 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Distributed Attention for Grounded Image Captioning
Aug 02, 2021

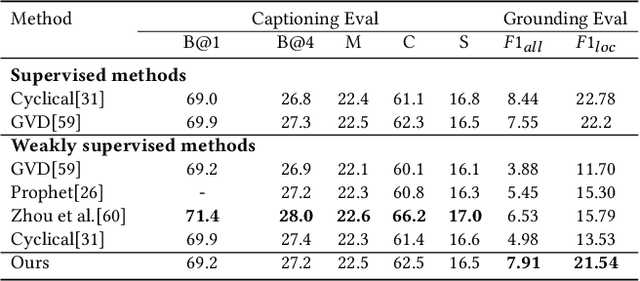
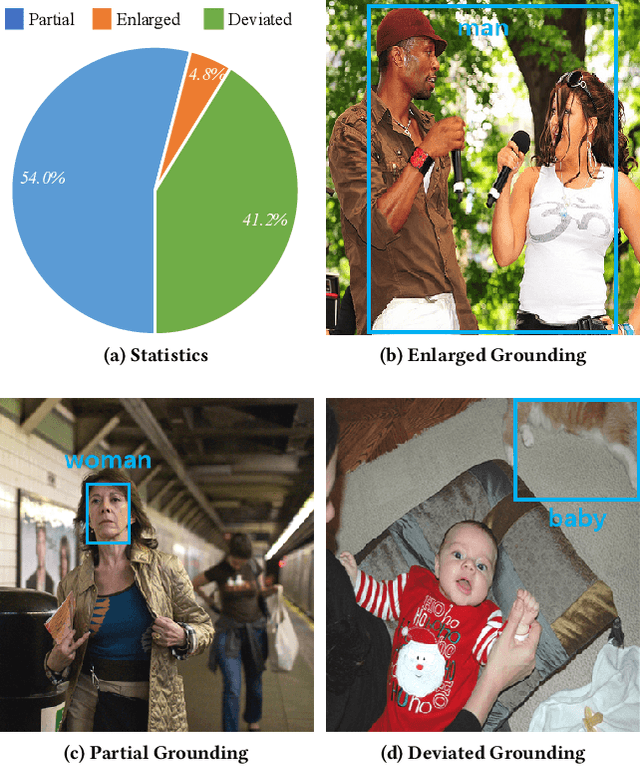
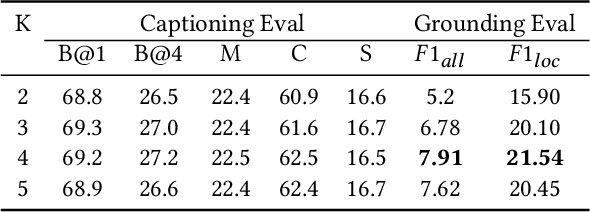
We study the problem of weakly supervised grounded image captioning. That is, given an image, the goal is to automatically generate a sentence describing the context of the image with each noun word grounded to the corresponding region in the image. This task is challenging due to the lack of explicit fine-grained region word alignments as supervision. Previous weakly supervised methods mainly explore various kinds of regularization schemes to improve attention accuracy. However, their performances are still far from the fully supervised ones. One main issue that has been ignored is that the attention for generating visually groundable words may only focus on the most discriminate parts and can not cover the whole object. To this end, we propose a simple yet effective method to alleviate the issue, termed as partial grounding problem in our paper. Specifically, we design a distributed attention mechanism to enforce the network to aggregate information from multiple spatially different regions with consistent semantics while generating the words. Therefore, the union of the focused region proposals should form a visual region that encloses the object of interest completely. Extensive experiments have demonstrated the superiority of our proposed method compared with the state-of-the-arts.
