 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SSH: A Self-Supervised Framework for Image Harmonization
Aug 15, 2021
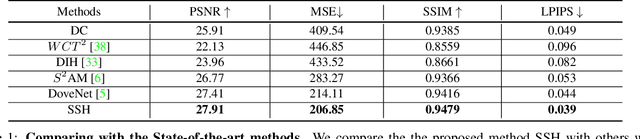
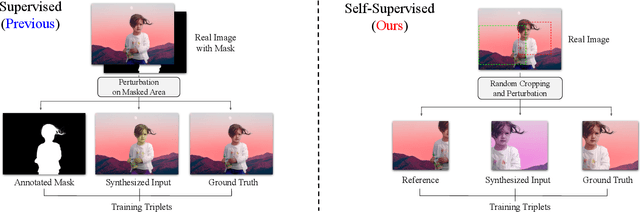
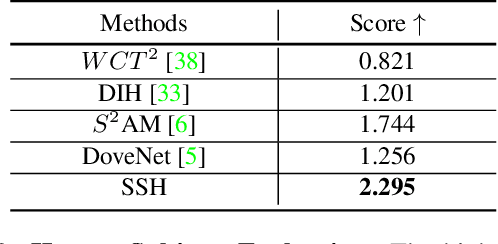
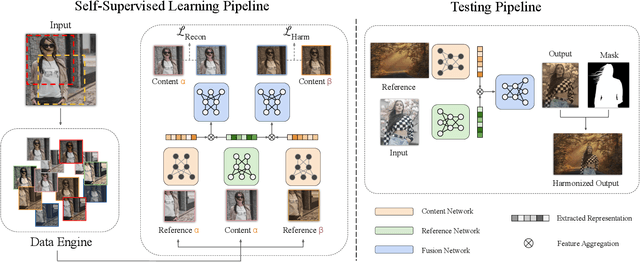
Image harmonization aims to improve the quality of image compositing by matching the "appearance" (\eg, color tone, brightness and contrast) between foreground and background images. However, collecting large-scale annotated datasets for this task requires complex professional retouching. Instead, we propose a novel Self-Supervised Harmonization framework (SSH) that can be trained using just "free" natural images without being edited. We reformulate the image harmonization problem from a representation fusion perspective, which separately processes the foreground and background examples, to address the background occlusion issue. This framework design allows for a dual data augmentation method, where diverse [foreground, background, pseudo GT] triplets can be generated by cropping an image with perturbations using 3D color lookup tables (LUTs). In addition, we build a real-world harmonization dataset as carefully created by expert users, for evaluation and benchmarking purposes. Our results show that the proposed self-supervised method outperforms previous state-of-the-art methods in terms of reference metrics, visual quality, and subject user study. Code and dataset are available at \url{https://github.com/VITA-Group/SSHarmonization}.
The Winning Solution to the iFLYTEK Challenge 2021 Cultivated Land Extraction from High-Resolution Remote Sensing Image
Feb 23, 2022
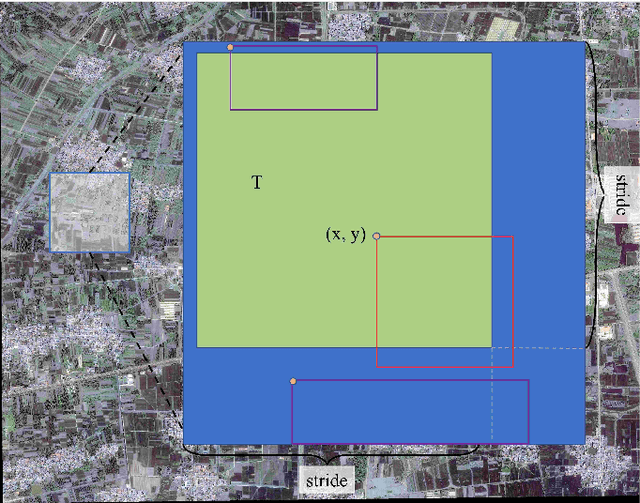
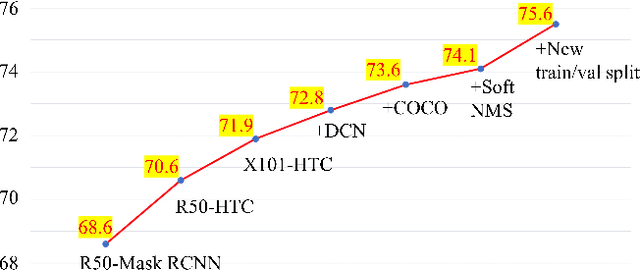
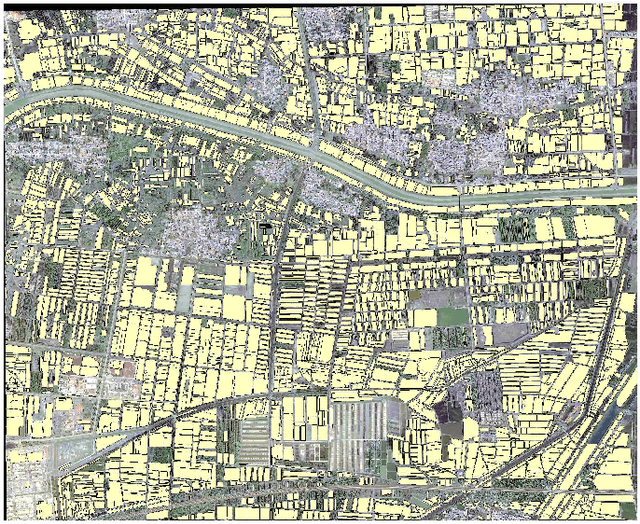
