 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Geometry Attention Transformer with Position-aware LSTMs for Image Captioning
Oct 01, 2021
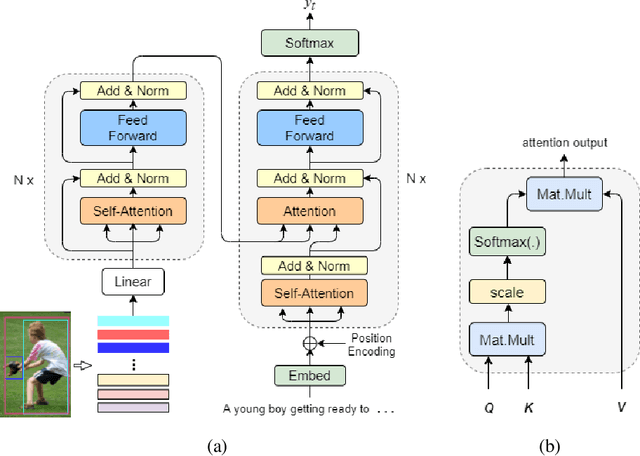
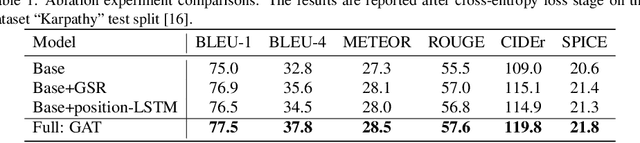
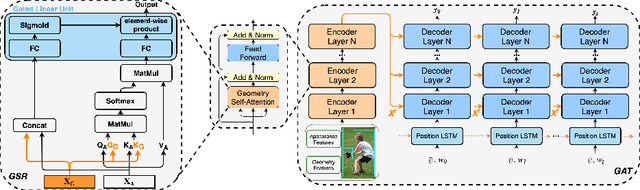
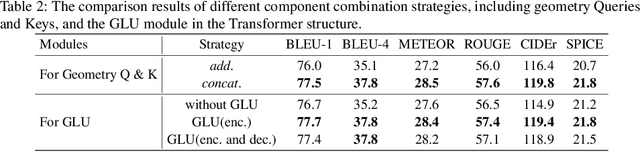
In recent years, transformer structures have been widely applied in image captioning with impressive performance. For good captioning results, the geometry and position relations of different visual objects are often thought of as crucial information. Aiming to further promote image captioning by transformers, this paper proposes an improved Geometry Attention Transformer (GAT) model. In order to further leverage geometric information, two novel geometry-aware architectures are designed respectively for the encoder and decoder in our GAT. Besides, this model includes the two work modules: 1) a geometry gate-controlled self-attention refiner, for explicitly incorporating relative spatial information into image region representations in encoding steps, and 2) a group of position-LSTMs, for precisely informing the decoder of relative word position in generating caption texts. The experiment comparisons on the datasets MS COCO and Flickr30K show that our GAT is efficient, and it could often outperform current state-of-the-art image captioning models.
