 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LineCap: Line Charts for Data Visualization Captioning Models
Jul 15, 2022
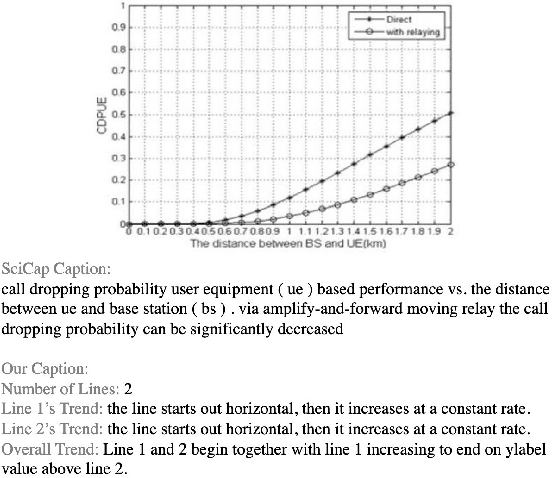
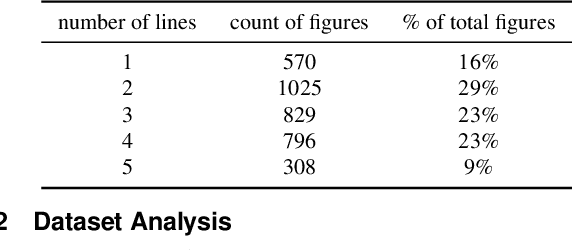
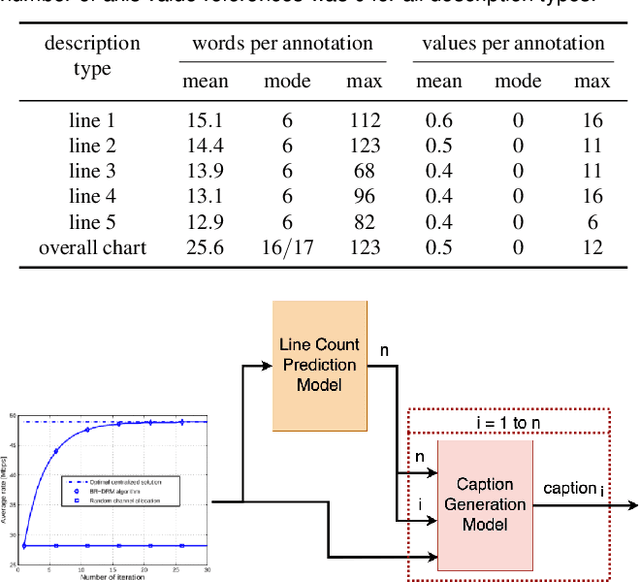
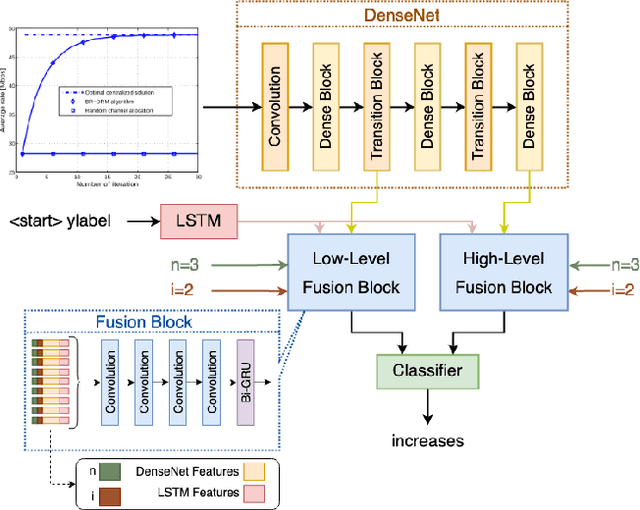
Data visualization captions help readers understand the purpose of a visualization and are crucial for individuals with visual impairments. The prevalence of poor figure captions and the successful application of deep learning approaches to image captioning motivate the use of similar techniques for automated figure captioning. However, research in this field has been stunted by the lack of suitable datasets. We introduce LineCap, a novel figure captioning dataset of 3,528 figures, and we provide insights from curating this dataset and using end-to-end deep learning models for automated figure captioning.
