 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Uncertainty-Guided Mutual Consistency Learning for Semi-Supervised Medical Image Segmentation
Dec 05, 2021
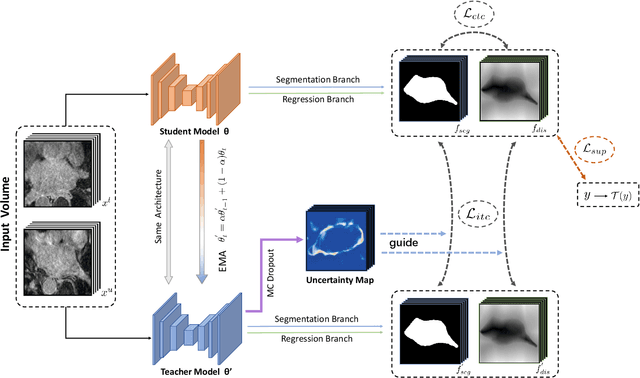
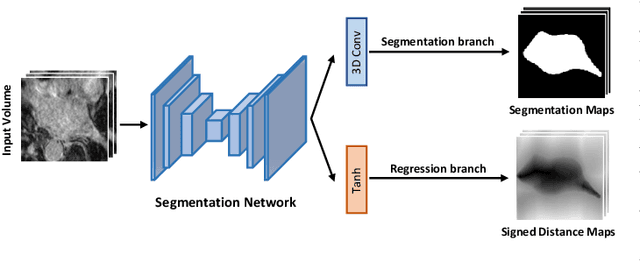
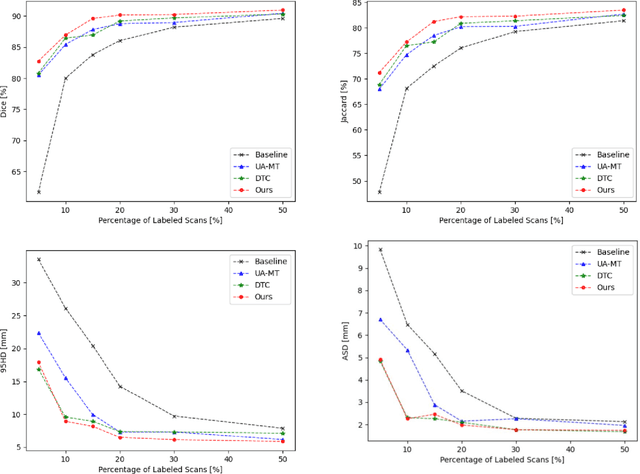
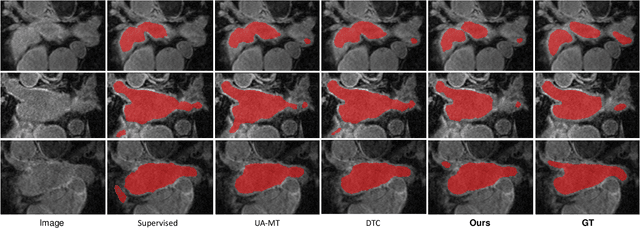
Medical image segmentation is a fundamental and critical step in many clinical approaches. Semi-supervised learning has been widely applied to medical image segmentation tasks since it alleviates the heavy burden of acquiring expert-examined annotations and takes the advantage of unlabeled data which is much easier to acquire. Although consistency learning has been proven to be an effective approach by enforcing an invariance of predictions under different distributions, existing approaches cannot make full use of region-level shape constraint and boundary-level distance information from unlabeled data. In this paper, we propose a novel uncertainty-guided mutual consistency learning framework to effectively exploit unlabeled data by integrating intra-task consistency learning from up-to-date predictions for self-ensembling and cross-task consistency learning from task-level regularization to exploit geometric shape information. The framework is guided by the estimated segmentation uncertainty of models to select out relatively certain predictions for consistency learning, so as to effectively exploit more reliable information from unlabeled data. We extensively validate our proposed method on two publicly available benchmark datasets: Left Atrium Segmentation (LA) dataset and Brain Tumor Segmentation (BraTS) dataset. Experimental results demonstrate that our method achieves performance gains by leveraging unlabeled data and outperforms existing semi-supervised segmentation methods.
