 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Toward Clinically Assisted Colorectal Polyp Recognition via Structured Cross-modal Representation Consistency
Jun 24, 2022
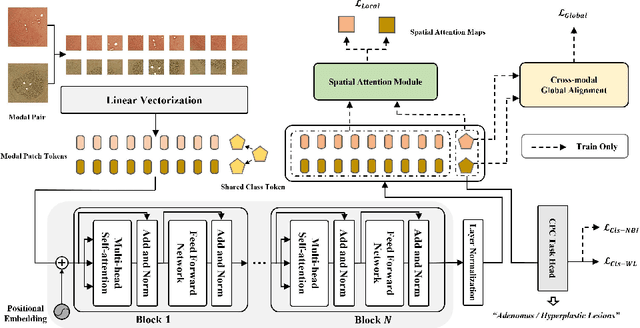
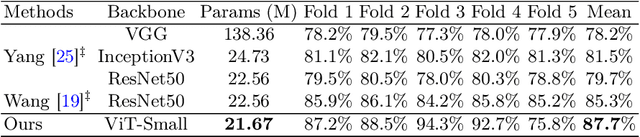
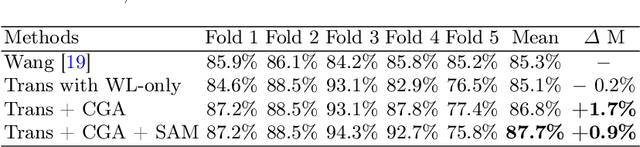
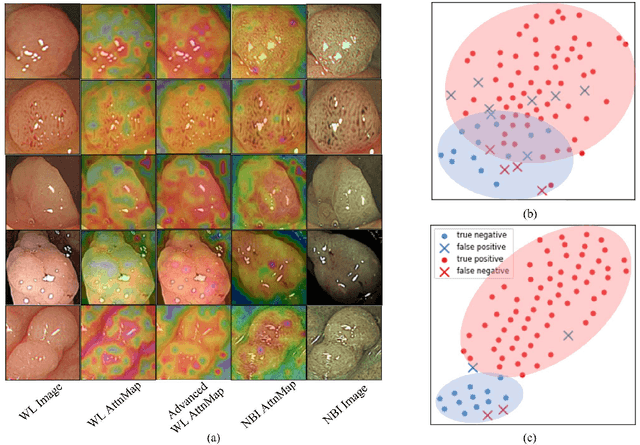
The colorectal polyps classification is a critical clinical examination. To improve the classification accuracy, most computer-aided diagnosis algorithms recognize colorectal polyps by adopting Narrow-Band Imaging (NBI). However, the NBI usually suffers from missing utilization in real clinic scenarios since the acquisition of this specific image requires manual switching of the light mode when polyps have been detected by using White-Light (WL) images. To avoid the above situation, we propose a novel method to directly achieve accurate white-light colonoscopy image classification by conducting structured cross-modal representation consistency. In practice, a pair of multi-modal images, i.e. NBI and WL, are fed into a shared Transformer to extract hierarchical feature representations. Then a novel designed Spatial Attention Module (SAM) is adopted to calculate the similarities between the class token and patch tokens %from multi-levels for a specific modality image. By aligning the class tokens and spatial attention maps of paired NBI and WL images at different levels, the Transformer achieves the ability to keep both global and local representation consistency for the above two modalities. Extensive experimental results illustrate the proposed method outperforms the recent studies with a margin, realizing multi-modal prediction with a single Transformer while greatly improving the classification accuracy when only with WL images.
