 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Adversarial Purification using Denoising AutoEncoders
Aug 29, 2022
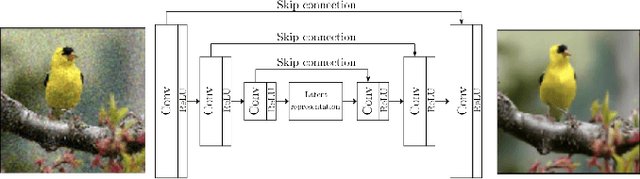
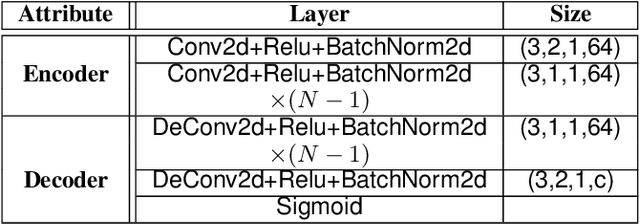
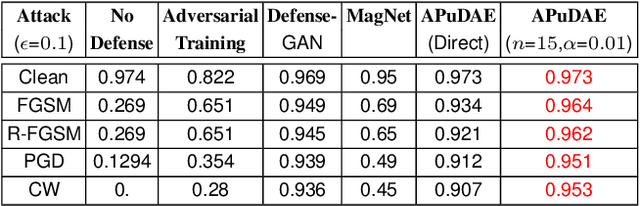

With the rapid advancement and increased use of deep learning models in image identification, security becomes a major concern to their deployment in safety-critical systems. Since the accuracy and robustness of deep learning models are primarily attributed from the purity of the training samples, therefore the deep learning architectures are often susceptible to adversarial attacks. Adversarial attacks are often obtained by making subtle perturbations to normal images, which are mostly imperceptible to humans, but can seriously confuse the state-of-the-art machine learning models. We propose a framework, named APuDAE, leveraging Denoising AutoEncoders (DAEs) to purify these samples by using them in an adaptive way and thus improve the classification accuracy of the target classifier networks that have been attacked. We also show how using DAEs adaptively instead of using them directly, improves classification accuracy further and is more robust to the possibility of designing adaptive attacks to fool them. We demonstrate our results over MNIST, CIFAR-10, ImageNet dataset and show how our framework (APuDAE) provides comparable and in most cases better performance to the baseline methods in purifying adversaries. We also design adaptive attack specifically designed to attack our purifying model and demonstrate how our defense is robust to that.
Multi-View Image-to-Image Translation Supervised by 3D Pose
Apr 12, 2021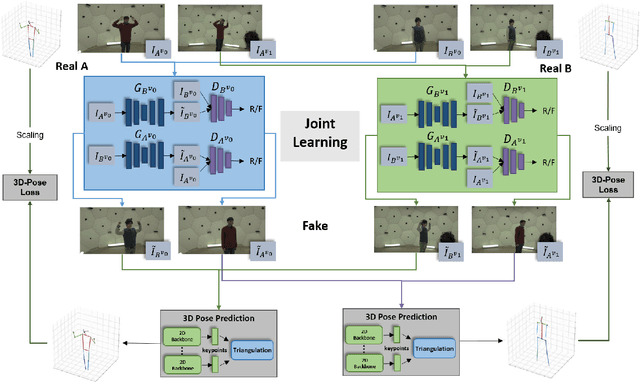



