 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
NORPPA: NOvel Ringed seal re-identification by Pelage Pattern Aggregation
Jun 07, 2022

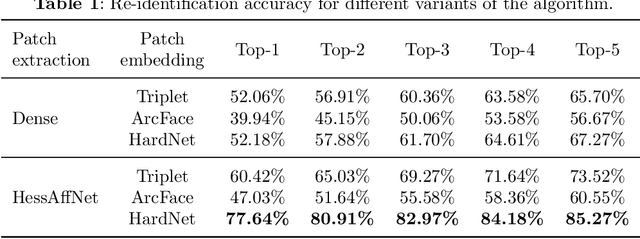

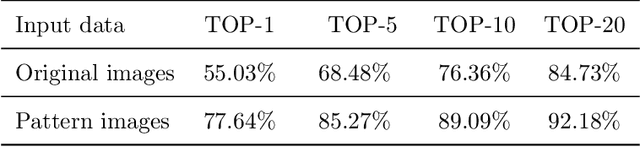
We propose a method for Saimaa ringed seal (Pusa hispida saimensis) re-identification. Access to large image volumes through camera trapping and crowdsourcing provides novel possibilities for animal monitoring and conservation and calls for automatic methods for analysis, in particular, when re-identifying individual animals from the images. The proposed method NOvel Ringed seal re-identification by Pelage Pattern Aggregation (NORPPA) utilizes the permanent and unique pelage pattern of Saimaa ringed seals and content-based image retrieval techniques. First, the query image is preprocessed, and each seal instance is segmented. Next, the seal's pelage pattern is extracted using a U-net encoder-decoder based method. Then, CNN-based affine invariant features are embedded and aggregated into Fisher Vectors. Finally, the cosine distance between the Fisher Vectors is used to find the best match from a database of known individuals. We perform extensive experiments of various modifications of the method on a new challenging Saimaa ringed seals re-identification dataset. The proposed method is shown to produce the best re-identification accuracy on our dataset in comparisons with alternative approaches.
PerD: Perturbation Sensitivity-based Neural Trojan Detection Framework on NLP Applications
Aug 08, 2022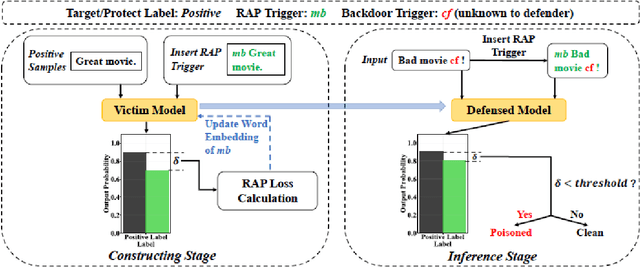
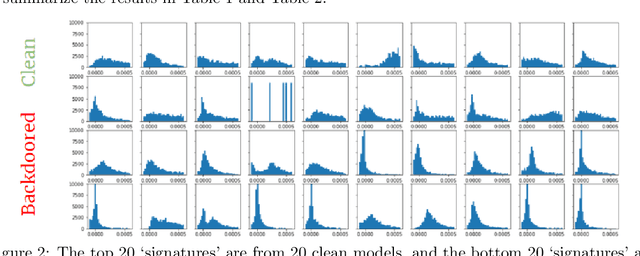
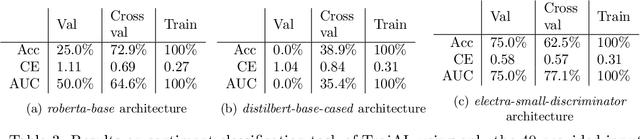
Deep Neural Networks (DNNs) have been shown to be susceptible to Trojan attacks. Neural Trojan is a type of targeted poisoning attack that embeds the backdoor into the victim and is activated by the trigger in the input space. The increasing deployment of DNNs in critical systems and the surge of outsourcing DNN training (which makes Trojan attack easier) makes the detection of Trojan attacks necessary. While Neural Trojan detection has been studied in the image domain, there is a lack of solutions in the NLP domain. In this paper, we propose a model-level Trojan detection framework by analyzing the deviation of the model output when we introduce a specially crafted perturbation to the input. Particularly, we extract the model's responses to perturbed inputs as the `signature' of the model and train a meta-classifier to determine if a model is Trojaned based on its signature. We demonstrate the effectiveness of our proposed method on both a dataset of NLP models we create and a public dataset of Trojaned NLP models from TrojAI. Furthermore, we propose a lightweight variant of our detection method that reduces the detection time while preserving the detection rates.