A Simple Approach to Image Tilt Correction with Self-Attention MobileNet for Smartphones
Oct 31, 2021

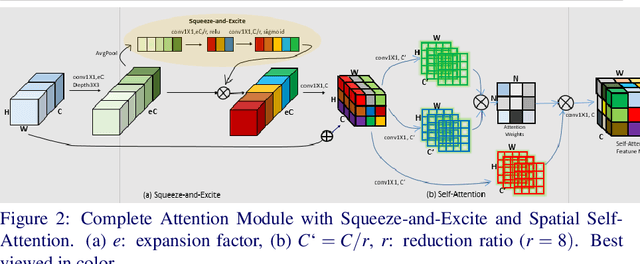
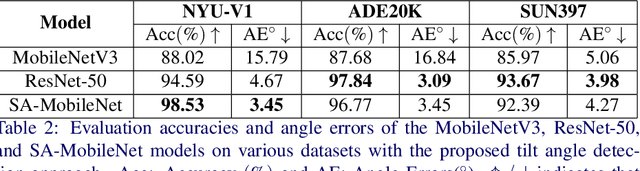
The main contributions of our work are two-fold. First, we present a Self-Attention MobileNet, called SA-MobileNet Network that can model long-range dependencies between the image features instead of processing the local region as done by standard convolutional kernels. SA-MobileNet contains self-attention modules integrated with the inverted bottleneck blocks of the MobileNetV3 model which results in modeling of both channel-wise attention and spatial attention of the image features and at the same time introduce a novel self-attention architecture for low-resource devices. Secondly, we propose a novel training pipeline for the task of image tilt detection. We treat this problem in a multi-label scenario where we predict multiple angles for a tilted input image in a narrow interval of range 1-2 degrees, depending on the dataset used. This process induces an implicit correlation between labels without any computational overhead of the second or higher-order methods in multi-label learning. With the combination of our novel approach and the architecture, we present state-of-the-art results on detecting the image tilt angle on mobile devices as compared to the MobileNetV3 model. Finally, we establish that SA-MobileNet is more accurate than MobileNetV3 on SUN397, NYU-V1, and ADE20K datasets by 6.42%, 10.51%, and 9.09% points respectively, and faster by at least 4 milliseconds on Snapdragon 750 Octa-core.
Two-Stream Transformer Architecture for Long Video Understanding
Aug 02, 2022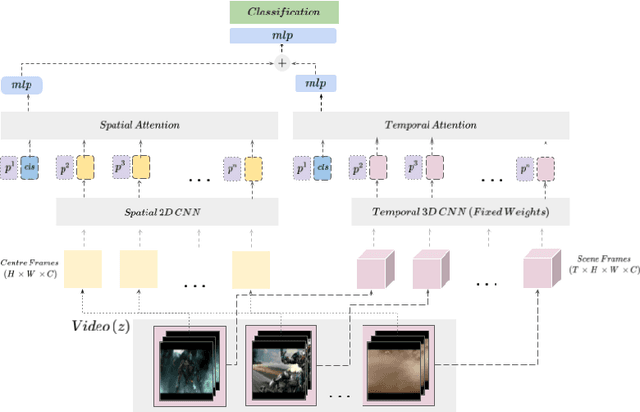
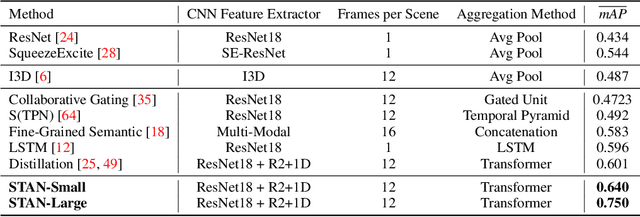
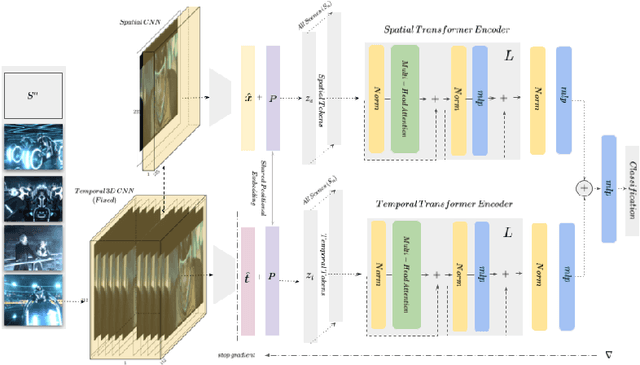
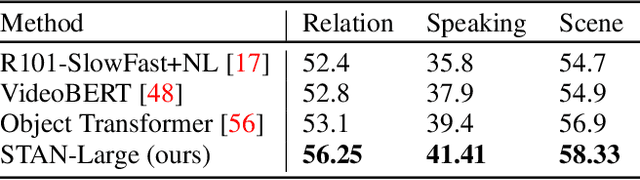
Pure vision transformer architectures are highly effective for short video classification and action recognition tasks. However, due to the quadratic complexity of self attention and lack of inductive bias, transformers are resource intensive and suffer from data inefficiencies. Long form video understanding tasks amplify data and memory efficiency problems in transformers making current approaches unfeasible to implement on data or memory restricted domains. This paper introduces an efficient Spatio-Temporal Attention Network (STAN) which uses a two-stream transformer architecture to model dependencies between static image features and temporal contextual features. Our proposed approach can classify videos up to two minutes in length on a single GPU, is data efficient, and achieves SOTA performance on several long video understanding tasks.
