 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Predict, Prevent, and Evaluate: Disentangled Text-Driven Image Manipulation Empowered by Pre-Trained Vision-Language Model
Nov 26, 2021
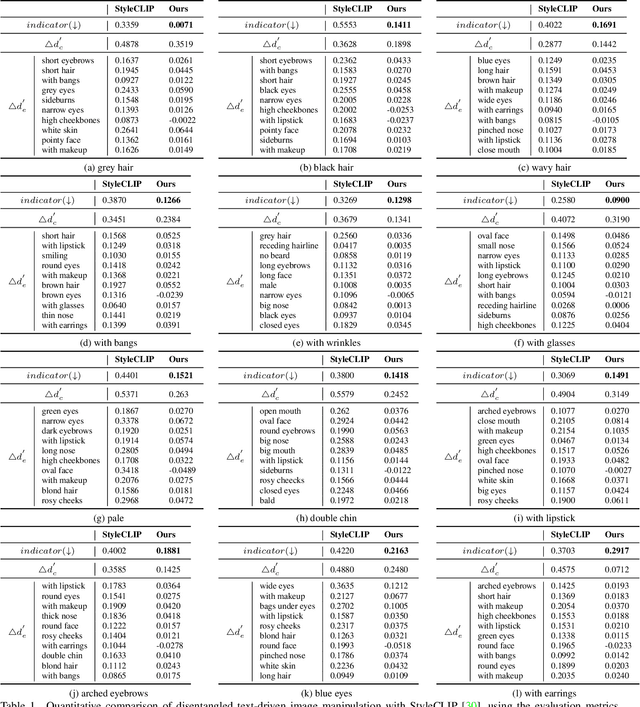
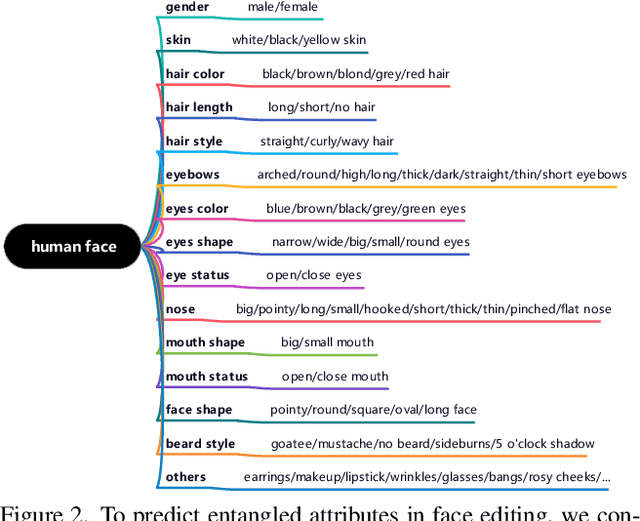
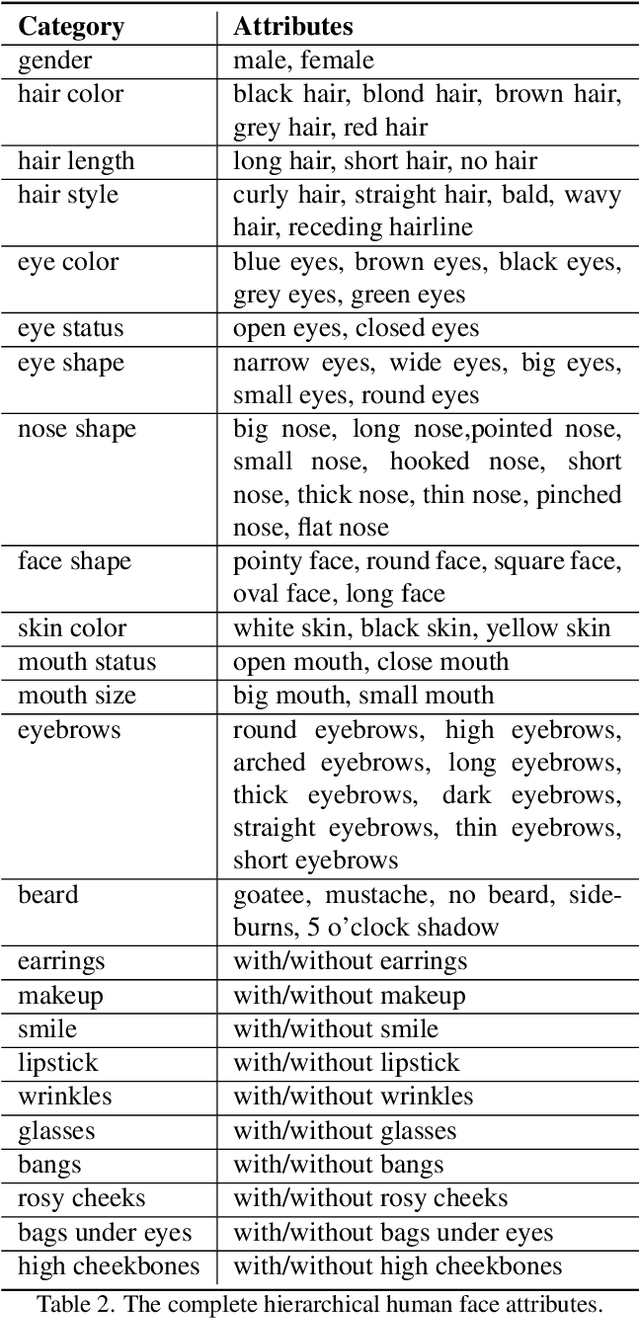

To achieve disentangled image manipulation, previous works depend heavily on manual annotation. Meanwhile, the available manipulations are limited to a pre-defined set the models were trained for. In this paper, we propose a novel framework, i.e., Predict, Prevent, and Evaluate (PPE), for disentangled text-driven image manipulation, which does not need manual annotation and thus is not limited to fixed manipulations. Our method approaches the targets by deeply exploiting the power of the large scale pre-trained vision-language model CLIP. Concretely, we firstly Predict the possibly entangled attributes for a given text command. Then, based on the predicted attributes, we introduce an entanglement loss to Prevent entanglements during training. Finally, we propose a new evaluation metric to Evaluate the disentangled image manipulation. We verify the effectiveness of our method on the challenging face editing task. Extensive experiments show that the proposed PPE framework achieves much better quantitative and qualitative results than the up-to-date StyleCLIP baseline.
AFTer-UNet: Axial Fusion Transformer UNet for Medical Image Segmentation
Oct 20, 2021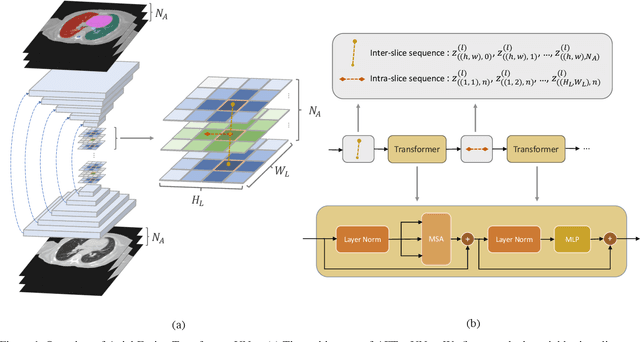
