 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Breast shape estimation and correction in CESM biopsy
Jul 28, 2022
Description of purpose: Contrast-enhanced spectral mammography can be used to guide needle biopsies. However, in vertical approach the compressed breast is deformed generating a so-called bump in the paddle aperture, which may interfere with the visibility of contrast-uptakes. Local thickness estimation would provide an enhanced image quality of the recombined image, increasing the visibility of the contrast-uptakes to be targeted during the biopsy procedure. In this work we propose a method to estimate the shape of the breast bump in biopsy vertical approach. Materials and Methods: Our method consists on two steps: first, we compute a raw thickness which does not take into account the presence of contrast-uptakes; second, we use a physical model to separate the sparse iodine texture from the breast shape. This physical model is composed by a sum of Fourier components, describing the main shape of the bump, a series of low-order polynomials, describing the main compressed thickness, paddle tilt and deflection, and non-linear components describing the translation and rotation of the paddle aperture. A 3D object mimicking a bump was fabricated to test the pertinence of our shape model. Also, clinical images of 21 patients which followed CESM-guided biopsy were visually assessed. Results: Comparison between raw and final estimated thickness of our 3D test object shows an error standard deviation of 0.37 mm similar to the noise standard deviation equals to 0.32 mm. The visual assessment of clinical cases showed that the thickness correction removes the superimposed low-frequency pattern due to non-uniform thickness of the bump, improving the identification of the lesion to be targeted. Conclusion: The proposed method for thickness estimation is adapted to CESM-guided biopsies in vertical approach and it improves the identification of the contrast-uptakes that need to be targeted during the procedure.
VMRF: View Matching Neural Radiance Fields
Jul 06, 2022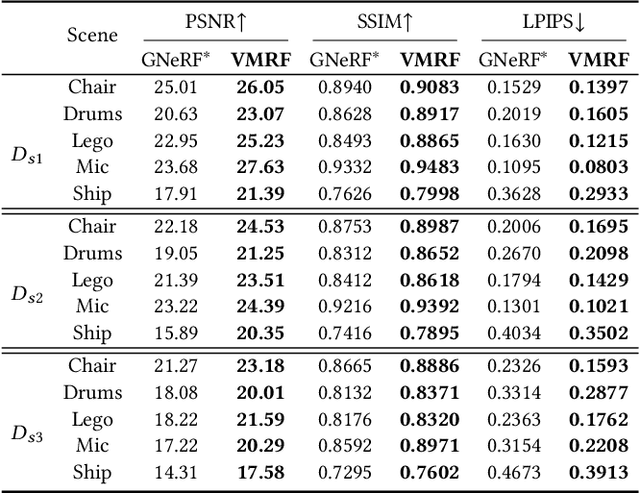
