 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
RepParser: End-to-End Multiple Human Parsing with Representative Parts
Aug 27, 2022
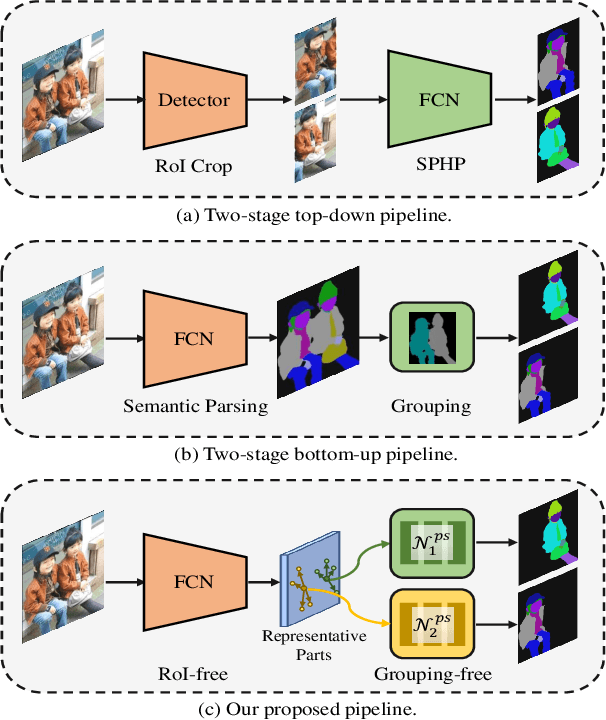
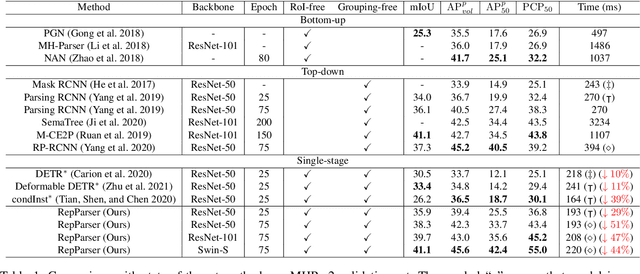
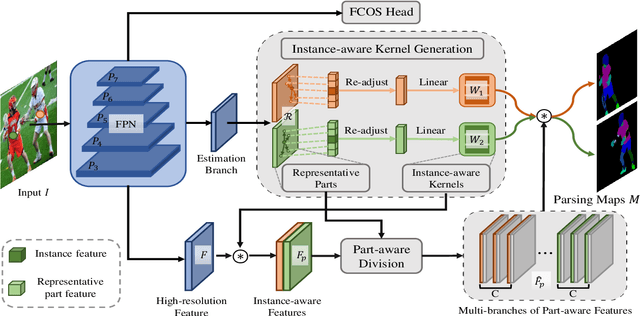
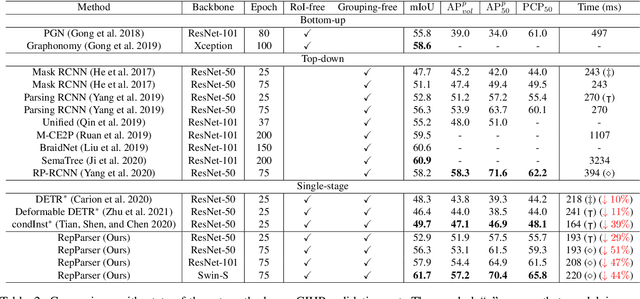
Existing methods of multiple human parsing usually adopt a two-stage strategy (typically top-down and bottom-up), which suffers from either strong dependence on prior detection or highly computational redundancy during post-grouping. In this work, we present an end-to-end multiple human parsing framework using representative parts, termed RepParser. Different from mainstream methods, RepParser solves the multiple human parsing in a new single-stage manner without resorting to person detection or post-grouping.To this end, RepParser decouples the parsing pipeline into instance-aware kernel generation and part-aware human parsing, which are responsible for instance separation and instance-specific part segmentation, respectively. In particular, we empower the parsing pipeline by representative parts, since they are characterized by instance-aware keypoints and can be utilized to dynamically parse each person instance. Specifically, representative parts are obtained by jointly localizing centers of instances and estimating keypoints of body part regions. After that, we dynamically predict instance-aware convolution kernels through representative parts, thus encoding person-part context into each kernel responsible for casting an image feature as an instance-specific representation.Furthermore, a multi-branch structure is adopted to divide each instance-specific representation into several part-aware representations for separate part segmentation.In this way, RepParser accordingly focuses on person instances with the guidance of representative parts and directly outputs parsing results for each person instance, thus eliminating the requirement of the prior detection or post-grouping.Extensive experiments on two challenging benchmarks demonstrate that our proposed RepParser is a simple yet effective framework and achieves very competitive performance.
