 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Generation of Artificial CT Images using Patch-based Conditional Generative Adversarial Networks
May 19, 2022
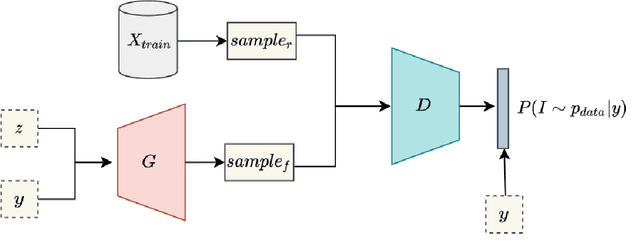
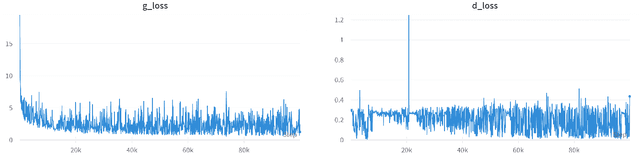
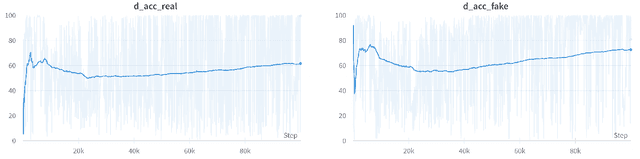
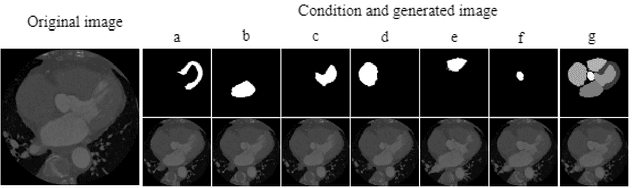
Deep learning has a great potential to alleviate diagnosis and prognosis for various clinical procedures. However, the lack of a sufficient number of medical images is the most common obstacle in conducting image-based analysis using deep learning. Due to the annotations scarcity, semi-supervised techniques in the automatic medical analysis are getting high attention. Artificial data augmentation and generation techniques such as generative adversarial networks (GANs) may help overcome this obstacle. In this work, we present an image generation approach that uses generative adversarial networks with a conditional discriminator where segmentation masks are used as conditions for image generation. We validate the feasibility of GAN-enhanced medical image generation on whole heart computed tomography (CT) images and its seven substructures, namely: left ventricle, right ventricle, left atrium, right atrium, myocardium, pulmonary arteries, and aorta. Obtained results demonstrate the suitability of the proposed adversarial approach for the accurate generation of high-quality CT images. The presented method shows great potential to facilitate further research in the domain of artificial medical image generation.
DeepRecon: Joint 2D Cardiac Segmentation and 3D Volume Reconstruction via A Structure-Specific Generative Method
Jun 14, 2022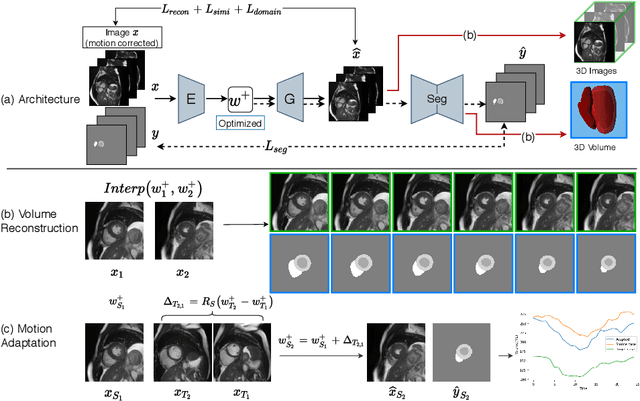
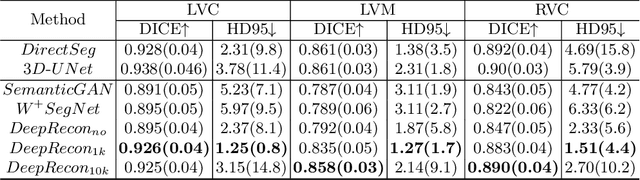
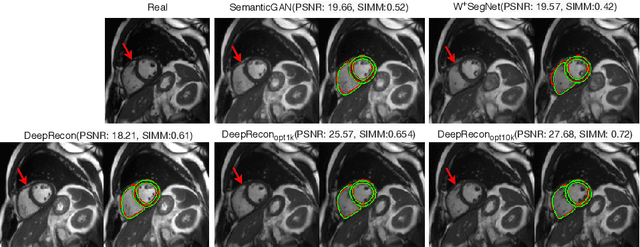
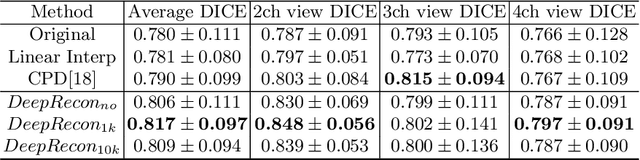
Joint 2D cardiac segmentation and 3D volume reconstruction are fundamental to building statistical cardiac anatomy models and understanding functional mechanisms from motion patterns. However, due to the low through-plane resolution of cine MR and high inter-subject variance, accurately segmenting cardiac images and reconstructing the 3D volume are challenging. In this study, we propose an end-to-end latent-space-based