 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
The 2021 Image Similarity Dataset and Challenge
Jun 17, 2021
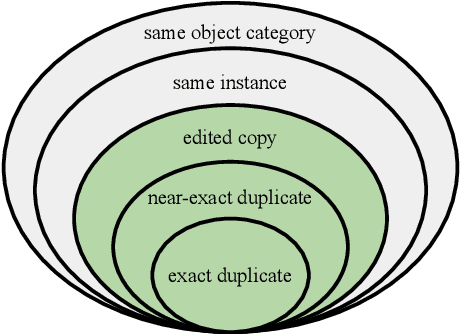
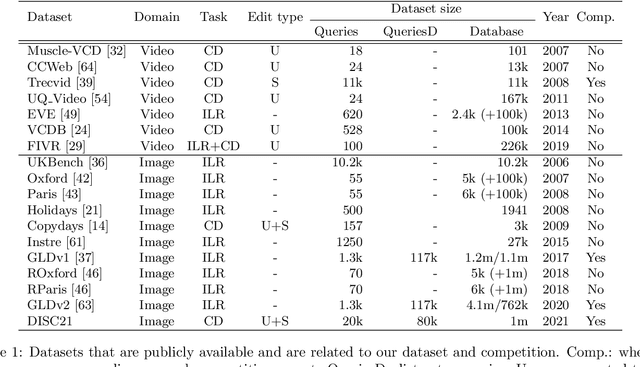
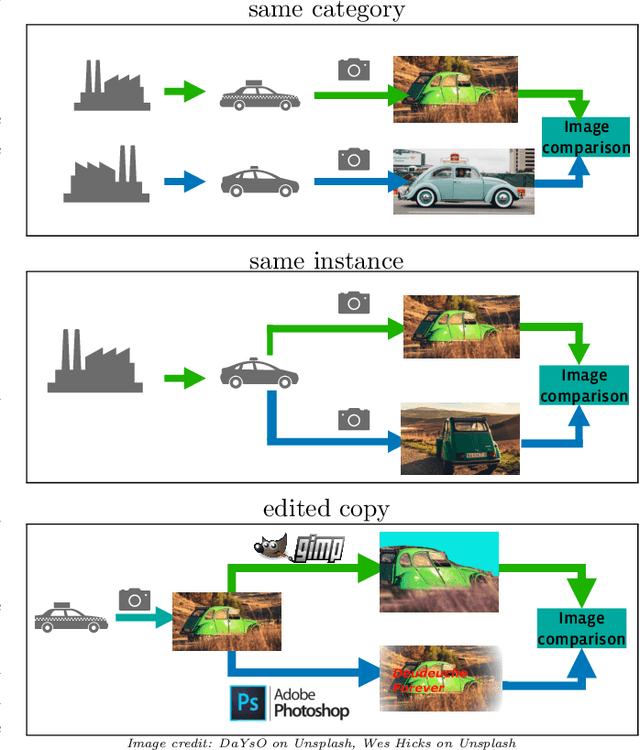

This paper introduces a new benchmark for large-scale image similarity detection. This benchmark is used for the Image Similarity Challenge at NeurIPS'21 (ISC2021). The goal is to determine whether a query image is a modified copy of any image in a reference corpus of size 1~million. The benchmark features a variety of image transformations such as automated transformations, hand-crafted image edits and machine-learning based manipulations. This mimics real-life cases appearing in social media, for example for integrity-related problems dealing with misinformation and objectionable content. The strength of the image manipulations, and therefore the difficulty of the benchmark, is calibrated according to the performance of a set of baseline approaches. Both the query and reference set contain a majority of ``distractor'' images that do not match, which corresponds to a real-life needle-in-haystack setting, and the evaluation metric reflects that. We expect the DISC21 benchmark to promote image copy detection as an important and challenging computer vision task and refresh the state of the art.
