 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Machine Learning with DBOS
Aug 10, 2022
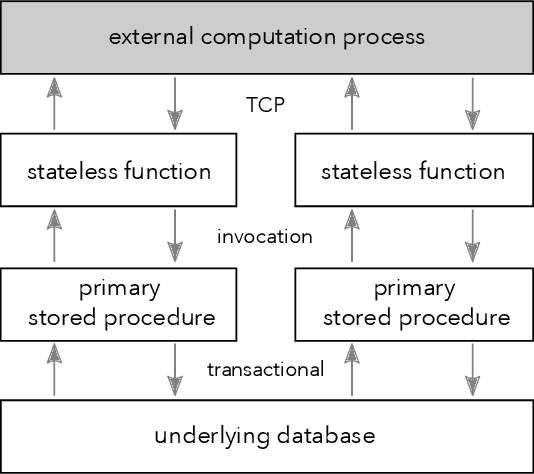
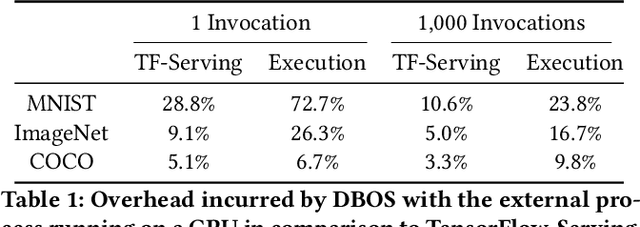

We recently proposed a new cluster operating system stack, DBOS, centered on a DBMS. DBOS enables unique support for ML applications by encapsulating ML code within stored procedures, centralizing ancillary ML data, providing security built into the underlying DBMS, co-locating ML code and data, and tracking data and workflow provenance. Here we demonstrate a subset of these benefits around two ML applications. We first show that image classification and object detection models using GPUs can be served as DBOS stored procedures with performance competitive to existing systems. We then present a 1D CNN trained to detect anomalies in HTTP requests on DBOS-backed web services, achieving SOTA results. We use this model to develop an interactive anomaly detection system and evaluate it through qualitative user feedback, demonstrating its usefulness as a proof of concept for future work to develop learned real-time security services on top of DBOS.
Wildfire Forecasting with Satellite Images and Deep Generative Model
Aug 22, 2022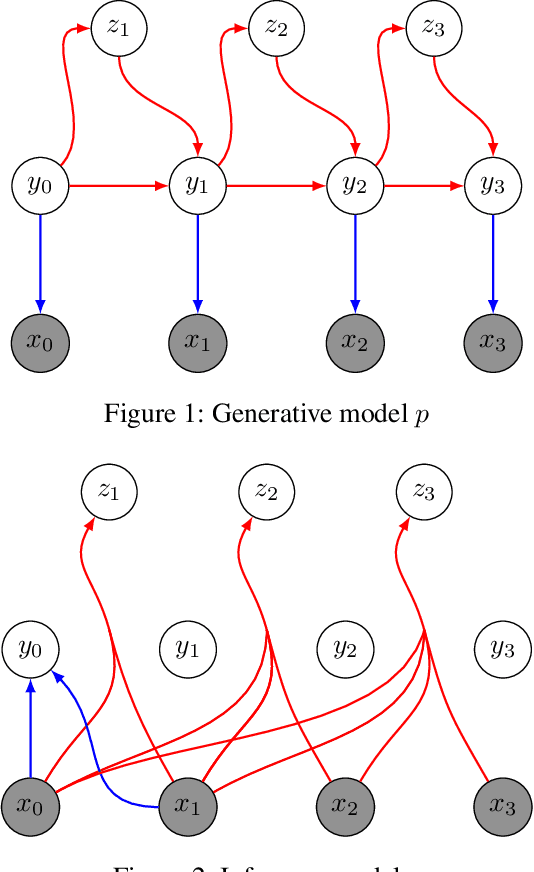

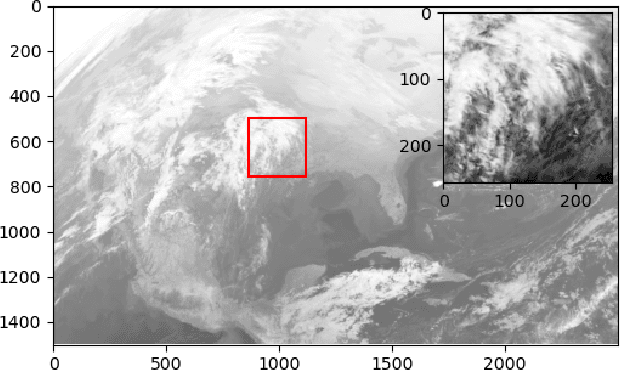
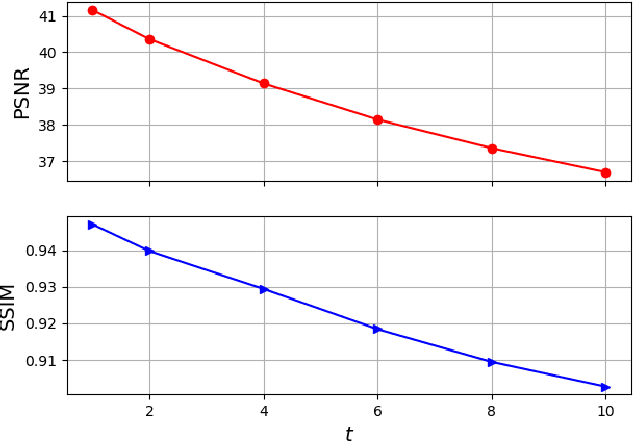
Wildfire forecasting has been one of the most critical tasks that humanities want to thrive. It plays a vital role in protecting human life. Wildfire prediction, on the other hand, is difficult because of its stochastic and chaotic properties. We tackled the problem by interpreting a series of wildfire images as a video and used it to anticipate how the fire would behave in the future. However, creating video prediction models that account for the inherent uncertainty of the future is challenging. The bulk of