 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SegPGD: An Effective and Efficient Adversarial Attack for Evaluating and Boosting Segmentation Robustness
Jul 25, 2022
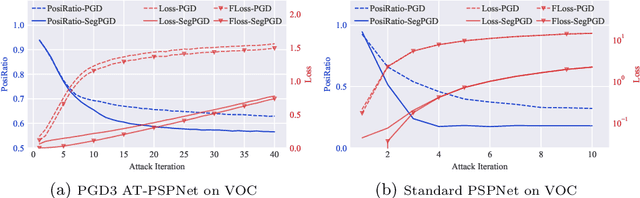
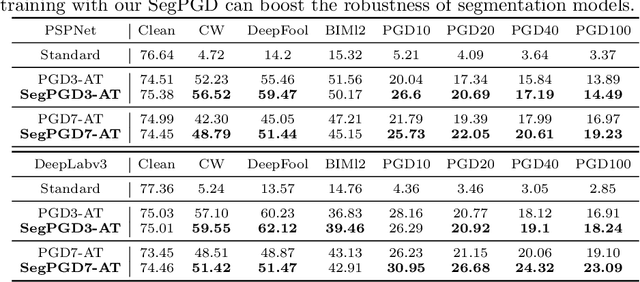
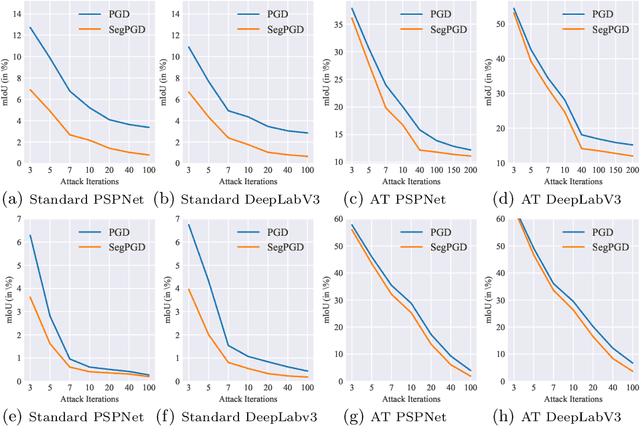
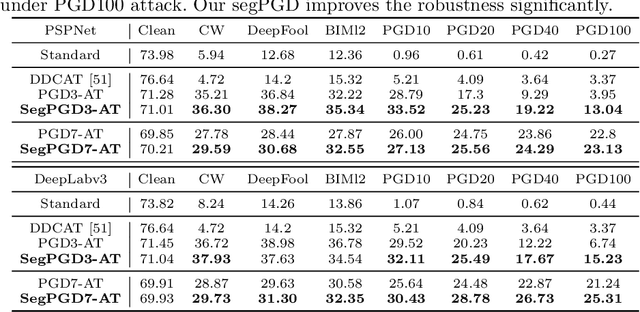
Deep neural network-based image classifications are vulnerable to adversarial perturbations. The image classifications can be easily fooled by adding artificial small and imperceptible perturbations to input images. As one of the most effective defense strategies, adversarial training was proposed to address the vulnerability of classification models, where the adversarial examples are created and injected into training data during training. The attack and defense of classification models have been intensively studied in past years. Semantic segmentation, as an extension of classifications, has also received great attention recently. Recent work shows a large number of attack iterations are required to create effective adversarial examples to fool segmentation models. The observation makes both robustness evaluation and adversarial training on segmentation models challenging. In this work, we propose an effective and efficient segmentation attack method, dubbed SegPGD. Besides, we provide a convergence analysis to show the proposed SegPGD can create more effective adversarial examples than PGD under the same number of attack iterations. Furthermore, we propose to apply our SegPGD as the underlying attack method for segmentation adversarial training. Since SegPGD can create more effective adversarial examples, the adversarial training with our SegPGD can boost the robustness of segmentation models. Our proposals are also verified with experiments on popular Segmentation model architectures and standard segmentation datasets.
