 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Compression with Recurrent Neural Network and Generalized Divisive Normalization
Sep 05, 2021
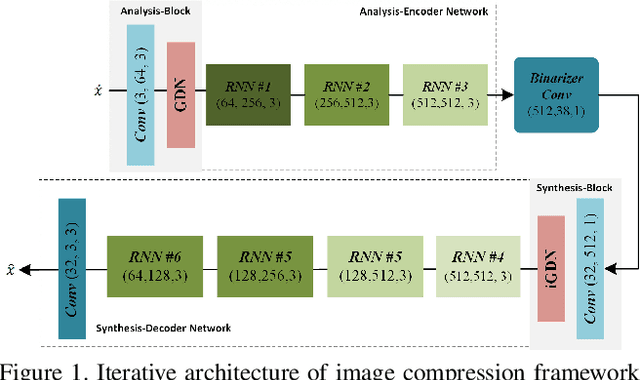
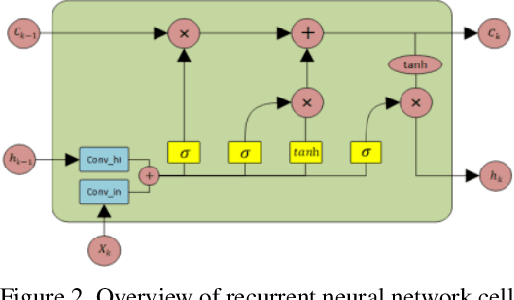
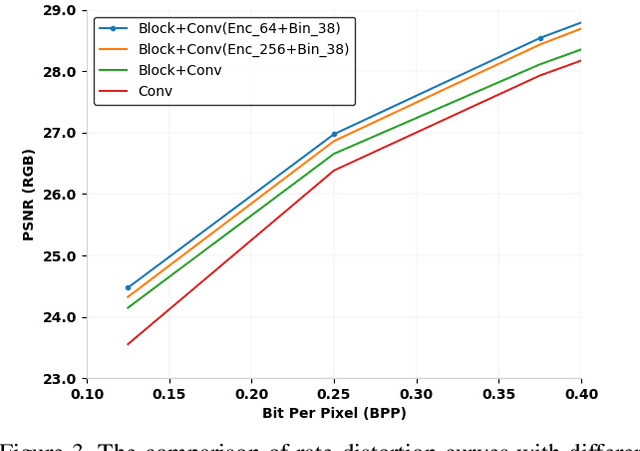
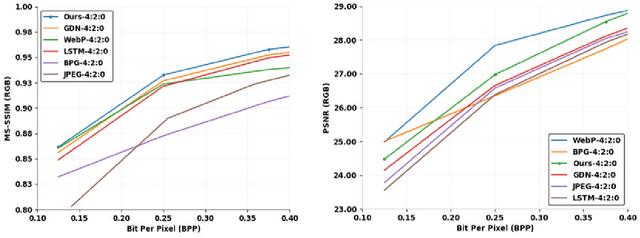
Image compression is a method to remove spatial redundancy between adjacent pixels and reconstruct a high-quality image. In the past few years, deep learning has gained huge attention from the research community and produced promising image reconstruction results. Therefore, recent methods focused on developing deeper and more complex networks, which significantly increased network complexity. In this paper, two effective novel blocks are developed: analysis and synthesis block that employs the convolution layer and Generalized Divisive Normalization (GDN) in the variable-rate encoder and decoder side. Our network utilizes a pixel RNN approach for quantization. Furthermore, to improve the whole network, we encode a residual image using LSTM cells to reduce unnecessary information. Experimental results demonstrated that the proposed variable-rate framework with novel blocks outperforms existing methods and standard image codecs, such as George's ~\cite{002} and JPEG in terms of image similarity. The project page along with code and models are available at https://khawar512.github.io/cvpr/
