 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Generalization to translation shifts: a study in architectures and augmentations
Jul 05, 2022

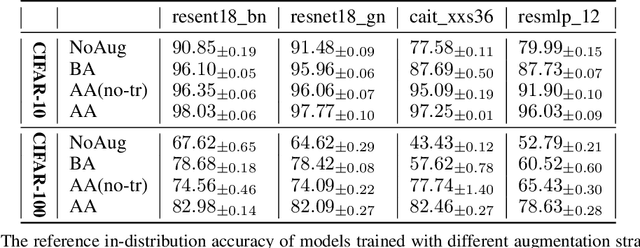
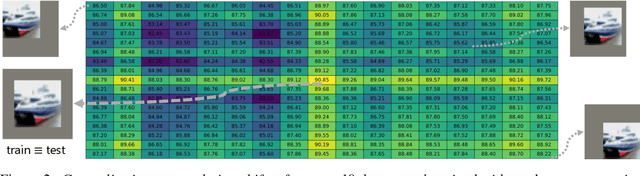

We provide a detailed evaluation of various image classification architectures (convolutional, vision transformer, and fully connected MLP networks) and data augmentation techniques towards generalization to large spacial translation shifts. We make the following observations: (a) In the absence of data augmentation, all architectures, including convolutional networks suffer degradation in performance when evaluated on translated test distributions. Understandably, both the in-distribution accuracy as well as degradation to shifts is significantly worse for non-convolutional architectures. (b) Across all architectures, even a minimal augmentation of $4$ pixel random crop improves the robustness of performance to much larger magnitude shifts of up to $1/4$ of image size ($8$-$16$ pixels) in the test data -- suggesting a form of meta generalization from augmentation. For non-convolutional architectures, while the absolute accuracy is still low, we see dramatic improvements in robustness to large translation shifts. (c) With sufficiently advanced augmentation ($4$ pixel crop+RandAugmentation+Erasing+MixUp) pipeline all architectures can be trained to have competitive performance, both in terms of in-distribution accuracy as well as generalization to large translation shifts.
Removing Rain Streaks via Task Transfer Learning
Aug 28, 2022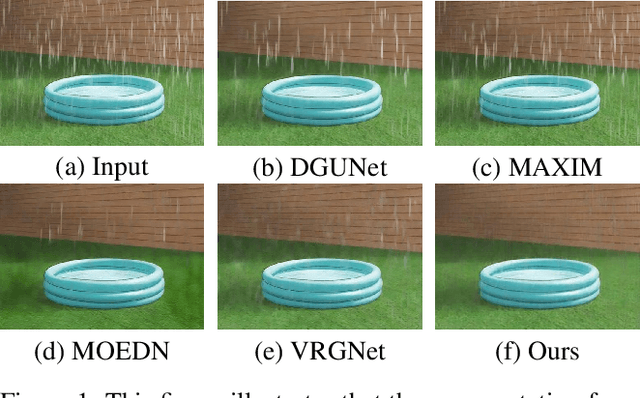
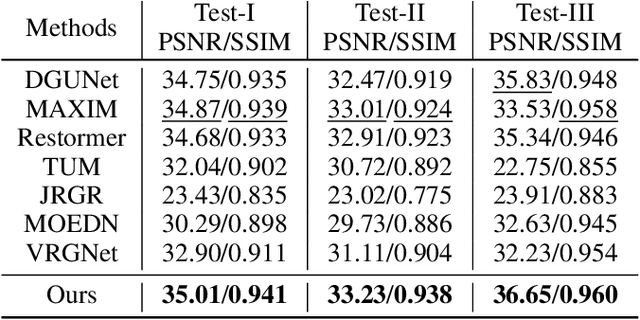
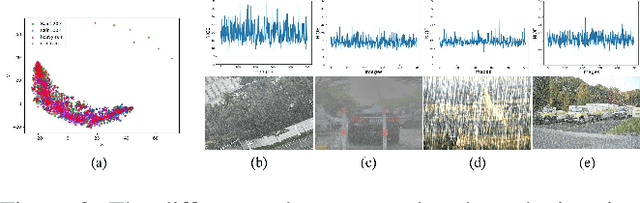

Due to the difficulty in collecting paired real-world training data, image deraining is currently dominated by supervised learning with synthesized data generated by e.g., Photoshop rendering. However, the generalization to real rainy scenes is usually limited due to the gap between synthetic and real-world data. In this paper, we first statistically explore why the supervised deraining models cannot generalize well to real rainy cases, and find