 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Boundary-Aware Network for Kidney Parsing
Aug 29, 2022
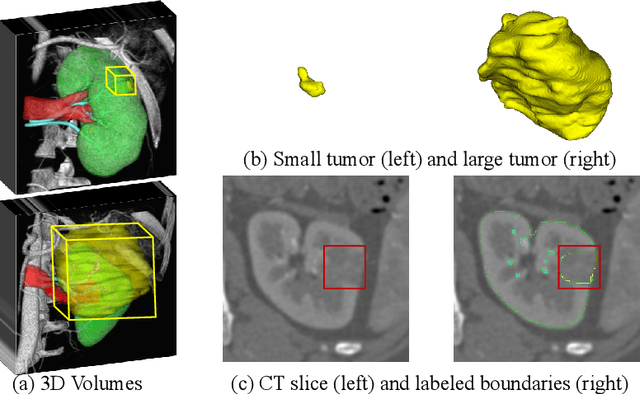
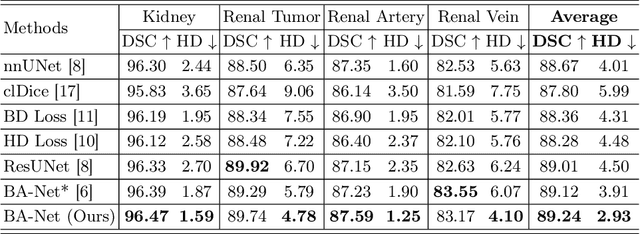
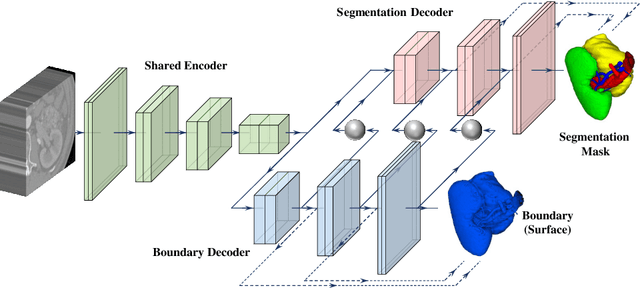
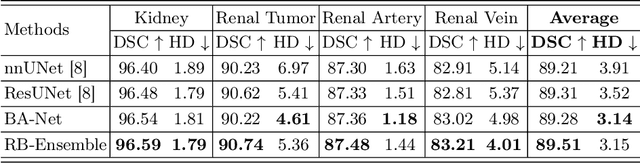
Kidney structures segmentation is a crucial yet challenging task in the computer-aided diagnosis of surgery-based renal cancer. Although numerous deep learning models have achieved remarkable success in many medical image segmentation tasks, accurate segmentation of kidney structures on computed tomography angiography (CTA) images remains challenging, due to the variable sizes of kidney tumors and the ambiguous boundaries between kidney structures and their surroundings. In this paper, we propose a boundary-aware network (BA-Net) to segment kidneys, kidney tumors, arteries, and veins on CTA scans. This model contains a shared encoder, a boundary decoder, and a segmentation decoder. The multi-scale deep supervision strategy is adopted on both decoders, which can alleviate the issues caused by variable tumor sizes. The boundary probability maps produced by the boundary decoder at each scale are used as attention to enhance the segmentation feature maps. We evaluated the BA-Net on the Kidney PArsing (KiPA) Challenge dataset and achieved an average Dice score of 89.65$\%$ for kidney structure segmentation on CTA scans using 4-fold cross-validation. The results demonstrate the effectiveness of the BA-Net.