Learning Object Placement via Dual-path Graph Completion
Jul 23, 2022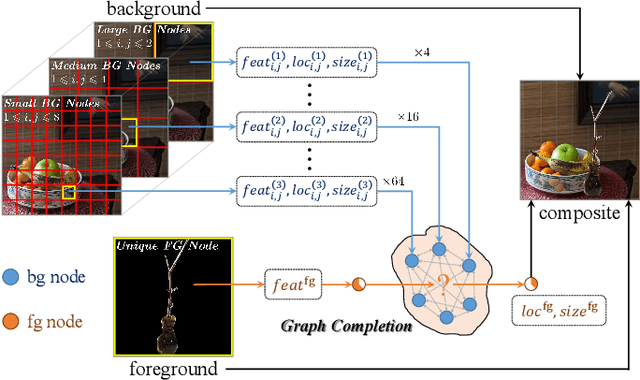
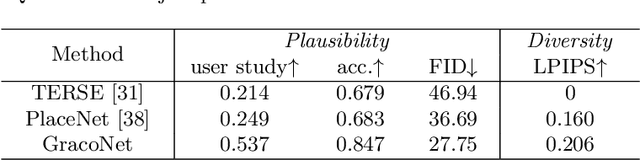
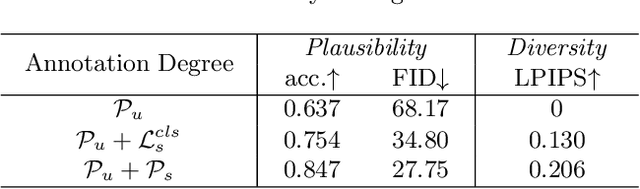

Object placement aims to place a foreground object over a background image with a suitable location and size. In this work, we treat object placement as a graph completion problem and propose a novel graph completion module (GCM). The background scene is represented by a graph with multiple nodes at different spatial locations with various receptive fields. The foreground object is encoded as a special node that should be inserted at a reasonable place in this graph. We also design a dual-path framework upon the structure of GCM to fully exploit annotated composite images. With extensive experiments on OPA dataset, our method proves to significantly outperform existing methods in generating plausible object placement without loss of diversity.
Self-Knowledge Distillation via Dropout
Aug 11, 2022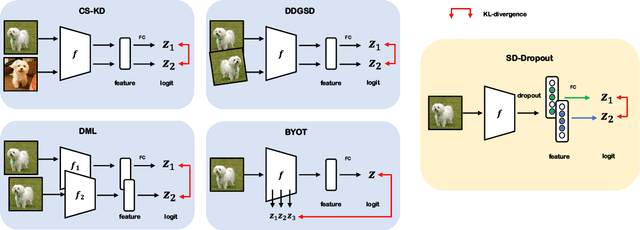
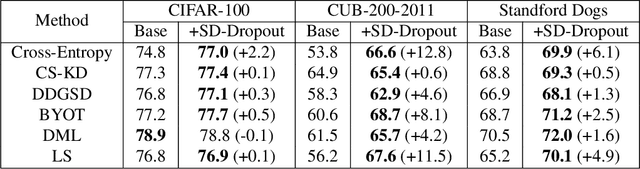
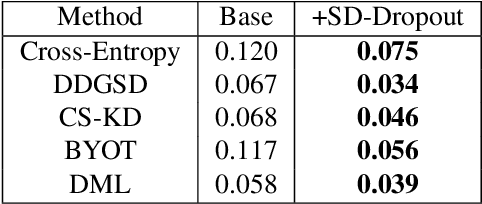

To boost the performance, deep neural networks require deeper or wider network structures that involve massive computational and memory costs. To alleviate this issue, the self-knowledge distillation method regularizes the model by distilling the internal knowledge of the model itself. Conventional self-knowledge distillation methods require additional trainable parameters or are dependent on the data. In this paper, we propose a simple and effective self-knowledge distillation method using a dropout (SD-Dropout). SD-Dropout distills the posterior distributions of multiple models through a dropout sampling. Our method does not require any additional trainable modules, does not rely on data, and requires only simple operations. Furthermore, this simple method can be easily combined with various self-knowledge distillation approaches. We provide a theoretical and experimental analysis of the effect of forward and reverse KL-divergences in our work. Extensive experiments on various vision tasks, i.e., image classification, object detection, and distribution shift, demonstrate that the proposed method can effectively improve the generalization of a single network. Further experiments show that the proposed method also improves calibration performance, adversarial robustness, and out-of-distribution detection ability.