D^2LV: A Data-Driven and Local-Verification Approach for Image Copy Detection
Nov 13, 2021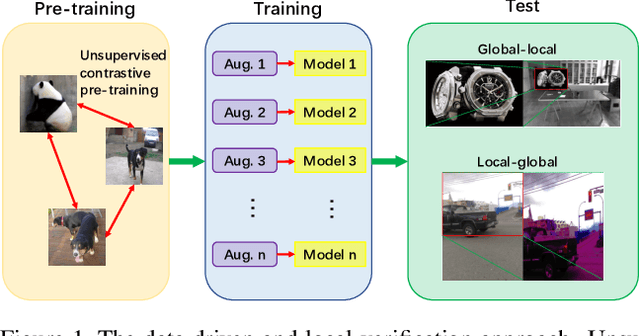
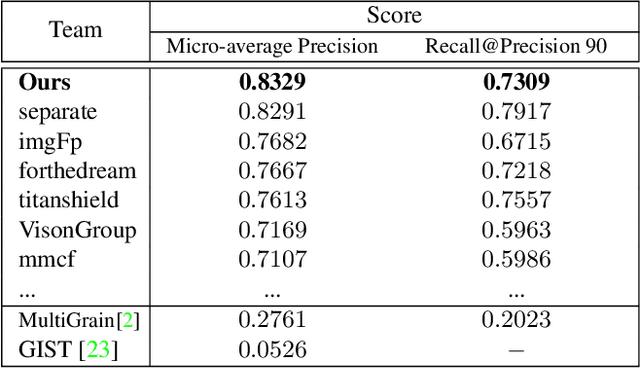
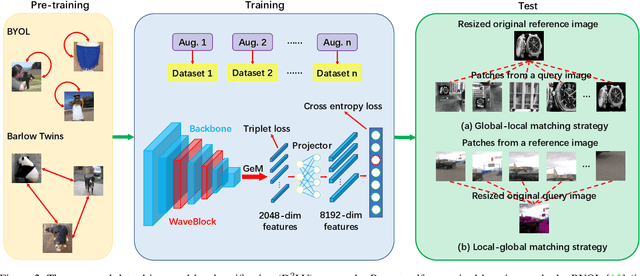
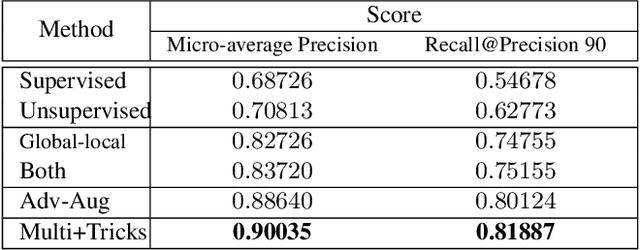
Image copy detection is of great importance in real-life social media. In this paper, a data-driven and local-verification (D^2LV) approach is proposed to compete for Image Similarity Challenge: Matching Track at NeurIPS'21. In D^2LV, unsupervised pre-training substitutes the commonly-used supervised one. When training, we design a set of basic and six advanced transformations, and a simple but effective baseline learns robust representation. During testing, a global-local and local-global matching strategy is proposed. The strategy performs local-verification between reference and query images. Experiments demonstrate that the proposed method is effective. The proposed approach ranks first out of 1,103 participants on the Facebook AI Image Similarity Challenge: Matching Track. The code and trained models are available at https://github.com/WangWenhao0716/ISC-Track1-Submission.