Real-Time Mask Detection Based on SSD-MobileNetV2
Aug 29, 2022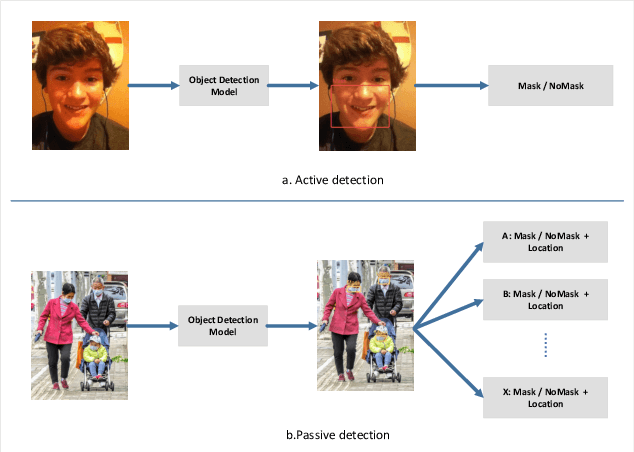
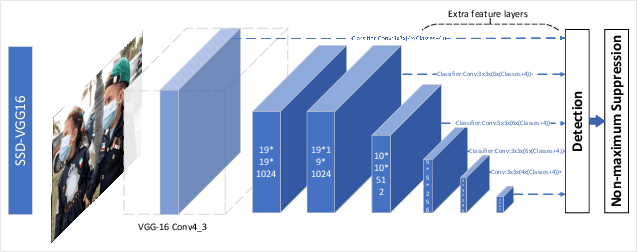
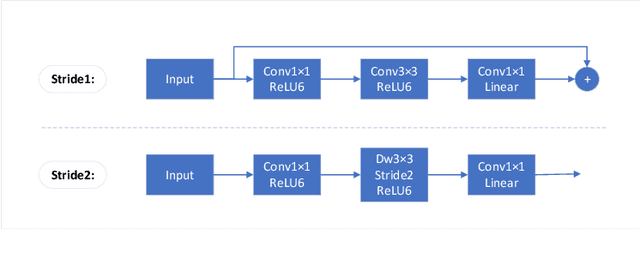
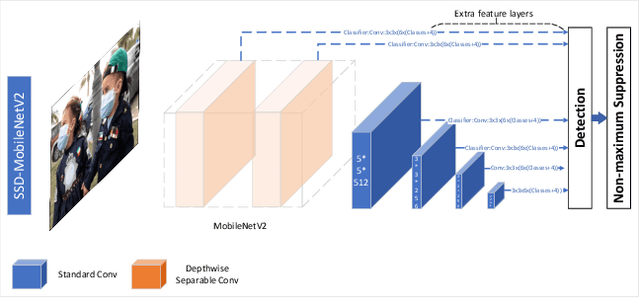
After the outbreak of COVID-19, mask detection, as the most convenient and effective means of prevention, plays a crucial role in epidemic prevention and control. An excellent automatic real-time mask detection system can reduce a lot of work pressure for relevant staff. However, by analyzing the existing mask detection approaches, we find that they are mostly resource-intensive and do not achieve a good balance between speed and accuracy. And there is no perfect face mask dataset at present. In this paper, we propose a new architecture for mask detection. Our system uses SSD as the mask locator and classifier, and further replaces VGG-16 with MobileNetV2 to extract the features of the image and reduce a lot of parameters. Therefore, our system can be deployed on embedded devices. Transfer learning methods are used to transfer pre-trained models from other domains to our model. Data enhancement methods in our system such as MixUp effectively prevent overfitting. It also effectively reduces the dependence on large-scale datasets. By doing experiments in practical scenarios, the results demonstrate that our system performed well in real-time mask detection.
