 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Structure Preserving Diffusion Models
Feb 29, 2024
Diffusion models have become the leading distribution-learning method in recent years. Herein, we introduce structure-preserving diffusion processes, a family of diffusion processes for learning distributions that possess additional structure, such as group symmetries, by developing theoretical conditions under which the diffusion transition steps preserve said symmetry. While also enabling equivariant data sampling trajectories, we exemplify these results by developing a collection of different symmetry equivariant diffusion models capable of learning distributions that are inherently symmetric. Empirical studies, over both synthetic and real-world datasets, are used to validate the developed models adhere to the proposed theory and are capable of achieving improved performance over existing methods in terms of sample equality. We also show how the proposed models can be used to achieve theoretically guaranteed equivariant image noise reduction without prior knowledge of the image orientation.
Neural Radiance Fields in Medical Imaging: Challenges and Next Steps
Mar 02, 2024Neural Radiance Fields (NeRF), as a pioneering technique in computer vision, offer great potential to revolutionize medical imaging by synthesizing three-dimensional representations from the projected two-dimensional image data. However, they face unique challenges when applied to medical applications. This paper presents a comprehensive examination of applications of NeRFs in medical imaging, highlighting four imminent challenges, including fundamental imaging principles, inner structure requirement, object boundary definition, and color density significance. We discuss current methods on different organs and discuss related limitations. We also review several datasets and evaluation metrics and propose several promising directions for future research.
Cross-Modal Contextualized Diffusion Models for Text-Guided Visual Generation and Editing
Mar 04, 2024Conditional diffusion models have exhibited superior performance in high-fidelity text-guided visual generation and editing. Nevertheless, prevailing text-guided visual diffusion models primarily focus on incorporating text-visual relationships exclusively into the reverse process, often disregarding their relevance in the forward process. This inconsistency between forward and reverse processes may limit the precise conveyance of textual semantics in visual synthesis results. To address this issue, we propose a novel and general contextualized diffusion model (ContextDiff) by incorporating the cross-modal context encompassing interactions