 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Contrastive Learning for OOD in Object detection
Aug 12, 2022
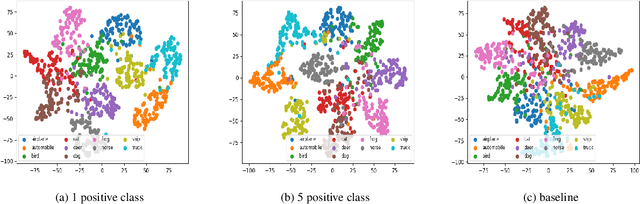
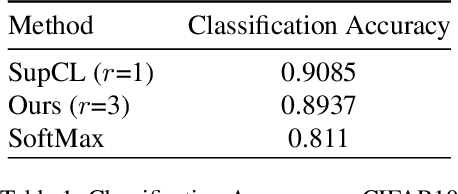
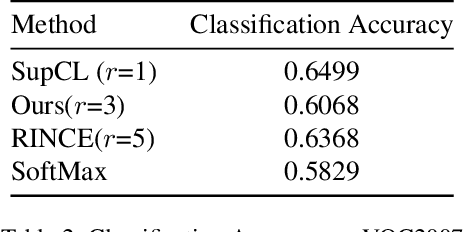
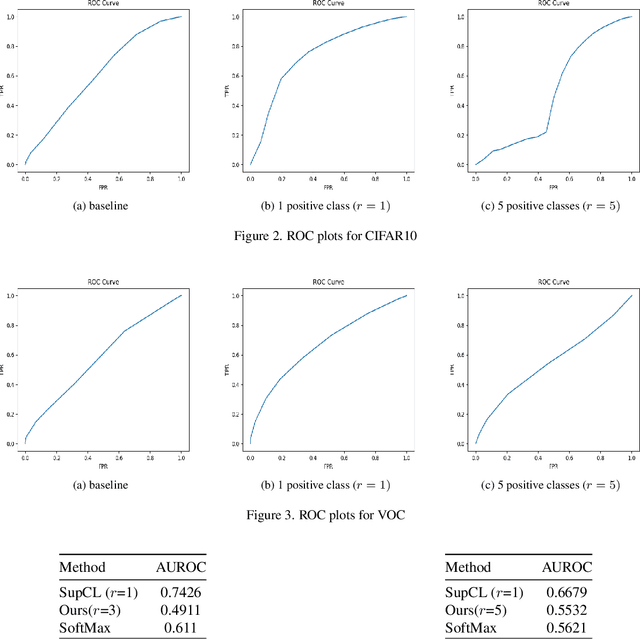
Contrastive learning is commonly applied to self-supervised learning, and has been shown to outperform traditional approaches such as the triplet loss and N-pair loss. However, the requirement of large batch sizes and memory banks has made it difficult and slow to train. Recently, Supervised Contrasative approaches have been developed to overcome these problems. They focus more on learning a good representation for each class individually, or between a cluster of classes. In this work we attempt to rank classes based on similarity using a user-defined ranking, to learn an efficient representation between all classes. We observe how incorporating human bias into the learning process could improve learning representations in the parameter space. We show that our results are comparable to Supervised Contrastive Learning for image classification and object detection, and discuss it's shortcomings in OOD Detection
A Temporal Learning Approach to Inpainting Endoscopic Specularities and Its effect on Image Correspondence
Mar 31, 2022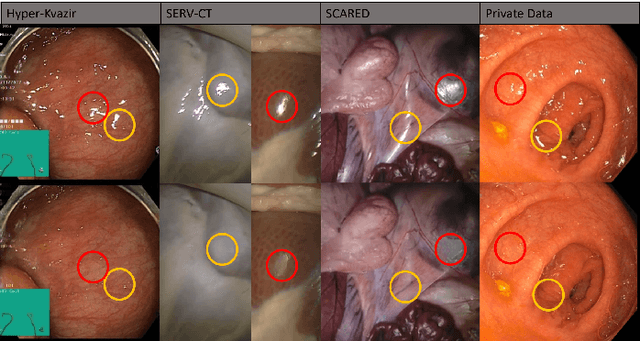
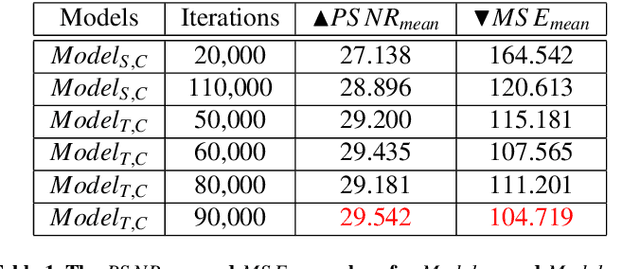
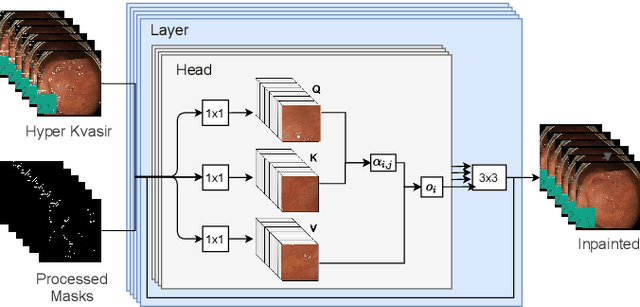
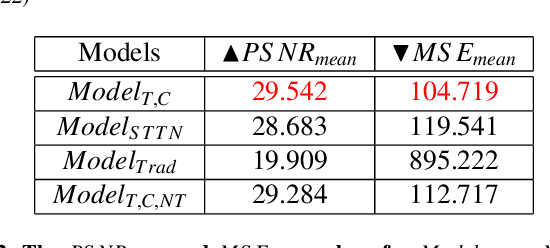
Video streams are utilised to guide minimally-invasive surgery and diagnostic procedures in a wide range of procedures, and many computer assisted techniques have been developed to automatically analyse them. These approaches can provide additional information to the surgeon such as lesion detection, instrument navigation, or anatomy 3D shape modeling. However, the necessary image features to recognise these patterns are not always reliably detected due to the presence of irregular light patterns such as specular highlight reflections. In this paper, we aim at removing specular highlights from endoscopic videos using machine learning. We propose using a temporal generative