 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Region-guided CycleGANs for Stain Transfer in Whole Slide Images
Aug 26, 2022
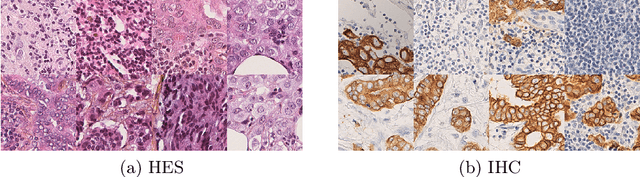
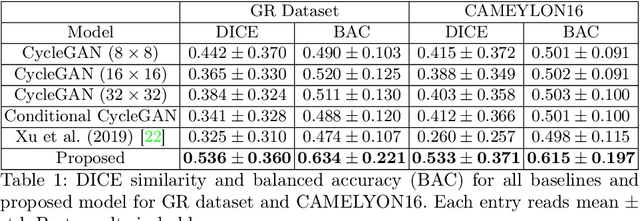
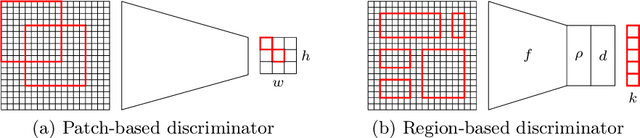
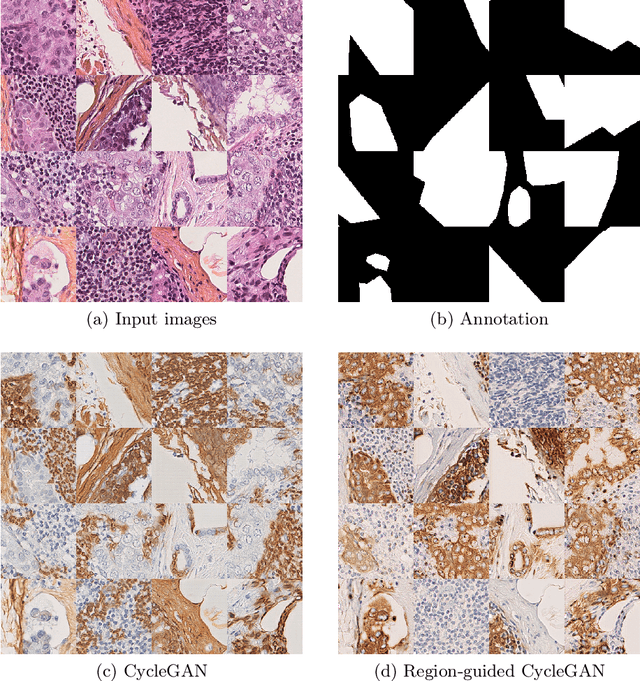
In whole slide imaging, commonly used staining techniques based on hematoxylin and eosin (H&E) and immunohistochemistry (IHC) stains accentuate different aspects of the tissue landscape. In the case of detecting metastases, IHC provides a distinct readout that is readily interpretable by pathologists. IHC, however, is a more expensive approach and not available at all medical centers. Virtually generating IHC images from H&E using deep neural networks thus becomes an attractive alternative. Deep generative models such as CycleGANs learn a semantically-consistent mapping between two image domains, while emulating the textural properties of each domain. They are therefore a suitable choice for stain transfer applications. However, they remain fully unsupervised, and possess no mechanism for enforcing biological consistency in stain transfer. In this paper, we propose an extension to CycleGANs in the form of a region of interest discriminator. This allows the CycleGAN to learn from unpaired datasets where, in addition, there is a partial annotation of objects for which one wishes to enforce consistency. We present a use case on whole slide images, where an IHC stain provides an experimentally generated signal for metastatic cells. We demonstrate the superiority of our approach over prior art in stain transfer on histopathology tiles over two datasets. Our code and model are available at https://github.com/jcboyd/miccai2022-roigan.
