 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
D^2LV: A Data-Driven and Local-Verification Approach for Image Copy Detection
Nov 13, 2021
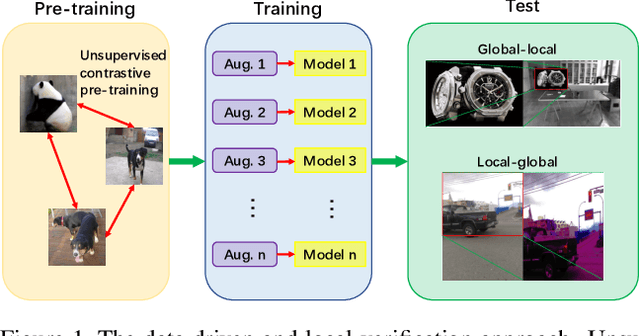
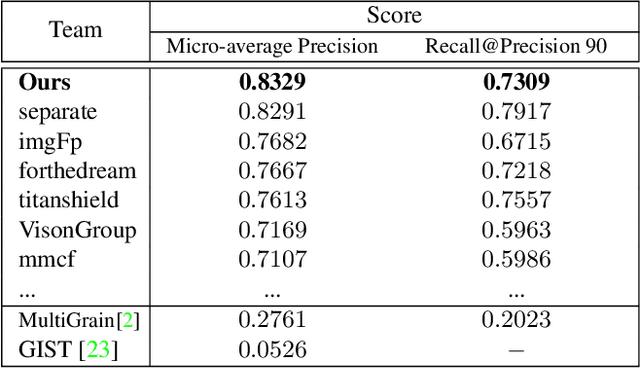
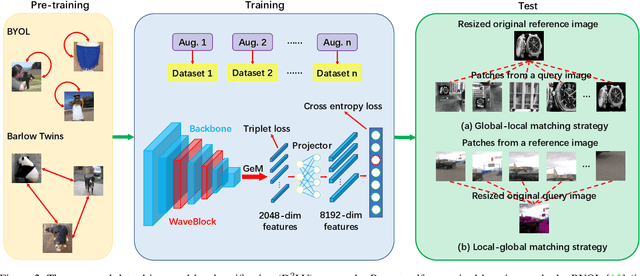
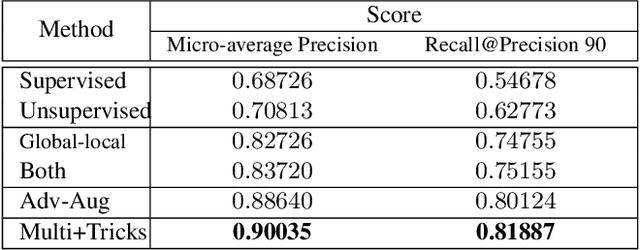
Image copy detection is of great importance in real-life social media. In this paper, a data-driven and local-verification (D^2LV) approach is proposed to compete for Image Similarity Challenge: Matching Track at NeurIPS'21. In D^2LV, unsupervised pre-training substitutes the commonly-used supervised one. When training, we design a set of basic and six advanced transformations, and a simple but effective baseline learns robust representation. During testing, a global-local and local-global matching strategy is proposed. The strategy performs local-verification between reference and query images. Experiments demonstrate that the proposed method is effective. The proposed approach ranks first out of 1,103 participants on the Facebook AI Image Similarity Challenge: Matching Track. The code and trained models are available at https://github.com/WangWenhao0716/ISC-Track1-Submission.
