 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Treating Point Cloud as Moving Camera Videos: A No-Reference Quality Assessment Metric
Aug 30, 2022

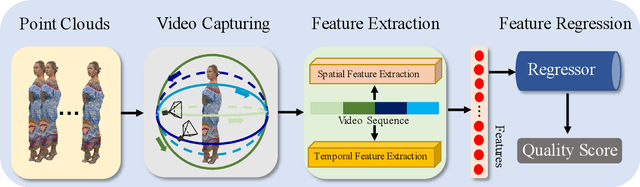
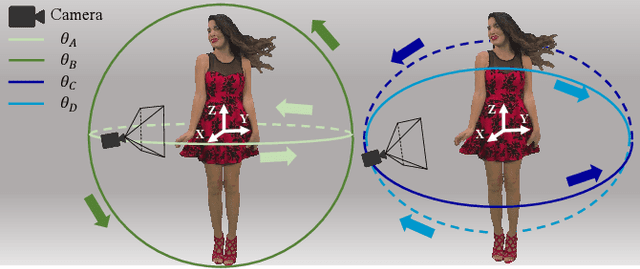
Point cloud is one of the most widely used digital representation formats for 3D contents, the visual quality of which may suffer from noise and geometric shift during the production procedure as well as compression and downsampling during the transmission process. To tackle the challenge of point cloud quality assessment (PCQA), many PCQA methods have been proposed to evaluate the visual quality levels of point clouds by assessing the rendered static 2D projections. Although such projection-based PCQA methods achieve competitive performance with the assistance of mature image quality assessment (IQA) methods, they neglect the dynamic quality-aware information, which does not fully match the fact that observers tend to perceive the point clouds through both static and dynamic views. Therefore, in this paper, we treat the point clouds as moving camera videos and explore the way of dealing with PCQA tasks via using video quality assessment (VQA) methods in a no-reference (NR) manner. First, we generate the captured videos by rotating the camera around the point clouds through four circular pathways. Then we extract both spatial and temporal quality-aware features from the selected key frames and the video clips by using trainable 2D-CNN and pre-trained 3D-CNN models respectively. Finally, the visual quality of point clouds is represented by the regressed video quality values. The experimental results reveal that the proposed