 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
The Weighting Game: Evaluating Quality of Explainability Methods
Aug 12, 2022

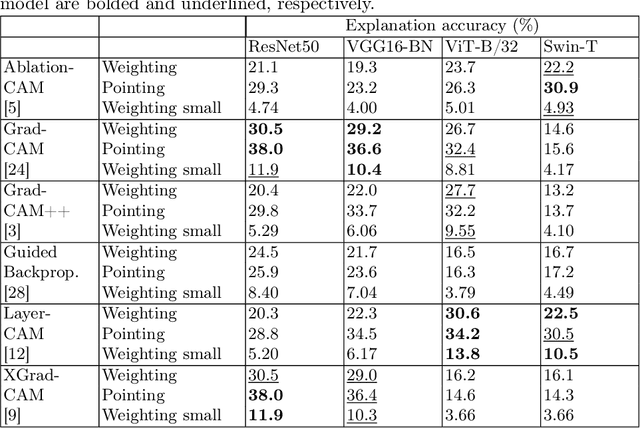

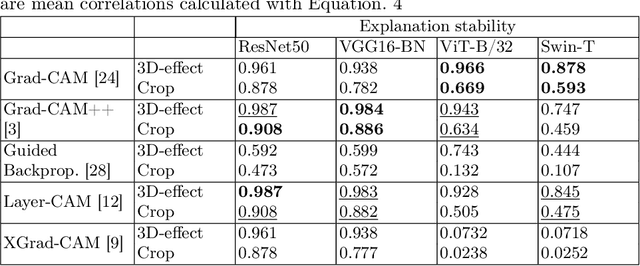
The objective of this paper is to assess the quality of explanation heatmaps for image classification tasks. To assess the quality of explainability methods, we approach the task through the lens of accuracy and stability. In this work, we make the following contributions. Firstly, we introduce the Weighting Game, which measures how much of a class-guided explanation is contained within the correct class' segmentation mask. Secondly, we introduce a metric for explanation stability, using zooming/panning transformations to measure differences between saliency maps with similar contents. Quantitative experiments are produced, using these new metrics, to evaluate the quality of explanations provided by commonly used CAM methods. The quality of explanations is also contrasted between different model architectures, with findings highlighting the need to consider model architecture when choosing an explainability method.
SAR Despeckling using a Denoising Diffusion Probabilistic Model
Jun 09, 2022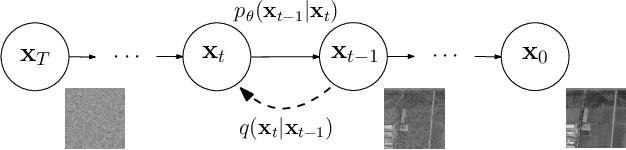


Speckle is a multiplicative noise which affects all coherent imaging modalities including Synthetic Aperture Radar (SAR) images. The presence of speckle degrades the image quality and adversely affects the performance of SAR image understanding applications such as automatic target recognition and change detection. Thus, SAR despeckling is an important problem in remote sensing. In this paper, we introduce SAR-DDPM, a denoising diffusion probabilistic model for SAR despeckling. The proposed method comprises of a Markov chain that transforms clean images to white Gaussian noise by repeatedly adding random noise. The despeckled image is recovered by a reverse process which iteratively predicts the added noise using a noise predictor which is conditioned on the speckled image. In addition, we propose a new inference strategy based on cycle spinning to improve the despeckling performance. Our experiments on both synthetic and real SAR images demonstrate that the proposed method achieves significant improvements in both quantitative and qualitative results over the state-of-the-art despeckling methods.
