 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Prompt-Driven Dynamic Object-Centric Learning for Single Domain Generalization
Feb 28, 2024
Single-domain generalization aims to learn a model from single source domain data to achieve generalized performance on other unseen target domains. Existing works primarily focus on improving the generalization ability of static networks. However, static networks are unable to dynamically adapt to the diverse variations in different image scenes, leading to limited generalization capability. Different scenes exhibit varying levels of complexity, and the complexity of images further varies significantly in cross-domain scenarios. In this paper, we propose a dynamic object-centric perception network based on prompt learning, aiming to adapt to the variations in image complexity. Specifically, we propose an object-centric gating module based on prompt learning to focus attention on the object-centric features guided by the various scene prompts. Then, with the object-centric gating masks, the dynamic selective module dynamically selects highly correlated feature regions in both spatial and channel dimensions enabling the model to adaptively perceive object-centric relevant features, thereby enhancing the generalization capability. Extensive experiments were conducted on single-domain generalization tasks in image classification and object detection. The experimental results demonstrate that our approach outperforms state-of-the-art methods, which validates the effectiveness and generally of our proposed method.
ADS: Approximate Densest Subgraph for Novel Image Discovery
Feb 13, 2024The volume of image repositories continues to grow. Despite the availability of content-based addressing, we still lack a lightweight tool that allows us to discover images of distinct characteristics from a large collection. In this paper, we propose a fast and training-free algorithm for novel image discovery. The key of our algorithm is formulating a collection of images as a perceptual distance-weighted graph, within which our task is to locate the K-densest subgraph that corresponds to a subset of the most unique images. While solving this problem is not just NP-hard but also requires a full computation of the potentially huge distance matrix, we propose to relax it into a K-sparse eigenvector problem that we can efficiently solve using stochastic gradient descent (SGD) without explicitly computing the distance matrix. We compare our algorithm against state-of-the-arts on both synthetic and real datasets, showing that it is considerably faster to run with a smaller memory footprint while able to mine novel images more accurately.
Decompose-and-Compose: A Compositional Approach to Mitigating Spurious Correlation
Feb 29, 2024While standard Empirical Risk Minimization (ERM) training is proven effective for image classification on in-distribution data, it fails to perform well on out-of-distribution samples. One of the main sources of distribution shift for image classification is the compositional nature of images. Specifically, in addition to the main object or component(s) determining the label, some other image components usually exist, which may lead to the shift of input distribution between train and test environments. More importantly, these components may have spurious correlations with the label. To address this issue, we propose Decompose-and-Compose (DaC), which improves robustness to correlation shift by a compositional approach based on combining elements of images. Based on our observations, models trained with ERM usually highly attend to either the causal components or the components having a high spurious correlation with the label (especially in datapoints on which models have a high confidence). In fact, according to the amount of spurious correlation and the easiness of classification based on the causal or non-causal components, the model usually attends to one of these more (on samples with high confidence). Following this, we first try to identify the causal components of images using class activation maps of models trained with ERM. Afterward, we intervene on images by combining them and retraining the model on the augmented data, including the counterfactual ones. Along with its high interpretability, this work proposes a group-balancing method by intervening on images without requiring group labels or information regarding the spurious features during training. The method has an overall better worst group accuracy compared to previous methods with the same amount of supervision on the group labels in correlation shift.