Maximum Entropy on Erroneous Predictions (MEEP): Improving model calibration for medical image segmentation
Dec 22, 2021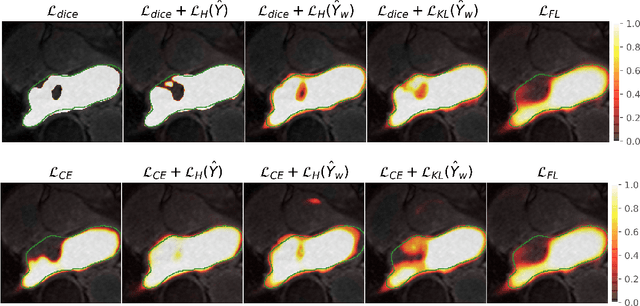
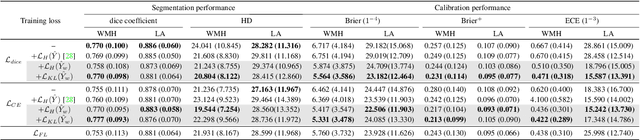
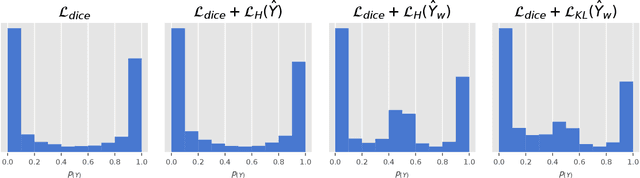
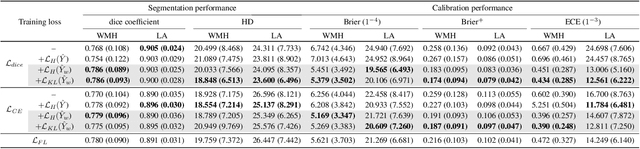
Modern deep neural networks have achieved remarkable progress in medical image segmentation tasks. However, it has recently been observed that they tend to produce overconfident estimates, even in situations of high uncertainty, leading to poorly calibrated and unreliable models. In this work we introduce Maximum Entropy on Erroneous Predictions (MEEP), a training strategy for segmentation networks which selectively penalizes overconfident predictions, focusing only on misclassified pixels. In particular, we design a regularization term that encourages high entropy posteriors for wrong predictions, increasing the network uncertainty in complex scenarios. Our method is agnostic to the neural architecture, does not increase model complexity and can be coupled with multiple segmentation loss functions. We benchmark the proposed strategy in two challenging medical image segmentation tasks: white matter hyperintensity lesions in magnetic resonance images (MRI) of the brain, and atrial segmentation in cardiac MRI. The experimental results demonstrate that coupling MEEP with standard segmentation losses leads to improvements not only in terms of model calibration, but also in segmentation quality.
Semantic Relation Preserving Knowledge Distillation for Image-to-Image Translation
Apr 30, 2021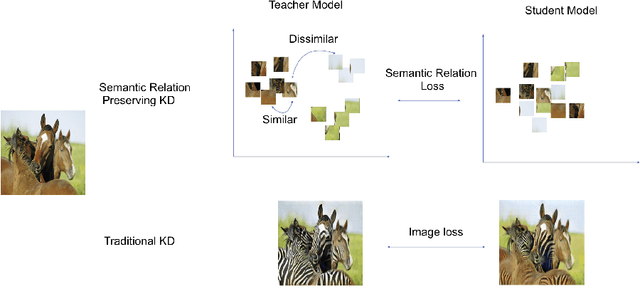
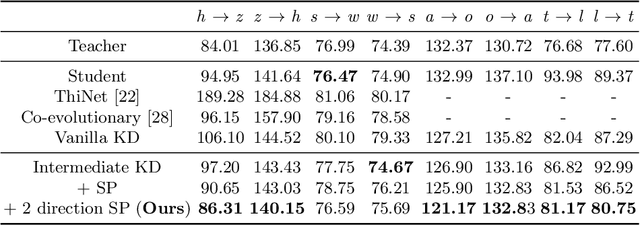
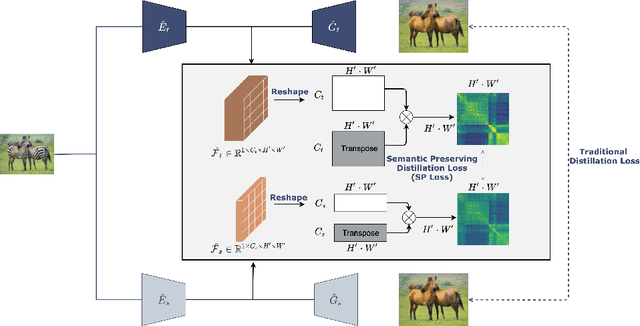
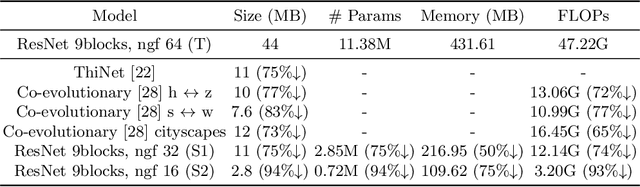
Generative adversarial networks (GANs) have shown significant potential in modeling high dimensional distributions of image data, especially on image-to-image translation tasks. However, due to the complexity of these tasks, state-of-the-art models often contain a tremendous amount of parameters, which results in large model size and long inference time. In this work, we propose a novel method to address this problem by applying knowledge distillation together with distillation of a semantic relation preserving matrix. This matrix, derived from the teacher's feature encoding, helps the student model learn better semantic relations. In contrast to existing compression methods designed for classification tasks, our proposed method adapts well to the image-to-image translation task on GANs. Experiments conducted on 5 different datasets and 3 different pairs of teacher and student models provide strong evidence that our methods achieve impressive results both qualitatively and quantitatively.