Exploiting Cross-Modal Prediction and Relation Consistency for Semi-Supervised Image Captioning
Oct 28, 2021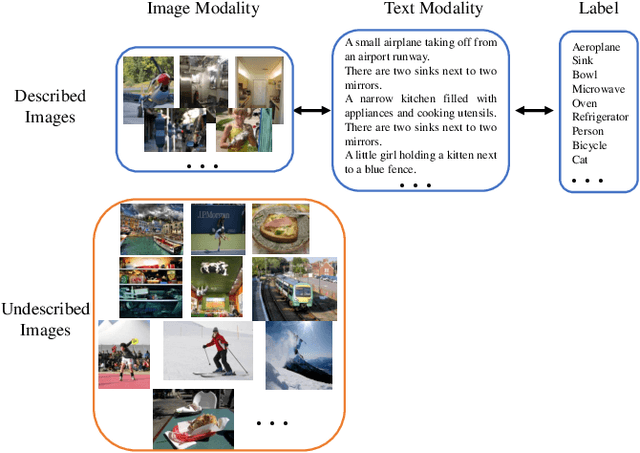
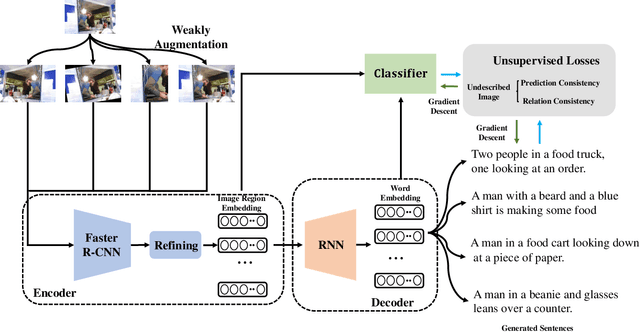
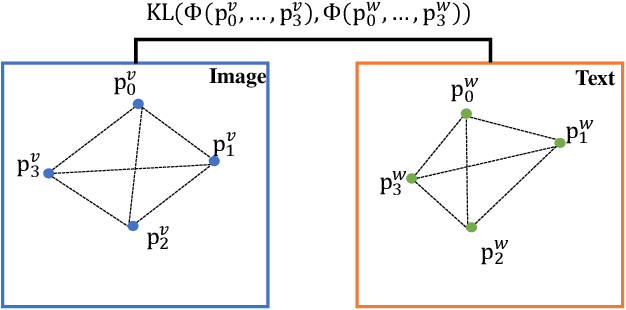
The task of image captioning aims to generate captions directly from images via the automatically learned cross-modal generator. To build a well-performing generator, existing approaches usually need a large number of described images, which requires a huge effects on manual labeling. However, in real-world applications, a more general scenario is that we only have limited amount of described images and a large number of undescribed images. Therefore, a resulting challenge is how to effectively combine the undescribed images into the learning of cross-modal generator. To solve this problem, we propose a novel image captioning method by exploiting the Cross-modal Prediction and Relation Consistency (CPRC), which aims to utilize the raw image input to constrain the generated sentence in the commonly semantic space. In detail, considering that the heterogeneous gap between modalities always leads to the supervision difficulty of using the global embedding directly, CPRC turns to transform both the raw image and corresponding generated sentence into the shared semantic space, and measure the generated sentence from two aspects: 1) Prediction consistency. CPRC utilizes the prediction of raw image as soft label to distill useful supervision for the generated sentence, rather than employing the traditional pseudo labeling; 2) Relation consistency. CPRC develops a novel relation consistency between augmented images and corresponding generated sentences to retain the important relational knowledge. In result, CPRC supervises the generated sentence from both the informativeness and representativeness perspectives, and can reasonably use the undescribed images to learn a more effective generator under the semi-supervised scenario.