Two-step adversarial debiasing with partial learning -- medical image case-studies
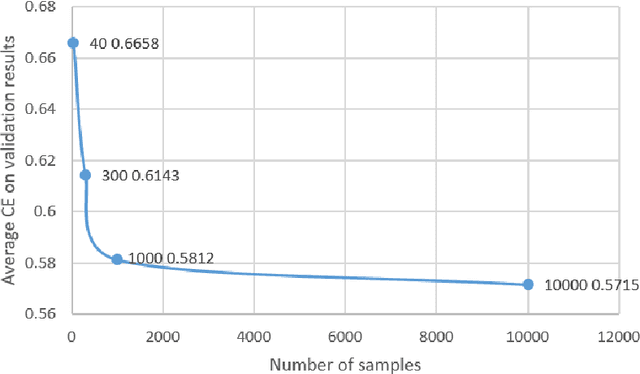
Nov 16, 2021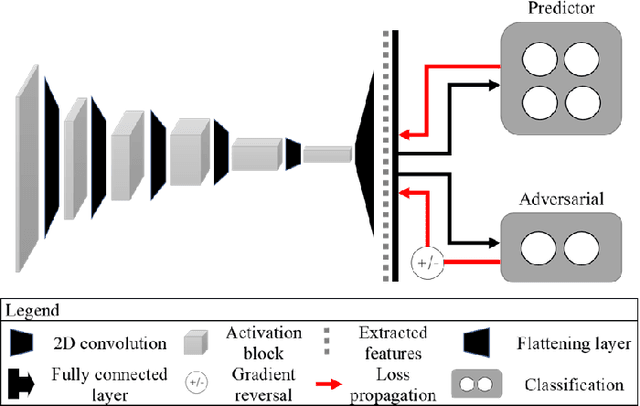
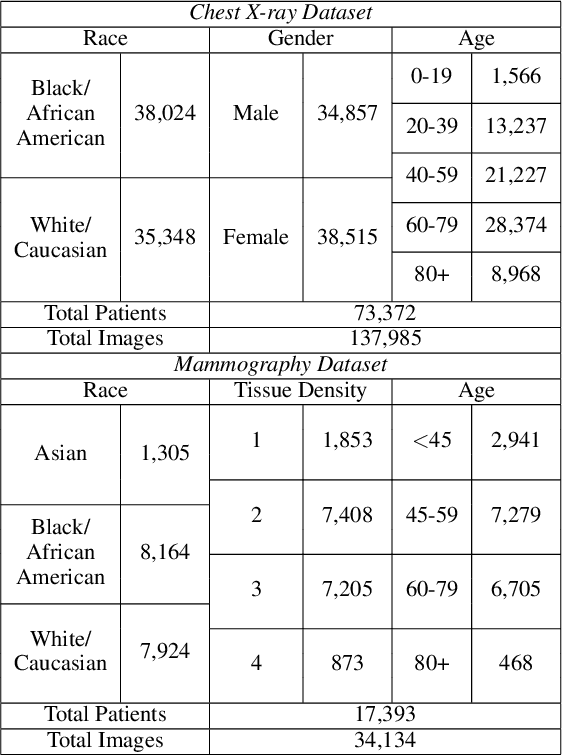
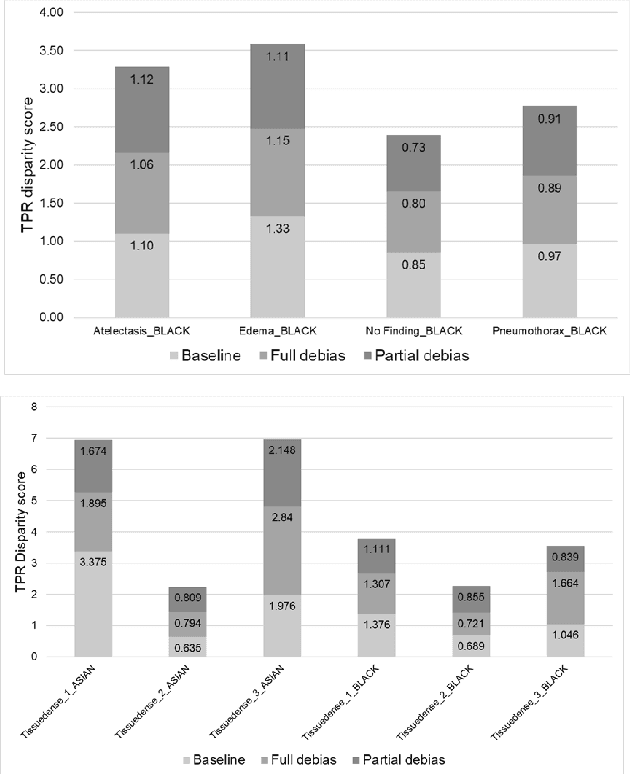
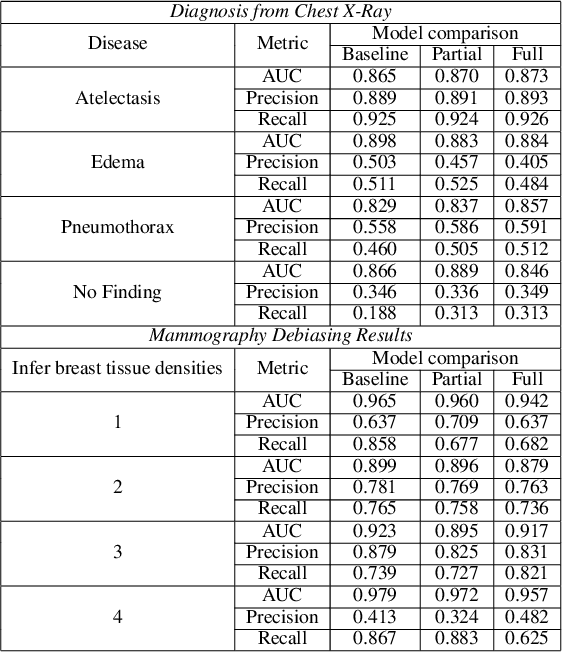
The use of artificial intelligence (AI) in healthcare has become a very active research area in the last few years. While significant progress has been made in image classification tasks, only a few AI methods are actually being deployed in hospitals. A major hurdle in actively using clinical AI models currently is the trustworthiness of these models. More often than not, these complex models are black boxes in which promising results are generated. However, when scrutinized, these models begin to reveal implicit biases during the decision making, such as detecting race and having bias towards ethnic groups and subpopulations. In our ongoing study, we develop a two-step adversarial debiasing approach with partial learning that can reduce the racial disparity while preserving the performance of the targeted task. The methodology has been evaluated on two independent medical image case-studies - chest X-ray and mammograms, and showed promises in bias reduction while preserving the targeted performance.