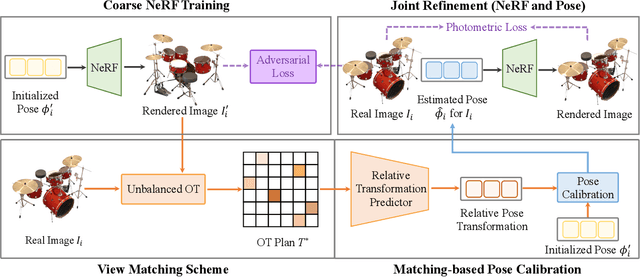
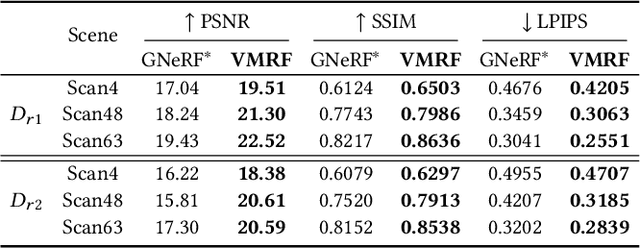
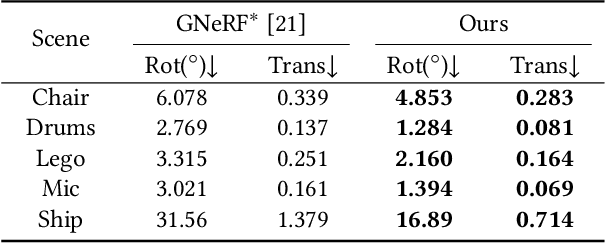
Neural Radiance Fields (NeRF) have demonstrated very impressive performance in novel view synthesis via implicitly modelling 3D representations from multi-view 2D images. However, most existing studies train NeRF models with either reasonable camera pose initialization or manually-crafted camera pose distributions which are often unavailable or hard to acquire in various real-world data. We design VMRF, an innovative view matching NeRF that enables effective NeRF training without requiring prior knowledge in camera poses or camera pose distributions. VMRF introduces a view matching scheme, which exploits unbalanced optimal transport to produce a feature transport plan for mapping a rendered image with randomly initialized camera pose to the corresponding real image. With the feature transport plan as the guidance, a novel pose calibration technique is designed which rectifies the initially randomized camera poses by predicting relative pose transformations between the pair of rendered and real images. Extensive experiments over a number of synthetic and real datasets show that the proposed VMRF outperforms the state-of-the-art qualitatively and quantitatively by large margins.
Bayesian Pseudo Labels: Expectation Maximization for Robust and Efficient Semi-Supervised Segmentation
Aug 08, 2022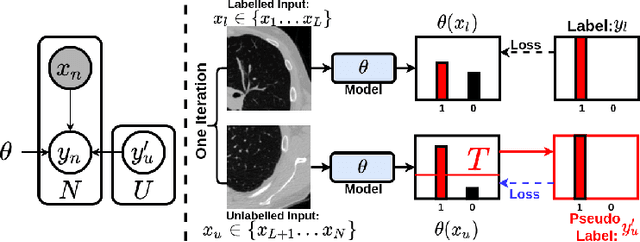
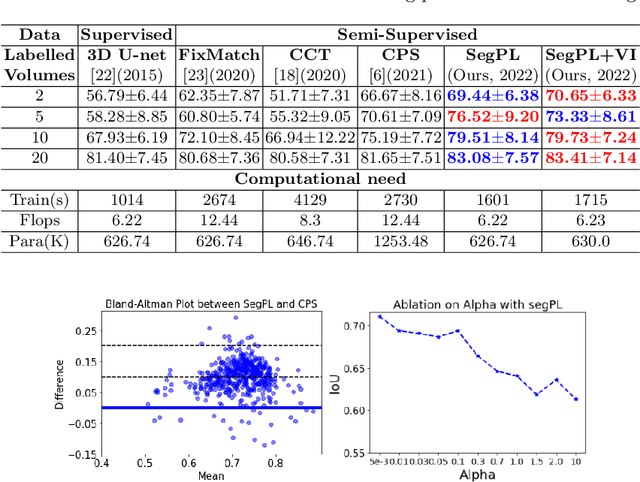
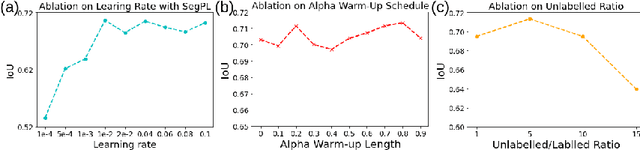
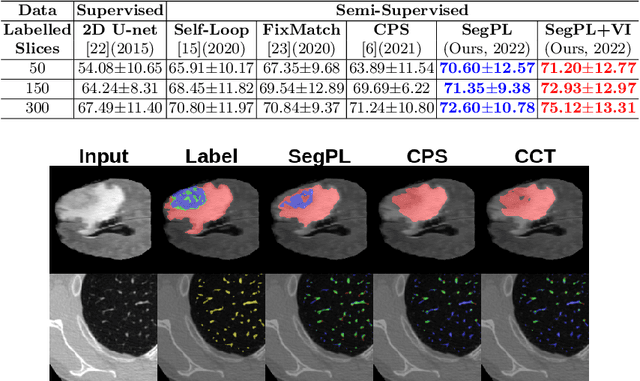
This paper concerns pseudo labelling in segmentation. Our contribution is fourfold. Firstly, we present a new formulation of pseudo-labelling as an Expectation-Maximization (EM) algorithm for clear statistical interpretation. Secondly, we propose a semi-supervised medical image segmentation method purely based on the original pseudo labelling, namely SegPL. We demonstrate SegPL is a competitive approach against state-of-the-art consistency regularisation based methods on semi-supervised segmentation on a 2D multi-class MRI brain tumour segmentation task and a 3D binary CT