Similarity Guided Deep Face Image Retrieval
Jul 11, 2021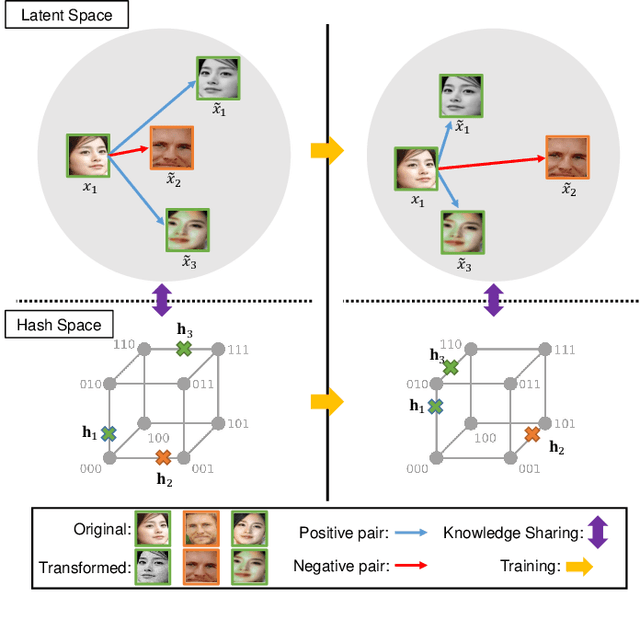
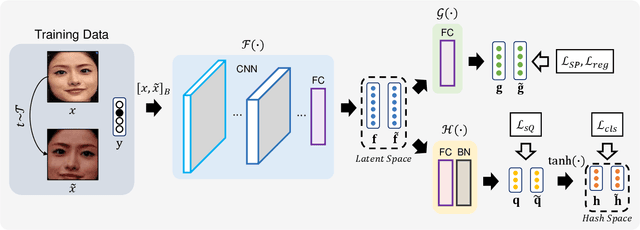

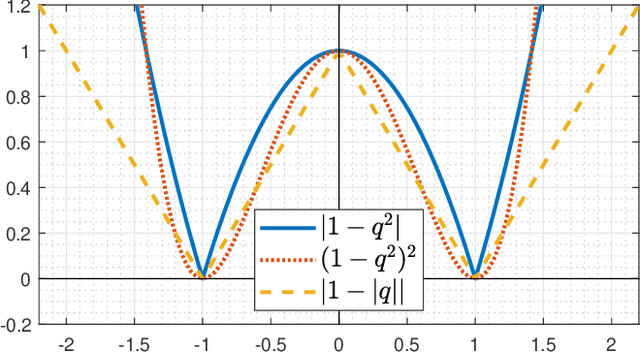
Face image retrieval, which searches for images of the same identity from the query input face image, is drawing more attention as the size of the image database increases rapidly. In order to conduct fast and accurate retrieval, a compact hash code-based methods have been proposed, and recently, deep face image hashing methods with supervised classification training have shown outstanding performance. However, classification-based scheme has a disadvantage in that it cannot reveal complex similarities between face images into the hash code learning. In this paper, we attempt to improve the face image retrieval quality by proposing a Similarity Guided Hashing (SGH) method, which gently considers self and pairwise-similarity simultaneously. SGH employs various data augmentations designed to explore elaborate similarities between face images, solving both intra and inter identity-wise difficulties. Extensive experimental results on the protocols with existing benchmarks and an additionally proposed large scale higher resolution face image dataset demonstrate that our SGH delivers state-of-the-art retrieval performance.
Shape-Aware Masking for Inpainting in Medical Imaging
Jul 12, 2022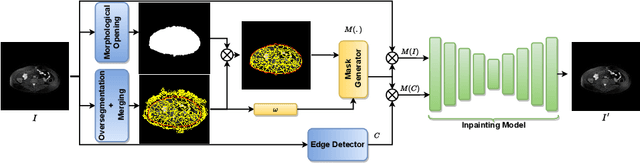

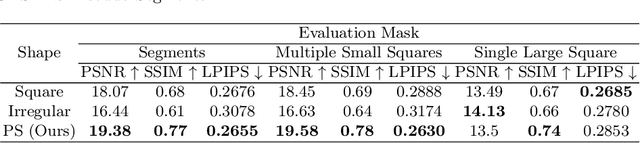
Inpainting has recently been proposed as a successful deep learning technique for unsupervised medical image model discovery. The masks used for inpainting are generally independent of the dataset and are not tailored to perform on different given classes of anatomy. In this work, we introduce a method for generating shape-aware masks for inpainting, which aims at learning the statistical shape prior. We hypothesize that although the variation of masks improves the generalizability of inpainting models, the shape of the masks should follow the topology of the organs of interest. Hence, we propose an unsupervised guided masking approach based on an off-the-shelf inpainting model and a superpixel over-segmentation algorithm to generate a wide range of shape-dependent masks. Experimental results on abdominal MR image reconstruction show the superiority of our proposed masking method over standard methods using square-shaped or dataset of irregular shape masks.