and alignments between text condition and visual sample into forward and reverse processes. We propagate this context to all timesteps in the two processes to adapt their trajectories, thereby facilitating cross-modal conditional modeling. We generalize our contextualized diffusion to both DDPMs and DDIMs with theoretical derivations, and demonstrate the effectiveness of our model in evaluations with two challenging tasks: text-to-image generation, and text-to-video editing. In each task, our ContextDiff achieves new state-of-the-art performance, significantly enhancing the semantic alignment between text condition and generated samples, as evidenced by quantitative and qualitative evaluations. Our code is available at https://github.com/YangLing0818/ContextDiff
RISeg: Robot Interactive Object Segmentation via Body Frame-Invariant Features
Mar 04, 2024
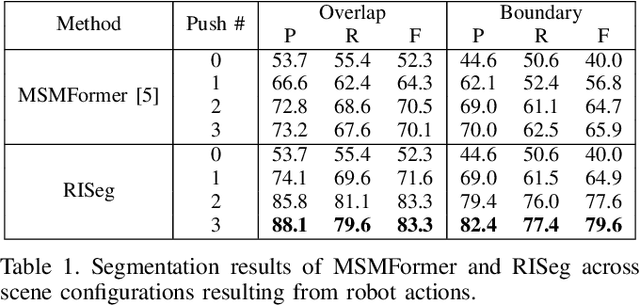
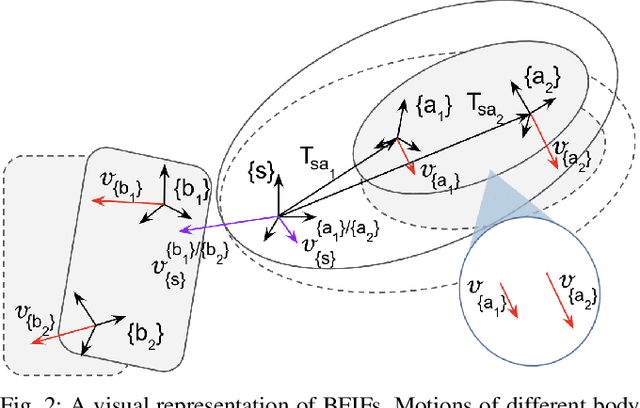
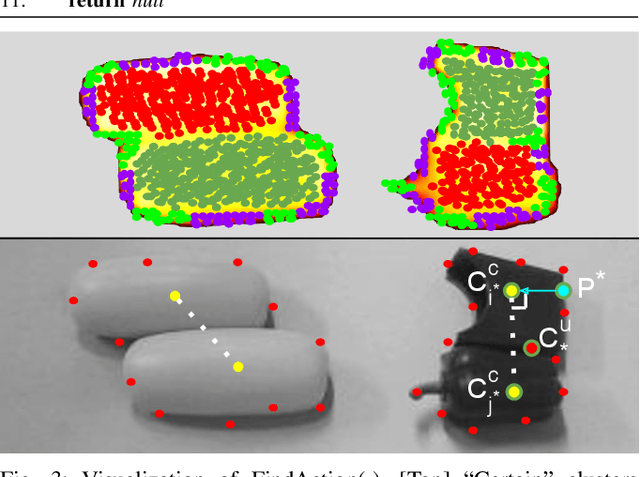
In order to successfully perform manipulation tasks in new environments, such as grasping, robots must be proficient in segmenting unseen objects from the background and/or other objects. Previous works perform unseen object instance segmentation (UOIS) by training deep neural networks on large-scale data to learn RGB/RGB-D feature embeddings, where cluttered environments often result in inaccurate segmentations. We build upon these methods and introduce a novel approach to correct inaccurate segmentation, such as under-segmentation, of static image-based UOIS masks by using robot interaction and a designed body frame-invariant feature. We demonstrate that the relative linear and rotational velocities of frames randomly attached to rigid bodies due to robot interactions can be used to identify objects and accumulate corrected object-level segmentation masks. By introducing motion to regions of segmentation uncertainty, we are able to drastically improve segmentation accuracy in an uncertainty-driven manner with minimal, non-disruptive interactions (ca. 2-3 per scene). We demonstrate the effectiveness of our proposed interactive perception pipeline in accurately segmenting cluttered scenes by achieving an average object segmentation accuracy rate of 80.7%, an increase of 28.2% when compared with other state-of-the-art UOIS methods.
3D Hand Reconstruction via Aggregating Intra and Inter Graphs Guided by Prior Knowledge for Hand-Object Interaction Scenario
Mar 04, 2024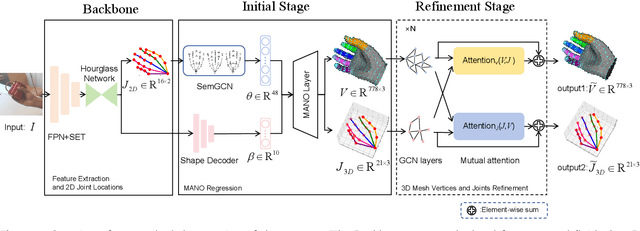
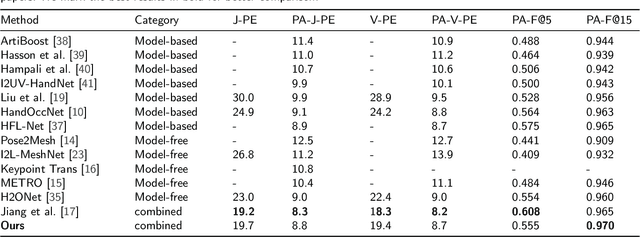
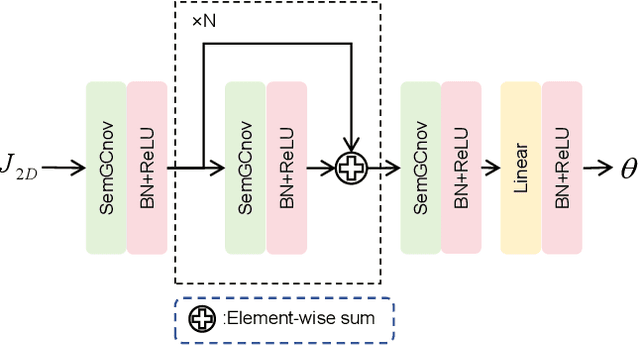
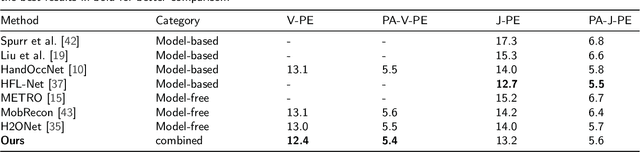