Dynamic Prototype Mask for Occluded Person Re-Identification
Jul 19, 2022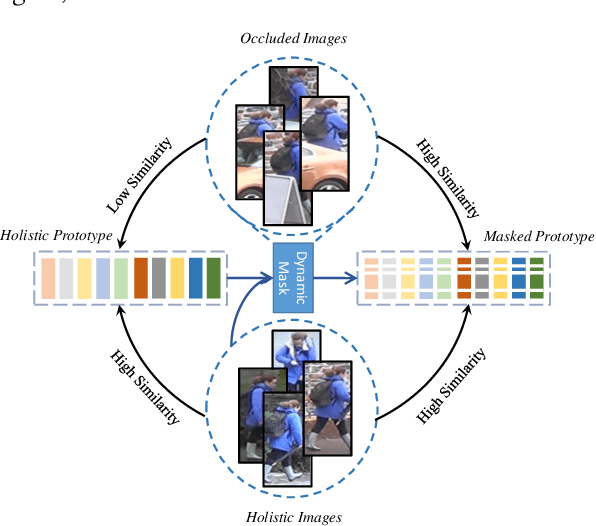
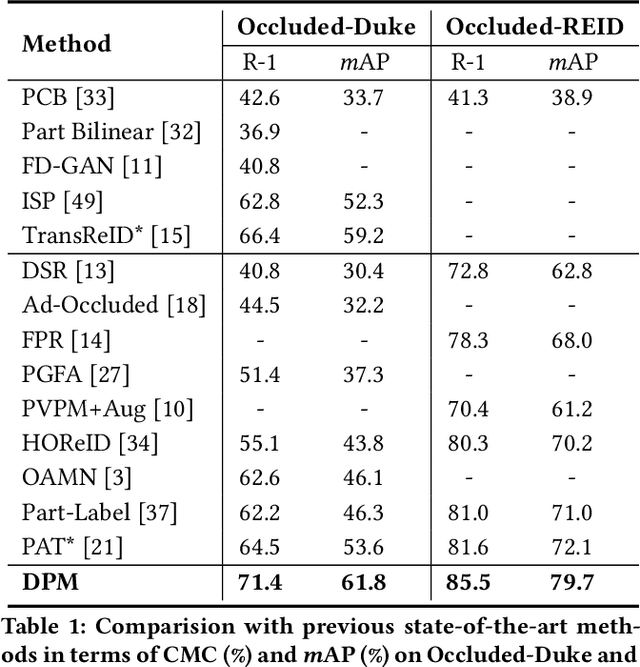
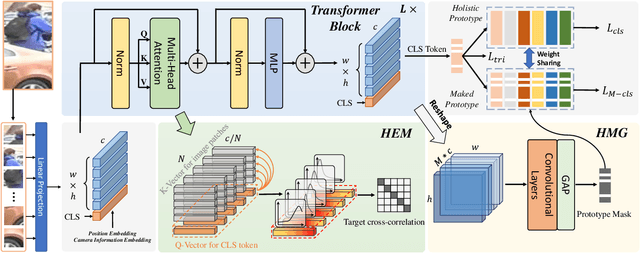
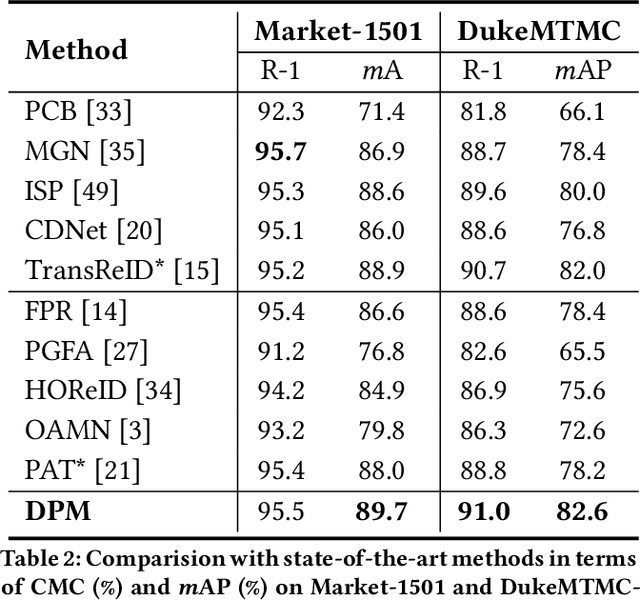
Although person re-identification has achieved an impressive improvement in recent years, the common occlusion case caused by different obstacles is still an unsettled issue in real application scenarios. Existing methods mainly address this issue by employing body clues provided by an extra network to distinguish the visible part. Nevertheless, the inevitable domain gap between the assistant model and the ReID datasets has highly increased the difficulty to obtain an effective and efficient model. To escape from the extra pre-trained networks and achieve an automatic alignment in an end-to-end trainable network, we propose a novel Dynamic Prototype Mask (DPM) based on two self-evident prior knowledge. Specifically, we first devise a Hierarchical Mask Generator which utilizes the hierarchical semantic to select the visible pattern space between the high-quality holistic prototype and the feature representation of the occluded input image. Under this condition, the occluded representation could be well aligned in a selected subspace spontaneously. Then, to enrich the feature representation of the high-quality holistic prototype and provide a more complete feature space, we introduce a Head Enrich Module to encourage different heads to aggregate different patterns representation in the whole image. Extensive experimental evaluations conducted on occluded and holistic person re-identification benchmarks demonstrate the superior performance of the DPM over the state-of-the-art methods. The code is released at https://github.com/stone96123/DPM.