Deep Model-Based Architectures for Inverse Problems under Mismatched Priors
Jul 26, 2022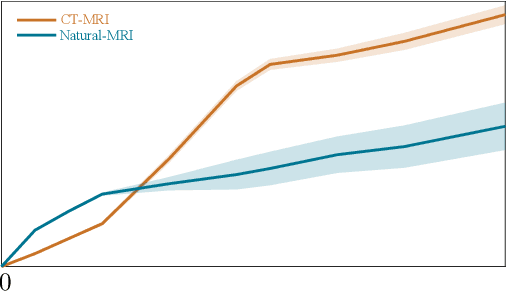
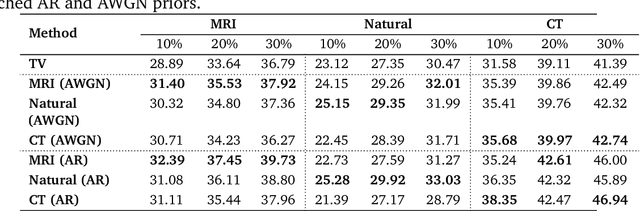
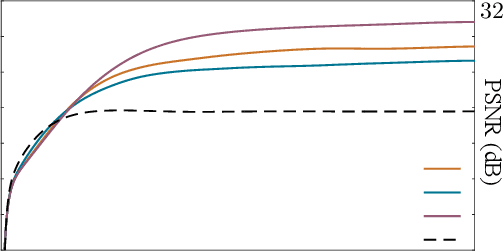
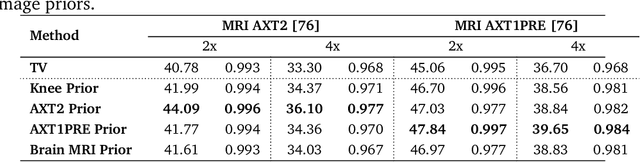
There is a growing interest in deep model-based architectures (DMBAs) for solving imaging inverse problems by combining physical measurement models and learned image priors specified using convolutional neural nets (CNNs). For example, well-known frameworks for systematically designing DMBAs include plug-and-play priors (PnP), deep unfolding (DU), and deep equilibrium models (DEQ). While the empirical performance and theoretical properties of DMBAs have been widely investigated, the existing work in the area has primarily focused on their performance when the desired image prior is known exactly. This work addresses the gap in the prior work by providing new theoretical and numerical insights into DMBAs under mismatched CNN priors. Mismatched priors arise naturally when there is a distribution shift between training and testing data, for example, due to test images being from a different distribution than images used for training the CNN prior. They also arise when the CNN prior used for inference is an approximation of some desired statistical estimator (MAP or MMSE). Our theoretical analysis provides explicit error bounds on the solution due to the mismatched CNN priors under a set of clearly specified assumptions. Our numerical results compare the empirical performance of DMBAs under realistic distribution shifts and approximate statistical estimators.
Low-light Image Enhancement via Breaking Down the Darkness
Nov 30, 2021
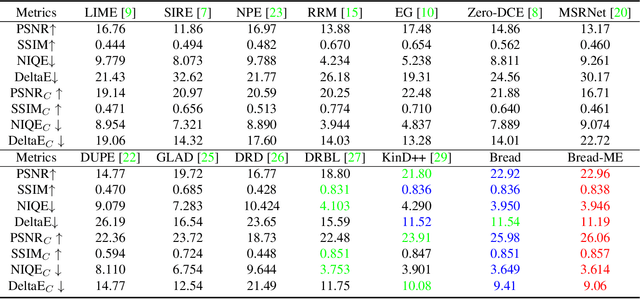

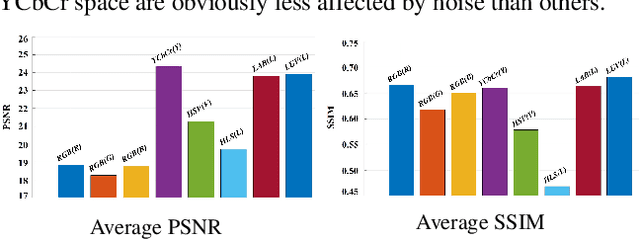
Images captured in low-light environment often suffer from complex degradation. Simply adjusting light would inevitably result in burst of hidden noise and color distortion. To seek results with satisfied lighting, cleanliness, and realism from degraded inputs, this paper presents a novel framework inspired by the divide-and-rule principle, greatly alleviating the degradation entanglement. Assuming that an image can be decomposed into texture (with possible noise) and color components, one can specifically execute noise removal and color correction along with light adjustment. Towards this purpose, we propose to convert an image from the RGB space into a luminance-chrominance one. An adjustable noise suppression network is designed to eliminate noise in the brightened luminance, having the illumination map estimated to indicate noise boosting levels. The enhanced luminance further serves as guidance for the chrominance mapper to generate realistic colors. Extensive experiments are conducted to reveal the effectiveness of our design, and demonstrate its superiority over state-of-the-art alternatives both quantitatively and qualitatively on several benchmark datasets. Our code is publicly available at https://github.com/mingcv/Bread.