Extracting cultivated land accurately from high-resolution remote images is a basic task for precision agriculture. This report introduces our solution to the iFLYTEK challenge 2021 cultivated land extraction from high-resolution remote sensing image. The challenge requires segmenting cultivated land objects in very high-resolution multispectral remote sensing images. We established a highly effective and efficient pipeline to solve this problem. We first divided the original images into small tiles and separately performed instance segmentation on each tile. We explored several instance segmentation algorithms that work well on natural images and developed a set of effective methods that are applicable to remote sensing images. Then we merged the prediction results of all small tiles into seamless, continuous segmentation results through our proposed overlap-tile fusion strategy. We achieved the first place among 486 teams in the challenge.
AMOS: A Large-Scale Abdominal Multi-Organ Benchmark for Versatile Medical Image Segmentation
Jun 16, 2022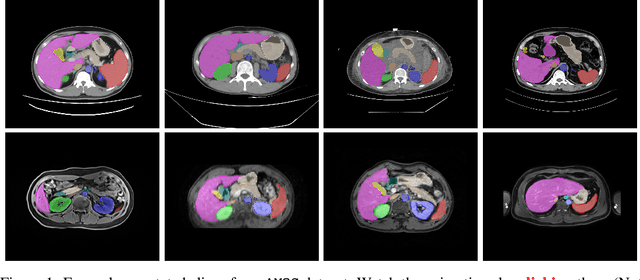
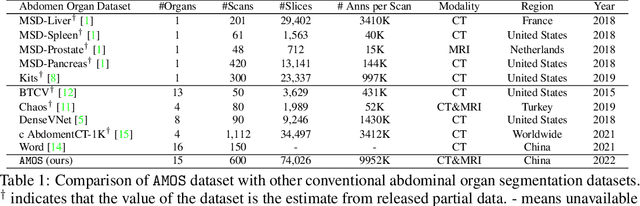
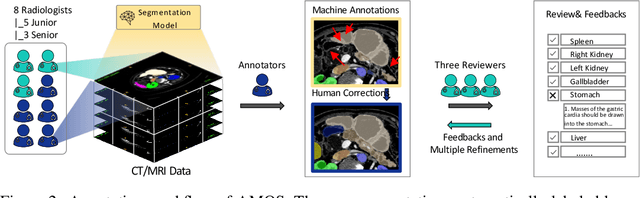
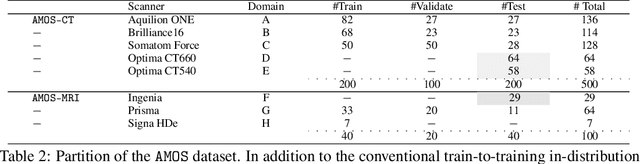
Despite the considerable progress in automatic abdominal multi-organ segmentation from CT/MRI scans in recent years, a comprehensive evaluation of the models' capabilities is hampered by the lack of a large-scale benchmark from diverse clinical scenarios. Constraint by the high cost of collecting and labeling 3D medical data, most of the deep learning models to date are driven by datasets with a limited number of organs of interest or samples, which still limits the power of modern deep models and makes it difficult to provide a fully comprehensive and fair estimate of various methods. To mitigate the limitations, we present AMOS, a large-scale, diverse, clinical dataset for abdominal organ segmentation. AMOS provides 500 CT and 100 MRI scans collected from