 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
RefineCap: Concept-Aware Refinement for Image Captioning
Sep 08, 2021
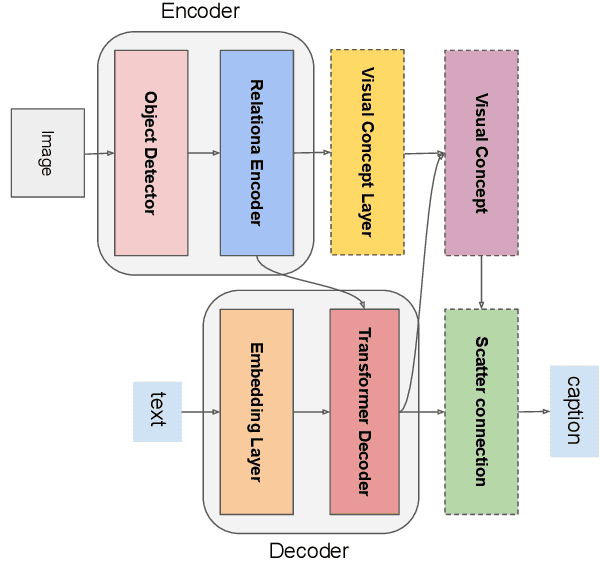
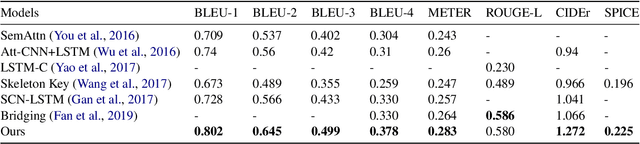

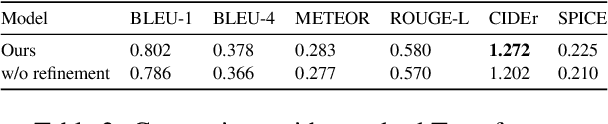
Automatically translating images to texts involves image scene understanding and language modeling. In this paper, we propose a novel model, termed RefineCap, that refines the output vocabulary of the language decoder using decoder-guided visual semantics, and implicitly learns the mapping between visual tag words and images. The proposed Visual-Concept Refinement method can allow the generator to attend to semantic details in the image, thereby generating more semantically descriptive captions. Our model achieves superior performance on the MS-COCO dataset in comparison with previous visual-concept based models.
Word-Level Fine-Grained Story Visualization
Aug 03, 2022

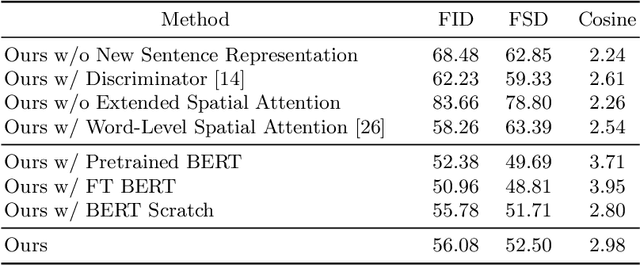
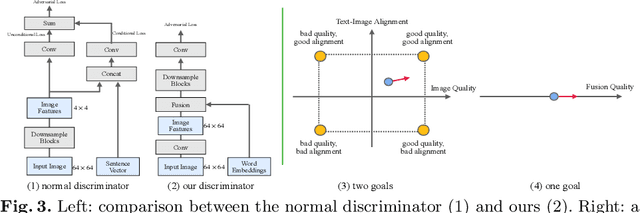
Story visualization aims to generate a sequence of images to narrate each sentence in a multi-sentence story with a global consistency across dynamic scenes and characters. Current works still struggle with output images' quality and consistency, and rely on additional semantic information or auxiliary captioning networks. To address these challenges, we first introduce a new sentence representation, which incorporates word information from all story sentences to mitigate the inconsistency problem. Then, we propose a new discriminator with fusion features and further extend the spatial attention to improve image quality and story consistency. Extensive experiments on different datasets and human evaluation demonstrate the superior performance of our approach, compared to state-of-the-art methods, neither using segmentation masks nor auxiliary captioning networks.