framework, DeepRecon, that generates multiple clinically essential outcomes, including accurate image segmentation, synthetic high-resolution 3D image, and 3D reconstructed volume. Our method identifies the optimal latent representation of the cine image that contains accurate semantic information for cardiac structures. In particular, our model jointly generates synthetic images with accurate semantic information and segmentation of the cardiac structures using the optimal latent representation. We further explore downstream applications of 3D shape reconstruction and 4D motion pattern adaptation by the different latent-space manipulation strategies.The simultaneously generated high-resolution images present a high interpretable value to assess the cardiac shape and motion.Experimental results demonstrate the effectiveness of our approach on multiple fronts including 2D segmentation, 3D reconstruction, downstream 4D motion pattern adaption performance.
Realistic Image Synthesis with Configurable 3D Scene Layouts
Aug 24, 2021
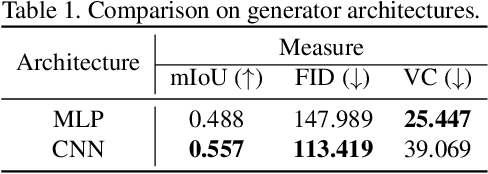
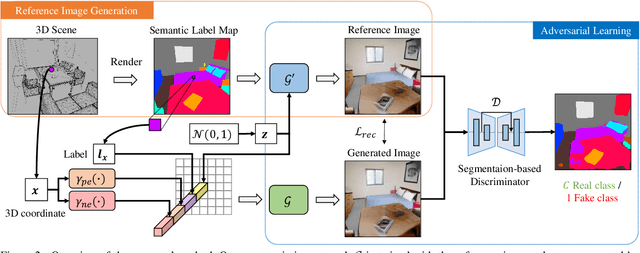
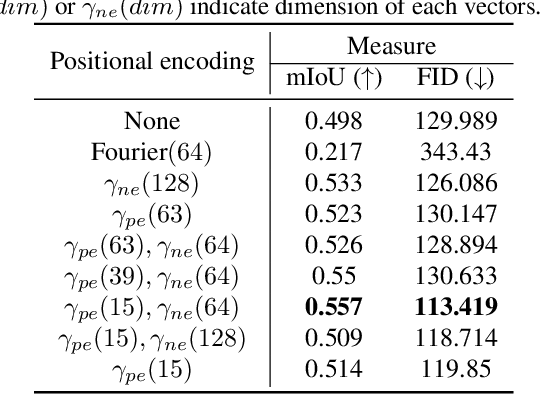
Recent conditional image synthesis approaches provide high-quality synthesized images. However, it is still challenging to accurately adjust image contents such as the positions and orientations of objects, and synthesized images often have geometrically invalid contents. To provide users with rich controllability on synthesized images in the aspect of 3D geometry, we propose a novel approach to realistic-looking image synthesis based on a configurable 3D scene layout. Our approach takes a 3D scene with semantic class labels as input and trains a 3D scene painting network that synthesizes color values for the input 3D scene. With the trained painting network, realistic-looking images for the input 3D scene can be rendered and manipulated. To train the painting network without 3D color supervision, we exploit an off-the-shelf 2D semantic image synthesis method. In experiments, we show that our approach produces images with geometrically correct structures and supports geometric manipulation such as the change of the viewpoint and object poses as well as manipulation of the painting style.
