 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Early Stopping for Deep Image Prior
Dec 11, 2021
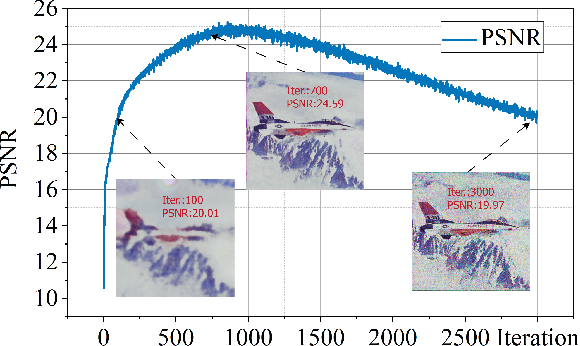

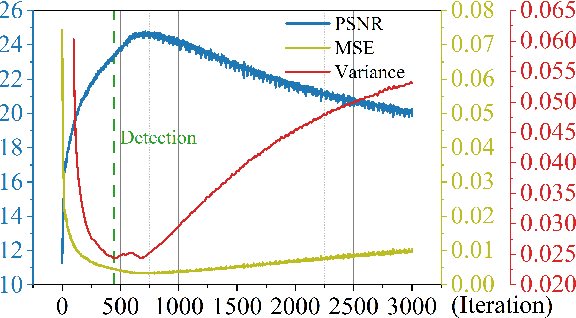
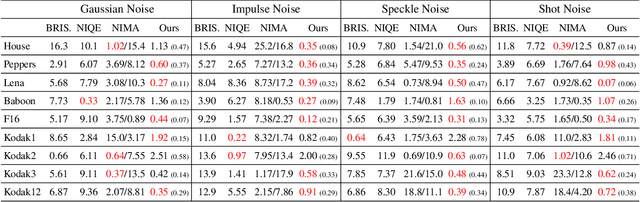
Deep image prior (DIP) and its variants have showed remarkable potential for solving inverse problems in computer vision, without any extra training data. Practical DIP models are often substantially overparameterized. During the fitting process, these models learn mostly the desired visual content first, and then pick up the potential modeling and observational noise, i.e., overfitting. Thus, the practicality of DIP often depends critically on good early stopping (ES) that captures the transition period. In this regard, the majority of DIP works for vision tasks only demonstrates the potential of the models -- reporting the peak performance against the ground truth, but provides no clue about how to operationally obtain near-peak performance without access to the groundtruth. In this paper, we set to break this practicality barrier of DIP, and propose an efficient ES strategy, which consistently detects near-peak performance across several vision tasks and DIP variants. Based on a simple measure of dispersion of consecutive DIP reconstructions, our ES method not only outpaces the existing ones -- which only work in very narrow domains, but also remains effective when combined with a number of methods that try to mitigate the overfitting. The code is available at https://github.com/sun-umn/Early_Stopping_for_DIP.