Category-Level Pose Retrieval with Contrastive Features Learnt with Occlusion Augmentation
Aug 16, 2022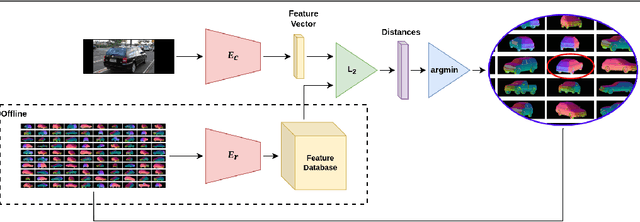
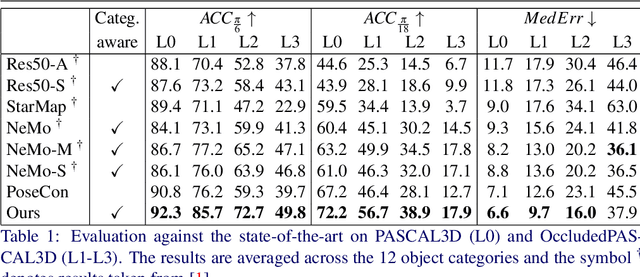

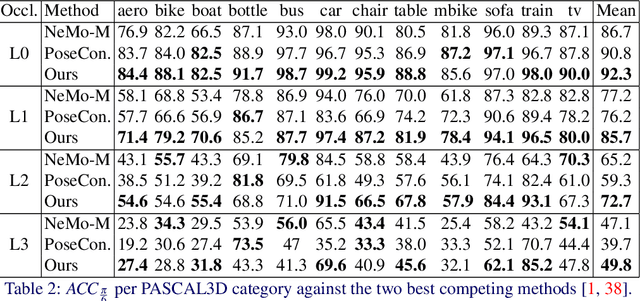
Pose estimation is usually tackled as either a bin classification problem or as a regression problem. In both cases, the idea is to directly predict the pose of an object. This is a non-trivial task because of appearance variations of similar poses and similarities between different poses. Instead, we follow the key idea that it is easier to compare two poses than to estimate them. Render-and-compare approaches have been employed to that end, however, they tend to be unstable, computationally expensive, and slow for real-time applications. We propose doing category-level pose estimation by learning an alignment metric using a contrastive loss with a dynamic margin and a continuous pose-label space. For efficient inference, we use a simple real-time image retrieval scheme with a reference set of renderings projected to an embedding space. To achieve robustness to real-world conditions, we employ synthetic occlusions, bounding box perturbations, and appearance augmentations. Our approach achieves state-of-the-art performance on PASCAL3D and OccludedPASCAL3D, as well as high-quality results on KITTI3D.
Using Soft Labels to Model Uncertainty in Medical Image Segmentation
Sep 26, 2021
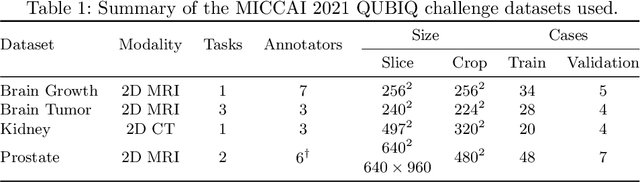
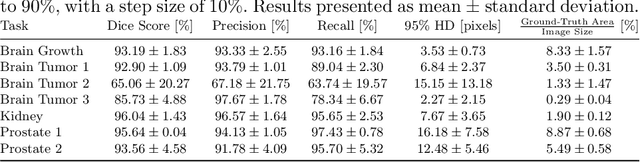
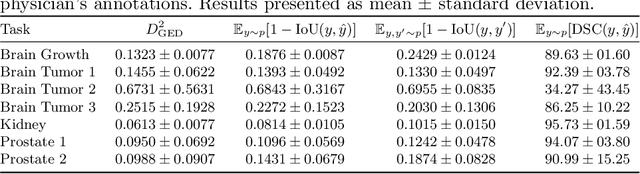
Medical image segmentation is inherently uncertain. For a given image, there may be multiple plausible segmentation hypotheses, and physicians will often disagree on lesion and organ boundaries. To be suited to real-world application, automatic segmentation systems must be able to capture this uncertainty and variability. Thus far, this has been addressed by building deep learning models that, through dropout, multiple heads, or variational inference, can produce a set - infinite, in some cases - of plausible segmentation hypotheses for any given image. However, in clinical practice, it may not be practical to browse all hypotheses. Furthermore, recent work shows that segmentation variability plateaus after a certain number of independent annotations, suggesting that a large enough group of physicians may be able to represent the whole space of possible segmentations. Inspired by this, we propose a simple method to obtain soft labels from the annotations of multiple physicians and train models that, for each image, produce a single well-calibrated output that can be thresholded at multiple confidence levels, according to each application's precision-recall requirements. We evaluated our method on the MICCAI 2021 QUBIQ challenge, showing that it performs well across multiple medical image segmentation tasks, produces well-calibrated predictions, and, on average, performs better at matching physicians' predictions than other physicians.