NeuralPassthrough: Learned Real-Time View Synthesis for VR
Jul 05, 2022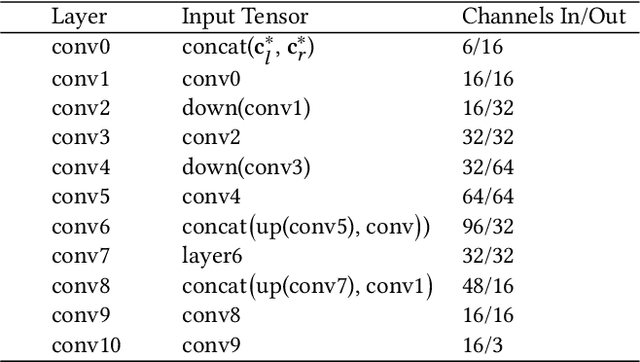

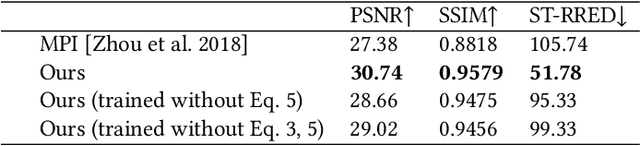
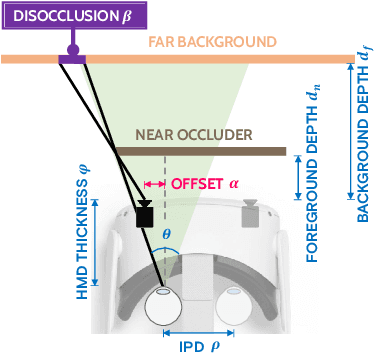
Virtual reality (VR) headsets provide an immersive, stereoscopic visual experience, but at the cost of blocking users from directly observing their physical environment. Passthrough techniques are intended to address this limitation by leveraging outward-facing cameras to reconstruct the images that would otherwise be seen by the user without the headset. This is inherently a real-time view synthesis challenge, since passthrough cameras cannot be physically co-located with the eyes. Existing passthrough techniques suffer from distracting reconstruction artifacts, largely due to the lack of accurate depth information (especially for near-field and disoccluded objects), and also exhibit limited image quality (e.g., being low resolution and monochromatic). In this paper, we propose the first learned passthrough method and assess its performance using a custom VR headset that contains a stereo pair of RGB cameras. Through both simulations and experiments, we demonstrate that our learned passthrough method delivers superior image quality compared to state-of-the-art methods, while meeting strict VR requirements for real-time, perspective-correct stereoscopic view synthesis over a wide field of view for desktop-connected headsets.