AdaCat: Adaptive Categorical Discretization for Autoregressive Models
Aug 03, 2022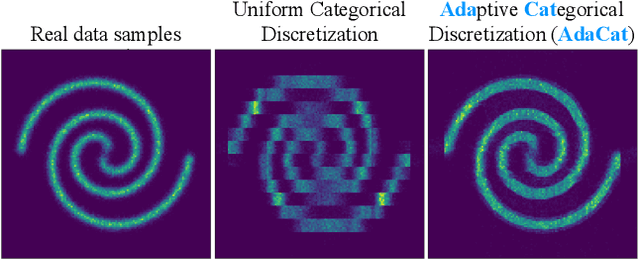
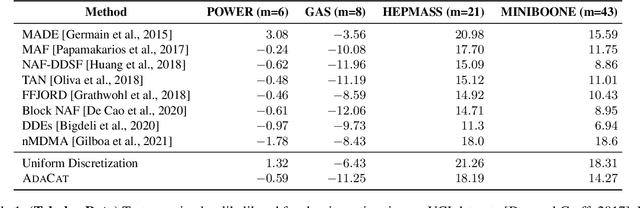
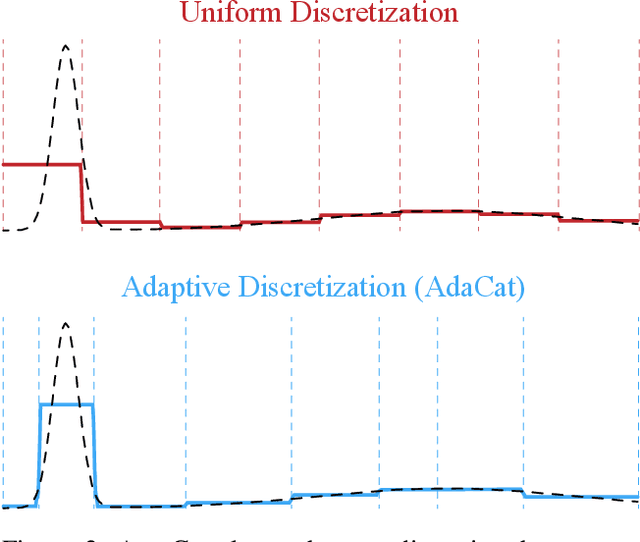
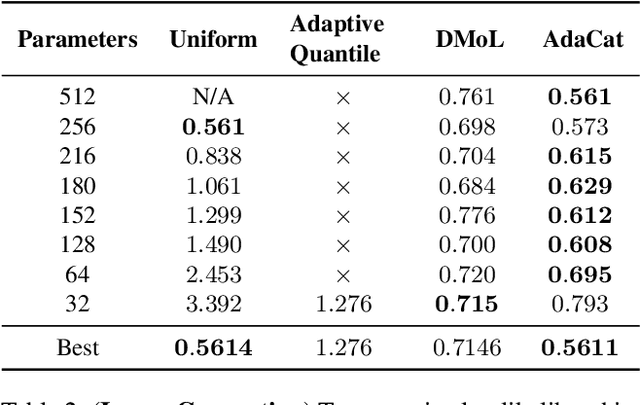
Autoregressive generative models can estimate complex continuous data distributions, like trajectory rollouts in an RL environment, image intensities, and audio. Most state-of-the-art models discretize continuous data into several bins and use categorical distributions over the bins to approximate the continuous data distribution. The advantage is that the categorical distribution can easily express multiple modes and are straightforward to optimize. However, such approximation cannot express sharp changes in density without using significantly more bins, making it parameter inefficient. We propose an efficient, expressive, multimodal parameterization called Adaptive Categorical Discretization (AdaCat). AdaCat discretizes each dimension of an autoregressive model adaptively, which allows the model to allocate density to fine intervals of interest, improving parameter efficiency. AdaCat generalizes both categoricals and quantile-based regression. AdaCat is a simple add-on to any discretization-based distribution estimator. In experiments, AdaCat improves density estimation for real-world tabular data, images, audio, and trajectories, and improves planning in model-based offline RL.