GAMa: Cross-view Video Geo-localization
Jul 06, 2022
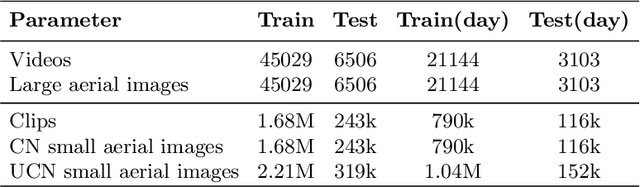


The existing work in cross-view geo-localization is based on images where a ground panorama is matched to an aerial image. In this work, we focus on ground videos instead of images which provides additional contextual cues which are important for this task. There are no existing datasets for this problem, therefore we propose GAMa dataset, a large-scale dataset with ground videos and corresponding aerial images. We also propose a novel approach to solve this problem. At clip-level, a short video clip is matched with corresponding aerial image and is later used to get video-level geo-localization of a long video. Moreover, we propose a hierarchical approach to further improve the clip-level geolocalization. It is a challenging dataset, unaligned and limited field of view, and our proposed method achieves a Top-1 recall rate of 19.4% and 45.1% @1.0mile. Code and dataset are available at following link: https://github.com/svyas23/GAMa.
Learning-based Noise Component Map Estimation for Image Denoising
Sep 24, 2021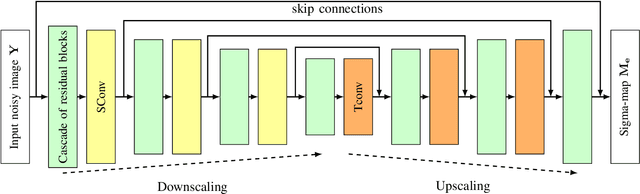
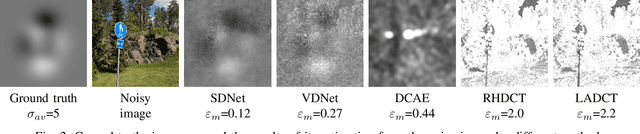
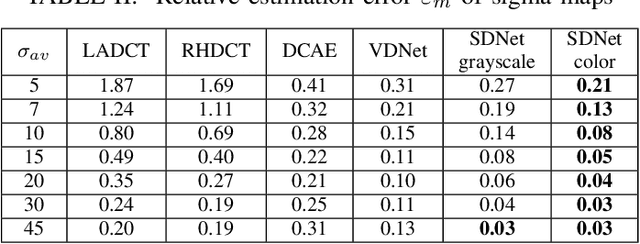
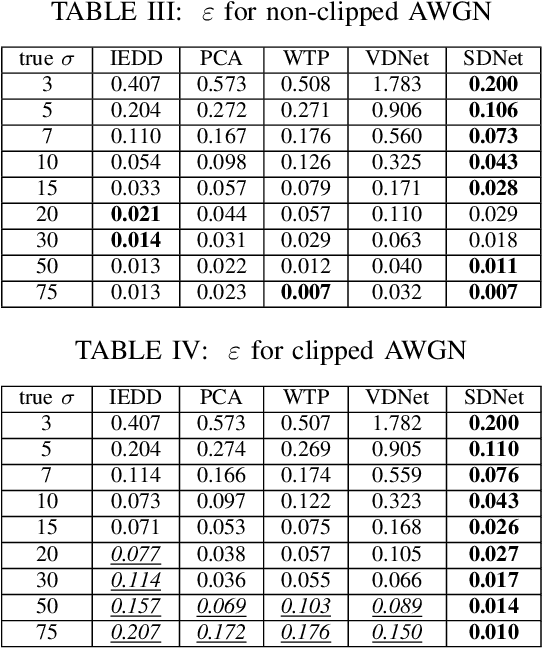
A problem of image denoising when images are corrupted by a non-stationary noise is considered in this paper. Since in practice no a priori information on noise is available, noise statistics should be pre-estimated for image denoising. In this paper, deep convolutional neural network (CNN) based method for estimation of a map of local, patch-wise, standard deviations of noise (so-called sigma-map) is proposed. It achieves the state-of-the-art performance in accuracy of estimation of sigma-map for the case of non-stationary noise, as well as estimation of noise variance for the case of additive white Gaussian noise. Extensive experiments on image denoising using estimated sigma-maps demonstrate that our method outperforms recent CNN-based blind image denoising methods by up to 6 dB in PSNR, as well as other state-of-the-art methods based on sigma-map estimation by up to 0.5 dB, providing same time better usage flexibility. Comparison with the ideal case, when denoising is applied using ground-truth sigma-map, shows that a difference of corresponding PSNR values for most of noise levels is within 0.1-0.2 dB and does not exceeds 0.6 dB.