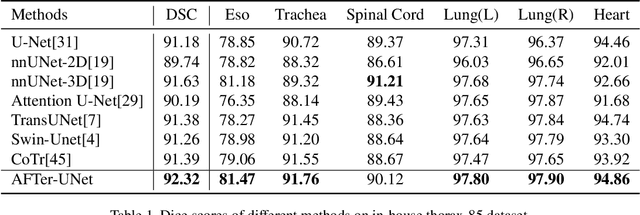

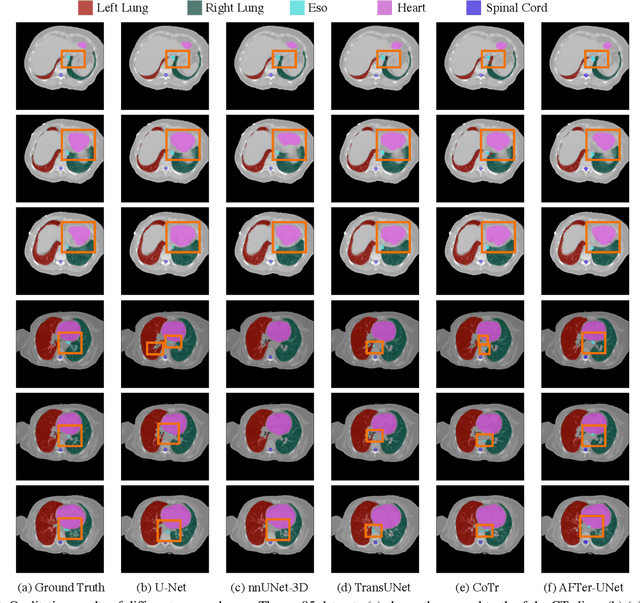
Recent advances in transformer-based models have drawn attention to exploring these techniques in medical image segmentation, especially in conjunction with the U-Net model (or its variants), which has shown great success in medical image segmentation, under both 2D and 3D settings. Current 2D based methods either directly replace convolutional layers with pure transformers or consider a transformer as an additional intermediate encoder between the encoder and decoder of U-Net. However, these approaches only consider the attention encoding within one single slice and do not utilize the axial-axis information naturally provided by a 3D volume. In the 3D setting, convolution on volumetric data and transformers both consume large GPU memory. One has to either downsample the image or use cropped local patches to reduce GPU memory usage, which limits its performance. In this paper, we propose Axial Fusion Transformer UNet (AFTer-UNet), which takes both advantages of convolutional layers' capability of extracting detailed features and transformers' strength on long sequence modeling. It considers both intra-slice and inter-slice long-range cues to guide the segmentation. Meanwhile, it has fewer parameters and takes less GPU memory to train than the previous transformer-based models. Extensive experiments on three multi-organ segmentation datasets demonstrate that our method outperforms current state-of-the-art methods.