Detecting Outliers with Poisson Image Interpolation
Jul 06, 2021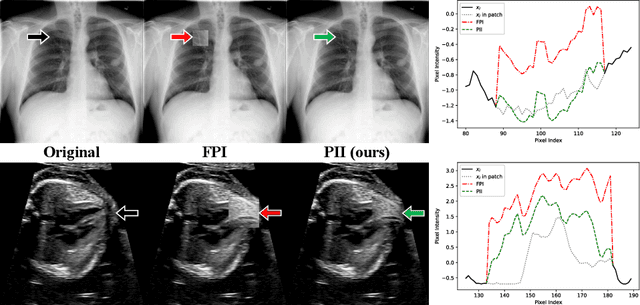
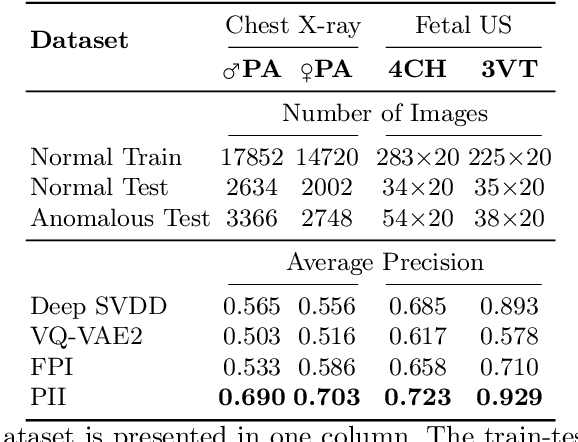
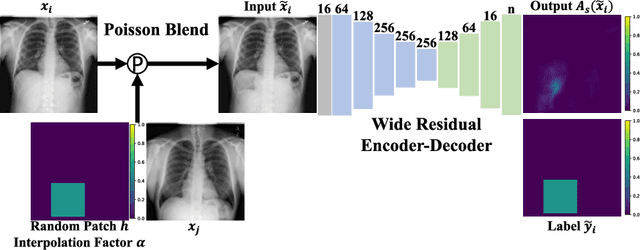
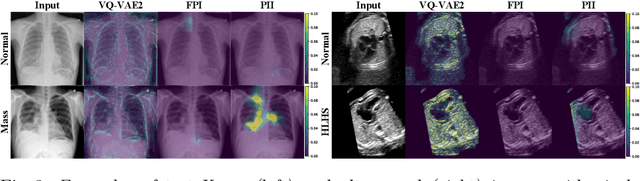
Supervised learning of every possible pathology is unrealistic for many primary care applications like health screening. Image anomaly detection methods that learn normal appearance from only healthy data have shown promising results recently. We propose an alternative to image reconstruction-based and image embedding-based methods and propose a new self-supervised method to tackle pathological anomaly detection. Our approach originates in the foreign patch interpolation (FPI) strategy that has shown superior performance on brain MRI and abdominal CT data. We propose to use a better patch interpolation strategy, Poisson image interpolation (PII), which makes our method suitable for applications in challenging data regimes. PII outperforms state-of-the-art methods by a good margin when tested on surrogate tasks like identifying common lung anomalies in chest X-rays or hypo-plastic left heart syndrome in prenatal, fetal cardiac ultrasound images. Code available at https://github.com/jemtan/PII.
