 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Segmentation Consistency Training: Out-of-Distribution Generalization for Medical Image Segmentation
May 30, 2022
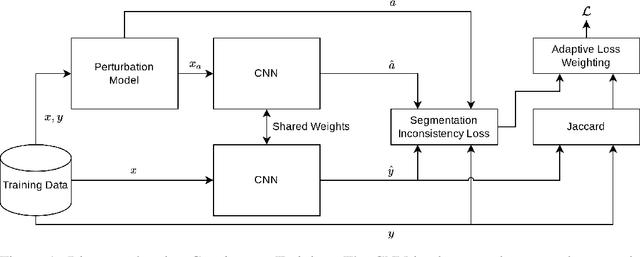
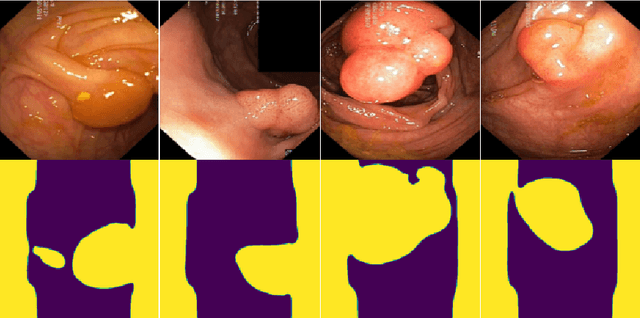

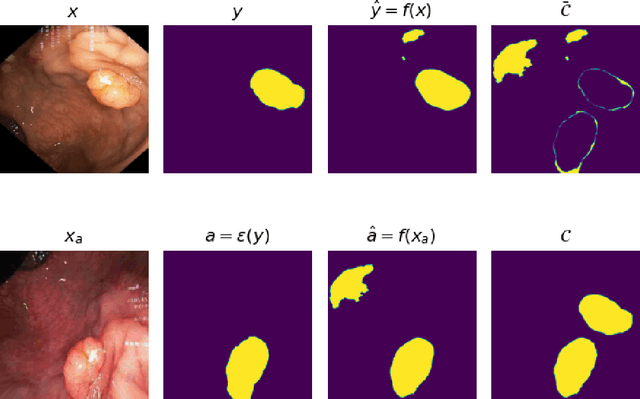
Generalizability is seen as one of the major challenges in deep learning, in particular in the domain of medical imaging, where a change of hospital or in imaging routines can lead to a complete failure of a model. To tackle this, we introduce Consistency Training, a training procedure and alternative to data augmentation based on maximizing models' prediction consistency across augmented and unaugmented data in order to facilitate better out-of-distribution generalization. To this end, we develop a novel region-based segmentation loss function called Segmentation Inconsistency Loss (SIL), which considers the differences between pairs of augmented and unaugmented predictions and labels. We demonstrate that Consistency Training outperforms conventional data augmentation on several out-of-distribution datasets on polyp segmentation, a popular medical task.
Semantic Self-adaptation: Enhancing Generalization with a Single Sample
Aug 10, 2022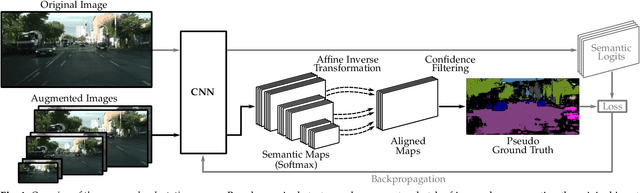

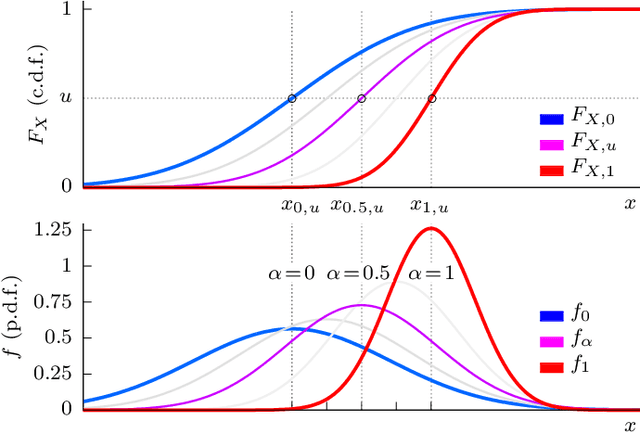
Despite years of research, out-of-domain generalization remains a critical weakness of deep networks for semantic segmentation. Previous studies relied on the assumption of a static model, i.e. once the training process is complete, model parameters remain fixed at test time. In this work, we challenge this premise with a self-adaptive approach for semantic segmentation that adjusts the inference process to each input sample. Self-adaptation operates on two levels. First, it employs a self-supervised loss that customizes the parameters of convolutional layers in the network to the input image. Second, in Batch Normalization layers, self-adaptation approximates the mean and the variance of the entire test data, which is assumed unavailable. It achieves this by interpolating between the training and the reference distribution derived from a single test sample. To empirically analyze our self-adaptive inference strategy, we develop and follow a rigorous evaluation protocol that addresses serious limitations of previous work. Our extensive analysis leads to a surprising conclusion: Using a standard training procedure, self-adaptation significantly outperforms strong baselines and sets new state-of-the-art accuracy on multi-domain benchmarks. Our study suggests that self-adaptive inference may complement the established practice of model regularization at training time for improving deep network generalization to out-of-domain data.