Fashion Recommendation Based on Style and Social Events
Aug 01, 2022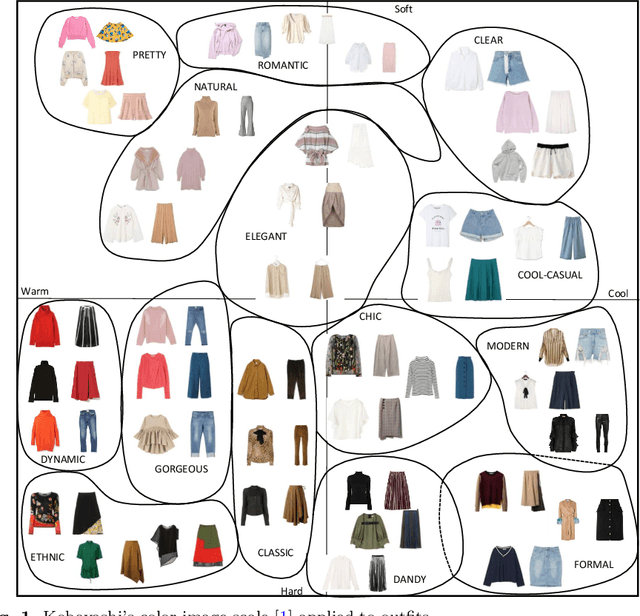
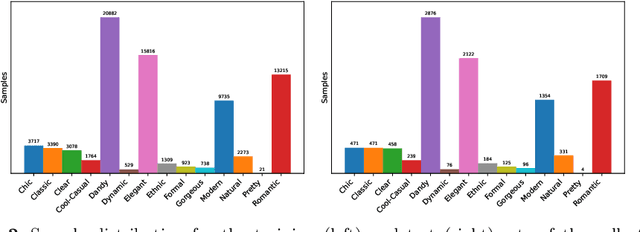


Fashion recommendation is often declined as the task of finding complementary items given a query garment or retrieving outfits that are suitable for a given user. In this work we address the problem by adding an additional semantic layer based on the style of the proposed dressing. We model style according to two important aspects: the mood and the emotion concealed behind color combination patterns and the appropriateness of the retrieved garments for a given type of social event. To address the former we rely on Shigenobu Kobayashi's color image scale, which associated emotional patterns and moods to color triples. The latter instead is analyzed by extracting garments from images of social events. Overall, we integrate in a state of the art garment recommendation framework a style classifier and an event classifier in order to condition recommendation on a given query.
NeFSAC: Neurally Filtered Minimal Samples
Jul 16, 2022
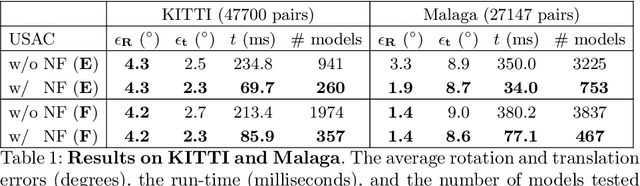

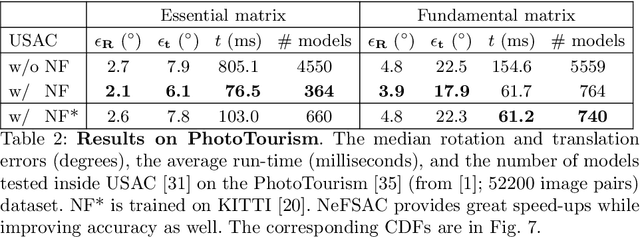
Since RANSAC, a great deal of research has been devoted to improving both its accuracy and run-time. Still, only a few methods aim at recognizing invalid minimal samples early, before the often expensive model estimation and quality calculation are done. To this end, we propose NeFSAC, an efficient algorithm for neural filtering of motion-inconsistent and poorly-conditioned minimal samples. We train NeFSAC to predict the probability of a minimal sample leading to an accurate relative pose, only based on the pixel coordinates of the image correspondences. Our neural filtering model learns typical motion patterns of samples which lead to unstable poses, and regularities in the possible motions to favour well-conditioned and likely-correct samples. The novel lightweight architecture implements the main invariants of minimal samples for pose estimation, and a novel training scheme addresses the problem of extreme class imbalance. NeFSAC can be plugged into any existing RANSAC-based pipeline. We integrate it into USAC and show that it consistently provides strong speed-ups even under extreme train-test domain gaps - for example, the model trained for the autonomous driving scenario works on PhotoTourism too. We tested NeFSAC on more than 100k image pairs from three publicly available real-world datasets and found that it leads to one order of magnitude speed-up, while often finding more accurate results than USAC alone. The source code is available at https://github.com/cavalli1234/NeFSAC.