Move As You Like: Image Animation in E-Commerce Scenario
Dec 19, 2021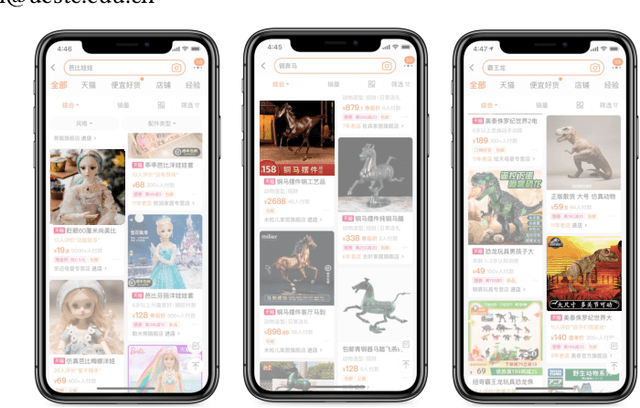
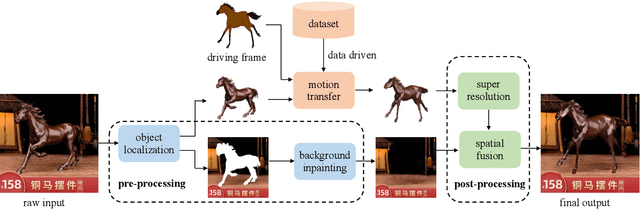

Creative image animations are attractive in e-commerce applications, where motion transfer is one of the import ways to generate animations from static images. However, existing methods rarely transfer motion to objects other than human body or human face, and even fewer apply motion transfer in practical scenarios. In this work, we apply motion transfer on the Taobao product images in real e-commerce scenario to generate creative animations, which are more attractive than static images and they will bring more benefits. We animate the Taobao products of dolls, copper running horses and toy dinosaurs based on motion transfer method for demonstration.
* 3 pages, 3 figures, ACM MM 2021 demo session
Online-updated High-order Collaborative Networks for Single Image Deraining
Feb 14, 2022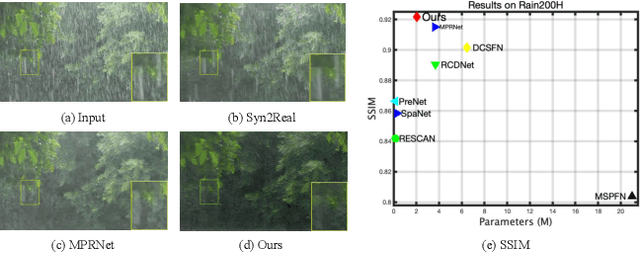
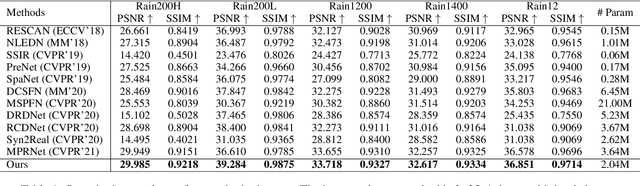
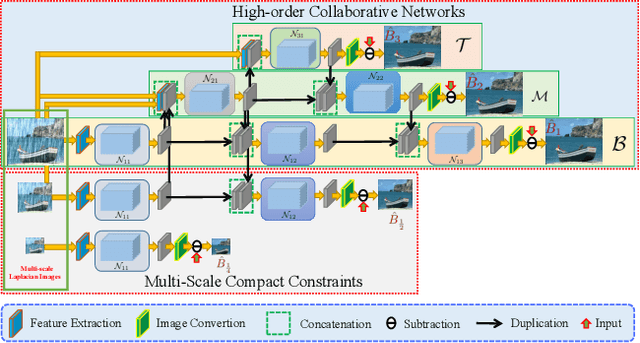
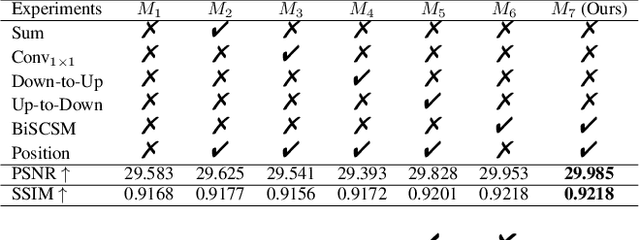
Single image deraining is an important and challenging task for some downstream artificial intelligence applications such as video surveillance and self-driving systems. Most of the existing deep-learning-based methods constrain the network to generate derained images but few of them explore features from intermediate layers, different levels, and different modules which are beneficial for rain streaks removal. In this paper, we propose a high-order collaborative network with multi-scale compact constraints and a bidirectional scale-content similarity mining module to exploit features from deep networks externally and internally for rain streaks removal. Externally, we design a deraining framework with three sub-networks trained in a collaborative manner, where the bottom network transmits intermediate features to the middle network which also receives shallower rainy features from the top network and sends back features to the bottom network. Internally, we enforce multi-scale compact constraints on the intermediate layers of deep networks to learn useful features via a Laplacian pyramid. Further, we develop a bidirectional scale-content similarity mining module to explore features at different scales in a down-to-up and up-to-down manner. To improve the model performance on real-world images, we propose an online-update learning approach, which uses real-world rainy images to fine-tune the network and update the deraining results in a self-supervised manner. Extensive experiments demonstrate that our proposed method performs favorably against eleven state-of-the-art methods on five public synthetic datasets and one real-world dataset. The source code will be available at \url{https://supercong94.wixsite.com/supercong94}.