PolypConnect: Image inpainting for generating realistic gastrointestinal tract images with polyps
May 30, 2022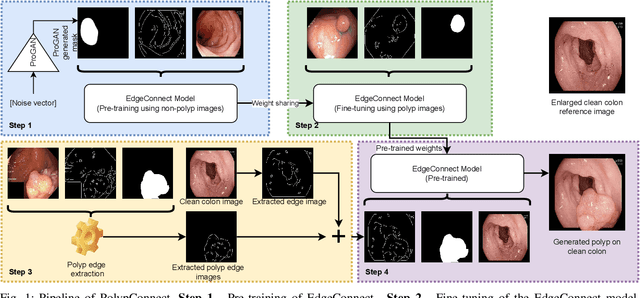



Early identification of a polyp in the lower gastrointestinal (GI) tract can lead to prevention of life-threatening colorectal cancer. Developing computer-aided diagnosis (CAD) systems to detect polyps can improve detection accuracy and efficiency and save the time of the domain experts called endoscopists. Lack of annotated data is a common challenge when building CAD systems. Generating synthetic medical data is an active research area to overcome the problem of having relatively few true positive cases in the medical domain. To be able to efficiently train machine learning (ML) models, which are the core of CAD systems, a considerable amount of data should be used. In this respect, we propose the PolypConnect pipeline, which can convert non-polyp images into polyp images to increase the size of training datasets for training. We present the whole pipeline with quantitative and qualitative evaluations involving endoscopists. The polyp segmentation model trained using synthetic data, and real data shows a 5.1% improvement of mean intersection over union (mIOU), compared to the model trained only using real data. The codes of all the experiments are available on GitHub to reproduce the results.
Practical Insights of Repairing Model Problems on Image Classification
May 14, 2022
Additional training of a deep learning model can cause negative effects on the results, turning an initially positive sample into a negative one (degradation). Such degradation is possible in real-world use cases due to the diversity of sample characteristics. That is, a set of samples is a mixture of critical ones which should not be missed and less important ones. Therefore, we cannot understand the performance by accuracy alone. While existing research aims to prevent a model degradation, insights into the related methods are needed to grasp their benefits and limitations. In this talk, we will present implications derived from a comparison of methods for reducing degradation. Especially, we formulated use cases for industrial settings in terms of arrangements of a data set. The results imply that a practitioner should care about better method continuously considering dataset availability and life cycle of an AI system because of a trade-off between accuracy and preventing degradation.