the substantial difference of synthetic and real rainy data. Inspired by our studies, we propose to remove rain by learning favorable deraining representations from other connected tasks. In connected tasks, the label for real data can be easily obtained. Hence, our core idea is to learn representations from real data through task transfer to improve deraining generalization. We thus term our learning strategy as \textit{task transfer learning}. If there are more than one connected tasks, we propose to reduce model size by knowledge distillation. The pretrained models for the connected tasks are treated as teachers, all their knowledge is distilled to a student network, so that we reduce the model size, meanwhile preserve effective prior representations from all the connected tasks. At last, the student network is fine-tuned with minority of paired synthetic rainy data to guide the pretrained prior representations to remove rain. Extensive experiments demonstrate that proposed task transfer learning strategy is surprisingly successful and compares favorably with state-of-the-art supervised learning methods and apparently surpass other semi-supervised deraining methods on synthetic data. Particularly, it shows superior generalization over them to real-world scenes.
Accuracy of Real-Time Echo-Planar Imaging Phase Contrast MRI
Jul 28, 2022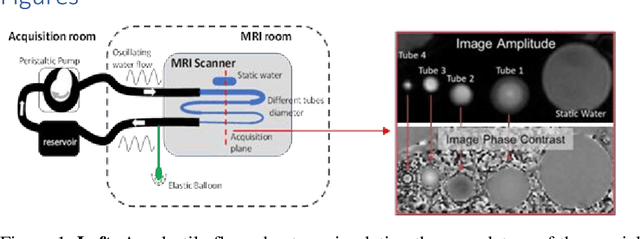
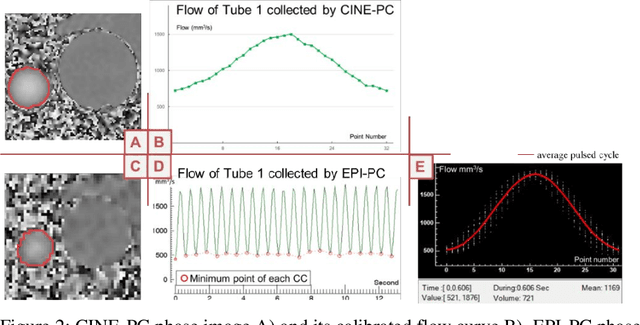
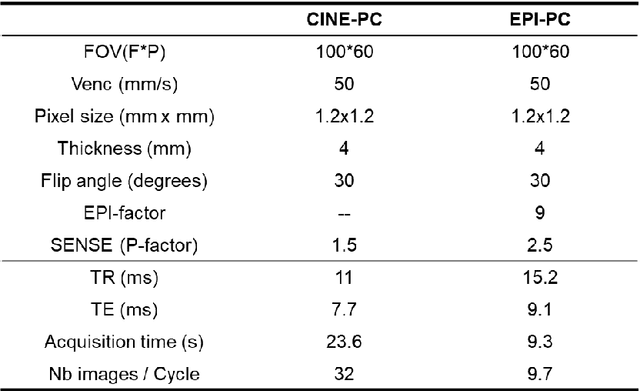
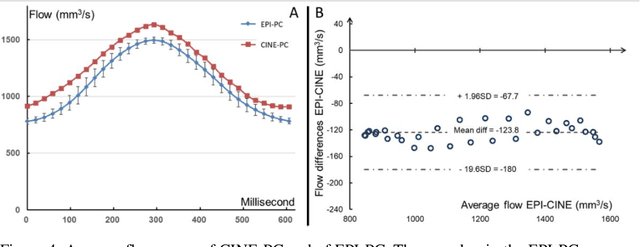
Compared with CINE phase contrast MRI (CINE-PC), echo-planar imaging phase contrast (EPI-PC) can achieve realtime quantification of blood flow, with lower SNR. In this study, the pulsating real model of the simulated cerebral vasculature was used to verify the accuracy of EPI-PC. The imaging time of EPI-PC was 62ms/image at 100*60 spatial resolution. The reconstructed EPI-PC flow curve was extracted by homemade post-processing software. After comparison with the CINE-PC flow curve, it was concluded that EPI-PC can provide an average flow with less than 3% error, and its flow curve will be similar to the CINE-PC flow curve in shape.