Validation of Vector Data using Oblique Images
Jun 17, 2022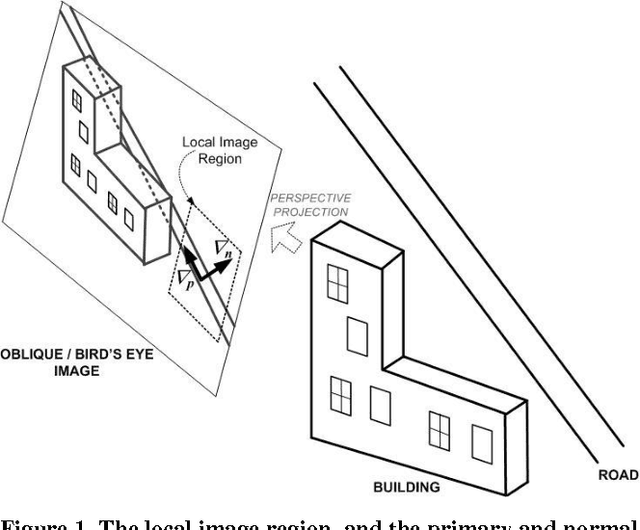
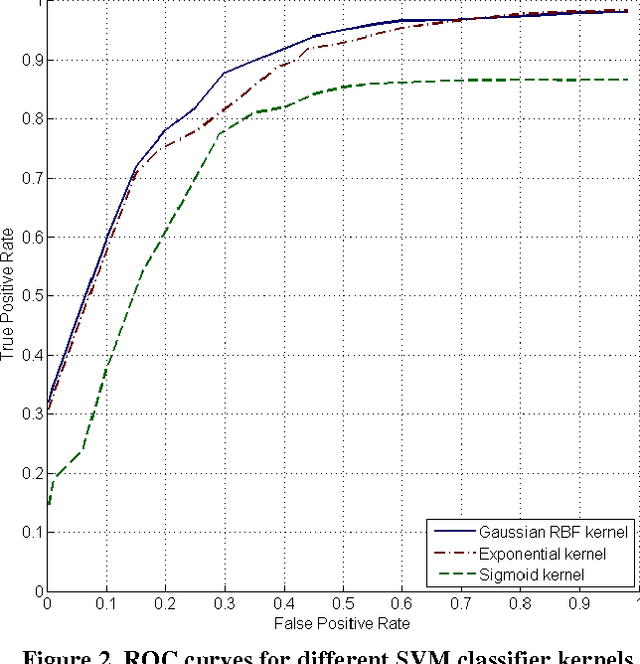
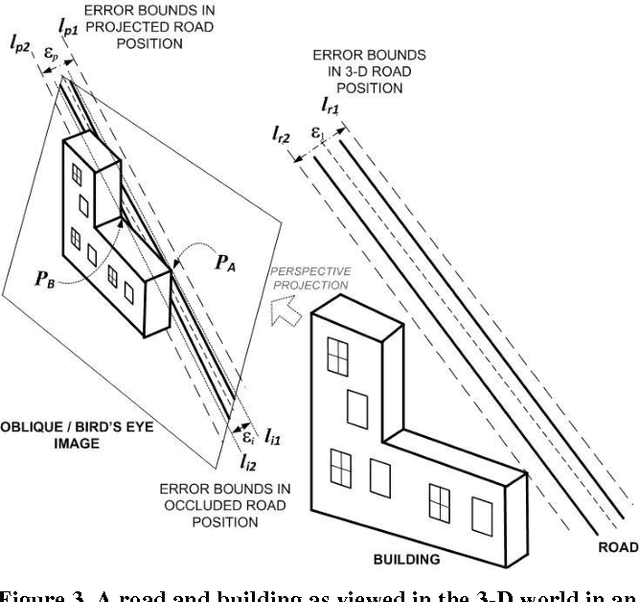
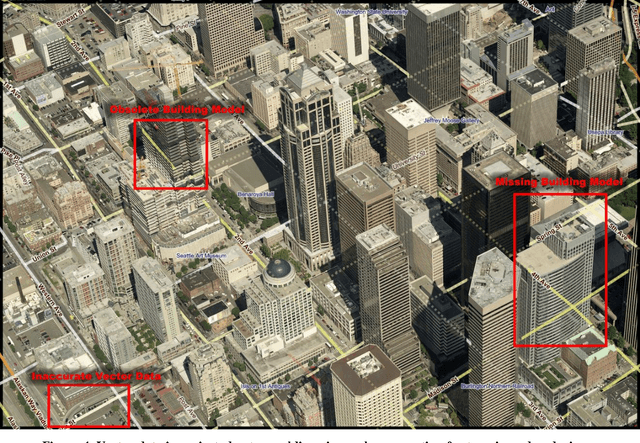
Oblique images are aerial photographs taken at oblique angles to the earth's surface. Projections of vector and other geospatial data in these images depend on camera parameters, positions of the geospatial entities, surface terrain, occlusions, and visibility. This paper presents a robust and scalable algorithm to detect inconsistencies in vector data using oblique images. The algorithm uses image descriptors to encode the local appearance of a geospatial entity in images. These image descriptors combine color, pixel-intensity gradients, texture, and steerable filter responses. A Support Vector Machine classifier is trained to detect image descriptors that are not consistent with underlying vector data, digital elevation maps, building models, and camera parameters. In this paper, we train the classifier on visible road segments and non-road data. Thereafter, the trained classifier detects inconsistencies in vectors, which include both occluded and misaligned road segments. The consistent road segments validate our vector, DEM, and 3-D model data for those areas while inconsistent segments point out errors. We further show that a search for descriptors that are consistent with visible road segments in the neighborhood of a misaligned road yields the desired road alignment that is consistent with pixels in the image.
* In Proceedings of 16th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems (ACM GIS'08)
PixSelect: Less but Reliable Pixels for Accurate and Efficient Localization
Jun 08, 2022
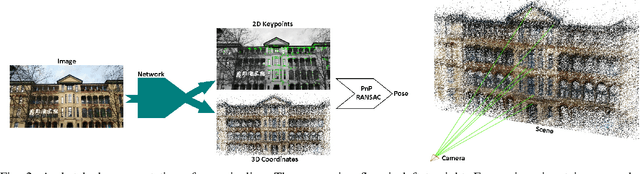