Training Generative Adversarial Networks for Optical Property Mapping using Synthetic Image Data
Mar 15, 2022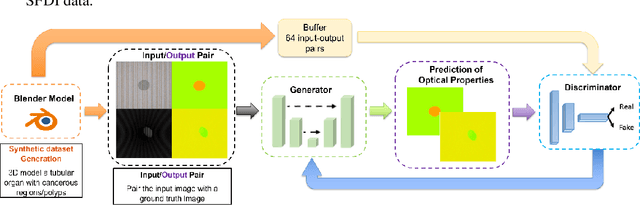

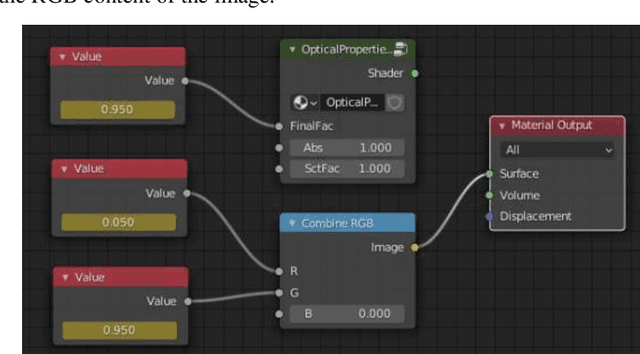
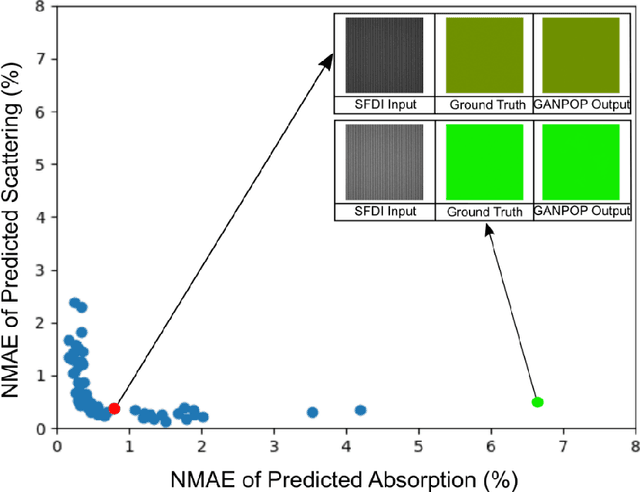
We demonstrate training of a Generative Adversarial Network (GAN) for prediction of optical property maps (scattering and absorption) using spatial frequency domain imaging (SFDI) image data sets generated synthetically with free open-source 3D modelling and rendering software, Blender. The flexibility of Blender is exploited to simulate 3 models with real-life relevance to clinical SFDI of diseased tissue: flat samples, flat samples with spheroidal tumours and cylindrical samples with spheroidal tumours representing imaging inside a tubular organ e.g. the gastro-intestinal tract. In all 3 scenarios we show the GAN provides accurate reconstruction of optical properties from single SFDI images with mean normalised error ranging from 1-1.2% for absorption and 0.7-1.2% for scattering, resulting in visually improved contrast for tumour spheroid structures. This compares favourably with 25% absorption error and 10% scattering error achieved using GANs on experimental SFDI data. However, some of this improvement is due to lower noise and availability of perfect ground truths so we therefore cross-validate our synthetically-trained GAN with a GAN trained on experimental data and observe visually accurate results with error of <40% for absorption and <25% for scattering, due largely to the presence of spatial frequency mismatch artefacts. Our synthetically trained GAN is therefore highly relevant to real experimental samples, but provides significant added benefits of large training datasets, perfect ground-truths and the ability to test realistic imaging geometries, e.g. inside cylinders, for which no conventional single-shot demodulation algorithms exist. In future we expect that application of techniques such as domain adaptation or training on hybrid real-synthetic datasets will create a powerful tool for fast, accurate production of optical property maps from real clinical imaging systems.