adversarial network (GAN) to inpaint the hidden anatomy under specularities, inferring its appearance spatially and from neighbouring frames where they are not present in the same location. This is achieved using in-vivo data of gastric endoscopy (Hyper-Kvasir) in a fully unsupervised manner that relies on automatic detection of specular highlights. System evaluations show significant improvements to traditional methods through direct comparison as well as other machine learning techniques through an ablation study that depicts the importance of the network's temporal and transfer learning components. The generalizability of our system to different surgical setups and procedures was also evaluated qualitatively on in-vivo data of gastric endoscopy and ex-vivo porcine data (SERV-CT, SCARED). We also assess the effect of our method in computer vision tasks that underpin 3D reconstruction and camera motion estimation, namely stereo disparity, optical flow, and sparse point feature matching. These are evaluated quantitatively and qualitatively and results show a positive effect of specular highlight inpainting on these tasks in a novel comprehensive analysis.
Sparse Subspace Clustering Friendly Deep Dictionary Learning for Hyperspectral Image Classification
Nov 27, 2021
Subspace clustering techniques have shown promise in hyperspectral image segmentation. The fundamental assumption in subspace clustering is that the samples belonging to different clusters/segments lie in separable subspaces. What if this condition does not hold? We surmise that even if the condition does not hold in the original space, the data may be nonlinearly transformed to a space where it will be separable into subspaces. In this work, we propose a transformation based on the tenets of deep dictionary learning (DDL). In particular, we incorporate the sparse subspace clustering (SSC) loss in the DDL formulation. Here DDL nonlinearly transforms the data such that the transformed representation (of the data) is separable into subspaces. We show that the proposed formulation improves over the state-of-the-art deep learning techniques in hyperspectral image clustering.