Learning Low Bending and Low Distortion Manifold Embeddings: Theory and Applications
Aug 22, 2022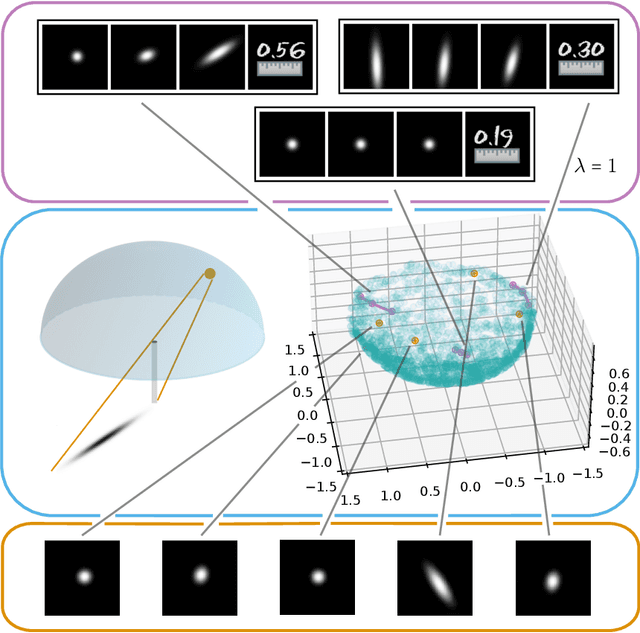
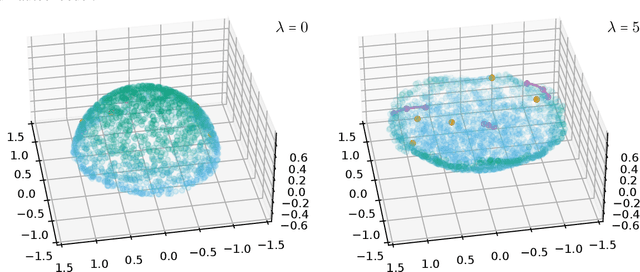
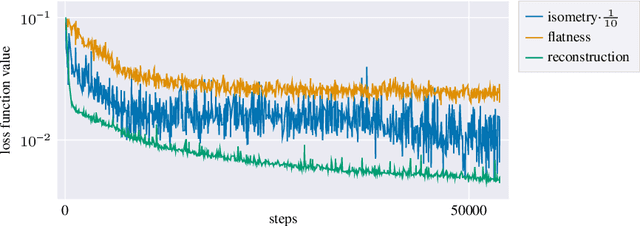
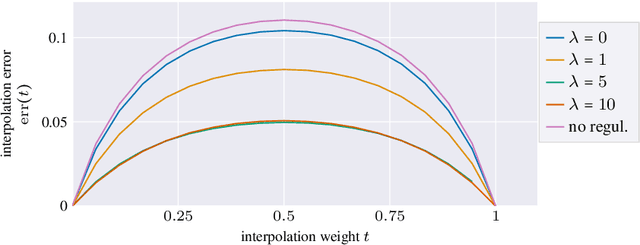
Autoencoders, which consist of an encoder and a decoder, are widely used in machine learning for dimension reduction of high-dimensional data. The encoder embeds the input data manifold into a lower-dimensional latent space, while the decoder represents the inverse map, providing a parametrization of the data manifold by the manifold in latent space. A good regularity and structure of the embedded manifold may substantially simplify further data processing tasks such as cluster analysis or data interpolation. We propose and analyze a novel regularization for learning the encoder component of an autoencoder: a loss functional that prefers isometric, extrinsically flat embeddings and allows to train the encoder on its own. To perform the training it is assumed that for pairs of nearby points on the input manifold their local Riemannian distance and their local Riemannian average can be evaluated. The loss functional is computed via Monte Carlo integration with different sampling strategies for pairs of points on the input manifold. Our main theorem identifies a geometric loss functional of the embedding map as the $\Gamma$-limit of the sampling-dependent loss functionals. Numerical tests, using image data that encodes different explicitly given data manifolds, show that smooth manifold embeddings into latent space are obtained. Due to the promotion of extrinsic flatness, these embeddings are regular enough such that interpolation between not too distant points on the manifold is well approximated by linear interpolation in latent space as one possible postprocessing.