Deepfake: Definitions, Performance Metrics and Standards, Datasets and Benchmarks, and a Meta-Review
Aug 21, 2022
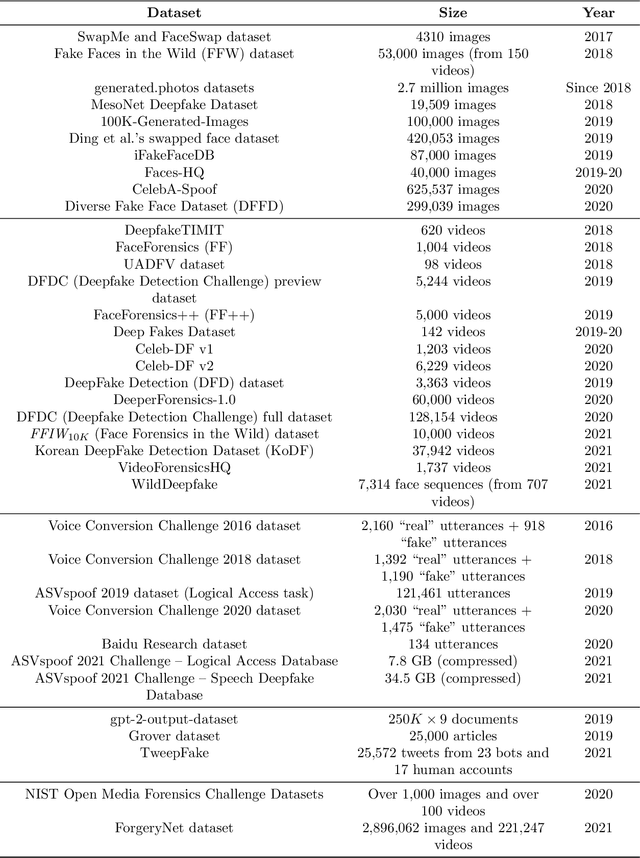
Recent advancements in AI, especially deep learning, have contributed to a significant increase in the creation of new realistic-looking synthetic media (video, image, and audio) and manipulation of existing media, which has led to the creation of the new term ``deepfake''. Based on both the research literature and resources in English and in Chinese, this paper gives a comprehensive overview of deepfake, covering multiple important aspects of this emerging concept, including 1) different definitions, 2) commonly used performance metrics and standards, and 3) deepfake-related datasets, challenges, competitions and benchmarks. In addition, the paper also reports a meta-review of 12 selected deepfake-related survey papers published in 2020 and 2021, focusing not only on the mentioned aspects, but also on the analysis of key challenges and recommendations. We believe that this paper is the most comprehensive review of deepfake in terms of aspects covered, and the first one covering both the English and Chinese literature and sources.