Exploring Content Based Image Retrieval for Highly Imbalanced Melanoma Data using Style Transfer, Semantic Image Segmentation and Ensemble Learning
Oct 12, 2021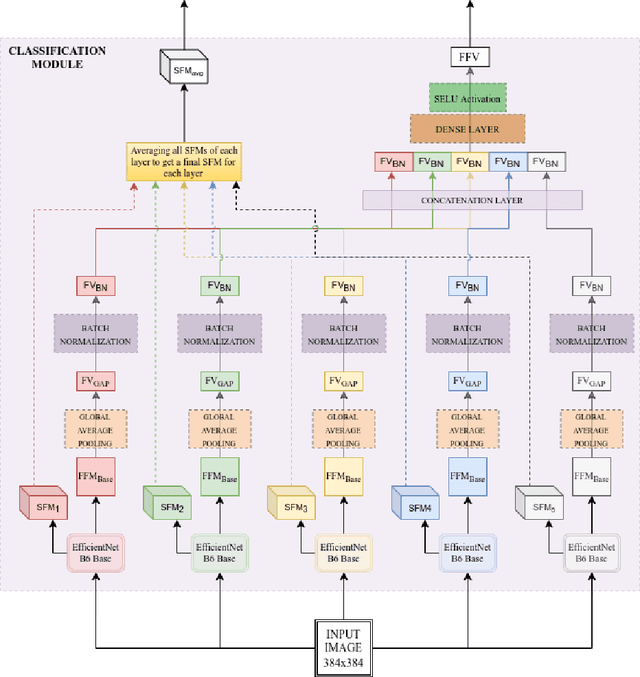
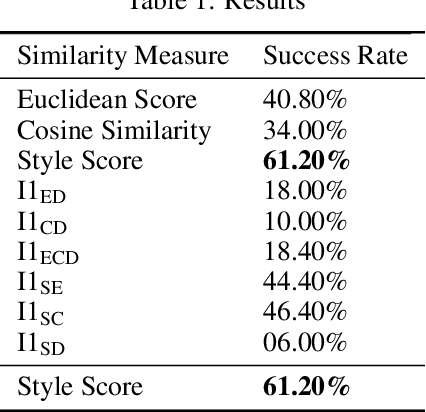

Lesion images are frequently taken in open-set settings. Because of this, the image data generated is extremely varied in nature.It is difficult for a convolutional neural network to find proper features and generalise well, as a result content based image retrieval (CBIR) system for lesion images are difficult to build. This paper explores this domain and proposes multiple similarity measures which uses Style Loss and Dice Coefficient via a novel similarity measure called I1-Score. Out of the CBIR similarity measures proposed, pure style loss approach achieves a remarkable accuracy increase over traditional approaches like Euclidean Distance and Cosine Similarity. The I1-Scores using style loss performed better than traditional approaches by a small margin, whereas, I1-Scores with dice-coefficient faired very poorly. The model used is trained using ensemble learning for better generalization.