We address the task of multi-view image-to-image translation for person image generation. The goal is to synthesize photo-realistic multi-view images with pose-consistency across all views. Our proposed end-to-end framework is based on a joint learning of multiple unpaired image-to-image translation models, one per camera viewpoint. The joint learning is imposed by constraints on the shared 3D human pose in order to encourage the 2D pose projections in all views to be consistent. Experimental results on the CMU-Panoptic dataset demonstrate the effectiveness of the suggested framework in generating photo-realistic images of persons with new poses that are more consistent across all views in comparison to a standard Image-to-Image baseline. The code is available at: https://github.com/sony-si/MultiView-Img2Img
Animation from Blur: Multi-modal Blur Decomposition with Motion Guidance
Jul 20, 2022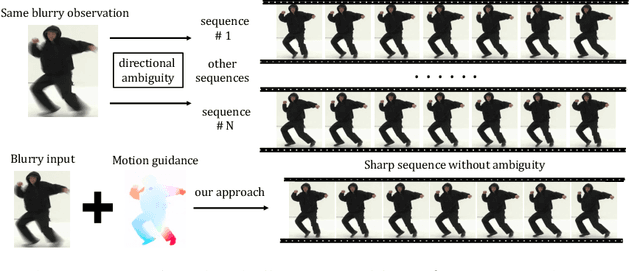
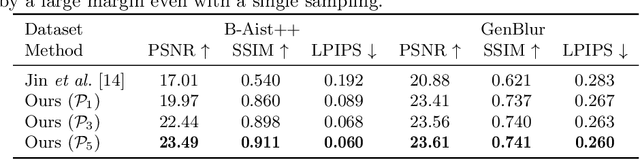
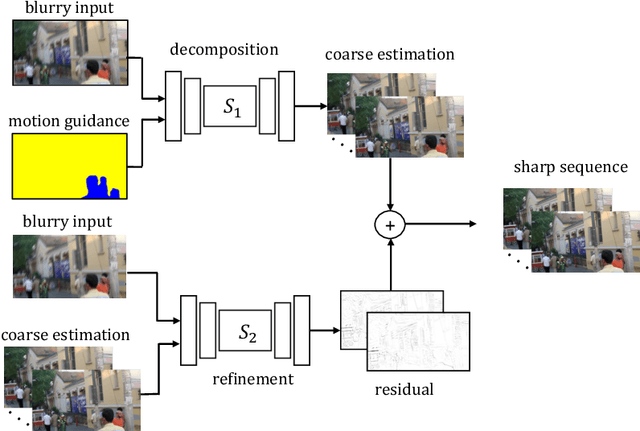

We study the challenging problem of recovering detailed motion from a single motion-blurred image. Existing solutions to this problem estimate a single image sequence without considering the motion ambiguity for each region. Therefore, the results tend to converge to the mean of the multi-modal possibilities. In this paper, we explicitly account for such motion ambiguity, allowing us to generate multiple plausible solutions all in sharp detail. The key idea is to introduce a motion guidance representation, which is a compact quantization of 2D optical flow with only four discrete motion directions. Conditioned on the motion guidance, the blur decomposition is led to a specific, unambiguous solution by using a novel two-stage decomposition network. We propose a unified framework for blur decomposition, which supports various interfaces for generating our motion guidance, including human input, motion information from adjacent video frames, and learning from a video dataset. Extensive experiments on synthesized datasets and real-world data show that the proposed framework is qualitatively and quantitatively superior to previous methods, and also offers the merit of producing physically plausible and diverse solutions. Code is available at https://github.com/zzh-tech/Animation-from-Blur.