method is effective for predicting the visual quality levels of the point clouds and even competitive with full-reference (FR) PCQA methods. The ablation studies further verify the rationality of the proposed framework and confirm the contributions made by the quality-aware features extracted from dynamic views.
An Image Patch is a Wave: Phase-Aware Vision MLP
Nov 24, 2021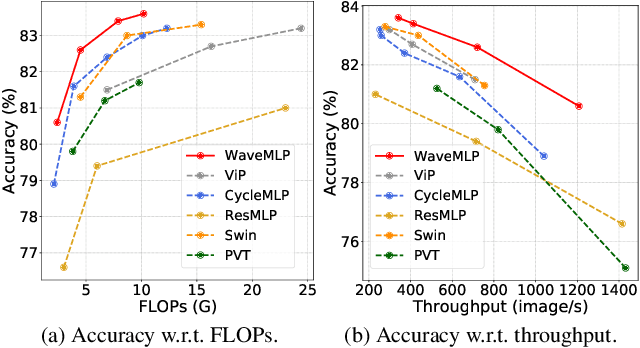
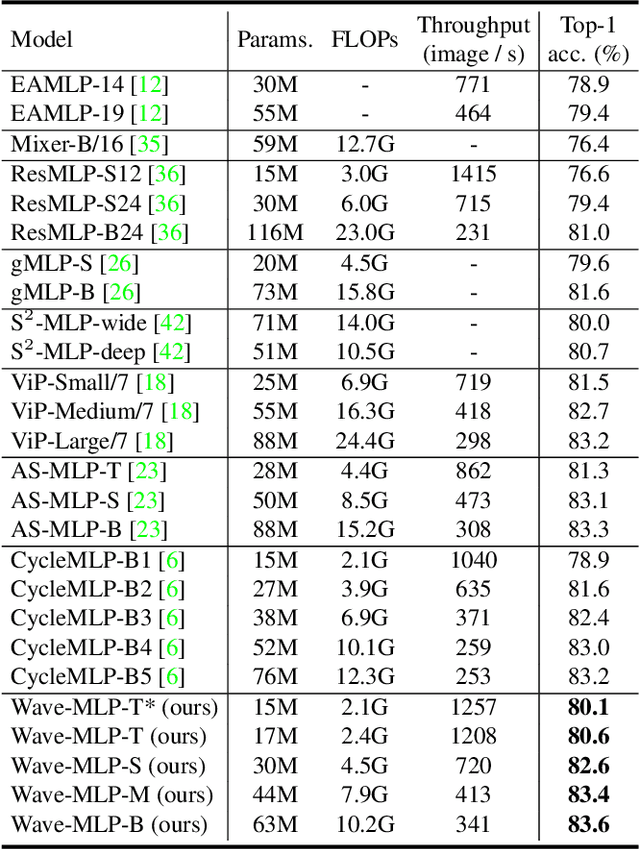
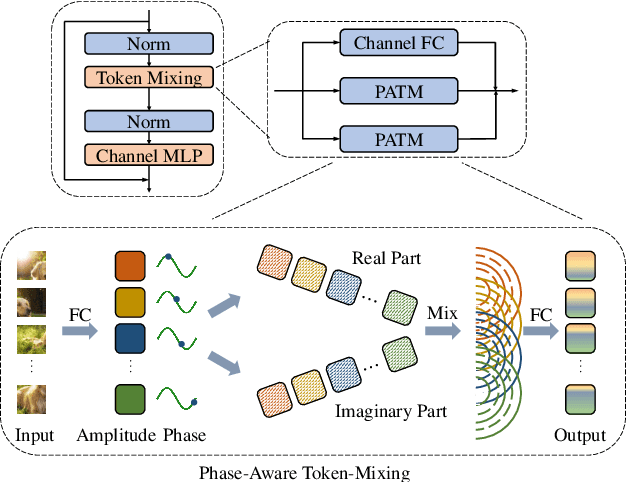
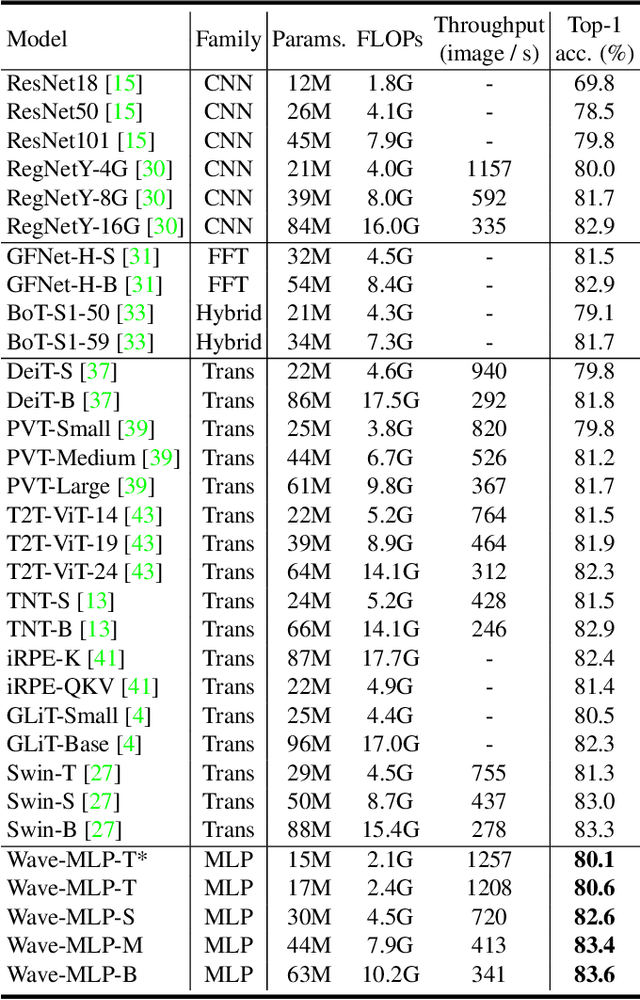
Different from traditional convolutional neural network (CNN) and vision transformer, the multilayer perceptron (MLP) is a new kind of vision model with extremely simple architecture that only stacked by fully-connected layers. An input image of vision MLP is usually split into multiple tokens (patches), while the existing MLP models directly aggregate them with fixed weights, neglecting the varying semantic information of tokens from different images. To dynamically aggregate tokens, we propose to represent each token as a wave function with two parts, amplitude and phase. Amplitude is the original feature and the phase term is a complex value changing according to the semantic contents of input images. Introducing the phase term can dynamically modulate the relationship between tokens and fixed weights in MLP. Based on the wave-like token representation, we establish a novel Wave-MLP architecture for vision tasks. Extensive experiments demonstrate that the proposed Wave-MLP is superior to the state-of-the-art MLP architectures on various vision tasks such as image classification, object detection and semantic segmentation.