Self-supervised Product Quantization for Deep Unsupervised Image Retrieval
Sep 06, 2021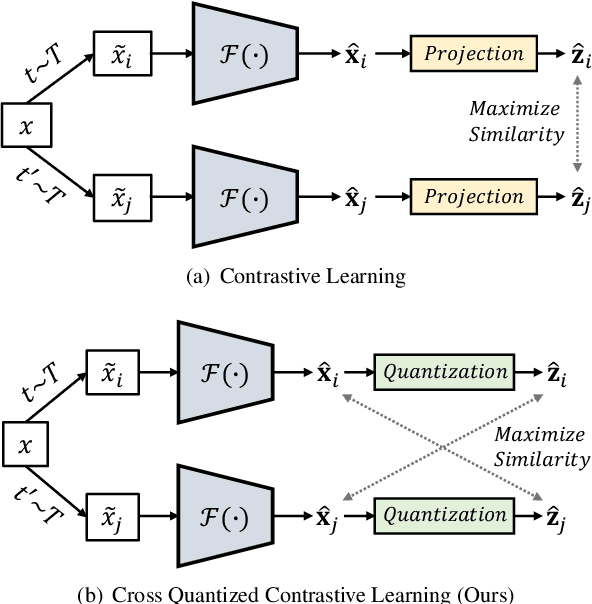
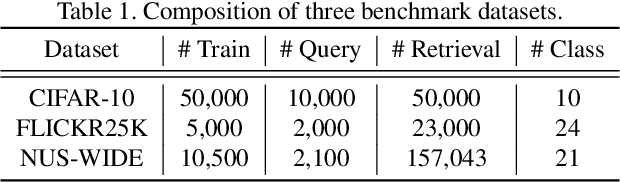
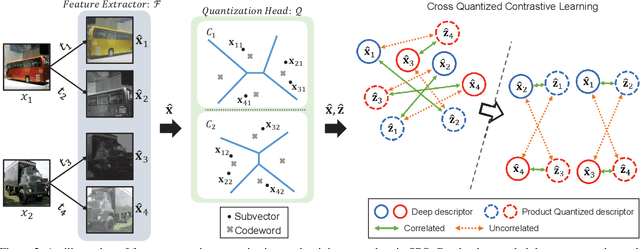
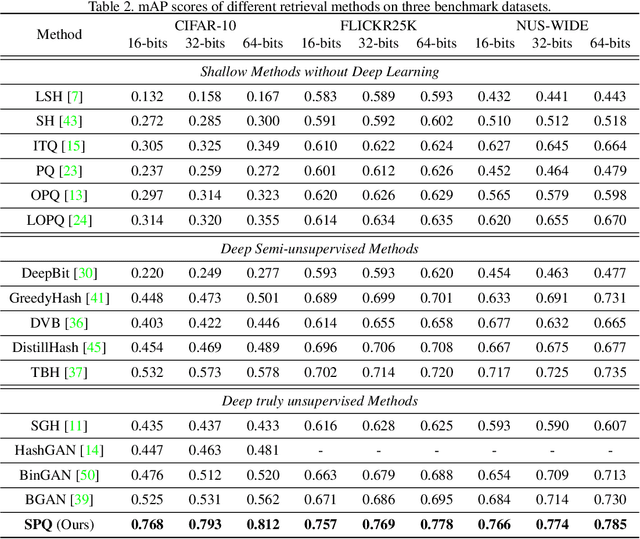
Supervised deep learning-based hash and vector quantization are enabling fast and large-scale image retrieval systems. By fully exploiting label annotations, they are achieving outstanding retrieval performances compared to the conventional methods. However, it is painstaking to assign labels precisely for a vast amount of training data, and also, the annotation process is error-prone. To tackle these issues, we propose the first deep unsupervised image retrieval method dubbed Self-supervised Product Quantization (SPQ) network, which is label-free and trained in a self-supervised manner. We design a Cross Quantized Contrastive learning strategy that jointly learns codewords and deep visual descriptors by comparing individually transformed images (views). Our method analyzes the image contents to extract descriptive features, allowing us to understand image representations for accurate retrieval. By conducting extensive experiments on benchmarks, we demonstrate that the proposed method yields state-of-the-art results even without supervised pretraining.