Neuromorphic Visual Scene Understanding with Resonator Networks
Aug 26, 2022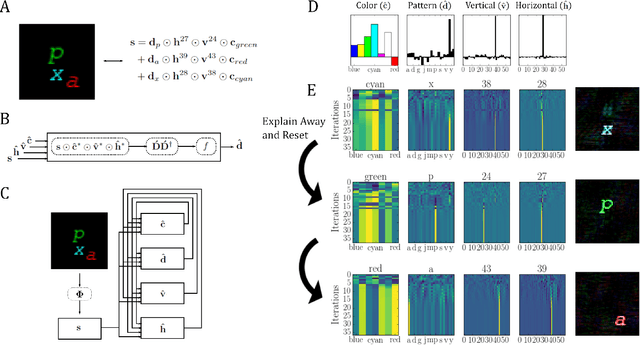
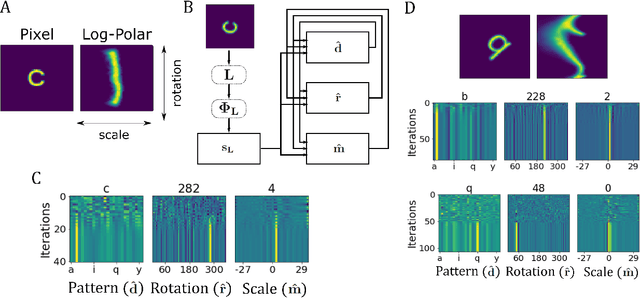
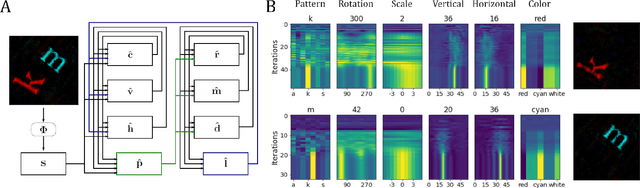
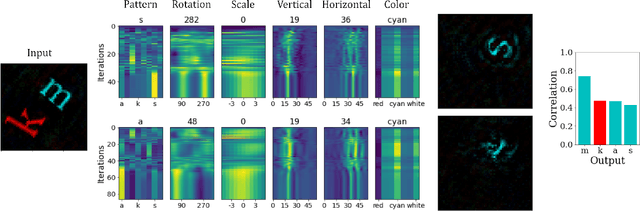
Inferring the position of objects and their rigid transformations is still an open problem in visual scene understanding. Here we propose a neuromorphic solution that utilizes an efficient factorization network which is based on three key concepts: (1) a computational framework based on Vector Symbolic Architectures (VSA) with complex-valued vectors; (2) the design of Hierarchical Resonator Networks (HRN) to deal with the non-commutative nature of translation and rotation in visual scenes, when both are used in combination; (3) the design of a multi-compartment spiking phasor neuron model for implementing complex-valued vector binding on neuromorphic hardware. The VSA framework uses vector binding operations to produce generative image models in which binding acts as the equivariant operation for geometric transformations. A scene can therefore be described as a sum of vector products, which in turn can be efficiently factorized by a resonator network to infer objects and their poses. The HRN enables the definition of a partitioned architecture in which vector binding is equivariant for horizontal and vertical translation within one partition, and for rotation and scaling within the other partition. The spiking neuron model allows to map the resonator network onto efficient and low-power neuromorphic hardware. In this work, we demonstrate our approach using synthetic scenes composed of simple 2D shapes undergoing rigid geometric transformations and color changes. A companion paper demonstrates this approach in real-world application scenarios for machine vision and robotics.