Distributed Image Transmission using Deep Joint Source-Channel Coding
Jan 25, 2022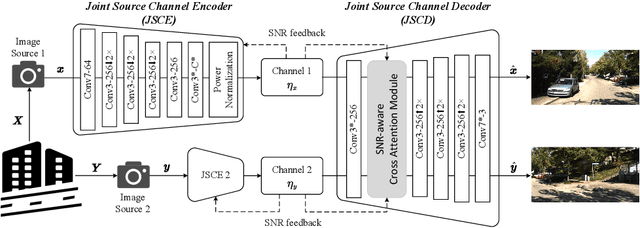
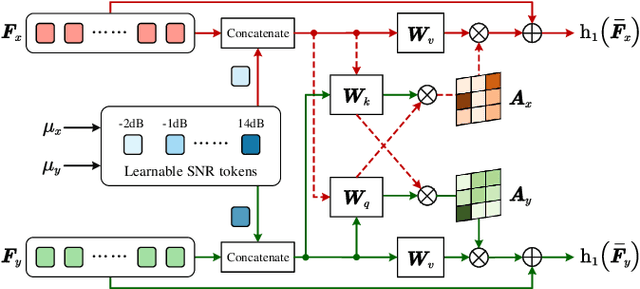

We study the problem of deep joint source-channel coding (D-JSCC) for correlated image sources, where each source is transmitted through a noisy independent channel to the common receiver. In particular, we consider a pair of images captured by two cameras with probably overlapping fields of view transmitted over wireless channels and reconstructed in the center node. The challenging problem involves designing a practical code to utilize both source and channel correlations to improve transmission efficiency without additional transmission overhead. To tackle this, we need to consider the common information across two stereo images as well as the differences between two transmission channels. In this case, we propose a deep neural networks solution that includes lightweight edge encoders and a powerful center decoder. Besides, in the decoder, we propose a novel channel state information aware cross attention module to highlight the overlapping fields and leverage the relevance between two noisy feature maps.Our results show the impressive improvement of reconstruction quality in both links by exploiting the noisy representations of the other link. Moreover, the proposed scheme shows competitive results compared to the separated schemes with capacity-achieving channel codes.
Flow-based Visual Quality Enhancer for Super-resolution Magnetic Resonance Spectroscopic Imaging
Jul 20, 2022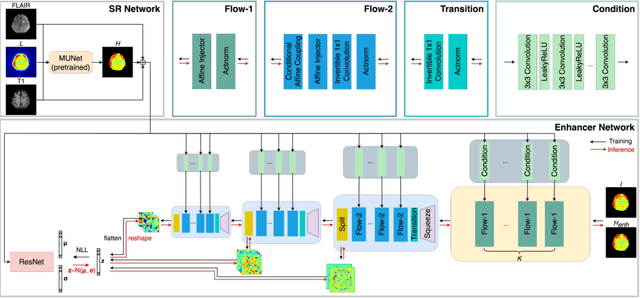
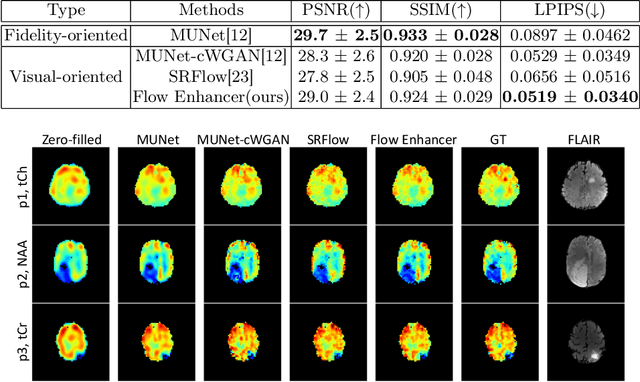
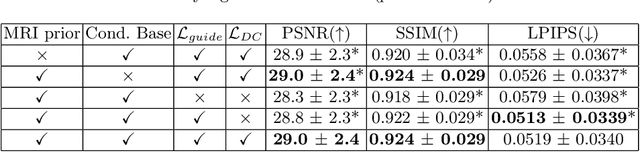
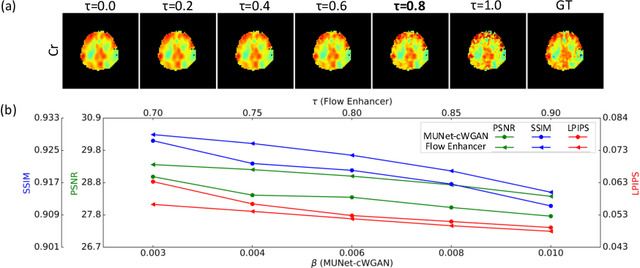
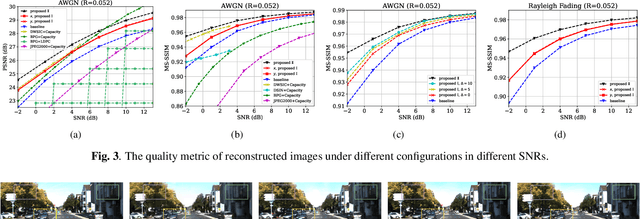
Magnetic Resonance Spectroscopic Imaging (MRSI) is an essential tool for quantifying metabolites in the body, but the low spatial resolution limits its clinical applications. Deep learning-based super-resolution methods provided promising results for improving the spatial resolution of MRSI, but the super-resolved images are often blurry compared to the experimentally-acquired high-resolution images. Attempts have been made with the generative adversarial networks to improve the image visual quality. In this work, we consider another type of generative model, the flow-based model, of which the training is more stable and interpretable compared to the adversarial networks. Specifically, we propose a flow-based enhancer network to improve the visual quality of super-resolution MRSI. Different from previous flow-based models, our enhancer network incorporates anatomical information from additional image modalities (MRI) and uses a learnable base distribution. In addition, we impose a guide loss and a data-consistency loss to encourage the network to generate images with high visual quality while maintaining high fidelity. Experiments on a 1H-MRSI dataset acquired from 25 high-grade glioma patients indicate that our enhancer network outperforms the adversarial networks and the baseline flow-based methods. Our method also allows visual quality adjustment and uncertainty estimation.