ImageBART: Bidirectional Context with Multinomial Diffusion for Autoregressive Image Synthesis
Aug 19, 2021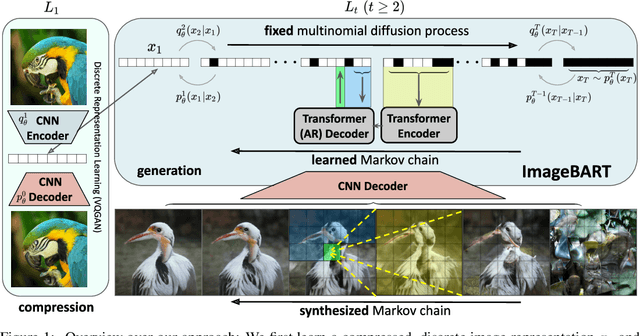



Autoregressive models and their sequential factorization of the data likelihood have recently demonstrated great potential for image representation and synthesis. Nevertheless, they incorporate image context in a linear 1D order by attending only to previously synthesized image patches above or to the left. Not only is this unidirectional, sequential bias of attention unnatural for images as it disregards large parts of a scene until synthesis is almost complete. It also processes the entire image on a single scale, thus ignoring more global contextual information up to the gist of the entire scene. As a remedy we incorporate a coarse-to-fine hierarchy of context by combining the autoregressive formulation with a multinomial diffusion process: Whereas a multistage diffusion process successively removes information to coarsen an image, we train a (short) Markov chain to invert this process. In each stage, the resulting autoregressive ImageBART model progressively incorporates context from previous stages in a coarse-to-fine manner. Experiments show greatly improved image modification capabilities over autoregressive models while also providing high-fidelity image generation, both of which are enabled through efficient training in a compressed latent space. Specifically, our approach can take unrestricted, user-provided masks into account to perform local image editing. Thus, in contrast to pure autoregressive models, it can solve free-form image inpainting and, in the case of conditional models, local, text-guided image modification without requiring mask-specific training.
Symbolic Replay: Scene Graph as Prompt for Continual Learning on VQA Task
Aug 29, 2022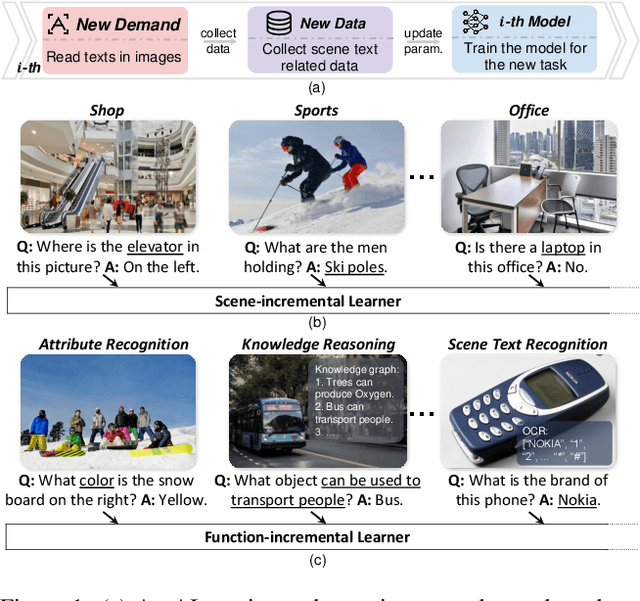
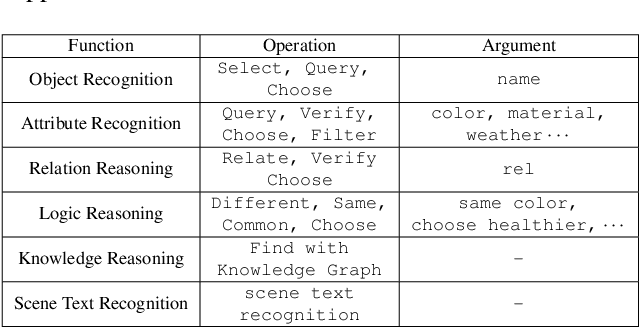
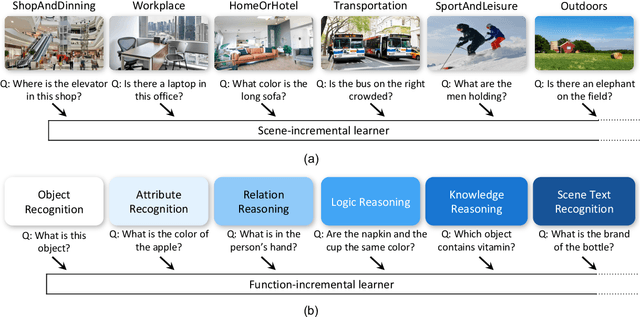
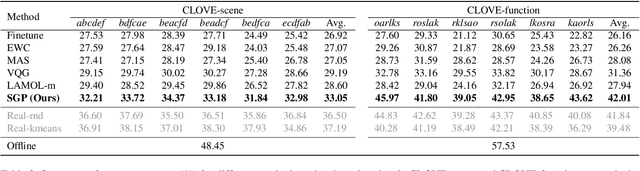