One-shot Generative Prior Learned from Hankel-k-space for Parallel Imaging Reconstruction
Aug 15, 2022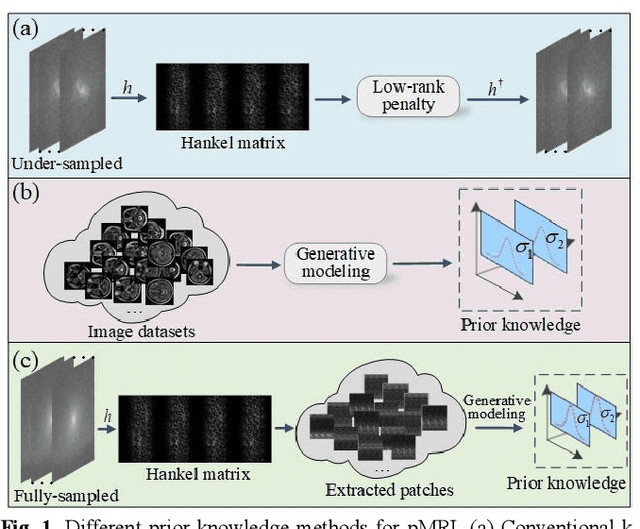
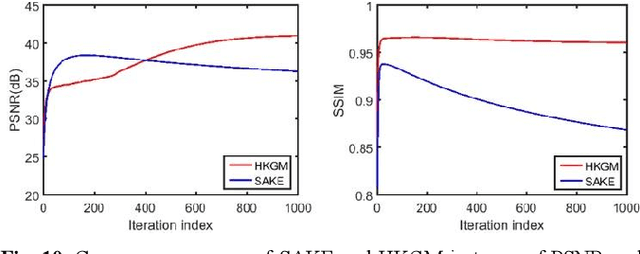
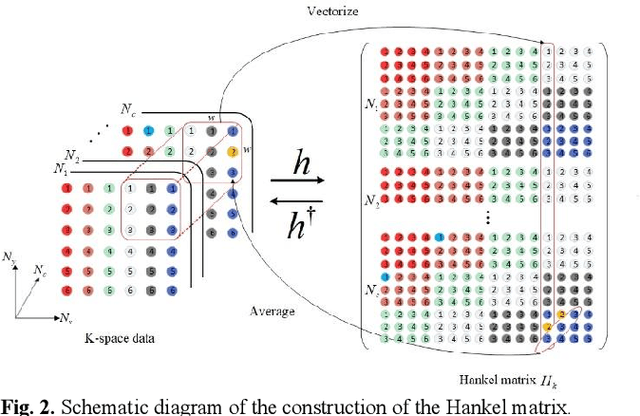
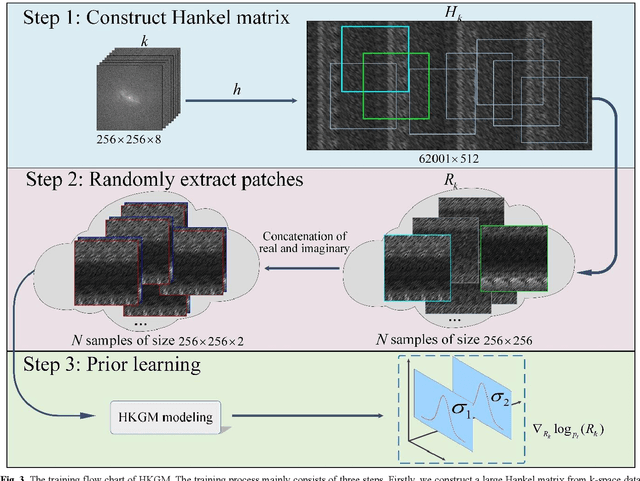
Magnetic resonance imaging serves as an essential tool for clinical diagnosis. However, it suffers from a long acquisition time. The utilization of deep learning, especially the deep generative models, offers aggressive acceleration and better reconstruction in magnetic resonance imaging. Nevertheless, learning the data distribution as prior knowledge and reconstructing the image from limited data remains challenging. In this work, we propose a novel Hankel-k-space generative model (HKGM), which can generate samples from a training set of as little as one k-space data. At the prior learning stage, we first construct a large Hankel matrix from k-space data, then extract multiple structured k-space patches from the large Hankel matrix to capture the internal distribution among different patches. Extracting patches from a Hankel matrix enables the generative model to be learned from redundant and low-rank data space. At the iterative reconstruction stage, it is observed that the desired solution obeys the learned prior knowledge. The intermediate reconstruction solution is updated by taking it as the input of the generative model. The updated result is then alternatively operated by imposing low-rank penalty on its Hankel matrix and data consistency con-strain on the measurement data. Experimental results confirmed that the internal statistics of patches within a single k-space data carry enough information for learning a powerful generative model and provide state-of-the-art reconstruction.