multi-center, multi-vendor, multi-modality, multi-phase, multi-disease patients, each with voxel-level annotations of 15 abdominal organs, providing challenging examples and test-bed for studying robust segmentation algorithms under diverse targets and scenarios. We further benchmark several state-of-the-art medical segmentation models to evaluate the status of the existing methods on this new challenging dataset. We have made our datasets, benchmark servers, and baselines publicly available, and hope to inspire future research. Information can be found at https://amos22.grand-challenge.org.
Inpainting at Modern Camera Resolution by Guided PatchMatch with Auto-Curation
Aug 06, 2022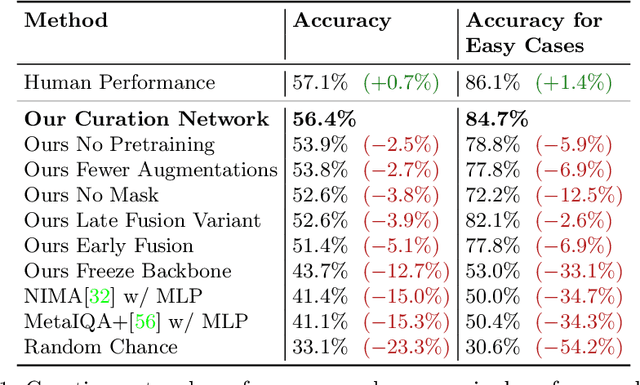

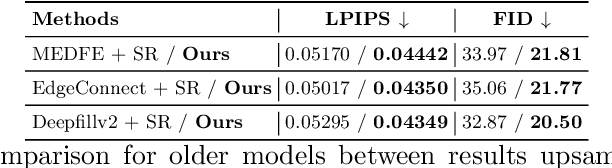

Recently, deep models have established SOTA performance for low-resolution image inpainting, but they lack fidelity at resolutions associated with modern cameras such as 4K or more, and for large holes. We contribute an inpainting benchmark dataset of photos at 4K and above representative of modern sensors. We demonstrate a novel framework that combines deep learning and traditional methods. We use an existing deep inpainting model LaMa to fill the hole plausibly, establish three guide images consisting of structure, segmentation, depth, and apply a multiply-guided PatchMatch to produce eight candidate upsampled inpainted images. Next, we feed all candidate inpaintings through a novel curation module that chooses a good inpainting by column summation on an 8x8 antisymmetric pairwise preference matrix. Our framework's results are overwhelmingly preferred by users over 8 strong baselines, with improvements of quantitative metrics up to 7.4 over the best baseline LaMa, and our technique when paired with 4 different SOTA inpainting backbones improves each such that ours is overwhelmingly preferred by users over a strong super-res baseline.