Detection and Localization of Multiple Image Splicing Using MobileNet V1
Aug 22, 2021
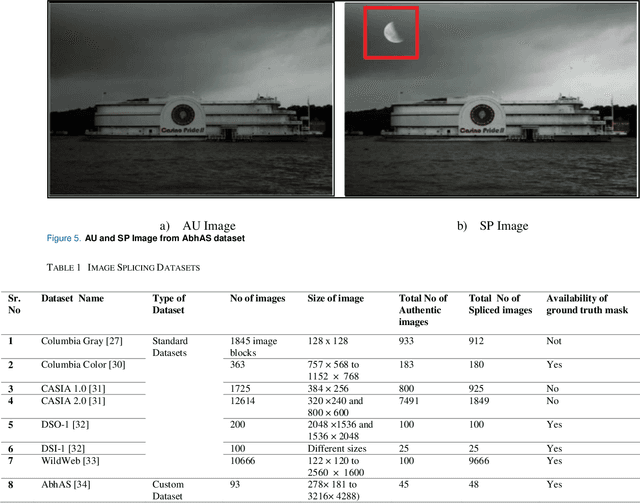


In modern society, digital images have become a prominent source of information and medium of communication. They can, however, be simply altered using freely available image editing software. Two or more images are combined to generate a new image that can transmit information across social media platforms to influence the people in the society. This information may have both positive and negative consequences. Hence there is a need to develop a technique that will detect and locates a multiple image splicing forgery in an image. This research work proposes multiple image splicing forgery detection using Mask R-CNN, with a backbone as a MobileNet V1. It also calculates the percentage score of a forged region of multiple spliced images. The comparative analysis of the proposed work with the variants of ResNet is performed. The proposed model is trained and tested using our MISD (Multiple Image Splicing Dataset), and it is observed that the proposed model outperforms the variants of ResNet models (ResNet 51,101 and 151).
Forensic License Plate Recognition with Compression-Informed Transformers
Jul 29, 2022
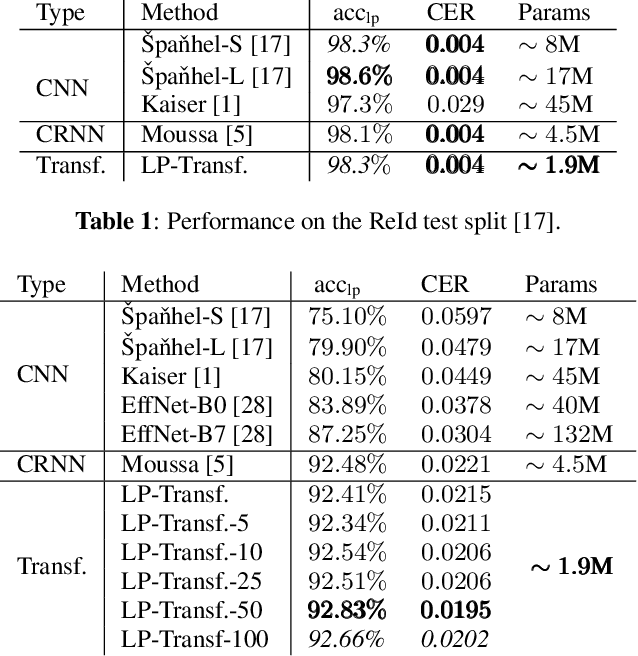

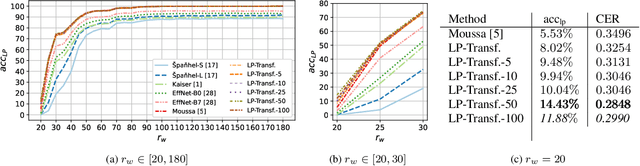
Forensic license plate recognition (FLPR) remains an open challenge in legal contexts such as criminal investigations, where unreadable license plates (LPs) need to be deciphered from highly compressed and/or low resolution footage, e.g., from surveillance cameras. In this work, we propose a side-informed Transformer architecture that embeds knowledge on the input compression level to improve recognition under strong compression. We show the effectiveness of Transformers for license plate recognition (LPR) on a low-quality real-world dataset. We also provide a synthetic dataset that includes strongly degraded, illegible LP images and analyze the impact of knowledge embedding on it. The network outperforms existing FLPR methods and standard state-of-the art image recognition models while requiring less parameters. For the severest degraded images, we can improve recognition by up to 8.9 percent points.