VQA is an ambitious task aiming to answer any image-related question. However, in reality, it is hard to build such a system once for all since the needs of users are continuously updated, and the system has to implement new functions. Thus, Continual Learning (CL) ability is a must in developing advanced VQA systems. Recently, a pioneer work split a VQA dataset into disjoint answer sets to study this topic. However, CL on VQA involves not only the expansion of label sets (new Answer sets). It is crucial to study how to answer questions when deploying VQA systems to new environments (new Visual scenes) and how to answer questions requiring new functions (new Question types). Thus, we propose CLOVE, a benchmark for Continual Learning On Visual quEstion answering, which contains scene- and function-incremental settings for the two aforementioned CL scenarios. In terms of methodology, the main difference between CL on VQA and classification is that the former additionally involves expanding and preventing forgetting of reasoning mechanisms, while the latter focusing on class representation. Thus, we propose a real-data-free replay-based method tailored for CL on VQA, named Scene Graph as Prompt for Symbolic Replay. Using a piece of scene graph as a prompt, it replays pseudo scene graphs to represent the past images, along with correlated QA pairs. A unified VQA model is also proposed to utilize the current and replayed data to enhance its QA ability. Finally, experimental results reveal challenges in CLOVE and demonstrate the effectiveness of our method. The dataset and code will be available at https://github.com/showlab/CLVQA.
CoMoGAN: continuous model-guided image-to-image translation
Apr 08, 2021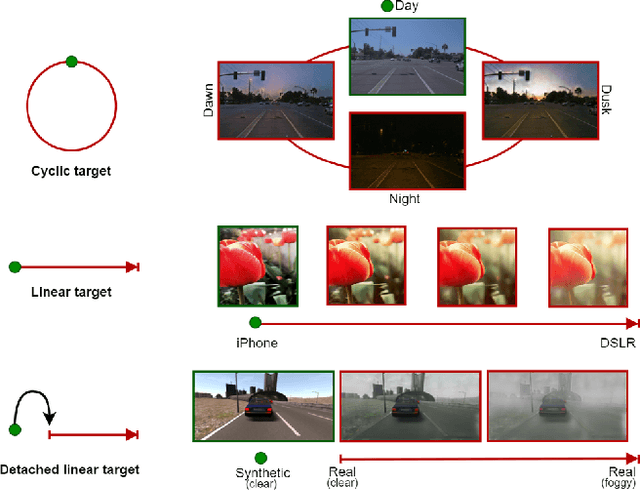

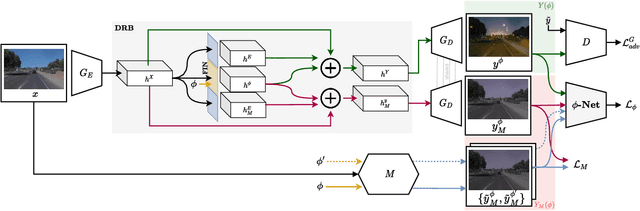
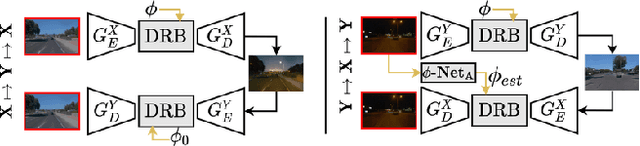
CoMoGAN is a continuous GAN relying on the unsupervised reorganization of the target data on a functional manifold. To that matter, we introduce a new Functional Instance Normalization layer and residual mechanism, which together disentangle image content from position on target manifold. We rely on naive physics-inspired models to guide the training while allowing private model/translations features. CoMoGAN can be used with any GAN backbone and allows new types of image translation, such as cyclic image translation like timelapse generation, or detached linear translation. On all datasets, it outperforms the literature. Our code is available at http://github.com/cv-rits/CoMoGAN .