Benchmarking Safety Monitors for Image Classifiers with Machine Learning
Oct 04, 2021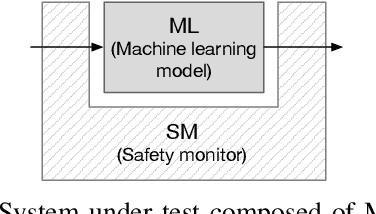
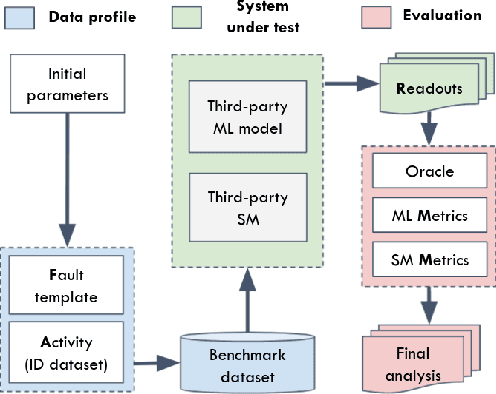
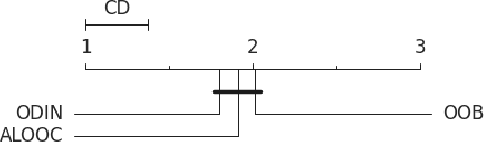
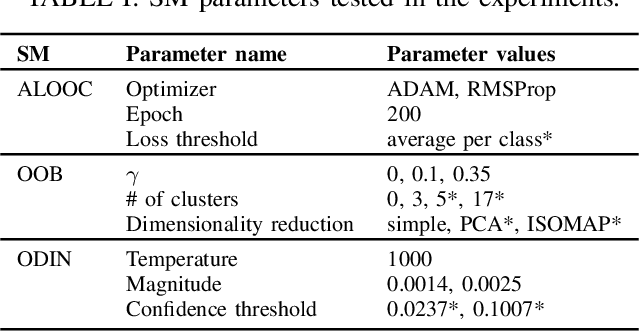
High-accurate machine learning (ML) image classifiers cannot guarantee that they will not fail at operation. Thus, their deployment in safety-critical applications such as autonomous vehicles is still an open issue. The use of fault tolerance mechanisms such as safety monitors is a promising direction to keep the system in a safe state despite errors of the ML classifier. As the prediction from the ML is the core information directly impacting safety, many works are focusing on monitoring the ML model itself. Checking the efficiency of such monitors in the context of safety-critical applications is thus a significant challenge. Therefore, this paper aims at establishing a baseline framework for benchmarking monitors for ML image classifiers. Furthermore, we propose a framework covering the entire pipeline, from data generation to evaluation. Our approach measures monitor performance with a broader set of metrics than usually proposed in the literature. Moreover, we benchmark three different monitor approaches in 79 benchmark datasets containing five categories of out-of-distribution data for image classifiers: class novelty, noise, anomalies, distributional shifts, and adversarial attacks. Our results indicate that these monitors are no more accurate than a random monitor. We also release the code of all experiments for reproducibility.
Beta Generalized Normal Distribution with an Application for SAR Image Processing
Jun 03, 2022We introduce the beta generalized normal distribution which is obtained by compounding the beta and generalized normal [Nadarajah, S., A generalized normal distribution, \emph{Journal of Applied Statistics}. 32, 685--694, 2005] distributions. The new model includes as sub-models the beta normal, beta Laplace, normal, and Laplace distributions. The shape of the new distribution is quite flexible, specially the skewness and the tail weights, due to two additional parameters. We obtain general expansions for the moments. The estimation of the parameters is investigated by maximum likelihood. We also proposed a random number generator for the new distribution. Actual synthetic aperture radar were analyzed and modeled after the new distribution. Results could outperform the $\mathcal{G}^0$, $\mathcal{K}$, and $\Gamma$ distributions in several scenarios.
