 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Work In Progress: Safety and Robustness Verification of Autoencoder-Based Regression Models using the NNV Tool
Jul 14, 2022
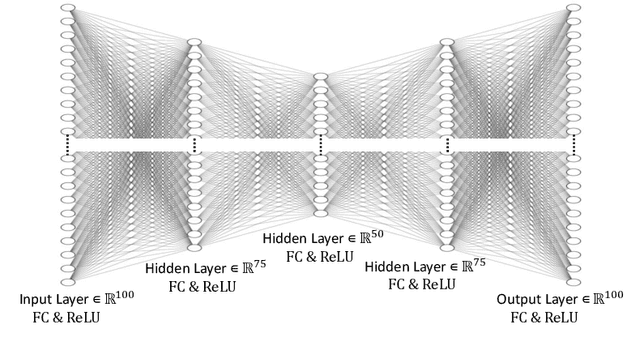
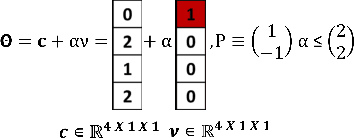
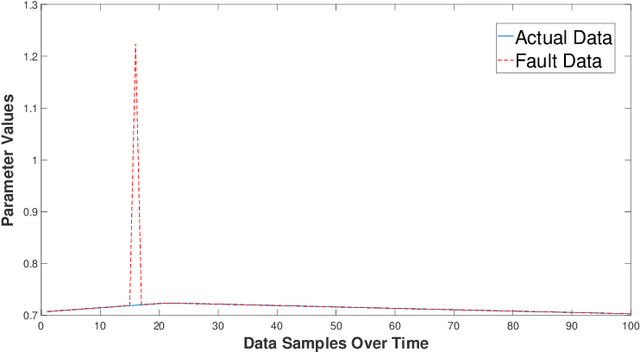

This work in progress paper introduces robustness verification for autoencoder-based regression neural network (NN) models, following state-of-the-art approaches for robustness verification of image classification NNs. Despite the ongoing progress in developing verification methods for safety and robustness in various deep neural networks (DNNs), robustness checking of autoencoder models has not yet been considered. We explore this open space of research and check ways to bridge the gap between existing DNN verification methods by extending existing robustness analysis methods for such autoencoder networks. While classification models using autoencoders work more or less similar to image classification NNs, the functionality of regression models is distinctly different. We introduce two definitions of robustness evaluation metrics for autoencoder-based regression models, specifically the percentage robustness and un-robustness grade. We also modified the existing Imagestar approach, adjusting the variables to take care of the specific input types for regression networks. The approach is implemented as an extension of NNV, then applied and evaluated on a dataset, with a case study experiment shown using the same dataset. As per the authors' understanding, this work in progress paper is the first to show possible reachability analysis of autoencoder-based NNs.
* In Proceedings SNR 2021, arXiv:2207.04391
HSIC-InfoGAN: Learning Unsupervised Disentangled Representations by Maximising Approximated Mutual Information
Aug 06, 2022
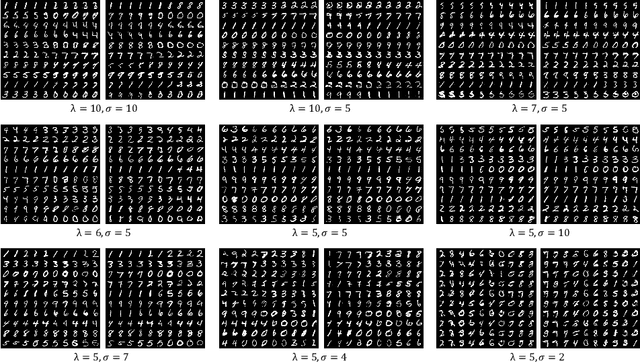
Learning disentangled representations requires either supervision or the introduction of specific model designs and learning constraints as biases. InfoGAN is a popular disentanglement framework that learns unsupervised disentangled representations by maximising the mutual information between latent representations and their corresponding generated images. Maximisation of mutual information is achieved by introducing an auxiliary network and training with a latent regression loss. In this short exploratory paper, we study the use of the Hilbert-Schmidt Independence Criterion (HSIC) to approximate mutual information between latent representation and image, termed HSIC-InfoGAN. Directly optimising the HSIC loss avoids the need for an additional auxiliary network. We qualitatively compare the level of disentanglement in each model, suggest a strategy to tune the hyperparameters of HSIC-InfoGAN, and discuss the potential of HSIC-InfoGAN for medical applications.