published attempts is based on stochastic image-autoregressive recurrent networks, which raises various performance and application difficulties, such as computational cost and limited efficiency on massive datasets. Another possibility is to use entirely latent temporal models that combine frame synthesis and temporal dynamics. However, due to design and training issues, no such model for stochastic video prediction has yet been proposed in the literature. This paper addresses these issues by introducing a novel stochastic temporal model whose dynamics are driven in a latent space. It naturally predicts video dynamics by allowing our lighter, more interpretable latent model to beat previous state-of-the-art approaches on the GOES-16 dataset. Results will be compared towards various benchmarking models.
GAMa: Cross-view Video Geo-localization
Jul 06, 2022
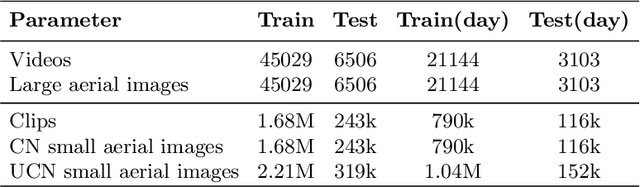


The existing work in cross-view geo-localization is based on images where a ground panorama is matched to an aerial image. In this work, we focus on ground videos instead of images which provides additional contextual cues which are important for this task. There are no existing datasets for this problem, therefore we propose GAMa dataset, a large-scale dataset with ground videos and corresponding aerial images. We also propose a novel approach to solve this problem. At clip-level, a short video clip is matched with corresponding aerial image and is later used to get video-level geo-localization of a long video. Moreover, we propose a hierarchical approach to further improve the clip-level geolocalization. It is a challenging dataset, unaligned and limited field of view, and our proposed method achieves a Top-1 recall rate of 19.4% and 45.1% @1.0mile. Code and dataset are available at following link: https://github.com/svyas23/GAMa.