ReFormer: The Relational Transformer for Image Captioning
Jul 29, 2021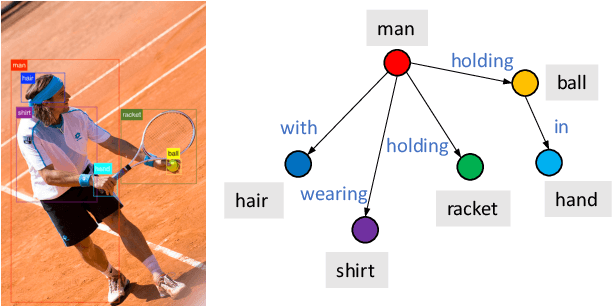
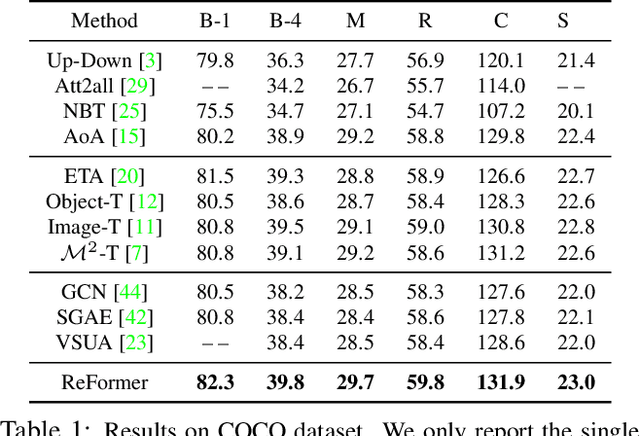
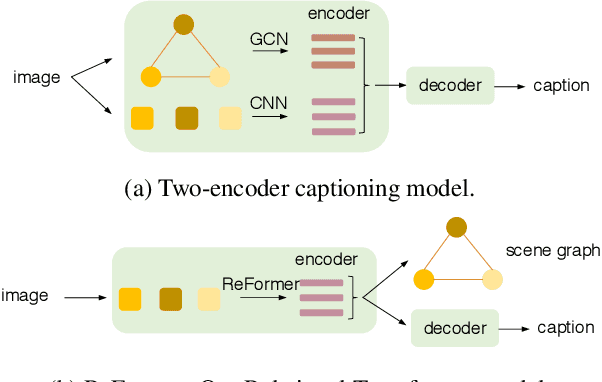
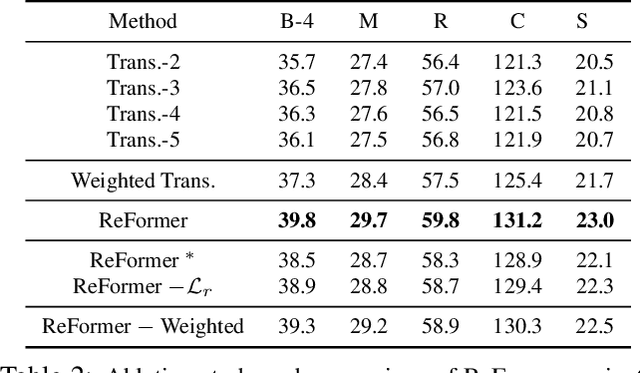
Image captioning is shown to be able to achieve a better performance by using scene graphs to represent the relations of objects in the image. The current captioning encoders generally use a Graph Convolutional Net (GCN) to represent the relation information and merge it with the object region features via concatenation or convolution to get the final input for sentence decoding. However, the GCN-based encoders in the existing methods are less effective for captioning due to two reasons. First, using the image captioning as the objective (i.e., Maximum Likelihood Estimation) rather than a relation-centric loss cannot fully explore the potential of the encoder. Second, using a pre-trained model instead of the encoder itself to extract the relationships is not flexible and cannot contribute to the explainability of the model. To improve the quality of image captioning, we propose a novel architecture ReFormer -- a RElational transFORMER to generate features with relation information embedded and to explicitly express the pair-wise relationships between objects in the image. ReFormer incorporates the objective of scene graph generation with that of image captioning using one modified Transformer model. This design allows ReFormer to generate not only better image captions with the bene-fit of extracting strong relational image features, but also scene graphs to explicitly describe the pair-wise relation-ships. Experiments on publicly available datasets show that our model significantly outperforms state-of-the-art methods on image captioning and scene graph generation