lung vessel segmentation task. The simplicity of SegPL allows less computational cost comparing to prior methods. Thirdly, we demonstrate that the effectiveness of SegPL may originate from its robustness against out-of-distribution noises and adversarial attacks. Lastly, under the EM framework, we introduce a probabilistic generalisation of SegPL via variational inference, which learns a dynamic threshold for pseudo labelling during the training. We show that SegPL with variational inference can perform uncertainty estimation on par with the gold-standard method Deep Ensemble.
PoseBERT: A Generic Transformer Module for Temporal 3D Human Modeling
Aug 22, 2022
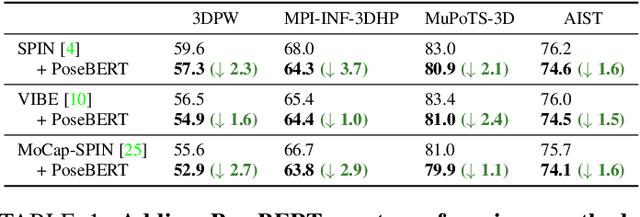
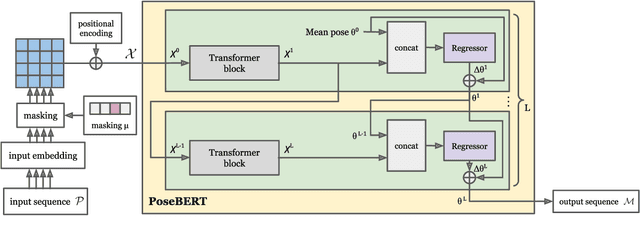
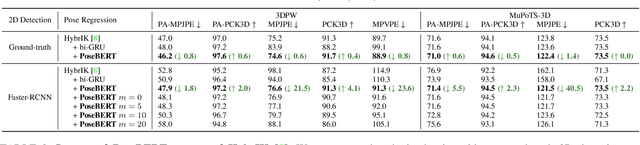
Training state-of-the-art models for human pose estimation in videos requires datasets with annotations that are really hard and expensive to obtain. Although transformers have been recently utilized for body pose sequence modeling, related methods rely on pseudo-ground truth to augment the currently limited training data available for learning such models. In this paper, we introduce PoseBERT, a transformer module that is fully trained on 3D Motion Capture (MoCap) data via masked modeling. It is simple, generic and versatile, as it can be plugged on top of any image-based model to transform it in a video-based model leveraging temporal information. We showcase variants of PoseBERT with different inputs varying from 3D skeleton keypoints to rotations of a 3D parametric model for either the full body (SMPL) or just the hands (MANO). Since PoseBERT training is task agnostic, the model can be applied to several tasks such as pose refinement, future pose prediction or motion completion without finetuning. Our experimental results validate that adding PoseBERT on top of various state-of-the-art pose estimation methods consistently improves their performances, while its low computational cost allows us to use it in a real-time demo for smoothly animating a robotic hand via a webcam. Test code and models are available at https://github.com/naver/posebert.