Improved $α$-GAN architecture for generating 3D connected volumes with an application to radiosurgery treatment planning
Jul 13, 2022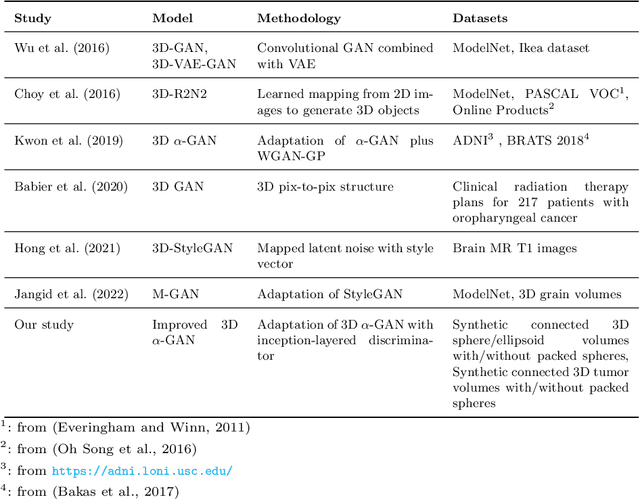
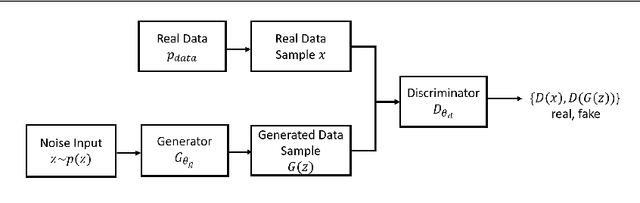
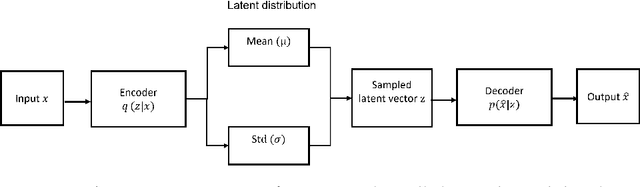
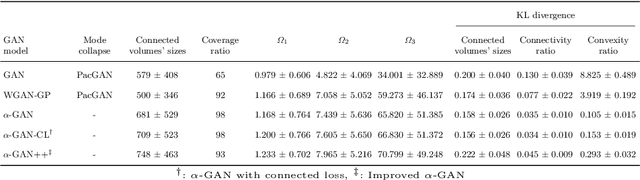
Generative Adversarial Networks (GANs) have gained significant attention in several computer vision tasks for generating high-quality synthetic data. Various medical applications including diagnostic imaging and radiation therapy can benefit greatly from synthetic data generation due to data scarcity in the domain. However, medical image data is typically kept in 3D space, and generative models suffer from the curse of dimensionality issues in generating such synthetic data. In this paper, we investigate the potential of GANs for generating connected 3D volumes. We propose an improved version of 3D $\alpha$-GAN by incorporating various architectural enhancements. On a synthetic dataset of connected 3D spheres and ellipsoids, our model can generate fully connected 3D shapes with similar geometrical characteristics to that of training data. We also show that our 3D GAN model can successfully generate high-quality 3D tumor volumes and associated treatment specifications (e.g., isocenter locations). Similar moment invariants to the training data as well as fully connected 3D shapes confirm that improved 3D $\alpha$-GAN implicitly learns the training data distribution, and generates realistic-looking samples. The capability of improved 3D $\alpha$-GAN makes it a valuable source for generating synthetic medical image data that can help future research in this domain.