* 17 pages, 2 tables, 6 figures
Exploring Feature Representation Learning for Semi-supervised Medical Image Segmentation
Nov 22, 2021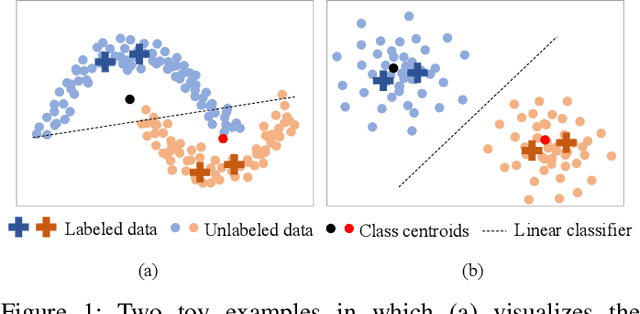
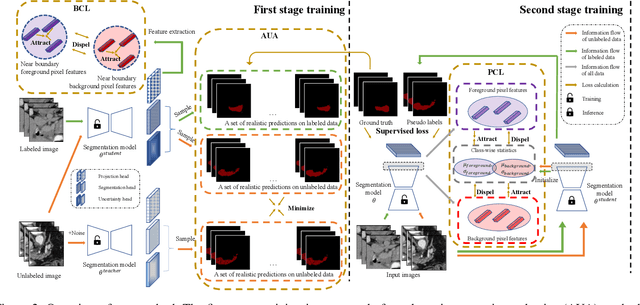
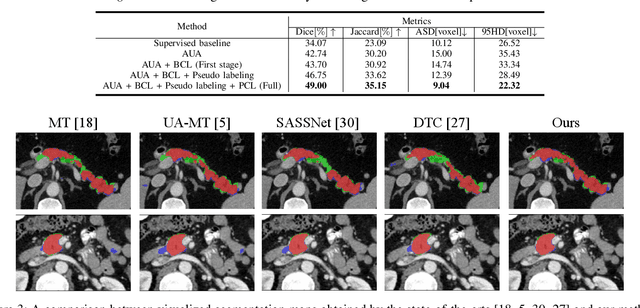
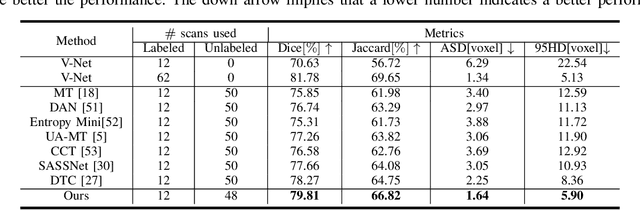
This paper presents a simple yet effective two-stage framework for semi-supervised medical image segmentation. Our key insight is to explore the feature representation learning with labeled and unlabeled (i.e., pseudo labeled) images to enhance the segmentation performance. In the first stage, we present an aleatoric uncertainty-aware method, namely AUA, to improve the segmentation performance for generating high-quality pseudo labels. Considering the inherent ambiguity of medical images, AUA adaptively regularizes the consistency on images with low ambiguity. To enhance the representation learning, we propose a stage-adaptive contrastive learning method, including a boundary-aware contrastive loss to regularize the labeled images in the first stage and a prototype-aware contrastive loss to optimize both labeled and pseudo labeled images in the second stage. The boundary-aware contrastive loss only optimizes pixels around the segmentation boundaries to reduce the computational cost. The prototype-aware contrastive loss fully leverages both labeled images and pseudo labeled images by building a centroid for each class to reduce computational cost for pair-wise comparison. Our method achieves the best results on two public medical image segmentation benchmarks. Notably, our method outperforms the prior state-of-the-art by 5.7% on Dice for colon tumor segmentation relying on just 5% labeled images.