Two-Stage Architectural Fine-Tuning with Neural Architecture Search using Early-Stopping in Image Classification
Feb 17, 2022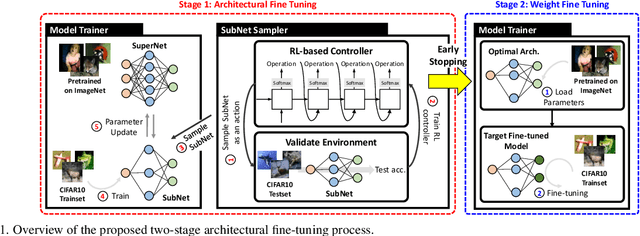

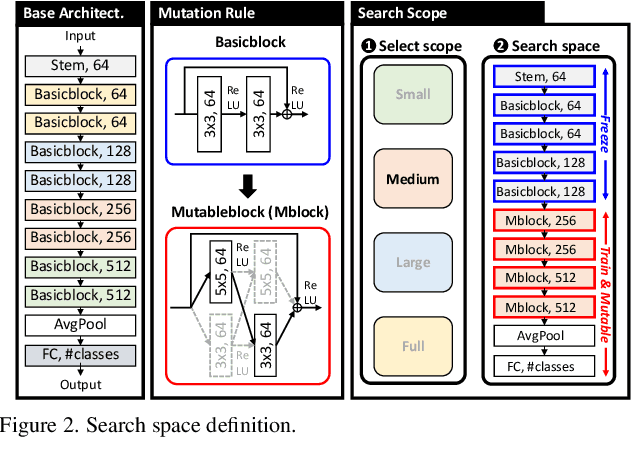
Deep neural networks (NN) perform well in various tasks (e.g., computer vision) because of the convolutional neural networks (CNN). However, the difficulty of gathering quality data in the industry field hinders the practical use of NN. To cope with this issue, the concept of transfer learning (TL) has emerged, which leverages the fine-tuning of NNs trained on large-scale datasets in data-scarce situations. Therefore, this paper suggests a two-stage architectural fine-tuning method for image classification, inspired by the concept of neural architecture search (NAS). One of the main ideas of our proposed method is a mutation with base architectures, which reduces the search cost by using given architectural information. Moreover, an early-stopping is also considered which directly reduces NAS costs. Experimental results verify that our proposed method reduces computational and searching costs by up to 28.2% and 22.3%, compared to existing methods.
Multi-Granularity Distillation Scheme Towards Lightweight Semi-Supervised Semantic Segmentation
Aug 22, 2022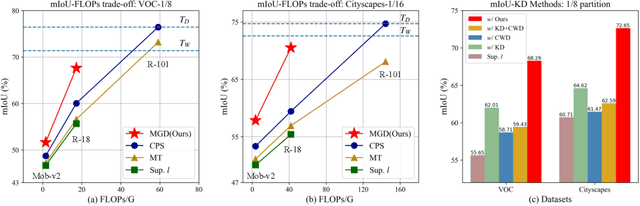
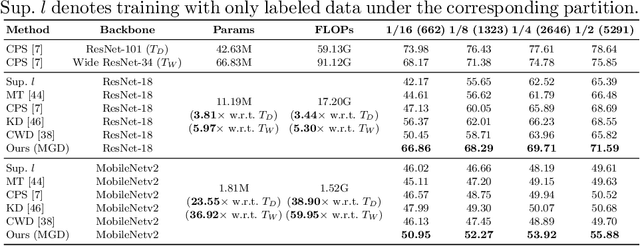
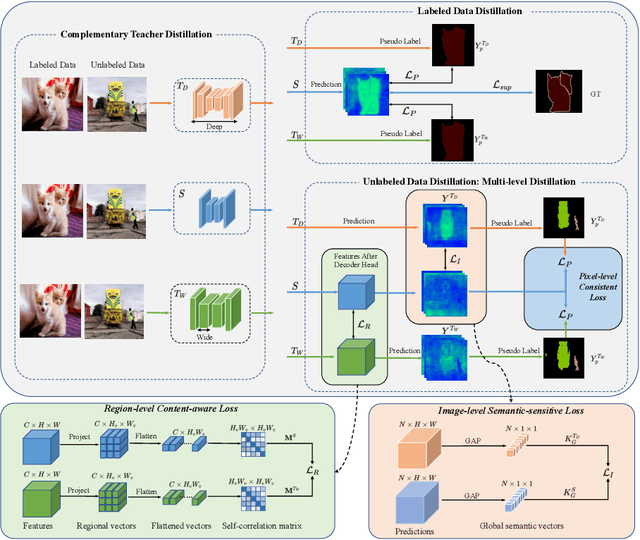
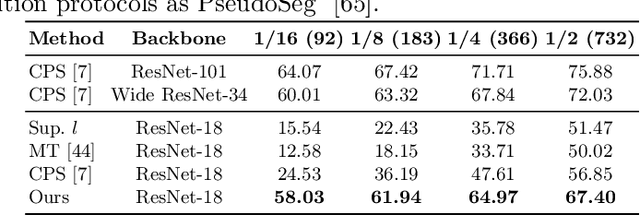
Albeit with varying degrees of progress in the field of Semi-Supervised Semantic Segmentation, most of its recent successes are involved in unwieldy models and the lightweight solution is still not yet explored. We find that existing knowledge distillation techniques pay more attention to pixel-level concepts from labeled data, which fails to take more informative cues within unlabeled data into account. Consequently, we offer the first attempt to provide lightweight SSSS models via a novel multi-granularity distillation (MGD) scheme, where multi-granularity is captured from three aspects: i) complementary teacher