Breast shape estimation and correction in CESM biopsy
Jul 28, 2022Description of purpose: Contrast-enhanced spectral mammography can be used to guide needle biopsies. However, in vertical approach the compressed breast is deformed generating a so-called bump in the paddle aperture, which may interfere with the visibility of contrast-uptakes. Local thickness estimation would provide an enhanced image quality of the recombined image, increasing the visibility of the contrast-uptakes to be targeted during the biopsy procedure. In this work we propose a method to estimate the shape of the breast bump in biopsy vertical approach. Materials and Methods: Our method consists on two steps: first, we compute a raw thickness which does not take into account the presence of contrast-uptakes; second, we use a physical model to separate the sparse iodine texture from the breast shape. This physical model is composed by a sum of Fourier components, describing the main shape of the bump, a series of low-order polynomials, describing the main compressed thickness, paddle tilt and deflection, and non-linear components describing the translation and rotation of the paddle aperture. A 3D object mimicking a bump was fabricated to test the pertinence of our shape model. Also, clinical images of 21 patients which followed CESM-guided biopsy were visually assessed. Results: Comparison between raw and final estimated thickness of our 3D test object shows an error standard deviation of 0.37 mm similar to the noise standard deviation equals to 0.32 mm. The visual assessment of clinical cases showed that the thickness correction removes the superimposed low-frequency pattern due to non-uniform thickness of the bump, improving the identification of the lesion to be targeted. Conclusion: The proposed method for thickness estimation is adapted to CESM-guided biopsies in vertical approach and it improves the identification of the contrast-uptakes that need to be targeted during the procedure.
Asian Giant Hornet Control based on Image Processing and Biological Dispersal
Nov 26, 2021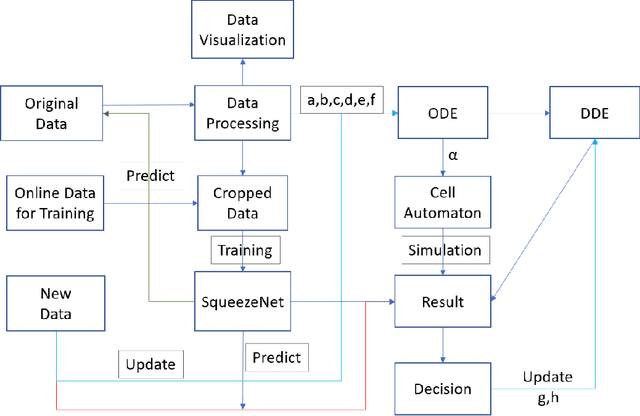


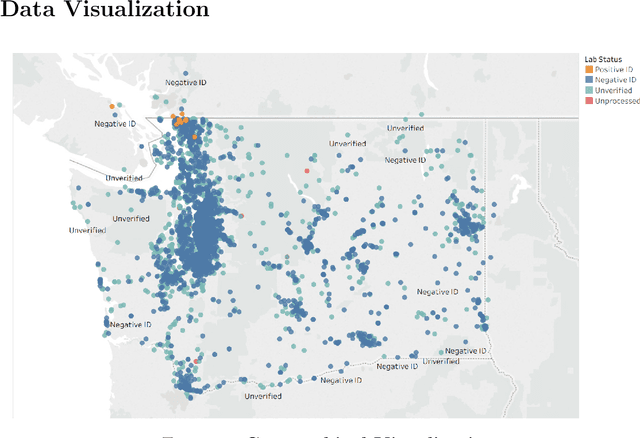
The Asian giant hornet (AGH) appeared in Washington State appears to have a potential danger of bioinvasion. Washington State has collected public photos and videos of detected insects for verification and further investigation. In this paper, we analyze AGH using data analysis,statistics, discrete mathematics, and deep learning techniques to process the data to controlAGH spreading.First, we visualize the geographical distribution of insects in Washington State. Then we investigate insect populations to varying months of the year and different days of a month.Third, we employ wavelet analysis to examine the periodic spread of AGH. Fourth, we apply ordinary differential equations to examine AGH numbers at the different natural growthrate and reaction speed and output the potential propagation coefficient. Next, we leverage cellular automaton combined with the potential propagation coefficient to simulate the geographical spread under changing potential propagation. To update the model, we use delayed differential equations to simulate human intervention. We use the time difference between detection time and submission time to determine the unit of time to delay time. After that, we construct a lightweight CNN called SqueezeNet and assess its classification performance. We then relate several non-reference image quality metrics, including NIQE, image gradient, entropy, contrast, and TOPSIS to judge the cause of misclassification. Furthermore, we build a Random Forest classifier to identify positive and negative samples based on image qualities only. We also display the feature importance and conduct an error analysis. Besides, we present sensitivity analysis to verify the robustness of our models. Finally, we show the strengths and weaknesses of our model and derives the conclusions.