MISSFormer: An Effective Medical Image Segmentation Transformer
Sep 15, 2021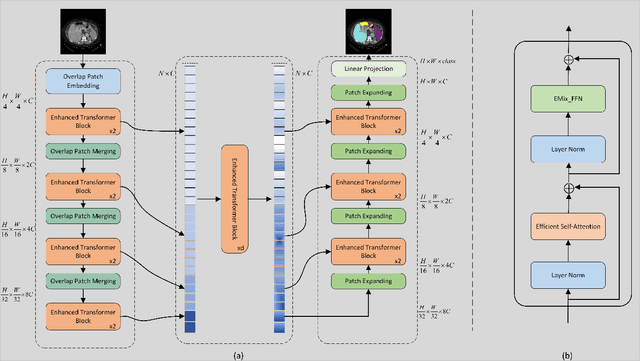

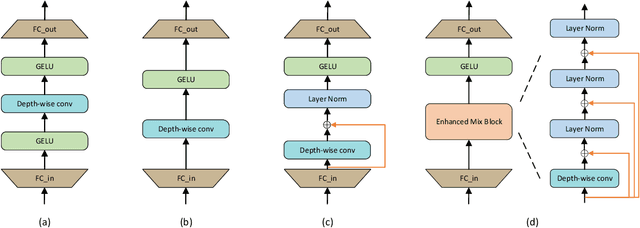
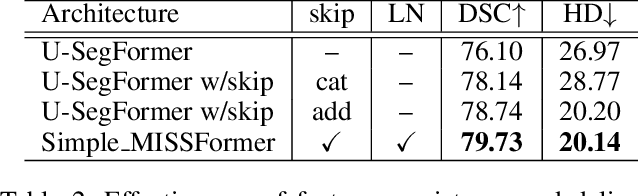
The CNN-based methods have achieved impressive results in medical image segmentation, but it failed to capture the long-range dependencies due to the inherent locality of convolution operation. Transformer-based methods are popular in vision tasks recently because of its capacity of long-range dependencies and get a promising performance. However, it lacks in modeling local context, although some works attempted to embed convolutional layer to overcome this problem and achieved some improvement, but it makes the feature inconsistent and fails to leverage the natural multi-scale features of hierarchical transformer, which limit the performance of models. In this paper, taking medical image segmentation as an example, we present MISSFormer, an effective and powerful Medical Image Segmentation tranSFormer. MISSFormer is a hierarchical encoder-decoder network and has two appealing designs: 1) A feed forward network is redesigned with the proposed Enhanced Transformer Block, which makes features aligned adaptively and enhances the long-range dependencies and local context. 2) We proposed Enhanced Transformer Context Bridge, a context bridge with the enhanced transformer block to model the long-range dependencies and local context of multi-scale features generated by our hierarchical transformer encoder. Driven by these two designs, the MISSFormer shows strong capacity to capture more valuable dependencies and context in medical image segmentation. The experiments on multi-organ and cardiac segmentation tasks demonstrate the superiority, effectiveness and robustness of our MISSFormer, the exprimental results of MISSFormer trained from scratch even outperforms state-of-the-art methods pretrained on ImageNet, and the core designs can be generalized to other visual segmentation tasks. The code will be released in Github.
Introduction of Integrated Image Deep Learning Solution and how it brought laboratorial level heart rate and blood oxygen results to everyone