Joint Prediction of Meningioma Grade and Brain Invasion via Task-Aware Contrastive Learning
Sep 04, 2022
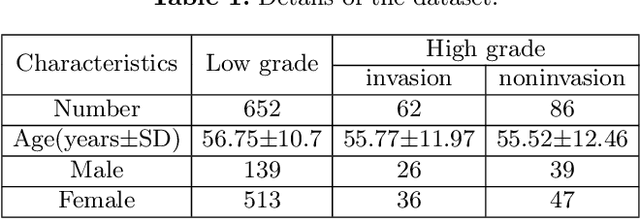
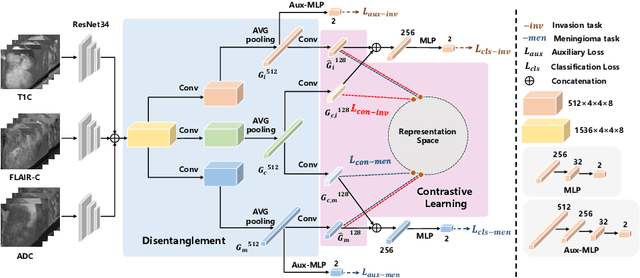
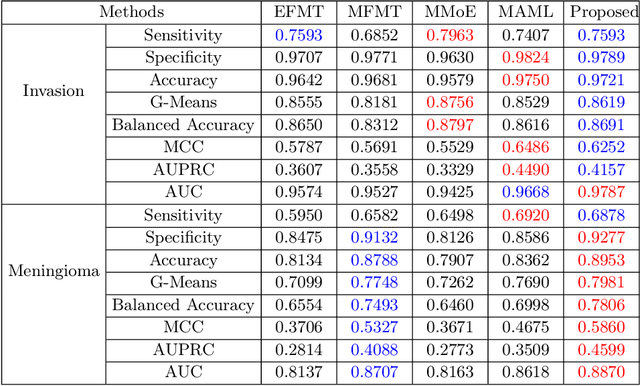
Preoperative and noninvasive prediction of the meningioma grade is important in clinical practice, as it directly influences the clinical decision making. What's more, brain invasion in meningioma (i.e., the presence of tumor tissue within the adjacent brain tissue) is an independent criterion for the grading of meningioma and influences the treatment strategy. Although efforts have been reported to address these two tasks, most of them rely on hand-crafted features and there is no attempt to exploit the two prediction tasks simultaneously. In this paper, we propose a novel task-aware contrastive learning algorithm to jointly predict meningioma grade and brain invasion from multi-modal MRIs. Based on the basic multi-task learning framework, our key idea is to adopt contrastive learning strategy to disentangle the image features into task-specific features and task-common features, and explicitly leverage their inherent connections to improve feature representation for the two prediction tasks. In this retrospective study, an MRI dataset was collected, for which 800 patients (containing 148 high-grade, 62 invasion) were diagnosed with meningioma by pathological analysis. Experimental results show that the proposed algorithm outperforms alternative multi-task learning methods, achieving AUCs of 0:8870 and 0:9787 for the prediction of meningioma grade and brain invasion, respectively. The code is available at https://github.com/IsDling/predictTCL.