Bayesian Pseudo Labels: Expectation Maximization for Robust and Efficient Semi-Supervised Segmentation
Aug 08, 2022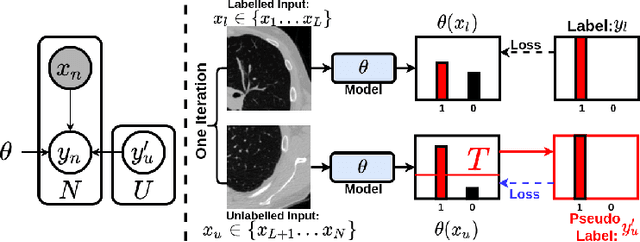
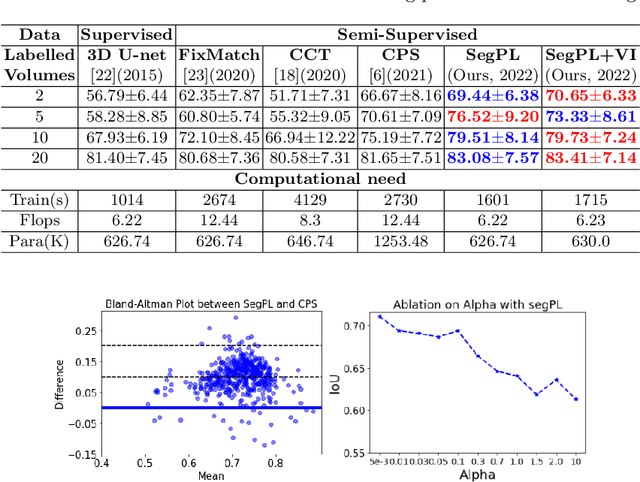
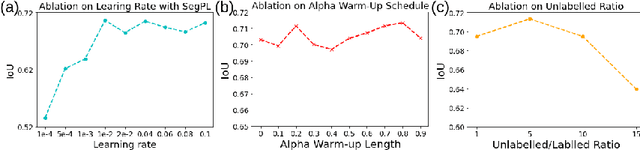
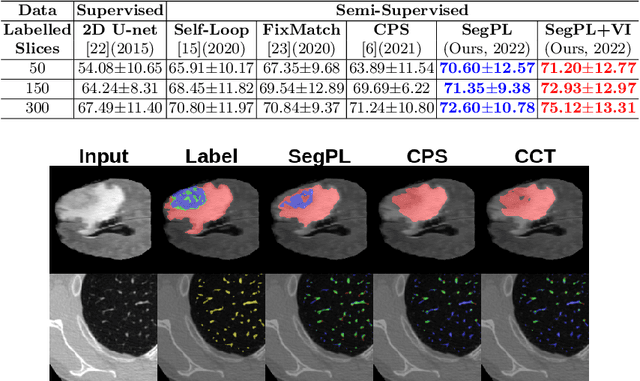
This paper concerns pseudo labelling in segmentation. Our contribution is fourfold. Firstly, we present a new formulation of pseudo-labelling as an Expectation-Maximization (EM) algorithm for clear statistical interpretation. Secondly, we propose a semi-supervised medical image segmentation method purely based on the original pseudo labelling, namely SegPL. We demonstrate SegPL is a competitive approach against state-of-the-art consistency regularisation based methods on semi-supervised segmentation on a 2D multi-class MRI brain tumour segmentation task and a 3D binary CT lung vessel segmentation task. The simplicity of SegPL allows less computational cost comparing to prior methods. Thirdly, we demonstrate that the effectiveness of SegPL may originate from its robustness against out-of-distribution noises and adversarial attacks. Lastly, under the EM framework, we introduce a probabilistic generalisation of SegPL via variational inference, which learns a dynamic threshold for pseudo labelling during the training. We show that SegPL with variational inference can perform uncertainty estimation on par with the gold-standard method Deep Ensemble.