Mix-Teaching: A Simple, Unified and Effective Semi-Supervised Learning Framework for Monocular 3D Object Detection
Jul 10, 2022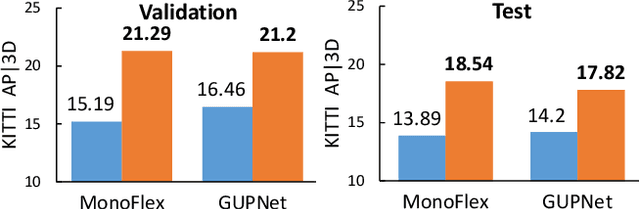
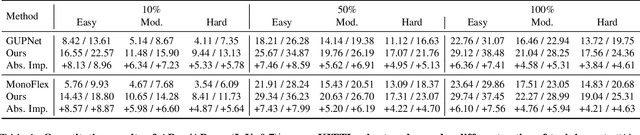
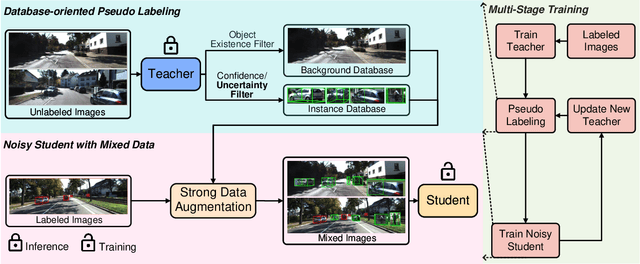
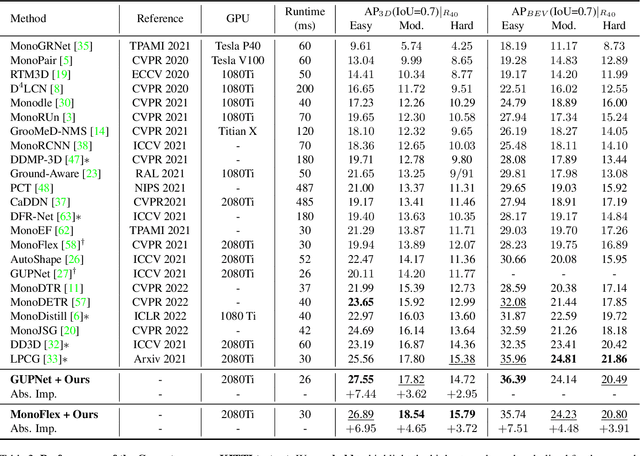
Monocular 3D object detection is an essential perception task for autonomous driving. However, the high reliance on large-scale labeled data make it costly and time-consuming during model optimization. To reduce such over-reliance on human annotations, we propose Mix-Teaching, an effective semi-supervised learning framework applicable to employ both labeled and unlabeled images in training stage. Mix-Teaching first generates pseudo-labels for unlabeled images by self-training. The student model is then trained on the mixed images possessing much more intensive and precise labeling by merging instance-level image patches into empty backgrounds or labeled images. This is the first to break the image-level limitation and put high-quality pseudo labels from multi frames into one image for semi-supervised training. Besides, as a result of the misalignment between confidence score and localization quality, it's hard to discriminate high-quality pseudo-labels from noisy predictions using only confidence-based criterion. To that end, we further introduce an uncertainty-based filter to help select reliable pseudo boxes for the above mixing operation. To the best of our knowledge, this is the first unified SSL framework for monocular 3D object detection. Mix-Teaching consistently improves MonoFlex and GUPNet by significant margins under various labeling ratios on KITTI dataset. For example, our method achieves around +6.34% AP@0.7 improvement against the GUPNet baseline on validation set when using only 10% labeled data. Besides, by leveraging full training set and the additional 48K raw images of KITTI, it can further improve the MonoFlex by +4.65% improvement on AP@0.7 for car detection, reaching 18.54% AP@0.7, which ranks the 1st place among all monocular based methods on KITTI test leaderboard. The code and pretrained models will be released at https://github.com/yanglei18/Mix-Teaching.