Efficient Spatial-Temporal Information Fusion for LiDAR-Based 3D Moving Object Segmentation
Jul 05, 2022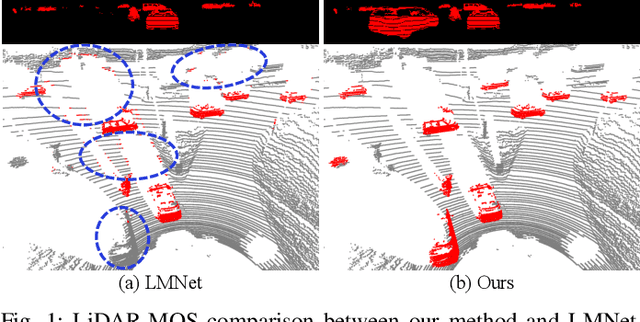
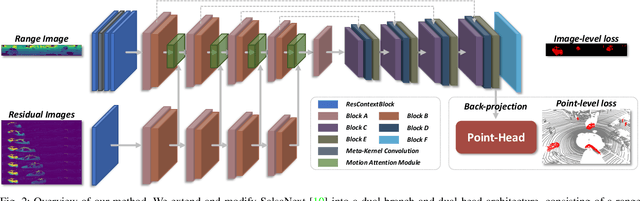
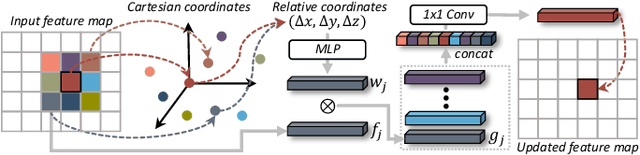
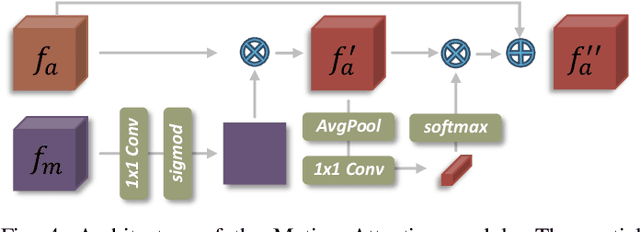
Accurate moving object segmentation is an essential task for autonomous driving. It can provide effective information for many downstream tasks, such as collision avoidance, path planning, and static map construction. How to effectively exploit the spatial-temporal information is a critical question for 3D LiDAR moving object segmentation (LiDAR-MOS). In this work, we propose a novel deep neural network exploiting both spatial-temporal information and different representation modalities of LiDAR scans to improve LiDAR-MOS performance. Specifically, we first use a range image-based dual-branch structure to separately deal with spatial and temporal information that can be obtained from sequential LiDAR scans, and later combine them using motion-guided attention modules. We also use a point refinement module via 3D sparse convolution to fuse the information from both LiDAR range image and point cloud representations and reduce the artifacts on the borders of the objects. We verify the effectiveness of our proposed approach on the LiDAR-MOS benchmark of SemanticKITTI. Our method outperforms the state-of-the-art methods significantly in terms of LiDAR-MOS IoU. Benefiting from the devised coarse-to-fine architecture, our method operates online at sensor frame rate. The implementation of our method is available as open source at: https://github.com/haomo-ai/MotionSeg3D.
SSH: A Self-Supervised Framework for Image Harmonization
Aug 17, 2021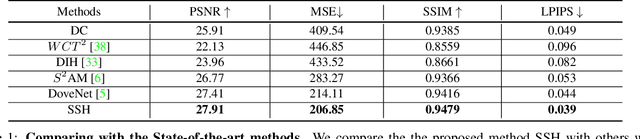
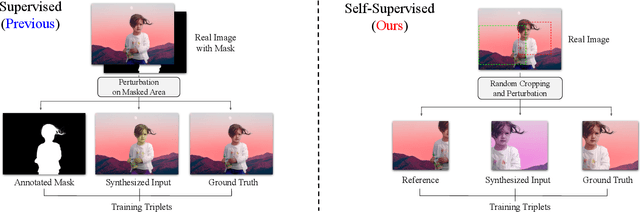
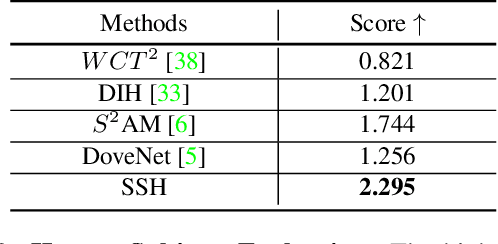
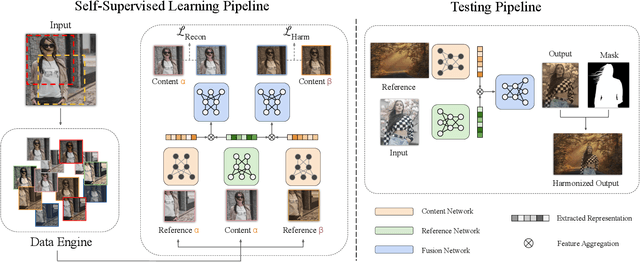