Simulation of Muon Tomography Projections to Image the Pyramids of Giza
Feb 27, 2024Purpose: A geometric simulation of a possible two-plane detector was developed to test the abilities of the detector to generate high-resolution images of the Great Pyramid using muon tomography. Methods and Materials: Trajectory range, angular resolution, and acceptance of the detector were calculated with a simulation. Trajectories and the corresponding sinogram space covered were simulated first with one detector in one location, and then two moving detectors on adjacent sides of the pyramid. The resolution at the center slice of the pyramid was calculated using the angular resolution of the detector. Results: The simulation returned trajectory range encompassing the pyramid and peak angular resolution of .0004sr. Sinogram space covered by one position was inadequate, however two moving detectors on adjacent sides of the pyramid cover a significant portion. Resolution at the center of the pyramid is roughly 3m. Conclusions: The simulation provides a way to calculate the detector positions needed to cover an adequate amount of sinogram space for high-resolution cosmic-ray tomographic reconstruction of the Great Pyramids. Key Words: high-resolution muon tomography, one-sided tomography, sinogram simulation, detector simulation
Trajectory Consistency Distillation
Feb 29, 2024Latent Consistency Model (LCM) extends the Consistency Model to the latent space and leverages the guided consistency distillation technique to achieve impressive performance in accelerating text-to-image synthesis. However, we observed that LCM struggles to generate images with both clarity and detailed intricacy. To address this limitation, we initially delve into and elucidate the underlying causes. Our investigation identifies that the primary issue stems from errors in three distinct areas. Consequently, we introduce Trajectory Consistency Distillation (TCD), which encompasses trajectory consistency function and strategic stochastic sampling. The trajectory consistency function diminishes the distillation errors by broadening the scope of the self-consistency boundary condition and endowing the TCD with the ability to accurately trace the entire trajectory of the Probability Flow ODE. Additionally, strategic stochastic sampling is specifically designed to circumvent the accumulated errors inherent in multi-step consistency sampling, which is meticulously tailored to complement the TCD model. Experiments demonstrate that TCD not only significantly enhances image quality at low NFEs but also yields more detailed results compared to the teacher model at high NFEs.
ProtoP-OD: Explainable Object Detection with Prototypical Parts
Feb 29, 2024Interpretation and visualization of the behavior of detection transformers tends to highlight the locations in the image that the model attends to, but it provides limited insight into the \emph{semantics} that the model is focusing on. This paper introduces an extension to detection transformers that constructs prototypical local features and uses them in object detection. These custom features, which we call prototypical parts, are designed to be mutually exclusive and align with the classifications of the model. The proposed extension consists of a bottleneck module, the prototype neck, that computes a discretized representation of prototype activations and a new loss term that matches prototypes to object classes. This setup leads to interpretable representations in the prototype neck, allowing visual inspection of the image content perceived by the model and a better understanding of the model's reliability. We show experimentally that our method incurs only a limited performance penalty, and we provide examples that demonstrate the quality of the explanations provided by our method, which we argue outweighs the performance penalty.
Theoretical Insights for Diffusion Guidance: A Case Study for Gaussian Mixture Models
Mar 03, 2024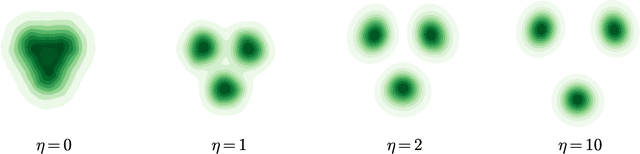
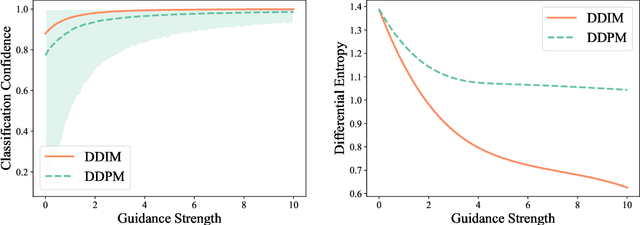
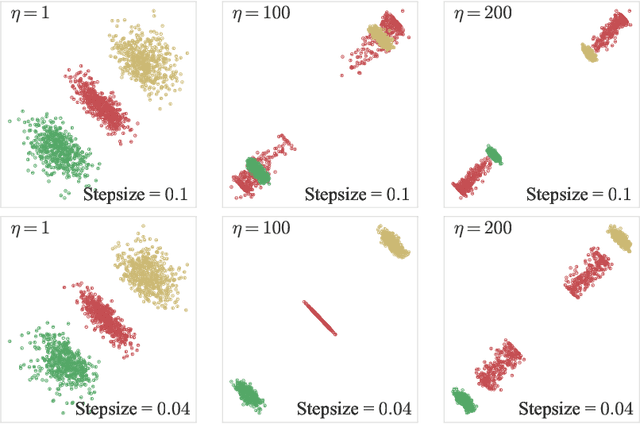
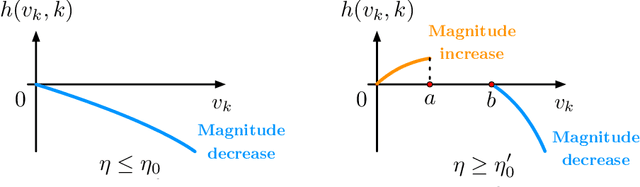
Diffusion models benefit from instillation of task-specific information into the score function to steer the sample generation towards desired properties. Such information is coined as guidance. For example, in text-to-image synthesis, text input is encoded as guidance to generate semantically aligned images. Proper guidance inputs are closely tied to the performance of diffusion models. A common observation is that strong guidance promotes a tight alignment to the task-specific information, while reducing the diversity of the generated samples. In this paper, we provide the first theoretical study towards understanding the influence of guidance on diffusion models in the context of Gaussian mixture models. Under mild conditions, we prove that incorporating diffusion guidance not only boosts classification confidence but also diminishes distribution diversity, leading to a reduction in the differential entropy of the output distribution. Our analysis covers the widely adopted sampling schemes including DDPM and DDIM, and leverages comparison inequalities for differential equations as well as the Fokker-Planck equation that characterizes the evolution of probability density function, which may be of independent theoretical interest.