Sparse to Dense Motion Transfer for Face Image Animation
Sep 03, 2021


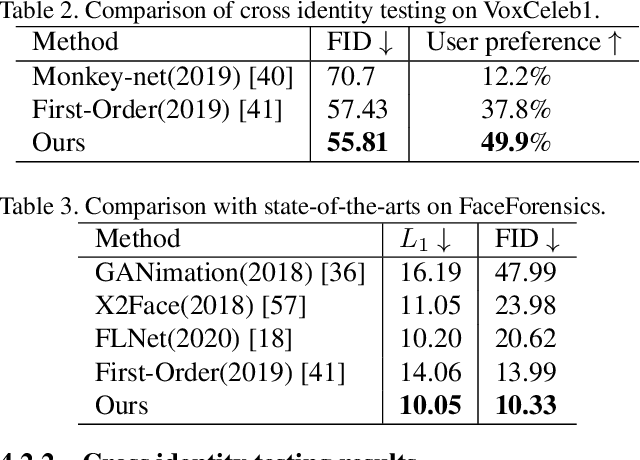
Face image animation from a single image has achieved remarkable progress. However, it remains challenging when only sparse landmarks are available as the driving signal. Given a source face image and a sequence of sparse face landmarks, our goal is to generate a video of the face imitating the motion of landmarks. We develop an efficient and effective method for motion transfer from sparse landmarks to the face image. We then combine global and local motion estimation in a unified model to faithfully transfer the motion. The model can learn to segment the moving foreground from the background and generate not only global motion, such as rotation and translation of the face, but also subtle local motion such as the gaze change. We further improve face landmark detection on videos. With temporally better aligned landmark sequences for training, our method can generate temporally coherent videos with higher visual quality. Experiments suggest we achieve results comparable to the state-of-the-art image driven method on the same identity testing and better results on cross identity testing.
A No-Reference Deep Learning Quality Assessment Method for Super-resolution Images Based on Frequency Maps
Jun 09, 2022
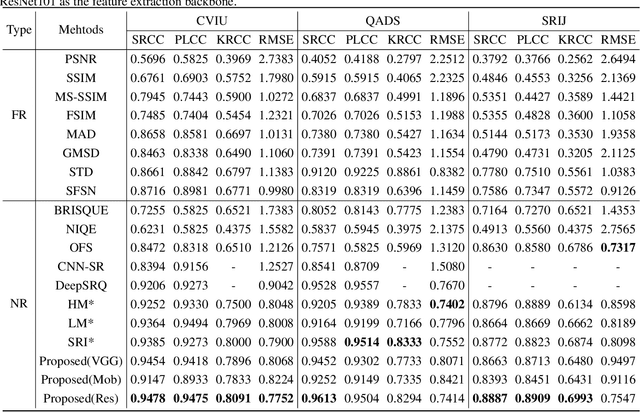
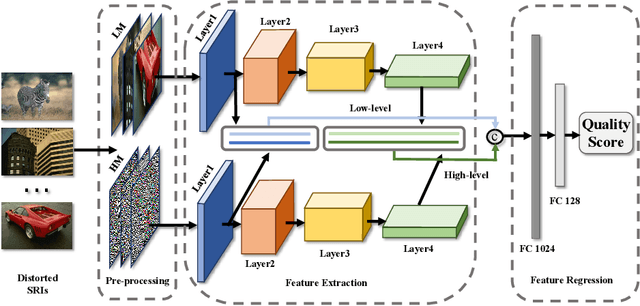
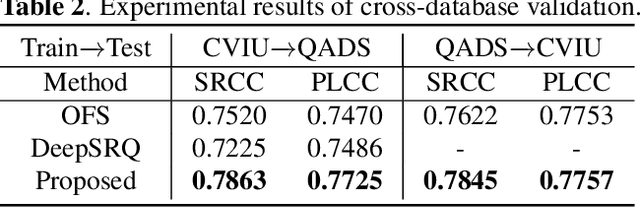
To support the application scenarios where high-resolution (HR) images are urgently needed, various single image super-resolution (SISR) algorithms are developed. However, SISR is an ill-posed inverse problem, which may bring artifacts like texture shift, blur, etc. to the reconstructed images, thus it is necessary to evaluate the quality of super-resolution images (SRIs). Note that most existing image quality assessment (IQA) methods were developed for synthetically distorted images, which may not work for SRIs since their distortions are more diverse and complicated. Therefore, in