Infrared Image Super-Resolution via Heterogeneous Convolutional WGAN
Sep 02, 2021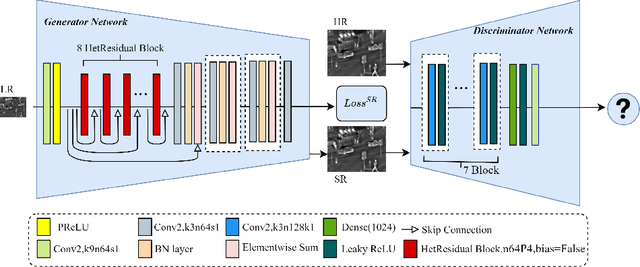
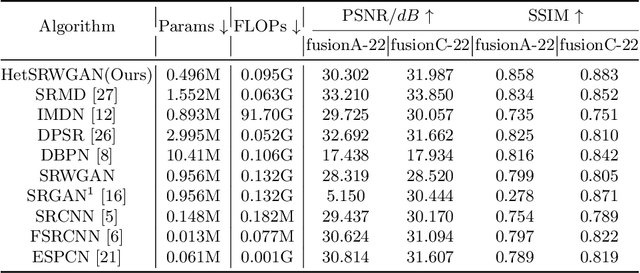
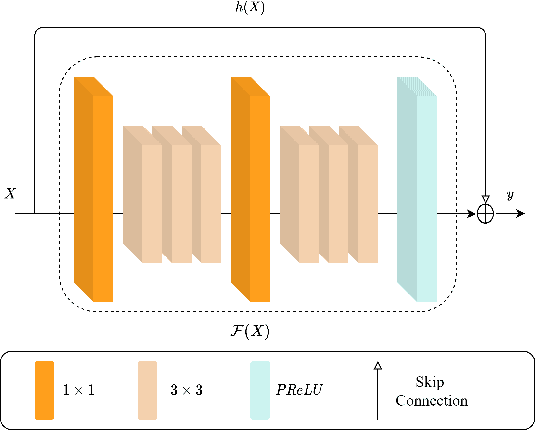
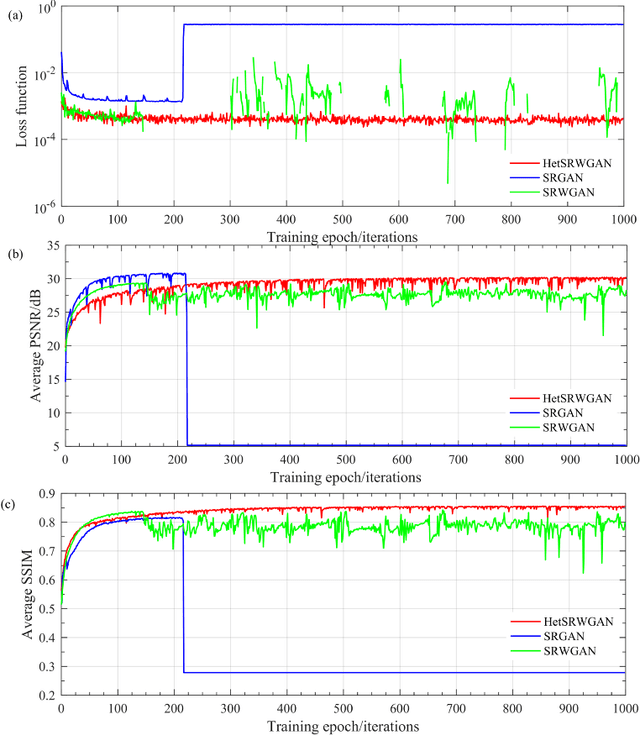
Image super-resolution is important in many fields, such as surveillance and remote sensing. However, infrared (IR) images normally have low resolution since the optical equipment is relatively expensive. Recently, deep learning methods have dominated image super-resolution and achieved remarkable performance on visible images; however, IR images have received less attention. IR images have fewer patterns, and hence, it is difficult for deep neural networks (DNNs) to learn diverse features from IR images. In this paper, we present a framework that employs heterogeneous convolution and adversarial training, namely, heterogeneous kernel-based super-resolution Wasserstein GAN (HetSRWGAN), for IR image super-resolution. The HetSRWGAN algorithm is a lightweight GAN architecture that applies a plug-and-play heterogeneous kernel-based residual block. Moreover, a novel loss function that employs image gradients is adopted, which can be applied to an arbitrary model. The proposed HetSRWGAN achieves consistently better performance in both qualitative and quantitative evaluations. According to the experimental results, the whole training process is more stable.