Convergence of denoising diffusion models under the manifold hypothesis
Aug 10, 2022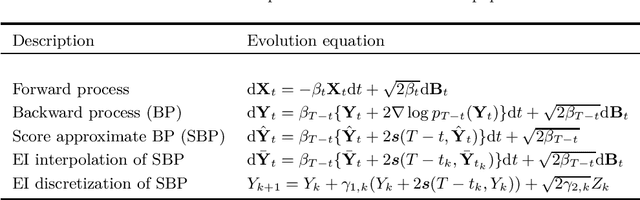
Denoising diffusion models are a recent class of generative models exhibiting state-of-the-art performance in image and audio synthesis. Such models approximate the time-reversal of a forward noising process from a target distribution to a reference density, which is usually Gaussian. Despite their strong empirical results, the theoretical analysis of such models remains limited. In particular, all current approaches crucially assume that the target density admits a density w.r.t. the Lebesgue measure. This does not cover settings where the target distribution is supported on a lower-dimensional manifold or is given by some empirical distribution. In this paper, we bridge this gap by providing the first convergence results for diffusion models in this more general setting. In particular, we provide quantitative bounds on the Wasserstein distance of order one between the target data distribution and the generative distribution of the diffusion model.
Attention-based Multi-Reference Learning for Image Super-Resolution
Aug 31, 2021
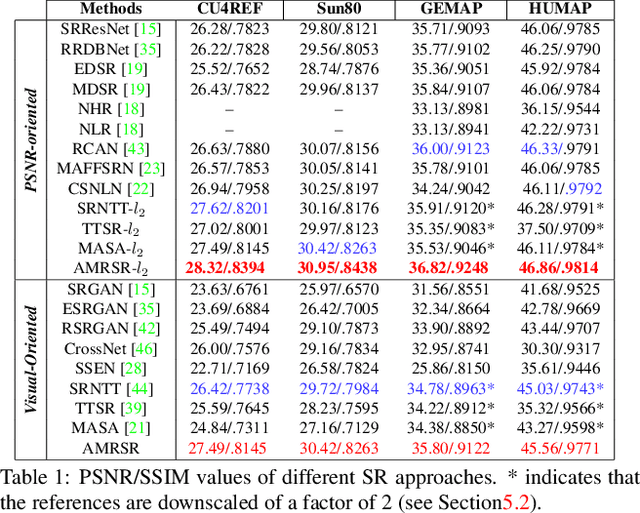
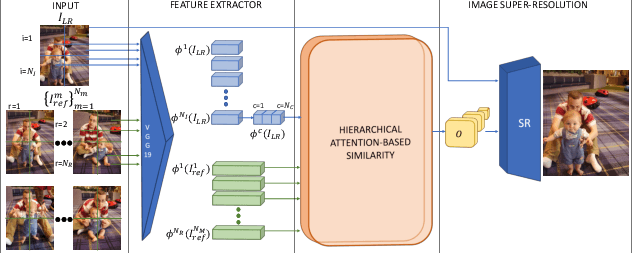
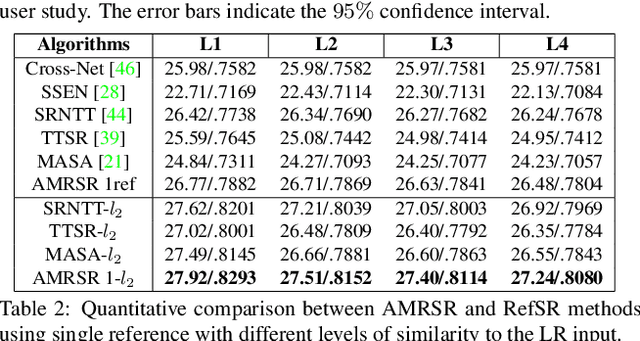
This paper proposes a novel Attention-based Multi-Reference Super-resolution network (AMRSR) that, given a low-resolution image, learns to adaptively transfer the most similar texture from multiple reference images to the super-resolution output whilst maintaining spatial coherence. The use of multiple reference images together with attention-based sampling is demonstrated to achieve significantly improved performance over state-of-the-art reference super-resolution approaches on multiple benchmark datasets. Reference super-resolution approaches have recently been proposed to overcome the ill-posed problem of image super-resolution by providing additional information from a high-resolution