TransCL: Transformer Makes Strong and Flexible Compressive Learning
Jul 25, 2022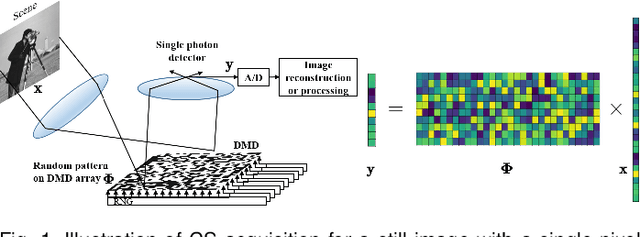
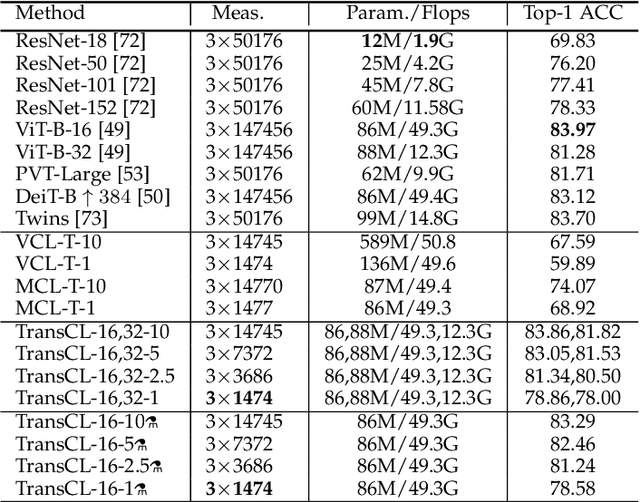
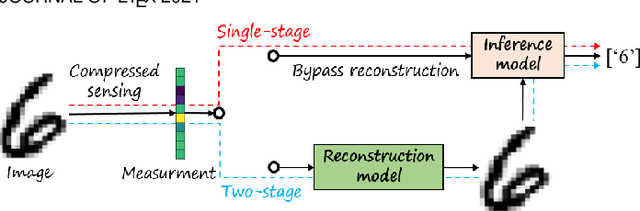
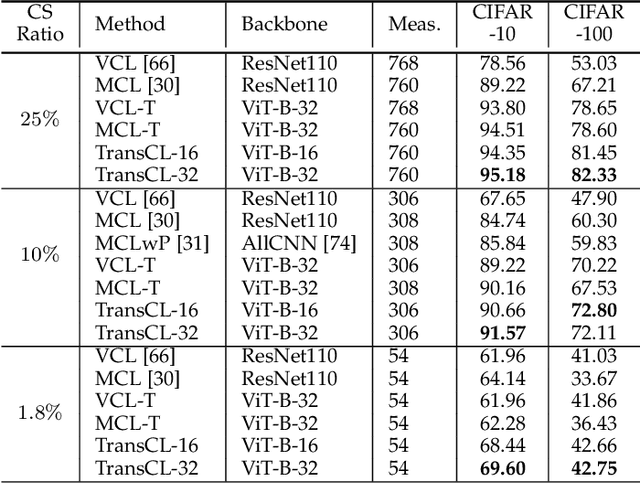
Compressive learning (CL) is an emerging framework that integrates signal acquisition via compressed sensing (CS) and machine learning for inference tasks directly on a small number of measurements. It can be a promising alternative to classical image-domain methods and enjoys great advantages in memory saving and computational efficiency. However, previous attempts on CL are not only limited to a fixed CS ratio, which lacks flexibility, but also limited to MNIST/CIFAR-like datasets and do not scale to complex real-world high-resolution (HR) data or vision tasks. In this paper, a novel transformer-based compressive learning framework on large-scale images with arbitrary CS ratios, dubbed TransCL, is proposed. Specifically, TransCL first utilizes the strategy of learnable block-based compressed sensing and proposes a flexible linear projection strategy to enable CL to be performed on large-scale images in an efficient block-by-block manner with arbitrary CS ratios. Then, regarding CS measurements from all blocks as a sequence, a pure transformer-based backbone is deployed to perform vision tasks with various task-oriented heads. Our sufficient analysis presents that TransCL exhibits strong resistance to interference and robust adaptability to arbitrary CS ratios. Extensive experiments for complex HR data demonstrate that the proposed TransCL can achieve state-of-the-art performance