Adversarial Ensemble Training by Jointly Learning Label Dependencies and Member Models
Jun 29, 2022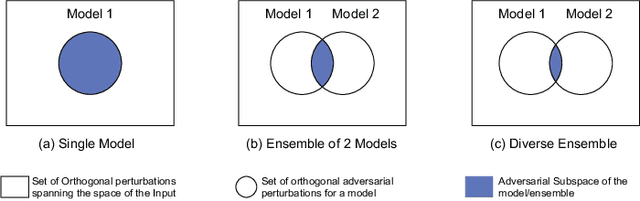
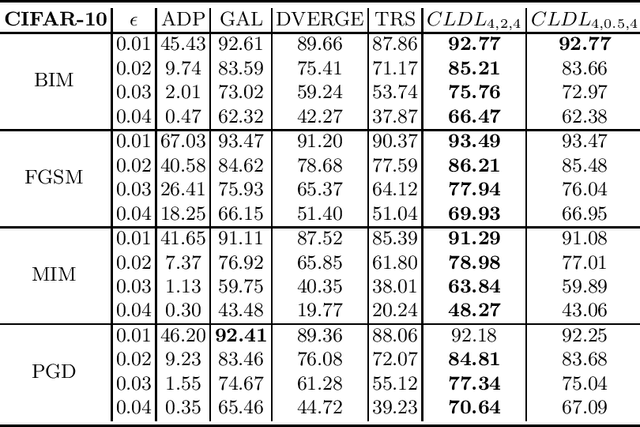
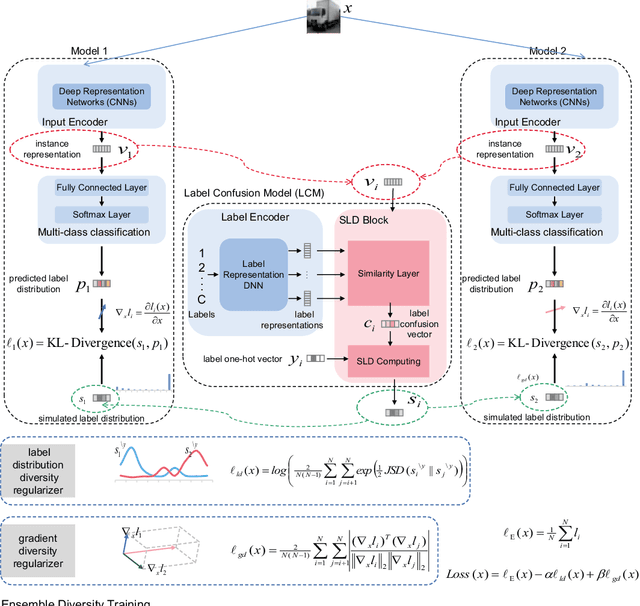
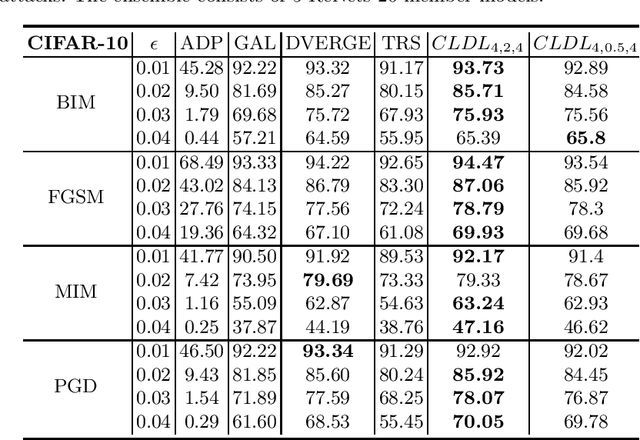
Training an ensemble of different sub-models has empirically proven to be an effective strategy to improve deep neural networks' adversarial robustness. Current ensemble training methods for image recognition usually encode the image labels by one-hot vectors, which neglect dependency relationships between the labels. Here we propose a novel adversarial training approach that learns the conditional dependencies between labels and the model ensemble jointly. We test our approach on widely used datasets MNIST, FasionMNIST and CIFAR-10. Results show that our approach is more robust against black-box attacks compared with state-of-the-art methods. Our code is available at https://github.com/ZJLAB-AMMI/LSD.