DeepJSCC-Q: Constellation Constrained Deep Joint Source-Channel Coding
Jun 16, 2022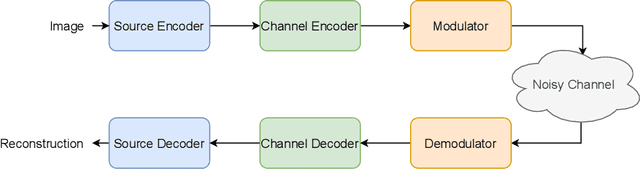
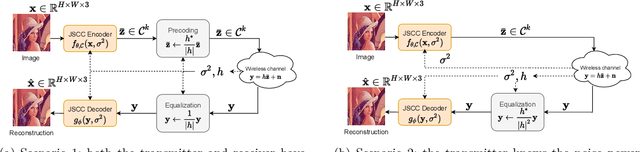
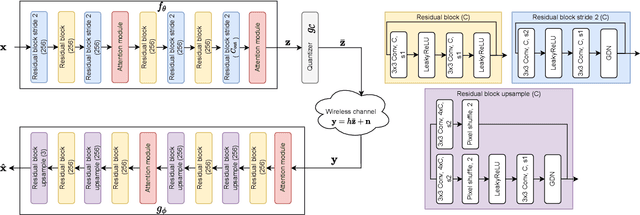
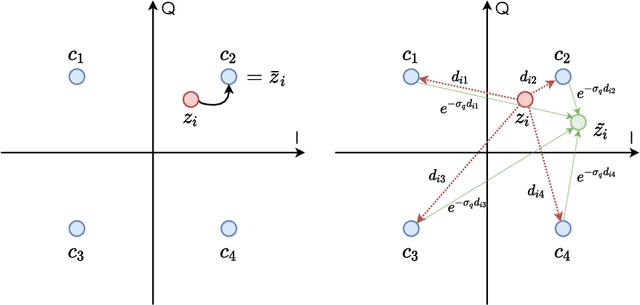
Recent works have shown that modern machine learning techniques can provide an alternative approach to the long-standing joint source-channel coding (JSCC) problem. Very promising initial results, superior to popular digital schemes that utilize separate source and channel codes, have been demonstrated for wireless image and video transmission using deep neural networks (DNNs). However, end-to-end training of such schemes requires a differentiable channel input representation; hence, prior works have assumed that any complex value can be transmitted over the channel. This can prevent the application of these codes in scenarios where the hardware or protocol can only admit certain sets of channel inputs, prescribed by a digital constellation. Herein, we propose DeepJSCC-Q, an end-to-end optimized JSCC solution for wireless image transmission using a finite channel input alphabet. We show that DeepJSCC-Q can achieve similar performance to prior works that allow any complex valued channel input, especially when high modulation orders are available, and that the performance asymptotically approaches that of unconstrained channel input as the modulation order increases. Importantly, DeepJSCC-Q preserves the graceful degradation of image quality in unpredictable channel conditions, a desirable property for deployment in mobile systems with rapidly changing channel conditions.
Single image deep defocus estimation and its applications
Jul 30, 2021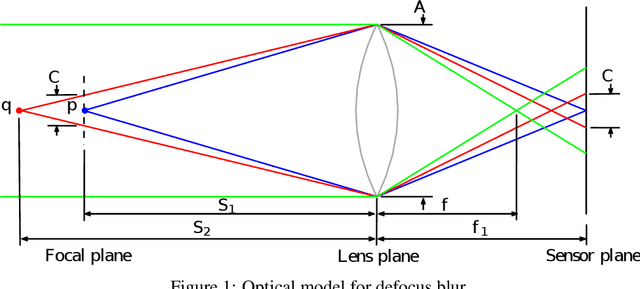


The depth information is useful in many image processing applications. However, since taking a picture is a process of projection of a 3D scene onto a 2D imaging sensor, the depth information is embedded in the image. Extracting the depth information from the image is a challenging task. A guiding principle is that the level of blurriness due to defocus is related to the distance between the object and the focal plane. Based on this principle and the widely used assumption that Gaussian blur is a good model for defocus blur, we formulate the problem of estimating the spatially varying defocus blurriness as a Gaussian blur classification problem. We solved the problem by training a deep neural network to classify image patches into one of the 20 levels of blurriness. We have created a dataset of more than 500000 image patches of size 32x32 which are used to train and test several well-known network models. We find that MobileNetV2 is suitable for this application due to its low memory requirement and high accuracy. The trained model is used to determine the patch blurriness which is then refined by applying an iterative weighted guided filter. The result is a defocus map that carries the information of the degree of blurriness for each pixel. We compare the proposed method with state-of-the-art techniques and we demonstrate its successful applications in adaptive image enhancement, defocus magnification, and multi-focus image fusion.
