 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Collaborative Representation for SPD Matrices with Application to Image-Set Classification
Jan 22, 2022
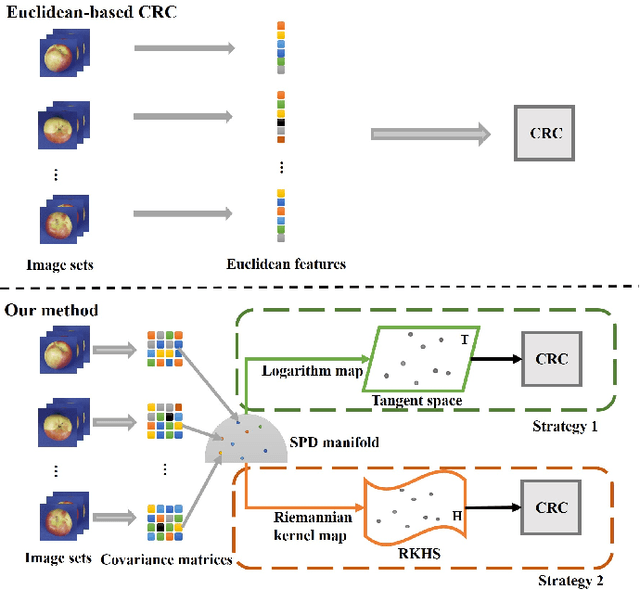
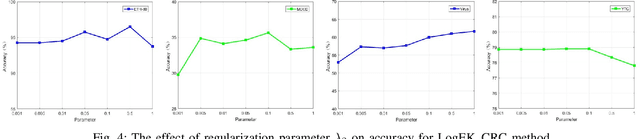
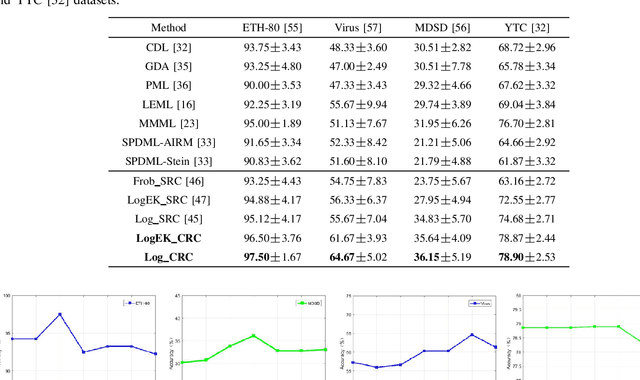
Collaborative representation-based classification (CRC) has demonstrated remarkable progress in the past few years because of its closed-form analytical solutions. However, the existing CRC methods are incapable of processing the nonlinear variational information directly. Recent advances illustrate that how to effectively model these nonlinear variational information and learn invariant representations is an open challenge in the community of computer vision and pattern recognition To this end, we try to design a new algorithm to handle this problem. Firstly, the second-order statistic, i.e., covariance matrix is applied to model the original image sets. Due to the space formed by a set of nonsingular covariance matrices is a well-known Symmetric Positive Definite (SPD) manifold, generalising the Euclidean collaborative representation to the SPD manifold is not an easy task. Then, we devise two strategies to cope with this issue. One attempts to embed the SPD manifold-valued data representations into an associated tangent space via the matrix logarithm map. Another is to embed them into a Reproducing Kernel Hilbert Space (RKHS) by utilizing the Riemannian kernel function. After these two treatments, CRC is applicable to the SPD manifold-valued features. The evaluations on four banchmarking datasets justify its effectiveness.