Accurate camera pose estimation is a fundamental requirement for numerous applications, such as autonomous driving, mobile robotics, and augmented reality. In this work, we address the problem of estimating the global 6 DoF camera pose from a single RGB image in a given environment. Previous works consider every part of the image valuable for localization. However, many image regions such as the sky, occlusions, and repetitive non-distinguishable patterns cannot be utilized for localization. In addition to adding unnecessary computation efforts, extracting and matching features from such regions produce many wrong matches which in turn degrades the localization accuracy and efficiency. Our work addresses this particular issue and shows by exploiting an interesting concept of sparse 3D models that we can exploit discriminatory environment parts and avoid useless image regions for the sake of a single image localization. Interestingly, through avoiding selecting keypoints from non-reliable image regions such as trees, bushes, cars, pedestrians, and occlusions, our work acts naturally as an outlier filter. This makes our system highly efficient in that minimal set of correspondences is needed and highly accurate as the number of outliers is low. Our work exceeds state-ofthe-art methods on outdoor Cambridge Landmarks dataset. With only relying on single image at inference, it outweighs in terms of accuracy methods that exploit pose priors and/or reference 3D models while being much faster. By choosing as little as 100 correspondences, it surpasses similar methods that localize from thousands of correspondences, while being more efficient. In particular, it achieves, compared to these methods, an improvement of localization by 33% on OldHospital scene. Furthermore, It outstands direct pose regressors even those that learn from sequence of images
Res-Dense Net for 3D Covid Chest CT-scan classification
Aug 09, 2022One of the most contentious areas of research in Medical Image Preprocessing is 3D CT-scan. With the rapid spread of COVID-19, the function of CT-scan in properly and swiftly diagnosing the disease has become critical. It has a positive impact on infection prevention. There are many tasks to diagnose the illness through CT-scan images, include COVID-19. In this paper, we propose a method that using a Stacking Deep Neural Network to detect the Covid 19 through the series of 3D CT-scans images . In our method, we experiment with two backbones are DenseNet 121 and ResNet 101. This method achieves a competitive performance on some evaluation metrics