Recently, 3D hand reconstruction has gained more attention in human-computer cooperation, especially for hand-object interaction scenario. However, it still remains huge challenge due to severe hand-occlusion caused by interaction, which contain the balance of accuracy and physical plausibility, highly nonlinear mapping of model parameters and occlusion feature enhancement. To overcome these issues, we propose a 3D hand reconstruction network combining the benefits of model-based and model-free approaches to balance accuracy and physical plausibility for hand-object interaction scenario. Firstly, we present a novel MANO pose parameters regression module from 2D joints directly, which avoids the process of highly nonlinear mapping from abstract image feature and no longer depends on accurate 3D joints. Moreover, we further propose a vertex-joint mutual graph-attention model guided by MANO to jointly refine hand meshes and joints, which model the dependencies of vertex-vertex and joint-joint and capture the correlation of vertex-joint for aggregating intra-graph and inter-graph node features respectively. The experimental results demonstrate that our method achieves a competitive performance on recently benchmark datasets HO3DV2 and Dex-YCB, and outperforms all only model-base approaches and model-free approaches.
xT: Nested Tokenization for Larger Context in Large Images
Mar 04, 2024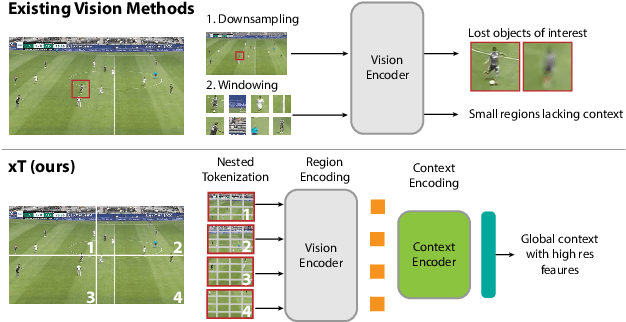
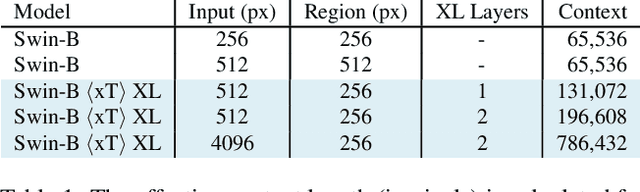
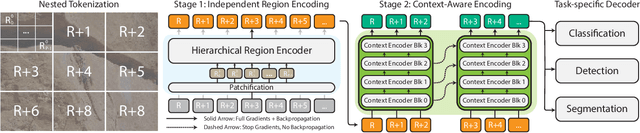
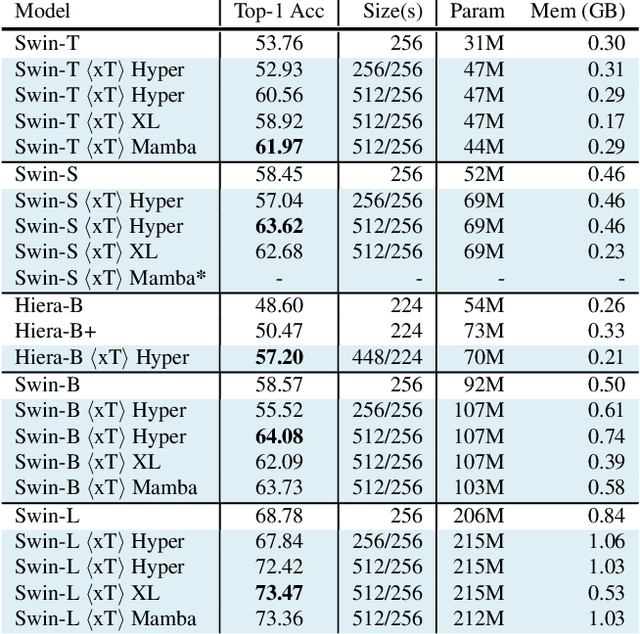
Modern computer vision pipelines handle large images in one of two sub-optimal ways: down-sampling or cropping. These two methods incur significant losses in the amount of information and context present in an image. There are many downstream applications in which global context matters as much as high frequency details, such as in real-world satellite imagery; in such cases researchers have to make the uncomfortable choice of which information to discard. We introduce xT, a simple framework for vision transformers which effectively aggregates global context with local details and can model large images end-to-end on contemporary GPUs. We select a set of benchmark datasets across classic vision tasks which accurately reflect a vision model's ability to understand truly large images and incorporate fine details over large scales and assess our method's improvement on them. By introducing a nested tokenization scheme for large images in conjunction with long-sequence length models normally used for natural language processing, we are able to increase accuracy by up to 8.6% on challenging classification tasks and $F_1$ score by 11.6 on context-dependent segmentation in large images.