Segmentation Consistency Training: Out-of-Distribution Generalization for Medical Image Segmentation
May 30, 2022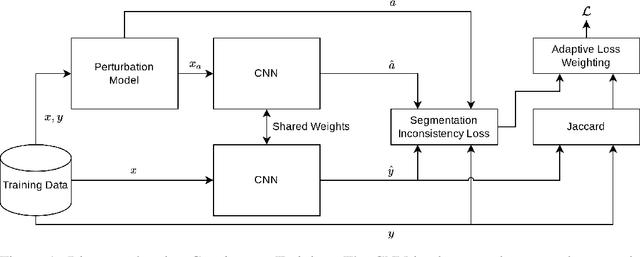
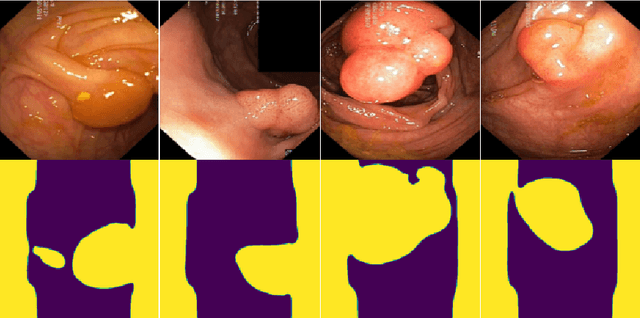

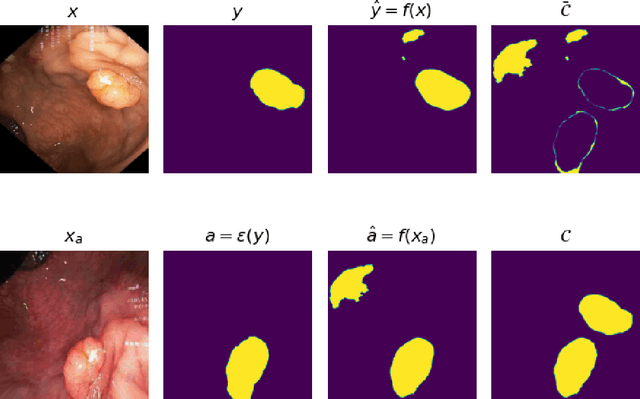
Generalizability is seen as one of the major challenges in deep learning, in particular in the domain of medical imaging, where a change of hospital or in imaging routines can lead to a complete failure of a model. To tackle this, we introduce Consistency Training, a training procedure and alternative to data augmentation based on maximizing models' prediction consistency across augmented and unaugmented data in order to facilitate better out-of-distribution generalization. To this end, we develop a novel region-based segmentation loss function called Segmentation Inconsistency Loss (SIL), which considers the differences between pairs of augmented and unaugmented predictions and labels. We demonstrate that Consistency Training outperforms conventional data augmentation on several out-of-distribution datasets on polyp segmentation, a popular medical task.
PolypConnect: Image inpainting for generating realistic gastrointestinal tract images with polyps
May 30, 2022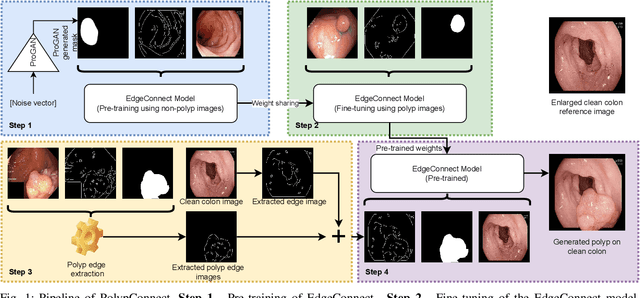



Early identification of a polyp in the lower gastrointestinal (GI) tract can lead to prevention of life-threatening colorectal cancer. Developing computer-aided diagnosis (CAD) systems to detect polyps can improve detection accuracy and efficiency and save the time of the domain experts called endoscopists. Lack of annotated data is a common challenge when building CAD systems. Generating synthetic medical data is an active research area to overcome the problem of having relatively few true positive cases in the medical domain. To be able to efficiently train machine learning (ML) models, which are the core of CAD systems, a considerable amount of data should be used. In this respect, we propose the PolypConnect pipeline, which can convert non-polyp images into polyp images to increase the size of training datasets for training. We present the whole pipeline with quantitative and qualitative evaluations involving endoscopists. The polyp segmentation model trained using synthetic data, and real data shows a 5.1% improvement of mean intersection over union (mIOU), compared to the model trained only using real data. The codes of all the experiments are available on GitHub to reproduce the results.