Fast Auto-Differentiable Digitally Reconstructed Radiographs for Solving Inverse Problems in Intraoperative Imaging
Aug 26, 2022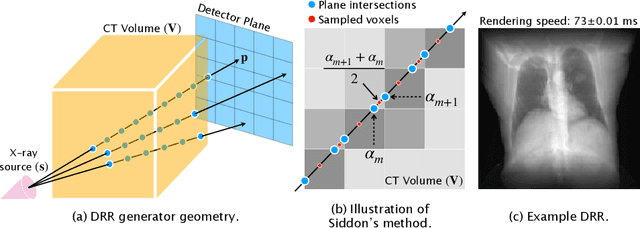
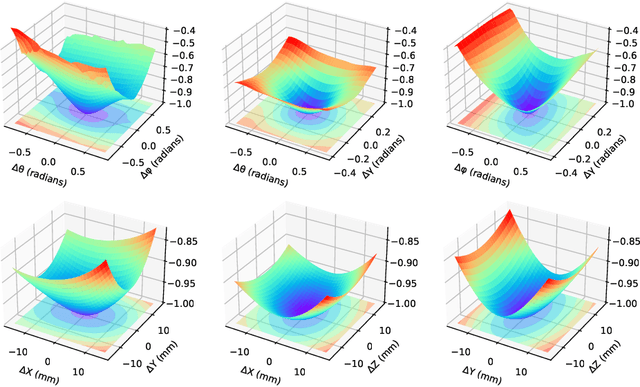
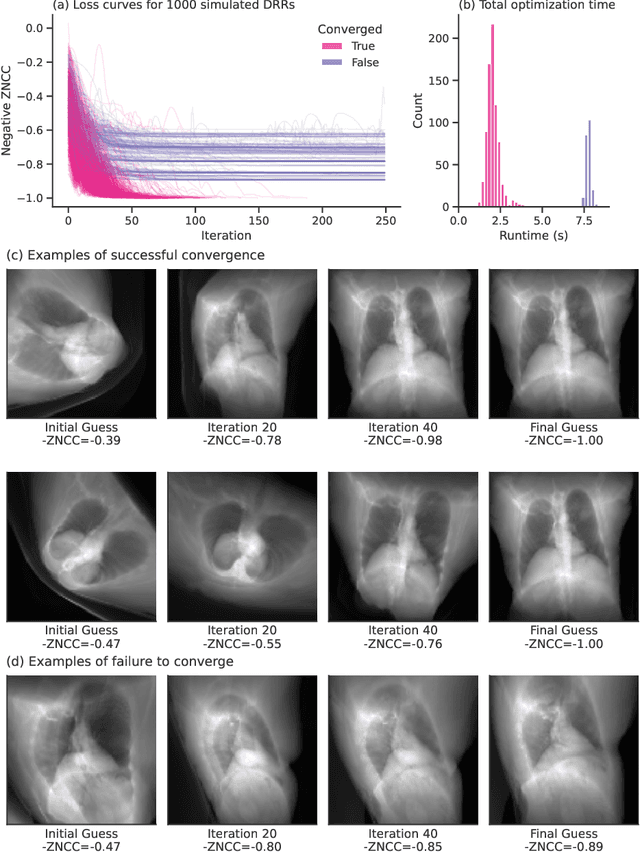
The use of digitally reconstructed radiographs (DRRs) to solve inverse problems such as slice-to-volume registration and 3D reconstruction is well-studied in preoperative settings. In intraoperative imaging, the utility of DRRs is limited by the challenges in generating them in real-time and supporting optimization procedures that rely on repeated DRR synthesis. While immense progress has been made in accelerating the generation of DRRs through algorithmic refinements and GPU implementations, DRR-based optimization remains slow because most DRR generators do not offer a straightforward way to obtain gradients with respect to the imaging parameters. To make DRRs interoperable with gradient-based optimization and deep learning frameworks, we have reformulated Siddon's method, the most popular ray-tracing algorithm used in DRR generation, as a series of vectorized tensor operations. We implemented this vectorized version of Siddon's method in PyTorch, taking advantage of the library's strong automatic differentiation engine to make this DRR generator fully differentiable with respect to its parameters. Additionally, using GPU-accelerated tensor computation enables our vectorized implementation to achieve rendering speeds equivalent to state-of-the-art DRR generators implemented in CUDA and C++. We illustrate the resulting method in the context of slice-to-volume registration. Moreover, our simulations suggest that the loss landscapes for the slice-to-volume registration problem are convex in the neighborhood of the optimal solution, and gradient-based registration promises a much faster solution than prevailing gradient-free optimization strategies. The proposed DRR generator enables fast computer vision algorithms to support image guidance in minimally invasive procedures. Our implementation is publically available at https://github.com/v715/DiffDRR.