Satellite Detection in Unresolved Space Imagery for Space Domain Awareness Using Neural Networks
Jul 23, 2022


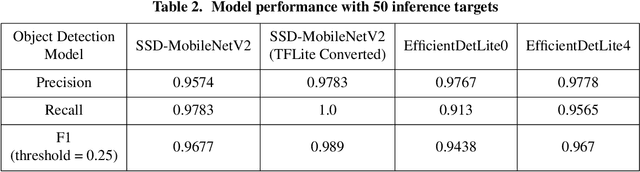
This work utilizes a MobileNetV2 Convolutional Neural Network (CNN) for fast, mobile detection of satellites, and rejection of stars, in cluttered unresolved space imagery. First, a custom database is created using imagery from a synthetic satellite image program and labeled with bounding boxes over satellites for "satellite-positive" images. The CNN is then trained on this database and the inference is validated by checking the accuracy of the model on an external dataset constructed of real telescope imagery. In doing so, the trained CNN provides a method of rapid satellite identification for subsequent utilization in ground-based orbit estimation.
Visual Transformers with Primal Object Queries for Multi-Label Image Classification
Dec 10, 2021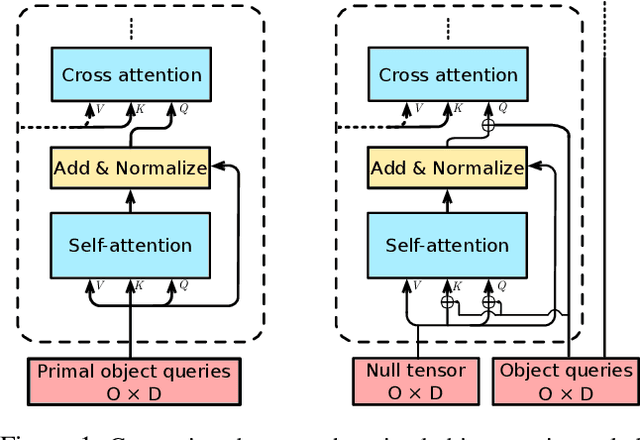
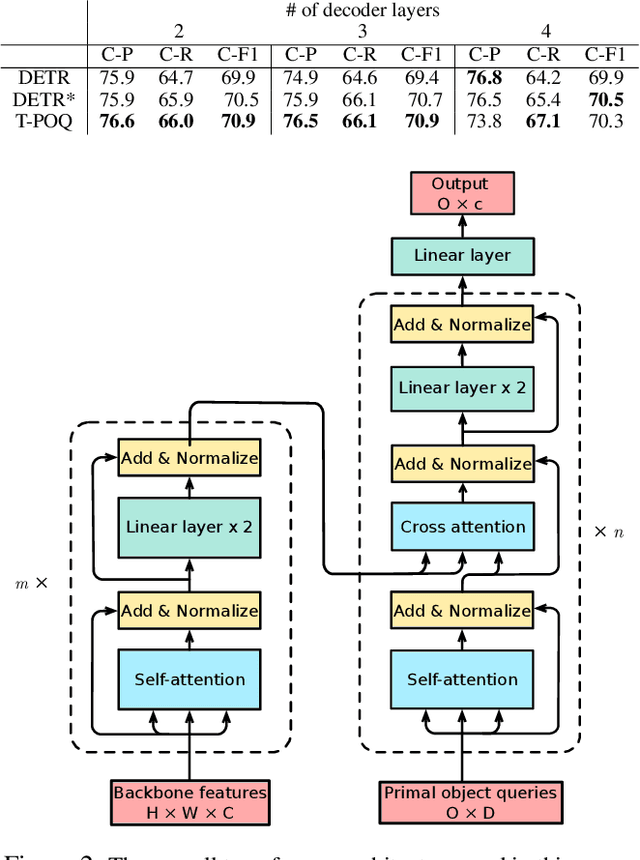
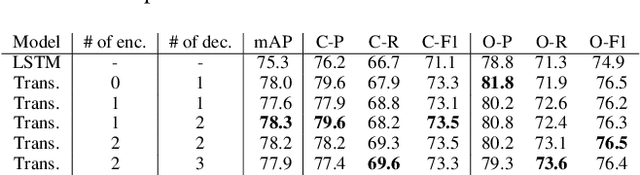

Multi-label image classification is about predicting a set of class labels that can be considered as orderless sequential data. Transformers process the sequential data as a whole, therefore they are inherently good at set prediction. The first vision-based transformer model, which was proposed for the object detection task introduced the concept of object queries. Object queries are learnable positional encodings that are used by attention modules in decoder layers to decode the object classes or bounding boxes using the region of interests in an image. However, inputting the same set of object queries to different decoder layers hinders the training: it results in lower performance