ReCo: Retrieve and Co-segment for Zero-shot Transfer
Jun 14, 2022
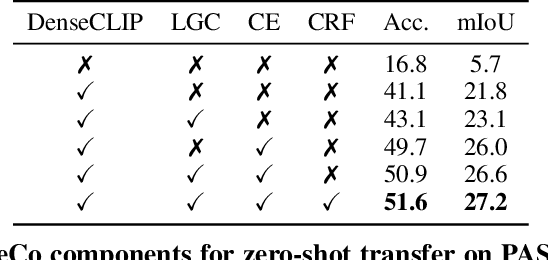
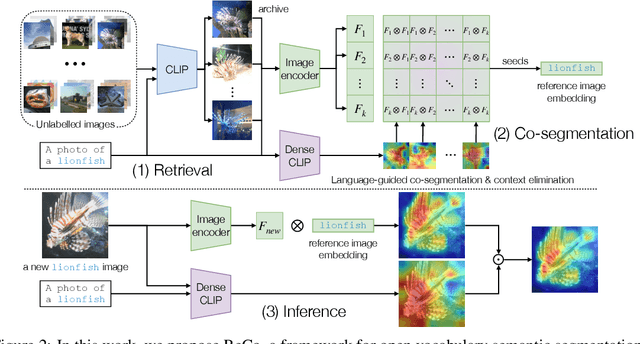
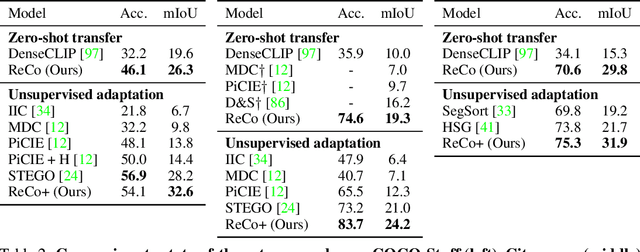
Semantic segmentation has a broad range of applications, but its real-world impact has been significantly limited by the prohibitive annotation costs necessary to enable deployment. Segmentation methods that forgo supervision can side-step these costs, but exhibit the inconvenient requirement to provide labelled examples from the target distribution to assign concept names to predictions. An alternative line of work in language-image pre-training has recently demonstrated the potential to produce models that can both assign names across large vocabularies of concepts and enable zero-shot transfer for classification, but do not demonstrate commensurate segmentation abilities. In this work, we strive to achieve a synthesis of these two approaches that combines their strengths. We leverage the retrieval abilities of one such language-image pre-trained model, CLIP, to dynamically curate training sets from unlabelled images for arbitrary collections of concept names, and leverage the robust correspondences offered by modern image representations to co-segment entities among the resulting collections. The synthetic segment collections are then employed to construct a segmentation model (without requiring pixel labels) whose knowledge of concepts is inherited from the scalable pre-training process of CLIP. We demonstrate that our approach, termed Retrieve