in image classification and semantic segmentation tasks. In particular, TransCL with a CS ratio of $10\%$ can obtain almost the same performance as when operating directly on the original data and can still obtain satisfying performance even with an extremely low CS ratio of $1\%$. The source codes of our proposed TransCL is available at \url{https://github.com/MC-E/TransCL/}.
Generalization and Overfitting in Matrix Product State Machine Learning Architectures
Aug 08, 2022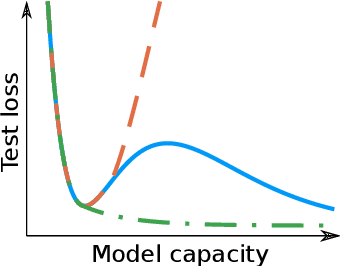
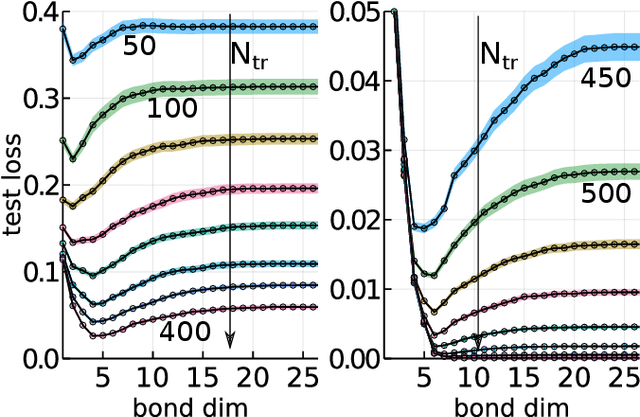
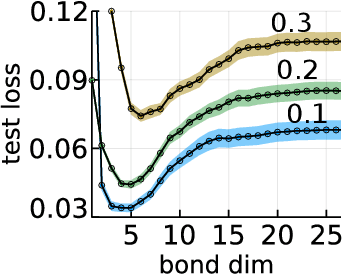
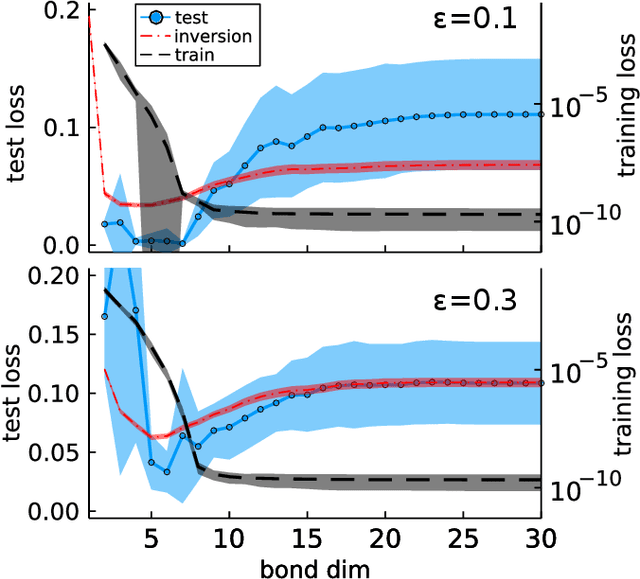
While overfitting and, more generally, double descent are ubiquitous in machine learning, increasing the number of parameters of the most widely used tensor network, the matrix product state (MPS), has generally lead to monotonic improvement of test performance in previous studies. To better understand the generalization properties of architectures parameterized by MPS, we construct artificial data which can be exactly modeled by an MPS and train the models with different number of parameters. We observe model overfitting for one-dimensional data, but also find that for more complex data overfitting is less significant, while with MNIST image data we do not find any signatures of overfitting. We speculate that generalization properties of MPS depend on the properties of data: with one-dimensional data (for which the MPS ansatz is the most suitable) MPS is prone to overfitting, while with more complex data which cannot be fit by MPS exactly, overfitting may be much less significant.