Understanding Diffusion Models: A Unified Perspective
Aug 25, 2022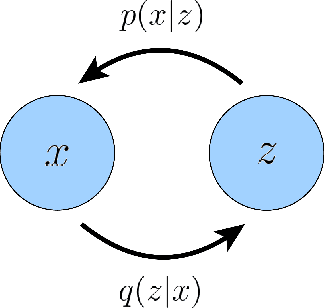
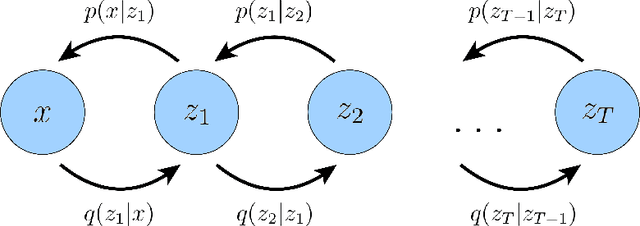
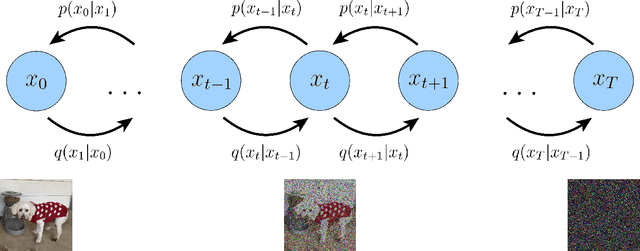
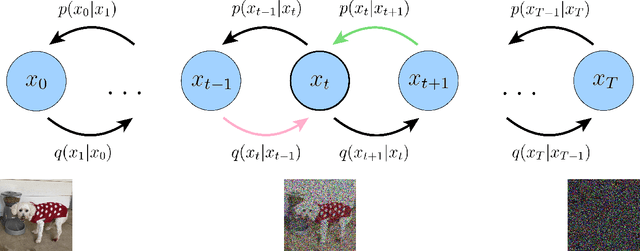
Diffusion models have shown incredible capabilities as generative models; indeed, they power the current state-of-the-art models on text-conditioned image generation such as Imagen and DALL-E 2. In this work we review, demystify, and unify the understanding of diffusion models across both variational and score-based perspectives. We first derive Variational Diffusion Models (VDM) as a special case of a Markovian Hierarchical Variational Autoencoder, where three key assumptions enable tractable computation and scalable optimization of the ELBO. We then prove that optimizing a VDM boils down to learning a neural network to predict one of three potential objectives: the original source input from any arbitrary noisification of it, the original source noise from any arbitrarily noisified input, or the score function of a noisified input at any arbitrary noise level. We then dive deeper into what it means to learn the score function, and connect the variational perspective of a diffusion model explicitly with the Score-based Generative Modeling perspective through Tweedie's Formula. Lastly, we cover how to learn a conditional distribution using diffusion models via guidance.
Spatiotemporal Cardiac Statistical Shape Modeling: A Data-Driven Approach
Sep 06, 2022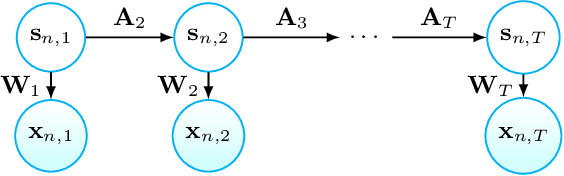

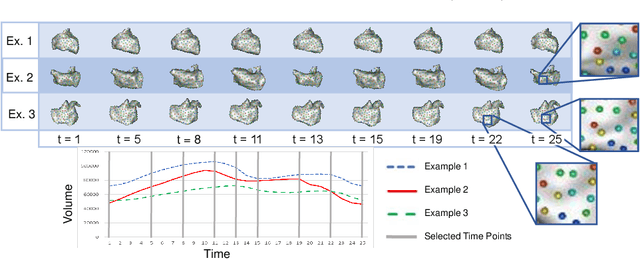
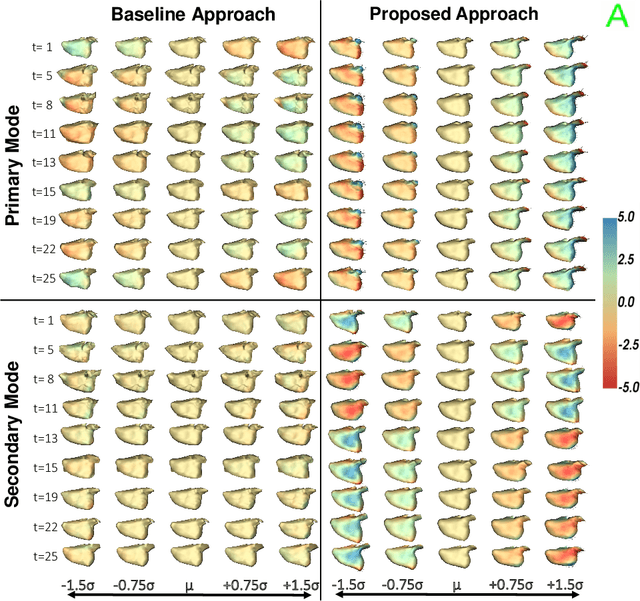
Clinical investigations of anatomy's structural changes over time could greatly benefit from population-level quantification of shape, or spatiotemporal statistic shape modeling (SSM). Such a tool enables characterizing patient organ cycles or disease progression in relation to a cohort of interest. Constructing shape models requires establishing a quantitative shape representation (e.g., corresponding landmarks). Particle-based shape modeling (PSM) is a data-driven SSM approach that captures population-level shape variations by optimizing landmark placement. However, it assumes cross-sectional study designs and hence has limited statistical power in representing shape changes over time. Existing methods for modeling spatiotemporal or longitudinal shape changes require predefined shape atlases and pre-built shape