A QuadTree Image Representation for Computational Pathology
Aug 24, 2021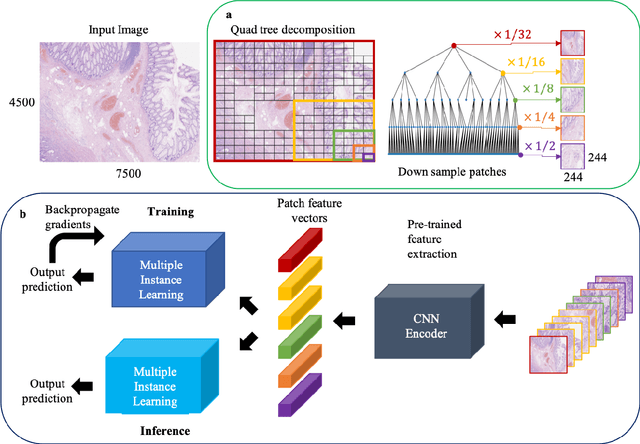
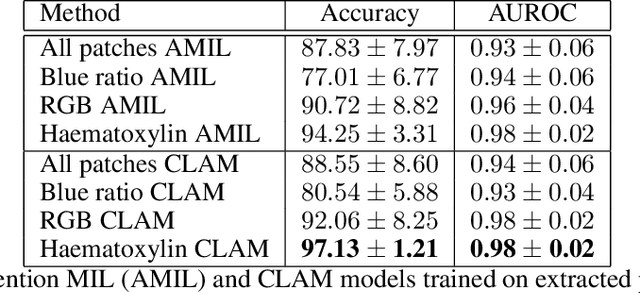


The field of computational pathology presents many challenges for computer vision algorithms due to the sheer size of pathology images. Histopathology images are large and need to be split up into image tiles or patches so modern convolutional neural networks (CNNs) can process them. In this work, we present a method to generate an interpretable image representation of computational pathology images using quadtrees and a pipeline to use these representations for highly accurate downstream classification. To the best of our knowledge, this is the first attempt to use quadtrees for pathology image data. We show it is highly accurate, able to achieve as good results as the currently widely adopted tissue mask patch extraction methods all while using over 38% less data.