Supervision Exists Everywhere: A Data Efficient Contrastive Language-Image Pre-training Paradigm
Oct 11, 2021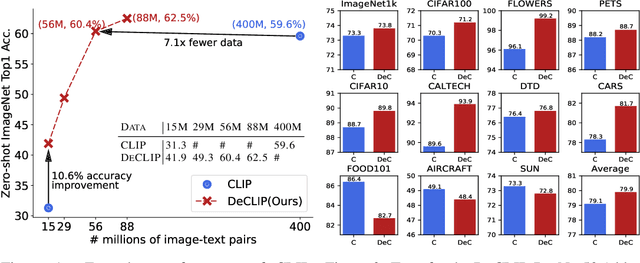
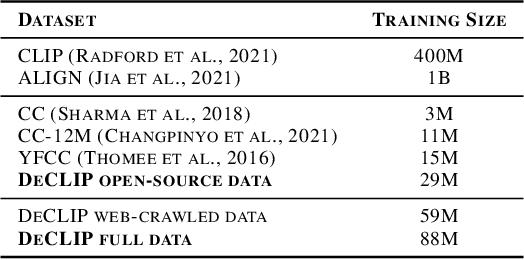
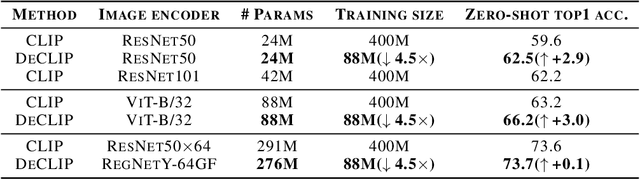
Recently, large-scale Contrastive Language-Image Pre-training (CLIP) has attracted unprecedented attention for its impressive zero-shot recognition ability and excellent transferability to downstream tasks. However, CLIP is quite data-hungry and requires 400M image-text pairs for pre-training, thereby restricting its adoption. This work proposes a novel training paradigm, Data efficient CLIP (DeCLIP), to alleviate this limitation. We demonstrate that by carefully utilizing the widespread supervision among the image-text pairs, our De-CLIP can learn generic visual features more efficiently. Instead of using the single image-text contrastive supervision, we fully exploit data potential through the use of (1) self-supervision within each modality; (2) multi-view supervision across modalities; (3) nearest-neighbor supervision from other similar pairs. Benefiting from intrinsic supervision, our DeCLIP-ResNet50 can achieve 60.4% zero-shot top1 accuracy on ImageNet, which is 0.8% above the CLIP-ResNet50 while using 7.1 x fewer data. Our DeCLIP-ResNet50 outperforms its counterpart in 8 out of 11 visual datasets when transferred to downstream tasks. Moreover, Scaling up the model and computing also works well in our framework.Our code, dataset and models are released at: https://github.com/Sense-GVT/DeCLIP
SSformer: A Lightweight Transformer for Semantic Segmentation
Aug 03, 2022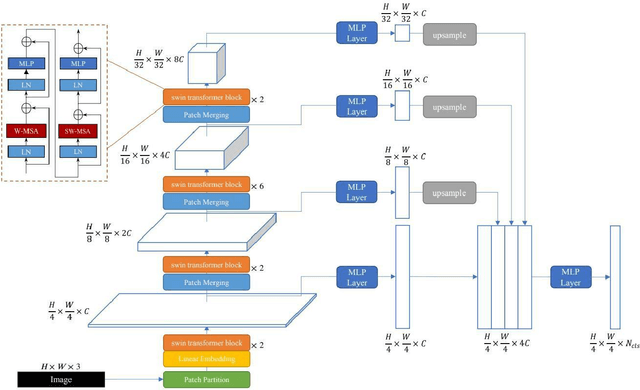


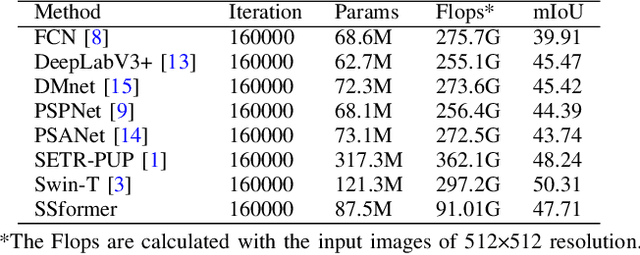
It is well believed that Transformer performs better in semantic segmentation compared to convolutional neural networks. Nevertheless, the original Vision Transformer may lack of inductive biases of local neighborhoods and possess a high time complexity. Recently, Swin Transformer sets a new record in various vision tasks by using hierarchical architecture and shifted windows while being more efficient. However, as Swin Transformer is specifically designed for image classification, it may achieve suboptimal performance on dense prediction-based segmentation task. Further, simply combing Swin Transformer with existing methods would lead to the boost of model size and parameters for the final segmentation model. In this paper, we rethink the Swin Transformer for semantic segmentation, and design a lightweight yet effective transformer model, called SSformer. In this model, considering the inherent hierarchical design of Swin Transformer, we propose a decoder to aggregate information from different layers, thus obtaining both local and global attentions. Experimental results show the proposed SSformer yields comparable mIoU performance with state-of-the-art models, while maintaining a smaller model size and lower compute.