Image harmonization aims to improve the quality of image compositing by matching the "appearance" (\eg, color tone, brightness and contrast) between foreground and background images. However, collecting large-scale annotated datasets for this task requires complex professional retouching. Instead, we propose a novel Self-Supervised Harmonization framework (SSH) that can be trained using just "free" natural images without being edited. We reformulate the image harmonization problem from a representation fusion perspective, which separately processes the foreground and background examples, to address the background occlusion issue. This framework design allows for a dual data augmentation method, where diverse [foreground, background, pseudo GT] triplets can be generated by cropping an image with perturbations using 3D color lookup tables (LUTs). In addition, we build a real-world harmonization dataset as carefully created by expert users, for evaluation and benchmarking purposes. Our results show that the proposed self-supervised method outperforms previous state-of-the-art methods in terms of reference metrics, visual quality, and subject user study. Code and dataset are available at \url{https://github.com/VITA-Group/SSHarmonization}.
Temporal extrapolation of heart wall segmentation in cardiac magnetic resonance images via pixel tracking
Jul 30, 2022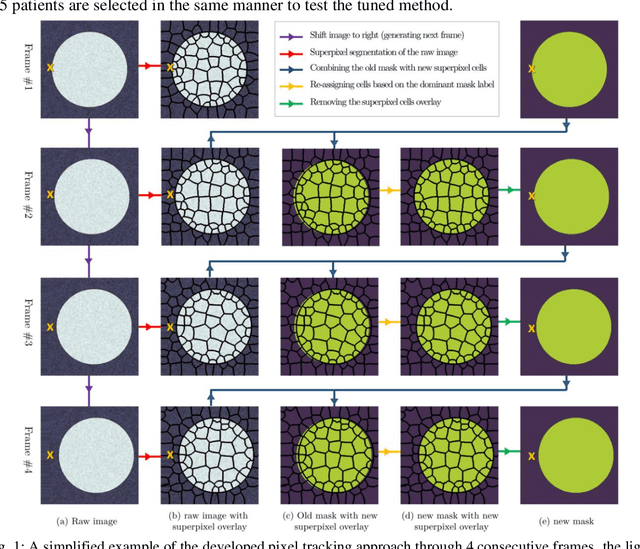
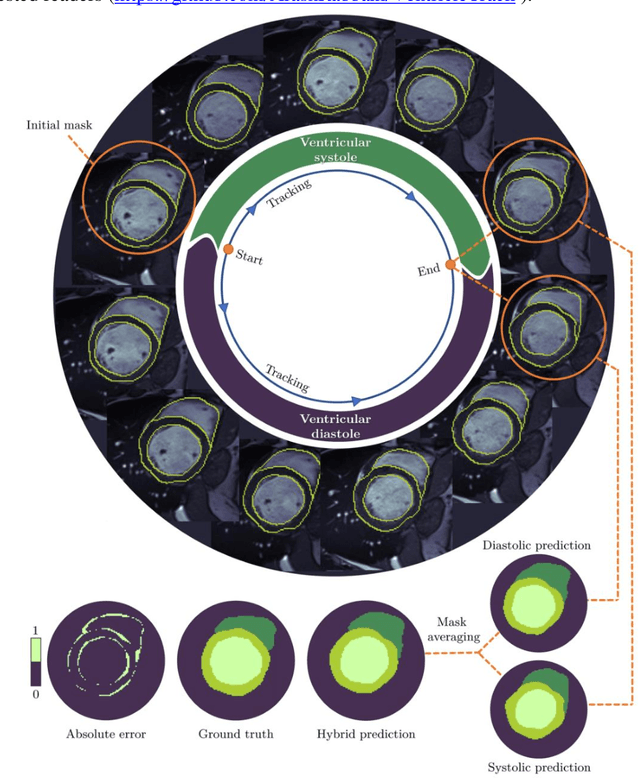
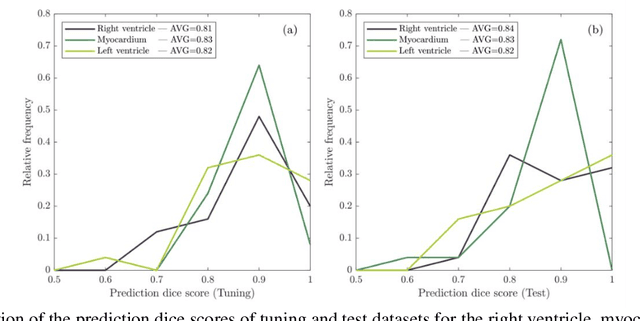
In this study, we have tailored a pixel tracking method for temporal extrapolation of the ventricular segmentation masks in cardiac magnetic resonance images. The pixel tracking process starts from the end-diastolic frame of the heart cycle using the available manually segmented images to predict the end-systolic segmentation mask. The superpixels approach is used to divide the raw images into