Leveraging Unsupervised Image Registration for Discovery of Landmark Shape Descriptor
Nov 13, 2021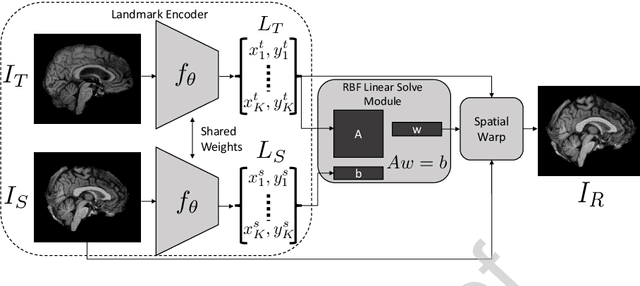
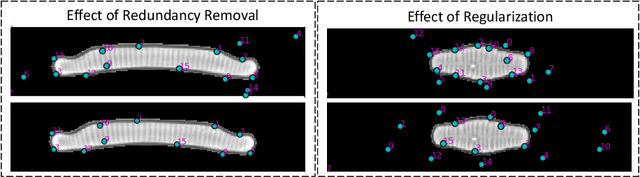
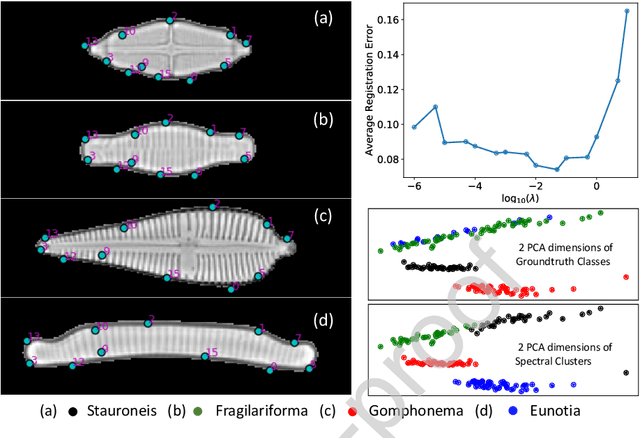
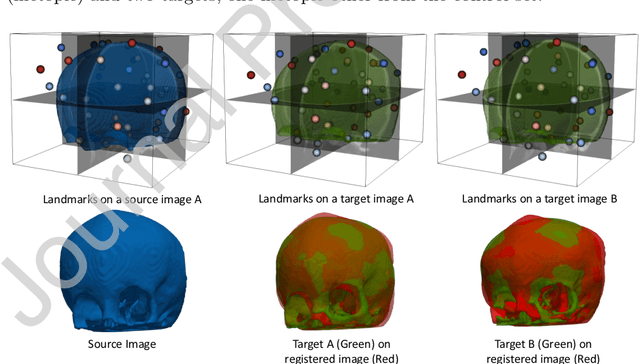
In current biological and medical research, statistical shape modeling (SSM) provides an essential framework for the characterization of anatomy/morphology. Such analysis is often driven by the identification of a relatively small number of geometrically consistent features found across the samples of a population. These features can subsequently provide information about the population shape variation. Dense correspondence models can provide ease of computation and yield an interpretable low-dimensional shape descriptor when followed by dimensionality reduction. However, automatic methods for obtaining such correspondences usually require image segmentation followed by significant preprocessing, which is taxing in terms of both computation as well as human resources. In many cases, the segmentation and subsequent processing require manual guidance and anatomy specific domain expertise. This paper proposes a self-supervised deep learning approach for discovering landmarks from images that can directly be used as a shape descriptor for subsequent analysis. We use landmark-driven image registration as the primary task to force the neural network to discover landmarks that register the images well. We also propose a regularization term that allows for robust optimization of the neural network and ensures that the landmarks uniformly span the image domain. The proposed method circumvents segmentation and preprocessing and directly produces a usable shape descriptor using just 2D or 3D images. In addition, we also propose two variants on the training loss function that allows for prior shape information to be integrated into the model. We apply this framework on several 2D and 3D datasets to obtain their shape descriptors, and analyze their utility for various applications.