Bayesian model calibration for block copolymer self-assembly: Likelihood-free inference and expected information gain computation via measure transport
Jun 22, 2022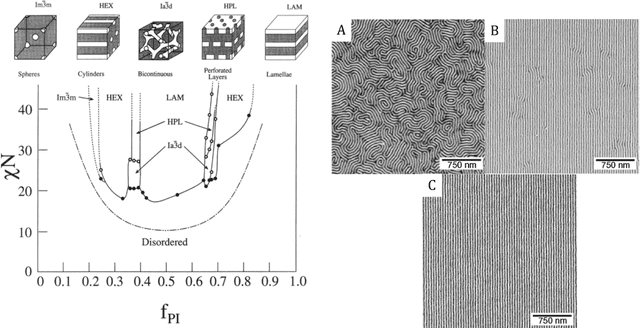
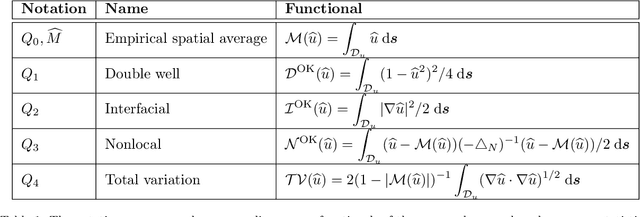
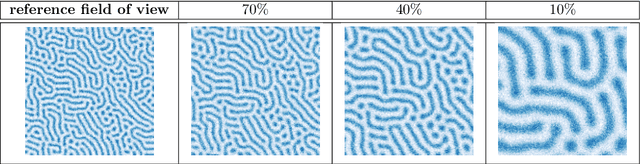
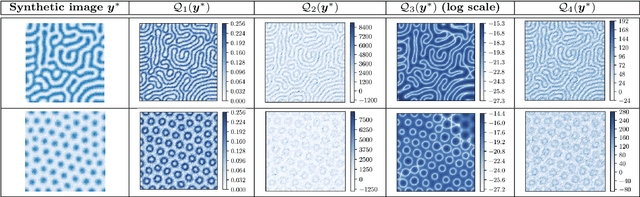
We consider the Bayesian calibration of models describing the phenomenon of block copolymer (BCP) self-assembly using image data produced by microscopy or X-ray scattering techniques. To account for the random long-range disorder in BCP equilibrium structures, we introduce auxiliary variables to represent this aleatory uncertainty. These variables, however, result in an integrated likelihood for high-dimensional image data that is generally intractable to evaluate. We tackle this challenging Bayesian inference problem using a likelihood-free approach based on measure transport together with the construction of summary statistics for the image data. We also show that expected information gains (EIGs) from the observed data about the model parameters can be computed with no significant additional cost. Lastly, we present a numerical case study based on the Ohta--Kawasaki model for diblock copolymer thin film self-assembly and top-down microscopy characterization. For calibration, we introduce several domain-specific energy- and Fourier-based summary statistics, and quantify their informativeness using EIG. We demonstrate the power of the proposed approach to study the effect of data corruptions and experimental designs on the calibration results.
3rd Place: A Global and Local Dual Retrieval Solution to Facebook AI Image Similarity Challenge
Dec 04, 2021
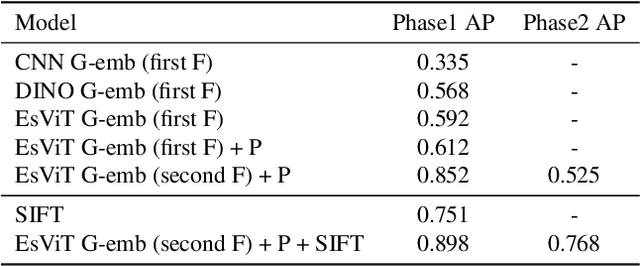
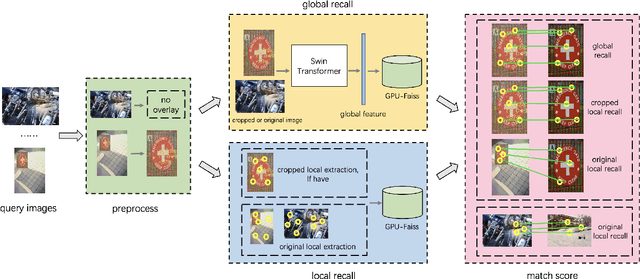
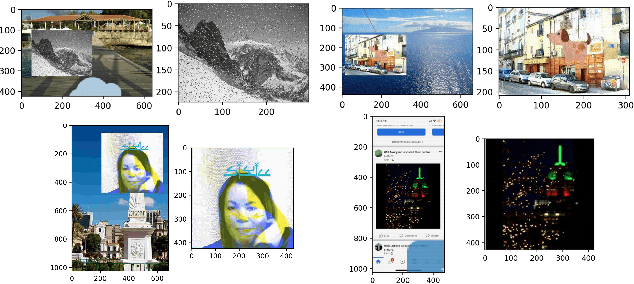
As a basic task of computer vision, image similarity retrieval is facing the challenge of large-scale data and image copy attacks. This paper presents our 3rd place solution to the matching track of Image Similarity Challenge (ISC) 2021 organized by Facebook AI. We propose a multi-branch retrieval method of combining global descriptors and local descriptors to cover all attack cases. Specifically, we attempt many strategies to optimize global descriptors, including abundant data augmentations, self-supervised learning with a single Transformer model, overlay detection preprocessing. Moreover, we introduce the robust SIFT feature and GPU Faiss for local retrieval which makes up for the shortcomings of the global retrieval. Finally, KNN-matching algorithm is used to judge the match and merge scores. We show some ablation experiments of our method, which reveals the complementary advantages of global and local features.