Federated Learning of Generative Image Priors for MRI Reconstruction
Feb 08, 2022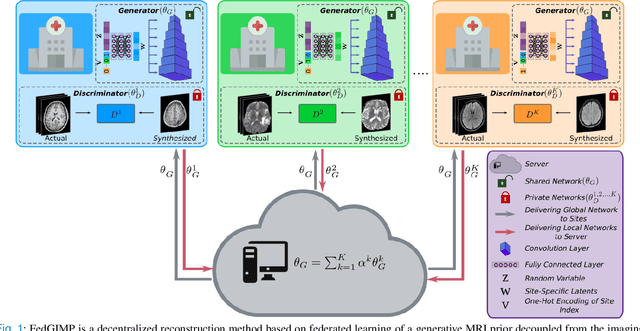
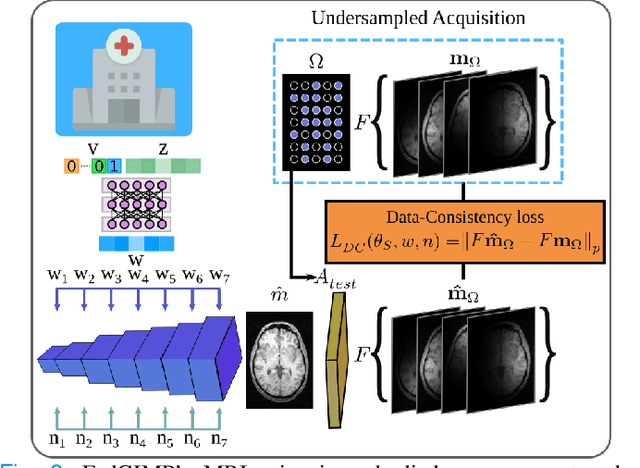
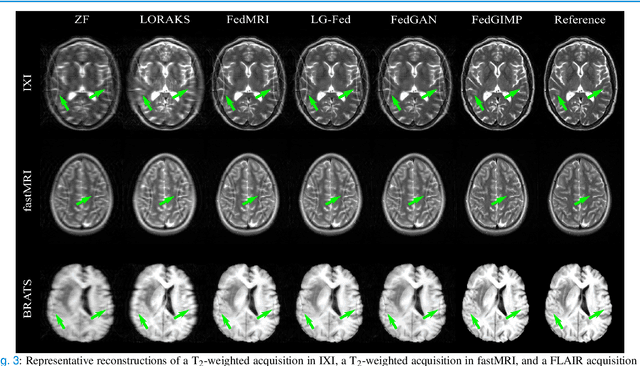
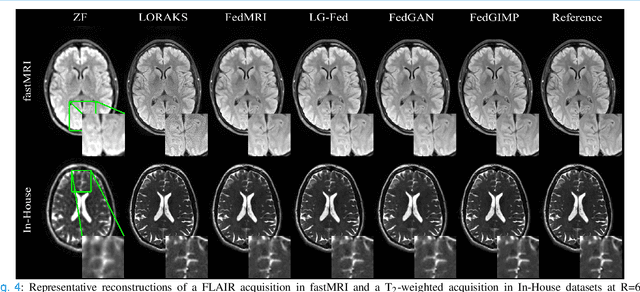
Multi-institutional efforts can facilitate training of deep MRI reconstruction models, albeit privacy risks arise during cross-site sharing of imaging data. Federated learning (FL) has recently been introduced to address privacy concerns by enabling distributed training without transfer of imaging data. Existing FL methods for MRI reconstruction employ conditional models to map from undersampled to fully-sampled acquisitions via explicit knowledge of the imaging operator. Since conditional models generalize poorly across different acceleration rates or sampling densities, imaging operators must be fixed between training and testing, and they are typically matched across sites. To improve generalization and flexibility in multi-institutional collaborations, here we introduce a novel method for MRI reconstruction based on Federated learning of Generative IMage Priors (FedGIMP). FedGIMP leverages a two-stage approach: cross-site learning of a generative MRI prior, and subject-specific injection of the imaging operator. The global MRI prior is learned via an unconditional adversarial model that synthesizes high-quality MR images based on latent variables. Specificity in the prior is preserved via a mapper subnetwork that produces site-specific latents. During