Apr 13, 2022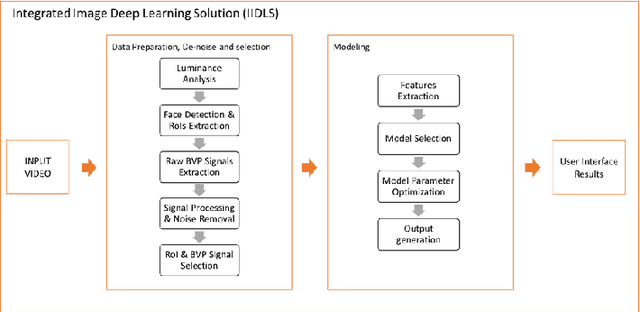
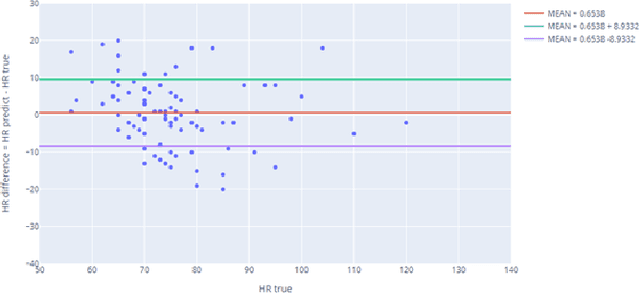
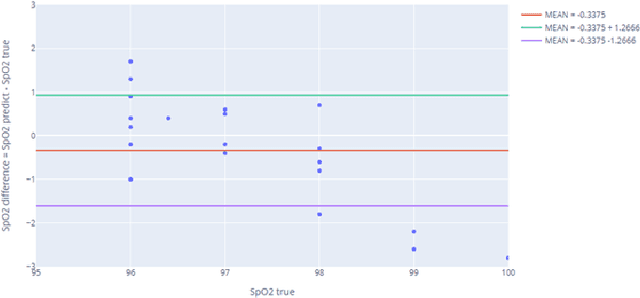
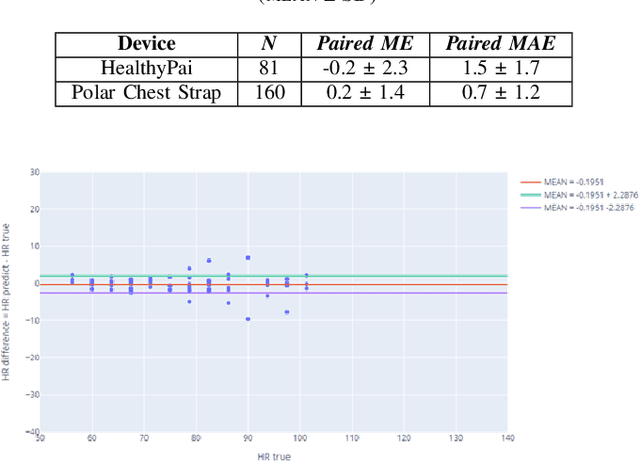
The general public and medical professionals recognized the importance of accurately measuring and storing blood oxygen levels and heart rate during the COVID-19 pandemic. The demand for accurate contact-less devices was motivated by the need for cross-infection reduction and the shortage of conventional oximeters, partially due to the global supply chain issue. This paper evaluated a contact-less mini-program HealthyPai's heart rate (HR) and oxygen saturation (SpO2) measurements compared with other wearable devices. In the HR study of 185 samples (81 in the laboratory environment, 104 in the real-life environment), the mean absolute error (MAE) $\pm$ standard deviation was $1.4827 \pm 1.7452$ in the lab, $6.9231 \pm 5.6426$ in the real-life setting. In the SpO2 study of 24 samples, the mean absolute error (MAE) $\pm$ standard deviation of the measurement was $1.0375 \pm 0.7745$. Our results validated that HealthyPai utilizing the Integrated Image Deep Learning Solution (IIDLS) framework can accurately measure HR and SpO2, providing the test quality at least comparable to other FDA-approved wearable devices in the market and surpassing the consumer-grade and research-grade wearable standards.
The 2021 Image Similarity Dataset and Challenge
Jul 01, 2021
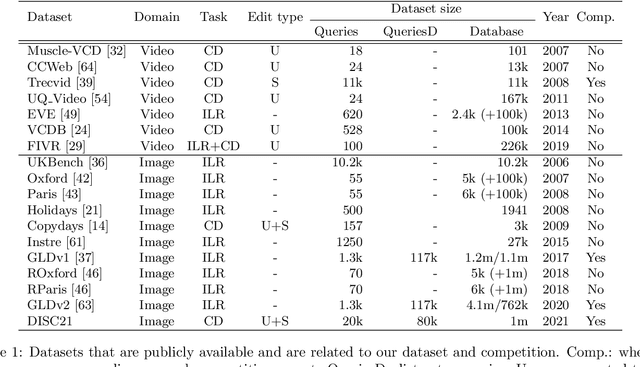
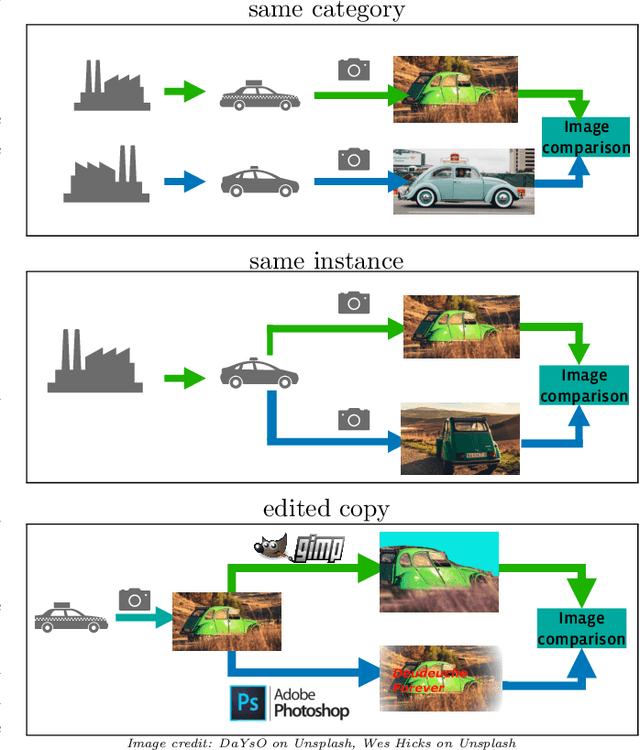

This paper introduces a new benchmark for large-scale image similarity detection. This benchmark is used for the Image Similarity Challenge at NeurIPS'21 (ISC2021). The goal is to determine whether a query image is a modified copy of any image in a reference corpus of size 1~million. The benchmark features a variety of image transformations such as automated transformations, hand-crafted image edits and machine-learning based manipulations. This mimics real-life cases appearing in social media, for example for integrity-related problems