FFCNet: Fourier Transform-Based Frequency Learning and Complex Convolutional Network for Colon Disease Classification
Jul 04, 2022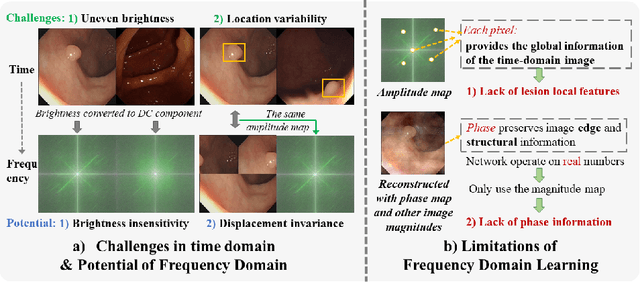
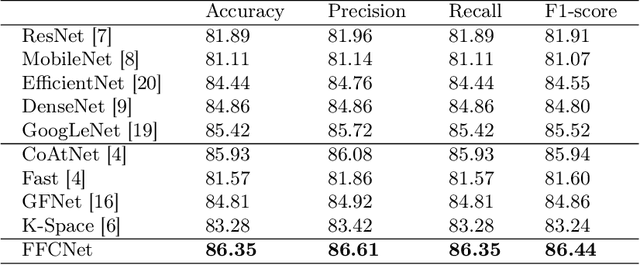
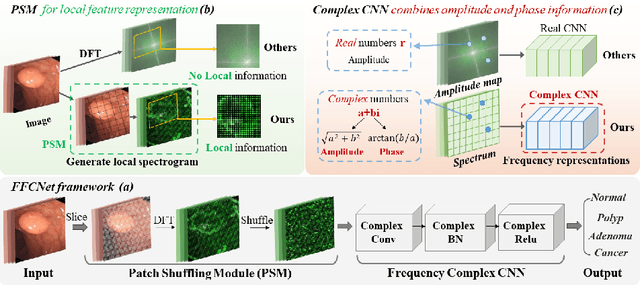
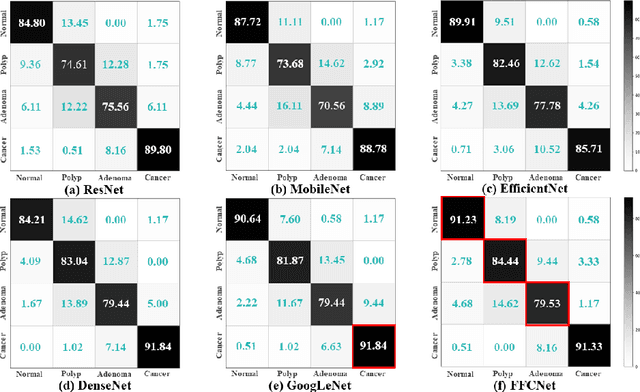
Reliable automatic classification of colonoscopy images is of great significance in assessing the stage of colonic lesions and formulating appropriate treatment plans. However, it is challenging due to uneven brightness, location variability, inter-class similarity, and intra-class dissimilarity, affecting the classification accuracy. To address the above issues, we propose a Fourier-based Frequency Complex Network (FFCNet) for colon disease classification in this study. Specifically, FFCNet is a novel complex network that enables the combination of complex convolutional networks with frequency learning to overcome the loss of phase information caused by real convolution operations. Also, our Fourier transform transfers the average brightness of an image to a point in the spectrum (the DC component), alleviating the effects of uneven brightness by decoupling image content and brightness. Moreover, the image patch scrambling module in FFCNet generates random local spectral blocks, empowering the network to learn long-range and local diseasespecific features and improving the discriminative ability of hard samples. We evaluated the proposed FFCNet on an in-house dataset with 2568 colonoscopy images, showing our method achieves high performance outperforming previous state-of-the art methods with an accuracy of 86:35% and an accuracy of 4.46% higher than the backbone. The project page with code is available at https://github.com/soleilssss/FFCNet.