A QuadTree Image Representation for Computational Pathology
Aug 24, 2021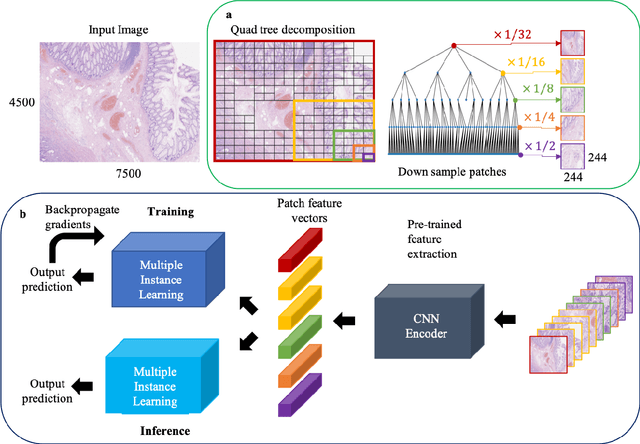
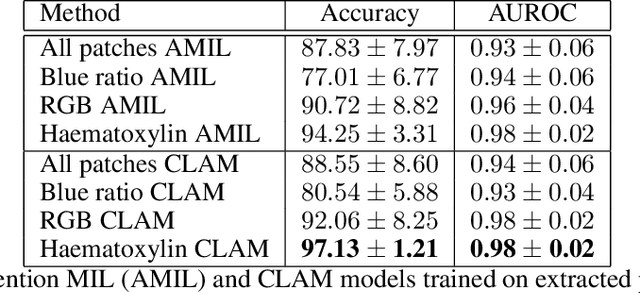


The field of computational pathology presents many challenges for computer vision algorithms due to the sheer size of pathology images. Histopathology images are large and need to be split up into image tiles or patches so modern convolutional neural networks (CNNs) can process them. In this work, we present a method to generate an interpretable image representation of computational pathology images using quadtrees and a pipeline to use these representations for highly accurate downstream classification. To the best of our knowledge, this is the first attempt to use quadtrees for pathology image data. We show it is highly accurate, able to achieve as good results as the currently widely adopted tissue mask patch extraction methods all while using over 38% less data.
Transferring Knowledge with Attention Distillation for Multi-Domain Image-to-Image Translation
Aug 17, 2021



Gradient-based attention modeling has been used widely as a way to visualize and understand convolutional neural networks. However, exploiting these visual explanations during the training of generative adversarial networks (GANs) is an unexplored area in computer vision research. Indeed, we argue that this kind of information can be used to influence GANs training in a positive way. For this reason, in this paper, it is shown how gradient based attentions can be used as knowledge to be conveyed in a teacher-student paradigm for multi-domain image-to-image translation tasks in order to improve the results of the student architecture. Further, it is demonstrated how "pseudo"-attentions can also be employed during training when teacher and student networks are trained on different domains which share some similarities. The approach is validated on multi-domain facial attributes transfer and human expression synthesis showing both qualitative and quantitative results.