Evaluating and Mitigating Number Hallucinations in Large Vision-Language Models: A Consistency Perspective
Mar 03, 2024
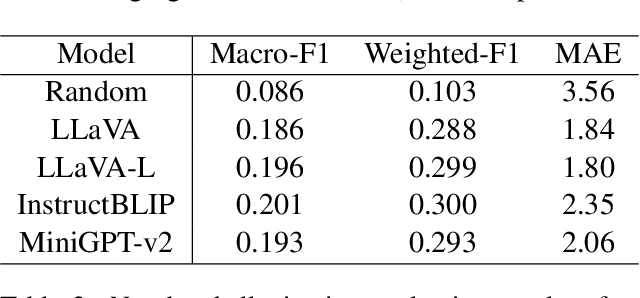
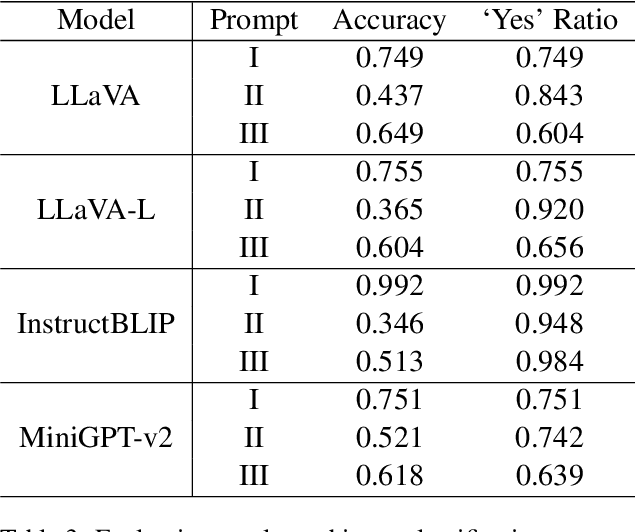
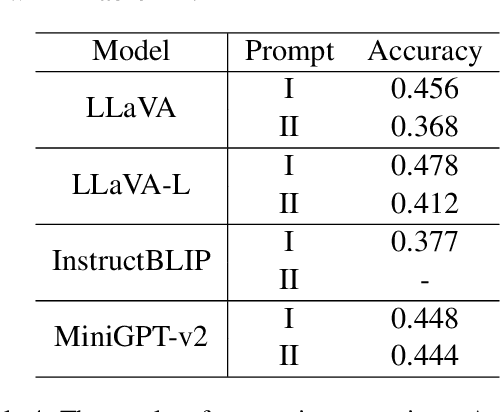
Large vision language models have demonstrated remarkable efficacy in addressing challenges related to both textual and visual content. Nevertheless, these models are susceptible to various hallucinations. In this paper, we focus on a new form of hallucination, specifically termed as number hallucination, which denotes instances where models fail to accurately identify the quantity of objects in an image. We establish a dataset and employ evaluation metrics to assess number hallucination, revealing a pronounced prevalence of this issue across mainstream large vision language models (LVLMs). Additionally, we delve into a thorough analysis of number hallucination, examining inner and outer inconsistency problem from two related perspectives. We assert that this inconsistency is one cause of number hallucination and propose a consistency training method as a means to alleviate such hallucination, which achieves an average improvement of 8\% compared with direct finetuning method.