ROSE: A RObust and SEcure DNN Watermarking
Jun 22, 2022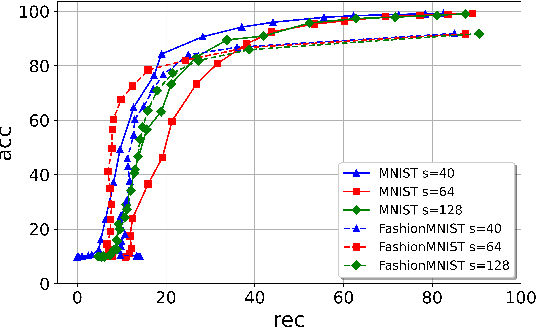
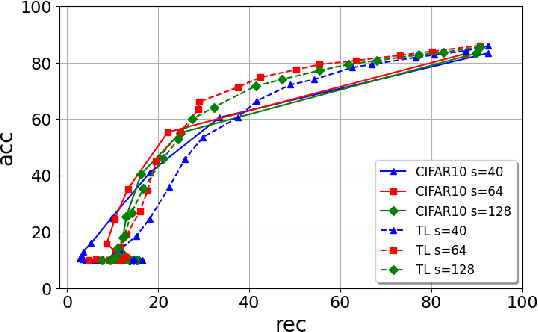
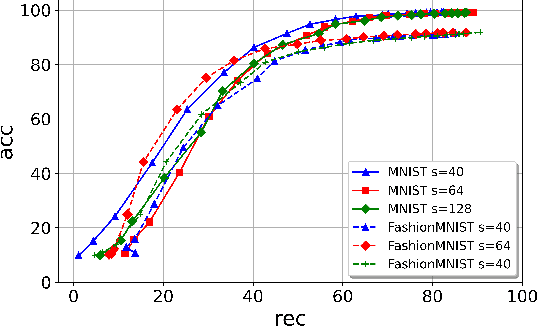
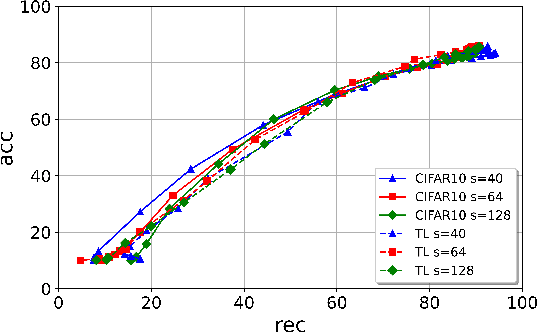
Protecting the Intellectual Property rights of DNN models is of primary importance prior to their deployment. So far, the proposed methods either necessitate changes to internal model parameters or the machine learning pipeline, or they fail to meet both the security and robustness requirements. This paper proposes a lightweight, robust, and secure black-box DNN watermarking protocol that takes advantage of cryptographic one-way functions as well as the injection of in-task key image-label pairs during the training process. These pairs are later used to prove DNN model ownership during testing. The main feature is that the value of the proof and its security are measurable. The extensive experiments watermarking image classification models for various datasets as well as exposing them to a variety of attacks, show that it provides protection while maintaining an adequate level of security and robustness.
Vehicle Trajectory Prediction on Highways Using Bird Eye View Representations and Deep Learning
Jul 04, 2022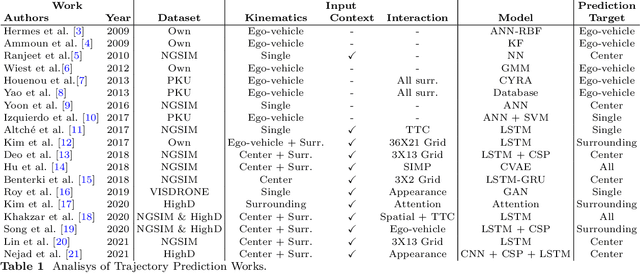


This work presents a novel method for predicting vehicle trajectories in highway scenarios using efficient bird's eye view representations and convolutional neural networks. Vehicle positions, motion histories, road configuration, and vehicle interactions are easily included in the prediction model using basic visual representations. The U-net model has been selected as the prediction kernel to generate future visual representations of the scene using an image-to-image regression approach. A method has been implemented to extract vehicle positions from the generated graphical representations to achieve subpixel resolution. The method has been trained and evaluated using the PREVENTION dataset, an on-board sensor dataset. Different network configurations and scene representations have been evaluated. This study found that U-net with 6 depth levels using a linear terminal layer and a Gaussian representation of the vehicles is the best performing configuration. The use of lane markings was found to produce no improvement in prediction performance. The average prediction error is 0.47 and 0.38 meters and the final prediction error is 0.76 and 0.53 meters for longitudinal and lateral coordinates, respectively, for a predicted trajectory length of 2.0 seconds. The prediction error is up to 50% lower compared to the baseline method.