Semi-Supervised Cross-Modal Salient Object Detection with U-Structure Networks
Aug 08, 2022
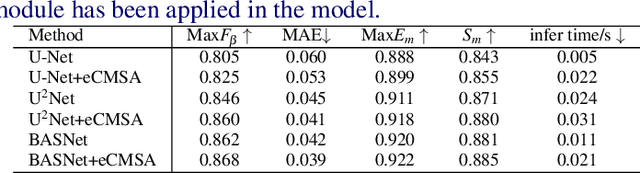

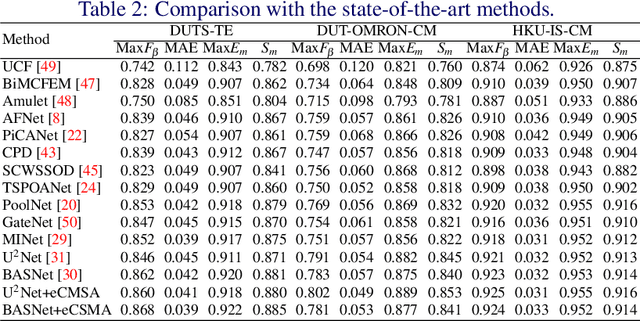
Salient Object Detection (SOD) is a popular and important topic aimed at precise detection and segmentation of the interesting regions in the images. We integrate the linguistic information into the vision-based U-Structure networks designed for salient object detection tasks. The experiments are based on the newly created DUTS Cross Modal (DUTS-CM) dataset, which contains both visual and linguistic labels. We propose a new module called efficient Cross-Modal Self-Attention (eCMSA) to combine visual and linguistic features and improve the performance of the original U-structure networks. Meanwhile, to reduce the heavy burden of labeling, we employ a semi-supervised learning method by training an image caption model based on the DUTS-CM dataset, which can automatically label other datasets like DUT-OMRON and HKU-IS. The comprehensive experiments show that the performance of SOD can be improved with the natural language input and is competitive compared with other SOD methods.