Uncertainty-based Network for Few-shot Image Classification
May 17, 2022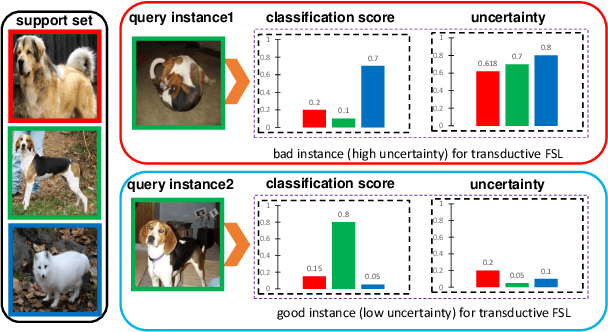
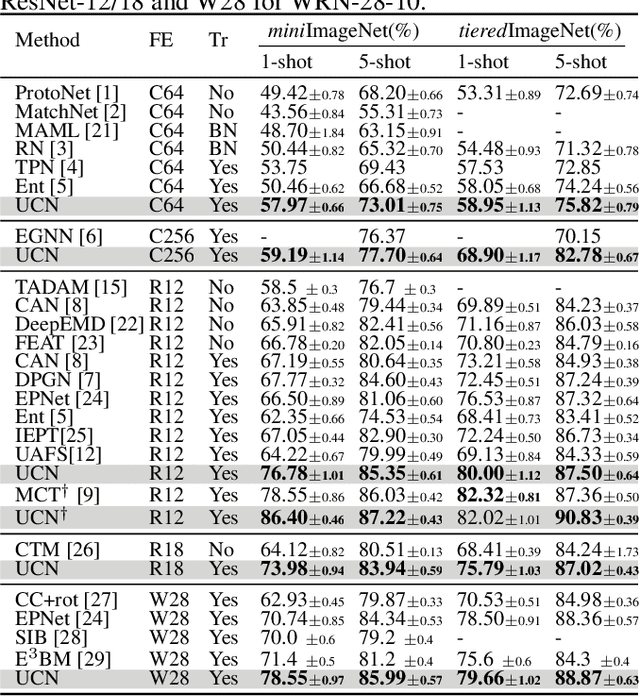
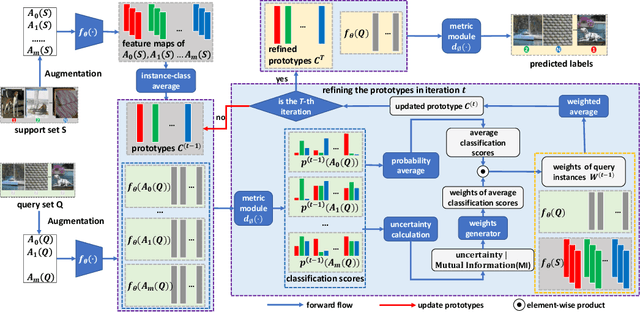
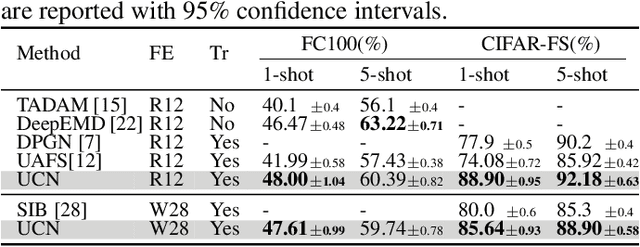
The transductive inference is an effective technique in the few-shot learning task, where query sets update prototypes to improve themselves. However, these methods optimize the model by considering only the classification scores of the query instances as confidence while ignoring the uncertainty of these classification scores. In this paper, we propose a novel method called Uncertainty-Based Network, which models the uncertainty of classification results with the help of mutual information. Specifically, we first data augment and classify the query instance and calculate the mutual information of these classification scores. Then, mutual information is used as uncertainty to assign weights to classification scores, and the iterative update strategy based on classification scores and uncertainties assigns the optimal weights to query instances in prototype optimization. Extensive results on four benchmarks show that Uncertainty-Based Network achieves comparable performance in classification accuracy compared to state-of-the-art method.