Multi-scale alignment and Spatial ROI Module for COVID-19 Diagnosis
Jul 04, 2022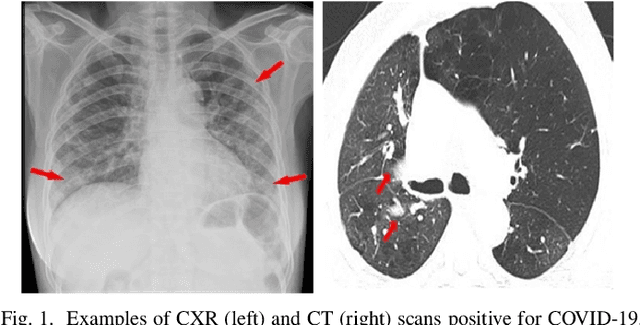
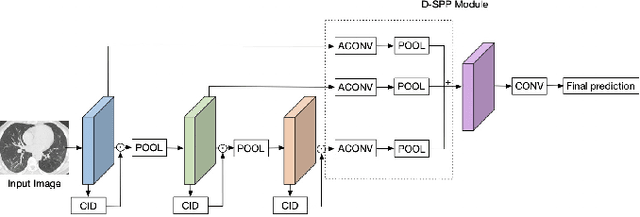
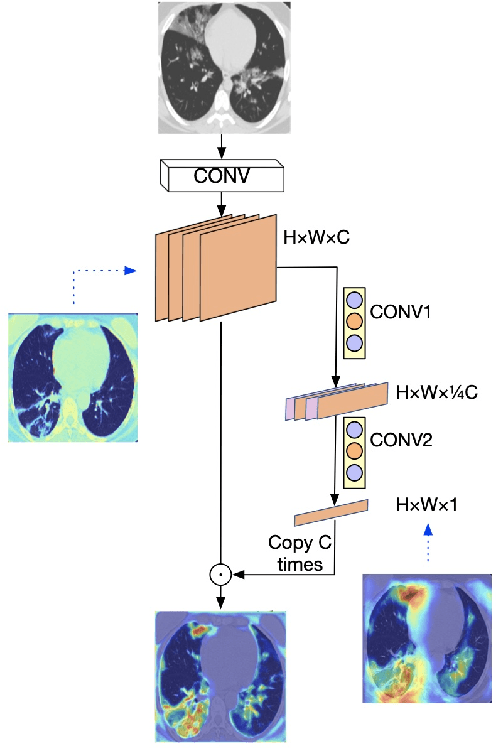
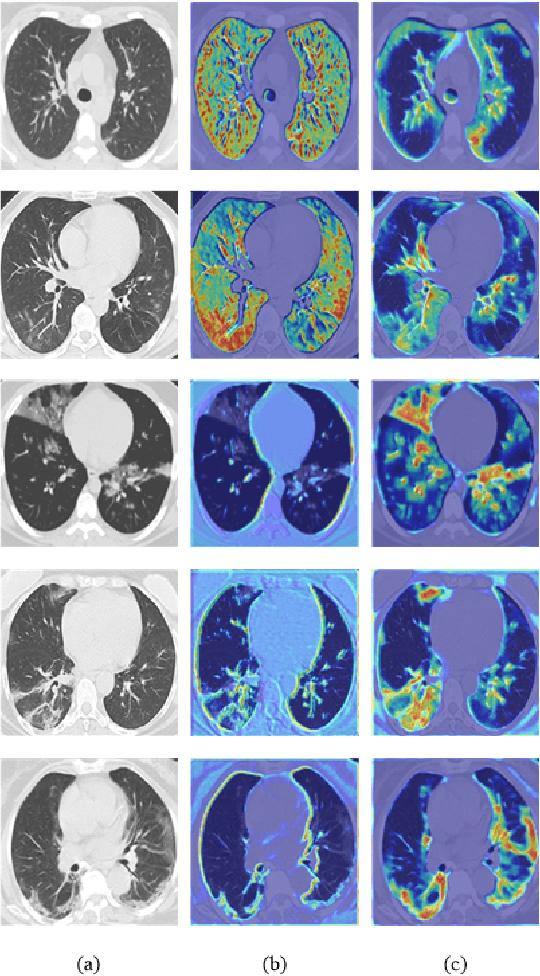
Coronavirus Disease 2019 (COVID-19) has spread globally and become a health crisis faced by humanity since first reported. Radiology imaging technologies such as computer tomography (CT) and chest X-ray imaging (CXR) are effective tools for diagnosing COVID-19. However, in CT and CXR images, the infected area occupies only a small part of the image. Some common deep learning methods that integrate large-scale receptive fields may cause the loss of image detail, resulting in the omission of the region of interest (ROI) in COVID-19 images and are therefore not suitable for further processing. To this end, we propose a deep spatial pyramid pooling (D-SPP) module to integrate contextual information over different resolutions, aiming to extract information under different scales of COVID-19 images effectively. Besides, we propose a COVID-19 infection detection (CID) module to draw attention to the lesion area and remove interference from irrelevant information. Extensive experiments on four CT and CXR datasets have shown that our method produces higher accuracy of detecting COVID-19 lesions in CT and CXR images. It can be used as a computer-aided diagnosis tool to help doctors effectively diagnose and screen for COVID-19.