models that are typically constructed cross-sectionally. This paper proposes a data-driven approach inspired by the PSM method to learn population-level spatiotemporal shape changes directly from shape data. We introduce a novel SSM optimization scheme that produces landmarks that are in correspondence both across the population (inter-subject) and across time-series (intra-subject). We apply the proposed method to 4D cardiac data from atrial-fibrillation patients and demonstrate its efficacy in representing the dynamic change of the left atrium. Furthermore, we show that our method outperforms an image-based approach for spatiotemporal SSM with respect to a generative time-series model, the Linear Dynamical System (LDS). LDS fit using a spatiotemporal shape model optimized via our approach provides better generalization and specificity, indicating it accurately captures the underlying time-dependency.
Monocular 3D Object Detection with Depth from Motion
Jul 26, 2022
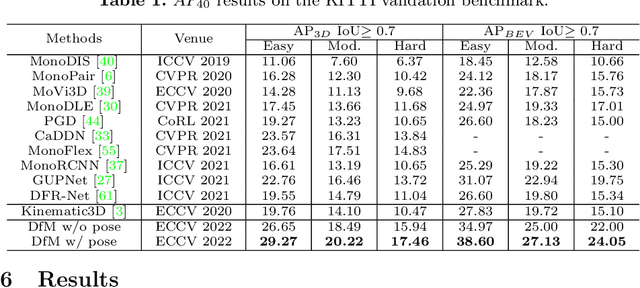
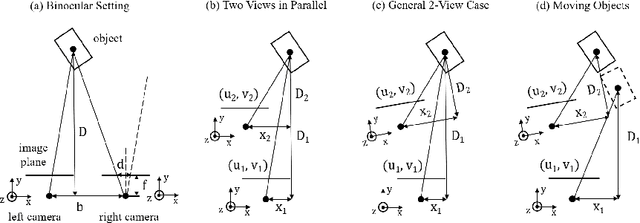

Perceiving 3D objects from monocular inputs is crucial for robotic systems, given its economy compared to multi-sensor settings. It is notably difficult as a single image can not provide any clues for predicting absolute depth values. Motivated by binocular methods for 3D object detection, we take advantage of the strong geometry structure provided by camera ego-motion for accurate object depth estimation and detection. We first make a theoretical analysis on this general two-view case and notice two challenges: 1) Cumulative errors from multiple estimations that make the direct prediction intractable; 2) Inherent dilemmas caused by static cameras and matching ambiguity. Accordingly, we establish the stereo correspondence with a geometry-aware cost volume as the alternative for depth estimation and further compensate it with monocular understanding to address the second problem. Our framework, named Depth from Motion (DfM), then uses the established geometry to lift 2D image features to the 3D space and detects 3D objects thereon. We also present a pose-free DfM to make it usable when the camera pose is unavailable. Our framework outperforms state-of-the-art methods by a large margin on the KITTI benchmark. Detailed quantitative and qualitative analyses also validate our theoretical conclusions. The code will be released at https://github.com/Tai-Wang/Depth-from-Motion.