Advancing Plain Vision Transformer Towards Remote Sensing Foundation Model
Aug 10, 2022
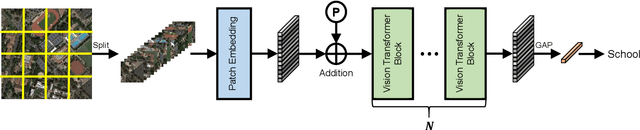
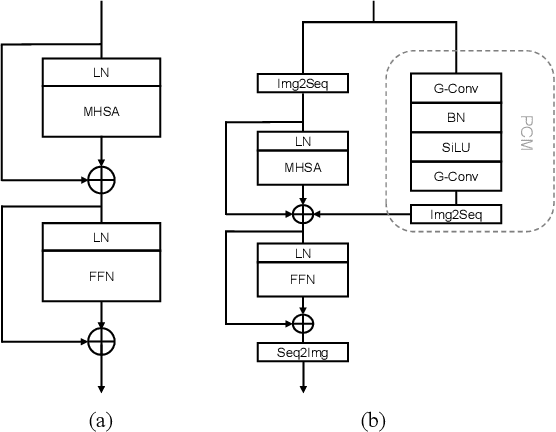
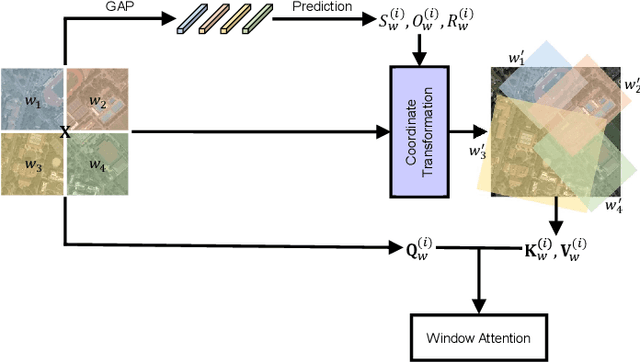
Large-scale vision foundation models have made significant progress in visual tasks on natural images, where the vision transformers are the primary choice for their good scalability and representation ability. However, the utilization of large models in the remote sensing (RS) community remains under-explored where existing models are still at small-scale, which limits the performance. In this paper, we resort to plain vision transformers with about 100 million parameters and make the first attempt to propose large vision models customized for RS tasks and explore how such large models perform. Specifically, to handle the large image size and objects of various orientations in RS images, we propose a new rotated varied-size window attention to substitute the original full attention in transformers, which could significantly reduce the computational cost and memory footprint while learn better object representation by extracting rich context from the generated diverse windows. Experiments on detection tasks demonstrate the superiority of our model over all state-of-the-art models, achieving 81.16% mAP on the DOTA-V1.0 dataset. The results of our models on downstream classification and segmentation tasks also demonstrate competitive performance compared with the existing advanced methods. Further experiments show the advantages of our models on computational complexity and few-shot learning.
Learned Image Compression with Separate Hyperprior Decoders
Oct 31, 2021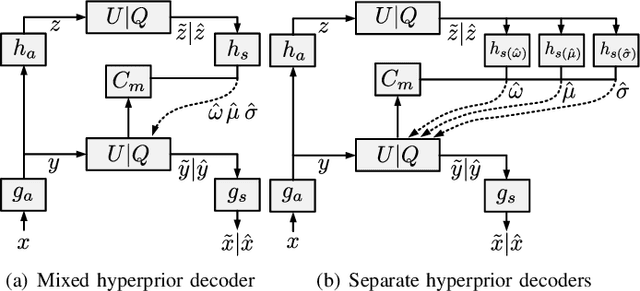