Camera Pose Auto-Encoders for Improving Pose Regression
Jul 12, 2022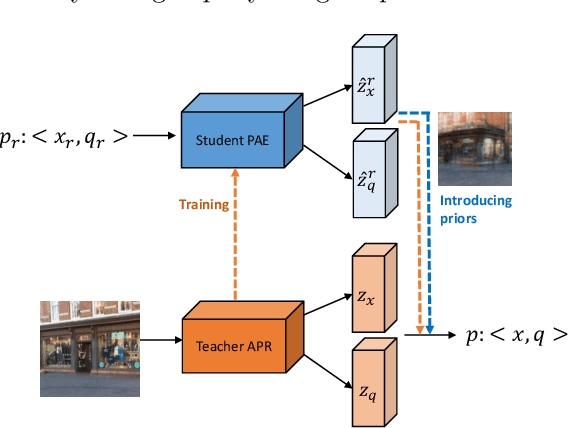

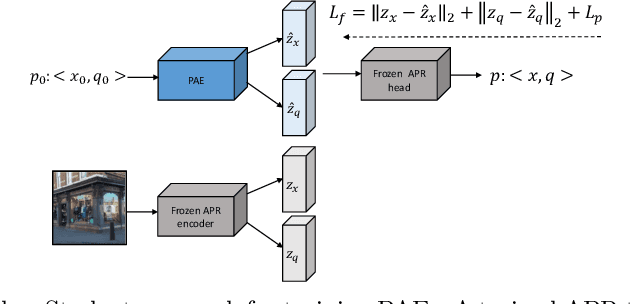
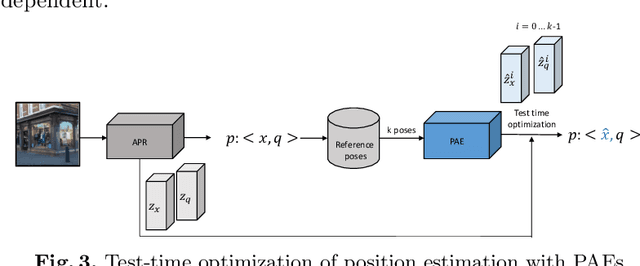
Absolute pose regressor (APR) networks are trained to estimate the pose of the camera given a captured image. They compute latent image representations from which the camera position and orientation are regressed. APRs provide a different tradeoff between localization accuracy, runtime, and memory, compared to structure-based localization schemes that provide state-of-the-art accuracy. In this work, we introduce Camera Pose Auto-Encoders (PAEs), multilayer perceptrons that are trained via a Teacher-Student approach to encode camera poses using APRs as their teachers. We show that the resulting latent pose representations can closely reproduce APR performance and demonstrate their effectiveness for related tasks. Specifically, we propose a light-weight test-time optimization in which the closest train poses are encoded and used to refine camera position estimation. This procedure achieves a new state-of-the-art position accuracy for APRs, on both the CambridgeLandmarks and 7Scenes benchmarks. We also show that train images can be reconstructed from the learned pose encoding, paving the way for integrating visual information from the train set at a low memory cost. Our code and pre-trained models are available at https://github.com/yolish/camera-pose-auto-encoders.
Show and Write: Entity-aware News Generation with Image Information
Dec 11, 2021
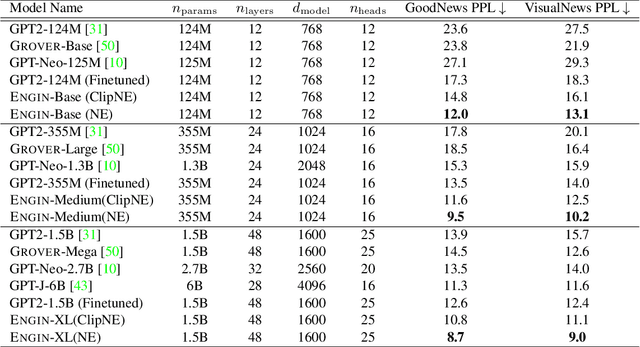
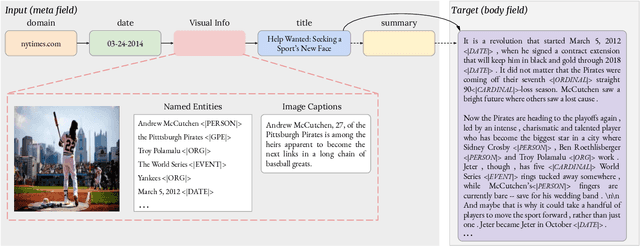

Automatically writing long articles is a complex and challenging language generation task. Prior work has primarily focused on generating these articles using human-written prompt to provide some topical context and some metadata about the article. That said, for many applications, such as generating news stories, these articles are often paired with images and their captions or alt-text, which in turn are based on real-world events and may reference many different named entities that are difficult to be correctly recognized and predicted by language models. To address these two problems, this paper introduces an Entity-aware News Generation method with Image iNformation, Engin, to incorporate news image information into language models. Engin produces news articles conditioned on both metadata and information such as captions and named entities extracted from images. We also propose an Entity-aware mechanism to help our model better recognize and predict the entity names in news. We perform experiments on two public large-scale news datasets, GoodNews and VisualNews. Quantitative results show that our approach improves article perplexity by 4-5 points over the base models. Qualitative results demonstrate the text generated by Engin is more consistent with news images. We also perform article quality annotation experiment on the generated articles to validate that our model produces higher-quality articles. Finally, we investigate the effect Engin has on methods that automatically detect machine-generated articles.