Sharp-GAN: Sharpness Loss Regularized GAN for Histopathology Image Synthesis
Oct 27, 2021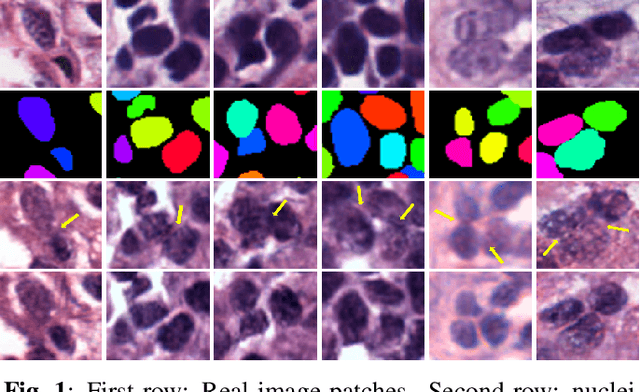
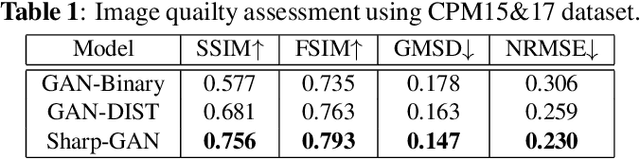
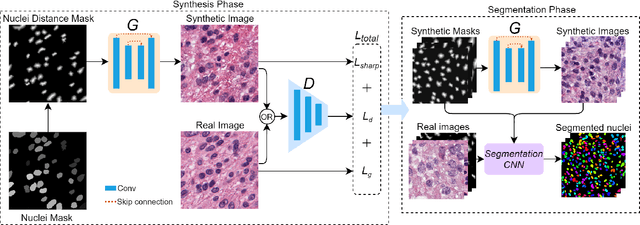

Existing deep learning-based approaches for histopathology image analysis require large annotated training sets to achieve good performance; but annotating histopathology images is slow and resource-intensive. Conditional generative adversarial networks have been applied to generate synthetic histopathology images to alleviate this issue, but current approaches fail to generate clear contours for overlapped and touching nuclei. In this study, We propose a sharpness loss regularized generative adversarial network to synthesize realistic histopathology images. The proposed network uses normalized nucleus distance map rather than the binary mask to encode nuclei contour information. The proposed sharpness loss enhances the contrast of nuclei contour pixels. The proposed method is evaluated using four image quality metrics and segmentation results on two public datasets. Both quantitative and qualitative results demonstrate that the proposed approach can generate realistic histopathology images with clear nuclei contours.
Towards the Use of Saliency Maps for Explaining Low-Quality Electrocardiograms to End Users
Jul 06, 2022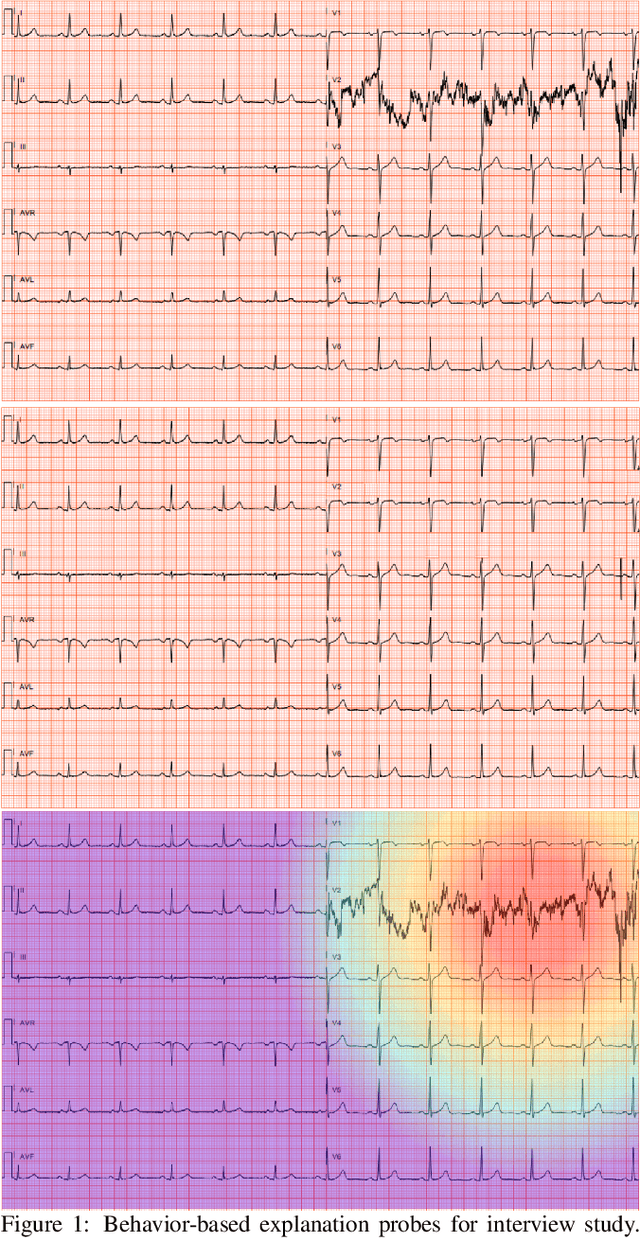

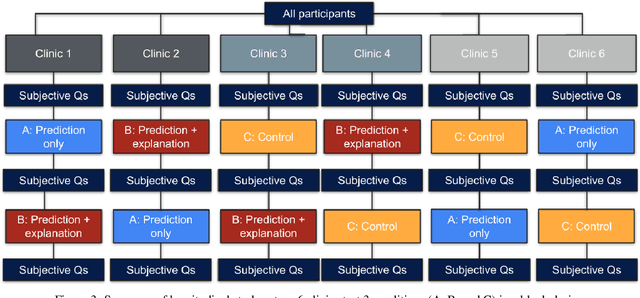
When using medical images for diagnosis, either by clinicians or artificial intelligence (AI) systems, it is important that the images are of high quality. When an image is of low quality, the medical exam that produced the image often needs to be redone. In telemedicine, a common problem is that the quality issue is only flagged once the patient has left the clinic, meaning they must return in order to have the exam redone. This can be especially difficult for people living in remote regions, who make up a substantial portion of the patients at Portal Telemedicina, a digital