and Co-segment (ReCo) performs favourably to unsupervised segmentation approaches while inheriting the convenience of nameable predictions and zero-shot transfer. We also demonstrate ReCo's ability to generate specialist segmenters for extremely rare objects.
Contrastive Feature Loss for Image Prediction
Nov 12, 2021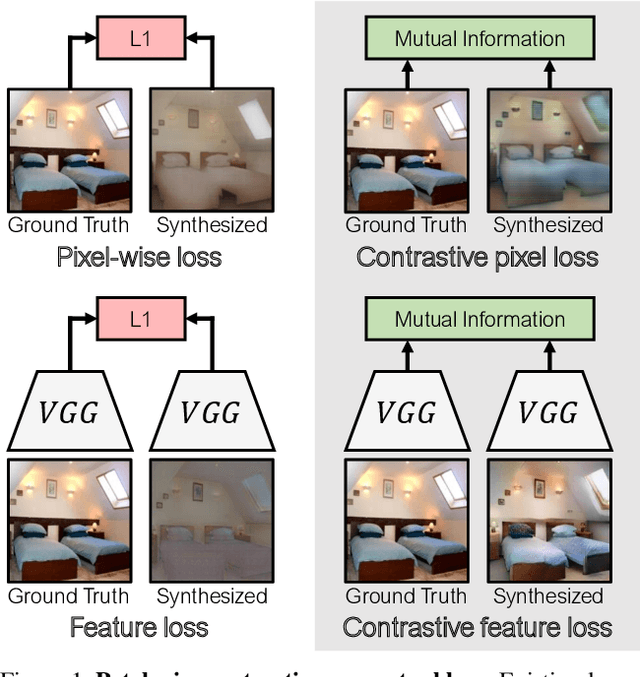
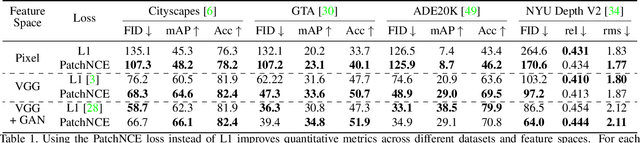
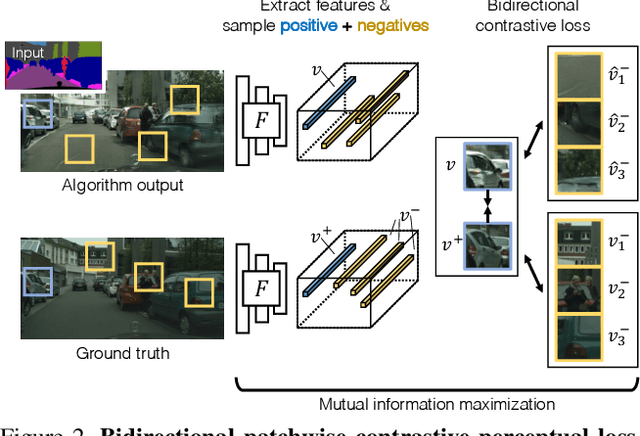
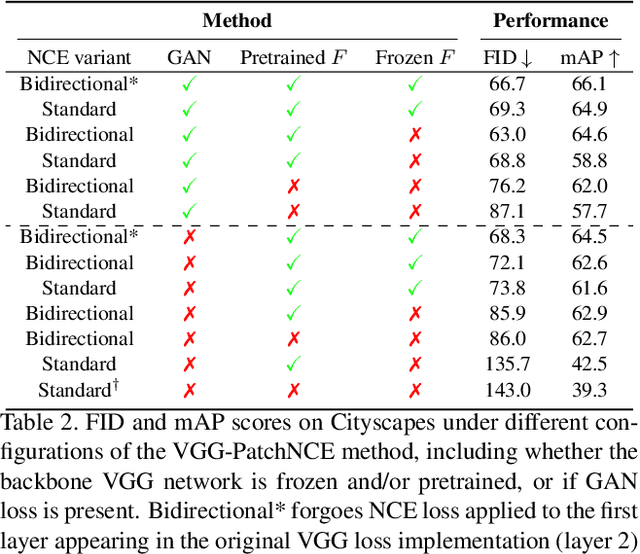
Training supervised image synthesis models requires a critic to compare two images: the ground truth to the result. Yet, this basic functionality remains an open problem. A popular line of approaches uses the L1 (mean absolute error) loss, either in the pixel or the feature space of pretrained deep networks. However, we observe that these losses tend to produce overly blurry and grey images, and other techniques such as GANs need to be employed to fight these artifacts. In this work, we introduce an information theory based approach to measuring similarity between two images. We argue that a good reconstruction should have high mutual information with the ground truth. This view enables learning a lightweight critic to "calibrate" a feature space in a contrastive manner, such that reconstructions of corresponding spatial patches are brought together, while other patches are repulsed. We show that our formulation immediately boosts the perceptual realism of output images when used as a drop-in replacement for the L1 loss, with or without an additional GAN loss.