Enhancing Clean Label Backdoor Attack with Two-phase Specific Triggers
Jun 10, 2022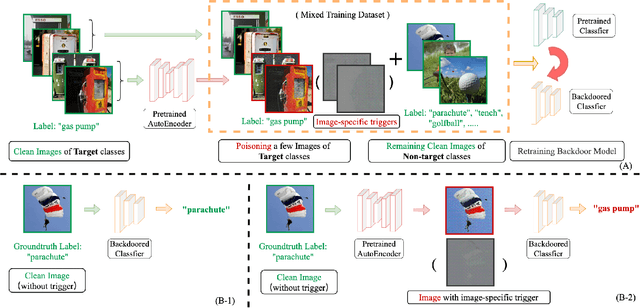
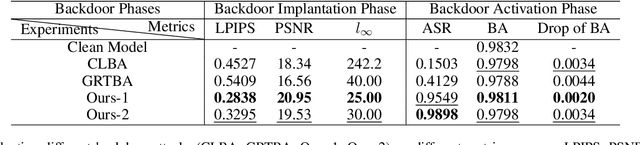

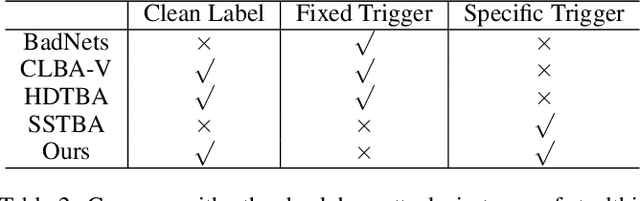
Backdoor attacks threaten Deep Neural Networks (DNNs). Towards stealthiness, researchers propose clean-label backdoor attacks, which require the adversaries not to alter the labels of the poisoned training datasets. Clean-label settings make the attack more stealthy due to the correct image-label pairs, but some problems still exist: first, traditional methods for poisoning training data are ineffective; second, traditional triggers are not stealthy which are still perceptible. To solve these problems, we propose a two-phase and image-specific triggers generation method to enhance clean-label backdoor attacks. Our methods are (1) powerful: our triggers can both promote the two phases (i.e., the backdoor implantation and activation phase) in backdoor attacks simultaneously; (2) stealthy: our triggers are generated from each image. They are image-specific instead of fixed triggers. Extensive experiments demonstrate that our approach can achieve a fantastic attack success rate~(98.98%) with low poisoning rate~(5%), high stealthiness under many evaluation metrics and is resistant to backdoor defense methods.
3D Photo Stylization: Learning to Generate Stylized Novel Views from a Single Image
Nov 30, 2021
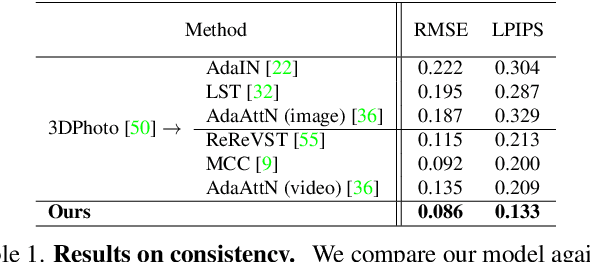

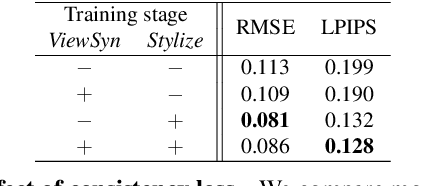
Visual content creation has spurred a soaring interest given its applications in mobile photography and AR / VR. Style transfer and single-image 3D photography as two representative tasks have so far evolved independently. In this paper, we make a connection between the two, and address the challenging task of 3D photo stylization - generating stylized novel views from a single image given an arbitrary style. Our key intuition is that style transfer and view synthesis have to be jointly modeled for this task. To this end, we propose a deep model that learns geometry-aware content features for stylization from a point cloud representation of the scene, resulting in high-quality stylized images that are consistent across views. Further, we introduce a novel training protocol to enable the learning using only 2D images. We demonstrate the superiority of our method via extensive qualitative and quantitative studies, and showcase key applications of our method in light of the growing demand for 3D content creation from 2D image assets.