Automatic laser steering for middle ear surgery
Aug 18, 2022
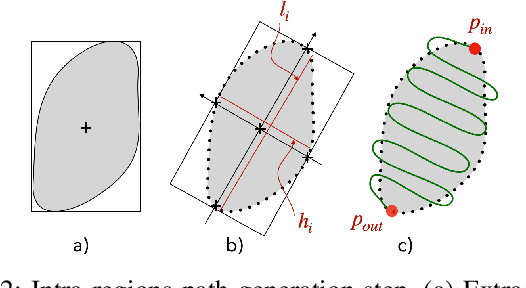
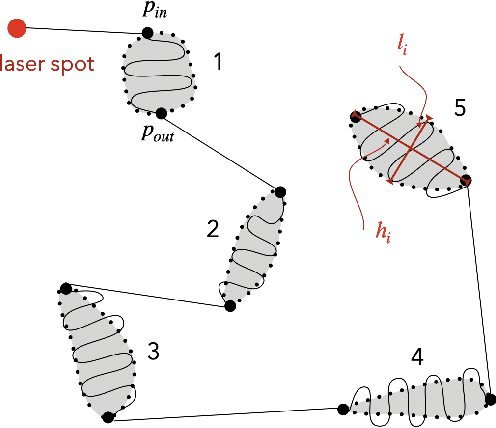
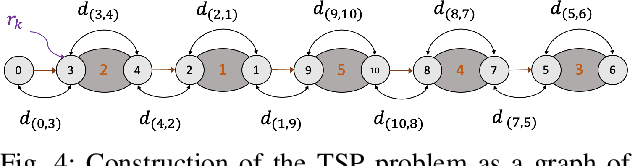
This paper deals with the control of laser spot in the context of minimally invasive surgery of the middle ear, e.g., cholesteatoma removal. More precisely, our work is concerned with the exhaustive burring of residual infected cells after primary mechanical resection of the pathological tissues since the latter cannot guarantee the treatment of all the infected tissues, the remaining infected cells cause regeneration of the diseases in 20%-25\-% of cases, which require a second surgery 12-18 months later. To tackle such a complex surgery, we have developed a robotic platform that consists of the combination of a macro-scale system (7 degrees of freedom (DoFs) robotic arm) and a micro-scale flexible system (2 DoFs) which operates inside the middle ear cavity. To be able to treat the residual cholesteatoma regions, we proposed a method to automatically generate optimal laser scanning trajectories inside the regions and between them. The trajectories are tacked using an image-based control scheme. The proposed method and materials were validated experimentally using the lab-made robotic platform. The obtained results in terms of accuracy and behaviour meet perfectly the laser surgery requirements.
VTAMIQ: Transformers for Attention Modulated Image Quality Assessment
Oct 04, 2021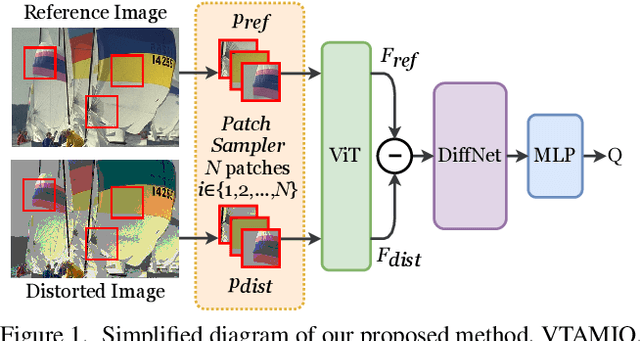
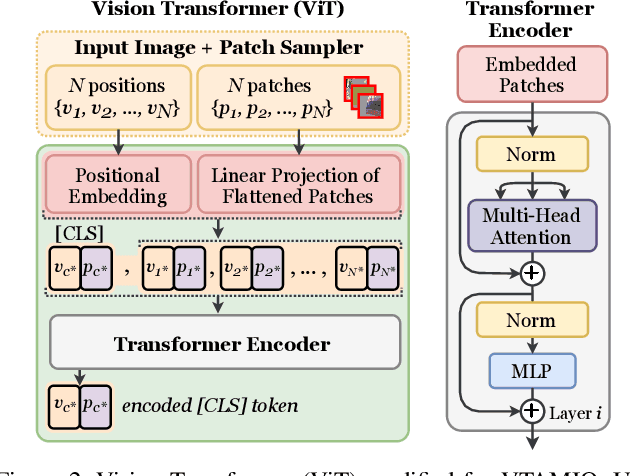
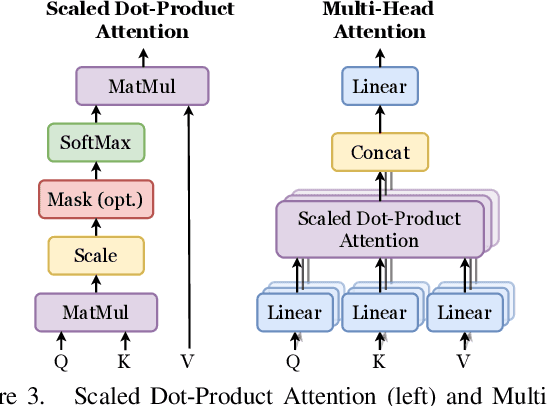
Following the major successes of self-attention and Transformers for image analysis, we investigate the use of such attention mechanisms in the context of Image Quality Assessment (IQA) and propose a novel full-reference IQA method, Vision Transformer for Attention Modulated Image Quality (VTAMIQ). Our method achieves competitive or state-of-the-art performance on the existing IQA datasets and significantly outperforms previous metrics in cross-database evaluations. Most patch-wise IQA methods treat each patch independently; this partially discards global information and limits the ability to model long-distance interactions. We avoid this problem altogether by employing a transformer to encode a sequence of patches as a single global representation, which by design considers interdependencies between patches. We rely on various attention mechanisms -- first with self-attention within the Transformer, and second with channel attention within our difference modulation network -- specifically to reveal and enhance the more salient features throughout our architecture. With large-scale pre-training for both classification and IQA tasks, VTAMIQ generalizes well to unseen sets of images and distortions, further demonstrating the strength of transformer-based networks for vision modelling.