Centre Symmetric Quadruple Pattern: A Novel Descriptor for Facial Image Recognition and Retrieval
Jan 03, 2022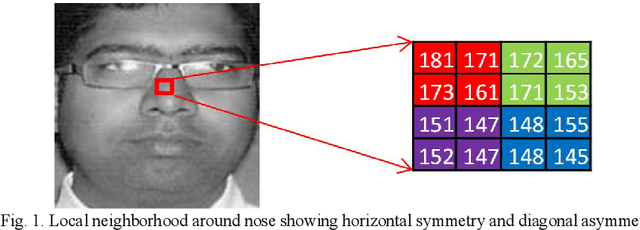
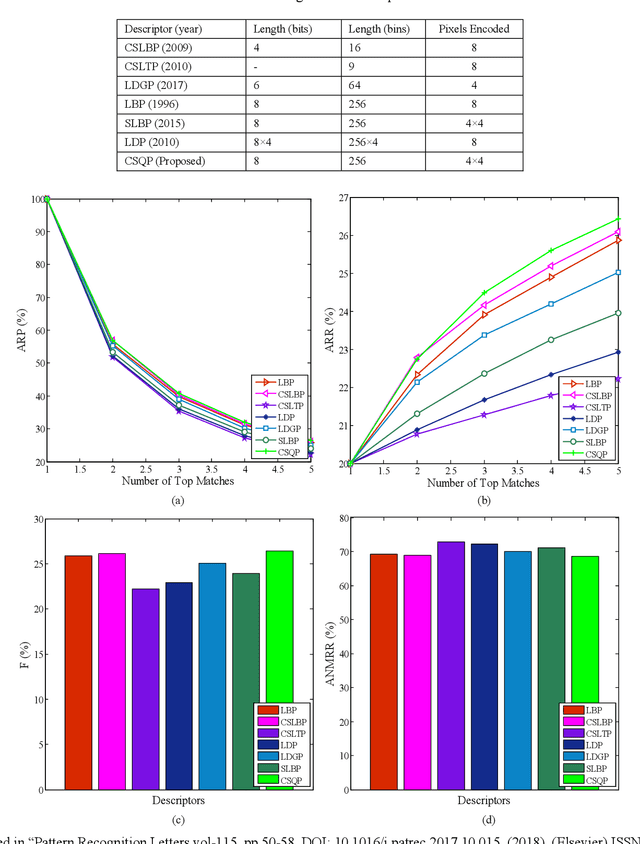

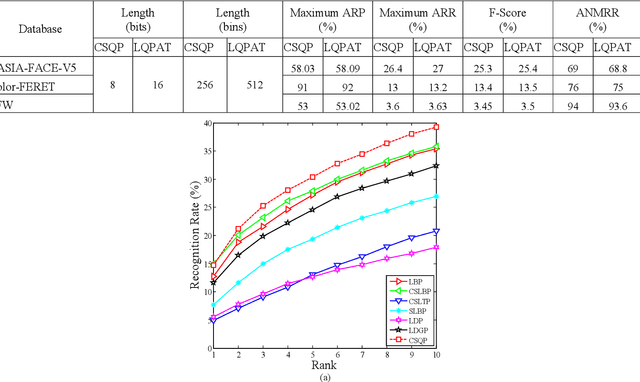
Facial features are defined as the local relationships that exist amongst the pixels of a facial image. Hand-crafted descriptors identify the relationships of the pixels in the local neighbourhood defined by the kernel. Kernel is a two dimensional matrix which is moved across the facial image. Distinctive information captured by the kernel with limited number of pixel achieves satisfactory recognition and retrieval accuracies on facial images taken under constrained environment (controlled variations in light, pose, expressions, and background). To achieve similar accuracies under unconstrained environment local neighbourhood has to be increased, in order to encode more pixels. Increasing local neighbourhood also increases the feature length of the descriptor. In this paper we propose a hand-crafted descriptor namely Centre Symmetric Quadruple Pattern (CSQP), which is structurally symmetric and encodes the facial asymmetry in quadruple space. The proposed descriptor efficiently encodes larger neighbourhood with optimal number of binary bits. It has been shown using average entropy, computed over feature images encoded with the proposed descriptor, that the CSQP captures more meaningful information as compared to state of the art descriptors. The retrieval and recognition accuracies of the proposed descriptor has been compared with state of the art hand-crafted descriptors (CSLBP, CSLTP, LDP, LBP, SLBP and LDGP) on bench mark databases namely; LFW, Colour-FERET, and CASIA-face-v5. Result analysis shows that the proposed descriptor performs well under controlled as well as uncontrolled variations in pose, illumination, background and expressions.