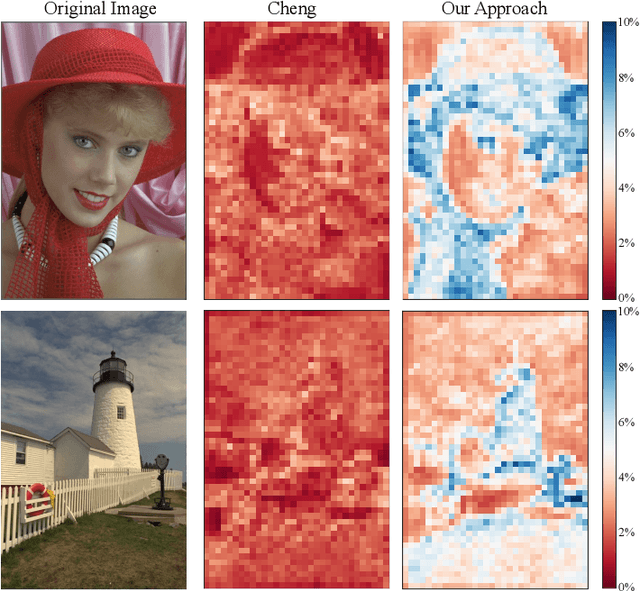
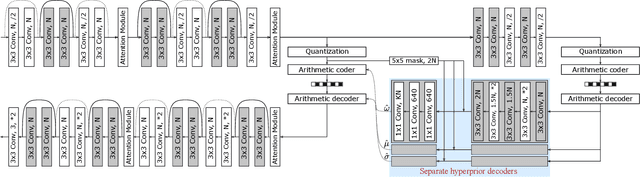
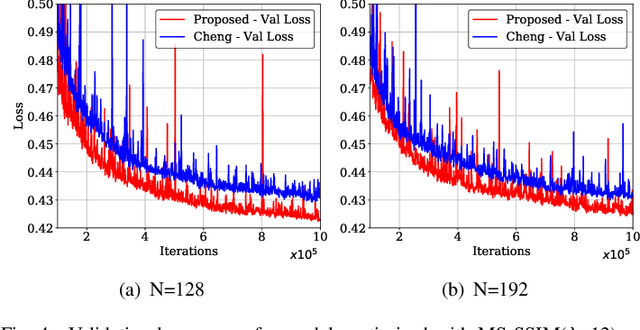
Learned image compression techniques have achieved considerable development in recent years. In this paper, we find that the performance bottleneck lies in the use of a single hyperprior decoder, in which case the ternary Gaussian model collapses to a binary one. To solve this, we propose to use three hyperprior decoders to separate the decoding process of the mixed parameters in discrete Gaussian mixture likelihoods, achieving more accurate parameters estimation. Experimental results demonstrate the proposed method optimized by MS-SSIM achieves on average 3.36% BD-rate reduction compared with state-of-the-art approach. The contribution of the proposed method to the coding time and FLOPs is negligible.
ALBench: A Framework for Evaluating Active Learning in Object Detection
Aug 10, 2022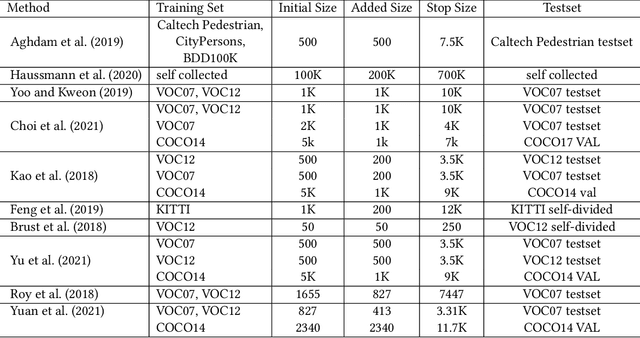
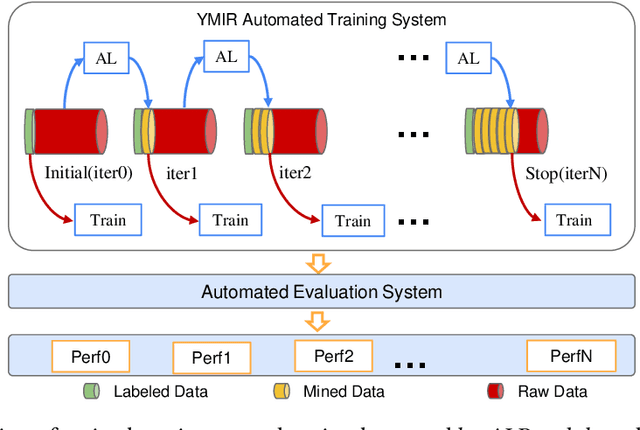
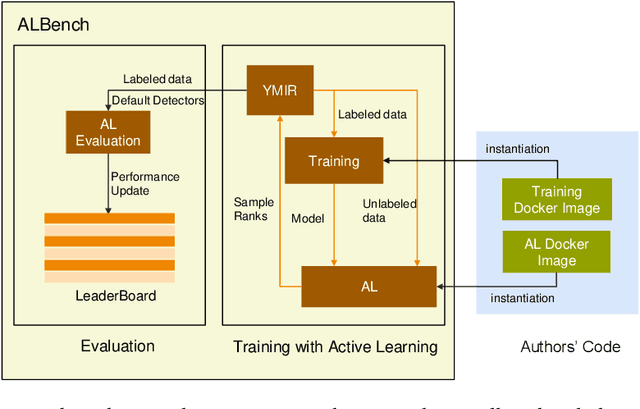
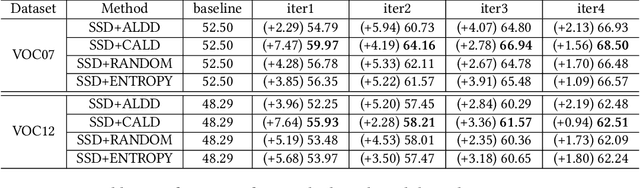
Active learning is an important technology for automated machine learning systems. In contrast to Neural Architecture Search (NAS) which aims at automating neural network architecture design, active learning aims at automating training data selection. It is especially critical for training a long-tailed task, in which positive samples are sparsely distributed. Active learning alleviates the expensive data annotation issue through incrementally training models powered with efficient data selection. Instead of annotating all unlabeled samples, it iteratively selects and annotates the most valuable samples. Active learning has been popular in image classification, but