Cascaded Cross MLP-Mixer GANs for Cross-View Image Translation
Oct 19, 2021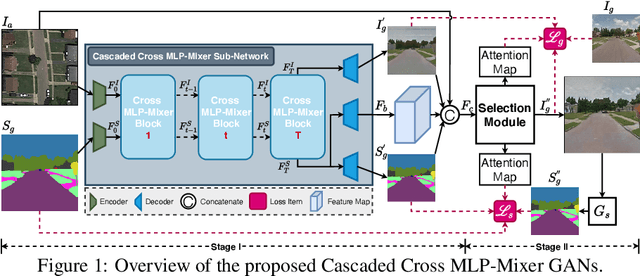
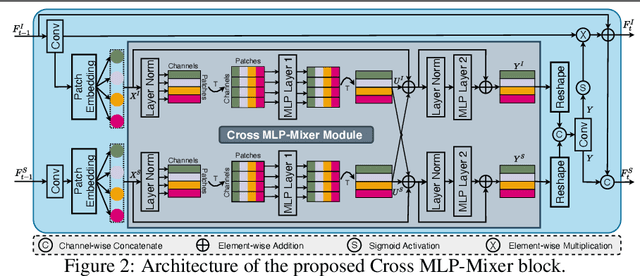
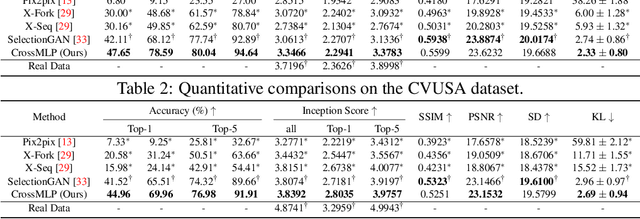

It is hard to generate an image at target view well for previous cross-view image translation methods that directly adopt a simple encoder-decoder or U-Net structure, especially for drastically different views and severe deformation cases. To ease this problem, we propose a novel two-stage framework with a new Cascaded Cross MLP-Mixer (CrossMLP) sub-network in the first stage and one refined pixel-level loss in the second stage. In the first stage, the CrossMLP sub-network learns the latent transformation cues between image code and semantic map code via our novel CrossMLP blocks. Then the coarse results are generated progressively under the guidance of those cues. Moreover, in the second stage, we design a refined pixel-level loss that eases the noisy semantic label problem with more reasonable regularization in a more compact fashion for better optimization. Extensive experimental results on Dayton~\cite{vo2016localizing} and CVUSA~\cite{workman2015wide} datasets show that our method can generate significantly better results than state-of-the-art methods. The source code and trained models are available at https://github.com/Amazingren/CrossMLP.
Two Decades of Colorization and Decolorization for Images and Videos
Apr 28, 2022



Colorization is a computer-aided process, which aims to give color to a gray image or video. It can be used to enhance black-and-white images, including black-and-white photos, old-fashioned films, and scientific imaging results. On the contrary, decolorization is to convert a color image or video into a grayscale one. A grayscale image or video refers to an image or video with only brightness information without color information. It is the basis of some downstream image processing applications such as pattern recognition, image segmentation, and image enhancement. Different from image decolorization, video decolorization should not only consider the image contrast preservation in each video frame, but also respect the temporal and spatial consistency between video frames. Researchers were devoted to develop decolorization