A Simple Approach to Image Tilt Correction with Self-Attention MobileNet for Smartphones
Oct 31, 2021

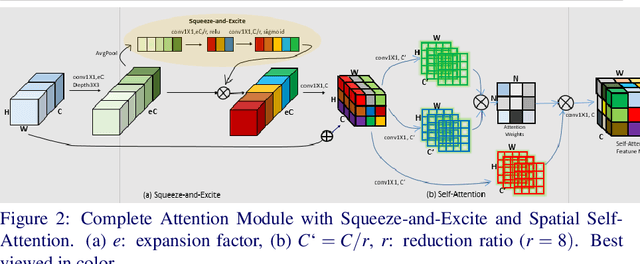
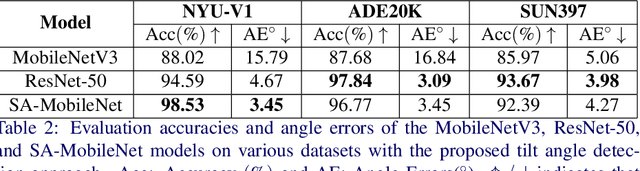
The main contributions of our work are two-fold. First, we present a Self-Attention MobileNet, called SA-MobileNet Network that can model long-range dependencies between the image features instead of processing the local region as done by standard convolutional kernels. SA-MobileNet contains self-attention modules integrated with the inverted bottleneck blocks of the MobileNetV3 model which results in modeling of both channel-wise attention and spatial attention of the image features and at the same time introduce a novel self-attention architecture for low-resource devices. Secondly, we propose a novel training pipeline for the task of image tilt detection. We treat this problem in a multi-label scenario where we predict multiple angles for a tilted input image in a narrow interval of range 1-2 degrees, depending on the dataset used. This process induces an implicit correlation between labels without any computational overhead of the second or higher-order methods in multi-label learning. With the combination of our novel approach and the architecture, we present state-of-the-art results on detecting the image tilt angle on mobile devices as compared to the MobileNetV3 model. Finally, we establish that SA-MobileNet is more accurate than MobileNetV3 on SUN397, NYU-V1, and ADE20K datasets by 6.42%, 10.51%, and 9.09% points respectively, and faster by at least 4 milliseconds on Snapdragon 750 Octa-core.