smaller cells and in each time frame, new labels are assigned to the image cells which leads to tracking the movement of the heart wall elements through different frames. The tracked masks at the end of systole are compared with the already available manually segmented masks and dice scores are found to be between 0.81 to 0.84. Considering the fact that the proposed method does not necessarily require a training dataset, it could be an attractive alternative approach to deep learning segmentation methods in scenarios where training data are limited.
Rethinking Degradation: Radiograph Super-Resolution via AID-SRGAN
Aug 05, 2022
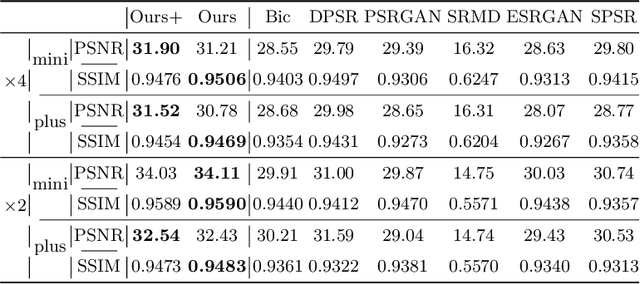
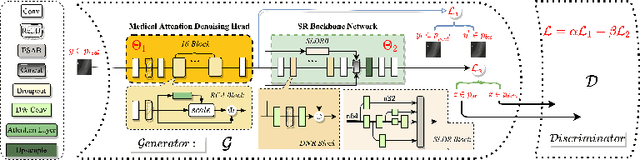

In this paper, we present a medical AttentIon Denoising Super Resolution Generative Adversarial Network (AID-SRGAN) for diographic image super-resolution. First, we present a medical practical degradation model that considers various degradation factors beyond downsampling. To the best of our knowledge, this is the first composite degradation model proposed for radiographic images. Furthermore, we propose AID-SRGAN, which can simultaneously denoise and generate high-resolution (HR) radiographs. In this model, we introduce an attention mechanism into the denoising module to make it more robust to complicated degradation. Finally, the SR module reconstructs the HR radiographs using the "clean" low-resolution (LR) radiographs. In addition, we propose a separate-joint training approach to train the model, and extensive experiments are conducted to show that the proposed method is superior to its counterparts. e.g., our proposed method achieves $31.90$ of PSNR with a scale factor of $4 \times$, which is $7.05 \%$ higher than that obtained by recent work, SPSR [16]. Our dataset and code will be made available at: https://github.com/yongsongH/AIDSRGAN-MICCAI2022.