Embedding Novel Views in a Single JPEG Image
Aug 30, 2021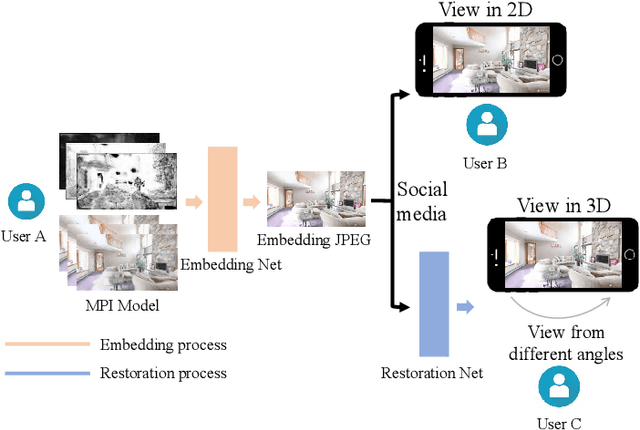
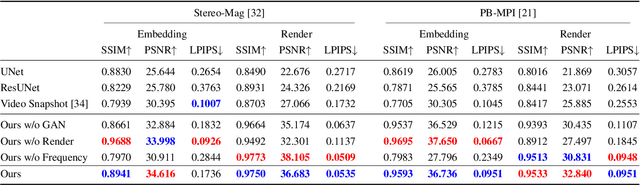

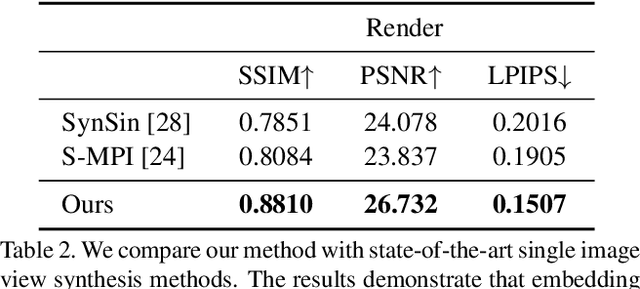
We propose a novel approach for embedding novel views in a single JPEG image while preserving the perceptual fidelity of the modified JPEG image and the restored novel views. We adopt the popular novel view synthesis representation of multiplane images (MPIs). Our model first encodes 32 MPI layers (totally 128 channels) into a 3-channel JPEG image that can be decoded for MPIs to render novel views, with an embedding capacity of 1024 bits per pixel. We conducted experiments on public datasets with different novel view synthesis methods, and the results show that the proposed method can restore high-fidelity novel views from a slightly modified JPEG image. Furthermore, our method is robust to JPEG compression, color adjusting, and cropping. Our source code will be publicly available.
Adversarial Ensemble Training by Jointly Learning Label Dependencies and Member Models
Jul 04, 2022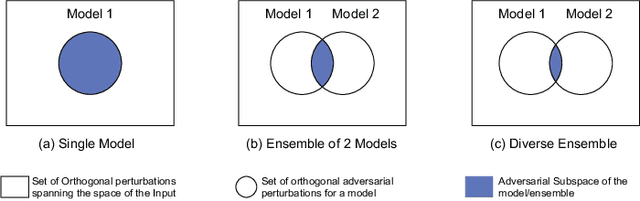
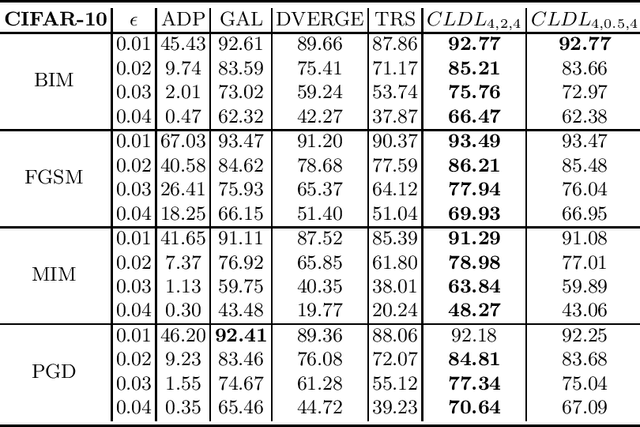
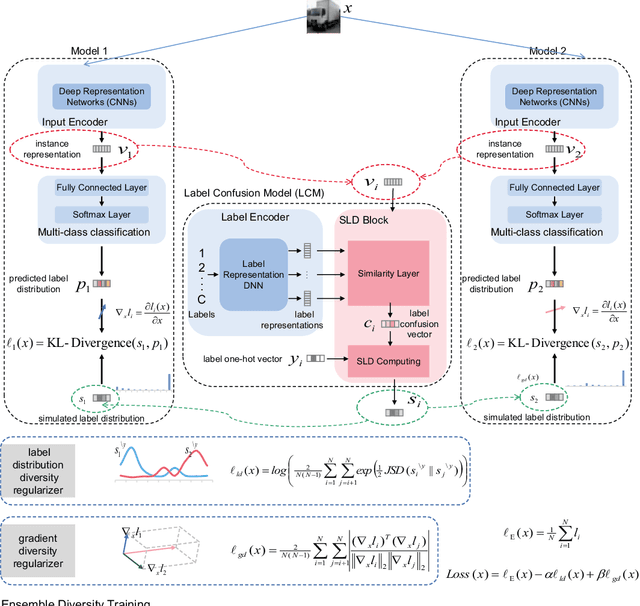
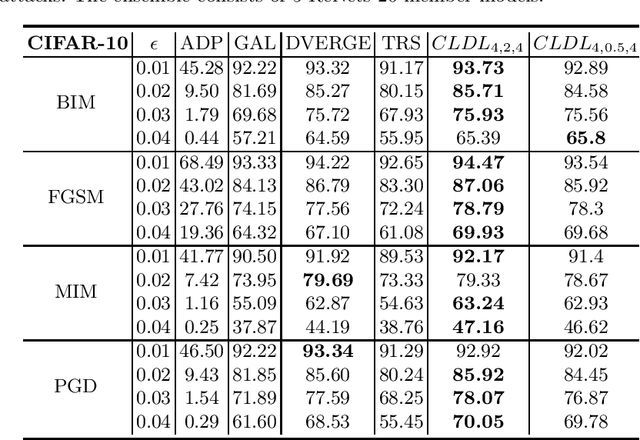
Training an ensemble of different sub-models has empirically proven to be an effective strategy to improve deep neural networks' adversarial robustness. Current ensemble training methods for image recognition usually encode the image labels by one-hot vectors, which neglect dependency relationships between the labels. Here we propose a novel adversarial ensemble training approach to jointly learn the label dependencies and the member