PoseBERT: A Generic Transformer Module for Temporal 3D Human Modeling
Aug 22, 2022
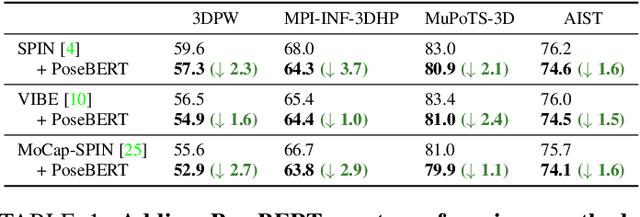
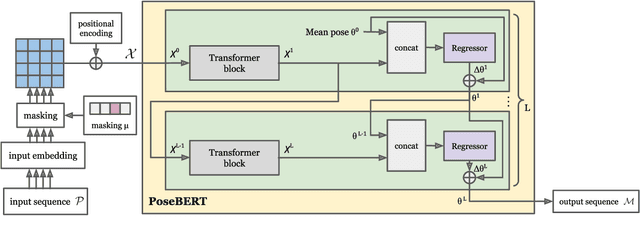
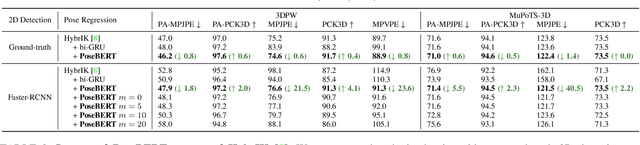
Training state-of-the-art models for human pose estimation in videos requires datasets with annotations that are really hard and expensive to obtain. Although transformers have been recently utilized for body pose sequence modeling, related methods rely on pseudo-ground truth to augment the currently limited training data available for learning such models. In this paper, we introduce PoseBERT, a transformer module that is fully trained on 3D Motion Capture (MoCap) data via masked modeling. It is simple, generic and versatile, as it can be plugged on top of any image-based model to transform it in a video-based model leveraging temporal information. We showcase variants of PoseBERT with different inputs varying from 3D skeleton keypoints to rotations of a 3D parametric model for either the full body (SMPL) or just the hands (MANO). Since PoseBERT training is task agnostic, the model can be applied to several tasks such as pose refinement, future pose prediction or motion completion without finetuning. Our experimental results validate that adding PoseBERT on top of various state-of-the-art pose estimation methods consistently improves their performances, while its low computational cost allows us to use it in a real-time demo for smoothly animating a robotic hand via a webcam. Test code and models are available at https://github.com/naver/posebert.
VMRF: View Matching Neural Radiance Fields
Jul 06, 2022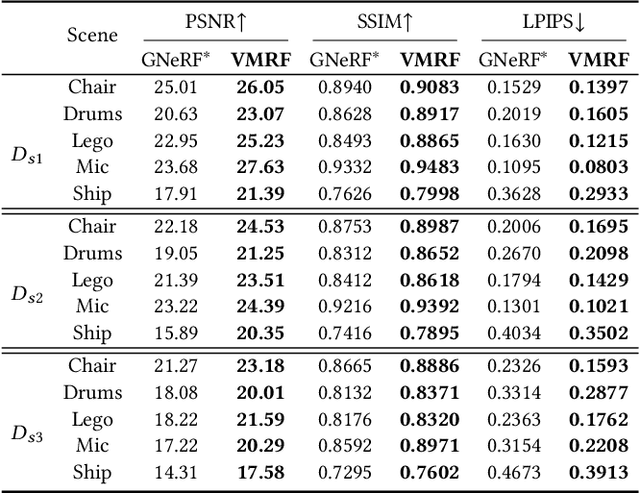
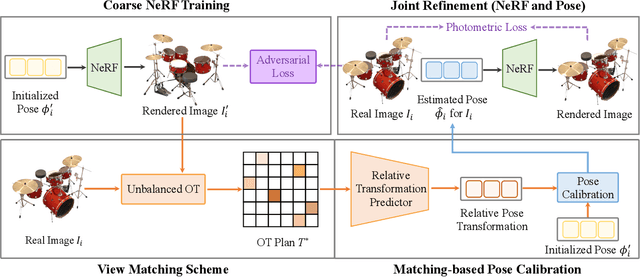
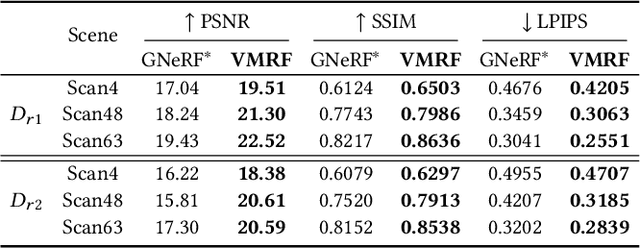
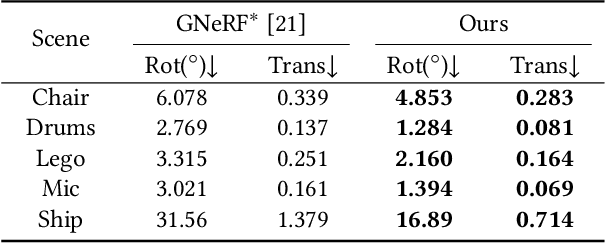
Neural Radiance Fields (NeRF) have demonstrated very impressive performance in novel view synthesis via implicitly modelling 3D representations from multi-view 2D images. However, most existing studies train NeRF models with either reasonable camera pose initialization or manually-crafted camera pose distributions which are often unavailable or hard to acquire in various real-world data. We design VMRF, an innovative view matching NeRF that enables effective NeRF training without requiring prior knowledge in camera poses or camera pose distributions. VMRF introduces a view matching scheme, which exploits unbalanced optimal transport to produce a feature transport plan for mapping a rendered image with randomly initialized camera pose to the corresponding real image. With the feature transport plan as the guidance, a novel pose calibration technique is designed which rectifies the initially randomized camera poses by predicting relative pose transformations between the pair of rendered and real images. Extensive experiments over a number of synthetic and real datasets show that the proposed VMRF outperforms the state-of-the-art qualitatively and quantitatively by large margins.