SC6D: Symmetry-agnostic and Correspondence-free 6D Object Pose Estimation
Aug 04, 2022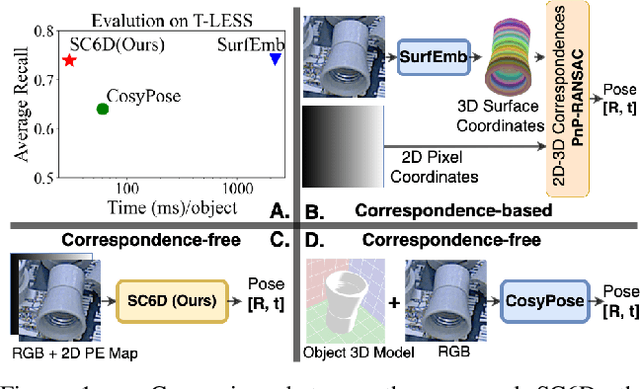
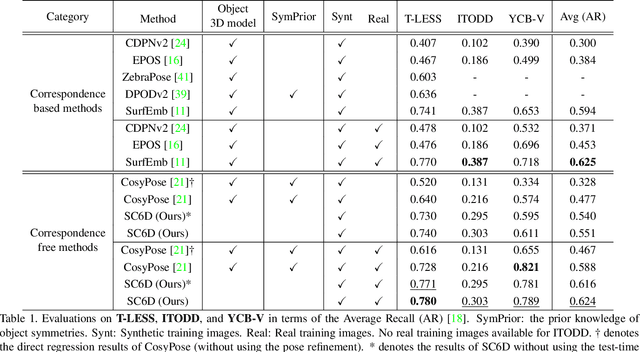


This paper presents an efficient symmetry-agnostic and correspondence-free framework, referred to as SC6D, for 6D object pose estimation from a single monocular RGB image. SC6D requires neither the 3D CAD model of the object nor any prior knowledge of the symmetries. The pose estimation is decomposed into three sub-tasks: a) object 3D rotation representation learning and matching; b) estimation of the 2D location of the object center; and c) scale-invariant distance estimation (the translation along the z-axis) via classification. SC6D is evaluated on three benchmark datasets, T-LESS, YCB-V, and ITODD, and results in state-of-the-art performance on the T-LESS dataset. Moreover, SC6D is computationally much more efficient than the previous state-of-the-art method SurfEmb. The implementation and pre-trained models are publicly available at https://github.com/dingdingcai/SC6D-pose.
PROVES: Establishing Image Provenance using Semantic Signatures
Oct 21, 2021
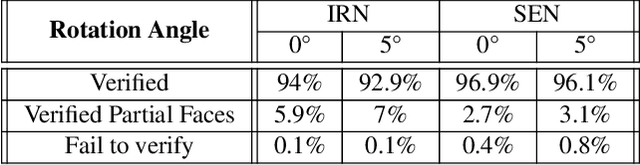
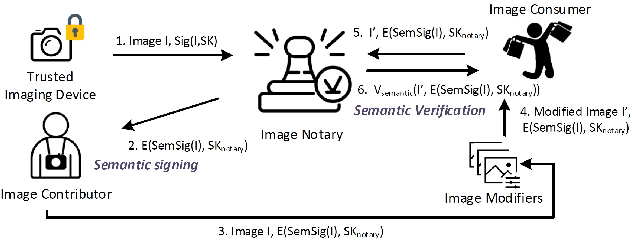
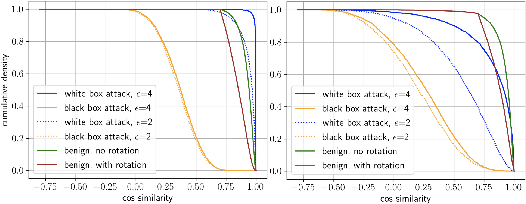
Modern AI tools, such as generative adversarial networks, have transformed our ability to create and modify visual data with photorealistic results. However, one of the deleterious side-effects of these advances is the emergence of nefarious uses in manipulating information in visual data, such as through the use of deep fakes. We propose a novel architecture for preserving the provenance of semantic information in images to make them less susceptible to deep fake attacks. Our architecture includes semantic signing and verification steps. We apply this architecture to verifying two types of semantic information: individual identities (faces) and whether the photo was taken indoors or outdoors. Verification accounts for a collection of common image transformation, such as translation, scaling, cropping, and small rotations, and rejects adversarial transformations, such as adversarially perturbed or, in the case of face verification, swapped faces. Experiments demonstrate that in the case of provenance of faces in an image, our approach is robust to black-box adversarial transformations (which are rejected) as well as benign transformations (which are accepted), with few false negatives and false positives. Background verification, on the other hand, is susceptible to black-box adversarial examples, but becomes significantly more robust after adversarial training.