Surrogate-assisted Multi-objective Neural Architecture Search for Real-time Semantic Segmentation
Aug 14, 2022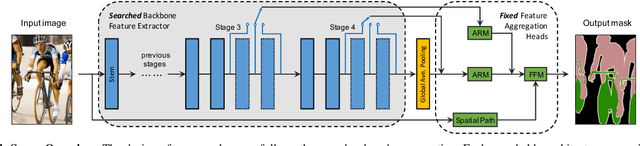
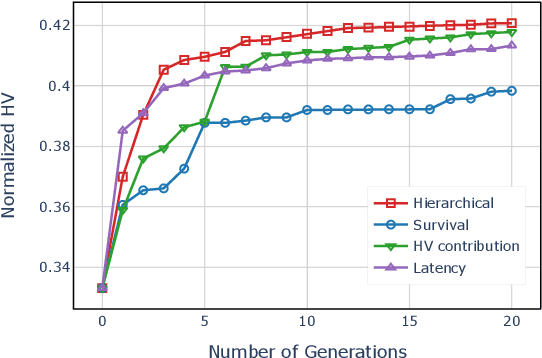
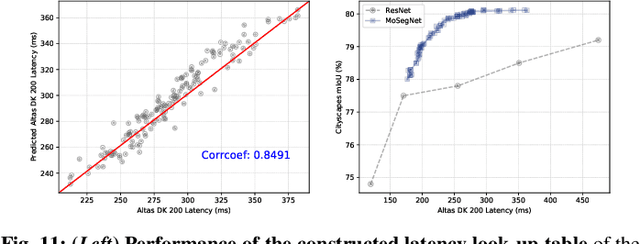
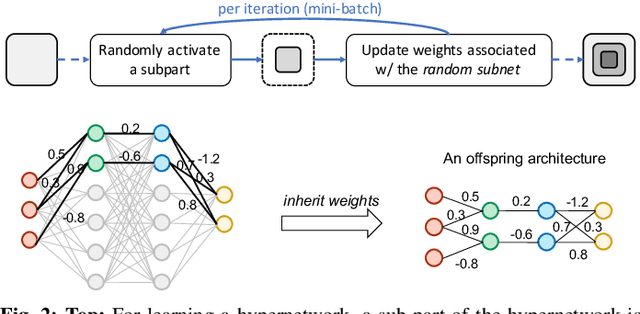
The architectural advancements in deep neural networks have led to remarkable leap-forwards across a broad array of computer vision tasks. Instead of relying on human expertise, neural architecture search (NAS) has emerged as a promising avenue toward automating the design of architectures. While recent achievements in image classification have suggested opportunities, the promises of NAS have yet to be thoroughly assessed on more challenging tasks of semantic segmentation. The main challenges of applying NAS to semantic segmentation arise from two aspects: (i) high-resolution images to be processed; (ii) additional requirement of real-time inference speed (i.e., real-time semantic segmentation) for applications such as autonomous driving. To meet such challenges, we propose a surrogate-assisted multi-objective method in this paper. Through a series of customized prediction models, our method effectively transforms the original NAS task into an ordinary multi-objective optimization problem. Followed by a hierarchical pre-screening criterion for in-fill selection, our method progressively achieves a set of efficient architectures trading-off between segmentation accuracy and inference speed. Empirical evaluations on three benchmark datasets together with an application using Huawei Atlas 200 DK suggest that our method can identify architectures significantly outperforming existing state-of-the-art architectures designed both manually by human experts and automatically by other NAS methods.