Two-Stage Architectural Fine-Tuning with Neural Architecture Search using Early-Stopping in Image Classification
Feb 18, 2022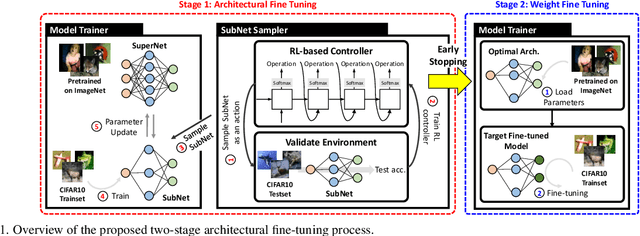

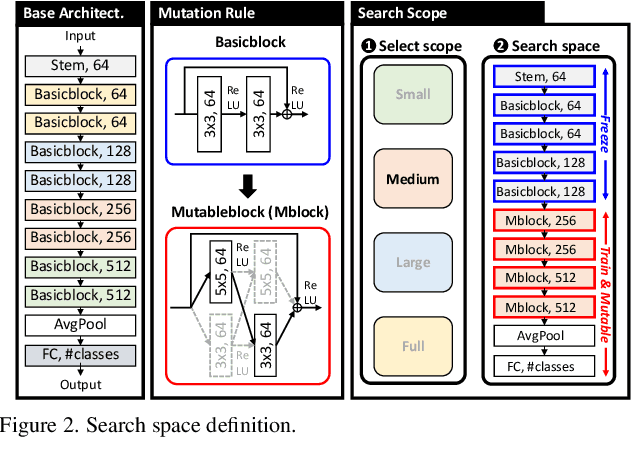
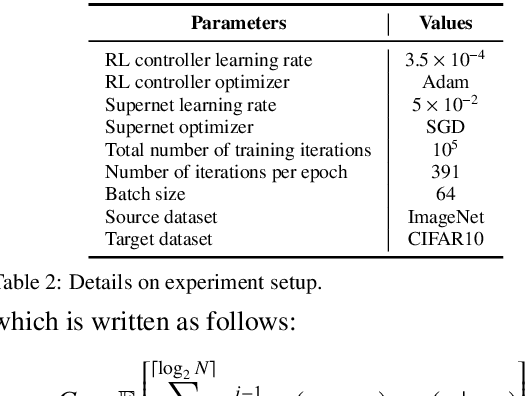
Deep neural networks (NN) perform well in various tasks (e.g., computer vision) because of the convolutional neural networks (CNN). However, the difficulty of gathering quality data in the industry field hinders the practical use of NN. To cope with this issue, the concept of transfer learning (TL) has emerged, which leverages the fine-tuning of NNs trained on large-scale datasets in data-scarce situations. Therefore, this paper suggests a two-stage architectural fine-tuning method for image classification, inspired by the concept of neural architecture search (NAS). One of the main ideas of our proposed method is a mutation with base architectures, which reduces the search cost by using given architectural information. Moreover, an early-stopping is also considered which directly reduces NAS costs. Experimental results verify that our proposed method reduces computational and searching costs by up to 28.2% and 22.3%, compared to existing methods.