this paper, we propose a no-reference deep-learning image quality assessment method based on frequency maps because the artifacts caused by SISR algorithms are quite sensitive to frequency information. Specifically, we first obtain the high-frequency map (HM) and low-frequency map (LM) of SRI by using Sobel operator and piecewise smooth image approximation. Then, a two-stream network is employed to extract the quality-aware features of both frequency maps. Finally, the features are regressed into a single quality value using fully connected layers. The experimental results show that our method outperforms all compared IQA models on the selected three super-resolution quality assessment (SRQA) databases.
Frequency-Supervised MR-to-CT Image Synthesis
Jul 19, 2021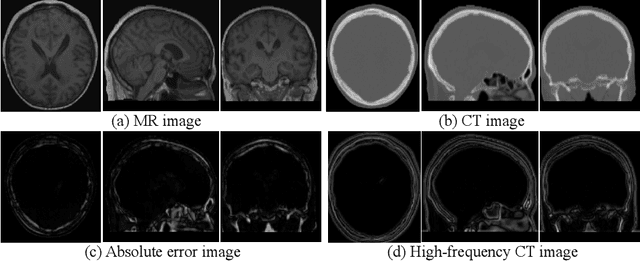

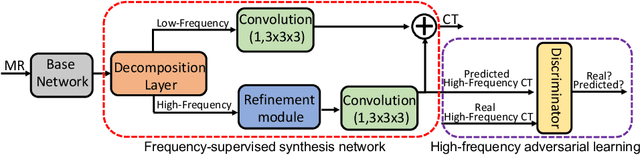

This paper strives to generate a synthetic computed tomography (CT) image from a magnetic resonance (MR) image. The synthetic CT image is valuable for radiotherapy planning when only an MR image is available. Recent approaches have made large strides in solving this challenging synthesis problem with convolutional neural networks that learn a mapping from MR inputs to CT outputs. In this paper, we find that all existing approaches share a common limitation: reconstruction breaks down in and around the high-frequency parts of CT images. To address this common limitation, we introduce frequency-supervised deep networks to explicitly enhance high-frequency MR-to-CT image reconstruction. We propose a frequency decomposition layer that learns to decompose predicted CT outputs into low- and high-frequency components, and we introduce a refinement module to improve high-frequency reconstruction through high-frequency adversarial learning. Experimental results on a new dataset with 45 pairs of 3D MR-CT brain images show the effectiveness and potential of the proposed approach. Code is available at \url{https://github.com/shizenglin/Frequency-Supervised-MR-to-CT-Image-Synthesis}.