Your ViT is Secretly a Hybrid Discriminative-Generative Diffusion Model
Aug 16, 2022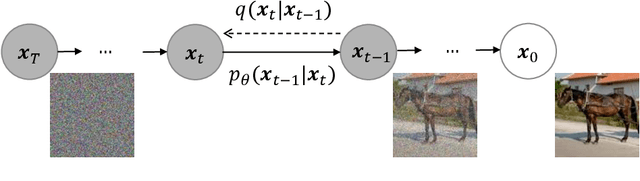
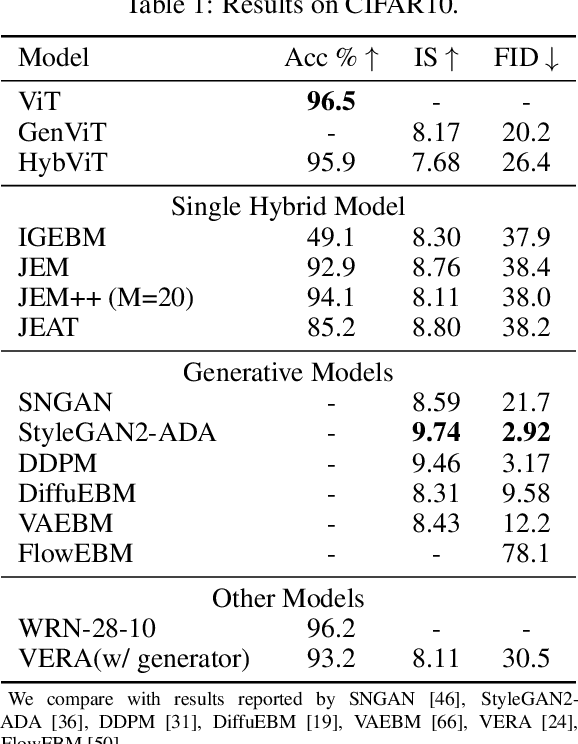
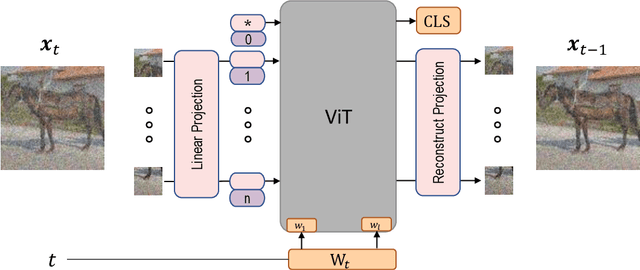
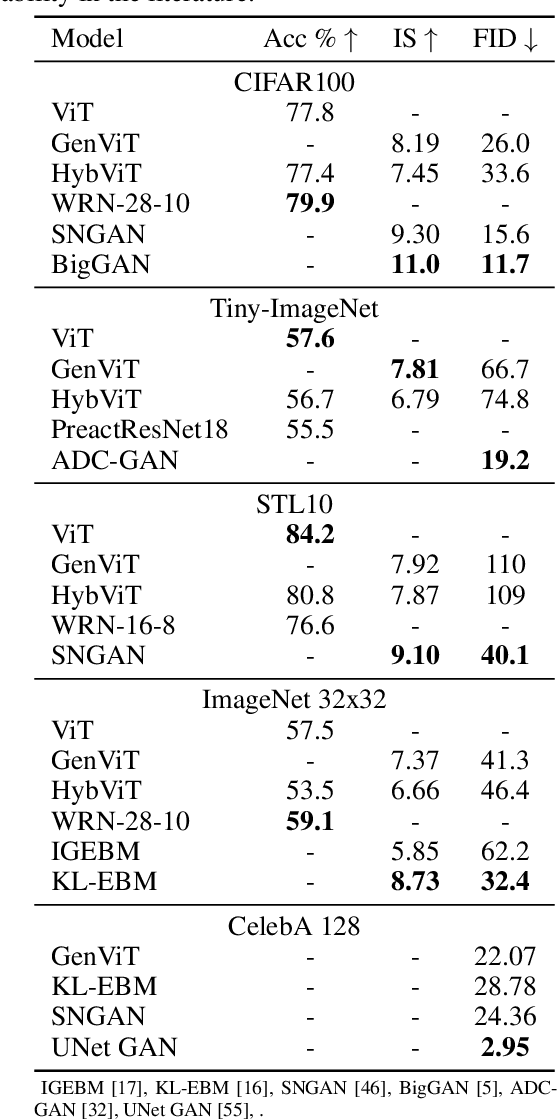
Diffusion Denoising Probability Models (DDPM) and Vision Transformer (ViT) have demonstrated significant progress in generative tasks and discriminative tasks, respectively, and thus far these models have largely been developed in their own domains. In this paper, we establish a direct connection between DDPM and ViT by integrating the ViT architecture into DDPM, and introduce a new generative model called Generative ViT (GenViT). The modeling flexibility of ViT enables us to further extend GenViT to hybrid discriminative-generative modeling, and introduce a Hybrid ViT (HybViT). Our work is among the first to explore a single ViT for image generation and classification jointly. We conduct a series of experiments to analyze the performance of proposed models and demonstrate their superiority over prior state-of-the-arts in both generative and discriminative tasks. Our code and pre-trained models can be found in https://github.com/sndnyang/Diffusion_ViT .