methods by balancing spatial-temporal consistency and algorithm efficiency. With the prevalance of the digital cameras and mobile phones, image and video colorization and decolorization have been paid more and more attention by researchers. This paper gives an overview of the progress of image and video colorization and decolorization methods in the last two decades.
Symbolic Replay: Scene Graph as Prompt for Continual Learning on VQA Task
Aug 29, 2022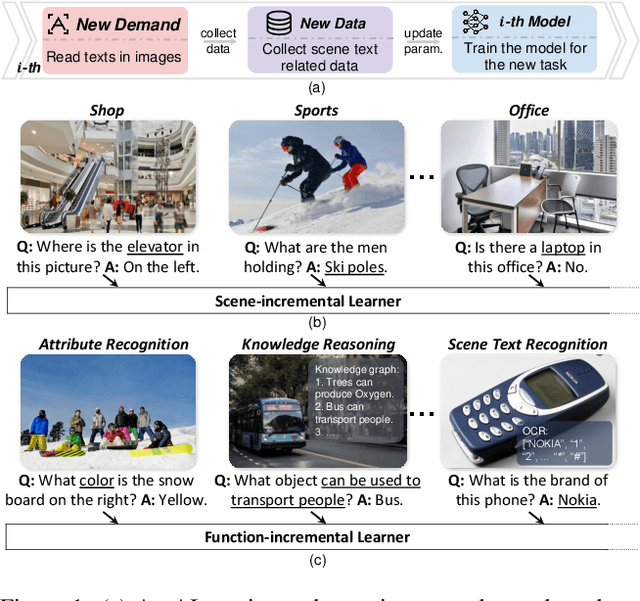
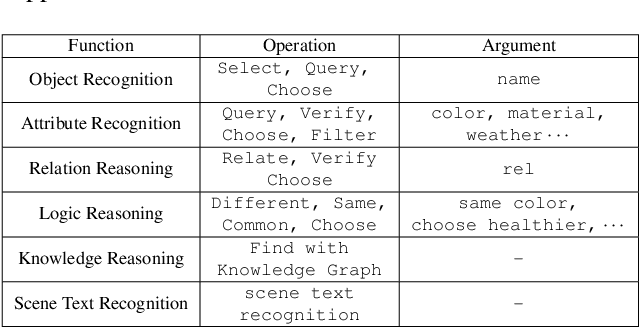
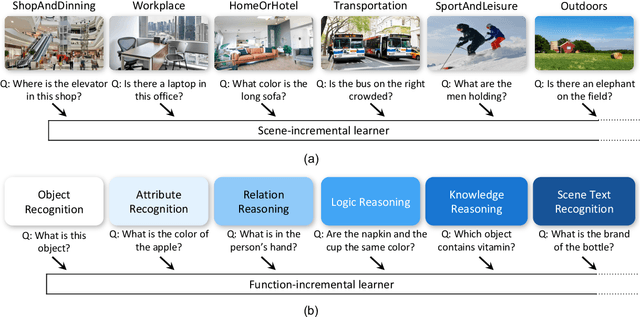
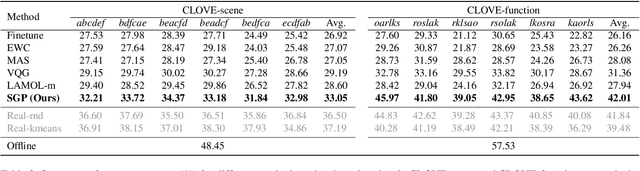
VQA is an ambitious task aiming to answer any image-related question. However, in reality, it is hard to build such a system once for all since the needs of users are continuously updated, and the system has to implement new functions. Thus, Continual Learning (CL) ability is a must in developing advanced VQA systems. Recently, a pioneer work split a VQA dataset into disjoint answer sets to study this topic. However, CL on VQA involves not only the expansion of label sets (new Answer sets). It is crucial to study how to answer questions when deploying VQA systems to new environments (new Visual scenes) and how to answer questions requiring new functions (new Question types). Thus, we propose CLOVE, a benchmark for Continual Learning On Visual quEstion answering, which contains scene- and function-incremental settings for the two aforementioned CL scenarios. In terms of methodology, the main difference between CL on VQA and classification is that the former additionally involves expanding and preventing forgetting of reasoning mechanisms, while the latter focusing on class representation. Thus, we propose a real-data-free replay-based method tailored for CL on VQA, named Scene Graph as Prompt for Symbolic Replay. Using a piece of scene graph as a prompt, it replays pseudo scene graphs to represent the past images, along with correlated QA pairs. A unified VQA model is also proposed to utilize the current and replayed data to enhance its QA ability. Finally, experimental results reveal challenges in CLOVE and demonstrate the effectiveness of our method. The dataset and code will be available at https://github.com/showlab/CLVQA.