Online Pole Segmentation on Range Images for Long-term LiDAR Localization in Urban Environments
Aug 15, 2022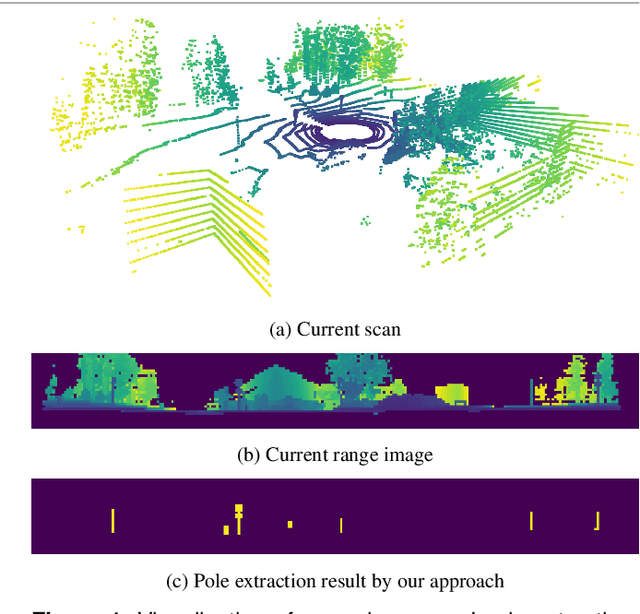
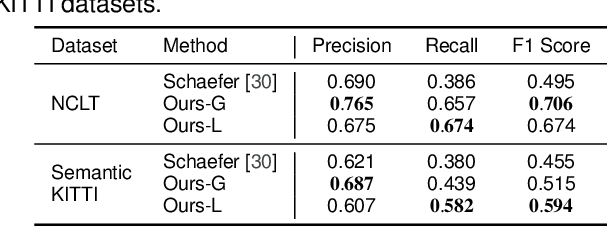
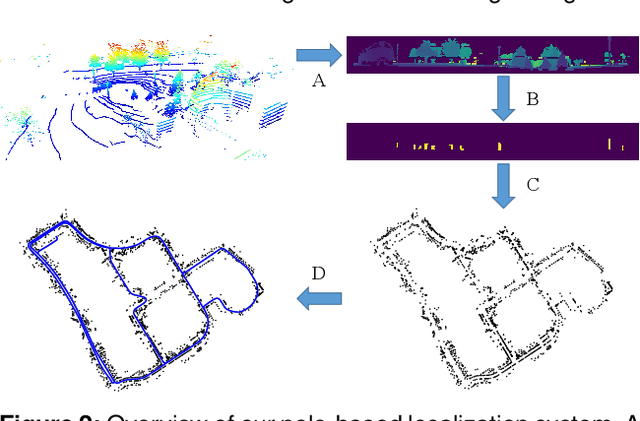
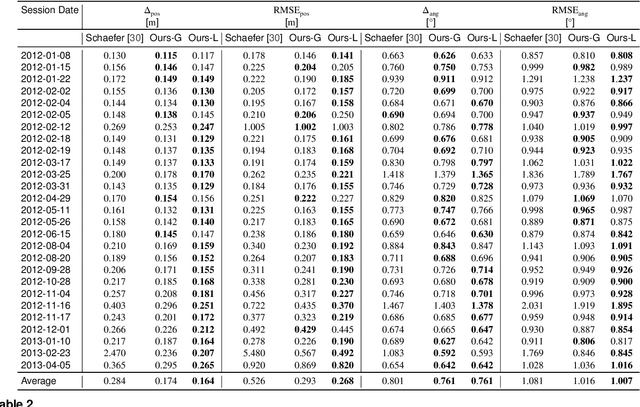
Robust and accurate localization is a basic requirement for mobile autonomous systems. Pole-like objects, such as traffic signs, poles, and lamps are frequently used landmarks for localization in urban environments due to their local distinctiveness and long-term stability. In this paper, we present a novel, accurate, and fast pole extraction approach based on geometric features that runs online and has little computational demands. Our method performs all computations directly on range images generated from 3D LiDAR scans, which avoids processing 3D point clouds explicitly and enables fast pole extraction for each scan. We further use the extracted poles as pseudo labels to train a deep neural network for online range image-based pole segmentation. We test both our geometric and learning-based pole extraction methods for localization on different datasets with different LiDAR scanners, routes, and seasonal changes. The experimental results show that our methods outperform other state-of-the-art approaches. Moreover, boosted with pseudo pole labels extracted from multiple datasets, our learning-based method can run across different datasets and achieve even better localization results compared to our geometry-based method. We released our pole datasets to the public for evaluating the performance of pole extractors, as well as the implementation of our approach.