inference, the prior is combined with subject-specific imaging operators to enable reconstruction, and further adapted to individual test samples by minimizing data-consistency loss. Comprehensive experiments on multi-institutional datasets clearly demonstrate enhanced generalization performance of FedGIMP against site-specific and federated methods based on conditional models, as well as traditional reconstruction methods.
Realtime strategy for image data labelling using binary models and active sampling
Feb 28, 2022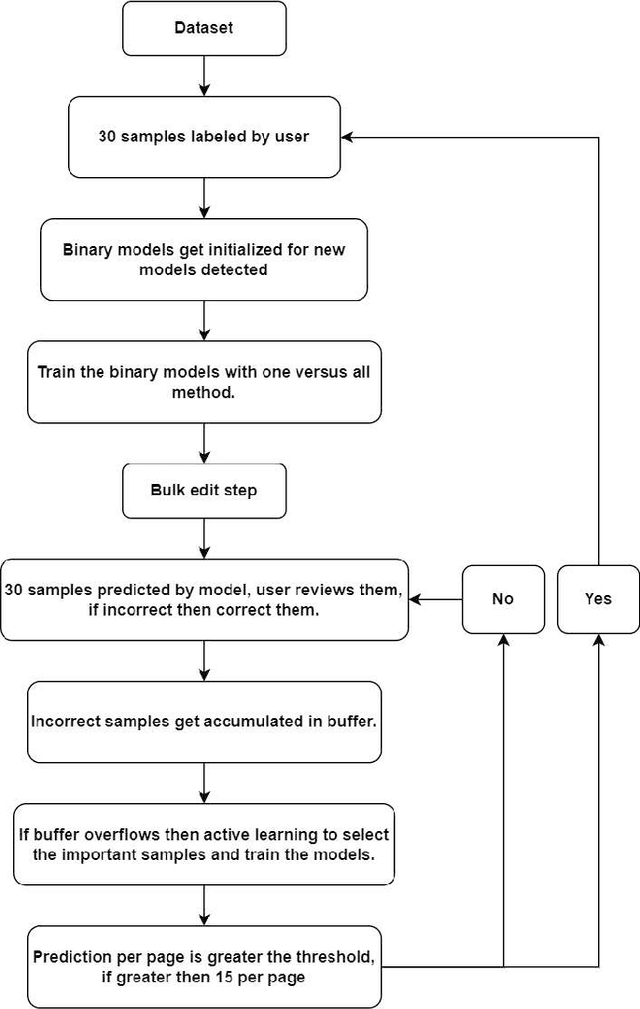
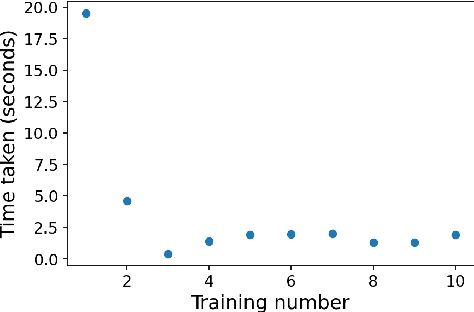
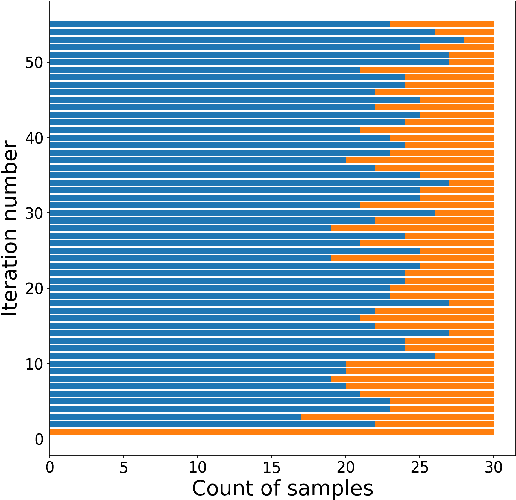
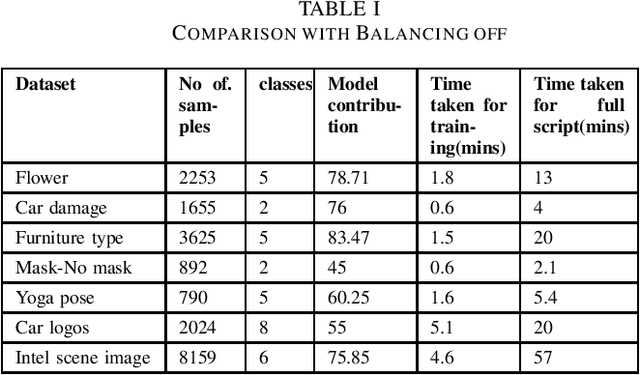
Machine learning (ML) and Deep Learning (DL) tasks primarily depend on data. Most of the ML and DL applications involve supervised learning which requires labelled data. In the initial phases of ML realm lack of data used to be a problem, now we are in a new era of big data. The supervised ML algorithms require data to be labelled and of good quality. Labelling task requires a large amount of money and time investment. Data labelling require a skilled person who will charge high for this task, consider the case of the medical field or the data is in bulk that requires a lot of people assigned to label it. The amount of data that is well enough for training needs to be known, money and time can not be wasted to label the whole data. This paper mainly aims to propose a strategy that helps in labelling the data