SCSNet: An Efficient Paradigm for Learning Simultaneously Image Colorization and Super-Resolution
Jan 12, 2022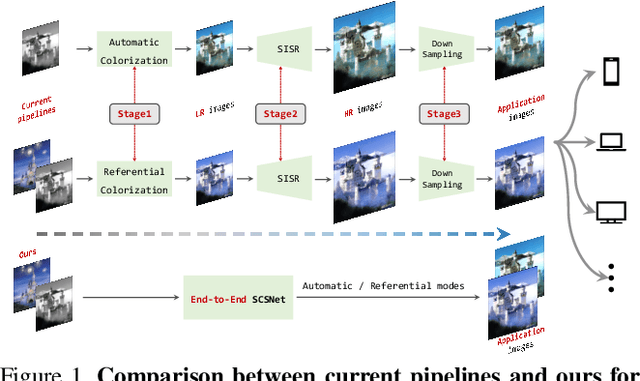
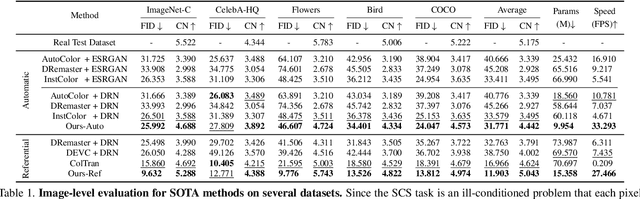

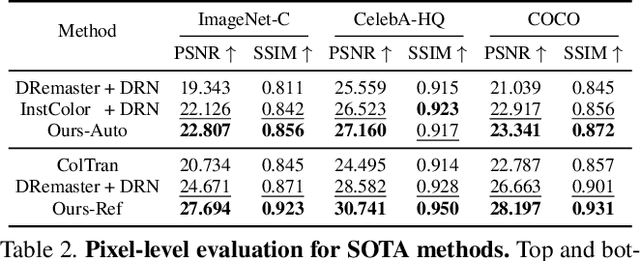
In the practical application of restoring low-resolution gray-scale images, we generally need to run three separate processes of image colorization, super-resolution, and dows-sampling operation for the target device. However, this pipeline is redundant and inefficient for the independent processes, and some inner features could have been shared. Therefore, we present an efficient paradigm to perform {S}imultaneously Image {C}olorization and {S}uper-resolution (SCS) and propose an end-to-end SCSNet to achieve this goal. The proposed method consists of two parts: colorization branch for learning color information that employs the proposed plug-and-play \emph{Pyramid Valve Cross Attention} (PVCAttn) module to aggregate feature maps between source and reference images; and super-resolution branch for integrating color and texture information to predict target images, which uses the designed \emph{Continuous Pixel Mapping} (CPM) module to predict high-resolution images at continuous magnification. Furthermore, our SCSNet supports both automatic and referential modes that is more flexible for practical application. Abundant experiments demonstrate the superiority of our method for generating authentic images over state-of-the-art methods, e.g., averagely decreasing FID by 1.8$\downarrow$ and 5.1 $\downarrow$ compared with current best scores for automatic and referential modes, respectively, while owning fewer parameters (more than $\times$2$\downarrow$) and faster running speed (more than $\times$3$\uparrow$).