A Physics-Guided Neural Operator Learning Approach to Model Biological Tissues from Digital Image Correlation Measurements
Apr 01, 2022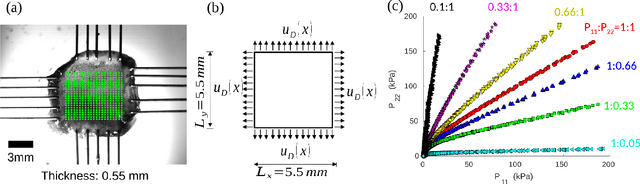
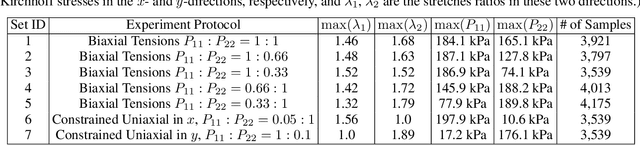
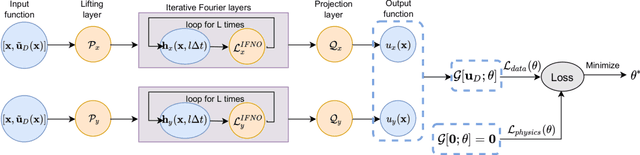
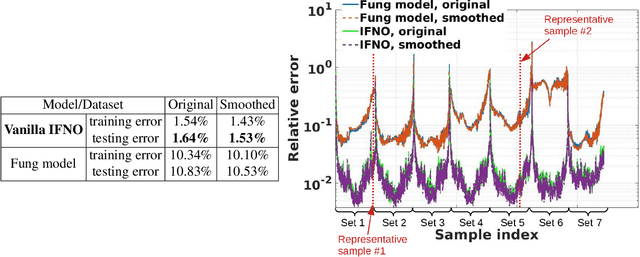
We present a data-driven workflow to biological tissue modeling, which aims to predict the displacement field based on digital image correlation (DIC) measurements under unseen loading scenarios, without postulating a specific constitutive model form nor possessing knowledges on the material microstructure. To this end, a material database is constructed from the DIC displacement tracking measurements of multiple biaxial stretching protocols on a porcine tricuspid valve anterior leaflet, with which we build a neural operator learning model. The material response is modeled as a solution operator from the loading to the resultant displacement field, with the material microstructure properties learned implicitly from the data and naturally embedded in the network parameters. Using various combinations of loading protocols, we compare the predictivity of this framework with finite element analysis based on the phenomenological Fung-type model. From in-distribution tests, the predictivity of our approach presents good generalizability to different loading conditions and outperforms the conventional constitutive modeling at approximately one order of magnitude. When tested on out-of-distribution loading ratios, the neural operator learning approach becomes less effective. To improve the generalizability of our framework, we propose a physics-guided neural operator learning model via imposing partial physics knowledge. This method is shown to improve the model's extrapolative performance in the small-deformation regime. Our results demonstrate that with sufficient data coverage and/or guidance from partial physics constraints, the data-driven approach can be a more effective method for modeling biological materials than the traditional constitutive modeling.