 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Word-Level Fine-Grained Story Visualization
Aug 03, 2022


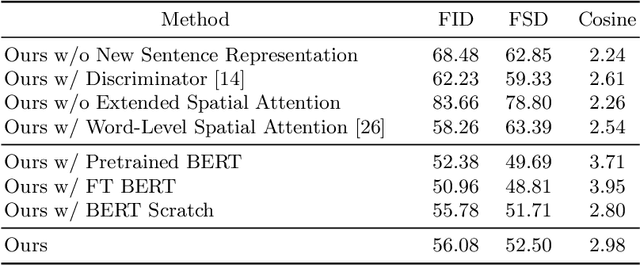
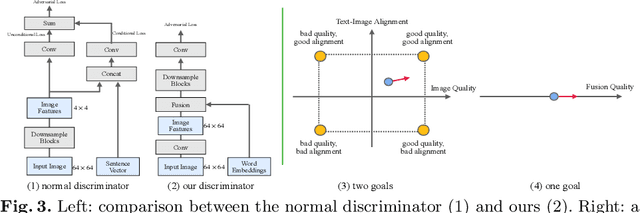
Story visualization aims to generate a sequence of images to narrate each sentence in a multi-sentence story with a global consistency across dynamic scenes and characters. Current works still struggle with output images' quality and consistency, and rely on additional semantic information or auxiliary captioning networks. To address these challenges, we first introduce a new sentence representation, which incorporates word information from all story sentences to mitigate the inconsistency problem. Then, we propose a new discriminator with fusion features and further extend the spatial attention to improve image quality and story consistency. Extensive experiments on different datasets and human evaluation demonstrate the superior performance of our approach, compared to state-of-the-art methods, neither using segmentation masks nor auxiliary captioning networks.
TransMEF: A Transformer-Based Multi-Exposure Image Fusion Framework using Self-Supervised Multi-Task Learning
Dec 15, 2021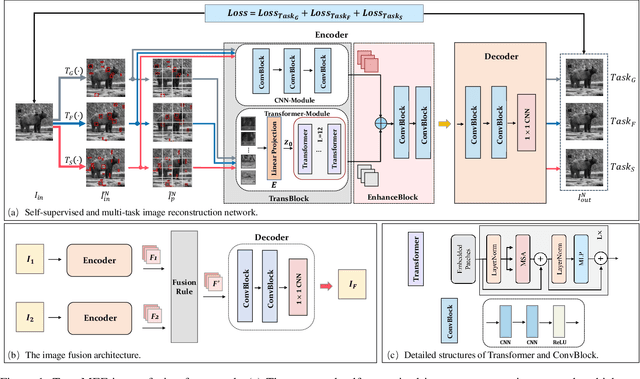
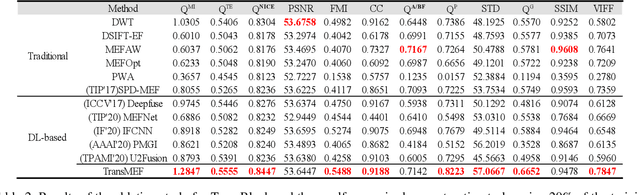


In this paper, we propose TransMEF, a transformer-based multi-exposure image fusion framework that uses self-supervised multi-task learning. The framework is based on an encoder-decoder network, which can be trained on large natural image datasets and does not require ground truth fusion images. We design three self-supervised reconstruction tasks according to the characteristics of multi-exposure images and conduct these tasks simultaneously using multi-task learning; through this process, the network can learn the characteristics of multi-exposure images and extract more generalized features. In addition, to compensate for the defect in establishing long-range dependencies in CNN-based architectures, we design an encoder that combines a CNN module with a transformer module. This combination enables the network to focus on both local and global information. We evaluated our method and compared it to 11 competitive traditional and deep learning-based methods on the latest released multi-exposure image fusion benchmark dataset, and our method achieved the best performance in both subjective and objective evaluations.