Geometry Attention Transformer with Position-aware LSTMs for Image Captioning
Oct 01, 2021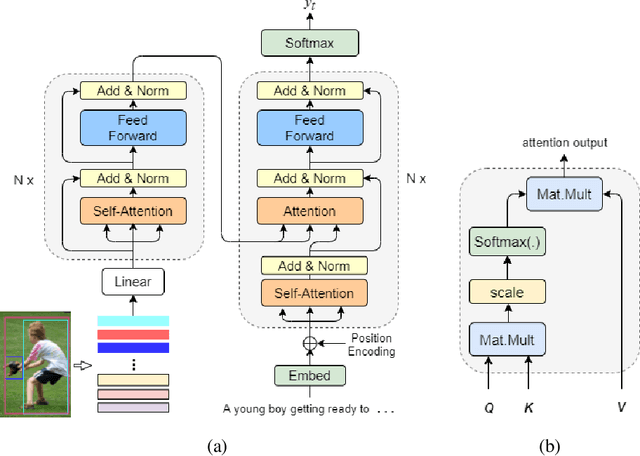
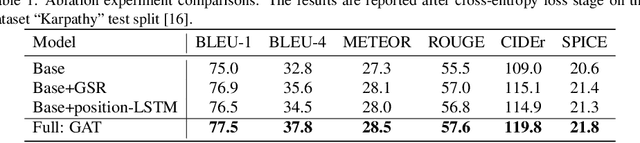
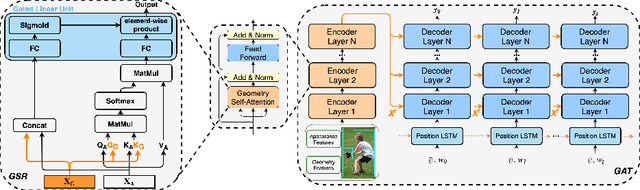
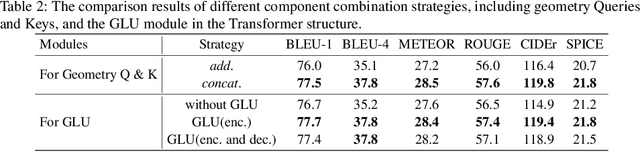
In recent years, transformer structures have been widely applied in image captioning with impressive performance. For good captioning results, the geometry and position relations of different visual objects are often thought of as crucial information. Aiming to further promote image captioning by transformers, this paper proposes an improved Geometry Attention Transformer (GAT) model. In order to further leverage geometric information, two novel geometry-aware architectures are designed respectively for the encoder and decoder in our GAT. Besides, this model includes the two work modules: 1) a geometry gate-controlled self-attention refiner, for explicitly incorporating relative spatial information into image region representations in encoding steps, and 2) a group of position-LSTMs, for precisely informing the decoder of relative word position in generating caption texts. The experiment comparisons on the datasets MS COCO and Flickr30K show that our GAT is efficient, and it could often outperform current state-of-the-art image captioning models.