structure; ii) labeled-unlabeled data cooperative distillation; iii) hierarchical and multi-levels loss setting. Specifically, MGD is formulated as a labeled-unlabeled data cooperative distillation scheme, which helps to take full advantage of diverse data characteristics that are essential in the semi-supervised setting. Image-level semantic-sensitive loss, region-level content-aware loss, and pixel-level consistency loss are set up to enrich hierarchical distillation abstraction via structurally complementary teachers. Experimental results on PASCAL VOC2012 and Cityscapes reveal that MGD can outperform the competitive approaches by a large margin under diverse partition protocols. For example, the performance of ResNet-18 and MobileNet-v2 backbone is boosted by 11.5% and 4.6% respectively under 1/16 partition protocol on Cityscapes. Although the FLOPs of the model backbone is compressed by 3.4-5.3x (ResNet-18) and 38.7-59.6x (MobileNetv2), the model manages to achieve satisfactory segmentation results.
Mutual Information Divergence: A Unified Metric for Multimodal Generative Models
May 25, 2022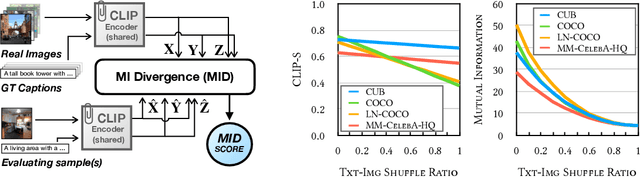
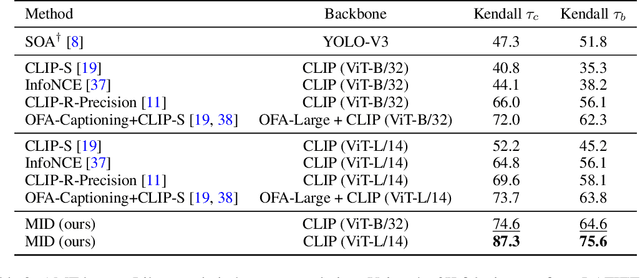
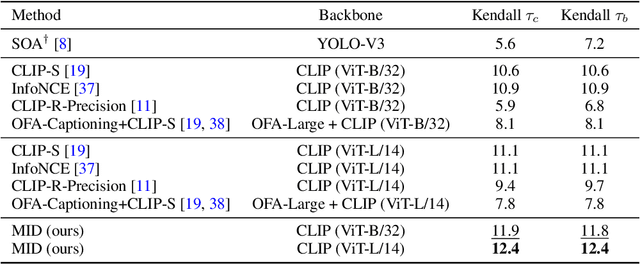
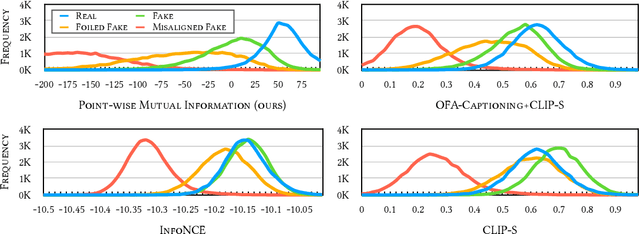
Text-to-image generation and image captioning are recently emerged as a new experimental paradigm to assess machine intelligence. They predict continuous quantity accompanied by their sampling techniques in the generation, making evaluation complicated and intractable to get marginal distributions. Based on a recent trend that multimodal generative evaluations exploit a vison-and-language pre-trained model, we propose the negative Gaussian cross-mutual information using the CLIP features as a unified metric, coined by Mutual Information Divergence (MID). To validate, we extensively compare it with competing metrics using carefully-generated or human-annotated judgments in text-to-image generation and image captioning tasks. The proposed MID significantly outperforms the competitive methods by having consistency across benchmarks, sample parsimony, and robustness toward the exploited CLIP model. We look forward to seeing the underrepresented implications of the Gaussian cross-mutual information in multimodal representation learning and the future works based on this novel proposition.