Adaptive and Implicit Regularization for Matrix Completion
Aug 11, 2022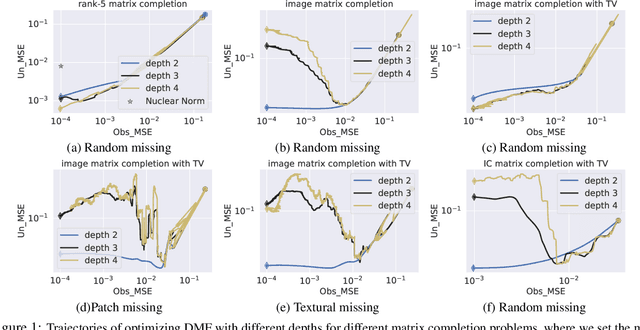
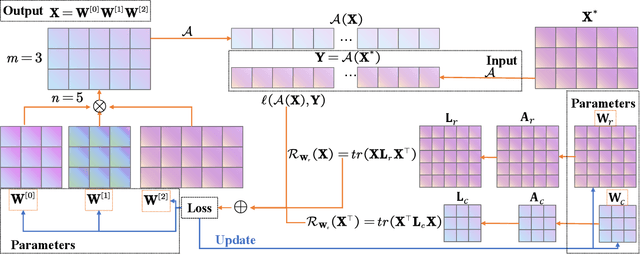
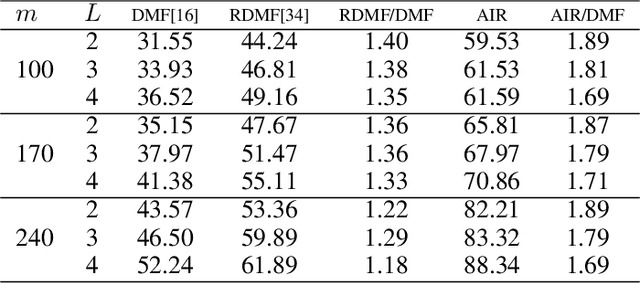
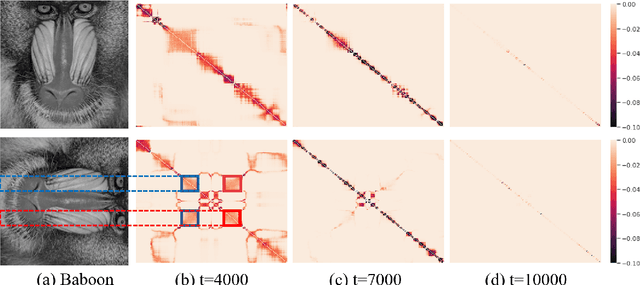
The explicit low-rank regularization, e.g., nuclear norm regularization, has been widely used in imaging sciences. However, it has been found that implicit regularization outperforms explicit ones in various image processing tasks. Another issue is that the fixed explicit regularization limits the applicability to broad images since different images favor different features captured by different explicit regularizations. As such, this paper proposes a new adaptive and implicit low-rank regularization that captures the low-rank prior dynamically from the training data. The core of our new adaptive and implicit low-rank regularization is parameterizing the Laplacian matrix in the Dirichlet energy-based regularization, which we call the regularization AIR. Theoretically, we show that the adaptive regularization of \ReTwo{AIR} enhances the implicit regularization and vanishes at the end of training. We validate AIR's effectiveness on various benchmark tasks, indicating that the AIR is particularly favorable for the scenarios when the missing entries are non-uniform. The code can be found at https://github.com/lizhemin15/AIR-Net.