dealing with misinformation and objectionable content. The strength of the image manipulations, and therefore the difficulty of the benchmark, is calibrated according to the performance of a set of baseline approaches. Both the query and reference set contain a majority of "distractor" images that do not match, which corresponds to a real-life needle-in-haystack setting, and the evaluation metric reflects that. We expect the DISC21 benchmark to promote image copy detection as an important and challenging computer vision task and refresh the state of the art.
Training Generative Adversarial Networks for Optical Property Mapping using Synthetic Image Data
Mar 15, 2022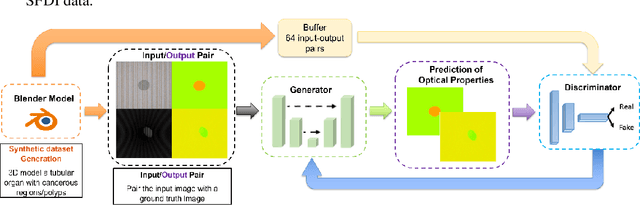

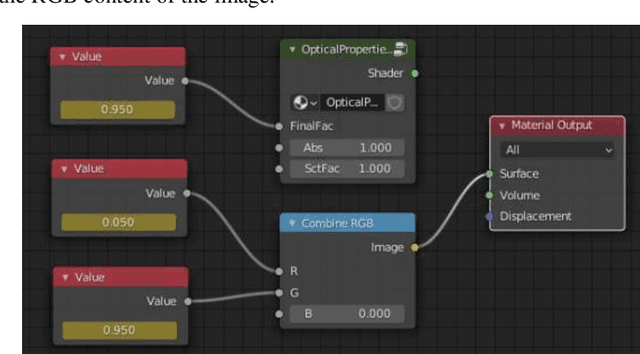
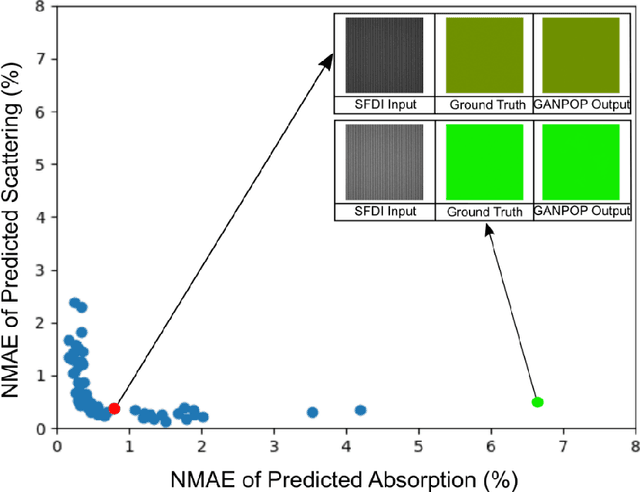
We demonstrate training of a Generative Adversarial Network (GAN) for prediction of optical property maps (scattering and absorption) using spatial frequency domain imaging (SFDI) image data sets generated synthetically with free open-source 3D modelling and rendering software, Blender. The flexibility of Blender is exploited to simulate 3 models with real-life relevance to clinical SFDI of diseased tissue: flat samples, flat samples with spheroidal tumours and cylindrical samples with spheroidal tumours representing imaging inside a tubular organ e.g. the gastro-intestinal tract. In all 3 scenarios we show the GAN provides accurate reconstruction of optical properties from single SFDI images with mean normalised error ranging from 1-1.2% for absorption and 0.7-1.2% for scattering, resulting in visually improved contrast for tumour spheroid structures. This compares favourably with 25% absorption error and 10% scattering error achieved using GANs on experimental SFDI data. However, some of this improvement is due to lower noise and availability of perfect ground truths so we therefore cross-validate our synthetically-trained GAN with a GAN trained on experimental data and observe visually accurate results with error of <40% for absorption and <25% for scattering, due largely to the presence of spatial frequency