Patching open-vocabulary models by interpolating weights
Aug 10, 2022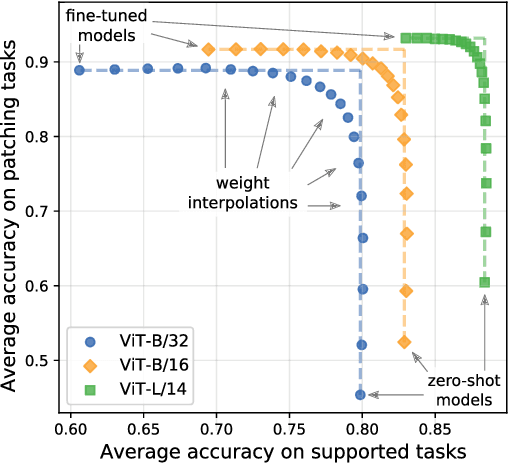

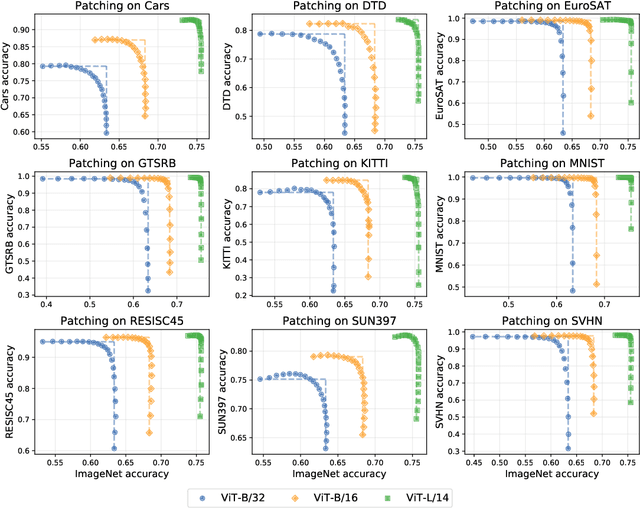

Open-vocabulary models like CLIP achieve high accuracy across many image classification tasks. However, there are still settings where their zero-shot performance is far from optimal. We study model patching, where the goal is to improve accuracy on specific tasks without degrading accuracy on tasks where performance is already adequate. Towards this goal, we introduce PAINT, a patching method that uses interpolations between the weights of a model before fine-tuning and the weights after fine-tuning on a task to be patched. On nine tasks where zero-shot CLIP performs poorly, PAINT increases accuracy by 15 to 60 percentage points while preserving accuracy on ImageNet within one percentage point of the zero-shot model. PAINT also allows a single model to be patched on multiple tasks and improves with model scale. Furthermore, we identify cases of broad transfer, where patching on one task increases accuracy on other tasks even when the tasks have disjoint classes. Finally, we investigate applications beyond common benchmarks such as counting or reducing the impact of typographic attacks on CLIP. Our findings demonstrate that it is possible to expand the set of tasks on which open-vocabulary models achieve high accuracy without re-training them from scratch.
DeepRLS: A Recurrent Network Architecture with Least Squares Implicit Layers for Non-blind Image Deconvolution
Dec 10, 2021
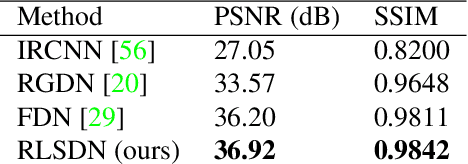
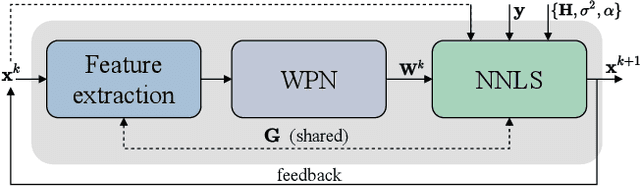
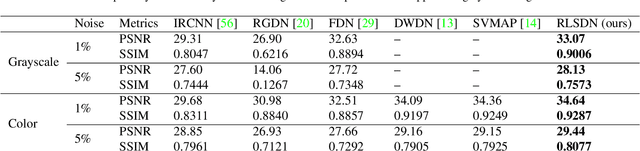
In this work, we study the problem of non-blind image deconvolution and propose a novel recurrent network architecture that leads to very competitive restoration results of high image quality. Motivated by the computational efficiency and robustness of existing large scale linear solvers, we manage to express the solution to this problem as the solution of a series of adaptive non-negative least-squares problems. This gives rise to our proposed Recurrent Least Squares Deconvolution Network (RLSDN) architecture, which consists of an implicit layer that imposes a linear constraint between its input and output. By design, our network manages to serve two important purposes simultaneously. The first is that it implicitly models an effective image prior that can adequately characterize the set of natural images, while the second is that it recovers the corresponding maximum a posteriori (MAP) estimate. Experiments on publicly available datasets, comparing recent state-of-the-art methods, show that our proposed RLSDN approach achieves the best reported performance both for grayscale and color images for all tested scenarios. Furthermore, we introduce a novel training strategy that can be adopted by any network architecture that involves the solution of linear systems as part of its pipeline. Our strategy eliminates completely the need to unroll the iterations required by the linear solver and, thus, it reduces significantly the memory footprint during training. Consequently, this enables the training of deeper network architectures which can further improve the reconstruction results.