Semantic Relation Preserving Knowledge Distillation for Image-to-Image Translation
Apr 30, 2021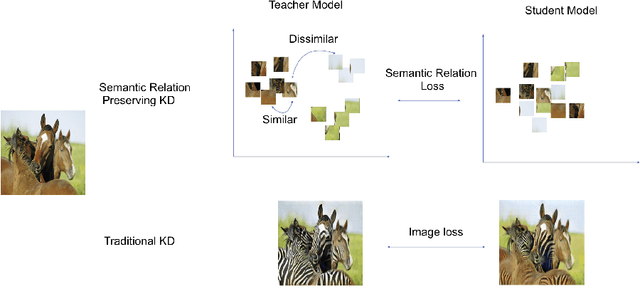
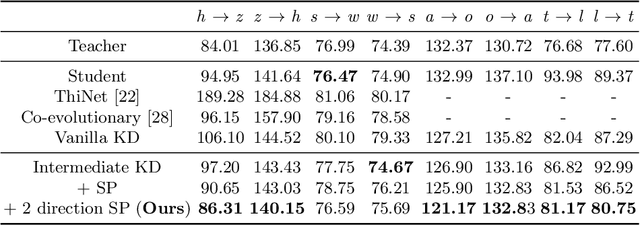
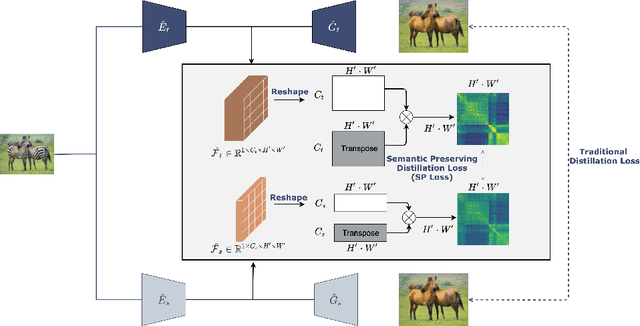
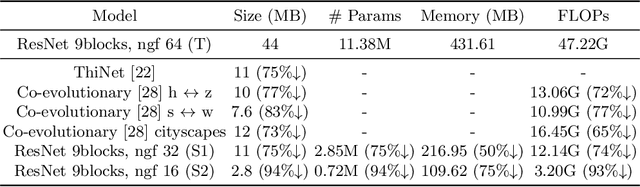
Generative adversarial networks (GANs) have shown significant potential in modeling high dimensional distributions of image data, especially on image-to-image translation tasks. However, due to the complexity of these tasks, state-of-the-art models often contain a tremendous amount of parameters, which results in large model size and long inference time. In this work, we propose a novel method to address this problem by applying knowledge distillation together with distillation of a semantic relation preserving matrix. This matrix, derived from the teacher's feature encoding, helps the student model learn better semantic relations. In contrast to existing compression methods designed for classification tasks, our proposed method adapts well to the image-to-image translation task on GANs. Experiments conducted on 5 different datasets and 3 different pairs of teacher and student models provide strong evidence that our methods achieve impressive results both qualitatively and quantitatively.
On the Activation Function Dependence of the Spectral Bias of Neural Networks
Aug 10, 2022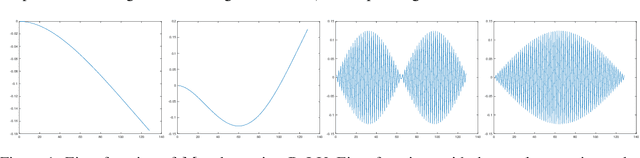
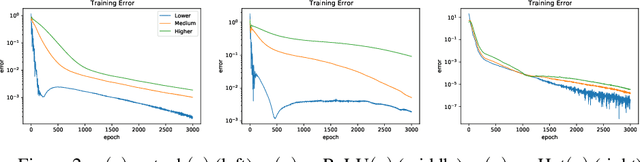
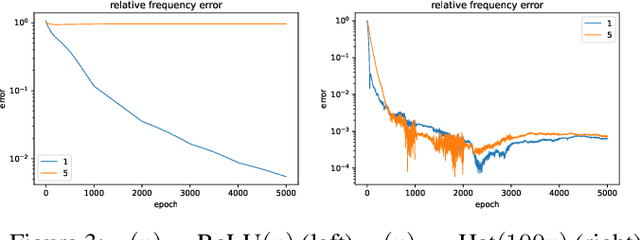
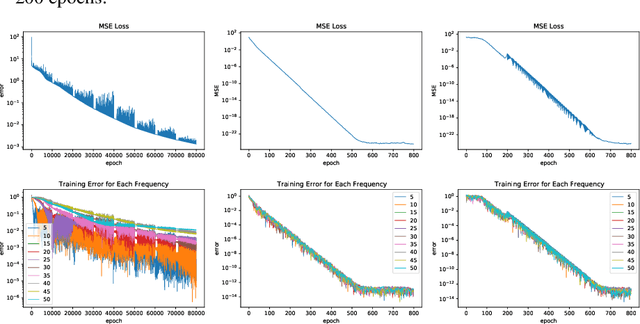
Neural networks are universal function approximators which are known to generalize well despite being dramatically overparameterized. We study this phenomenon from the point of view of the spectral bias of neural networks. Our contributions are two-fold. First, we provide a theoretical explanation for the spectral bias of ReLU neural networks by leveraging connections with the theory of finite element methods. Second, based upon this theory we predict that switching the activation function to a piecewise linear B-spline, namely the Hat function, will remove this spectral bias, which we verify empirically in a variety of settings. Our empirical studies also show that neural networks with the Hat activation function are trained significantly faster using stochastic gradient descent and ADAM. Combined with previous work showing that the Hat activation function also improves generalization accuracy on image classification tasks, this indicates that using the Hat activation provides significant advantages over the ReLU on certain problems.