Depth Estimation Algorithm Based on Transformer-Encoder and Feature Fusion
Mar 03, 2024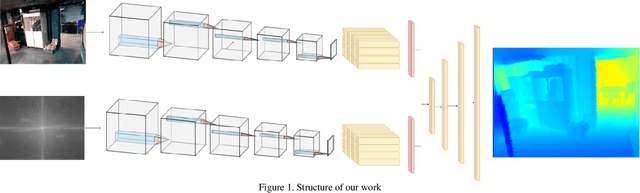
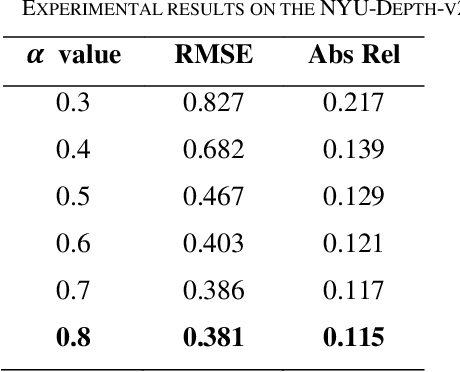
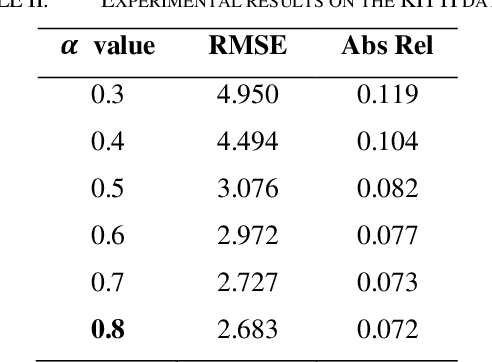

This research presents a novel depth estimation algorithm based on a Transformer-encoder architecture, tailored for the NYU and KITTI Depth Dataset. This research adopts a transformer model, initially renowned for its success in natural language processing, to capture intricate spatial relationships in visual data for depth estimation tasks. A significant innovation of the research is the integration of a composite loss function that combines Structural Similarity Index Measure (SSIM) with Mean Squared Error (MSE). This combined loss function is designed to ensure the structural integrity of the predicted depth maps relative to the original images (via SSIM) while minimizing pixel-wise estimation errors (via MSE). This research approach addresses the challenges of over-smoothing often seen in MSE-based losses and enhances the model's ability to predict depth maps that are not only accurate but also maintain structural coherence with the input images. Through rigorous training and evaluation using the NYU Depth Dataset, the model demonstrates superior performance, marking a significant advancement in single-image depth estimation, particularly in complex indoor and traffic environments.