An Image Patch is a Wave: Phase-Aware Vision MLP
Nov 24, 2021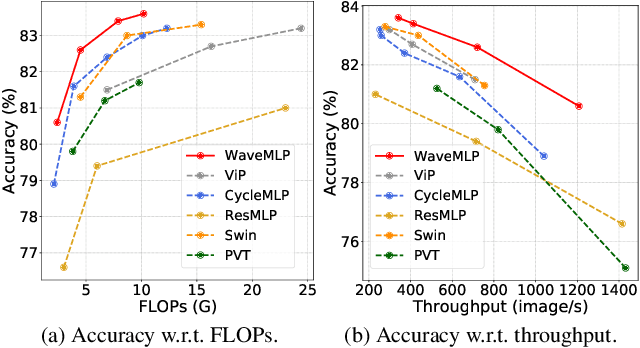
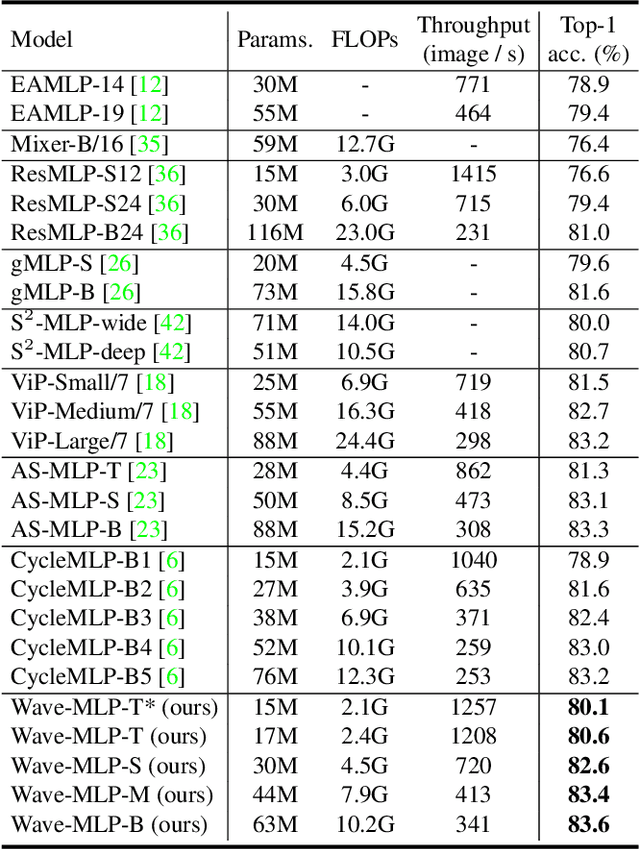
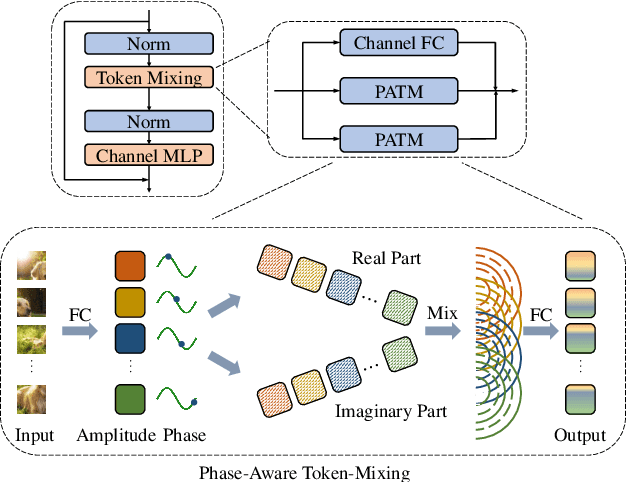
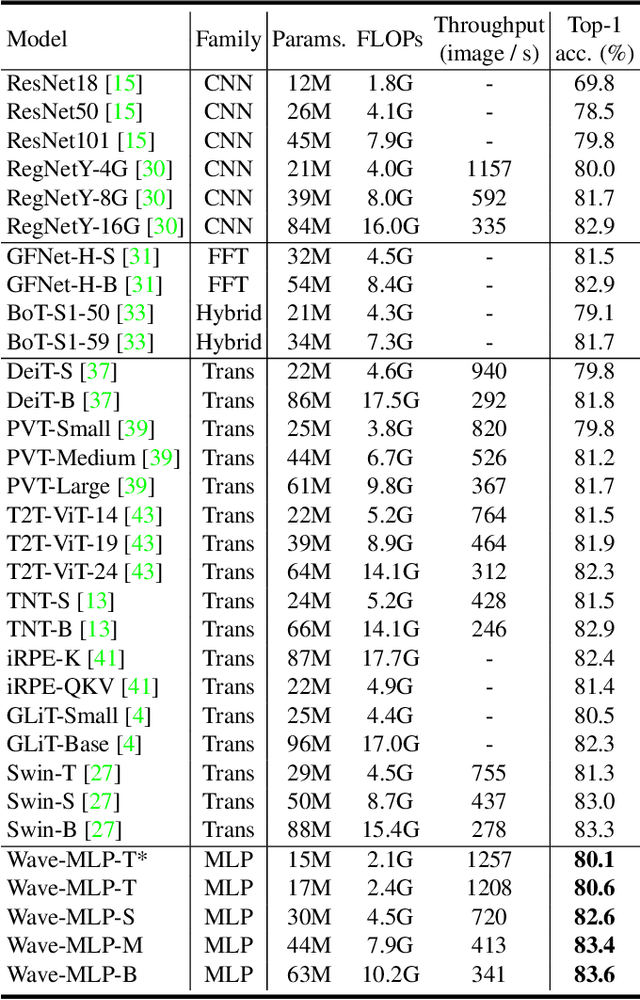
Different from traditional convolutional neural network (CNN) and vision transformer, the multilayer perceptron (MLP) is a new kind of vision model with extremely simple architecture that only stacked by fully-connected layers. An input image of vision MLP is usually split into multiple tokens (patches), while the existing MLP models directly aggregate them with fixed weights, neglecting the varying semantic information of tokens from different images. To dynamically aggregate tokens, we propose to represent each token as a wave function with two parts, amplitude and phase. Amplitude is the original feature and the phase term is a complex value changing according to the semantic contents of input images. Introducing the phase term can dynamically modulate the relationship between tokens and fixed weights in MLP. Based on the wave-like token representation, we establish a novel Wave-MLP architecture for vision tasks. Extensive experiments demonstrate that the proposed Wave-MLP is superior to the state-of-the-art MLP architectures on various vision tasks such as image classification, object detection and semantic segmentation.
Neural Novel Actor: Learning a Generalized Animatable Neural Representation for Human Actors