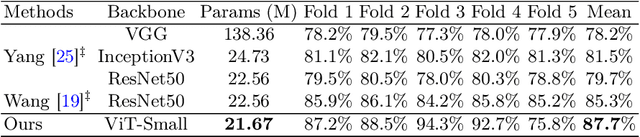
Toward Clinically Assisted Colorectal Polyp Recognition via Structured Cross-modal Representation Consistency
Jun 24, 2022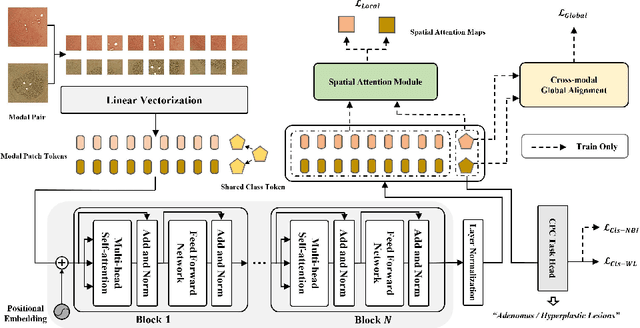
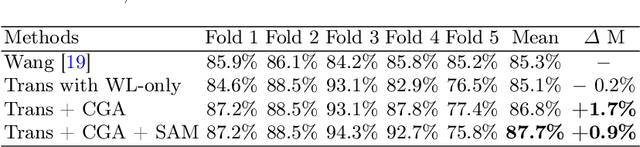
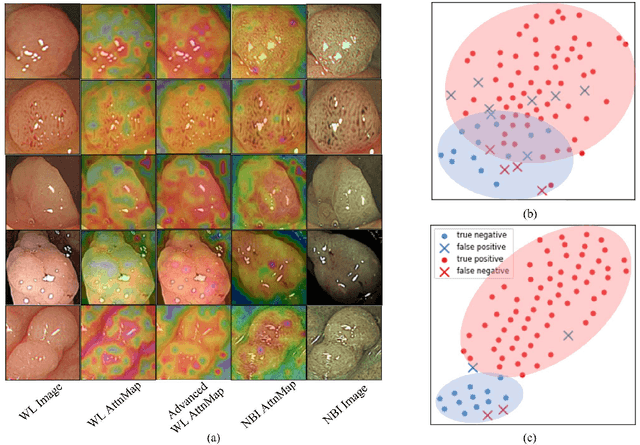
The colorectal polyps classification is a critical clinical examination. To improve the classification accuracy, most computer-aided diagnosis algorithms recognize colorectal polyps by adopting Narrow-Band Imaging (NBI). However, the NBI usually suffers from missing utilization in real clinic scenarios since the acquisition of this specific image requires manual switching of the light mode when polyps have been detected by using White-Light (WL) images. To avoid the above situation, we propose a novel method to directly achieve accurate white-light colonoscopy image classification by conducting structured cross-modal representation consistency. In practice, a pair of multi-modal images, i.e. NBI and WL, are fed into a shared Transformer to extract hierarchical feature representations. Then a novel designed Spatial Attention Module (SAM) is adopted to calculate the similarities between the class token and patch tokens %from multi-levels for a specific modality image. By aligning the class tokens and spatial attention maps of paired NBI and WL images at different levels, the Transformer achieves the ability to keep both global and local representation consistency for the above two modalities. Extensive experimental results illustrate the proposed method outperforms the recent studies with a margin, realizing multi-modal prediction with a single Transformer while greatly improving the classification accuracy when only with WL images.