Temporal extrapolation of heart wall segmentation in cardiac magnetic resonance images via pixel tracking
Jul 30, 2022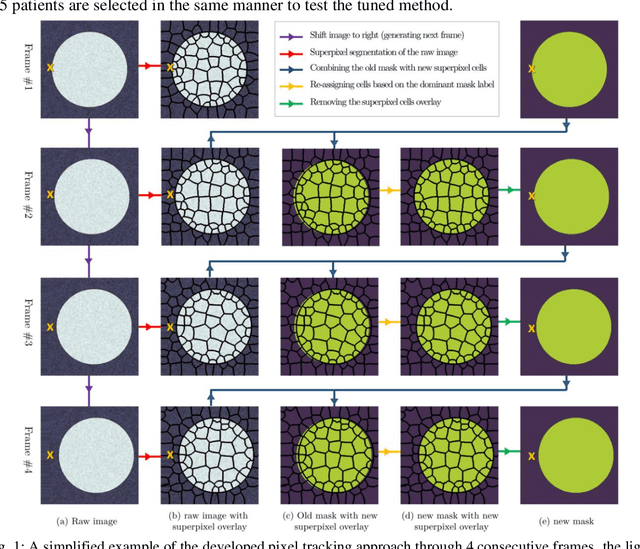
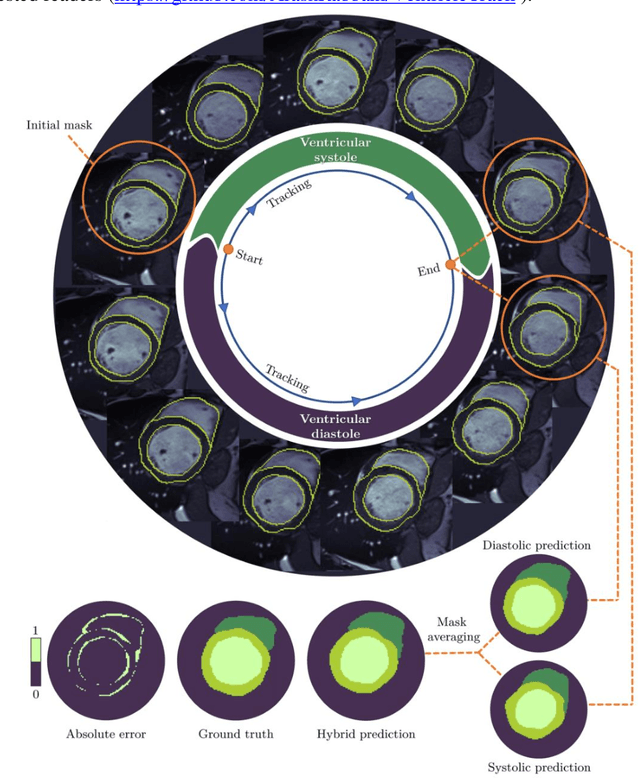
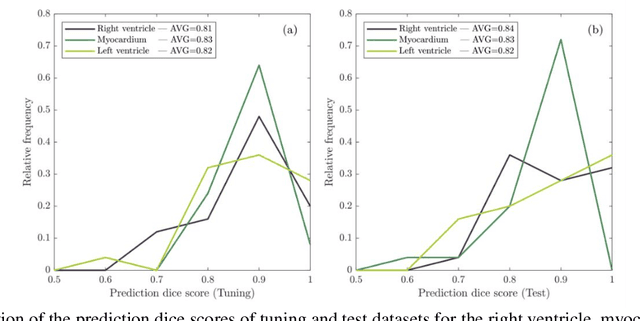
In this study, we have tailored a pixel tracking method for temporal extrapolation of the ventricular segmentation masks in cardiac magnetic resonance images. The pixel tracking process starts from the end-diastolic frame of the heart cycle using the available manually segmented images to predict the end-systolic segmentation mask. The superpixels approach is used to divide the raw images into smaller cells and in each time frame, new labels are assigned to the image cells which leads to tracking the movement of the heart wall elements through different frames. The tracked masks at the end of systole are compared with the already available manually segmented masks and dice scores are found to be between 0.81 to 0.84. Considering the fact that the proposed method does not necessarily require a training dataset, it could be an attractive alternative approach to deep learning segmentation methods in scenarios where training data are limited.