KnowPhish: Large Language Models Meet Multimodal Knowledge Graphs for Enhancing Reference-Based Phishing Detection
Mar 04, 2024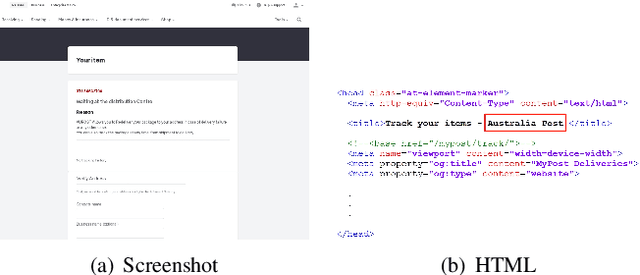

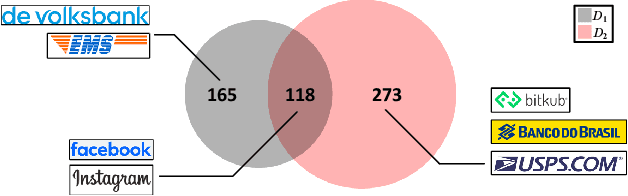

Phishing attacks have inflicted substantial losses on individuals and businesses alike, necessitating the development of robust and efficient automated phishing detection approaches. Reference-based phishing detectors (RBPDs), which compare the logos on a target webpage to a known set of logos, have emerged as the state-of-the-art approach. However, a major limitation of existing RBPDs is that they rely on a manually constructed brand knowledge base, making it infeasible to scale to a large number of brands, which results in false negative errors due to the insufficient brand coverage of the knowledge base. To address this issue, we propose an automated knowledge collection pipeline, using which we collect and release a large-scale multimodal brand knowledge base, KnowPhish, containing 20k brands with rich information about each brand. KnowPhish can be used to boost the performance of existing RBPDs in a plug-and-play manner. A second limitation of existing RBPDs is that they solely rely on the image modality, ignoring useful textual information present in the webpage HTML. To utilize this textual information, we propose a Large Language Model (LLM)-based approach to extract brand information of webpages from text. Our resulting multimodal phishing detection approach, KnowPhish Detector (KPD), can detect phishing webpages with or without logos. We evaluate KnowPhish and KPD on a manually validated dataset, and on a field study under Singapore's local context, showing substantial improvements in effectiveness and efficiency compared to state-of-the-art baselines.
Map-aided annotation for pole base detection
Mar 04, 2024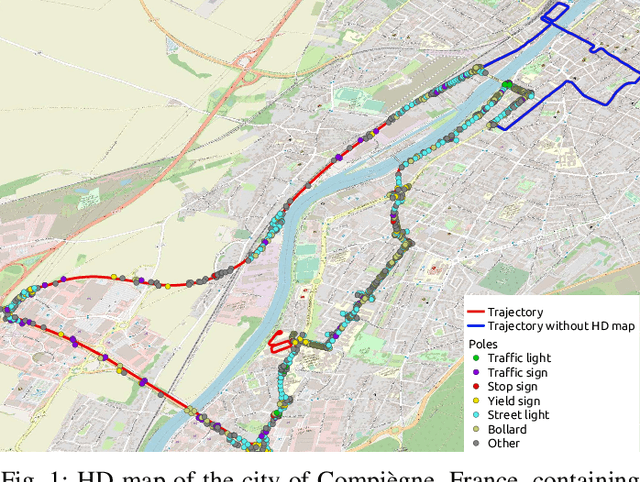



For autonomous navigation, high definition maps are a widely used source of information. Pole-like features encoded in HD maps such as traffic signs, traffic lights or street lights can be used as landmarks for localization. For this purpose, they first need to be detected by the vehicle using its embedded sensors. While geometric models can be used to process 3D point clouds retrieved by lidar sensors, modern image-based approaches rely on deep neural network and therefore heavily depend on annotated training data. In this paper, a 2D HD map is used to automatically annotate pole-like features in images. In the absence of height information, the map features are represented as pole bases at the ground level. We show how an additional lidar sensor can be used to filter out occluded features and refine the ground projection. We also demonstrate how an object detector can be trained to detect a pole base. To evaluate our methodology, it is first validated with data manually annotated from semantic segmentation and then compared to our own automatically generated annotated data recorded in the city of Compi{\`e}gne, France. Erratum: In the original version [1], an error occurred in the accuracy evaluation of the different models studied and the evaluation method applied on the detection results was not clearly defined. In this revision, we offer a rectification to this segment, presenting updated results, especially in terms of Mean Absolute Errors (MAE).