GPU-accelerated image alignment for object detection in industrial applications
Dec 10, 2021
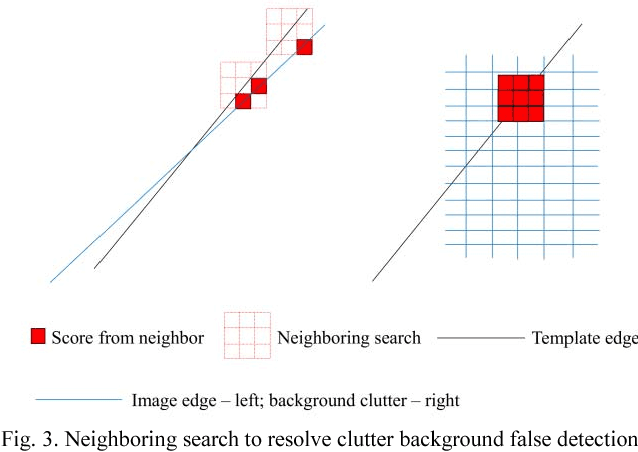

This research proposes a practical method for detecting featureless objects by using image alignment approach with a robust similarity measure in industrial applications. This similarity measure is robust against occlusion, illumination changes and background clutter. The performance of the proposed GPU (Graphics Processing Unit) accelerated algorithm is deemed successful in experiments of comparison between both CPU and GPU implementations
Offset equivariant networks and their applications
Jul 01, 2022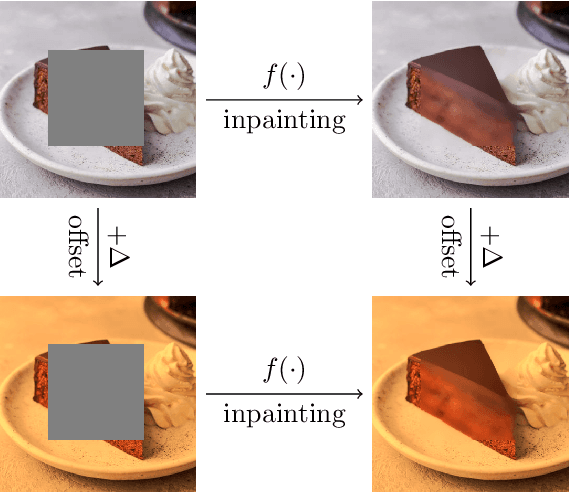
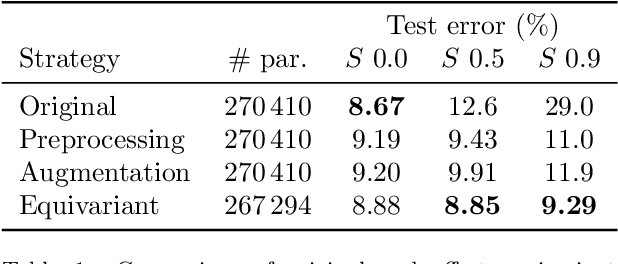
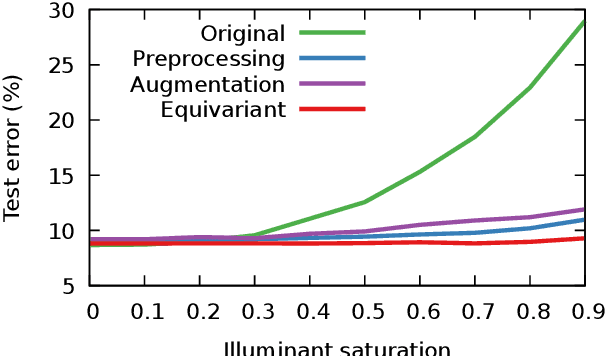
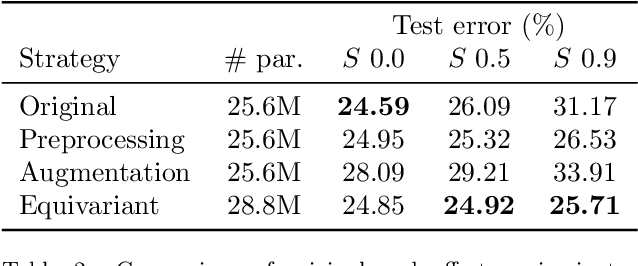
In this paper we present a framework for the design and implementation of offset equivariant networks, that is, neural networks that preserve in their output uniform increments in the input. In a suitable color space this kind of networks achieves equivariance with respect to the photometric transformations that characterize changes in the lighting conditions. We verified the framework on three different problems: image recognition, illuminant estimation, and image inpainting. Our experiments show that the performance of offset equivariant networks are comparable to those in the state of the art on regular data. Differently from conventional networks, however, equivariant networks do behave consistently well when the color of the illuminant changes.