UNetFormer: A Unified Vision Transformer Model and Pre-Training Framework for 3D Medical Image Segmentation
Apr 05, 2022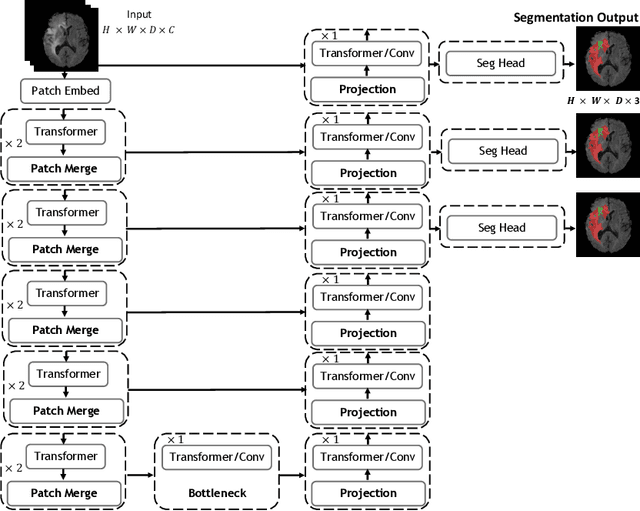
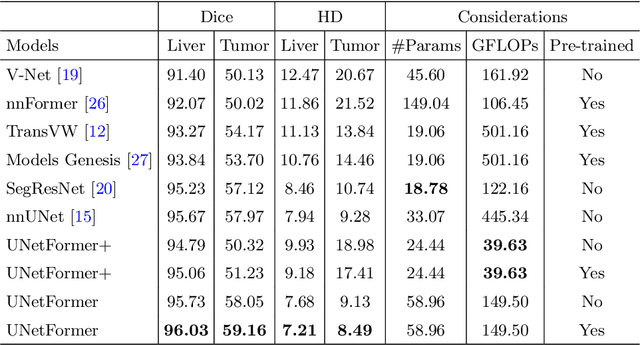
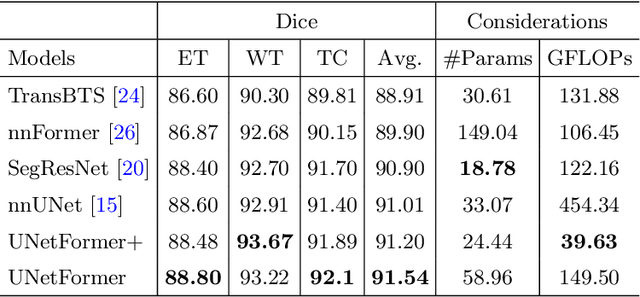
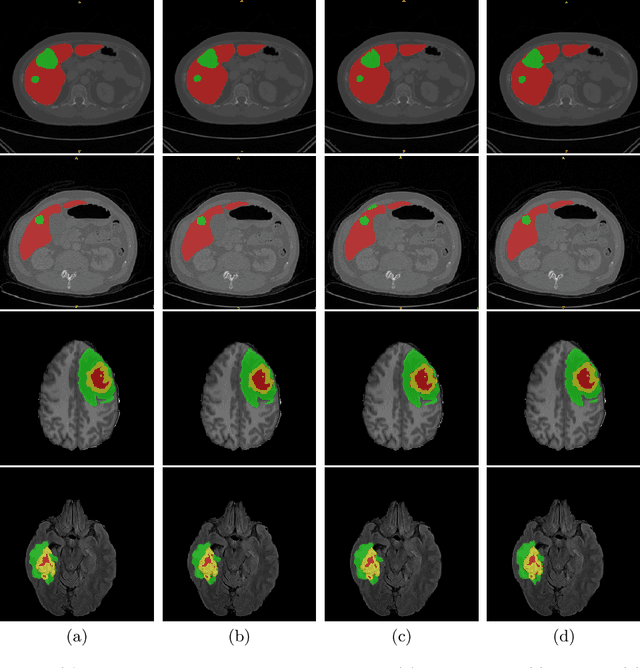
Vision Transformers (ViT)s have recently become popular due to their outstanding modeling capabilities, in particular for capturing long-range information, and scalability to dataset and model sizes which has led to state-of-the-art performance in various computer vision and medical image analysis tasks. In this work, we introduce a unified framework consisting of two architectures, dubbed UNetFormer, with a 3D Swin Transformer-based encoder and Convolutional Neural Network (CNN) and transformer-based decoders. In the proposed model, the encoder is linked to the decoder via skip connections at five different resolutions with deep supervision. The design of proposed architecture allows for meeting a wide range of trade-off requirements between accuracy and computational cost. In addition, we present a methodology for self-supervised pre-training of the encoder backbone via learning to predict randomly masked volumetric tokens using contextual information of visible tokens. We pre-train our framework on a cohort of $5050$ CT images, gathered from publicly available CT datasets, and present a systematic investigation of various components such as masking ratio and patch size that affect the representation learning capability and performance of downstream tasks. We validate the effectiveness of our pre-training approach by fine-tuning and testing our model on liver and liver tumor segmentation task using the Medical Segmentation Decathlon (MSD) dataset and achieve state-of-the-art performance in terms of various segmentation metrics. To demonstrate its generalizability, we train and test the model on BraTS 21 dataset for brain tumor segmentation using MRI images and outperform other methods in terms of Dice score. Code: https://github.com/Project-MONAI/research-contributions
Fundamentals of Task-Agnostic Data Valuation
Aug 25, 2022
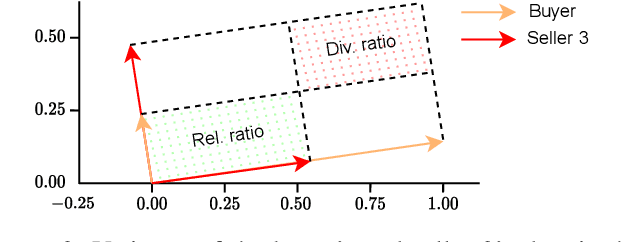
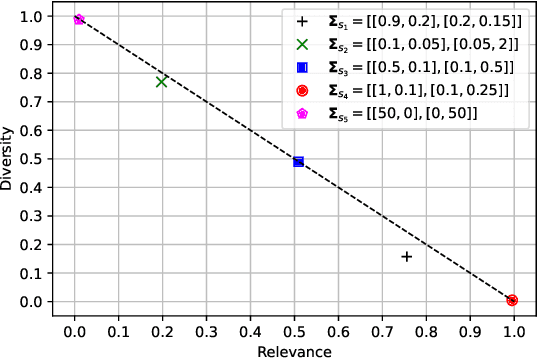
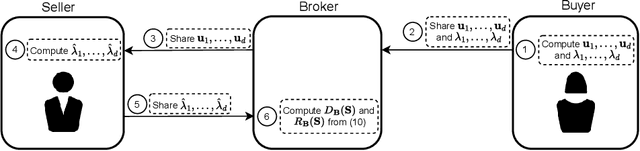