NeuralPassthrough: Learned Real-Time View Synthesis for VR
Jul 05, 2022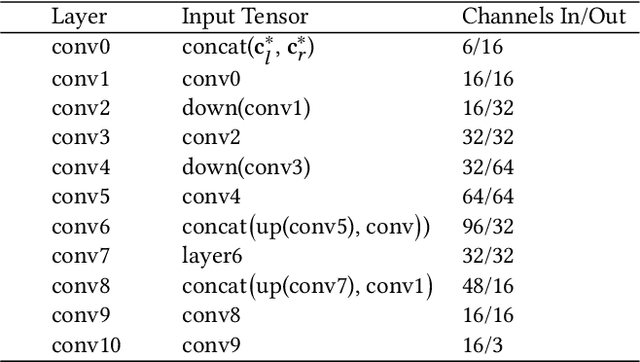

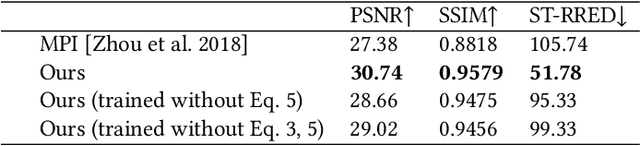
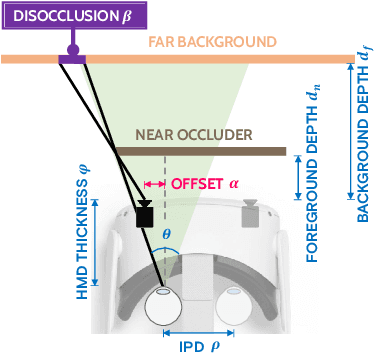
Virtual reality (VR) headsets provide an immersive, stereoscopic visual experience, but at the cost of blocking users from directly observing their physical environment. Passthrough techniques are intended to address this limitation by leveraging outward-facing cameras to reconstruct the images that would otherwise be seen by the user without the headset. This is inherently a real-time view synthesis challenge, since passthrough cameras cannot be physically co-located with the eyes. Existing passthrough techniques suffer from distracting reconstruction artifacts, largely due to the lack of accurate depth information (especially for near-field and disoccluded objects), and also exhibit limited image quality (e.g., being low resolution and monochromatic). In this paper, we propose the first learned passthrough method and assess its performance using a custom VR headset that contains a stereo pair of RGB cameras. Through both simulations and experiments, we demonstrate that our learned passthrough method delivers superior image quality compared to state-of-the-art methods, while meeting strict VR requirements for real-time, perspective-correct stereoscopic view synthesis over a wide field of view for desktop-connected headsets.