* 13 pages
Adversarial Robustness for Tabular Data through Cost and Utility Awareness
Aug 27, 2022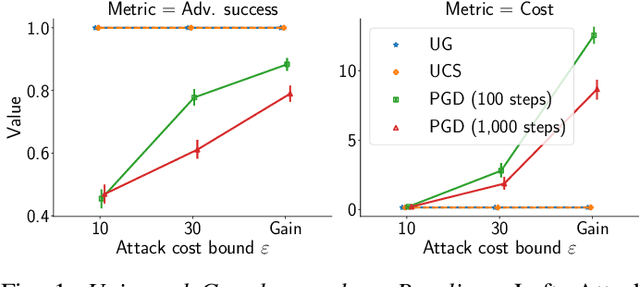
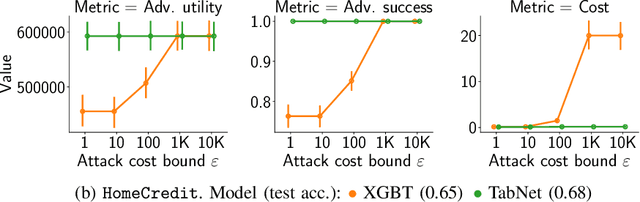
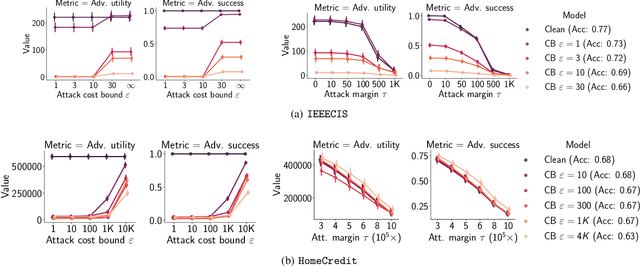
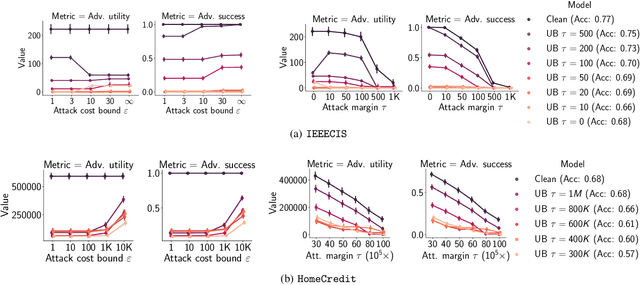
Many machine learning problems use data in the tabular domains. Adversarial examples can be especially damaging for these applications. Yet, existing works on adversarial robustness mainly focus on machine-learning models in the image and text domains. We argue that due to the differences between tabular data and images or text, existing threat models are inappropriate for tabular domains. These models do not capture that cost can be more important than imperceptibility, nor that the adversary could ascribe different value to the utility obtained from deploying different adversarial examples. We show that due to these differences the attack and defence methods used for images and text cannot be directly applied to the tabular setup. We address these issues by proposing new cost and utility-aware threat models tailored to the adversarial capabilities and constraints of attackers targeting tabular domains. We introduce a framework that enables us to design attack and defence mechanisms which result in models protected against cost or utility-aware adversaries, e.g., adversaries constrained by a certain dollar budget. We show that our approach is effective on three tabular datasets corresponding to applications for which adversarial examples can have economic and social implications.