Learning Sparsity-Promoting Regularizers using Bilevel Optimization
Jul 18, 2022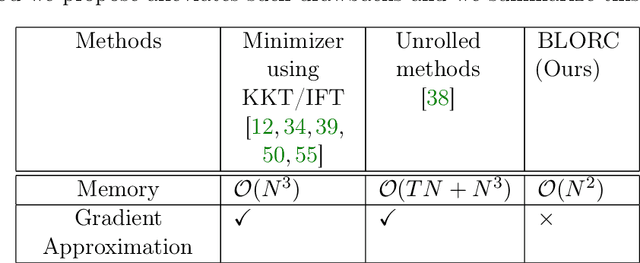
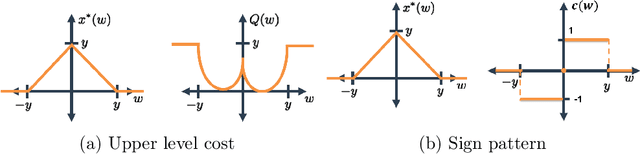
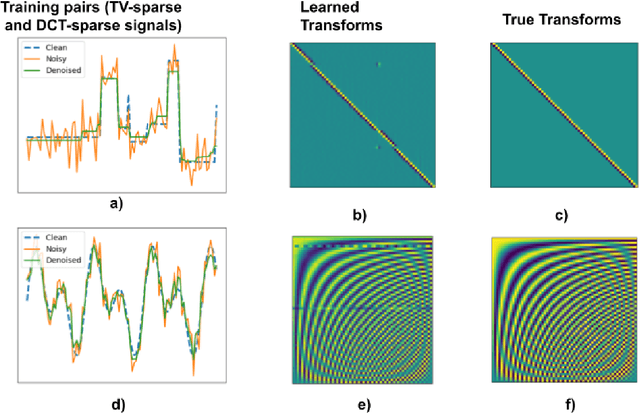

We present a method for supervised learning of sparsity-promoting regularizers for denoising signals and images. Sparsity-promoting regularization is a key ingredient in solving modern signal reconstruction problems; however, the operators underlying these regularizers are usually either designed by hand or learned from data in an unsupervised way. The recent success of supervised learning (mainly convolutional neural networks) in solving image reconstruction problems suggests that it could be a fruitful approach to designing regularizers. Towards this end, we propose to denoise signals using a variational formulation with a parametric, sparsity-promoting regularizer, where the parameters of the regularizer are learned to minimize the mean squared error of reconstructions on a training set of ground truth image and measurement pairs. Training involves solving a challenging bilievel optimization problem; we derive an expression for the gradient of the training loss using the closed-form solution of the denoising problem and provide an accompanying gradient descent algorithm to minimize it. Our experiments with structured 1D signals and natural images show that the proposed method can learn an operator that outperforms well-known regularizers (total variation, DCT-sparsity, and unsupervised dictionary learning) and collaborative filtering for denoising. While the approach we present is specific to denoising, we believe that it could be adapted to the larger class of inverse problems with linear measurement models, giving it applicability in a wide range of signal reconstruction settings.
Learning to segment from object sizes
Jul 01, 2022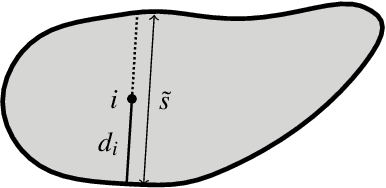


Deep learning has proved particularly useful for semantic segmentation, a fundamental image analysis task. However, the standard deep learning methods need many training images with ground-truth pixel-wise annotations, which are usually laborious to obtain and, in some cases (e.g., medical images), require domain expertise. Therefore, instead of pixel-wise annotations, we focus on image annotations that are significantly easier to acquire but still informative, namely the size of foreground objects. We define the object size as the maximum distance between a foreground pixel and the background. We propose an algorithm for training a deep segmentation network from a dataset of a few pixel-wise annotated images and many images with known object sizes. The algorithm minimizes a discrete (non-differentiable) loss function defined over the object sizes by sampling the gradient and then using the standard back-propagation algorithm. We study the performance of our approach in terms of training time and generalization error.