Which Generative Adversarial Network Yields High-Quality Synthetic Medical Images: Investigation Using AMD Image Datasets
Mar 25, 2022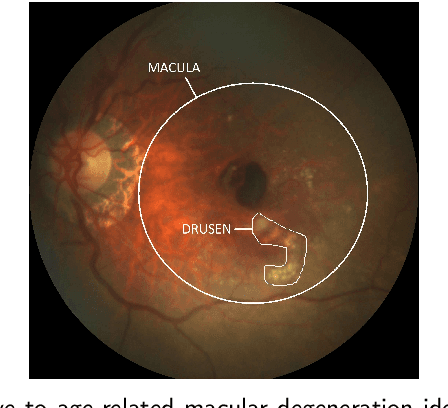

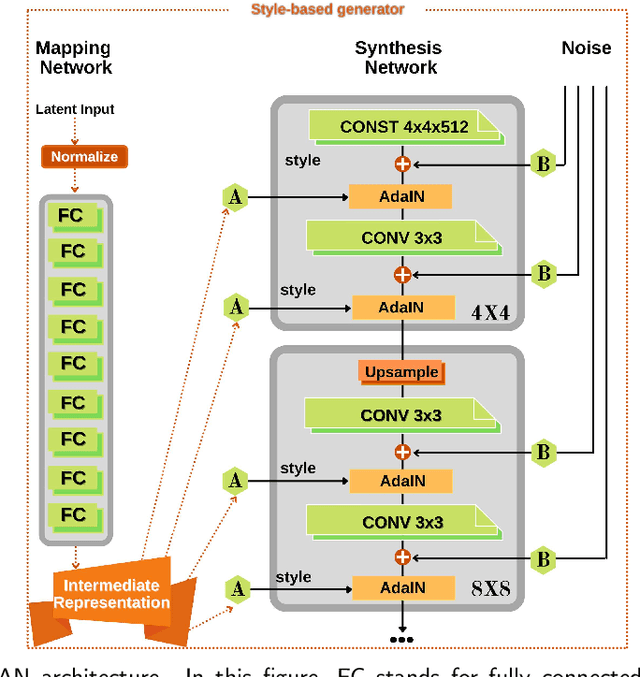

Deep learning has been proposed for the assessment and classification of medical images. However, many medical image databases with appropriately labeled and annotated images are small and imbalanced, and thus unsuitable to train and validate such models. The option is to generate synthetic images and one successful technique has been patented which limits its use for others. We have developed a free-access, alternate method for generating synthetic high-resolution images using Generative Adversarial Networks (GAN) for data augmentation and showed their effectiveness using eye-fundus images for Age-Related Macular Degeneration (AMD) identification. Ten different GAN architectures were compared to generate synthetic eye-fundus images with and without AMD. Data from three public databases were evaluated using the Fr\'echet Inception Distance (FID), two clinical experts and deep-learning classification. The results show that StyleGAN2 reached the lowest FID (166.17), and clinicians could not accurately differentiate between real and synthetic images. ResNet-18 architecture obtained the best performance with 85% accuracy and outperformed the two experts in detecting AMD fundus images, whose average accuracy was 77.5%. These results are similar to a recently patented method, and will provide an alternative to generating high-quality synthetic medical images. Free access has been provided to the entire method to facilitate the further development of this field.
SPSN: Superpixel Prototype Sampling Network for RGB-D Salient Object Detection
Jul 16, 2022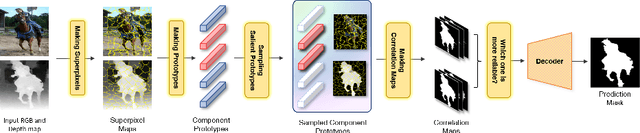
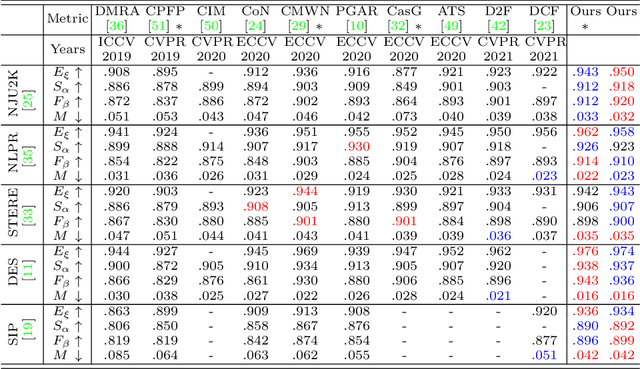
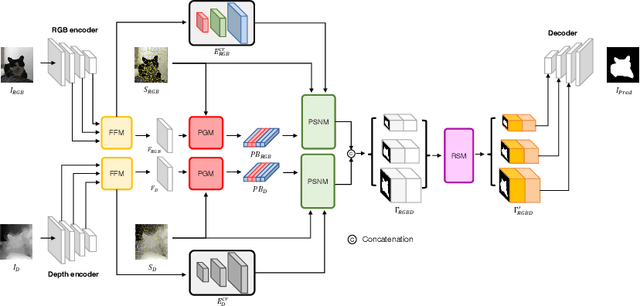
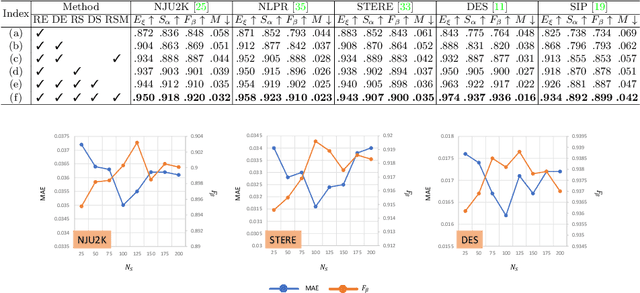
RGB-D salient object detection (SOD) has been in the spotlight recently because it is an important preprocessing operation for various vision tasks. However, despite advances in deep learning-based methods, RGB-D SOD is still challenging due to the large domain gap between an RGB image and the depth map and low-quality depth maps. To solve this problem, we propose a novel superpixel prototype sampling