and delays convergence. In this paper, we propose the usage of primal object queries that are only provided at the start of the transformer decoder stack. In addition, we improve the mixup technique proposed for multi-label classification. The proposed transformer model with primal object queries improves the state-of-the-art class wise F1 metric by 2.1% and 1.8%; and speeds up the convergence by 79.0% and 38.6% on MS-COCO and NUS-WIDE datasets respectively.
Generalization and Overfitting in Matrix Product State Machine Learning Architectures
Aug 08, 2022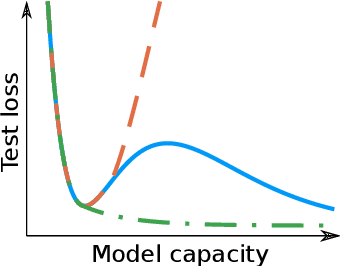
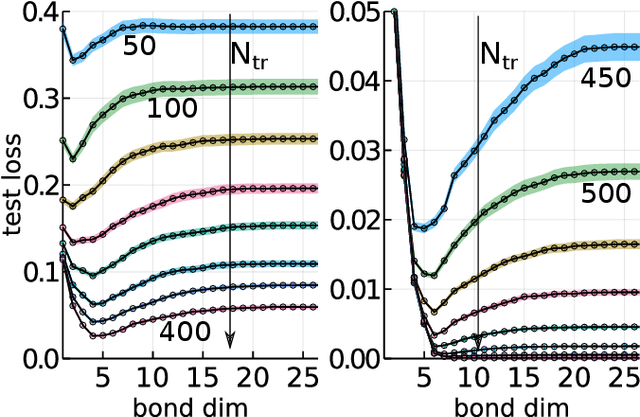
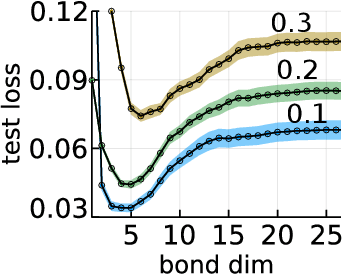
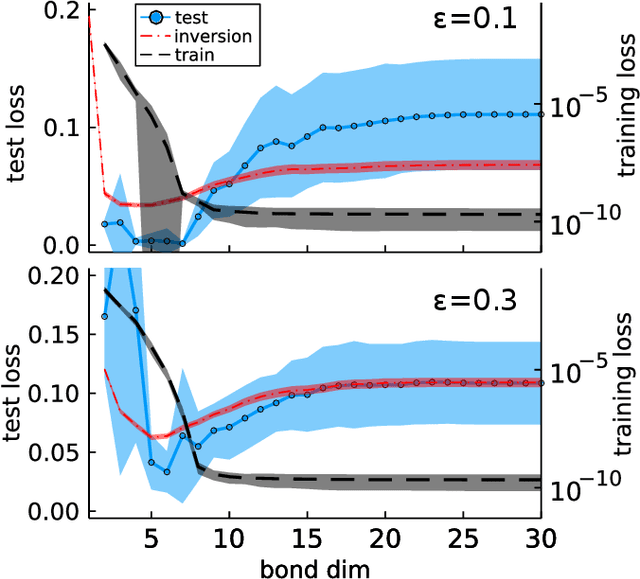
While overfitting and, more generally, double descent are ubiquitous in machine learning, increasing the number of parameters of the most widely used tensor network, the matrix product state (MPS), has generally lead to monotonic improvement of test performance in previous studies. To better understand the generalization properties of architectures parameterized by MPS, we construct artificial data which can be exactly modeled by an MPS and train the models with different number of parameters. We observe model overfitting for one-dimensional data, but also find that for more complex data overfitting is less significant, while with MNIST image data we do not find any signatures of overfitting. We speculate that generalization properties of MPS depend on the properties of data: with one-dimensional data (for which the MPS ansatz is the most suitable) MPS is prone to overfitting, while with more complex data which cannot be fit by MPS exactly, overfitting may be much less significant.