along with oracle in real-time. With balancing on model contribution for labelling is 89 and 81.1 for furniture type and intel scene image data sets respectively. Further with balancing being kept off model contribution is found to be 83.47 and 78.71 for furniture type and flower data sets respectively.
FloLPIPS: A Bespoke Video Quality Metric for Frame Interpoation
Jul 17, 2022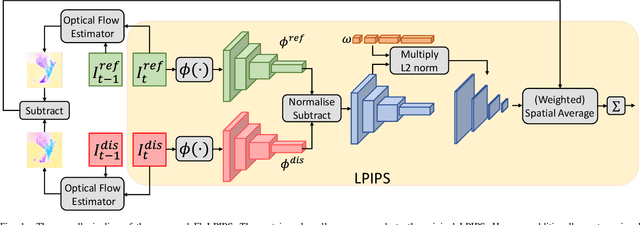
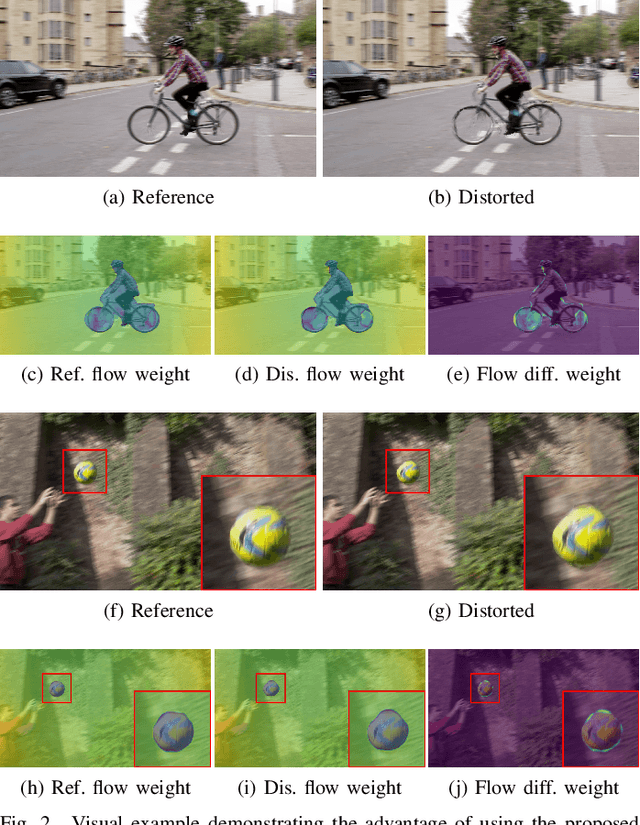
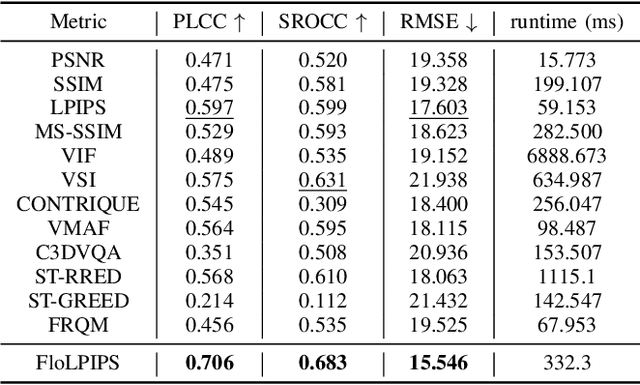

Video frame interpolation (VFI) serves as a useful tool for many video processing applications. Recently, it has also been applied in the video compression domain for enhancing both conventional video codecs and learning-based compression architectures. While there has been an increased focus on the development of enhanced frame interpolation algorithms in recent years, the perceptual quality assessment of interpolated content remains an open field of research. In this paper, we present a bespoke full reference video quality metric for VFI, FloLPIPS, that builds on the popular perceptual image quality metric, LPIPS, which captures the perceptual degradation in extracted image feature space. In order to enhance the performance of LPIPS for evaluating interpolated content, we re-designed its spatial feature aggregation step by using the temporal distortion (through comparing optical flows) to weight the feature difference maps. Evaluated on the BVI-VFI database, which contains 180 test sequences