Contrastive Cross-Modal Knowledge Sharing Pre-training for Vision-Language Representation Learning and Retrieval
Jul 02, 2022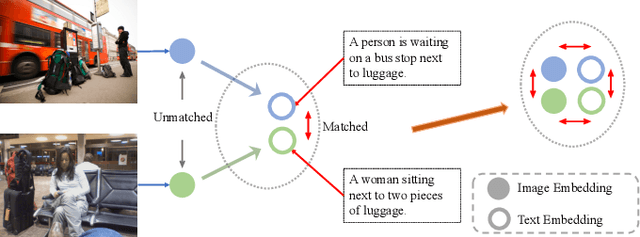
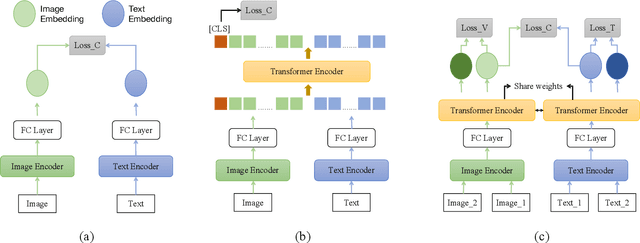
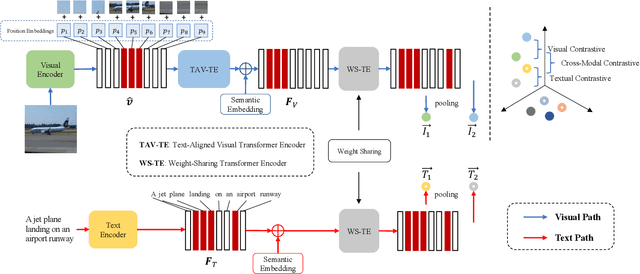

Recently, the cross-modal pre-training task has been a hotspot because of its wide application in various down-streaming researches including retrieval, captioning, question answering and so on. However, exiting methods adopt a one-stream pre-training model to explore the united vision-language representation for conducting cross-modal retrieval, which easily suffer from the calculation explosion. Moreover, although the conventional double-stream structures are quite efficient, they still lack the vital cross-modal interactions, resulting in low performances. Motivated by these challenges, we put forward a Contrastive Cross-Modal Knowledge Sharing Pre-training (COOKIE) to grasp the joint text-image representations. Structurally, COOKIE adopts the traditional double-stream structure because of the acceptable time consumption. To overcome the inherent defects of double-stream structure as mentioned above, we elaborately design two effective modules. Concretely, the first module is a weight-sharing transformer that builds on the head of the visual and textual encoders, aiming to semantically align text and image. This design enables visual and textual paths focus on the same semantics. The other one is three specially designed contrastive learning, aiming to share knowledge between different models. The shared cross-modal knowledge develops the study of unimodal representation greatly, promoting the single-modal retrieval tasks. Extensive experimental results on multi-modal matching researches that includes cross-modal retrieval, text matching, and image retrieval reveal the superiors in calculation efficiency and statistical indicators of our pre-training model.
Region-guided CycleGANs for Stain Transfer in Whole Slide Images
Aug 26, 2022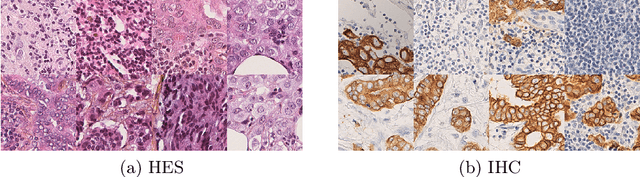
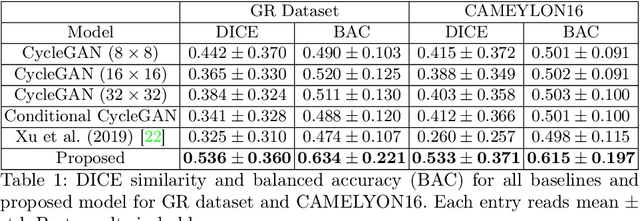
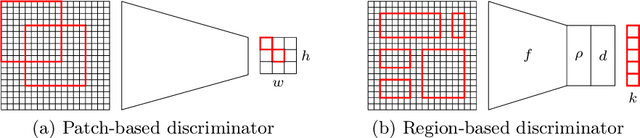
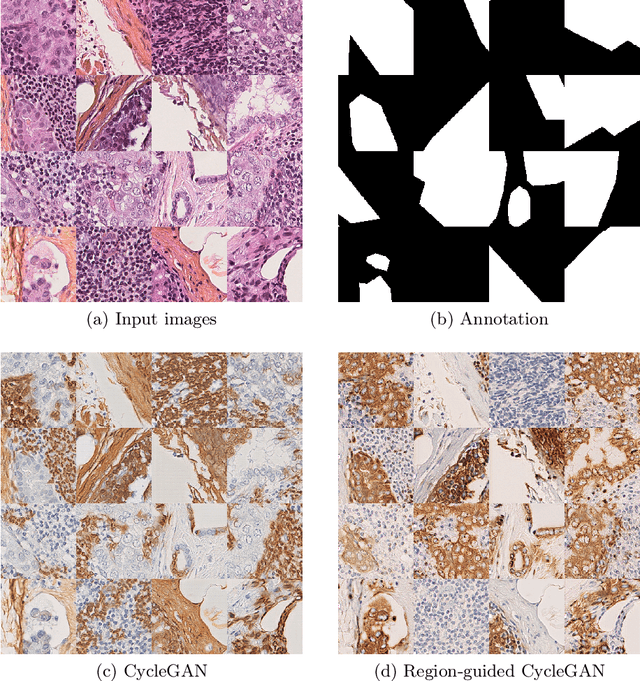