CoMoGAN: continuous model-guided image-to-image translation
Apr 08, 2021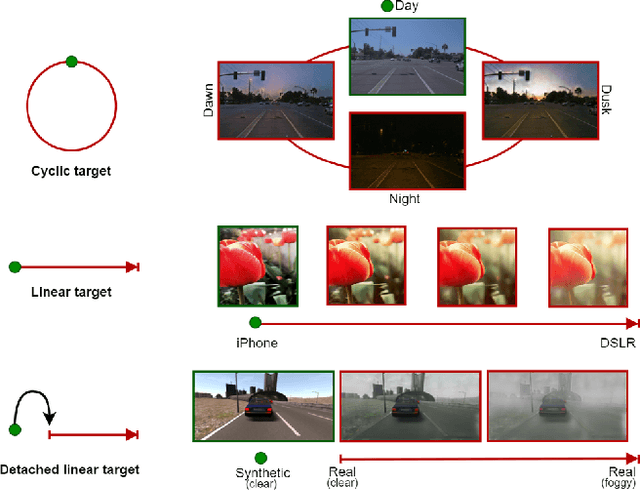

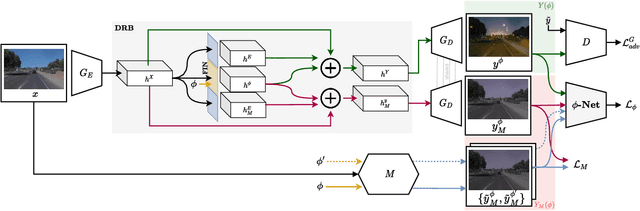
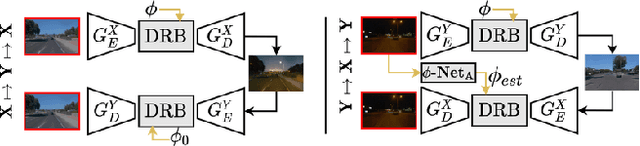
CoMoGAN is a continuous GAN relying on the unsupervised reorganization of the target data on a functional manifold. To that matter, we introduce a new Functional Instance Normalization layer and residual mechanism, which together disentangle image content from position on target manifold. We rely on naive physics-inspired models to guide the training while allowing private model/translations features. CoMoGAN can be used with any GAN backbone and allows new types of image translation, such as cyclic image translation like timelapse generation, or detached linear translation. On all datasets, it outperforms the literature. Our code is available at http://github.com/cv-rits/CoMoGAN .