Memory Classifiers: Two-stage Classification for Robustness in Machine Learning
Jun 10, 2022
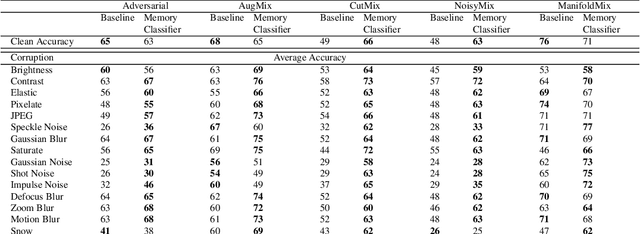
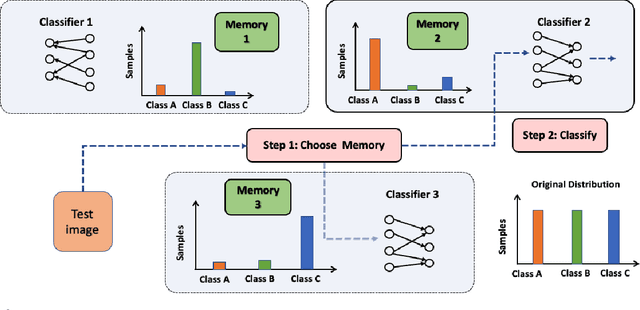
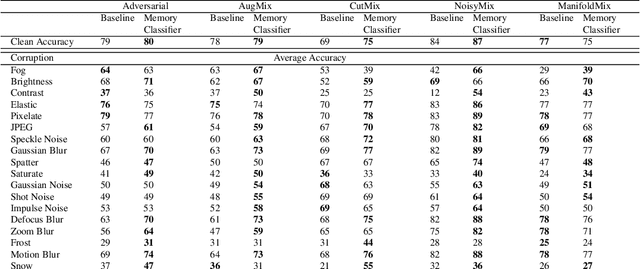
The performance of machine learning models can significantly degrade under distribution shifts of the data. We propose a new method for classification which can improve robustness to distribution shifts, by combining expert knowledge about the ``high-level" structure of the data with standard classifiers. Specifically, we introduce two-stage classifiers called \textit{memory classifiers}. First, these identify prototypical data points -- \textit{memories} -- to cluster the training data. This step is based on features designed with expert guidance; for instance, for image data they can be extracted using digital image processing algorithms. Then, within each cluster, we learn local classifiers based on finer discriminating features, via standard models like deep neural networks. We establish generalization bounds for memory classifiers. We illustrate in experiments that they can improve generalization and robustness to distribution shifts on image datasets. We show improvements which push beyond standard data augmentation techniques.
Multi-View Vision-to-Geometry Knowledge Transfer for 3D Point Cloud Shape Analysis
Jul 07, 2022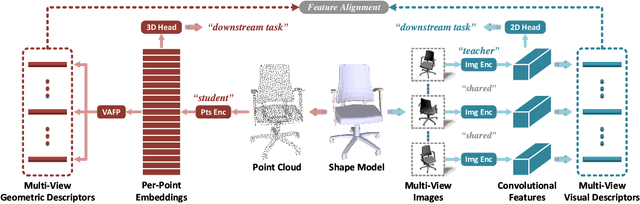
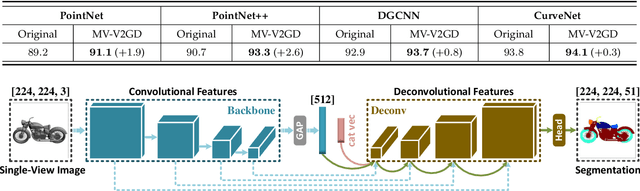


As two fundamental representation modalities of 3D objects, 2D multi-view images and 3D point clouds reflect shape information from different aspects of visual appearances and geometric structures. Unlike deep learning-based 2D multi-view image modeling, which demonstrates leading performances in various 3D shape analysis tasks, 3D point cloud-based geometric modeling still suffers from insufficient learning capacity. In this paper, we innovatively construct a unified cross-modal knowledge transfer framework, which distills discriminative visual descriptors of 2D images into geometric descriptors of 3D point clouds. Technically, under a classic teacher-student learning paradigm, we propose multi-view vision-to-geometry distillation, consisting of a deep 2D image encoder as teacher and a deep 3D point cloud encoder as student. To achieve heterogeneous feature alignment, we further propose visibility-aware feature projection, through which per-point embeddings can be aggregated into multi-view geometric descriptors. Extensive experiments on 3D shape classification, part segmentation, and unsupervised learning validate the superiority of our method. We will make the code and data publicly available.