with various frame interpolation artefacts, FloLPIPS shows superior correlation performance (with statistical significance) with subjective ground truth over 12 popular quality assessors. To facilitate further research in VFI quality assessment, our code is publicly available at https://danielism97.github.io/FloLPIPS.
The Importance of Background Information for Out of Distribution Generalization
Jun 17, 2022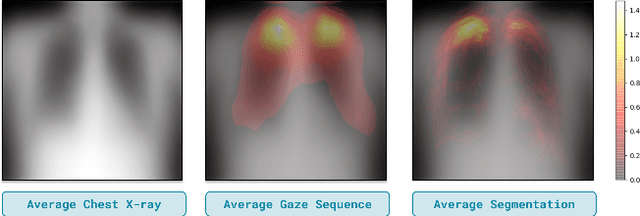
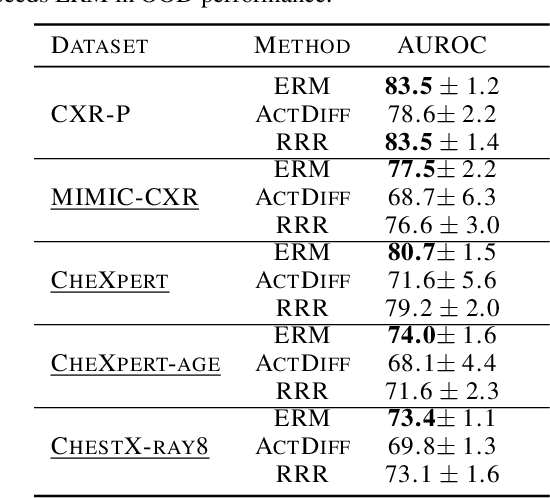

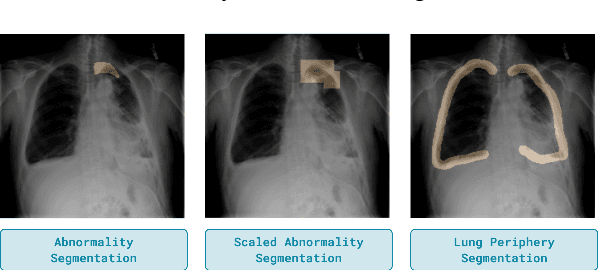
Domain generalization in medical image classification is an important problem for trustworthy machine learning to be deployed in healthcare. We find that existing approaches for domain generalization which utilize ground-truth abnormality segmentations to control feature attributions have poor out-of-distribution (OOD) performance relative to the standard baseline of empirical risk minimization (ERM). We investigate what regions of an image are important for medical image classification and show that parts of the background, that which is not contained in the abnormality segmentation, provides helpful signal. We then develop a new task-specific mask which covers all relevant regions. Utilizing this new segmentation mask significantly improves the performance of the existing methods on the OOD test sets. To obtain better generalization results than ERM, we find it necessary to scale up the training data size in addition to the usage of these task-specific masks.