Hierarchical Perceptual Noise Injection for Social Media Fingerprint Privacy Protection
Aug 23, 2022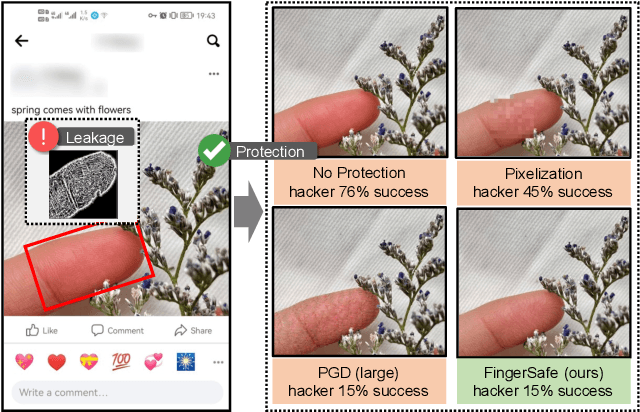
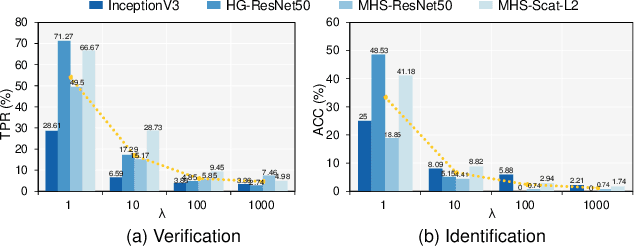
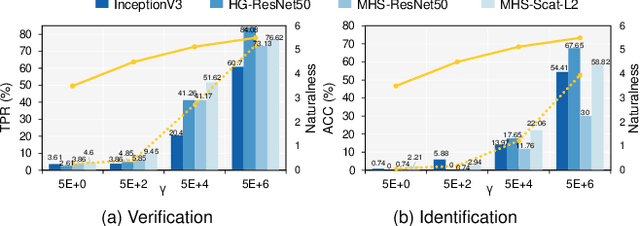
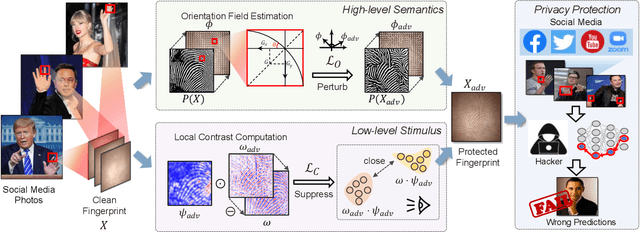
Billions of people are sharing their daily life images on social media every day. However, their biometric information (e.g., fingerprint) could be easily stolen from these images. The threat of fingerprint leakage from social media raises a strong desire for anonymizing shared images while maintaining image qualities, since fingerprints act as a lifelong individual biometric password. To guard the fingerprint leakage, adversarial attack emerges as a solution by adding imperceptible perturbations on images. However, existing works are either weak in black-box transferability or appear unnatural. Motivated by visual perception hierarchy (i.e., high-level perception exploits model-shared semantics that transfer well across models while low-level perception extracts primitive stimulus and will cause high visual sensitivities given suspicious stimulus), we propose FingerSafe, a hierarchical perceptual protective noise injection framework to address the mentioned problems. For black-box transferability, we inject protective noises on fingerprint orientation field to perturb the model-shared high-level semantics (i.e., fingerprint ridges). Considering visual naturalness, we suppress the low-level local contrast stimulus by regularizing the response of Lateral Geniculate Nucleus. Our FingerSafe is the first to provide feasible fingerprint protection in both digital (up to 94.12%) and realistic scenarios (Twitter and Facebook, up to 68.75%). Our code can be found at https://github.com/nlsde-safety-team/FingerSafe.
Convergence of denoising diffusion models under the manifold hypothesis
Aug 10, 2022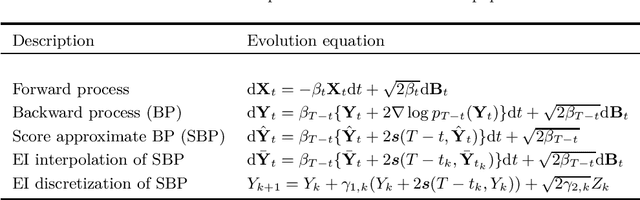
Denoising diffusion models are a recent class of generative models exhibiting state-of-the-art performance in image and audio synthesis. Such models approximate the time-reversal of a forward noising process from a target distribution to a reference density, which is usually Gaussian. Despite their strong empirical results, the theoretical analysis of such models remains limited. In particular, all current approaches crucially assume that the target density admits a density w.r.t. the Lebesgue measure. This does not cover settings where the target distribution is supported on a lower-dimensional manifold or is given by some empirical distribution. In this paper, we bridge this gap by providing the first convergence results for diffusion models in this more general setting. In particular, we provide quantitative bounds on the Wasserstein distance of order one between the target data distribution and the generative distribution of the diffusion model.