Move As You Like: Image Animation in E-Commerce Scenario
Dec 19, 2021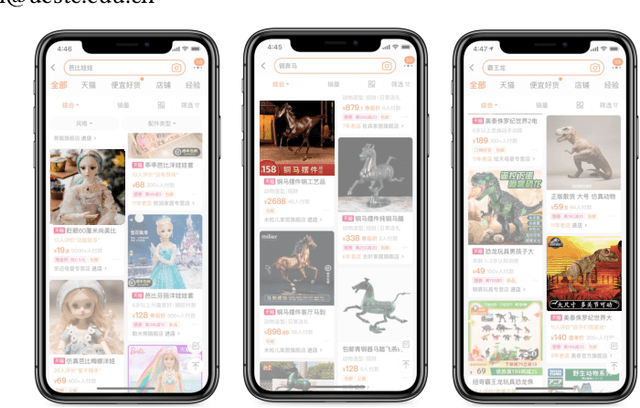
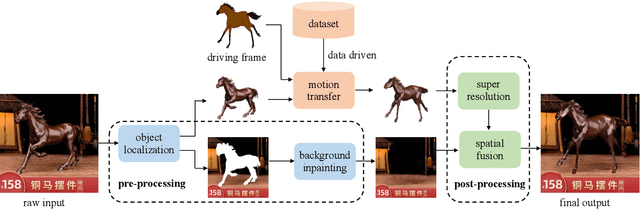

Creative image animations are attractive in e-commerce applications, where motion transfer is one of the import ways to generate animations from static images. However, existing methods rarely transfer motion to objects other than human body or human face, and even fewer apply motion transfer in practical scenarios. In this work, we apply motion transfer on the Taobao product images in real e-commerce scenario to generate creative animations, which are more attractive than static images and they will bring more benefits. We animate the Taobao products of dolls, copper running horses and toy dinosaurs based on motion transfer method for demonstration.
* 3 pages, 3 figures, ACM MM 2021 demo session
BIGRoC: Boosting Image Generation via a Robust Classifier
Aug 08, 2021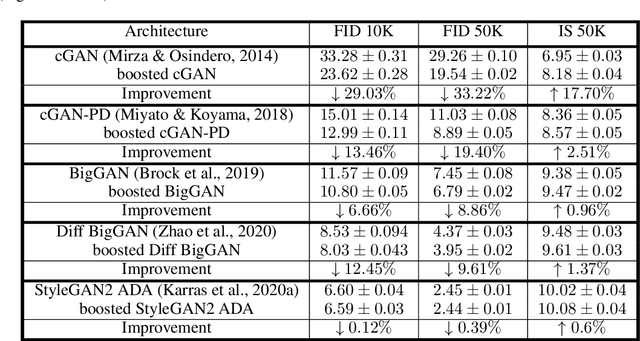
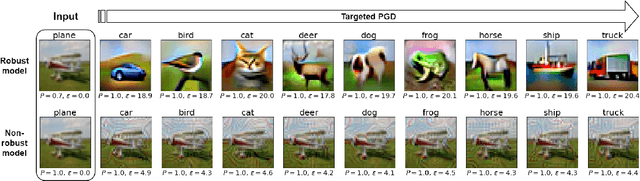
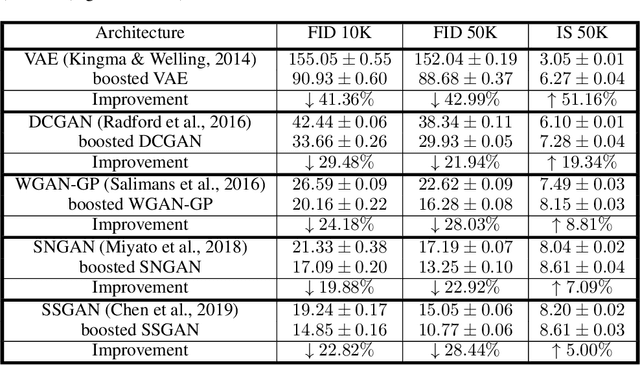
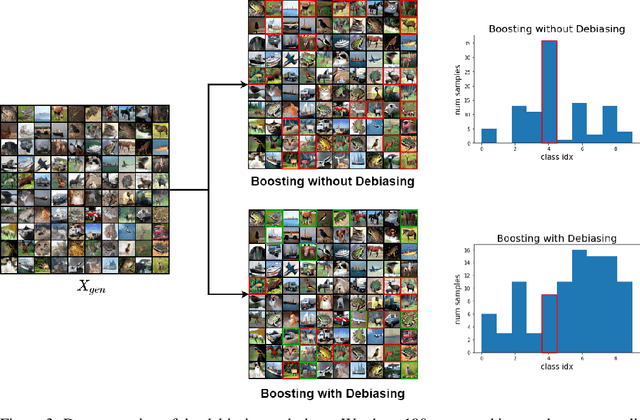
The interest of the machine learning community in image synthesis has grown significantly in recent years, with the introduction of a wide range of deep generative models and means for training them. Such machines' ultimate goal is to match the distributions of the given training images and the synthesized ones. In this work, we propose a general model-agnostic technique for improving the image quality and the distribution fidelity of generated images, obtained by any generative model. Our method, termed BIGRoC (boosting image generation via a robust classifier), is based on a post-processing procedure via the guidance of a given robust classifier and without a need for additional training of the generative model. Given a synthesized image, we propose to update it through projected gradient steps over the robust classifier, in an attempt to refine its recognition. We demonstrate this post-processing algorithm on various image synthesis methods and show a significant improvement of the generated images, both quantitatively and qualitatively.