In whole slide imaging, commonly used staining techniques based on hematoxylin and eosin (H&E) and immunohistochemistry (IHC) stains accentuate different aspects of the tissue landscape. In the case of detecting metastases, IHC provides a distinct readout that is readily interpretable by pathologists. IHC, however, is a more expensive approach and not available at all medical centers. Virtually generating IHC images from H&E using deep neural networks thus becomes an attractive alternative. Deep generative models such as CycleGANs learn a semantically-consistent mapping between two image domains, while emulating the textural properties of each domain. They are therefore a suitable choice for stain transfer applications. However, they remain fully unsupervised, and possess no mechanism for enforcing biological consistency in stain transfer. In this paper, we propose an extension to CycleGANs in the form of a region of interest discriminator. This allows the CycleGAN to learn from unpaired datasets where, in addition, there is a partial annotation of objects for which one wishes to enforce consistency. We present a use case on whole slide images, where an IHC stain provides an experimentally generated signal for metastatic cells. We demonstrate the superiority of our approach over prior art in stain transfer on histopathology tiles over two datasets. Our code and model are available at https://github.com/jcboyd/miccai2022-roigan.
Image-based Automatic Dial Meter Reading in Unconstrained Scenarios
Jan 08, 2022

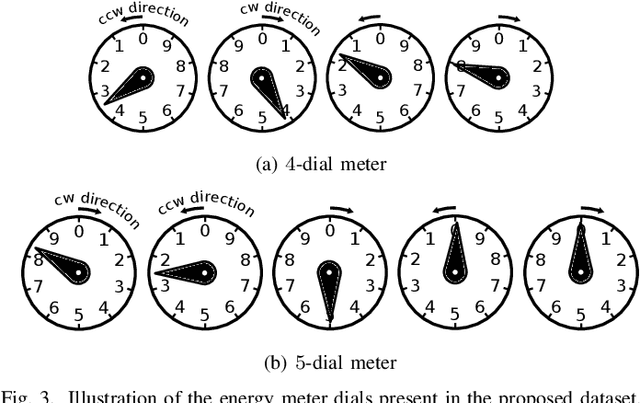
The replacement of analog meters with smart meters is costly, laborious, and far from complete in developing countries. The Energy Company of Parana (Copel) (Brazil) performs more than 4 million meter readings (almost entirely of non-smart devices) per month, and we estimate that 850 thousand of them are from dial meters. Therefore, an image-based automatic reading system can reduce human errors, create a proof of reading, and enable the customers to perform the reading themselves through a mobile application. We propose novel approaches for Automatic Dial Meter Reading (ADMR) and introduce a new dataset for ADMR in unconstrained scenarios, called UFPR-ADMR-v2. Our best-performing method combines YOLOv4 with a novel regression approach (AngReg), and explores several postprocessing techniques. Compared to previous works, it decreased the Mean Absolute Error (MAE) from 1,343 to 129 and achieved a meter recognition rate (MRR) of 98.90% -- with an error tolerance of 1 Kilowatt-hour (kWh).