reference image. Multi-reference super-resolution extends this approach by providing a more diverse pool of image features to overcome the inherent information deficit whilst maintaining memory efficiency. A novel hierarchical attention-based sampling approach is introduced to learn the similarity between low-resolution image features and multiple reference images based on a perceptual loss. Ablation demonstrates the contribution of both multi-reference and hierarchical attention-based sampling to overall performance. Perceptual and quantitative ground-truth evaluation demonstrates significant improvement in performance even when the reference images deviate significantly from the target image. The project website can be found at https://marcopesavento.github.io/AMRSR/
Introduction of Integrated Image Deep Learning Solution and how it brought laboratorial level heart rate and blood oxygen results to everyone
Apr 13, 2022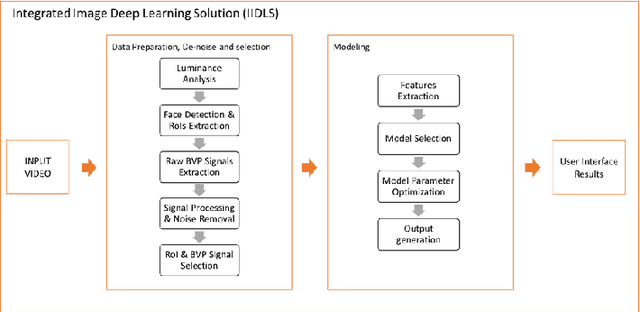
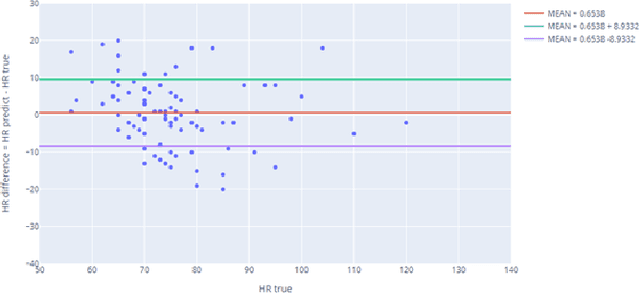
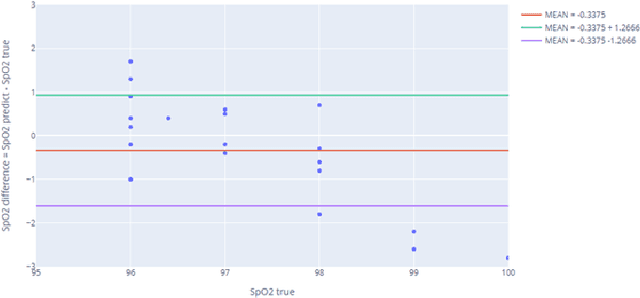
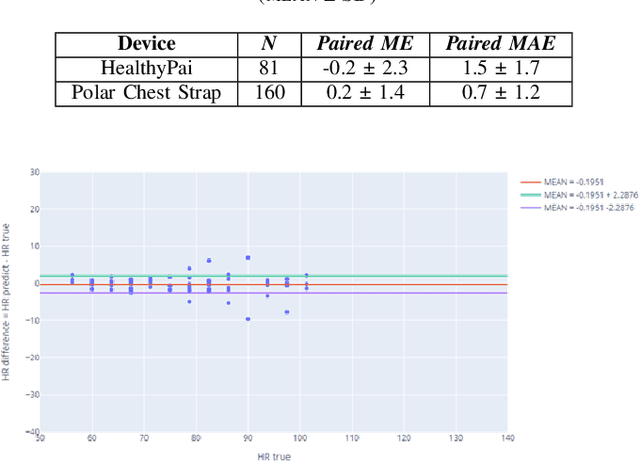
The general public and medical professionals recognized the importance of accurately measuring and storing blood oxygen levels and heart rate during the COVID-19 pandemic. The demand for accurate contact-less devices was motivated by the need for cross-infection reduction and the shortage of conventional oximeters, partially due to the global supply chain issue. This paper evaluated a contact-less mini-program HealthyPai's heart rate (HR) and oxygen saturation (SpO2) measurements compared with other wearable devices. In the HR study of 185 samples (81 in the laboratory environment, 104 in the real-life environment), the mean absolute error (MAE) $\pm$ standard deviation was $1.4827 \pm 1.7452$ in the lab, $6.9231 \pm 5.6426$ in the real-life setting. In the SpO2 study of 24 samples, the mean absolute error (MAE) $\pm$ standard deviation of the measurement was $1.0375 \pm 0.7745$. Our results