QU-net++: Image Quality Detection Framework for Segmentation of 3D Medical Image Stacks
Oct 27, 2021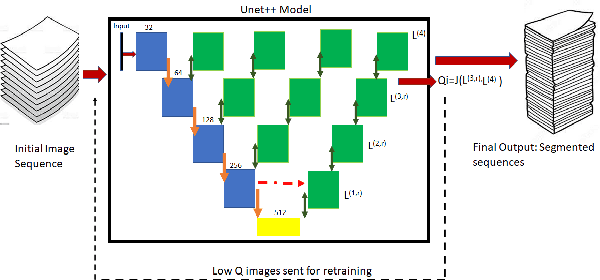
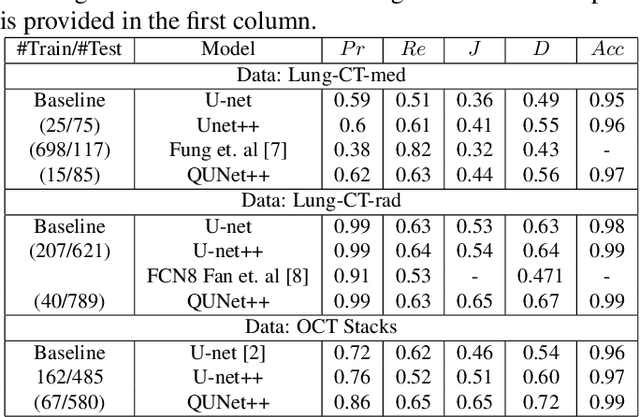
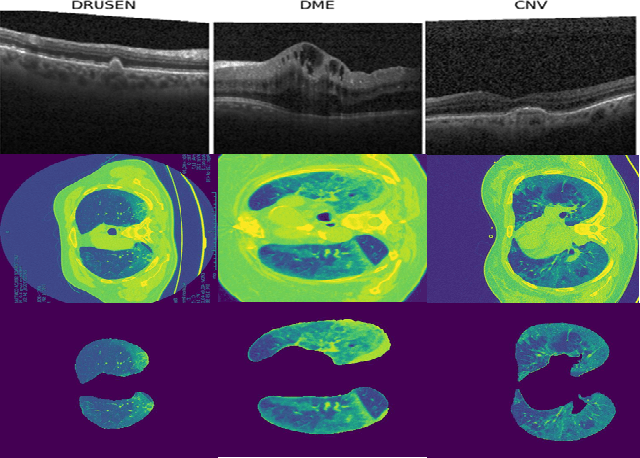
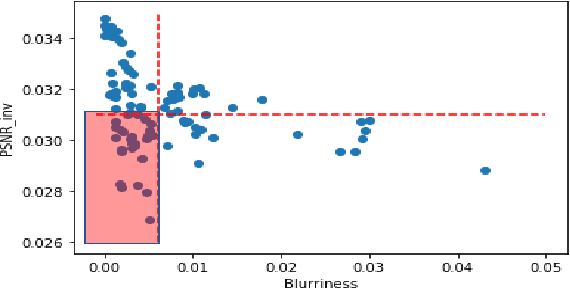
Automated segmentation of pathological regions of interest has been shown to aid prognosis and follow up treatment. However, accurate pathological segmentations require high quality of annotated data that can be both cost and time intensive to generate. In this work, we propose an automated two-step method that evaluates the quality of medical images from 3D image stacks using a U-net++ model, such that images that can aid further training of the U-net++ model can be detected based on the disagreement in segmentations produced from the final two layers. Images thus detected can then be used to further fine tune the U-net++ model for semantic segmentation. The proposed QU-net++ model isolates around 10\% of images per 3D stack and can scale across imaging modalities to segment cysts in OCT images and ground glass opacity in Lung CT images with Dice cores in the range 0.56-0.72. Thus, the proposed method can be applied for multi-modal binary segmentation of pathology.