Evaluating Continual Test-Time Adaptation for Contextual and Semantic Domain Shifts
Aug 18, 2022
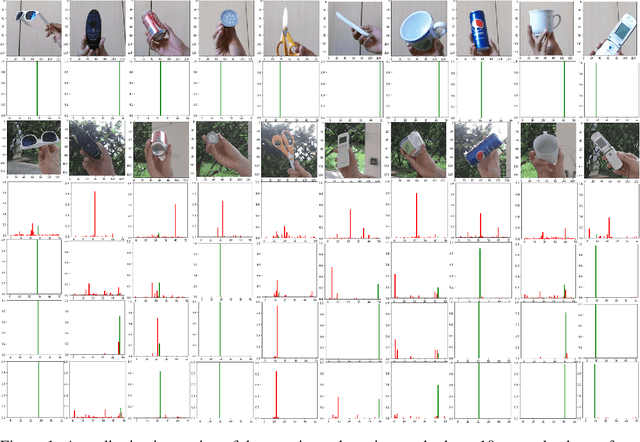

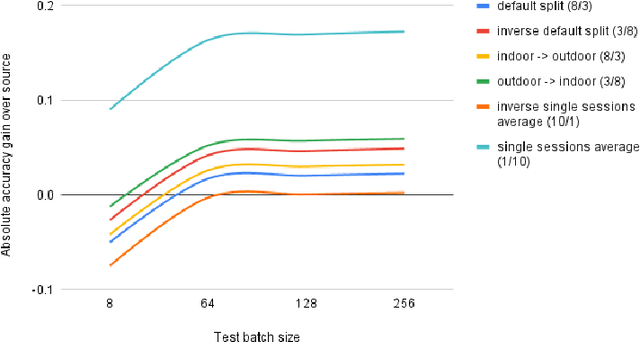
In this paper, our goal is to adapt a pre-trained Convolutional Neural Network to domain shifts at test time. We do so continually with the incoming stream of test batches, without labels. Existing literature mostly operates on artificial shifts obtained via adversarial perturbations of a test image. Motivated by this, we evaluate the state of the art on two realistic and challenging sources of domain shifts, namely contextual and semantic shifts. Contextual shifts correspond to the environment types, for example a model pre-trained on indoor context has to adapt to the outdoor context on CORe-50 [7]. Semantic shifts correspond to the capture types, for example a model pre-trained on natural images has to adapt to cliparts, sketches and paintings on DomainNet [10]. We include in our analysis recent techniques such as Prediction-Time Batch Normalization (BN) [8], Test Entropy Minimization (TENT) [16] and Continual Test-Time Adaptation (CoTTA) [17]. Our findings are three-fold: i) Test-time adaptation methods perform better and forget less on contextual shifts compared to semantic shifts, ii) TENT outperforms other methods on short-term adaptation, whereas CoTTA outpeforms other methods on long-term adaptation, iii) BN is most reliable and robust.