6D Camera Relocalization in Visually Ambiguous Extreme Environments
Jul 13, 2022
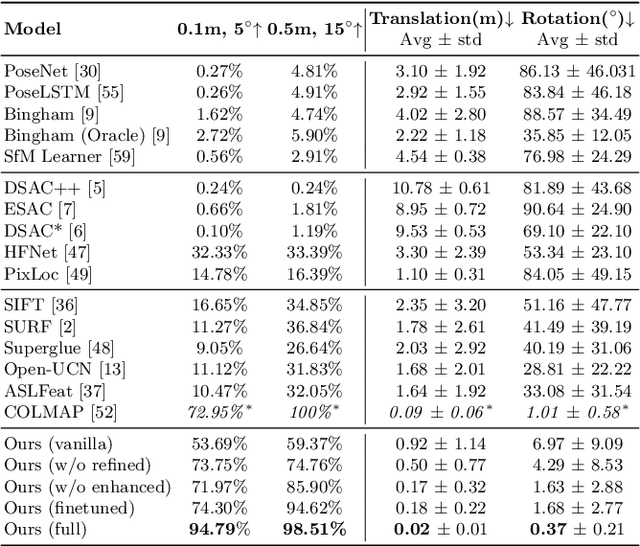
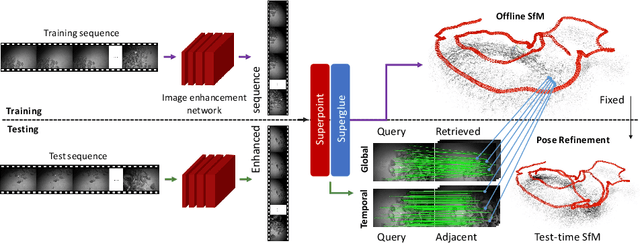
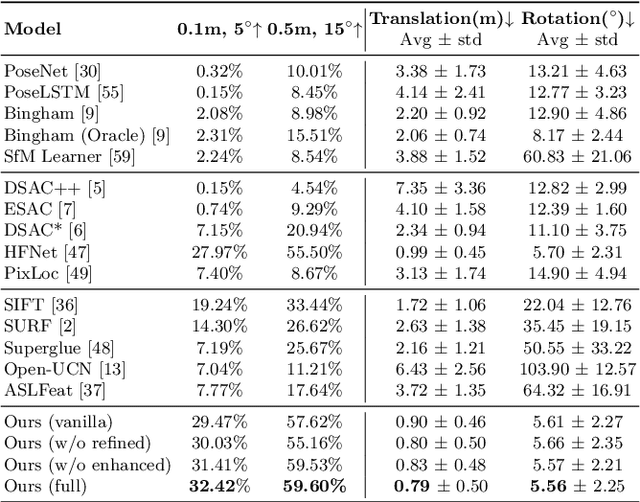
We propose a novel method to reliably estimate the pose of a camera given a sequence of images acquired in extreme environments such as deep seas or extraterrestrial terrains. Data acquired under these challenging conditions are corrupted by textureless surfaces, image degradation, and presence of repetitive and highly ambiguous structures. When naively deployed, the state-of-the-art methods can fail in those scenarios as confirmed by our empirical analysis. In this paper, we attempt to make camera relocalization work in these extreme situations. To this end, we propose: (i) a hierarchical localization system, where we leverage temporal information and (ii) a novel environment-aware image enhancement method to boost the robustness and accuracy. Our extensive experimental results demonstrate superior performance in favor of our method under two extreme settings: localizing an autonomous underwater vehicle and localizing a planetary rover in a Mars-like desert. In addition, our method achieves comparable performance with state-of-the-art methods on the indoor benchmark (7-Scenes dataset) using only 20% training data.