Speech Enhancement and Dereverberation with Diffusion-based Generative Models
Aug 11, 2022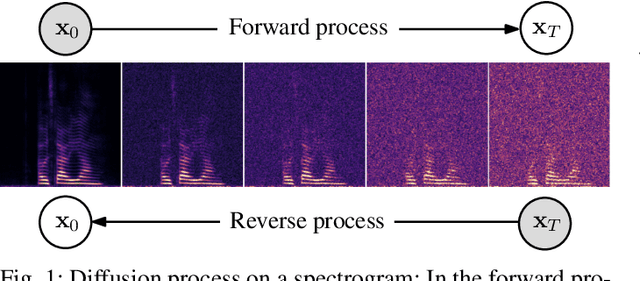
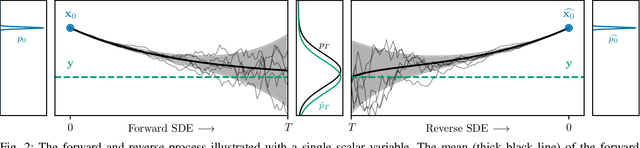
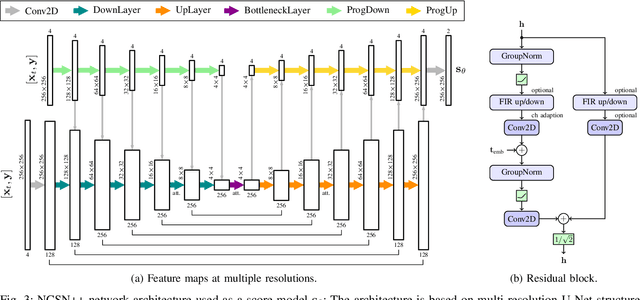
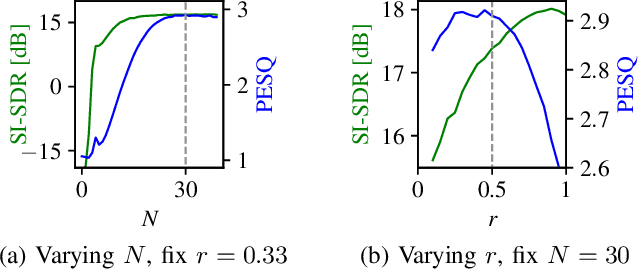
Recently, diffusion-based generative models have been introduced to the task of speech enhancement. The corruption of clean speech is modeled as a fixed forward process in which increasing amounts of noise are gradually added. By learning to reverse this process in an iterative fashion conditioned on the noisy input, clean speech is generated. We build upon our previous work and derive the training task within the formalism of stochastic differential equations. We present a detailed theoretical review of the underlying score matching objective and explore different sampler configurations for solving the reverse process at test time. By using a sophisticated network architecture from natural image generation literature, we significantly improve performance compared to our previous publication. We also show that we can compete with recent discriminative models and achieve better generalization when evaluating on a different corpus than used for training. We complement the evaluation results with a subjective listening test, in which our proposed method is rated best. Furthermore, we show that the proposed method achieves remarkable state-of-the-art performance in single-channel speech dereverberation. Our code and audio examples are available online, see https://uhh.de/inf-sp-sgmse
Learning Object Placement via Dual-path Graph Completion
Jul 23, 2022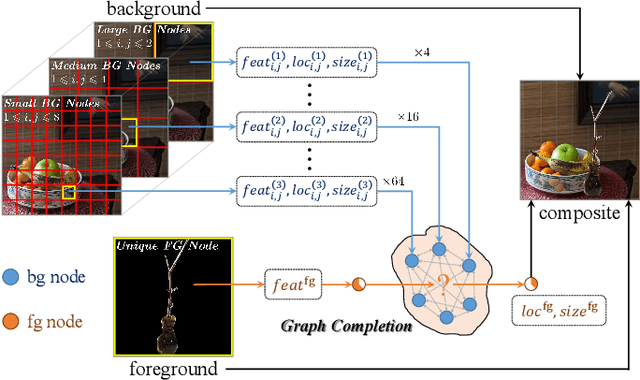
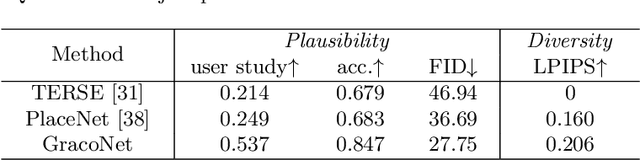
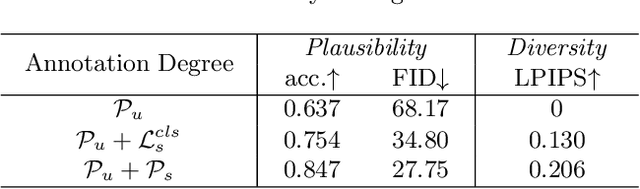