Swin Deformable Attention U-Net Transformer (SDAUT) for Explainable Fast MRI
Jul 05, 2022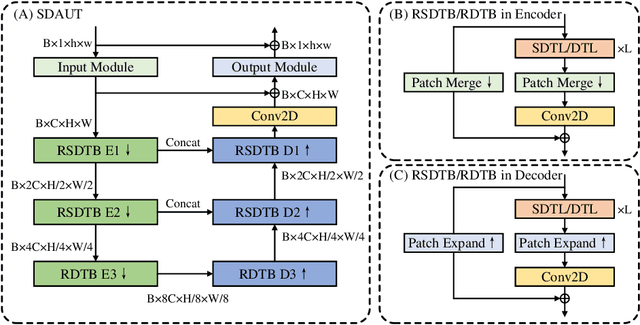
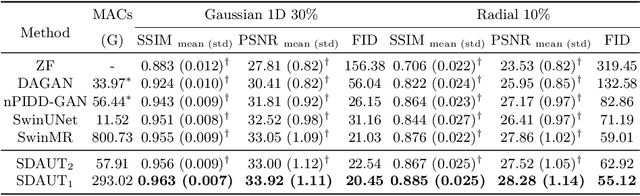
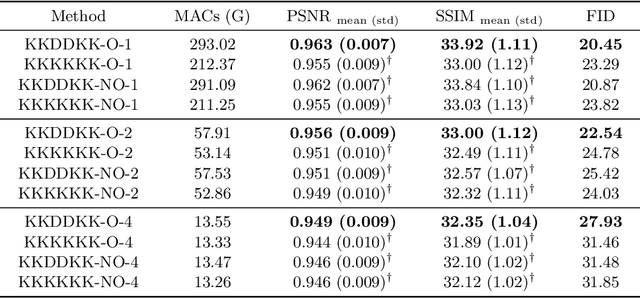
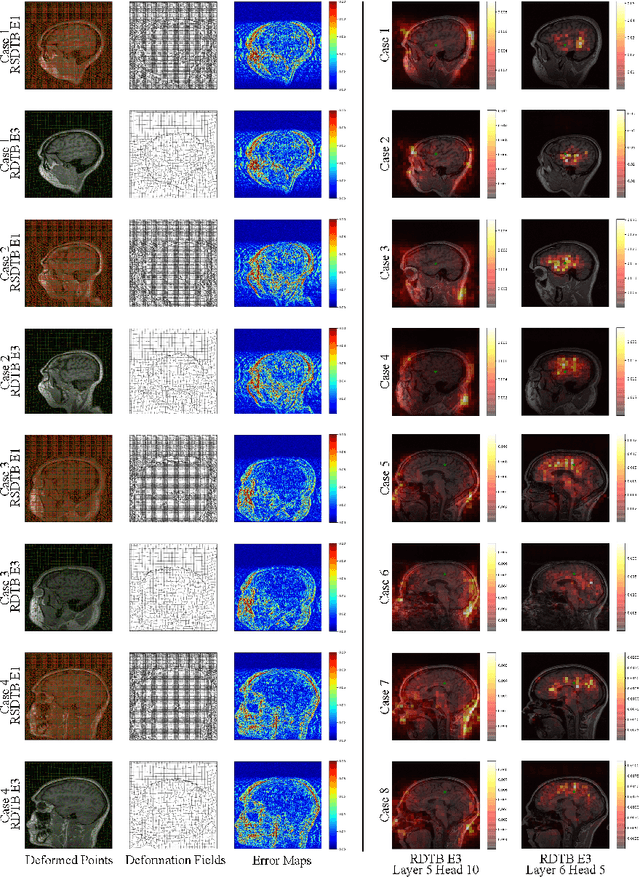
Fast MRI aims to reconstruct a high fidelity image from partially observed measurements. Exuberant development in fast MRI using deep learning has been witnessed recently. Meanwhile, novel deep learning paradigms, e.g., Transformer based models, are fast-growing in natural language processing and promptly developed for computer vision and medical image analysis due to their prominent performance. Nevertheless, due to the complexity of the Transformer, the application of fast MRI may not be straightforward. The main obstacle is the computational cost of the self-attention layer, which is the core part of the Transformer, can be expensive for high resolution MRI inputs. In this study, we propose a new Transformer architecture for solving fast MRI that coupled Shifted Windows Transformer with U-Net to reduce the network complexity. We incorporate deformable attention to construe the explainability of our reconstruction model. We empirically demonstrate that our method achieves consistently superior performance on the fast MRI task. Besides, compared to state-of-the-art Transformer models, our method has fewer network parameters while revealing explainability. The code is publicly available at https://github.com/ayanglab/SDAUT.