Prompt-Matched Semantic Segmentation
Aug 22, 2022
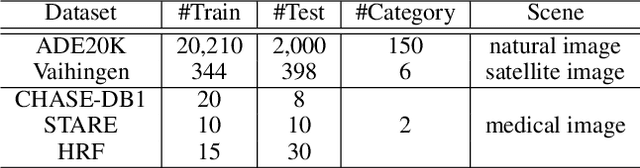
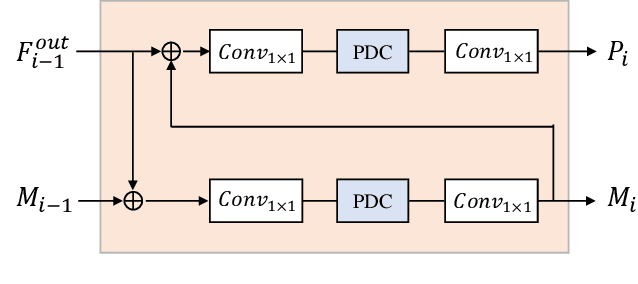

The objective of this work is to explore how to effectively and efficiently adapt pre-trained foundation models to various downstream tasks of image semantic segmentation. Conventional methods usually fine-tuned the whole networks for each specific dataset and it was burdensome to store the massive parameters of these networks. A few recent works attempted to insert some trainable parameters into the frozen network to learn visual prompts for efficient tuning. However, these works significantly modified the original structure of standard modules, making them inoperable on many existing high-speed inference devices, where standard modules and their parameters have been embedded. To facilitate prompt-based semantic segmentation, we propose a novel Inter-Stage Prompt-Matched Framework, which maintains the original structure of the foundation model while generating visual prompts adaptively for task-oriented tuning. Specifically, the pre-trained model is first divided into multiple stages, and their parameters are frozen and shared for all semantic segmentation tasks. A lightweight module termed Semantic-aware Prompt Matcher is then introduced to hierarchically interpolate between two stages to learn reasonable prompts for each specific task under the guidance of interim semantic maps. In this way, we can better stimulate the pre-trained knowledge of the frozen model to learn semantic concepts effectively on downstream datasets. Extensive experiments conducted on five benchmarks show that the proposed method can achieve a promising trade-off between parameter efficiency and performance effectiveness.