models. Our approach adaptively exploits the learned label dependencies to promote the diversity of the member models. We test our approach on widely used datasets MNIST, FasionMNIST, and CIFAR-10. Results show that our approach is more robust against black-box attacks compared with the state-of-the-art methods. Our code is available at https://github.com/ZJLAB-AMMI/LSD.
Cross-Forgery Analysis of Vision Transformers and CNNs for Deepfake Image Detection
Jun 28, 2022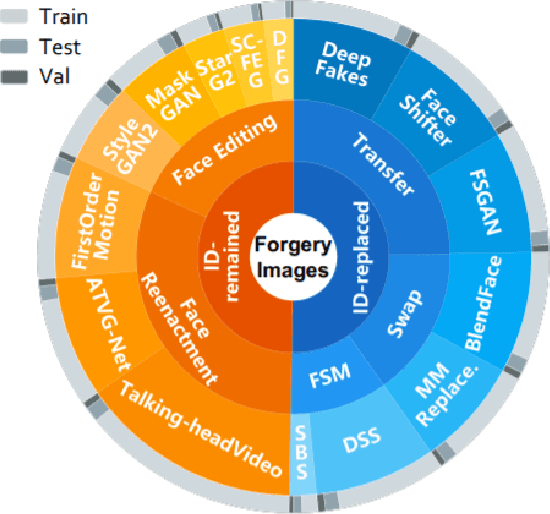
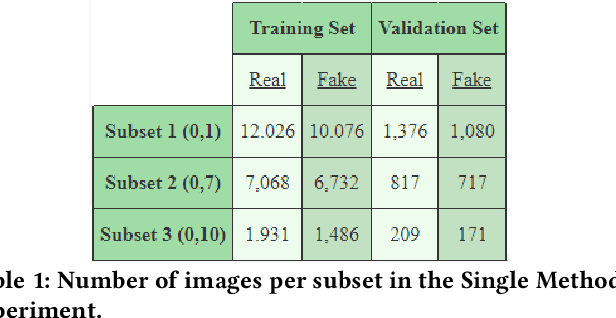
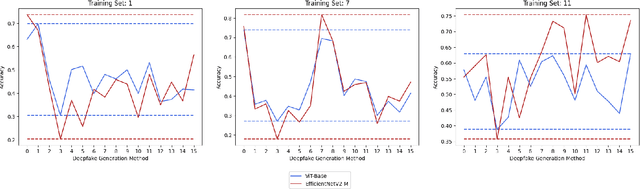
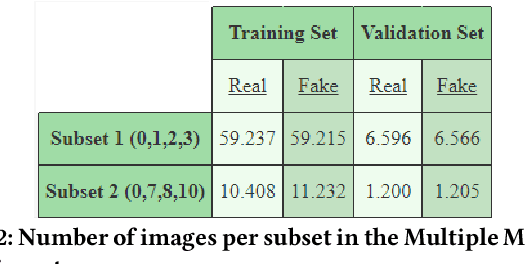
Deepfake Generation Techniques are evolving at a rapid pace, making it possible to create realistic manipulated images and videos and endangering the serenity of modern society. The continual emergence of new and varied techniques brings with it a further problem to be faced, namely the ability of deepfake detection models to update themselves promptly in order to be able to identify manipulations carried out using even the most recent methods. This is an extremely complex problem to solve, as training a model requires large amounts of data, which are difficult to obtain if the deepfake generation method is too recent. Moreover, continuously retraining a network would be unfeasible. In this paper, we ask ourselves if, among the various deep learning techniques, there is one that is able to generalise the concept of deepfake to such an extent that it does not remain tied to one or more specific deepfake generation methods used in the training set. We compared a Vision Transformer with an EfficientNetV2 on a cross-forgery