Vehicle Trajectory Prediction on Highways Using Bird Eye View Representations and Deep Learning
Jul 04, 2022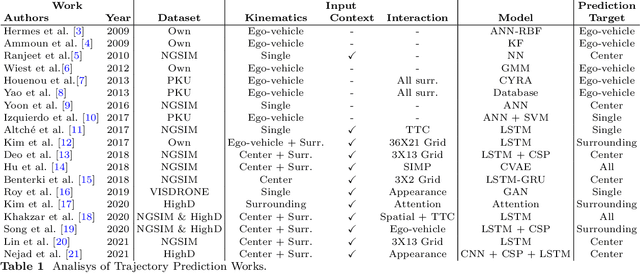
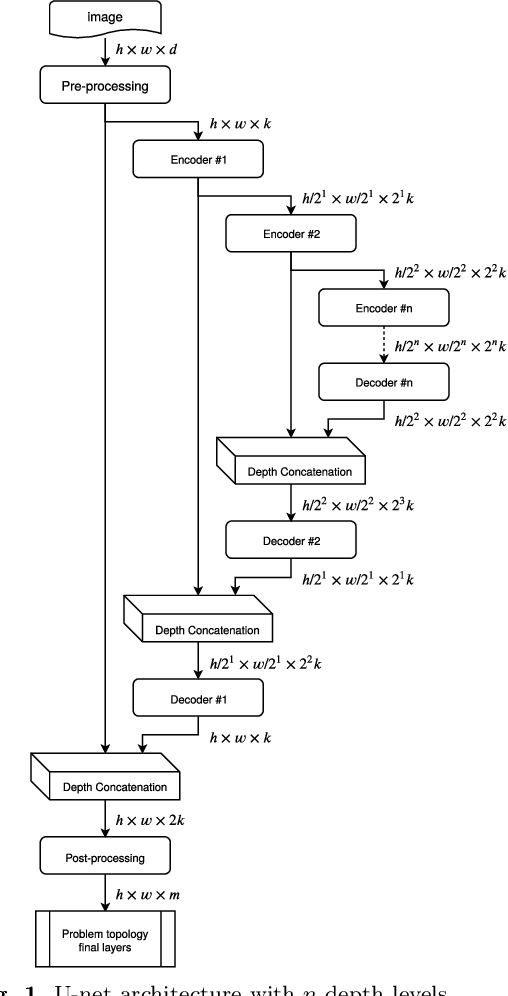


This work presents a novel method for predicting vehicle trajectories in highway scenarios using efficient bird's eye view representations and convolutional neural networks. Vehicle positions, motion histories, road configuration, and vehicle interactions are easily included in the prediction model using basic visual representations. The U-net model has been selected as the prediction kernel to generate future visual representations of the scene using an image-to-image regression approach. A method has been implemented to extract vehicle positions from the generated graphical representations to achieve subpixel resolution. The method has been trained and evaluated using the PREVENTION dataset, an on-board sensor dataset. Different network configurations and scene representations have been evaluated. This study found that U-net with 6 depth levels using a linear terminal layer and a Gaussian representation of the vehicles is the best performing configuration. The use of lane markings was found to produce no improvement in prediction performance. The average prediction error is 0.47 and 0.38 meters and the final prediction error is 0.76 and 0.53 meters for longitudinal and lateral coordinates, respectively, for a predicted trajectory length of 2.0 seconds. The prediction error is up to 50% lower compared to the baseline method.