Aesthetics Driven Autonomous Time-Lapse Photography Generation by Virtual and Real Robots
Aug 22, 2022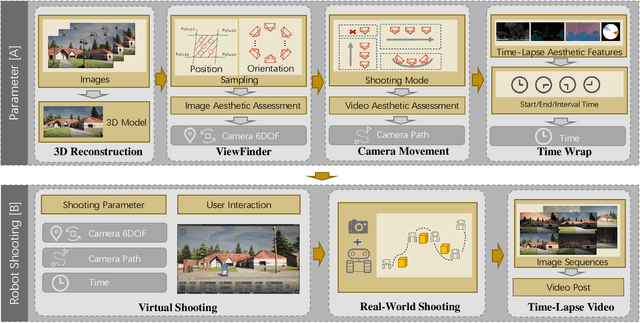
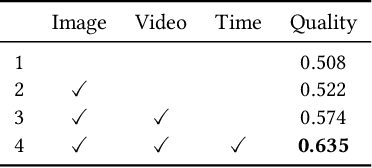

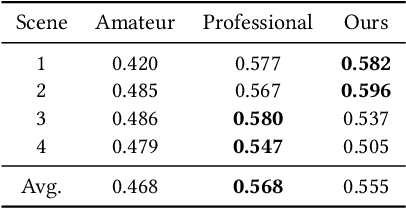
Time-lapse photography is employed in movies and promotional films because it can reflect the passage of time in a short time and strengthen the visual attraction. However, since it takes a long time and requires the stable shooting, it is a great challenge for the photographer. In this article, we propose a time-lapse photography system with virtual and real robots. To help users shoot time-lapse videos efficiently, we first parameterize the time-lapse photography and propose a parameter optimization method. For different parameters, different aesthetic models, including image and video aesthetic quality assessment networks, are used to generate optimal parameters. Then we propose a time-lapse photography interface to facilitate users to view and adjust parameters and use virtual robots to conduct virtual photography in a three-dimensional scene. The system can also export the parameters and provide them to real robots so that the time-lapse videos can be filmed in the real world. In addition, we propose a time-lapse photography aesthetic assessment method that can automatically evaluate the aesthetic quality of time-lapse video. The experimental results show that our method can efficiently obtain the time-lapse videos. We also conduct a user study. The results show that our system has the similar effect as professional photographers and is more efficient.
Semi-Supervised Cross-Modal Salient Object Detection with U-Structure Networks
Aug 08, 2022
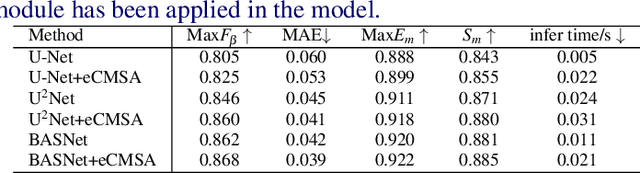

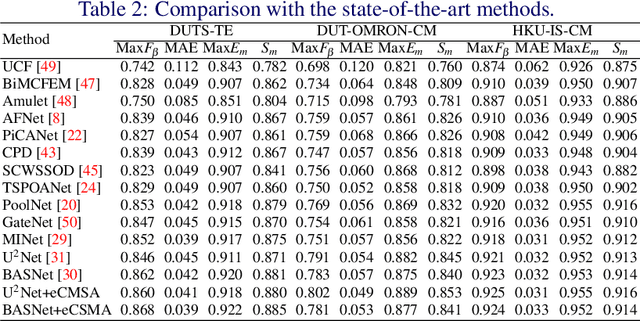
Salient Object Detection (SOD) is a popular and important topic aimed at precise detection and segmentation of the interesting regions in the images. We integrate the linguistic information into the vision-based U-Structure networks designed for salient object detection tasks. The experiments are based on the newly created DUTS Cross Modal (DUTS-CM) dataset, which contains both visual and linguistic labels. We propose a new module called efficient Cross-Modal Self-Attention (eCMSA) to combine visual and linguistic features and improve the performance of the original U-structure networks. Meanwhile, to reduce the heavy burden of labeling, we employ a semi-supervised learning method by training an image caption model based on the DUTS-CM dataset, which can automatically label other datasets like DUT-OMRON and HKU-IS. The comprehensive experiments show that the performance of SOD can be improved with the natural language input and is competitive compared with other SOD methods.