Quantifying the Knowledge in a DNN to Explain Knowledge Distillation for Classification
Aug 18, 2022
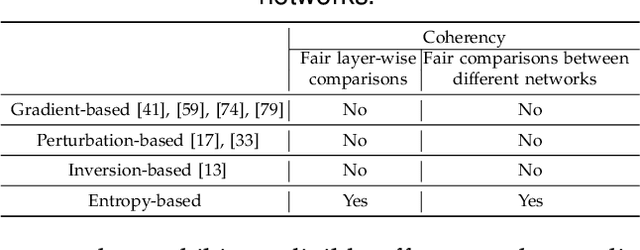
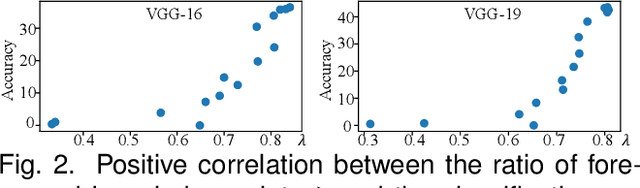
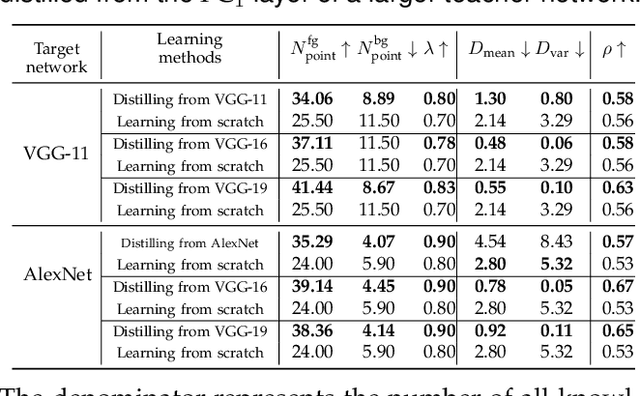
Compared to traditional learning from scratch, knowledge distillation sometimes makes the DNN achieve superior performance. This paper provides a new perspective to explain the success of knowledge distillation, i.e., quantifying knowledge points encoded in intermediate layers of a DNN for classification, based on the information theory. To this end, we consider the signal processing in a DNN as the layer-wise information discarding. A knowledge point is referred to as an input unit, whose information is much less discarded than other input units. Thus, we propose three hypotheses for knowledge distillation based on the quantification of knowledge points. 1. The DNN learning from knowledge distillation encodes more knowledge points than the DNN learning from scratch. 2. Knowledge distillation makes the DNN more likely to learn different knowledge points simultaneously. In comparison, the DNN learning from scratch tends to encode various knowledge points sequentially. 3. The DNN learning from knowledge distillation is often optimized more stably than the DNN learning from scratch. In order to verify the above hypotheses, we design three types of metrics with annotations of foreground objects to analyze feature representations of the DNN, \textit{i.e.} the quantity and the quality of knowledge points, the learning speed of different knowledge points, and the stability of optimization directions. In experiments, we diagnosed various DNNs for different classification tasks, i.e., image classification, 3D point cloud classification, binary sentiment classification, and question answering, which verified above hypotheses.
Attribute-specific Control Units in StyleGAN for Fine-grained Image Manipulation
Nov 25, 2021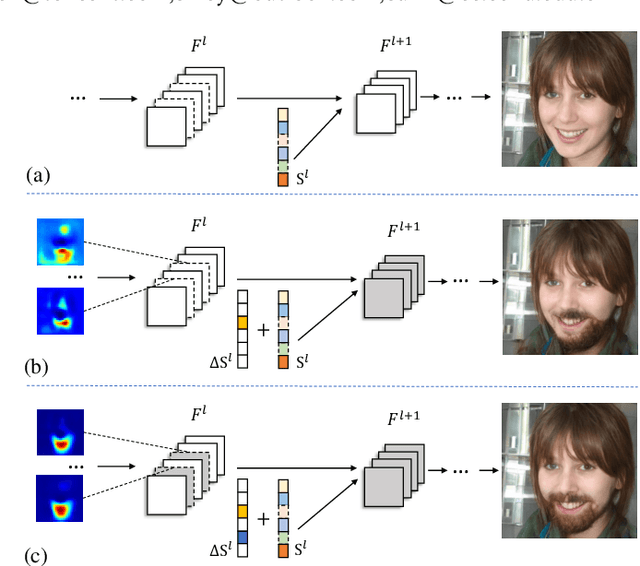



Image manipulation with StyleGAN has been an increasing concern in recent years.Recent works have achieved tremendous success in analyzing several semantic latent spaces to edit the attributes of the generated images.However, due to the limited semantic and spatial manipulation precision in these latent spaces, the existing endeavors are defeated in fine-grained StyleGAN image manipulation, i.e., local attribute translation.To address this issue, we discover attribute-specific control units, which consist of multiple channels of feature maps and modulation styles. Specifically, we collaboratively manipulate the modulation style channels and feature maps in control units rather than individual ones to obtain the semantic and spatial disentangled controls. Furthermore, we propose a simple yet effective method to detect the attribute-specific control units. We move the modulation style along a specific sparse direction vector and replace the filter-wise styles used to compute the feature maps to manipulate these control units. We evaluate our proposed method in various face attribute manipulation tasks. Extensive qualitative and quantitative results demonstrate that our proposed method performs favorably against the state-of-the-art methods. The manipulation results of real images further show the effectiveness of our method.