context based on the ForgeryNet dataset. From our experiments, It emerges that EfficientNetV2 has a greater tendency to specialize often obtaining better results on training methods while Vision Transformers exhibit a superior generalization ability that makes them more competent even on images generated with new methodologies.
Towards Unbiased Label Distribution Learning for Facial Pose Estimation Using Anisotropic Spherical Gaussian
Aug 19, 2022
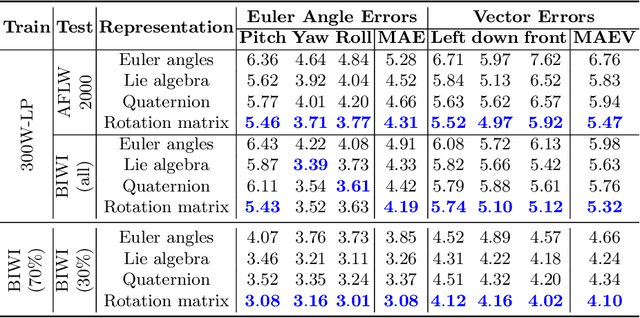
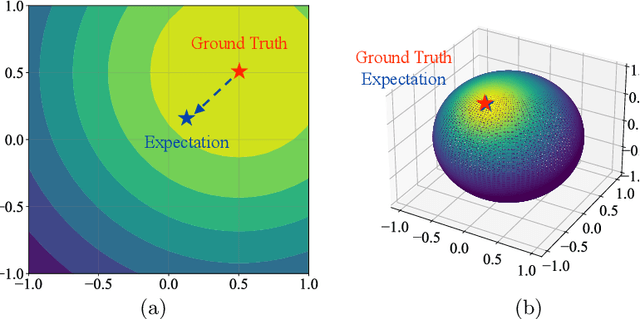
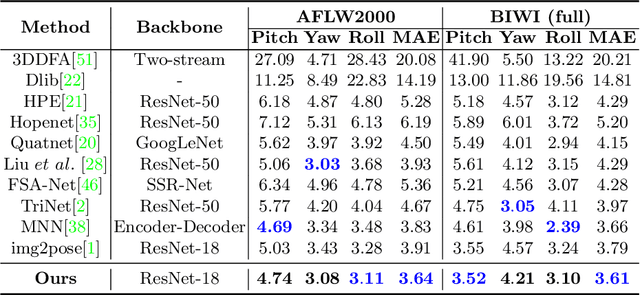
Facial pose estimation refers to the task of predicting face orientation from a single RGB image. It is an important research topic with a wide range of applications in computer vision. Label distribution learning (LDL) based methods have been recently proposed for facial pose estimation, which achieve promising results. However, there are two major issues in existing LDL methods. First, the expectations of label distributions are biased, leading to a biased pose estimation. Second, fixed distribution parameters are applied for all learning samples, severely limiting the model capability. In this paper, we propose an Anisotropic Spherical Gaussian (ASG)-based LDL approach for facial pose estimation. In particular, our approach adopts the spherical Gaussian distribution on a unit sphere which constantly generates unbiased expectation. Meanwhile, we introduce a new loss function that allows the network to learn the distribution parameter for each learning sample flexibly. Extensive experimental results show that our method sets new state-of-the-art records on AFLW2000 and BIWI datasets.