Aesthetic Language Guidance Generation of Images Using Attribute Comparison
Aug 09, 2022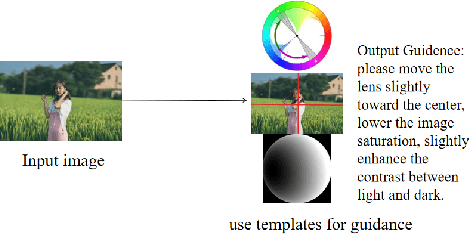
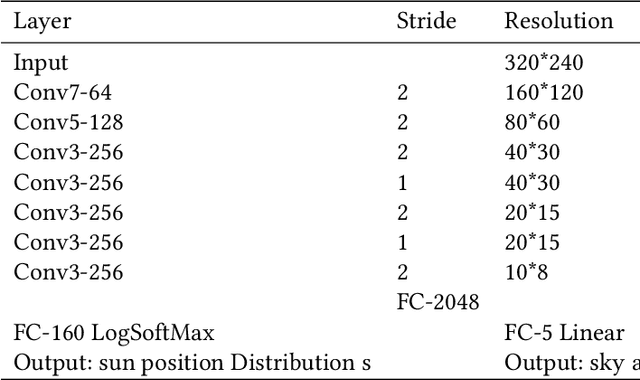

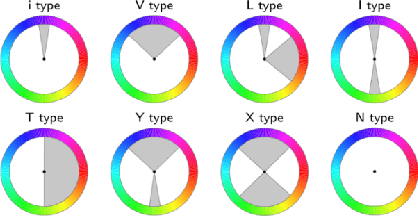
With the vigorous development of mobile photography technology, major mobile phone manufacturers are scrambling to improve the shooting ability of equipments and the photo beautification algorithm of software. However, the improvement of intelligent equipments and algorithms cannot replace human subjective photography technology. In this paper, we propose the aesthetic language guidance of image (ALG). We divide ALG into ALG-T and ALG-I according to whether the guiding rules are based on photography templates or guidance images. Whether it is ALG-T or ALG-I, we guide photography from three attributes of color, lighting and composition of the images. The differences of the three attributes between the input images and the photography templates or the guidance images are described in natural language, which is aesthetic natural language guidance (ALG). Also, because of the differences in lighting and composition between landscape images and portrait images, we divide the input images into landscape images and portrait images. Both ALG-T and ALG-I conduct aesthetic language guidance respectively for the two types of input images (landscape images and portrait images).
Lung nodules segmentation from CT with DeepHealth toolkit
Aug 01, 2022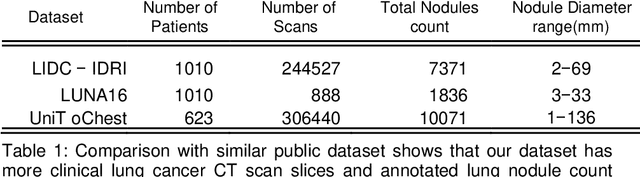
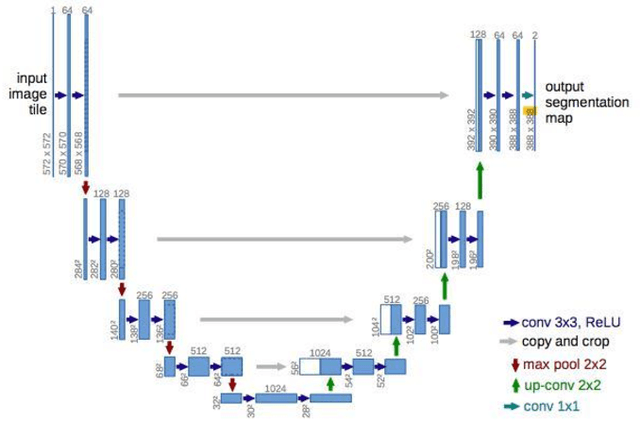

The accurate and consistent border segmentation plays an important role in the tumor volume estimation and its treatment in the field of Medical Image Segmentation. Globally, Lung cancer is one of the leading causes of death and the early detection of lung nodules is essential for the early cancer diagnosis and survival rate of patients. The goal of this study was to demonstrate the feasibility of Deephealth toolkit including PyECVL and PyEDDL libraries to precisely segment lung nodules. Experiments for lung nodules segmentation has been carried out on UniToChest using PyECVL and PyEDDL, for data pre-processing as well as neural network training. The results depict accurate segmentation of lung nodules across a wide diameter range and better accuracy over a traditional detection approach. The datasets and the code used in this paper are publicly available as a baseline reference.