Depthformer : Multiscale Vision Transformer For Monocular Depth Estimation With Local Global Information Fusion
Jul 12, 2022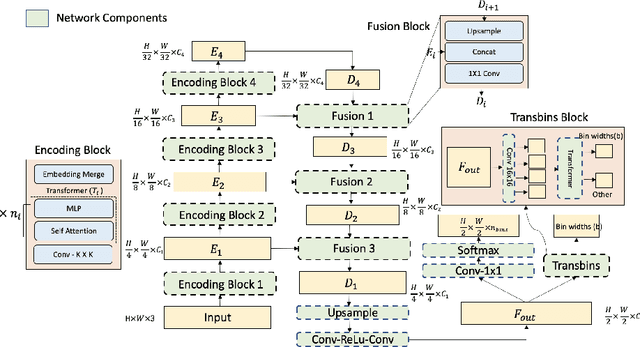
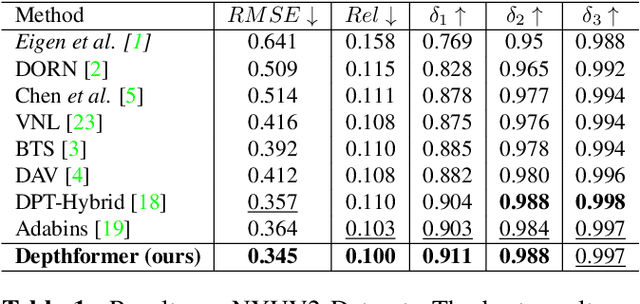

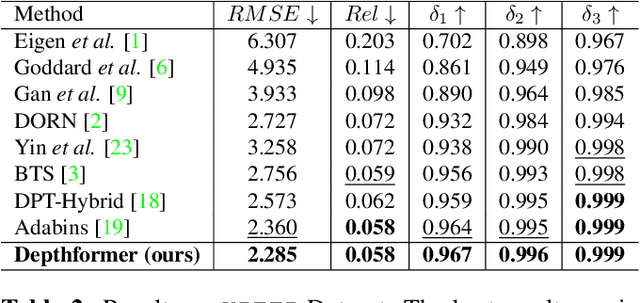
Attention-based models such as transformers have shown outstanding performance on dense prediction tasks, such as semantic segmentation, owing to their capability of capturing long-range dependency in an image. However, the benefit of transformers for monocular depth prediction has seldom been explored so far. This paper benchmarks various transformer-based models for the depth estimation task on an indoor NYUV2 dataset and an outdoor KITTI dataset. We propose a novel attention-based architecture, Depthformer for monocular depth estimation that uses multi-head self-attention to produce the multiscale feature maps, which are effectively combined by our proposed decoder network. We also propose a Transbins module that divides the depth range into bins whose center value is estimated adaptively per image. The final depth estimated is a linear combination of bin centers for each pixel. Transbins module takes advantage of the global receptive field using the transformer module in the encoding stage. Experimental results on NYUV2 and KITTI depth estimation benchmark demonstrate that our proposed method improves the state-of-the-art by 3.3%, and 3.3% respectively in terms of Root Mean Squared Error (RMSE). Code is available at https://github.com/ashutosh1807/Depthformer.git.
