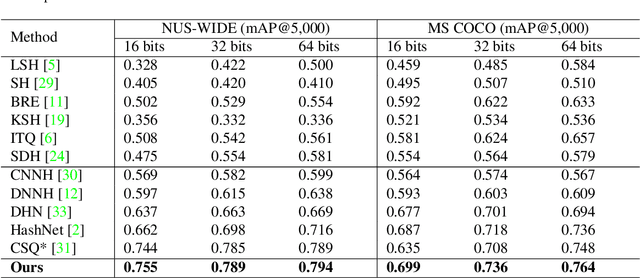
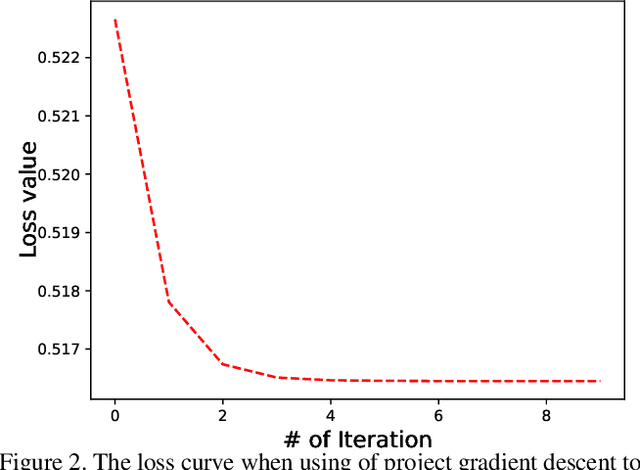
Deep hashing has been widely applied to large-scale image retrieval by encoding high-dimensional data points into binary codes for efficient retrieval. Compared with pairwise/triplet similarity based hash learning, central similarity based hashing can more efficiently capture the global data distribution. For multi-label image retrieval, however, previous methods only use multiple hash centers with equal weights to generate one centroid as the learning target, which ignores the relationship between the weights of hash centers and the proportion of instance regions in the image. To address the above issue, we propose a two-step alternative optimization approach, Instance-weighted Central Similarity (ICS), to automatically learn the center weight corresponding to a hash code. Firstly, we apply the maximum entropy regularizer to prevent one hash center from dominating the loss function, and compute the center weights via projection gradient descent. Secondly, we update neural network parameters by standard back-propagation with fixed center weights. More importantly, the learned center weights can well reflect the proportion of foreground instances in the image. Our method achieves the state-of-the-art performance on the image retrieval benchmarks, and especially improves the mAP by 1.6%-6.4% on the MS COCO dataset.
Self-Supervised Pre-training of Vision Transformers for Dense Prediction Tasks
Jun 07, 2022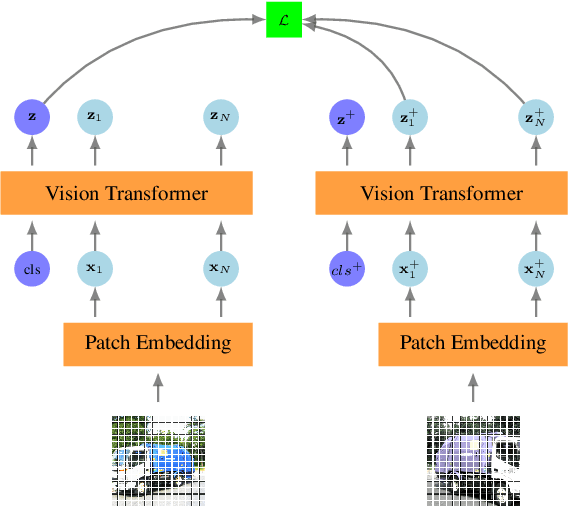
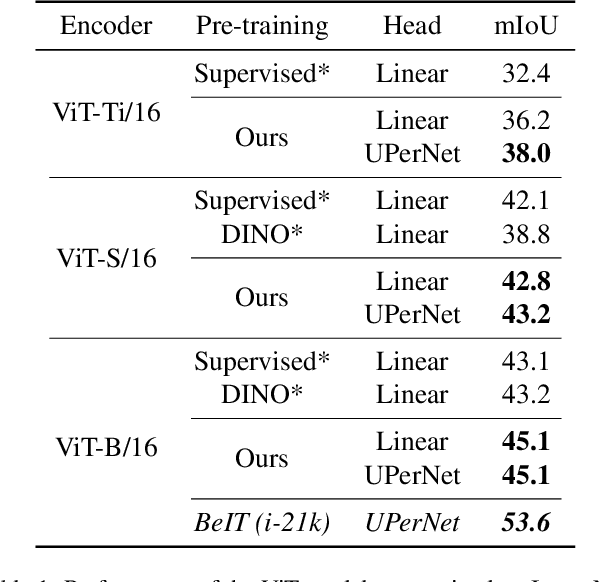
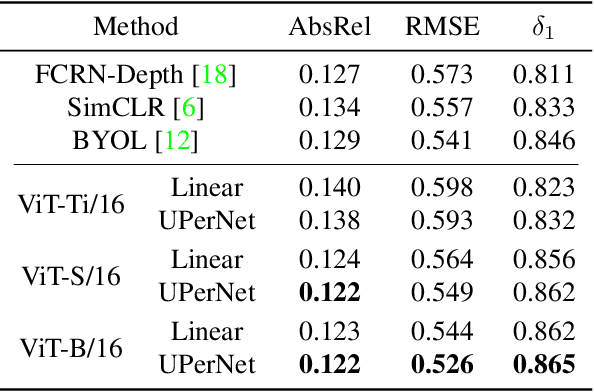
We present a new self-supervised pre-training of Vision Transformers for dense prediction tasks. It is based on a contrastive loss across views that compares pixel-level representations to global image representations. This strategy produces better local features suitable for dense prediction tasks as opposed to contrastive pre-training based on global image representation only. Furthermore, our approach does not suffer from a reduced batch size since the number of negative examples needed in the contrastive loss is in the order of the number of local features. We demonstrate the effectiveness of our pre-training strategy on two dense prediction tasks: semantic segmentation and monocular depth estimation.