has not been fully explored in object detection. Most of current approaches on object detection are evaluated with different settings, making it difficult to fairly compare their performance. To facilitate the research in this field, this paper contributes an active learning benchmark framework named as ALBench for evaluating active learning in object detection. Developed on an automatic deep model training system, this ALBench framework is easy-to-use, compatible with different active learning algorithms, and ensures the same training and testing protocols. We hope this automated benchmark system help researchers to easily reproduce literature's performance and have objective comparisons with prior arts. The code will be release through Github.
COBRA: Cpu-Only aBdominal oRgan segmentAtion
Jul 21, 2022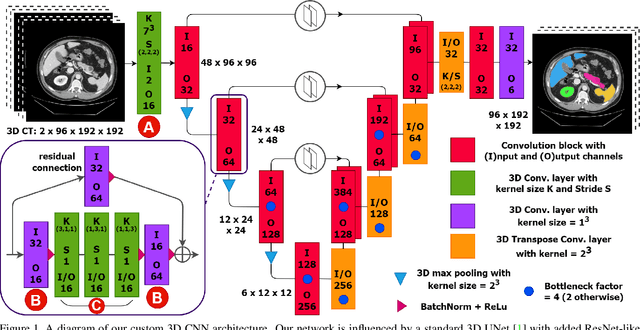

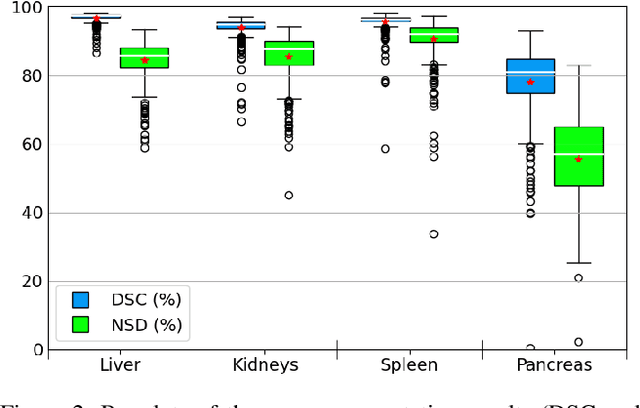
Abdominal organ segmentation is a difficult and time-consuming task. To reduce the burden on clinical experts, fully-automated methods are highly desirable. Current approaches are dominated by Convolutional Neural Networks (CNNs) however the computational requirements and the need for large data sets limit their application in practice. By implementing a small and efficient custom 3D CNN, compiling the trained model and optimizing the computational graph: our approach produces high accuracy segmentations (Dice Similarity Coefficient (%): Liver: 97.3$\pm$1.3, Kidneys: 94.8$\pm$3.6, Spleen: 96.4$\pm$3.0, Pancreas: 80.9$\pm$10.1) at a rate of 1.6 seconds per image. Crucially, we are able to perform segmentation inference solely on CPU (no GPU required), thereby facilitating easy and widespread deployment of the model without specialist hardware.