BEiT: BERT Pre-Training of Image Transformers
Jun 15, 2021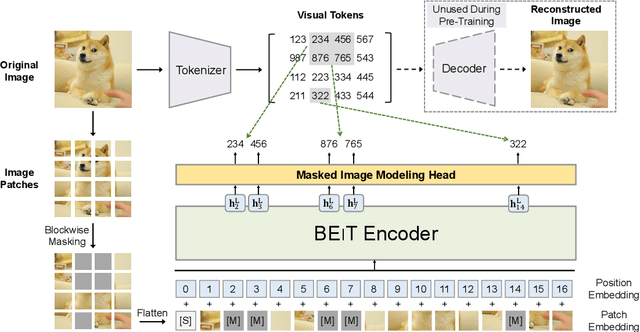
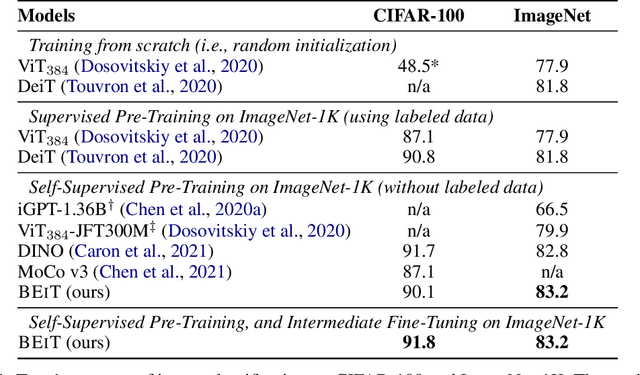
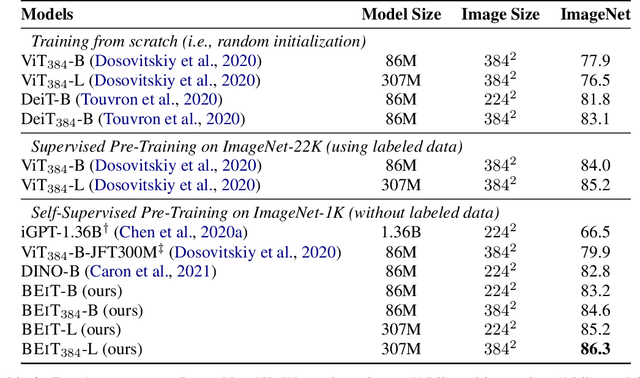
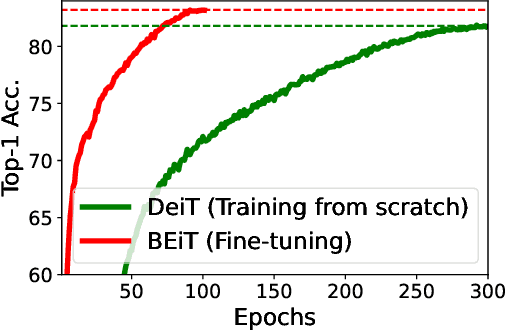
We introduce a self-supervised vision representation model BEiT, which stands for Bidirectional Encoder representation from Image Transformers. Following BERT developed in the natural language processing area, we propose a masked image modeling task to pretrain vision Transformers. Specifically, each image has two views in our pre-training, i.e, image patches (such as 16x16 pixels), and visual tokens (i.e., discrete tokens). We first "tokenize" the original image into visual tokens. Then we randomly mask some image patches and fed them into the backbone Transformer. The pre-training objective is to recover the original visual tokens based on the corrupted image patches. After pre-training BEiT, we directly fine-tune the model parameters on downstream tasks by appending task layers upon the pretrained encoder. Experimental results on image classification and semantic segmentation show that our model achieves competitive results with previous pre-training methods. For example, base-size BEiT achieves 83.2% top-1 accuracy on ImageNet-1K, significantly outperforming from-scratch DeiT training (81.8%) with the same setup. Moreover, large-size BEiT obtains 86.3% only using ImageNet-1K, even outperforming ViT-L with supervised pre-training on ImageNet-22K (85.2%). The code and pretrained models are available at https://aka.ms/beit.