network (SPSN) architecture. The proposed model splits the input RGB image and depth map into component superpixels to generate component prototypes. We design a prototype sampling network so that the network only samples prototypes corresponding to salient objects. In addition, we propose a reliance selection module to recognize the quality of each RGB and depth feature map and adaptively weight them in proportion to their reliability. The proposed method makes the model robust to inconsistencies between RGB images and depth maps and eliminates the influence of non-salient objects. Our method is evaluated on five popular datasets, achieving state-of-the-art performance. We prove the effectiveness of the proposed method through comparative experiments.
Deep-Learning-Based Single-Image Height Reconstruction from Very-High-Resolution SAR Intensity Data
Nov 03, 2021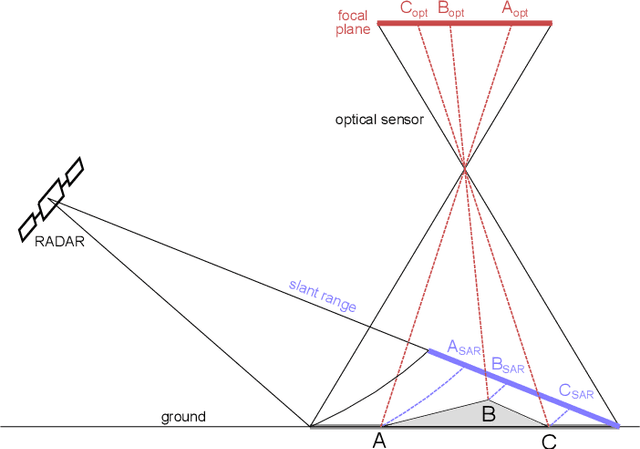
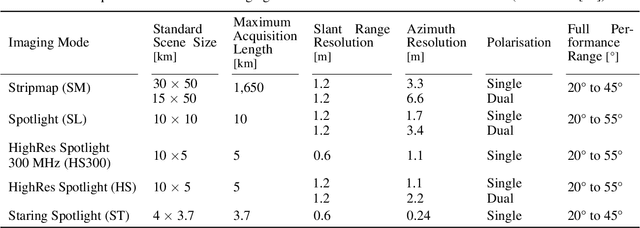
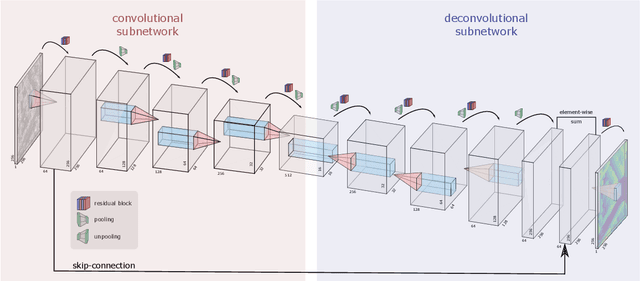
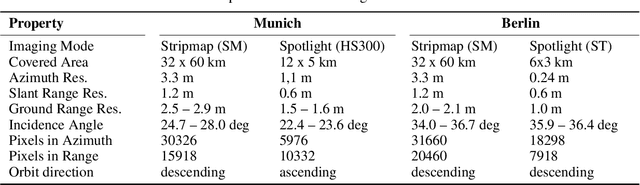
Originally developed in fields such as robotics and autonomous driving with image-based navigation in mind, deep learning-based single-image depth estimation (SIDE) has found great interest in the wider image analysis community. Remote sensing is no exception, as the possibility to estimate height maps from single aerial or satellite imagery bears great potential in the context of topographic reconstruction. A few pioneering investigations have demonstrated the general feasibility of single image height prediction from optical remote sensing images and motivate further studies in that direction. With this paper, we present the first-ever demonstration of deep learning-based single image height prediction for the other important sensor modality in remote sensing: synthetic aperture radar (SAR) data. Besides the adaptation of a convolutional neural network (CNN) architecture for SAR intensity images, we present a workflow for the generation of training data, and extensive experimental results for different SAR imaging modes and test sites. Since we put a particular emphasis on transferability, we are able to confirm that deep learning-based single-image height estimation is not only possible, but also transfers quite well to unseen data, even if acquired by different imaging modes and imaging parameters.