Analysis of the Two-Step Heterogeneous Transfer Learning for Laryngeal Blood Vessel Classification: Issue and Improvement
Mar 05, 2024Transferring features learned from natural to medical images for classification is common. However, challenges arise due to the scarcity of certain medical image types and the feature disparities between natural and medical images. Two-step transfer learning has been recognized as a promising solution for this issue. However, choosing an appropriate intermediate domain would be critical in further improving the classification performance. In this work, we explore the effectiveness of using color fundus photographs of the diabetic retina dataset as an intermediate domain for two-step heterogeneous learning (THTL) to classify laryngeal vascular images with nine deep-learning models. Experiment results confirm that although the images in both the intermediate and target domains share vascularized characteristics, the accuracy is drastically reduced compared to one-step transfer learning, where only the last layer is fine-tuned (e.g., ResNet18 drops 14.7%, ResNet50 drops 14.8%). By analyzing the Layer Class Activation Maps (LayerCAM), we uncover a novel finding that the prevalent radial vascular pattern in the intermediate domain prevents learning the features of twisted and tangled vessels that distinguish the malignant class in the target domain. To address the performance drop, we propose the Step-Wise Fine-Tuning (SWFT) method on ResNet in the second step of THTL, resulting in substantial accuracy improvements. Compared to THTL's second step, where only the last layer is fine-tuned, accuracy increases by 26.1% for ResNet18 and 20.4% for ResNet50. Additionally, compared to training from scratch, using ImageNet as the source domain could slightly improve classification performance for laryngeal vascular, but the differences are insignificant.
ADS: Approximate Densest Subgraph for Novel Image Discovery
Feb 13, 2024The volume of image repositories continues to grow. Despite the availability of content-based addressing, we still lack a lightweight tool that allows us to discover images of distinct characteristics from a large collection. In this paper, we propose a fast and training-free algorithm for novel image discovery. The key of our algorithm is formulating a collection of images as a perceptual distance-weighted graph, within which our task is to locate the K-densest subgraph that corresponds to a subset of the most unique images. While solving this problem is not just NP-hard but also requires a full computation of the potentially huge distance matrix, we propose to relax it into a K-sparse eigenvector problem that we can efficiently solve using stochastic gradient descent (SGD) without explicitly computing the distance matrix. We compare our algorithm against state-of-the-arts on both synthetic and real datasets, showing that it is considerably faster to run with a smaller memory footprint while able to mine novel images more accurately.
A Simple yet Effective Network based on Vision Transformer for Camouflaged Object and Salient Object Detection
Feb 29, 2024Camouflaged object detection (COD) and salient object detection (SOD) are two distinct yet closely-related computer vision tasks widely studied during the past decades. Though sharing the same purpose of segmenting an image into binary foreground and background regions, their distinction lies in the fact that COD focuses on concealed objects hidden in the image, while SOD concentrates on the most prominent objects in the image. Previous works achieved good performance by stacking various hand-designed modules and multi-scale features. However, these carefully-designed complex networks often performed well on one task but not on another. In this work, we propose a simple yet effective network (SENet) based on vision Transformer (ViT), by employing a simple design of an asymmetric ViT-based encoder-decoder structure, we yield competitive results on both tasks, exhibiting greater versatility than meticulously crafted ones. Furthermore, to enhance the Transformer's ability to model local information, which is important for pixel-level binary segmentation tasks, we propose a local information capture module (LICM). We also propose a dynamic weighted loss (DW loss) based on Binary Cross-Entropy (BCE) and Intersection over Union (IoU) loss, which guides the network to pay more attention to those smaller and more difficult-to-find target objects according to their size. Moreover, we explore the issue of joint training of SOD and COD, and propose a preliminary solution to the conflict in joint training, further improving the performance of SOD. Extensive experiments on multiple benchmark datasets demonstrate the effectiveness of our method. The code is available at https://github.com/linuxsino/SENet.