Remote Sensing Image Super-resolution and Object Detection: Benchmark and State of the Art
Nov 05, 2021
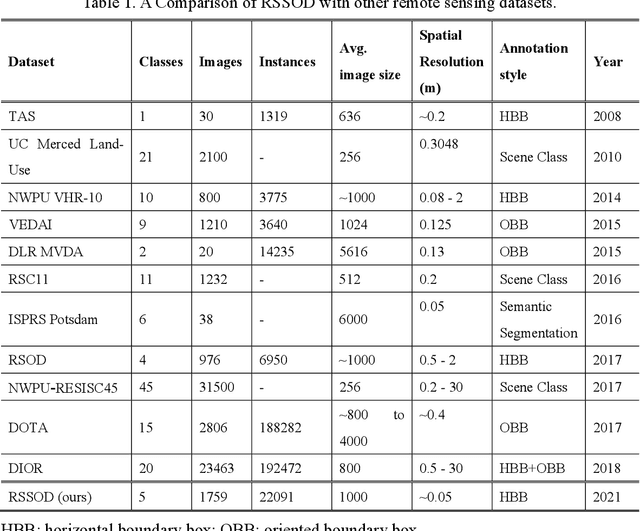
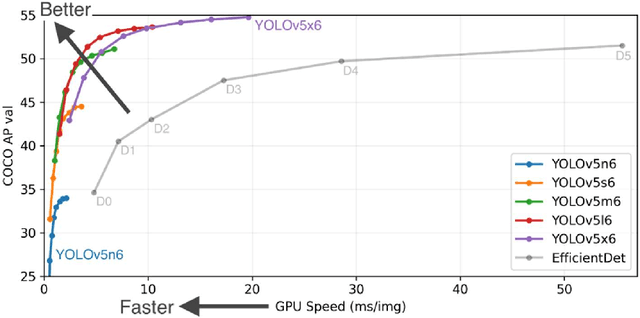
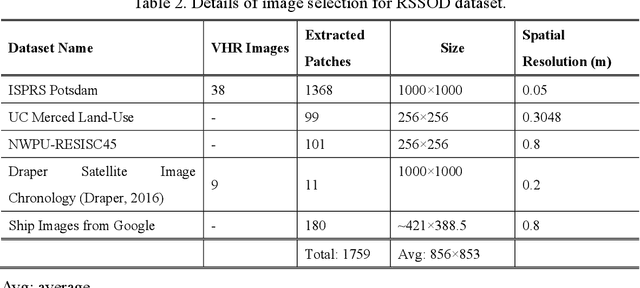
For the past two decades, there have been significant efforts to develop methods for object detection in Remote Sensing (RS) images. In most cases, the datasets for small object detection in remote sensing images are inadequate. Many researchers used scene classification datasets for object detection, which has its limitations; for example, the large-sized objects outnumber the small objects in object categories. Thus, they lack diversity; this further affects the detection performance of small object detectors in RS images. This paper reviews current datasets and object detection methods (deep learning-based) for remote sensing images. We also propose a large-scale, publicly available benchmark Remote Sensing Super-resolution Object Detection (RSSOD) dataset. The RSSOD dataset consists of 1,759 hand-annotated images with 22,091 instances of very high resolution (VHR) images with a spatial resolution of ~0.05 m. There are five classes with varying frequencies of labels per class. The image patches are extracted from satellite images, including real image distortions such as tangential scale distortion and skew distortion. We also propose a novel Multi-class Cyclic super-resolution Generative adversarial network with Residual feature aggregation (MCGR) and auxiliary YOLOv5 detector to benchmark image super-resolution-based object detection and compare with the existing state-of-the-art methods based on image super-resolution (SR). The proposed MCGR achieved state-of-the-art performance for image SR with an improvement of 1.2dB PSNR compared to the current state-of-the-art NLSN method. MCGR achieved best object detection mAPs of 0.758, 0.881, 0.841, and 0.983, respectively, for five-class, four-class, two-class, and single classes, respectively surpassing the performance of the state-of-the-art object detectors YOLOv5, EfficientDet, Faster RCNN, SSD, and RetinaNet.