mismatch artefacts. Our synthetically trained GAN is therefore highly relevant to real experimental samples, but provides significant added benefits of large training datasets, perfect ground-truths and the ability to test realistic imaging geometries, e.g. inside cylinders, for which no conventional single-shot demodulation algorithms exist. In future we expect that application of techniques such as domain adaptation or training on hybrid real-synthetic datasets will create a powerful tool for fast, accurate production of optical property maps from real clinical imaging systems.
Flexible Style Image Super-Resolution using Conditional Objective
Jan 13, 2022
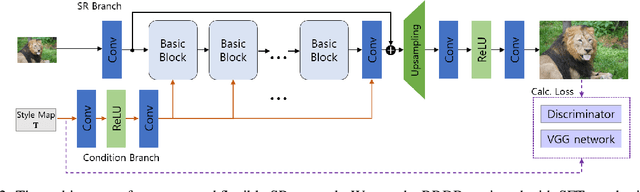

Recent studies have significantly enhanced the performance of single-image super-resolution (SR) using convolutional neural networks (CNNs). While there can be many high-resolution (HR) solutions for a given input, most existing CNN-based methods do not explore alternative solutions during the inference. A typical approach to obtaining alternative SR results is to train multiple SR models with different loss weightings and exploit the combination of these models. Instead of using multiple models, we present a more efficient method to train a single adjustable SR model on various combinations of losses by taking advantage of multi-task learning. Specifically, we optimize an SR model with a conditional objective during training, where the objective is a weighted sum of multiple perceptual losses at different feature levels. The weights vary according to given conditions, and the set of weights is defined as a style controller. Also, we present an architecture appropriate for this training scheme, which is the Residual-in-Residual Dense Block equipped with spatial feature transformation layers. At the inference phase, our trained model can generate locally different outputs conditioned on the style control map. Extensive experiments show that the proposed SR model produces various desirable reconstructions without artifacts and yields comparable quantitative performance to state-of-the-art SR methods.