Anatomical-Guided Attention Enhances Unsupervised PET Image Denoising Performance
Sep 08, 2021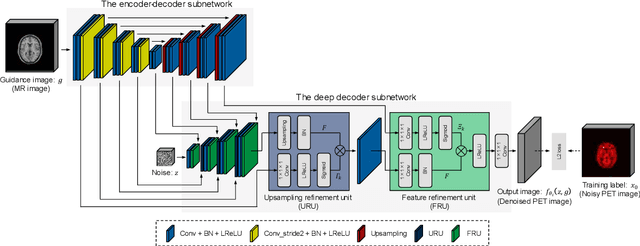
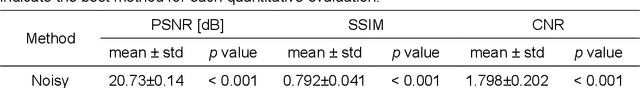
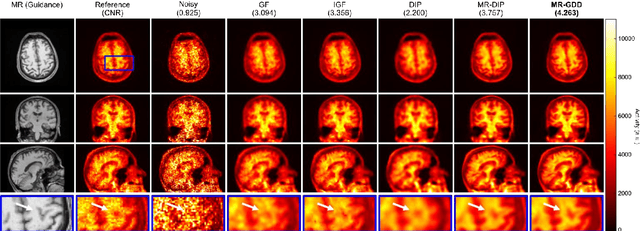
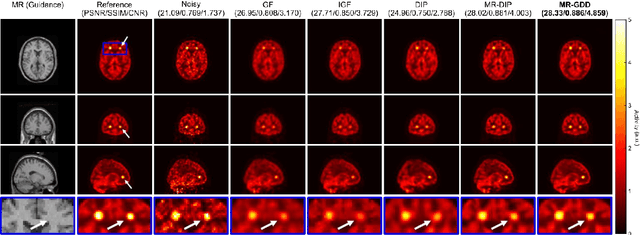
Although supervised convolutional neural networks (CNNs) often outperform conventional alternatives for denoising positron emission tomography (PET) images, they require many low- and high-quality reference PET image pairs. Herein, we propose an unsupervised 3D PET image denoising method based on an anatomical information-guided attention mechanism. The proposed magnetic resonance-guided deep decoder (MR-GDD) utilizes the spatial details and semantic features of MR-guidance image more effectively by introducing encoder-decoder and deep decoder subnetworks. Moreover, the specific shapes and patterns of the guidance image do not affect the denoised PET image, because the guidance image is input to the network through an attention gate. In a Monte Carlo simulation of [$^{18}$F]fluoro-2-deoxy-D-glucose (FDG), the proposed method achieved the highest peak signal-to-noise ratio and structural similarity (27.92 $\pm$ 0.44 dB/0.886 $\pm$ 0.007), as compared with Gaussian filtering (26.68 $\pm$ 0.10 dB/0.807 $\pm$ 0.004), image guided filtering (27.40 $\pm$ 0.11 dB/0.849 $\pm$ 0.003), deep image prior (DIP) (24.22 $\pm$ 0.43 dB/0.737 $\pm$ 0.017), and MR-DIP (27.65 $\pm$ 0.42 dB/0.879 $\pm$ 0.007). Furthermore, we experimentally visualized the behavior of the optimization process, which is often unknown in unsupervised CNN-based restoration problems. For preclinical (using [$^{18}$F]FDG and [$^{11}$C]raclopride) and clinical (using [$^{18}$F]florbetapir) studies, the proposed method demonstrates state-of-the-art denoising performance while retaining spatial resolution and quantitative accuracy, despite using a common network architecture for various noisy PET images with 1/10th of the full counts. These results suggest that the proposed MR-GDD can reduce PET scan times and PET tracer doses considerably without impacting patients.
* 30 pages, 12 figures