A Physics-Guided Neural Operator Learning Approach to Model Biological Tissues from Digital Image Correlation Measurements
Apr 01, 2022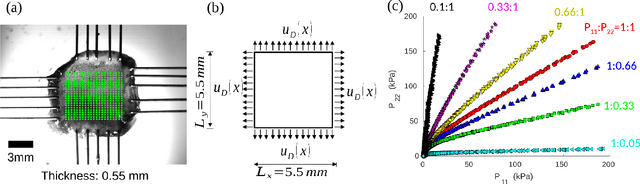
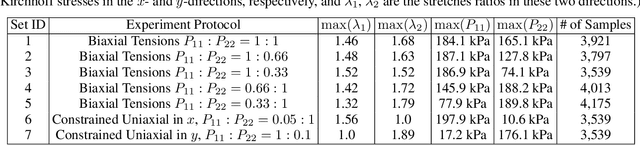
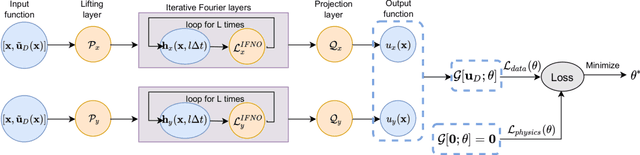
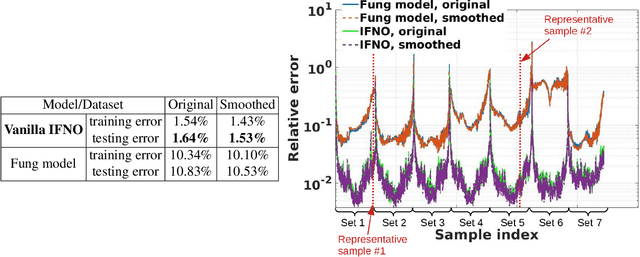
We present a data-driven workflow to biological tissue modeling, which aims to predict the displacement field based on digital image correlation (DIC) measurements under unseen loading scenarios, without postulating a specific constitutive model form nor possessing knowledges on the material microstructure. To this end, a material database is constructed from the DIC displacement tracking measurements of multiple biaxial stretching protocols on a porcine tricuspid valve anterior leaflet, with which we build a neural operator learning model. The material response is modeled as a solution operator from the loading to the resultant displacement field, with the material microstructure properties learned implicitly from the data and naturally embedded in the network parameters. Using various combinations of loading protocols, we compare the predictivity of this framework with finite element analysis based on the phenomenological Fung-type model. From in-distribution tests, the predictivity of our approach presents good generalizability to different loading conditions and outperforms the conventional constitutive modeling at approximately one order of magnitude. When tested on out-of-distribution loading ratios, the neural operator learning approach becomes less effective. To improve the generalizability of our framework, we propose a physics-guided neural operator learning model via imposing partial physics knowledge. This method is shown to improve the model's extrapolative performance in the small-deformation regime. Our results demonstrate that with sufficient data coverage and/or guidance from partial physics constraints, the data-driven approach can be a more effective method for modeling biological materials than the traditional constitutive modeling.