Aug 25, 2022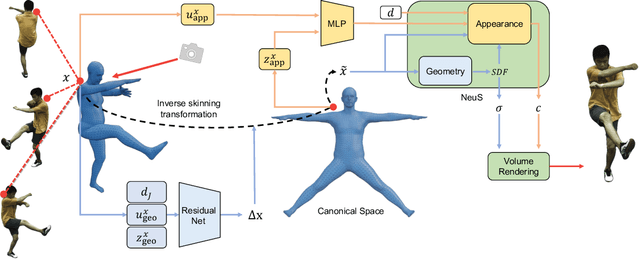

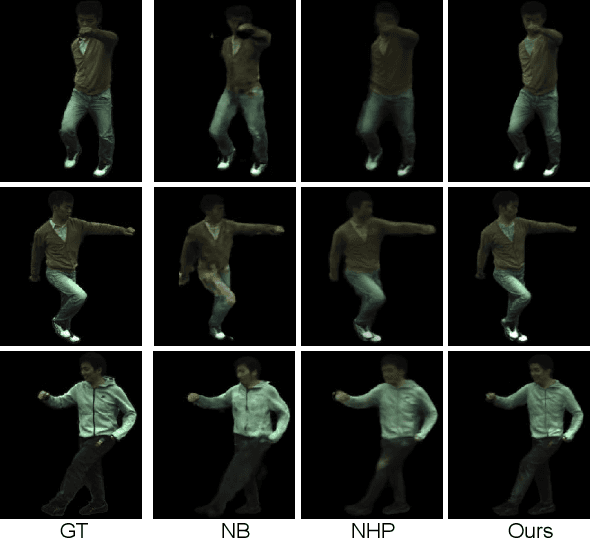

We propose a new method for learning a generalized animatable neural human representation from a sparse set of multi-view imagery of multiple persons. The learned representation can be used to synthesize novel view images of an arbitrary person from a sparse set of cameras, and further animate them with the user's pose control. While existing methods can either generalize to new persons or synthesize animations with user control, none of them can achieve both at the same time. We attribute this accomplishment to the employment of a 3D proxy for a shared multi-person human model, and further the warping of the spaces of different poses to a shared canonical pose space, in which we learn a neural field and predict the person- and pose-dependent deformations, as well as appearance with the features extracted from input images. To cope with the complexity of the large variations in body shapes, poses, and clothing deformations, we design our neural human model with disentangled geometry and appearance. Furthermore, we utilize the image features both at the spatial point and on the surface points of the 3D proxy for predicting person- and pose-dependent properties. Experiments show that our method significantly outperforms the state-of-the-arts on both tasks. The video and code are available at https://talegqz.github.io/neural_novel_actor.