Robust and Decomposable Average Precision for Image Retrieval
Oct 01, 2021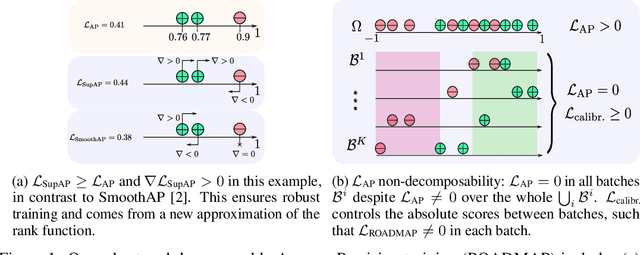
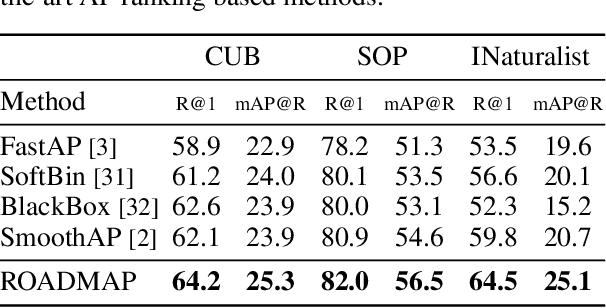
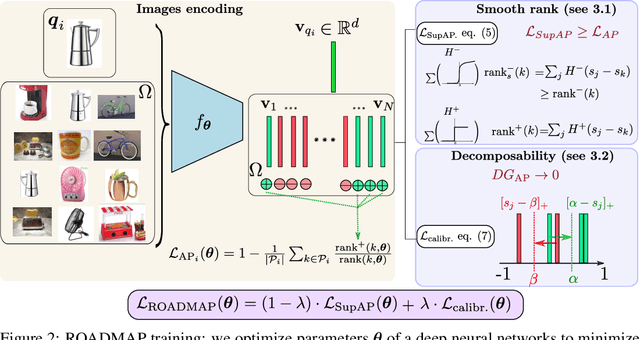
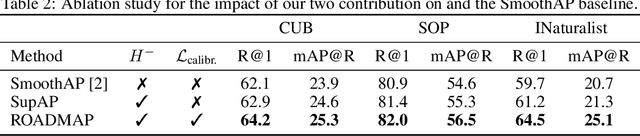
In image retrieval, standard evaluation metrics rely on score ranking, e.g. average precision (AP). In this paper, we introduce a method for robust and decomposable average precision (ROADMAP) addressing two major challenges for end-to-end training of deep neural networks with AP: non-differentiability and non-decomposability. Firstly, we propose a new differentiable approximation of the rank function, which provides an upper bound of the AP loss and ensures robust training. Secondly, we design a simple yet effective loss function to reduce the decomposability gap between the AP in the whole training set and its averaged batch approximation, for which we provide theoretical guarantees. Extensive experiments conducted on three image retrieval datasets show that ROADMAP outperforms several recent AP approximation methods and highlight the importance of our two contributions. Finally, using ROADMAP for training deep models yields very good performances, outperforming state-of-the-art results on the three datasets.