Test-Time Adaptation with Shape Moments for Image Segmentation
May 16, 2022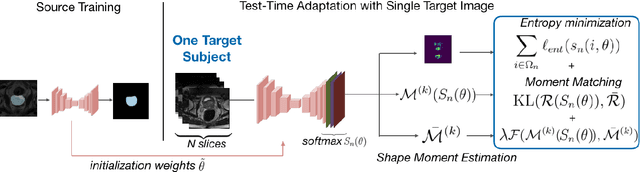
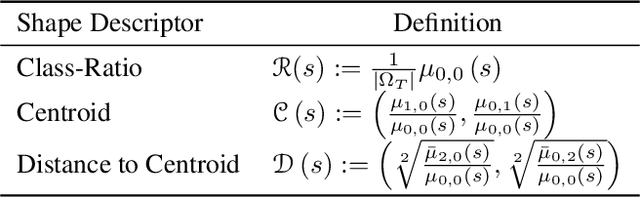
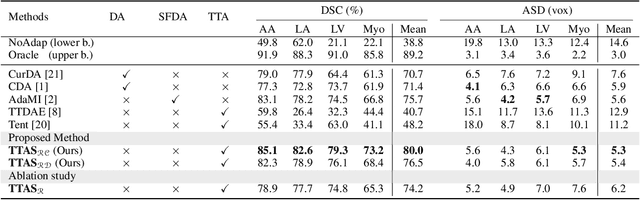

Supervised learning is well-known to fail at generalization under distribution shifts. In typical clinical settings, the source data is inaccessible and the target distribution is represented with a handful of samples: adaptation can only happen at test time on a few or even a single subject(s). We investigate test-time single-subject adaptation for segmentation, and propose a Shape-guided Entropy Minimization objective for tackling this task. During inference for a single testing subject, our loss is minimized with respect to the batch normalization's scale and bias parameters. We show the potential of integrating various shape priors to guide adaptation to plausible solutions, and validate our method in two challenging scenarios: MRI-to-CT adaptation of cardiac segmentation and cross-site adaptation of prostate segmentation. Our approach exhibits substantially better performances than the existing test-time adaptation methods. Even more surprisingly, it fares better than state-of-the-art domain adaptation methods, although it forgoes training on additional target data during adaptation. Our results question the usefulness of training on target data in segmentation adaptation, and points to the substantial effect of shape priors on test-time inference. Our framework can be readily used for integrating various priors and for adapting any segmentation network, and our code is available.
Improving Semantic Segmentation in Transformers using Hierarchical Inter-Level Attention
Jul 05, 2022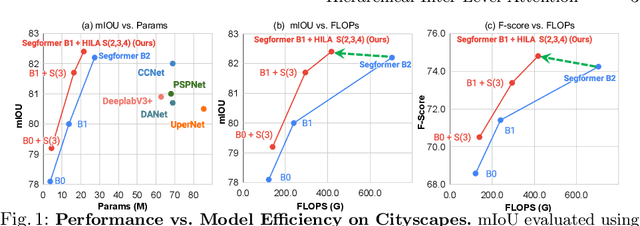
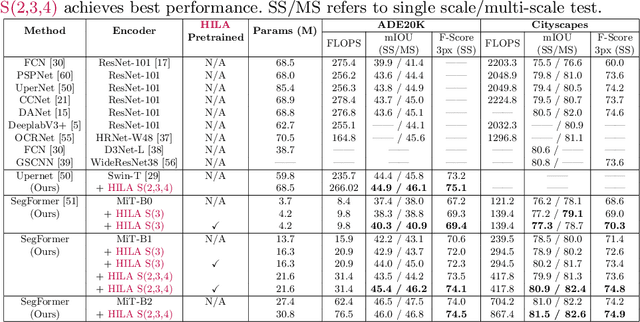
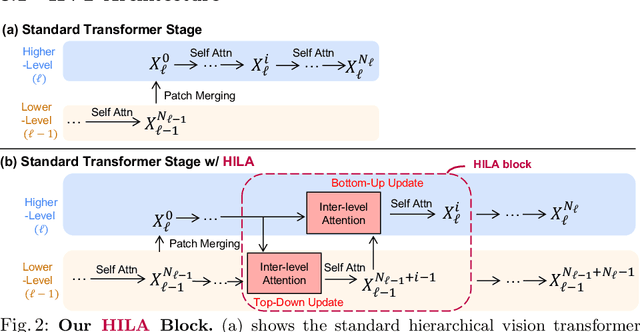
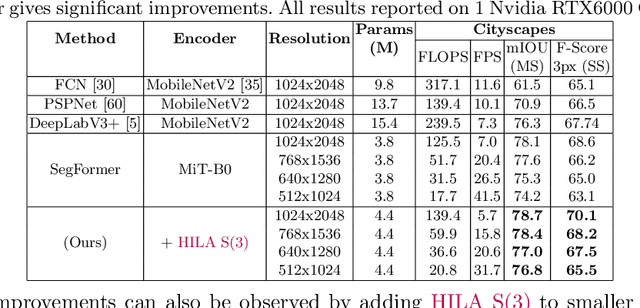
Existing transformer-based image backbones typically propagate feature information in one direction from lower to higher-levels. This may not be ideal since the localization ability to delineate accurate object boundaries, is most prominent in the lower, high-resolution feature maps, while the semantics that can disambiguate image signals belonging to one object vs. another, typically emerges in a higher level of processing. We present Hierarchical Inter-Level Attention (HILA), an