We study valuing the data of a data owner/seller for a data seeker/buyer. Data valuation is often carried out for a specific task assuming a particular utility metric, such as test accuracy on a validation set, that may not exist in practice. In this work, we focus on task-agnostic data valuation without any validation requirements. The data buyer has access to a limited amount of data (which could be publicly available) and seeks more data samples from a data seller. We formulate the problem as estimating the differences in the statistical properties of the data at the seller with respect to the baseline data available at the buyer. We capture these statistical differences through second moment by measuring diversity and relevance of the seller's data for the buyer; we estimate these measures through queries to the seller without requesting raw data. We design the queries with the proposed approach so that the seller is blind to the buyer's raw data and has no knowledge to fabricate responses to queries to obtain a desired outcome of the diversity and relevance trade-off.We will show through extensive experiments on real tabular and image datasets that the proposed estimates capture the diversity and relevance of the seller's data for the buyer.
GraphTTA: Test Time Adaptation on Graph Neural Networks
Aug 19, 2022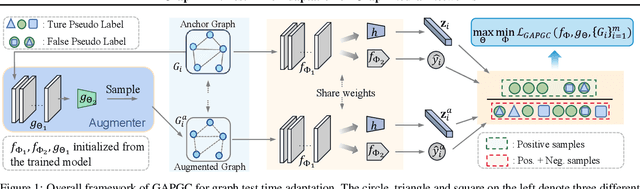
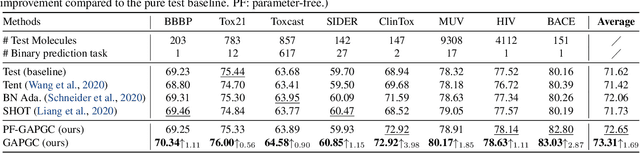
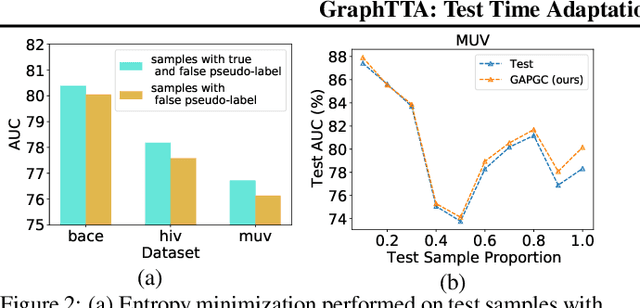

Recently, test time adaptation (TTA) has attracted increasing attention due to its power of handling the distribution shift issue in the real world. Unlike what has been developed for convolutional neural networks (CNNs) for image data, TTA is less explored for Graph Neural Networks (GNNs). There is still a lack of efficient algorithms tailored for graphs with irregular structures. In this paper, we present a novel test time adaptation strategy named Graph Adversarial Pseudo Group Contrast (GAPGC), for graph neural networks TTA, to better adapt to the Out Of Distribution (OOD) test data. Specifically, GAPGC employs a contrastive learning variant as a self-supervised task during TTA, equipped with Adversarial Learnable Augmenter and Group Pseudo-Positive Samples to enhance the relevance between the self-supervised task and the main task, boosting the performance of the main task. Furthermore, we provide theoretical evidence that GAPGC can extract minimal sufficient information for the main task from information theory perspective. Extensive experiments on molecular scaffold OOD dataset demonstrated that the proposed approach achieves state-of-the-art performance on GNNs.