Object placement aims to place a foreground object over a background image with a suitable location and size. In this work, we treat object placement as a graph completion problem and propose a novel graph completion module (GCM). The background scene is represented by a graph with multiple nodes at different spatial locations with various receptive fields. The foreground object is encoded as a special node that should be inserted at a reasonable place in this graph. We also design a dual-path framework upon the structure of GCM to fully exploit annotated composite images. With extensive experiments on OPA dataset, our method proves to significantly outperform existing methods in generating plausible object placement without loss of diversity.
FlowNAS: Neural Architecture Search for Optical Flow Estimation
Jul 04, 2022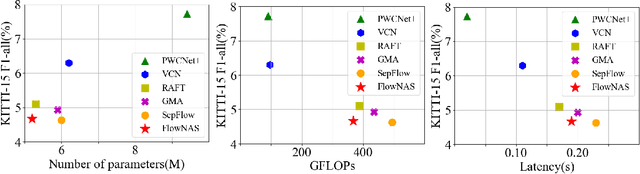
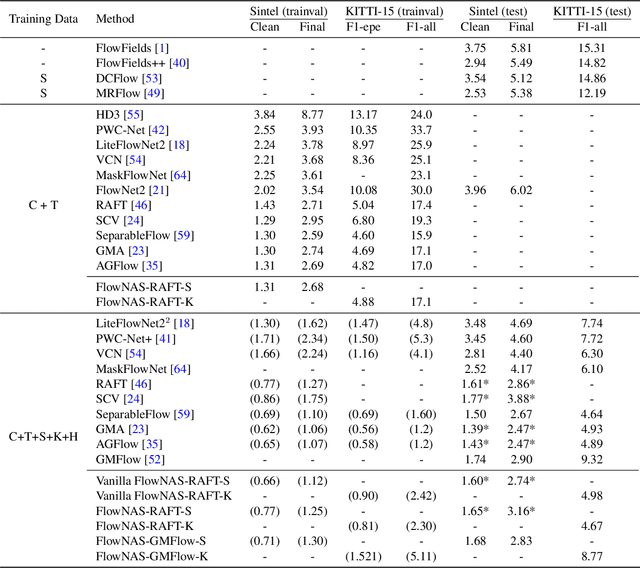
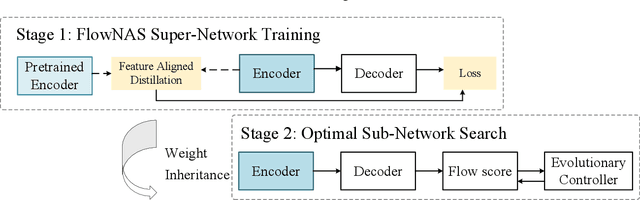
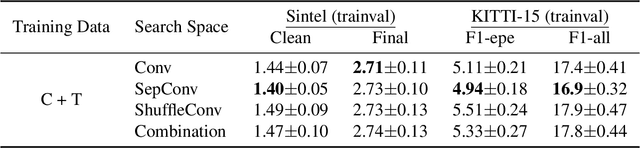
Existing optical flow estimators usually employ the network architectures typically designed for image classification as the encoder to extract per-pixel features. However, due to the natural difference between the tasks, the architectures designed for image classification may be sub-optimal for flow estimation. To address this issue, we propose a neural architecture search method named FlowNAS to automatically find the better encoder architecture for flow estimation task. We first design a suitable search space including various convolutional operators and construct a weight-sharing super-network for efficiently evaluating the candidate architectures. Then, for better training the super-network, we propose Feature Alignment Distillation, which utilizes a well-trained flow estimator to guide the training of super-network. Finally, a resource-constrained evolutionary algorithm is exploited to find an optimal architecture (i.e., sub-network). Experimental results show that the discovered architecture with the weights inherited from the super-network achieves 4.67\% F1-all error on KITTI, an 8.4\% reduction of RAFT baseline, surpassing state-of-the-art handcrafted models GMA and AGFlow, while reducing the model complexity and latency. The source code and trained models will be released in https://github.com/VDIGPKU/FlowNAS.