STS: Surround-view Temporal Stereo for Multi-view 3D Detection
Aug 22, 2022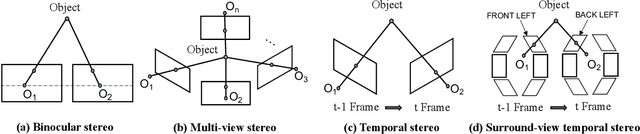
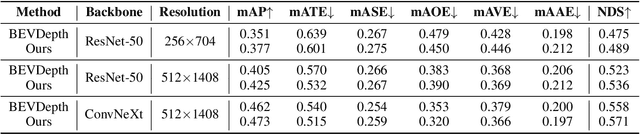
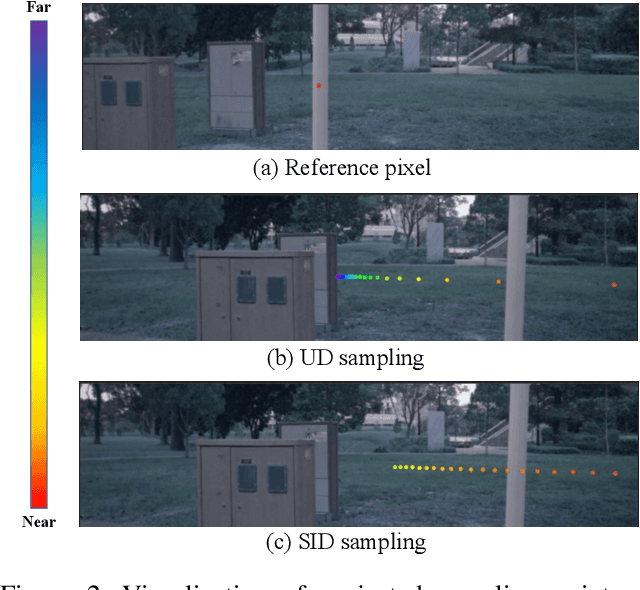
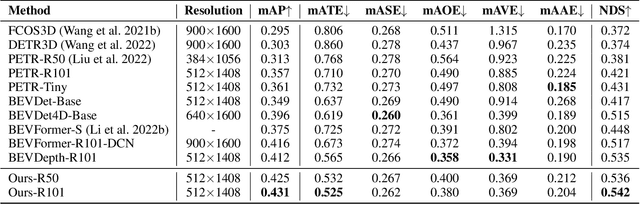
Learning accurate depth is essential to multi-view 3D object detection. Recent approaches mainly learn depth from monocular images, which confront inherent difficulties due to the ill-posed nature of monocular depth learning. Instead of using a sole monocular depth method, in this work, we propose a novel Surround-view Temporal Stereo (STS) technique that leverages the geometry correspondence between frames across time to facilitate accurate depth learning. Specifically, we regard the field of views from all cameras around the ego vehicle as a unified view, namely surroundview, and conduct temporal stereo matching on it. The resulting geometrical correspondence between different frames from STS is utilized and combined with the monocular depth to yield final depth prediction. Comprehensive experiments on nuScenes show that STS greatly boosts 3D detection ability, notably for medium and long distance objects. On BEVDepth with ResNet-50 backbone, STS improves mAP and NDS by 2.6% and 1.4%, respectively. Consistent improvements are observed when using a larger backbone and a larger image resolution, demonstrating its effectiveness
Metadata-enhanced contrastive learning from retinal optical coherence tomography images
Aug 04, 2022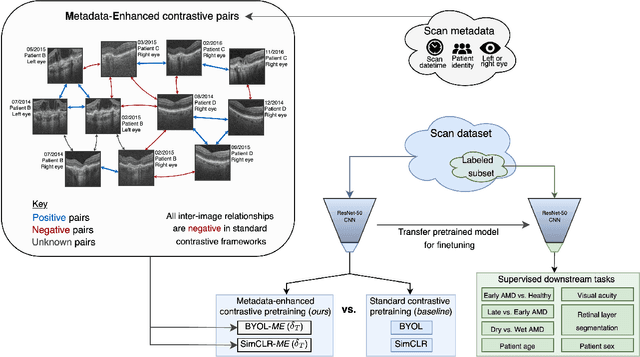
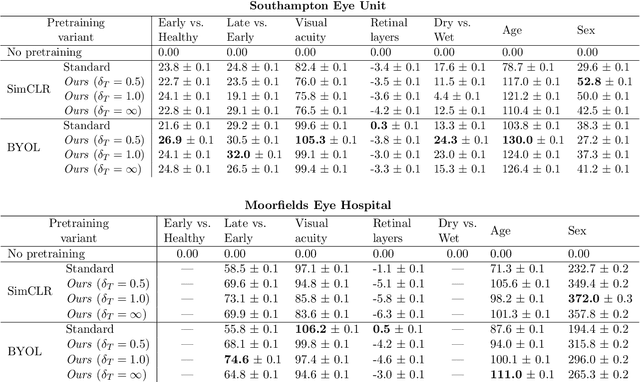
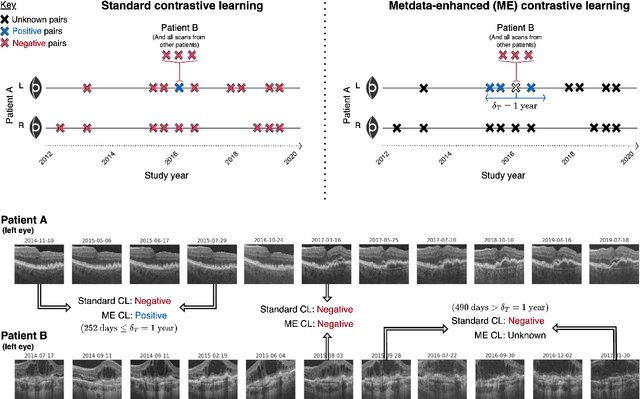
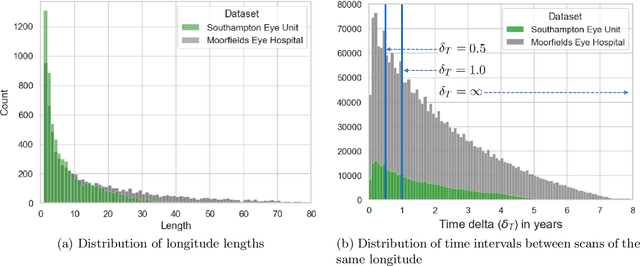