An Overview of Color Transfer and Style Transfer for Images and Videos
Apr 28, 2022
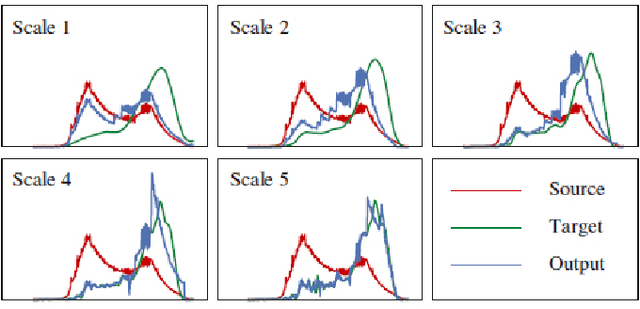


Image or video appearance features (e.g., color, texture, tone, illumination, and so on) reflect one's visual perception and direct impression of an image or video. Given a source image (video) and a target image (video), the image (video) color transfer technique aims to process the color of the source image or video (note that the source image or video is also referred to the reference image or video in some literature) to make it look like that of the target image or video, i.e., transferring the appearance of the target image or video to that of the source image or video, which can thereby change one's perception of the source image or video. As an extension of color transfer, style transfer refers to rendering the content of a target image or video in the style of an artist with either a style sample or a set of images through a style transfer model. As an emerging field, the study of style transfer has attracted the attention of a large number of researchers. After decades of development, it has become a highly interdisciplinary research with a variety of artistic expression styles can be achieved. This paper provides an overview of color transfer and style transfer methods over the past years.
Combining Image Features and Patient Metadata to Enhance Transfer Learning
Oct 08, 2021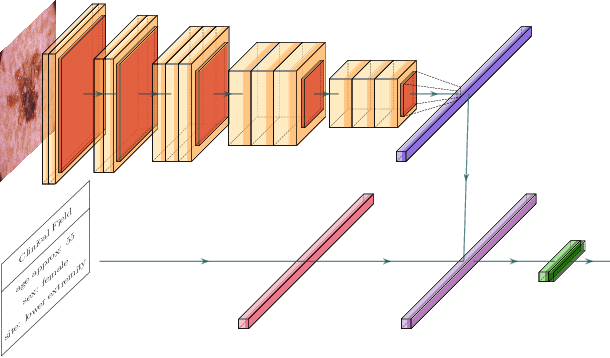
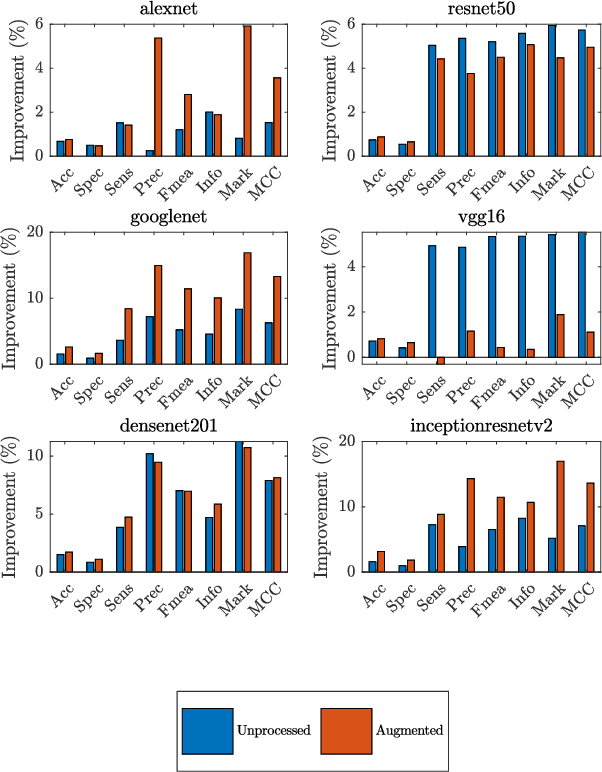
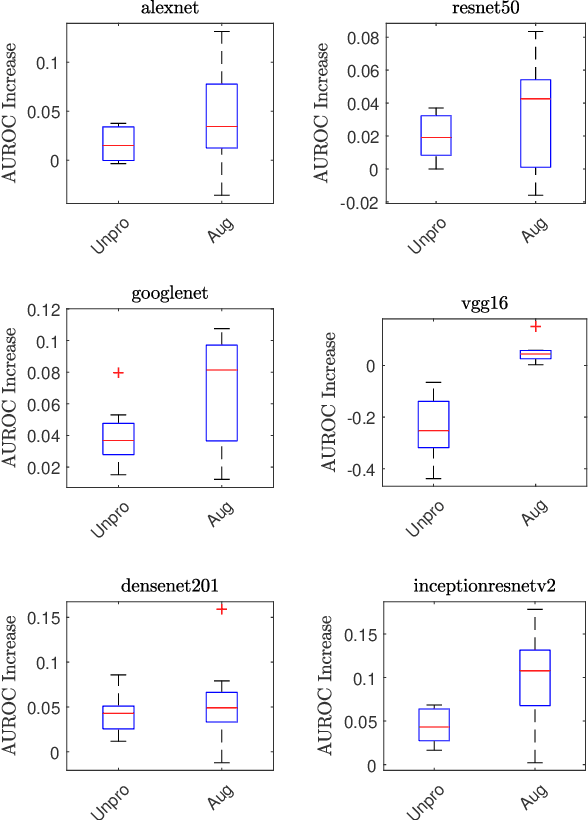
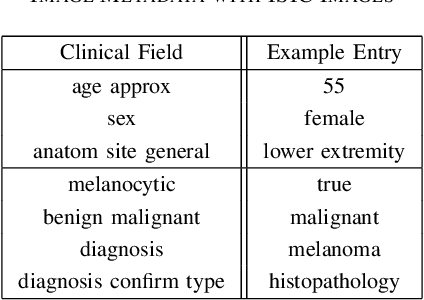