A Deep-Learning Framework for Improving COVID-19 CT Image Quality and Diagnostic Accuracy
Dec 16, 2021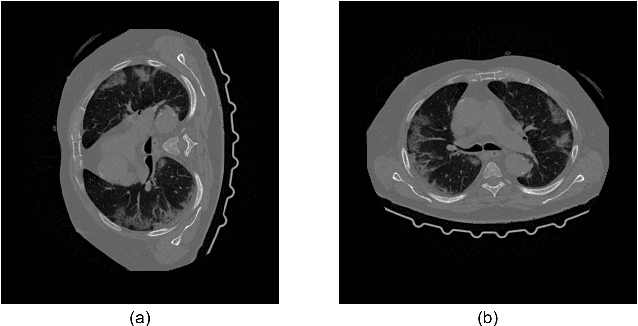
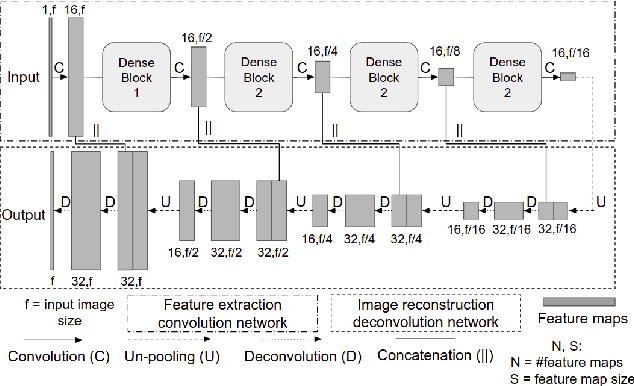
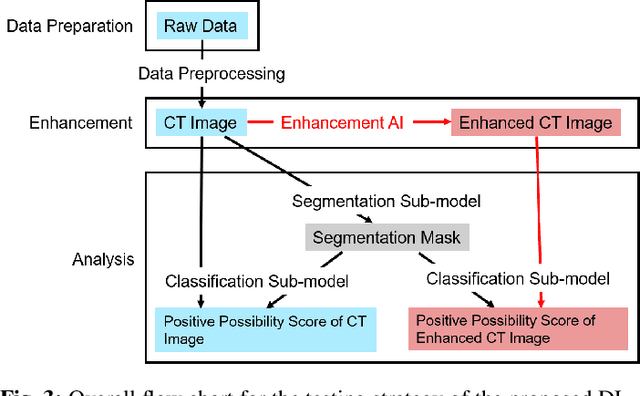
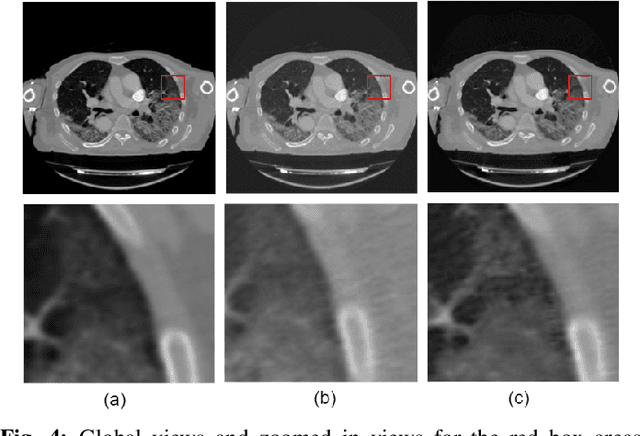
We present a deep-learning based computing framework for fast-and-accurate CT (DL-FACT) testing of COVID-19. Our CT-based DL framework was developed to improve the testing speed and accuracy of COVID-19 (plus its variants) via a DL-based approach for CT image enhancement and classification. The image enhancement network is adapted from DDnet, short for DenseNet and Deconvolution based network. To demonstrate its speed and accuracy, we evaluated DL-FACT across several sources of COVID-19 CT images. Our results show that DL-FACT can significantly shorten the turnaround time from days to minutes and improve the COVID-19 testing accuracy up to 91%. DL-FACT could be used as a software tool for medical professionals in diagnosing and monitoring COVID-19.