validated that HealthyPai utilizing the Integrated Image Deep Learning Solution (IIDLS) framework can accurately measure HR and SpO2, providing the test quality at least comparable to other FDA-approved wearable devices in the market and surpassing the consumer-grade and research-grade wearable standards.
Deep Image Compositing
Mar 29, 2021

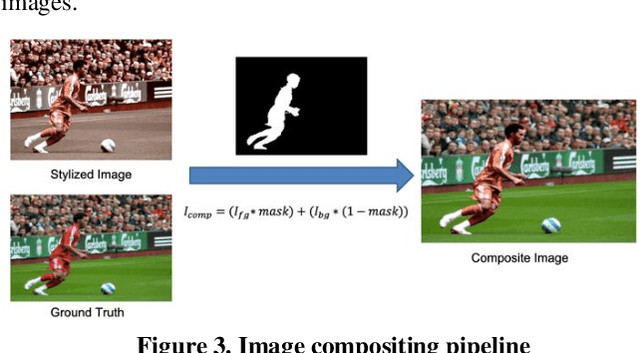
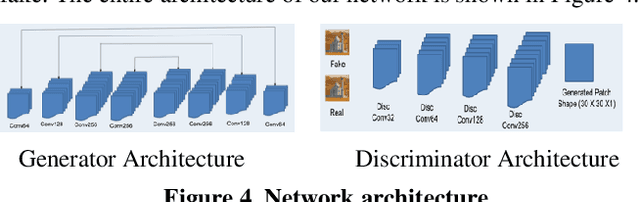
In image editing, the most common task is pasting objects from one image to the other and then eventually adjusting the manifestation of the foreground object with the background object. This task is called image compositing. But image compositing is a challenging problem that requires professional editing skills and a considerable amount of time. Not only these professionals are expensive to hire, but the tools (like Adobe Photoshop) used for doing such tasks are also expensive to purchase making the overall task of image compositing difficult for people without this skillset. In this work, we aim to cater to this problem by making composite images look realistic. To achieve this, we are using Generative Adversarial Networks (GANS). By training the network with a diverse range of filters applied to the images and special loss functions, the model is able to decode the color histogram of the foreground and background part of the image and also learns to blend the foreground object with the background. The hue and saturation values of the image play an important role as discussed in this paper. To the best of our knowledge, this is the first work that uses GANs for the task of image compositing. Currently, there is no benchmark dataset available for image compositing. So we created the dataset and will also make the dataset publicly available for benchmarking. Experimental results on this dataset show that our method outperforms all current state-of-the-art methods.
* ESSE 2020: Proceedings of the 2020 European Symposium on Software Engineering