In this work, we compare the performance of six state-of-the-art deep neural networks in classification tasks when using only image features, to when these are combined with patient metadata. We utilise transfer learning from networks pretrained on ImageNet to extract image features from the ISIC HAM10000 dataset prior to classification. Using several classification performance metrics, we evaluate the effects of including metadata with the image features. Furthermore, we repeat our experiments with data augmentation. Our results show an overall enhancement in performance of each network as assessed by all metrics, only noting degradation in a vgg16 architecture. Our results indicate that this performance enhancement may be a general property of deep networks and should be explored in other areas. Moreover, these improvements come at a negligible additional cost in computation time, and therefore are a practical method for other applications.
Early Stopping for Deep Image Prior
Dec 11, 2021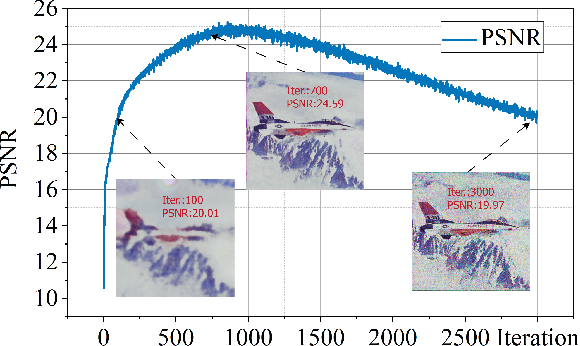

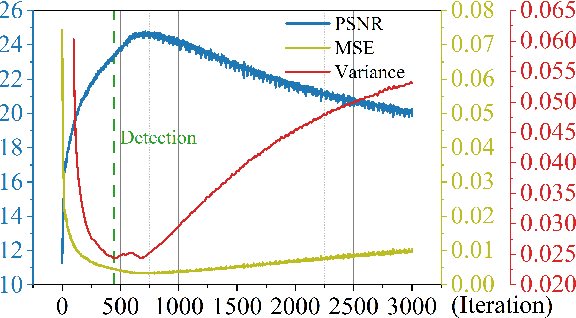
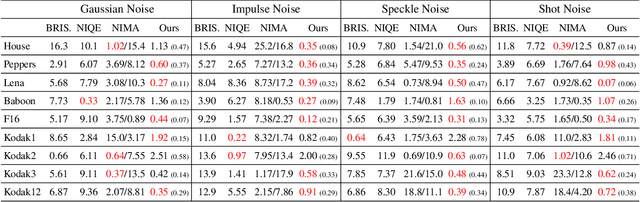
Deep image prior (DIP) and its variants have showed remarkable potential for solving inverse problems in computer vision, without any extra training data. Practical DIP models are often substantially overparameterized. During the fitting process, these models learn mostly the desired visual content first, and then pick up the potential modeling and observational noise, i.e., overfitting. Thus, the practicality of DIP often depends critically on good early stopping (ES) that captures the transition period. In this regard, the majority of DIP works for vision tasks only demonstrates the potential of the models -- reporting the peak performance against the ground truth, but provides no clue about how to operationally obtain near-peak performance without access to the groundtruth. In this paper, we set to break this practicality barrier of DIP, and propose an efficient ES strategy, which consistently detects near-peak performance across