FCSN: Global Context Aware Segmentation by Learning the Fourier Coefficients of Objects in Medical Images
Jul 29, 2022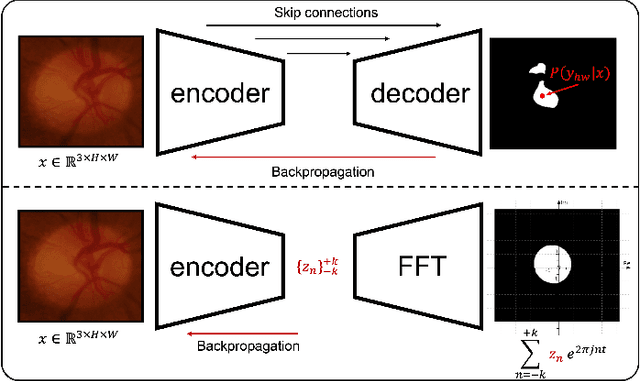
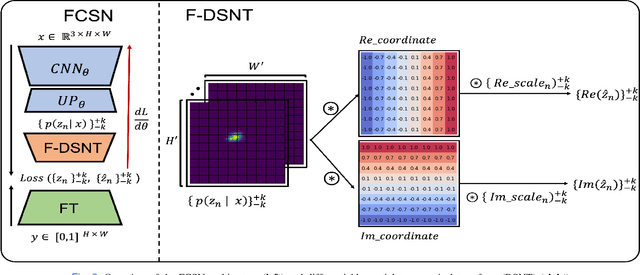

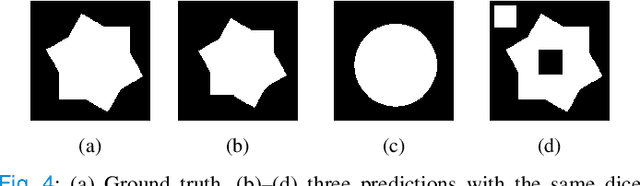
The encoder-decoder model is a commonly used Deep Neural Network (DNN) model for medical image segmentation. Conventional encoder-decoder models make pixel-wise predictions focusing heavily on local patterns around the pixel. This makes it challenging to give segmentation that preserves the object's shape and topology, which often requires an understanding of the global context of the object. In this work, we propose a Fourier Coefficient Segmentation Network~(FCSN) -- a novel DNN-based model that segments an object by learning the complex Fourier coefficients of the object's masks. The Fourier coefficients are calculated by integrating over the whole contour. Therefore, for our model to make a precise estimation of the coefficients, the model is motivated to incorporate the global context of the object, leading to a more accurate segmentation of the object's shape. This global context awareness also makes our model robust to unseen local perturbations during inference, such as additive noise or motion blur that are prevalent in medical images. When FCSN is compared with other state-of-the-art models (UNet+, DeepLabV3+, UNETR) on 3 medical image segmentation tasks (ISIC\_2018, RIM\_CUP, RIM\_DISC), FCSN attains significantly lower Hausdorff scores of 19.14 (6\%), 17.42 (6\%), and 9.16 (14\%) on the 3 tasks, respectively. Moreover, FCSN is lightweight by discarding the decoder module, which incurs significant computational overhead. FCSN only requires 22.2M parameters, 82M and 10M fewer parameters than UNETR and DeepLabV3+. FCSN attains inference and training speeds of 1.6ms/img and 6.3ms/img, that is 8$\times$ and 3$\times$ faster than UNet and UNETR.