A photosensor employing data-driven binning for ultrafast image recognition
Nov 20, 2021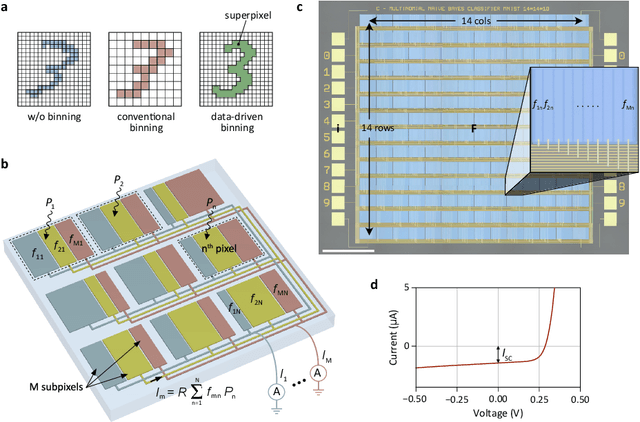
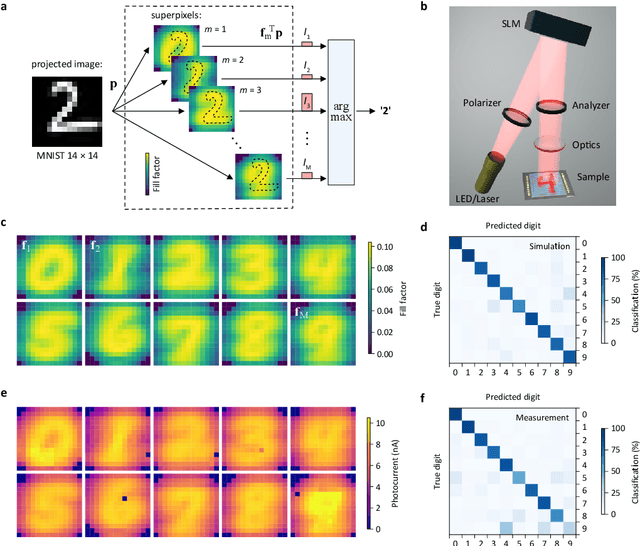
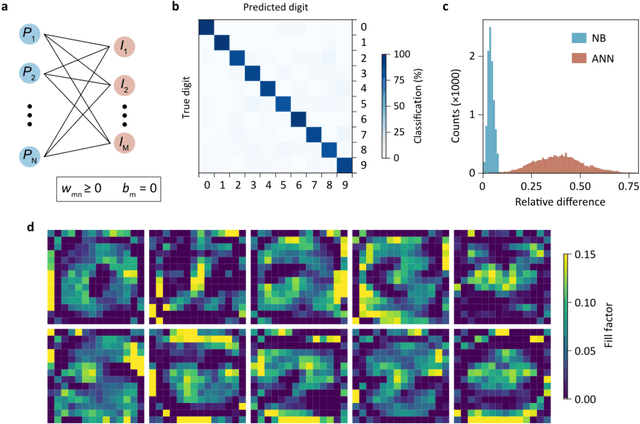
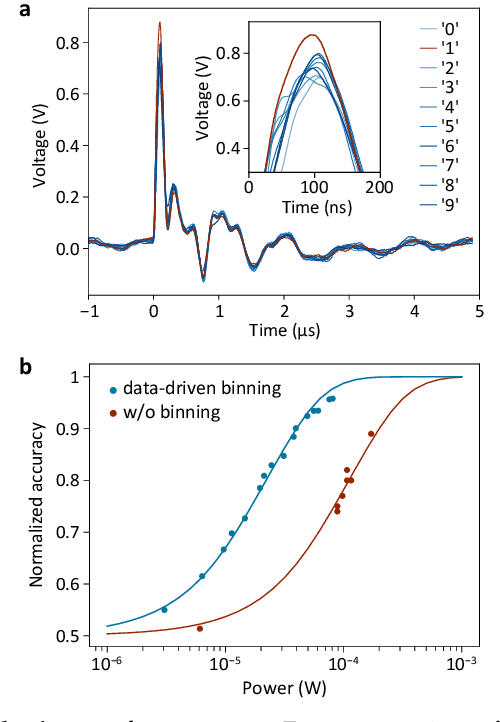
Pixel binning is a technique, widely used in optical image acquisition and spectroscopy, in which adjacent detector elements of an image sensor are combined into larger pixels. This reduces the amount of data to be processed as well as the impact of noise, but comes at the cost of a loss of information. Here, we push the concept of binning to its limit by combining a large fraction of the sensor elements into a single superpixel that extends over the whole face of the chip. For a given pattern recognition task, its optimal shape is determined from training data using a machine learning algorithm. We demonstrate the classification of optically projected images from the MNIST dataset on a nanosecond timescale, with enhanced sensitivity and without loss of classification accuracy. Our concept is not limited to imaging alone but can also be applied in optical spectroscopy or other sensing applications.