Supervised deep learning algorithms hold great potential to automate screening, monitoring and grading of medical images. However, training performant models has typically required vast quantities of labelled data, which is scarcely available in the medical domain. Self-supervised contrastive frameworks relax this dependency by first learning from unlabelled images. In this work we show that pretraining with two contrastive methods, SimCLR and BYOL, improves the utility of deep learning with regard to the clinical assessment of age-related macular degeneration (AMD). In experiments using two large clinical datasets containing 170,427 optical coherence tomography (OCT) images of 7,912 patients, we evaluate benefits attributed to pretraining across seven downstream tasks ranging from AMD stage and type classification to prediction of functional endpoints to segmentation of retinal layers, finding performance significantly increased in six out of seven tasks with fewer labels. However, standard contrastive frameworks have two known weaknesses that are detrimental to pretraining in the medical domain. Several of the image transformations used to create positive contrastive pairs are not applicable to greyscale medical scans. Furthermore, medical images often depict the same anatomical region and disease severity, resulting in numerous misleading negative pairs. To address these issues we develop a novel metadata-enhanced approach that exploits the rich set of inherently available patient information. To this end we employ records for patient identity, eye position (i.e. left or right) and time series data to indicate the typically unknowable set of inter-image contrastive relationships. By leveraging this often neglected information our metadata-enhanced contrastive pretraining leads to further benefits and outperforms conventional contrastive methods in five out of seven downstream tasks.