Learning Primitive-aware Discriminative Representations for FSL
Aug 20, 2022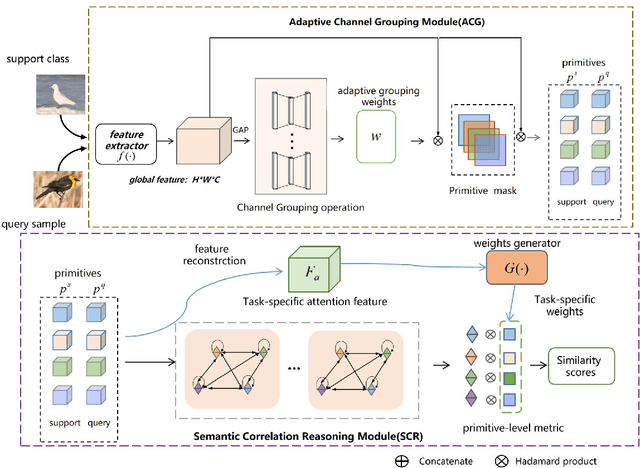
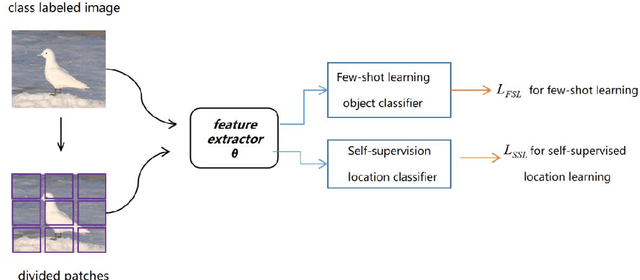
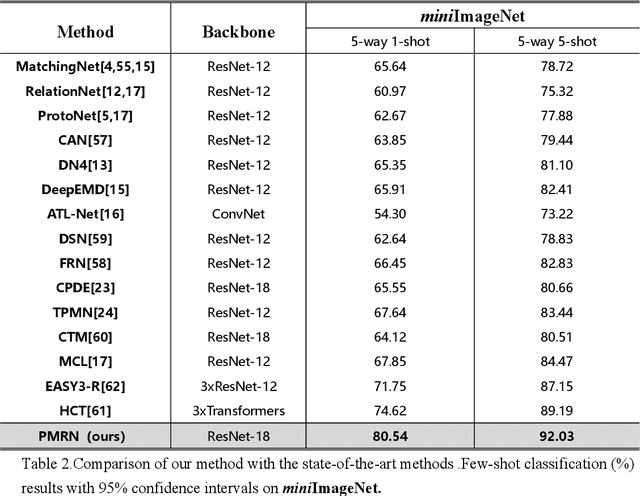
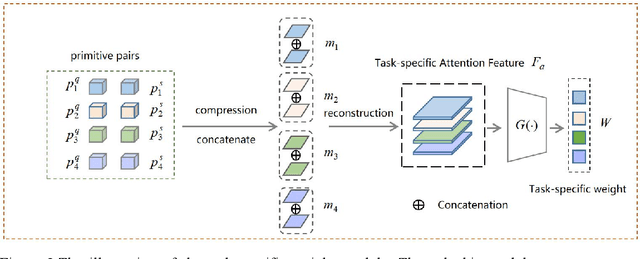
Few-shot learning (FSL) aims to learn a classifier that can be easily adapted to recognize novel classes,given only a few labeled examples per class.Limited data keep this task challenging for deep learning.Recent metric-based methods has achieved promising performance based on image-level features.However,these global features ignore abundant local and structural information that is transferable and consistent between seen and unseen classes.Some study in cognitive science argue that humans can recognize novel classes with the learned primitives.We expect to mine both transferable and discriminative representation from base classes and adopt them to recognize novel classes.Building on the episodic training mechanism,We propose a Primitive Mining and Reasoning Network(PMRN) to learn primitive-aware representation in an end-to-end manner for metric-based FSL model.We first add self-supervision auxiliary task,forcing feature extractor to learn tvisual pattern corresponding to primitives.To further mine and produce transferable primitive-aware representations,we design an Adaptive Channel Grouping(ACG)module to synthesize a set of visual primitives from object embedding by enhancing informative channel maps while suppressing useless ones. Based on the learned primitive feature,a Semantic Correlation Reasoning (SCR) module is proposed to capture internal relations among them.Finally,we learn the task-specific importance of primitives and conduct primitive-level metric based on the task-specific attention feature.Extensive experiments show that our method achieves state-of-the-art results on six standard benchmarks.