Transferring Knowledge with Attention Distillation for Multi-Domain Image-to-Image Translation
Aug 17, 2021



Gradient-based attention modeling has been used widely as a way to visualize and understand convolutional neural networks. However, exploiting these visual explanations during the training of generative adversarial networks (GANs) is an unexplored area in computer vision research. Indeed, we argue that this kind of information can be used to influence GANs training in a positive way. For this reason, in this paper, it is shown how gradient based attentions can be used as knowledge to be conveyed in a teacher-student paradigm for multi-domain image-to-image translation tasks in order to improve the results of the student architecture. Further, it is demonstrated how "pseudo"-attentions can also be employed during training when teacher and student networks are trained on different domains which share some similarities. The approach is validated on multi-domain facial attributes transfer and human expression synthesis showing both qualitative and quantitative results.
VTAMIQ: Transformers for Attention Modulated Image Quality Assessment
Oct 04, 2021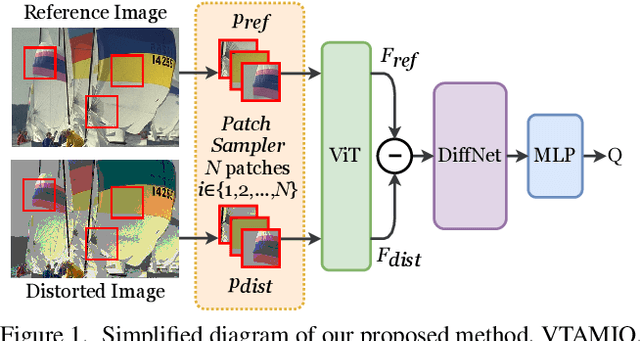
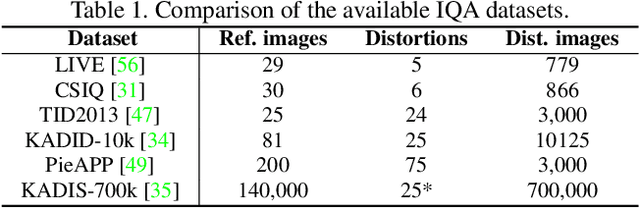
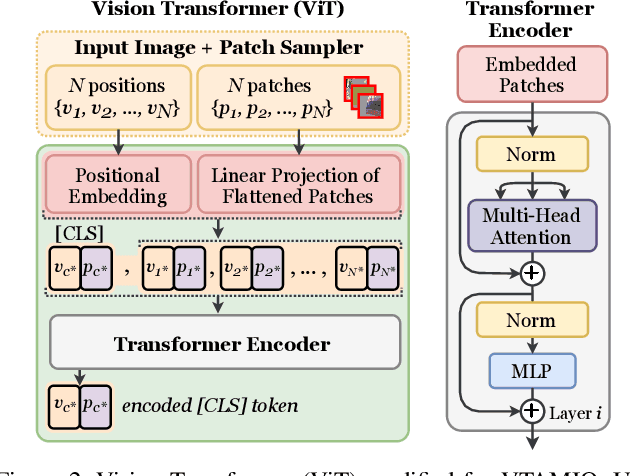
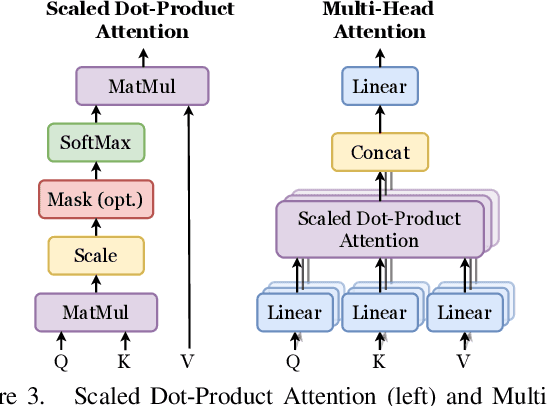
Following the major successes of self-attention and Transformers for image analysis, we investigate the use of such attention mechanisms in the context of Image Quality Assessment (IQA) and propose a novel full-reference IQA method, Vision Transformer for Attention Modulated Image Quality (VTAMIQ). Our method achieves competitive or state-of-the-art performance on the existing IQA datasets and significantly outperforms previous metrics in cross-database evaluations. Most patch-wise IQA methods treat each patch independently; this partially discards global information and limits the ability to model long-distance interactions. We avoid this problem altogether by employing a transformer to encode a sequence of patches as a single global representation, which by design considers interdependencies between patches. We rely on various attention mechanisms -- first with self-attention within the Transformer, and second with channel attention within our difference modulation network -- specifically to reveal and enhance the more salient features throughout our architecture. With large-scale pre-training for both classification and IQA tasks, VTAMIQ generalizes well to unseen sets of images and distortions, further demonstrating the strength of transformer-based networks for vision modelling.