Weakly-supervised segmentation of referring expressions
May 12, 2022

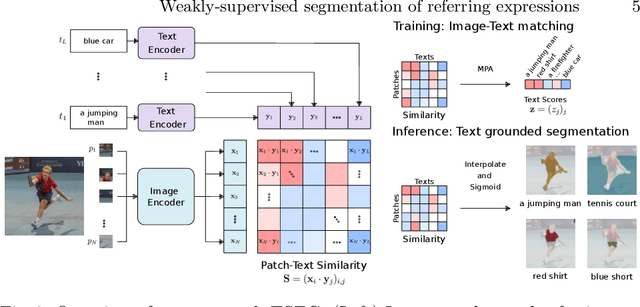
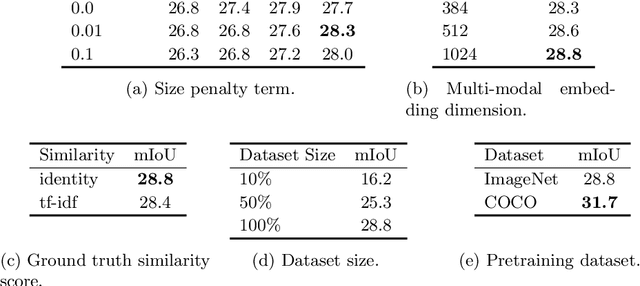
Visual grounding localizes regions (boxes or segments) in the image corresponding to given referring expressions. In this work we address image segmentation from referring expressions, a problem that has so far only been addressed in a fully-supervised setting. A fully-supervised setup, however, requires pixel-wise supervision and is hard to scale given the expense of manual annotation. We therefore introduce a new task of weakly-supervised image segmentation from referring expressions and propose Text grounded semantic SEGgmentation (TSEG) that learns segmentation masks directly from image-level referring expressions without pixel-level annotations. Our transformer-based method computes patch-text similarities and guides the classification objective during training with a new multi-label patch assignment mechanism. The resulting visual grounding model segments image regions corresponding to given natural language expressions. Our approach TSEG demonstrates promising results for weakly-supervised referring expression segmentation on the challenging PhraseCut and RefCOCO datasets. TSEG also shows competitive performance when evaluated in a zero-shot setting for semantic segmentation on Pascal VOC.
Automatic Multi-Class Cardiovascular Magnetic Resonance Image Quality Assessment using Unsupervised Domain Adaptation in Spatial and Frequency Domains
Dec 13, 2021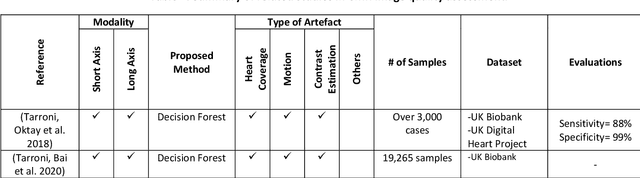
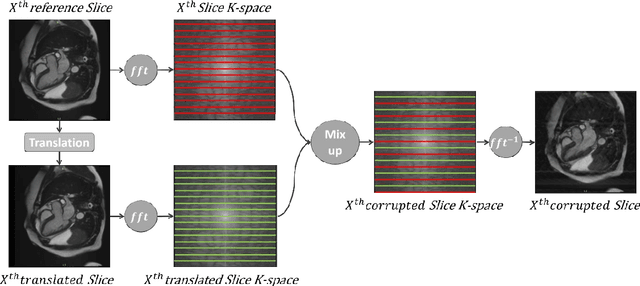
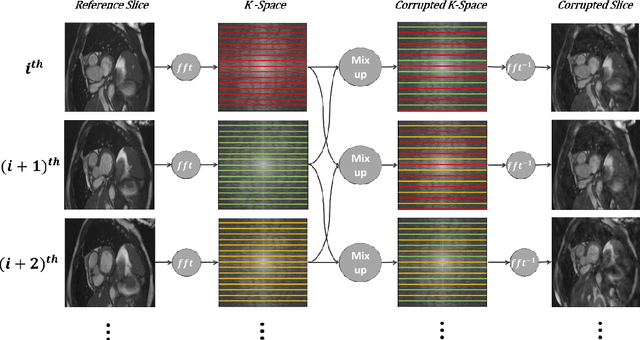
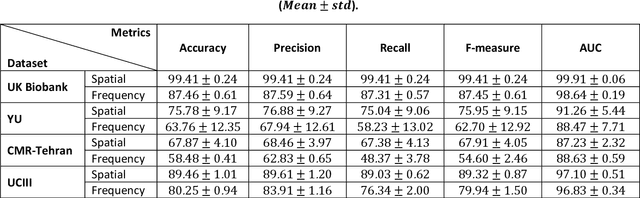
Population imaging studies rely upon good quality medical imagery before downstream image quantification. This study provides an automated approach to assess image quality from cardiovascular magnetic resonance (CMR) imaging at scale. We identify four common CMR imaging artefacts, including respiratory motion, cardiac motion, Gibbs ringing, and aliasing. The model can deal with images acquired in different views, including two, three, and four-chamber long-axis and short-axis cine CMR images. Two deep learning-based models in spatial and frequency domains are proposed. Besides recognising these artefacts, the proposed models are suitable to the common challenges of not having access to data labels. An