Neuroevolution-based Classifiers for Deforestation Detection in Tropical Forests
Aug 23, 2022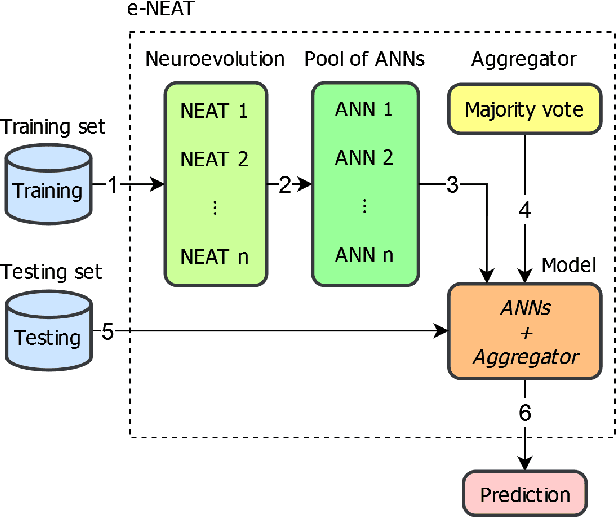
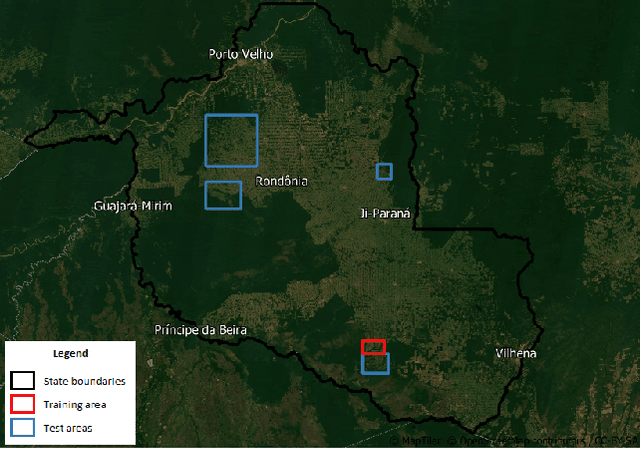
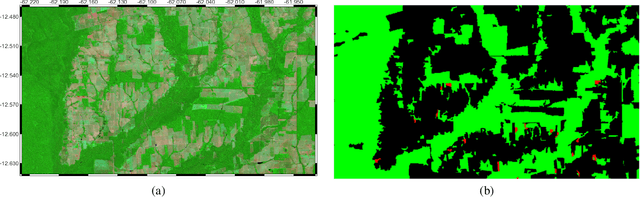

Tropical forests represent the home of many species on the planet for flora and fauna, retaining billions of tons of carbon footprint, promoting clouds and rain formation, implying a crucial role in the global ecosystem, besides representing the home to countless indigenous peoples. Unfortunately, millions of hectares of tropical forests are lost every year due to deforestation or degradation. To mitigate that fact, monitoring and deforestation detection programs are in use, in addition to public policies for the prevention and punishment of criminals. These monitoring/detection programs generally use remote sensing images, image processing techniques, machine learning methods, and expert photointerpretation to analyze, identify and quantify possible changes in forest cover. Several projects have proposed different computational approaches, tools, and models to efficiently identify recent deforestation areas, improving deforestation monitoring programs in tropical forests. In this sense, this paper proposes the use of pattern classifiers based on neuroevolution technique (NEAT) in tropical forest deforestation detection tasks. Furthermore, a novel framework called e-NEAT has been created and achieved classification results above $90\%$ for balanced accuracy measure in the target application using an extremely reduced and limited training set for learning the classification models. These results represent a relative gain of $6.2\%$ over the best baseline ensemble method compared in this paper
Disentangle and Remerge: Interventional Knowledge Distillation for Few-Shot Object Detection from A Conditional Causal Perspective
Aug 26, 2022
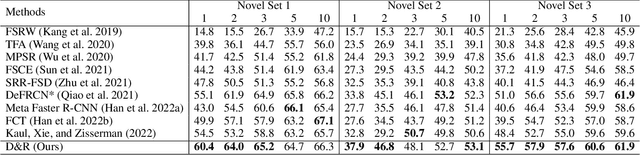
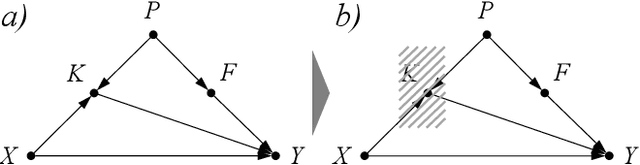
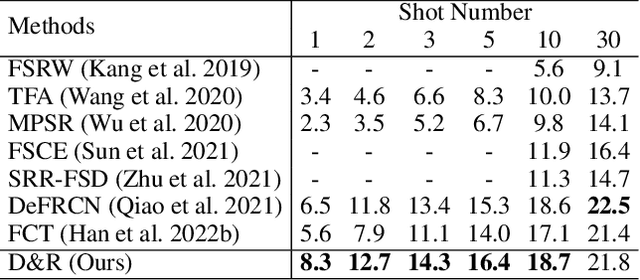
Few-shot learning models learn representations with limited human annotations, and such a learning paradigm demonstrates practicability in various tasks, e.g., image classification, object detection, etc. However, few-shot object detection methods suffer from an intrinsic defect that the limited training data makes the model cannot sufficiently explore semantic information. To tackle this, we introduce knowledge distillation to the few-shot object detection learning paradigm. We further run a motivating experiment, which demonstrates that in the process of knowledge distillation the empirical error of the teacher model degenerates the prediction performance of the few-shot object detection model, as the student. To understand the reasons behind this phenomenon, we revisit the learning paradigm of knowledge distillation on the few-shot object detection task from the causal theoretic standpoint, and accordingly, develop a Structural Causal Model. Following the theoretical guidance, we propose a backdoor adjustment-based knowledge distillation method for the few-shot object detection task, namely Disentangle and Remerge (D&R), to perform conditional causal intervention toward the corresponding Structural Causal Model. Theoretically, we provide an extended definition, i.e., general backdoor path, for the backdoor criterion, which can expand the theoretical application boundary of the backdoor criterion in specific cases. Empirically, the experiments on multiple benchmark datasets demonstrate that D&R can yield significant performance boosts in few-shot object detection.