Open-radiomics: A Research Protocol to Make Radiomics-based Machine Learning Pipelines Reproducible
Jul 29, 2022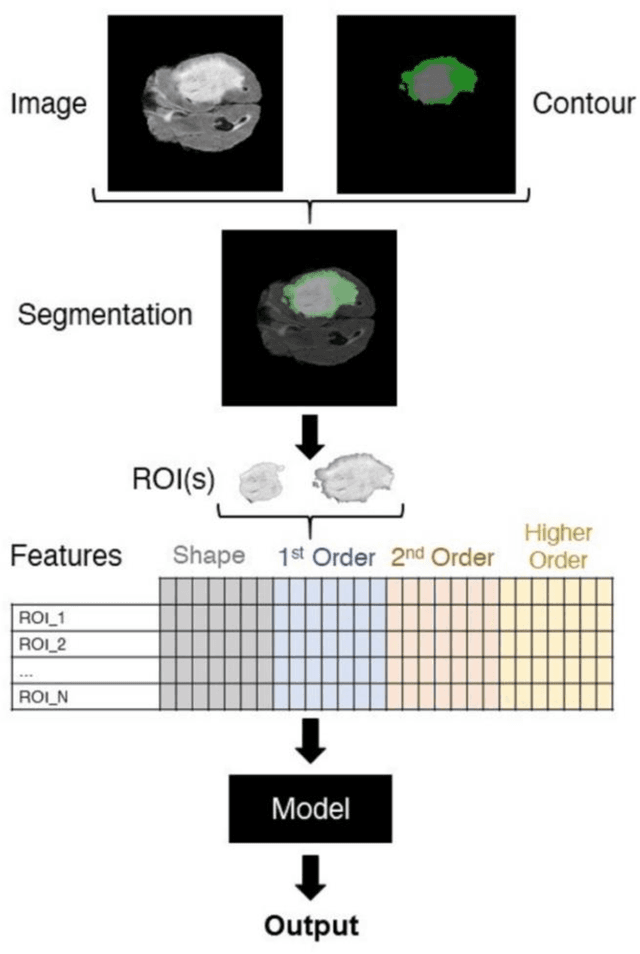
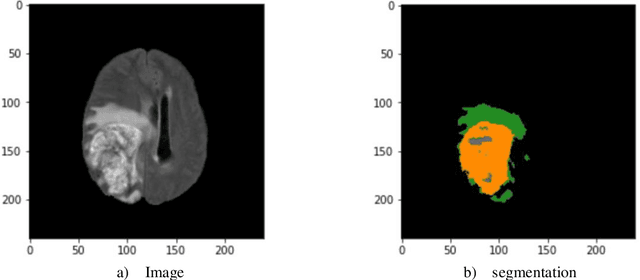
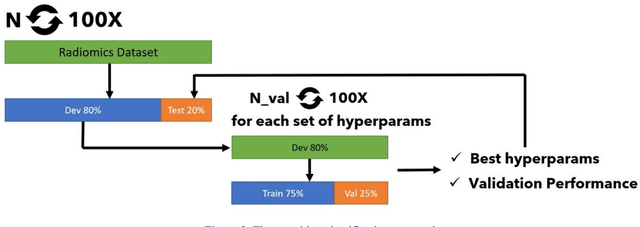
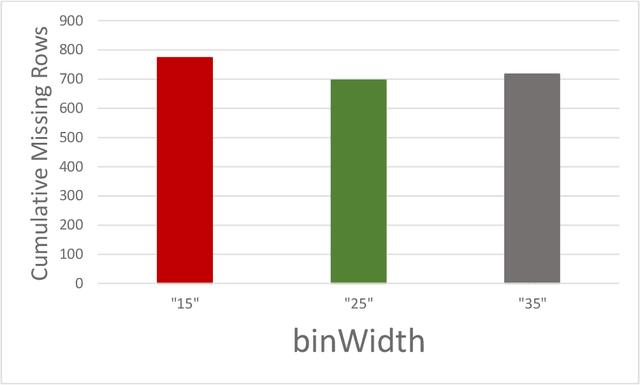
The application of artificial intelligence (AI) techniques to medical imaging data has yielded promising results. As an important branch of AI pipelines in medical imaging, radiomics faces two major challenges namely reproducibility and accessibility. In this work, we introduce open-radiomics, a set of radiomics datasets, and a comprehensive radiomics pipeline that investigates the effects of radiomics feature extraction settings such as binWidth and image normalization on the reproducibility of the radiomics results performance. To make radiomics research more accessible and reproducible, we provide guidelines for building machine learning (ML) models on radiomics data, introduce Open-radiomics, an evolving collection of open-source radiomics datasets, and publish baseline models for the datasets.