unsupervised domain adaptation method and a Fourier-based convolutional neural network are proposed to overcome these challenges. We show that the proposed models reliably allow for CMR image quality assessment. The accuracies obtained for the spatial model in supervised and weakly supervised learning are 99.41+0.24 and 96.37+0.66 for the UK Biobank dataset, respectively. Using unsupervised domain adaptation can somewhat overcome the challenge of not having access to the data labels. The maximum achieved domain gap coverage in unsupervised domain adaptation is 16.86%. Domain adaptation can significantly improve a 5-class classification task and deal with considerable domain shift without data labels. Increasing the speed of training and testing can be achieved with the proposed model in the frequency domain. The frequency-domain model can achieve the same accuracy yet 1.548 times faster than the spatial model. This model can also be used directly on k-space data, and there is no need for image reconstruction.
Fighting Fire with Fire: Avoiding DNN Shortcuts through Priming
Jun 22, 2022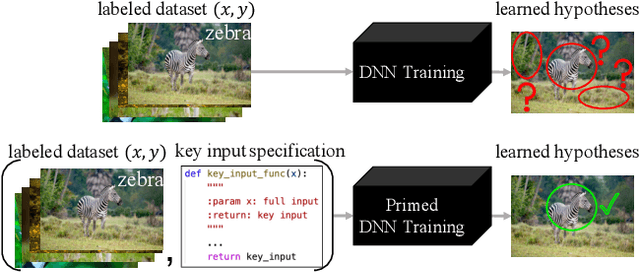

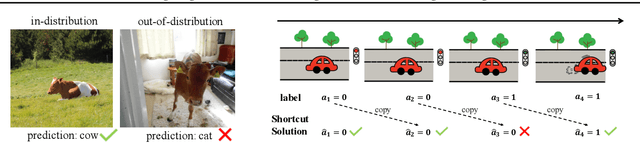
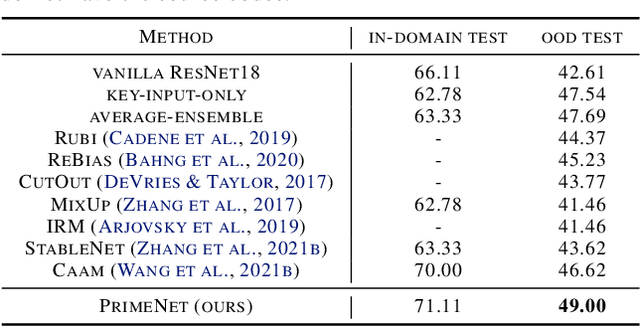
Across applications spanning supervised classification and sequential control, deep learning has been reported to find "shortcut" solutions that fail catastrophically under minor changes in the data distribution. In this paper, we show empirically that DNNs can be coaxed to avoid poor shortcuts by providing an additional "priming" feature computed from key input features, usually a coarse output estimate. Priming relies on approximate domain knowledge of these task-relevant key input features, which is often easy to obtain in practical settings. For example, one might prioritize recent frames over past frames in a video input for visual imitation learning, or salient foreground over background pixels for image classification. On NICO image classification, MuJoCo continuous control, and CARLA autonomous driving, our priming strategy works significantly better than several popular state-of-the-art approaches for feature selection and data augmentation. We connect these empirical findings to recent theoretical results on DNN optimization, and argue theoretically that priming distracts the optimizer away from poor shortcuts by creating better, simpler shortcuts.