Instance-weighted Central Similarity for Multi-label Image Retrieval
Aug 28, 2021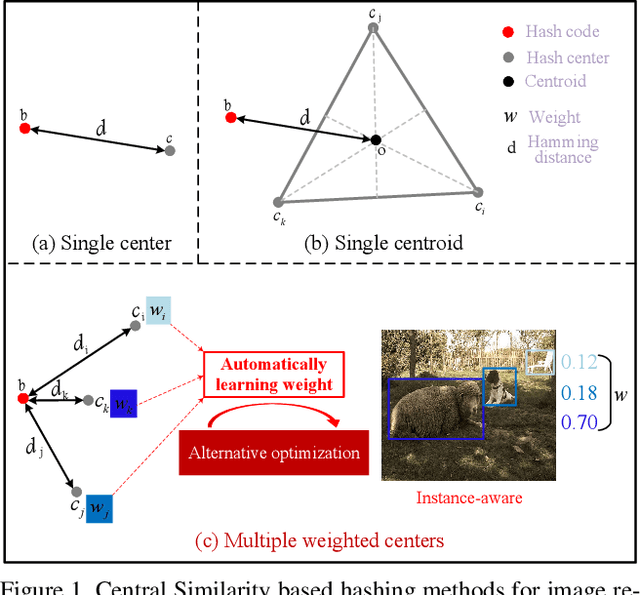

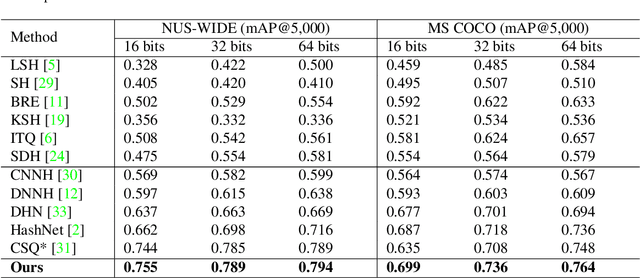
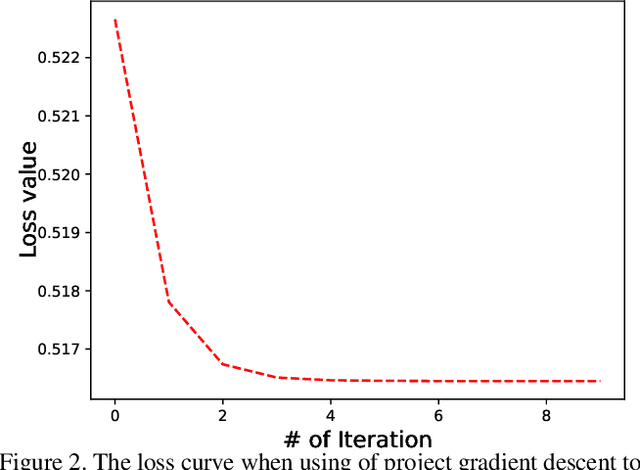
Deep hashing has been widely applied to large-scale image retrieval by encoding high-dimensional data points into binary codes for efficient retrieval. Compared with pairwise/triplet similarity based hash learning, central similarity based hashing can more efficiently capture the global data distribution. For multi-label image retrieval, however, previous methods only use multiple hash centers with equal weights to generate one centroid as the learning target, which ignores the relationship between the weights of hash centers and the proportion of instance regions in the image. To address the above issue, we propose a two-step alternative optimization approach, Instance-weighted Central Similarity (ICS), to automatically learn the center weight corresponding to a hash code. Firstly, we apply the maximum entropy regularizer to prevent one hash center from dominating the loss function, and compute the center weights via projection gradient descent. Secondly, we update neural network parameters by standard back-propagation with fixed center weights. More importantly, the learned center weights can well reflect the proportion of foreground instances in the image. Our method achieves the state-of-the-art performance on the image retrieval benchmarks, and especially improves the mAP by 1.6%-6.4% on the MS COCO dataset.