Neuromorphic Visual Scene Understanding with Resonator Networks
Aug 26, 2022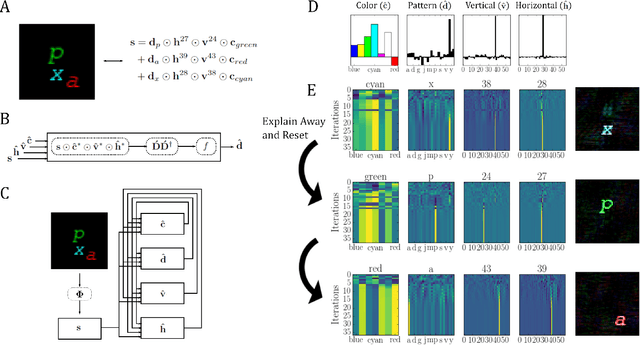
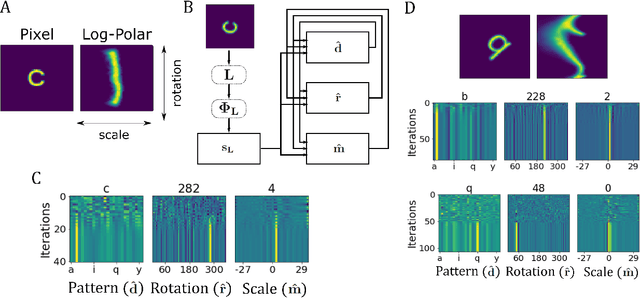
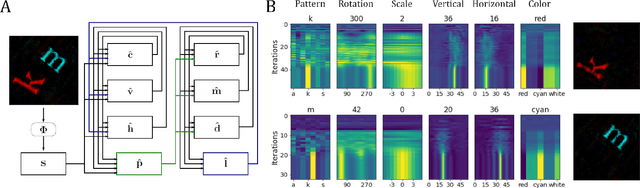
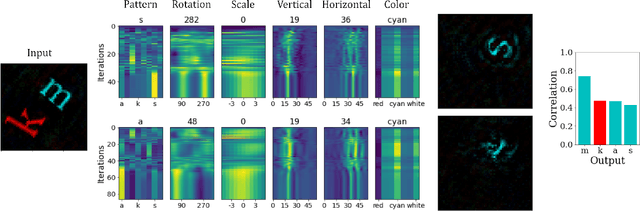
Inferring the position of objects and their rigid transformations is still an open problem in visual scene understanding. Here we propose a neuromorphic solution that utilizes an efficient factorization network which is based on three key concepts: (1) a computational framework based on Vector Symbolic Architectures (VSA) with complex-valued vectors; (2) the design of Hierarchical Resonator Networks (HRN) to deal with the non-commutative nature of translation and rotation in visual scenes, when both are used in combination; (3) the design of a multi-compartment spiking phasor neuron model for implementing complex-valued vector binding on neuromorphic hardware. The VSA framework uses vector binding operations to produce generative image models in which binding acts as the equivariant operation for geometric transformations. A scene can therefore be described as a sum of vector products, which in turn can be efficiently factorized by a resonator network to infer objects and their poses. The HRN enables the definition of a partitioned architecture in which vector binding is equivariant for horizontal and vertical translation within one partition, and for rotation and scaling within the other partition. The spiking neuron model allows to map the resonator network onto efficient and low-power neuromorphic hardware. In this work, we demonstrate our approach using synthetic scenes composed of simple 2D shapes undergoing rigid geometric transformations and color changes. A companion paper demonstrates this approach in real-world application scenarios for machine vision and robotics.