Asian Giant Hornet Control based on Image Processing and Biological Dispersal
Nov 26, 2021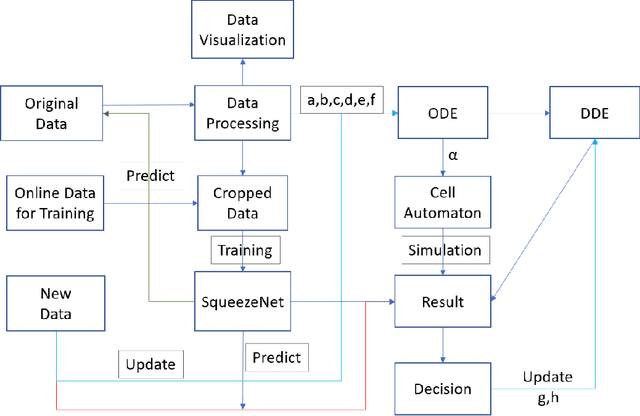


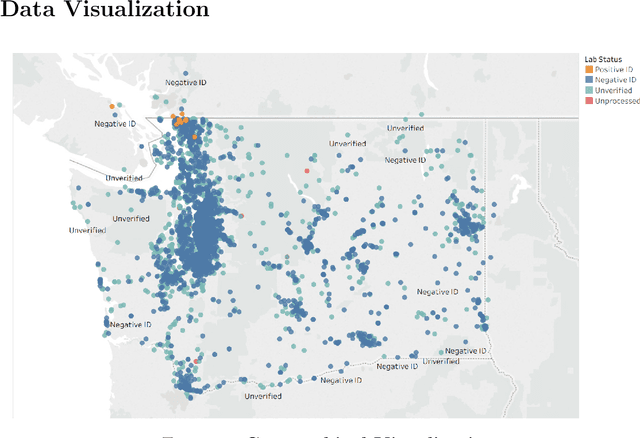
The Asian giant hornet (AGH) appeared in Washington State appears to have a potential danger of bioinvasion. Washington State has collected public photos and videos of detected insects for verification and further investigation. In this paper, we analyze AGH using data analysis,statistics, discrete mathematics, and deep learning techniques to process the data to controlAGH spreading.First, we visualize the geographical distribution of insects in Washington State. Then we investigate insect populations to varying months of the year and different days of a month.Third, we employ wavelet analysis to examine the periodic spread of AGH. Fourth, we apply ordinary differential equations to examine AGH numbers at the different natural growthrate and reaction speed and output the potential propagation coefficient. Next, we leverage cellular automaton combined with the potential propagation coefficient to simulate the geographical spread under changing potential propagation. To update the model, we use delayed differential equations to simulate human intervention. We use the time difference between detection time and submission time to determine the unit of time to delay time. After that, we construct a lightweight CNN called SqueezeNet and assess its classification performance. We then relate several non-reference image quality metrics, including NIQE, image gradient, entropy, contrast, and TOPSIS to judge the cause of misclassification. Furthermore, we build a Random Forest classifier to identify positive and negative samples based on image qualities only. We also display the feature importance and conduct an error analysis. Besides, we present sensitivity analysis to verify the robustness of our models. Finally, we show the strengths and weaknesses of our model and derives the conclusions.