Topological structure of complex predictions
Aug 06, 2022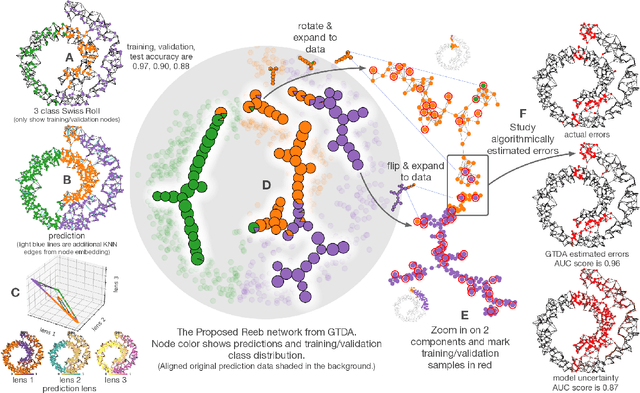

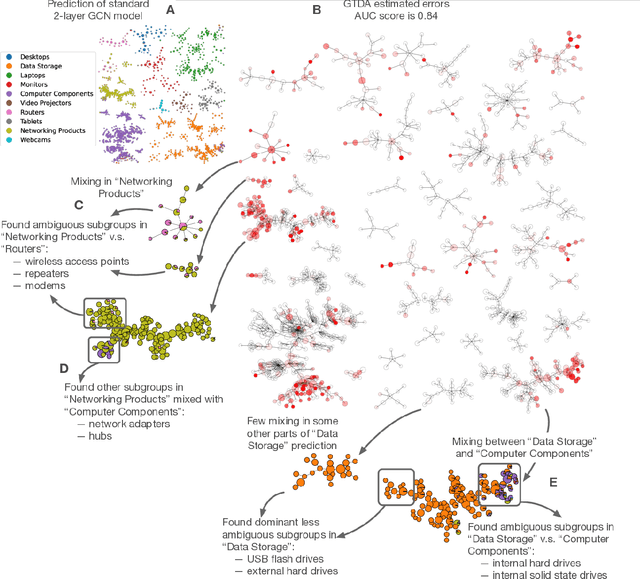
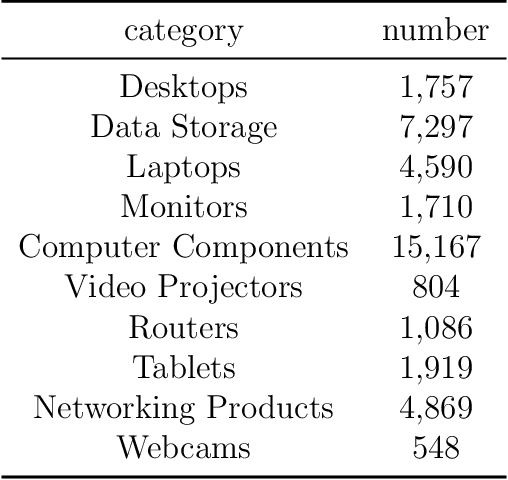
Complex prediction models such as deep learning are the output from fitting machine learning, neural networks, or AI models to a set of training data. These are now standard tools in science. A key challenge with the current generation of models is that they are highly parameterized, which makes describing and interpreting the prediction strategies difficult. We use topological data analysis to transform these complex prediction models into pictures representing a topological view. The result is a map of the predictions that enables inspection. The methods scale up to large datasets across different domains and enable us to detect labeling errors in training data, understand generalization in image classification, and inspect predictions of likely pathogenic mutations in the BRCA1 gene.