GAMa: Cross-view Video Geo-localization
Jul 06, 2022
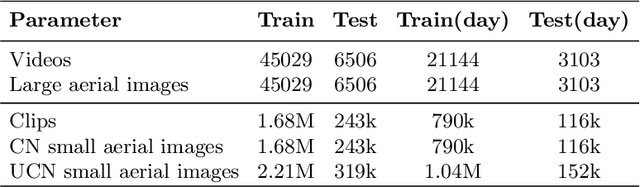


The existing work in cross-view geo-localization is based on images where a ground panorama is matched to an aerial image. In this work, we focus on ground videos instead of images which provides additional contextual cues which are important for this task. There are no existing datasets for this problem, therefore we propose GAMa dataset, a large-scale dataset with ground videos and corresponding aerial images. We also propose a novel approach to solve this problem. At clip-level, a short video clip is matched with corresponding aerial image and is later used to get video-level geo-localization of a long video. Moreover, we propose a hierarchical approach to further improve the clip-level geolocalization. It is a challenging dataset, unaligned and limited field of view, and our proposed method achieves a Top-1 recall rate of 19.4% and 45.1% @1.0mile. Code and dataset are available at following link: https://github.com/svyas23/GAMa.
Word-Level Fine-Grained Story Visualization
Aug 03, 2022

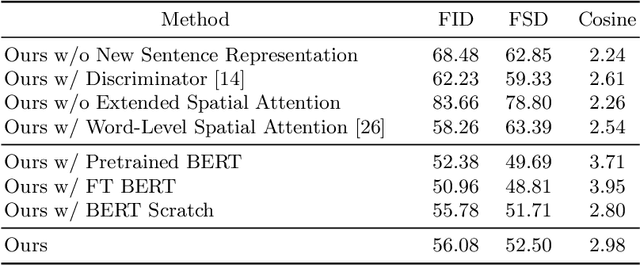
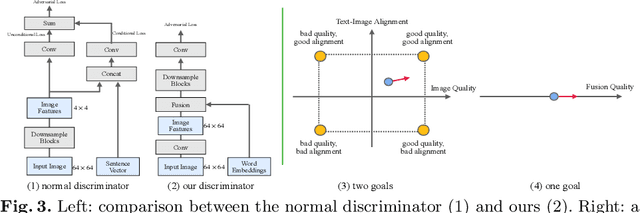
Story visualization aims to generate a sequence of images to narrate each sentence in a multi-sentence story with a global consistency across dynamic scenes and characters. Current works still struggle with output images' quality and consistency, and rely on additional semantic information or auxiliary captioning networks. To address these challenges, we first introduce a new sentence representation, which incorporates word information from all story sentences to mitigate the inconsistency problem. Then, we propose a new discriminator with fusion features and further extend the spatial attention to improve image quality and story consistency. Extensive experiments on different datasets and human evaluation demonstrate the superior performance of our approach, compared to state-of-the-art methods, neither using segmentation masks nor auxiliary captioning networks.