several vision tasks and DIP variants. Based on a simple measure of dispersion of consecutive DIP reconstructions, our ES method not only outpaces the existing ones -- which only work in very narrow domains, but also remains effective when combined with a number of methods that try to mitigate the overfitting. The code is available at https://github.com/sun-umn/Early_Stopping_for_DIP.
Evaluating Continual Test-Time Adaptation for Contextual and Semantic Domain Shifts
Aug 18, 2022
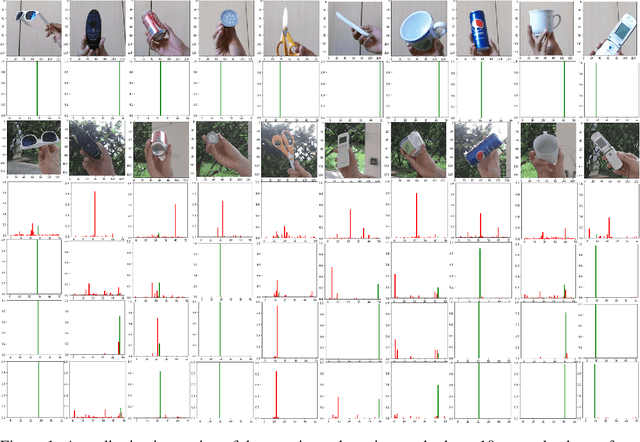

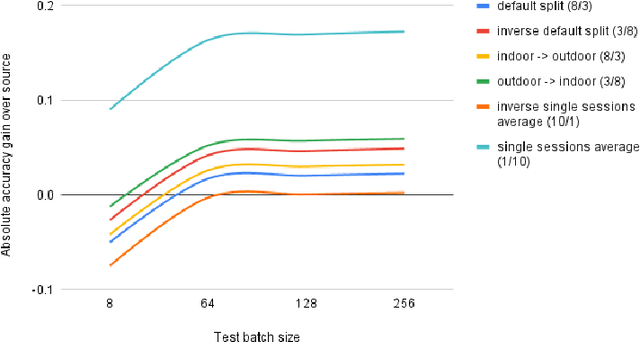
In this paper, our goal is to adapt a pre-trained Convolutional Neural Network to domain shifts at test time. We do so continually with the incoming stream of test batches, without labels. Existing literature mostly operates on artificial shifts obtained via adversarial perturbations of a test image. Motivated by this, we evaluate the state of the art on two realistic and challenging sources of domain shifts, namely contextual and semantic shifts. Contextual shifts correspond to the environment types, for example a model pre-trained on indoor context has to adapt to the outdoor context on CORe-50 [7]. Semantic shifts correspond to the capture types, for example a model pre-trained on natural images has to adapt to cliparts, sketches and paintings on DomainNet [10]. We include in our analysis recent techniques such as Prediction-Time Batch Normalization (BN) [8], Test Entropy Minimization (TENT) [16] and Continual Test-Time Adaptation (CoTTA) [17]. Our findings are three-fold: i) Test-time adaptation methods perform better and forget less on contextual shifts compared to semantic shifts, ii) TENT outperforms other methods on short-term adaptation, whereas CoTTA outpeforms other methods on long-term adaptation, iii) BN is most reliable and robust.