Conditional Vector Graphics Generation for Music Cover Images
May 15, 2022
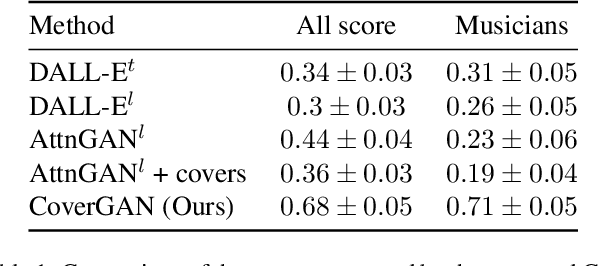

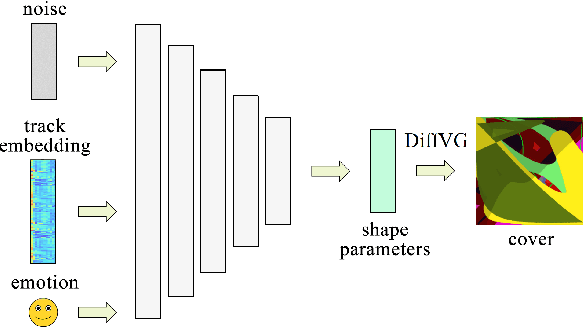
Generative Adversarial Networks (GAN) have motivated a rapid growth of the domain of computer image synthesis. As almost all the existing image synthesis algorithms consider an image as a pixel matrix, the high-resolution image synthesis is complicated.A good alternative can be vector images. However, they belong to the highly sophisticated parametric space, which is a restriction for solving the task of synthesizing vector graphics by GANs. In this paper, we consider a specific application domain that softens this restriction dramatically allowing the usage of vector image synthesis. Music cover images should meet the requirements of Internet streaming services and printing standards, which imply high resolution of graphic materials without any additional requirements on the content of such images. Existing music cover image generation services do not analyze tracks themselves; however, some services mostly consider only genre tags. To generate music covers as vector images that reflect the music and consist of simple geometric objects, we suggest a GAN-based algorithm called CoverGAN. The assessment of resulting images is based on their correspondence to the music compared with AttnGAN and DALL-E text-to-image generation according to title or lyrics. Moreover, the significance of the patterns found by CoverGAN has been evaluated in terms of the correspondence of the generated cover images to the musical tracks. Listeners evaluate the music covers generated by the proposed algorithm as quite satisfactory and corresponding to the tracks. Music cover images generation code and demo are available at https://github.com/IzhanVarsky/CoverGAN.