healthcare organization based in Brazil. In this paper, we report on ongoing work regarding (i) the development of an AI system for flagging and explaining low-quality medical images in real-time, (ii) an interview study to understand the explanation needs of stakeholders using the AI system at OurCompany, and, (iii) a longitudinal user study design to examine the effect of including explanations on the workflow of the technicians in our clinics. To the best of our knowledge, this would be the first longitudinal study on evaluating the effects of XAI methods on end-users -- stakeholders that use AI systems but do not have AI-specific expertise. We welcome feedback and suggestions on our experimental setup.
DSR -- A dual subspace re-projection network for surface anomaly detection
Aug 02, 2022
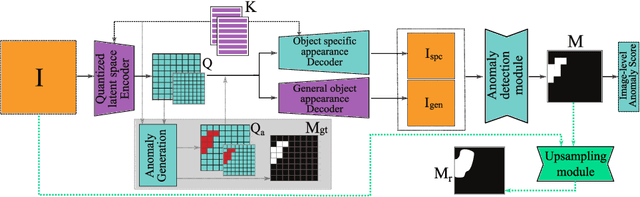
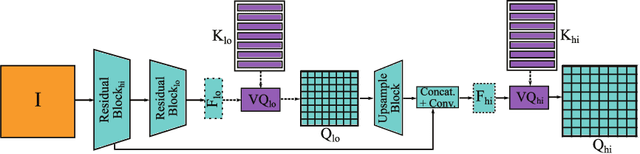
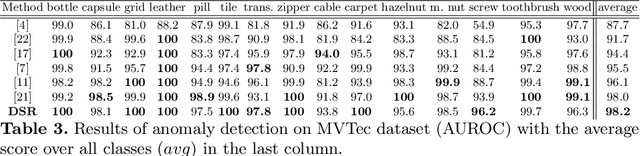
The state-of-the-art in discriminative unsupervised surface anomaly detection relies on external datasets for synthesizing anomaly-augmented training images. Such approaches are prone to failure on near-in-distribution anomalies since these are difficult to be synthesized realistically due to their similarity to anomaly-free regions. We propose an architecture based on quantized feature space representation with dual decoders, DSR, that avoids the image-level anomaly synthesis requirement. Without making any assumptions about the visual properties of anomalies, DSR generates the anomalies at the feature level by sampling the learned quantized feature space, which allows a controlled generation of near-in-distribution anomalies. DSR achieves state-of-the-art results on the KSDD2 and MVTec anomaly detection datasets. The experiments on the challenging real-world KSDD2 dataset show that DSR significantly outperforms other unsupervised surface anomaly detection methods, improving the previous top-performing methods by 10% AP in anomaly detection and 35% AP in anomaly localization.