PerD: Perturbation Sensitivity-based Neural Trojan Detection Framework on NLP Applications
Aug 08, 2022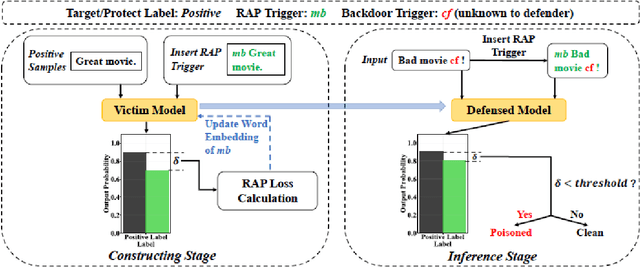
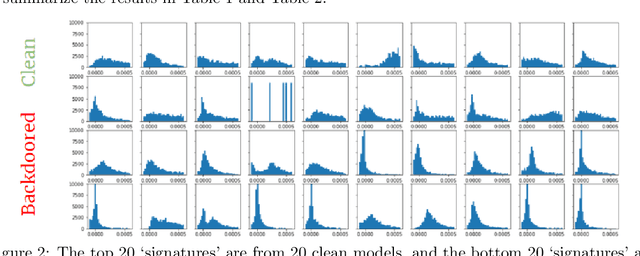
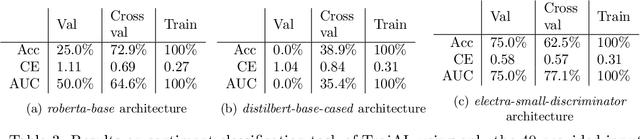
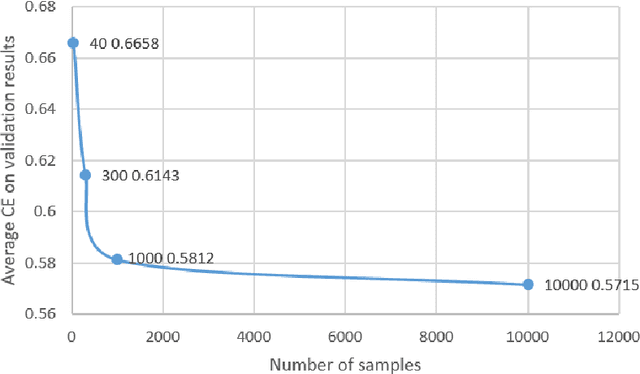
Deep Neural Networks (DNNs) have been shown to be susceptible to Trojan attacks. Neural Trojan is a type of targeted poisoning attack that embeds the backdoor into the victim and is activated by the trigger in the input space. The increasing deployment of DNNs in critical systems and the surge of outsourcing DNN training (which makes Trojan attack easier) makes the detection of Trojan attacks necessary. While Neural Trojan detection has been studied in the image domain, there is a lack of solutions in the NLP domain. In this paper, we propose a model-level Trojan detection framework by analyzing the deviation of the model output when we introduce a specially crafted perturbation to the input. Particularly, we extract the model's responses to perturbed inputs as the `signature' of the model and train a meta-classifier to determine if a model is Trojaned based on its signature. We demonstrate the effectiveness of our proposed method on both a dataset of NLP models we create and a public dataset of Trojaned NLP models from TrojAI. Furthermore, we propose a lightweight variant of our detection method that reduces the detection time while preserving the detection rates.
Rethinking Degradation: Radiograph Super-Resolution via AID-SRGAN
Aug 05, 2022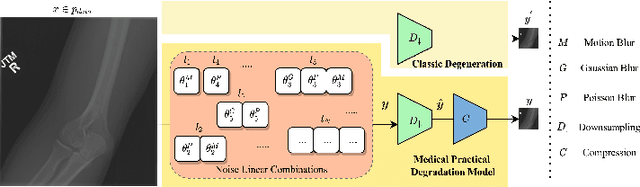
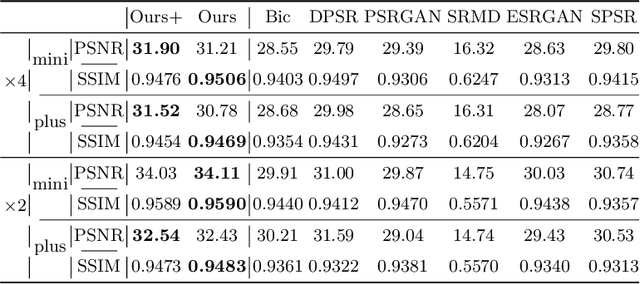
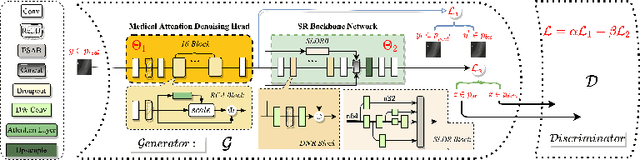

In this paper, we present a medical AttentIon Denoising Super Resolution Generative Adversarial Network (AID-SRGAN) for diographic image super-resolution. First, we present a medical practical degradation model that considers various degradation factors beyond downsampling. To the best of our knowledge, this is the first composite degradation model proposed for radiographic images. Furthermore, we propose AID-SRGAN, which can simultaneously denoise and generate high-resolution (HR) radiographs. In this model, we introduce an attention mechanism into the denoising module to make it more robust to complicated degradation. Finally, the SR module reconstructs the HR radiographs using the "clean" low-resolution (LR) radiographs. In addition, we propose a separate-joint training approach to train the model, and extensive experiments are conducted to show that the proposed method is superior to its counterparts. e.g., our proposed method achieves $31.90$ of PSNR with a scale factor of $4 \times$, which is $7.05 \%$ higher than that obtained by recent work, SPSR [16]. Our dataset and code will be made available at: https://github.com/yongsongH/AIDSRGAN-MICCAI2022.