MRF-UNets: Searching UNet with Markov Random Fields
Jul 13, 2022
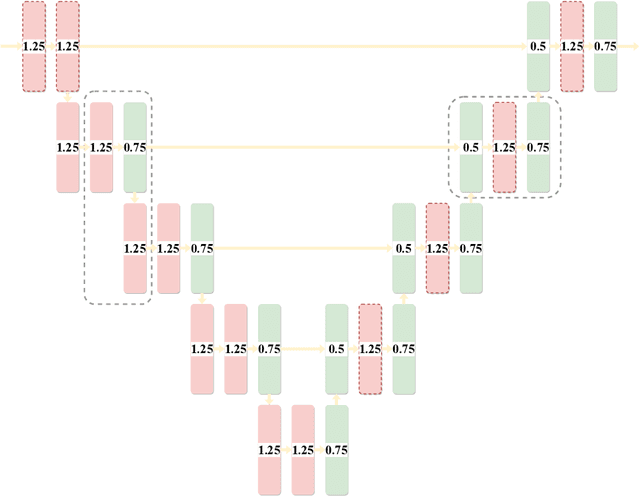
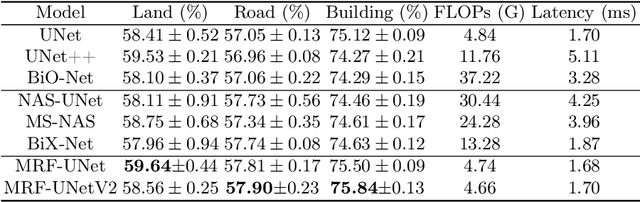
UNet [27] is widely used in semantic segmentation due to its simplicity and effectiveness. However, its manually-designed architecture is applied to a large number of problem settings, either with no architecture optimizations, or with manual tuning, which is time consuming and can be sub-optimal. In this work, firstly, we propose Markov Random Field Neural Architecture Search (MRF-NAS) that extends and improves the recent Adaptive and Optimal Network Width Search (AOWS) method [4] with (i) a more general MRF framework (ii) diverse M-best loopy inference (iii) differentiable parameter learning. This provides the necessary NAS framework to efficiently explore network architectures that induce loopy inference graphs, including loops that arise from skip connections. With UNet as the backbone, we find an architecture, MRF-UNet, that shows several interesting characteristics. Secondly, through the lens of these characteristics, we identify the sub-optimality of the original UNet architecture and further improve our results with MRF-UNetV2. Experiments show that our MRF-UNets significantly outperform several benchmarks on three aerial image datasets and two medical image datasets while maintaining low computational costs. The code is available at: https://github.com/zifuwanggg/MRF-UNets.
Towards reliable head and neck cancers locoregional recurrence prediction using delta-radiomics and learning with rejection option
Aug 30, 2022
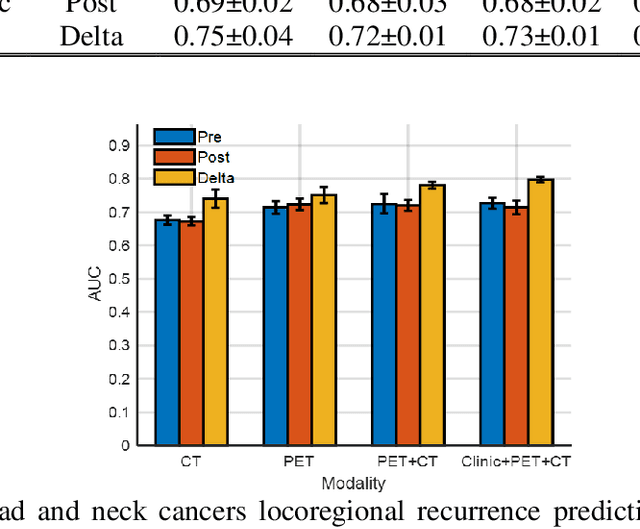
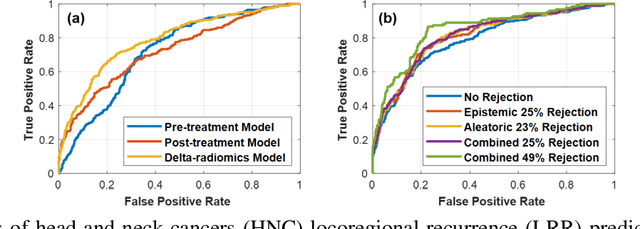
A reliable locoregional recurrence (LRR) prediction model is important for the personalized management of head and neck cancers (HNC) patients. This work aims to develop a delta-radiomics feature-based multi-classifier, multi-objective, and multi-modality (Delta-mCOM) model for post-treatment HNC LRR prediction and adopting a learning with rejection option (LRO) strategy to boost the prediction reliability by rejecting samples with high prediction uncertainties. In this retrospective study, we collected PET/CT image and clinical data from 224 HNC patients. We calculated the differences between radiomics features extracted from PET/CT images acquired before and after radiotherapy as the input features. Using clinical parameters, PET and CT radiomics features, we built and optimized three separate single-modality models. We used multiple classifiers for model construction and employed sensitivity and specificity simultaneously as the training objectives. For testing samples, we fused the output probabilities from all these single-modality models to obtain the final output probabilities of the Delta-mCOM model. In the LRO strategy, we estimated the epistemic and aleatoric uncertainties when predicting with Delta-mCOM model and identified patients associated with prediction of higher reliability. Predictions with higher epistemic uncertainty or higher aleatoric uncertainty than given thresholds were deemed unreliable, and they were rejected before providing a final prediction. Different thresholds corresponding to different low-reliability prediction rejection ratios were applied. The inclusion of the delta-radiomics feature improved the accuracy of HNC LRR prediction, and the proposed Delta-mCOM model can give more reliable predictions by rejecting predictions for samples of high uncertainty using the LRO strategy.