Multi-scale alignment and Spatial ROI Module for COVID-19 Diagnosis
Jul 04, 2022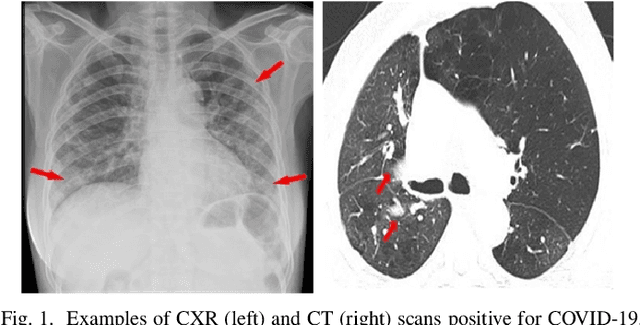
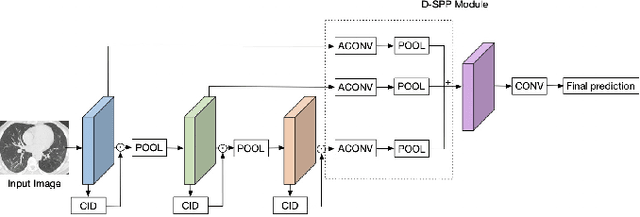
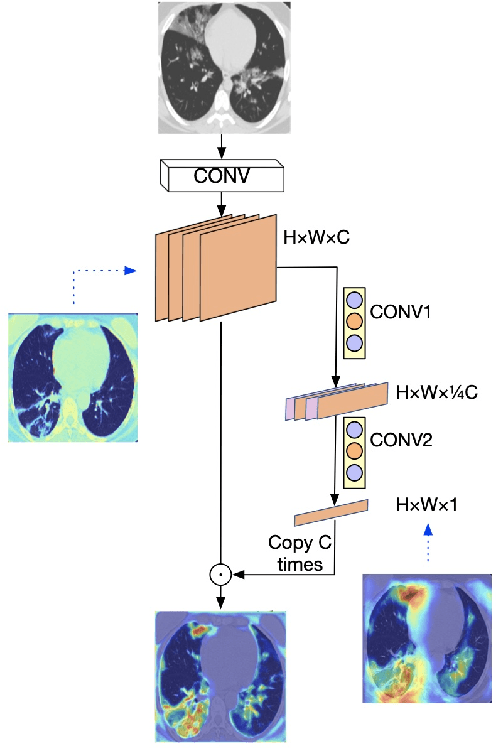
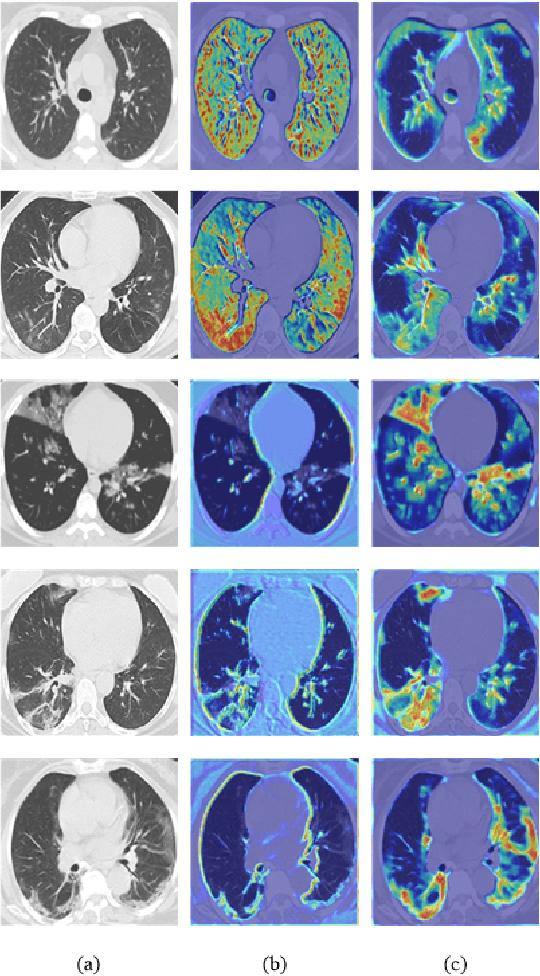
Coronavirus Disease 2019 (COVID-19) has spread globally and become a health crisis faced by humanity since first reported. Radiology imaging technologies such as computer tomography (CT) and chest X-ray imaging (CXR) are effective tools for diagnosing COVID-19. However, in CT and CXR images, the infected area occupies only a small part of the image. Some common deep learning methods that integrate large-scale receptive fields may cause the loss of image detail, resulting in the omission of the region of interest (ROI) in COVID-19 images and are therefore not suitable for further processing. To this end, we propose a deep spatial pyramid pooling (D-SPP) module to integrate contextual information over different resolutions, aiming to extract information under different scales of COVID-19 images effectively. Besides, we propose a COVID-19 infection detection (CID) module to draw attention to the lesion area and remove interference from irrelevant information. Extensive experiments on four CT and CXR datasets have shown that our method produces higher accuracy of detecting COVID-19 lesions in CT and CXR images. It can be used as a computer-aided diagnosis tool to help doctors effectively diagnose and screen for COVID-19.