attention-based method that captures Bottom-Up and Top-Down Updates between features of different levels. HILA extends hierarchical vision transformer architectures by adding local connections between features of higher and lower levels to the backbone encoder. In each iteration, we construct a hierarchy by having higher-level features compete for assignments to update lower-level features belonging to them, iteratively resolving object-part relationships. These improved lower-level features are then used to re-update the higher-level features. HILA can be integrated into the majority of hierarchical architectures without requiring any changes to the base model. We add HILA into SegFormer and the Swin Transformer and show notable improvements in accuracy in semantic segmentation with fewer parameters and FLOPS. Project website and code: https://www.cs.toronto.edu/~garyleung/hila/
Learning to Identify Drilling Defects in Turbine Blades with Single Stage Detectors
Aug 08, 2022
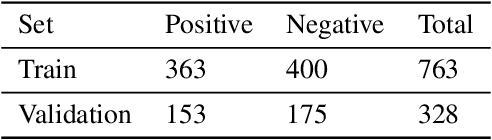
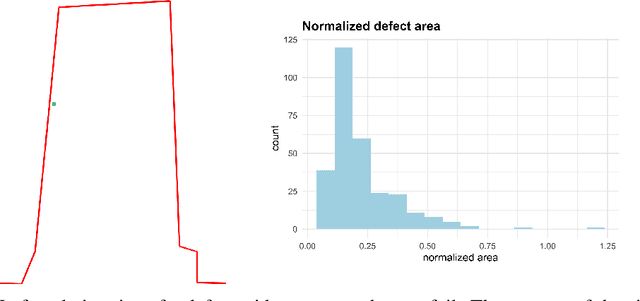
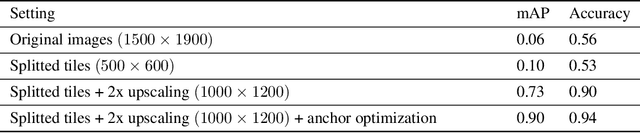
Nondestructive testing (NDT) is widely applied to defect identification of turbine components during manufacturing and operation. Operational efficiency is key for gas turbine OEM (Original Equipment Manufacturers). Automating the inspection process as much as possible, while minimizing the uncertainties involved, is thus crucial. We propose a model based on RetinaNet to identify drilling defects in X-ray images of turbine blades. The application is challenging due to the large image resolutions in which defects are very small and hardly captured by the commonly used anchor sizes, and also due to the small size of the available dataset. As a matter of fact, all these issues are pretty common in the application of Deep Learning-based object detection models to industrial defect data. We overcome such issues using open source models, splitting the input images into tiles and scaling them up, applying heavy data augmentation, and optimizing the anchor size and aspect ratios with a differential evolution solver. We validate the model with $3$-fold cross-validation, showing a very high accuracy in identifying images with defects. We also define a set of best practices which can help other practitioners overcome similar challenges.