A No-Reference Deep Learning Quality Assessment Method for Super-resolution Images Based on Frequency Maps
Jun 09, 2022
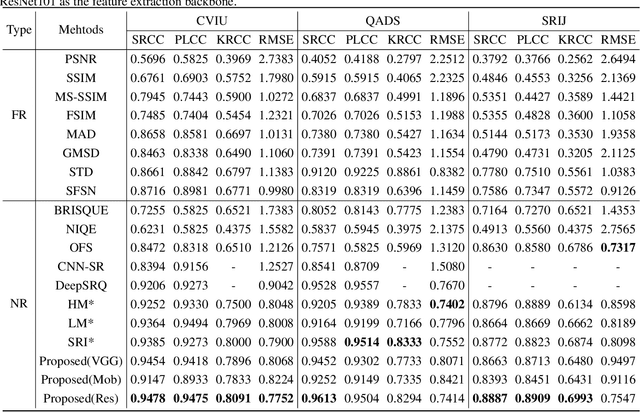
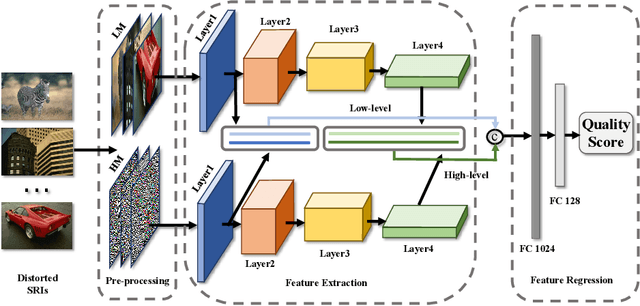
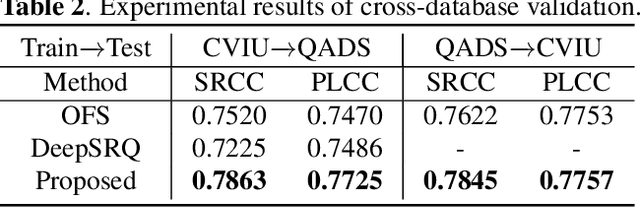
To support the application scenarios where high-resolution (HR) images are urgently needed, various single image super-resolution (SISR) algorithms are developed. However, SISR is an ill-posed inverse problem, which may bring artifacts like texture shift, blur, etc. to the reconstructed images, thus it is necessary to evaluate the quality of super-resolution images (SRIs). Note that most existing image quality assessment (IQA) methods were developed for synthetically distorted images, which may not work for SRIs since their distortions are more diverse and complicated. Therefore, in this paper, we propose a no-reference deep-learning image quality assessment method based on frequency maps because the artifacts caused by SISR algorithms are quite sensitive to frequency information. Specifically, we first obtain the high-frequency map (HM) and low-frequency map (LM) of SRI by using Sobel operator and piecewise smooth image approximation. Then, a two-stream network is employed to extract the quality-aware features of both frequency maps. Finally, the features are regressed into a single quality value using fully connected layers. The experimental results show that our method outperforms all compared IQA models on the selected three super-resolution quality assessment (SRQA) databases.