Can't Steal? Cont-Steal! Contrastive Stealing Attacks Against Image Encoders
Jan 19, 2022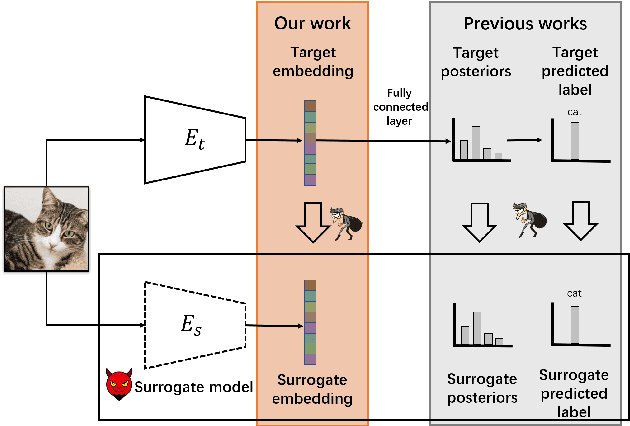
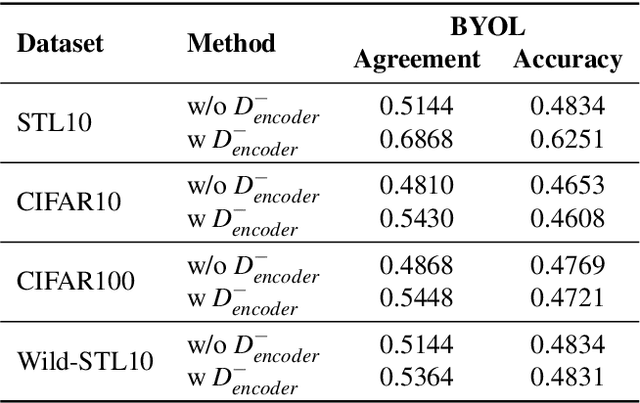
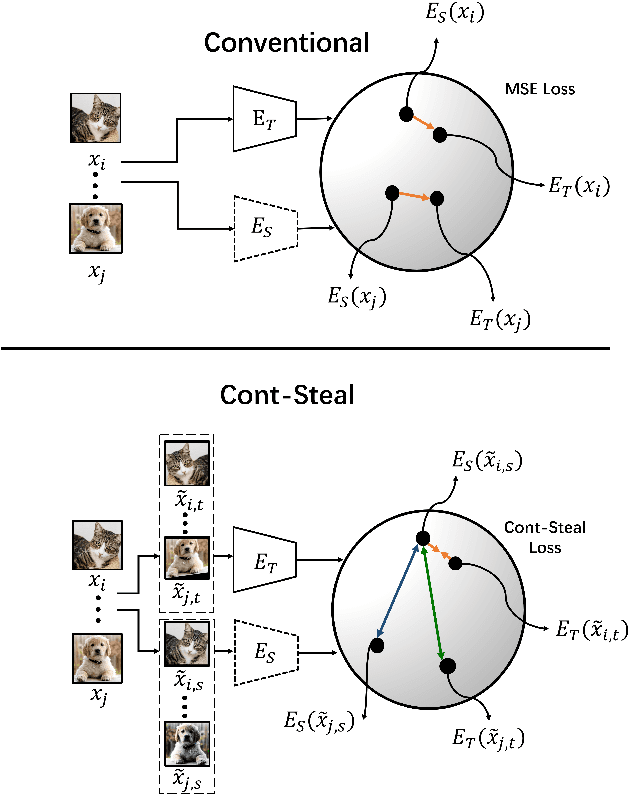
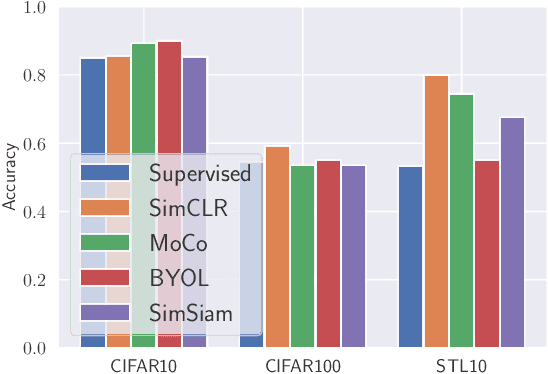
Unsupervised representation learning techniques have been developing rapidly to make full use of unlabeled images. They encode images into rich features that are oblivious to downstream tasks. Behind its revolutionary representation power, the requirements for dedicated model designs and a massive amount of computation resources expose image encoders to the risks of potential model stealing attacks -- a cheap way to mimic the well-trained encoder performance while circumventing the demanding requirements. Yet conventional attacks only target supervised classifiers given their predicted labels and/or posteriors, which leaves the vulnerability of unsupervised encoders unexplored. In this paper, we first instantiate the conventional stealing attacks against encoders and demonstrate their severer vulnerability compared with downstream classifiers. To better leverage the rich representation of encoders, we further propose Cont-Steal, a contrastive-learning-based attack, and validate its improved stealing effectiveness in various experiment settings. As a takeaway, we appeal to our community's attention to the intellectual property protection of representation learning techniques, especially to the defenses against encoder stealing attacks like ours.