Mixed Transformer U-Net For Medical Image Segmentation
Nov 11, 2021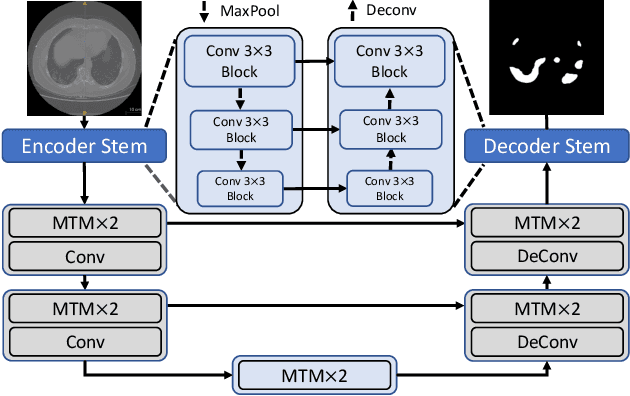

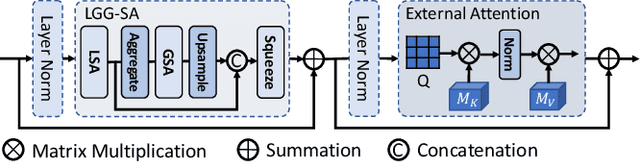
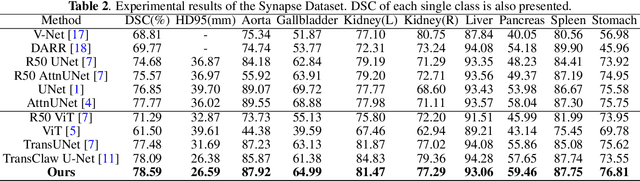
Though U-Net has achieved tremendous success in medical image segmentation tasks, it lacks the ability to explicitly model long-range dependencies. Therefore, Vision Transformers have emerged as alternative segmentation structures recently, for their innate ability of capturing long-range correlations through Self-Attention (SA). However, Transformers usually rely on large-scale pre-training and have high computational complexity. Furthermore, SA can only model self-affinities within a single sample, ignoring the potential correlations of the overall dataset. To address these problems, we propose a novel Transformer module named Mixed Transformer Module (MTM) for simultaneous inter- and intra- affinities learning. MTM first calculates self-affinities efficiently through our well-designed Local-Global Gaussian-Weighted Self-Attention (LGG-SA). Then, it mines inter-connections between data samples through External Attention (EA). By using MTM, we construct a U-shaped model named Mixed Transformer U-Net (MT-UNet) for accurate medical image segmentation. We test our method on two different public datasets, and the experimental results show that the proposed method achieves better performance over other state-of-the-art methods. The code is available at: https://github.com/Dootmaan/MT-UNet.
Unsupervised Domain Adaptation for Semantic Image Segmentation: a Comprehensive Survey
Dec 06, 2021
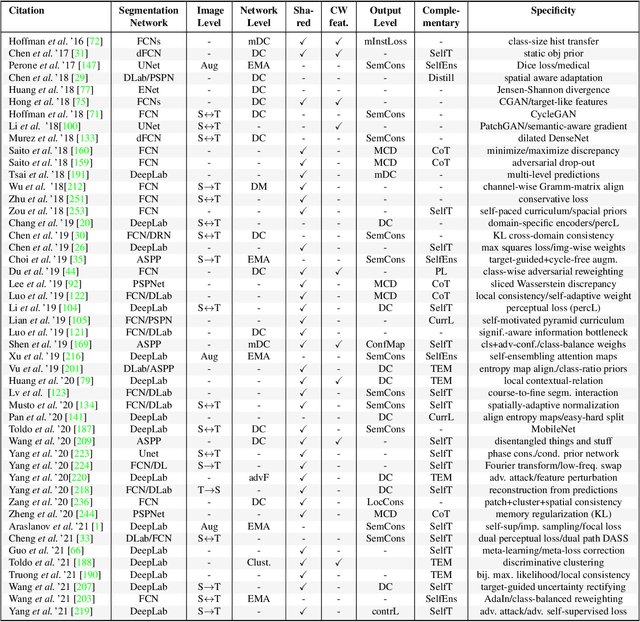
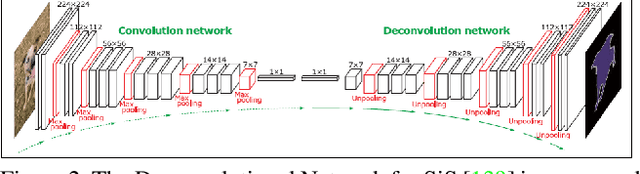
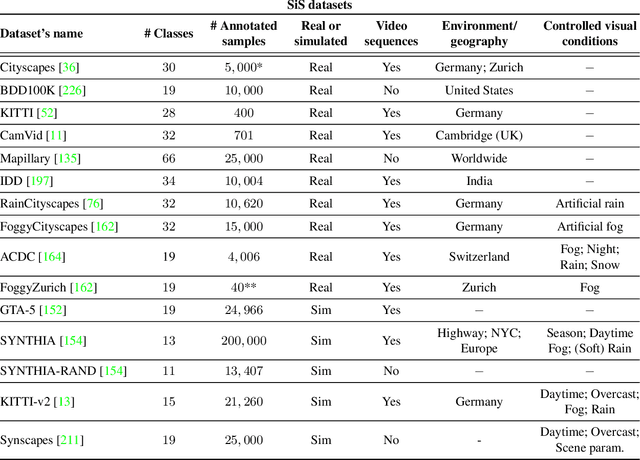
Semantic segmentation plays a fundamental role in a broad variety of computer vision applications, providing key information for the global understanding of an image. Yet, the state-of-the-art models rely on large amount of annotated samples, which are more expensive to obtain than in tasks such as image classification. Since unlabelled data is instead significantly cheaper to obtain, it is not surprising that Unsupervised Domain Adaptation reached a broad success within the semantic segmentation community. This survey is an effort to summarize five years of this incredibly rapidly growing field, which embraces the importance of semantic segmentation itself and a critical need of adapting segmentation models to new environments. We present the most important semantic segmentation methods; we provide a comprehensive survey on domain adaptation techniques for semantic segmentation; we unveil newer trends such as multi-domain learning, domain generalization, test-time adaptation or source-free domain adaptation; we conclude this survey by describing datasets and benchmarks most widely used in semantic segmentation research. We hope that this survey will provide researchers across academia and industry with a comprehensive reference guide and will help them in fostering new research directions in the field.
Out-of-distribution Detection via Frequency-regularized Generative Models
Aug 18, 2022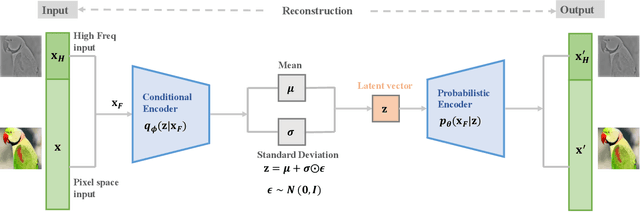
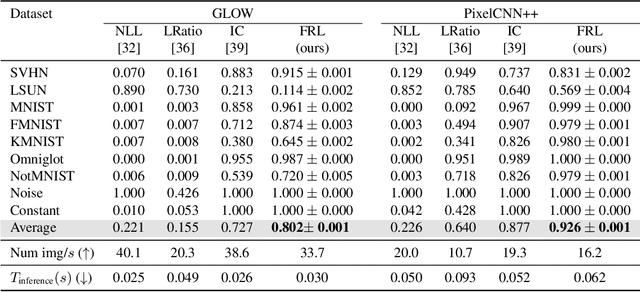

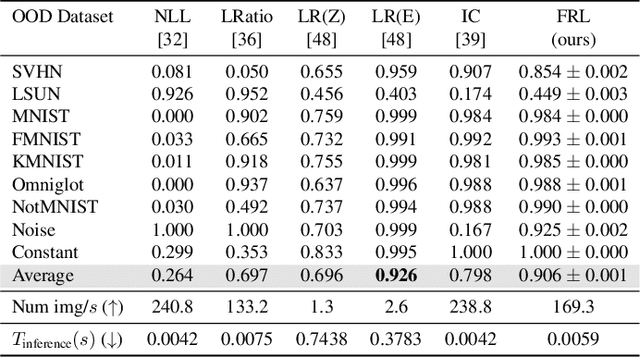
Modern deep generative models can assign high likelihood to inputs drawn from outside the training distribution, posing threats to models in open-world deployments. While much research attention has been placed on defining new test-time measures of OOD uncertainty, these methods do not fundamentally change how deep generative models are regularized and optimized in training. In particular, generative models are shown to overly rely on the background information to estimate the likelihood. To address the issue, we propose a novel frequency-regularized learning FRL framework for OOD detection, which incorporates high-frequency information into training and guides the model to focus on semantically relevant features. FRL effectively improves performance on a wide range of generative architectures, including variational auto-encoder, GLOW, and PixelCNN++. On a new large-scale evaluation task, FRL achieves the state-of-the-art performance, outperforming a strong baseline Likelihood Regret by 10.7% (AUROC) while achieving 147$\times$ faster inference speed. Extensive ablations show that FRL improves the OOD detection performance while preserving the image generation quality. Code is available at https://github.com/mu-cai/FRL.