A Novel Algorithm for Exact Concave Hull Extraction
Jun 23, 2022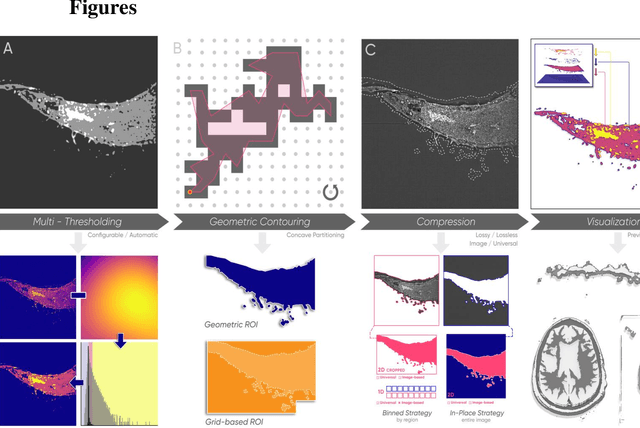

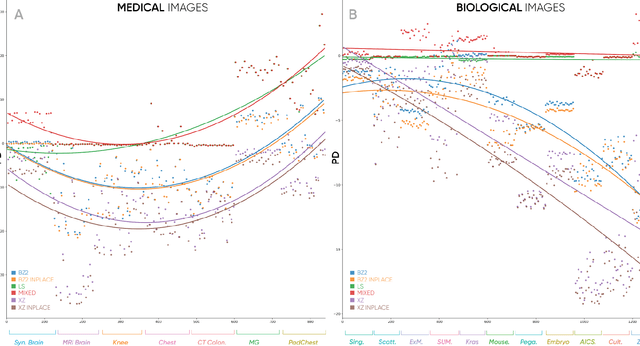
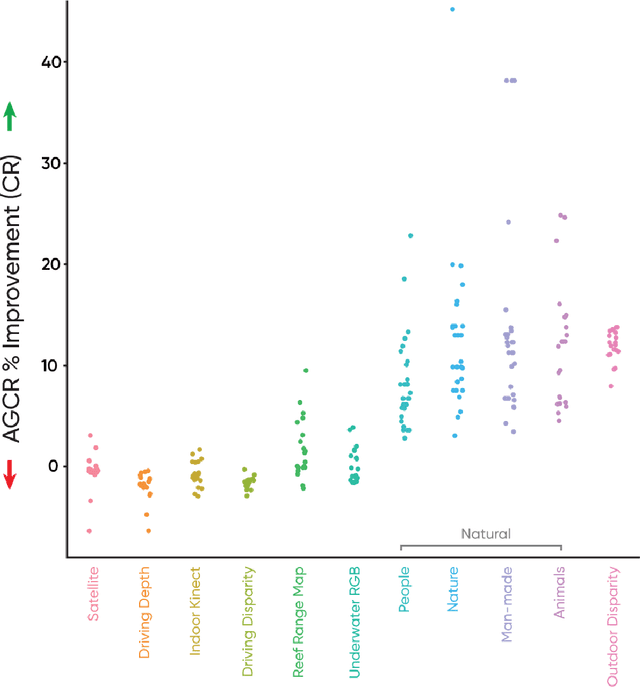
Region extraction is necessary in a wide range of applications, from object detection in autonomous driving to analysis of subcellular morphology in cell biology. There exist two main approaches: convex hull extraction, for which exact and efficient algorithms exist and concave hulls, which are better at capturing real-world shapes but do not have a single solution. Especially in the context of a uniform grid, concave hull algorithms are largely approximate, sacrificing region integrity for spatial and temporal efficiency. In this study, we present a novel algorithm that can provide vertex-minimized concave hulls with maximal (i.e. pixel-perfect) resolution and is tunable for speed-efficiency tradeoffs. Our method provides advantages in multiple downstream applications including data compression, retrieval, visualization, and analysis. To demonstrate the practical utility of our approach, we focus on image compression. We demonstrate significant improvements through context-dependent compression on disparate regions within a single image (entropy encoding for noisy and predictive encoding for the structured regions). We show that these improvements range from biomedical images to natural images. Beyond image compression, our algorithm can be applied more broadly to aid in a wide range of practical applications for data retrieval, visualization, and analysis.
Geometry Attention Transformer with Position-aware LSTMs for Image Captioning
Oct 01, 2021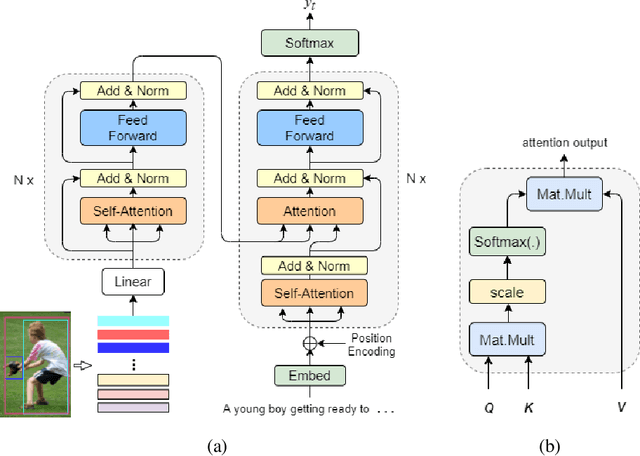
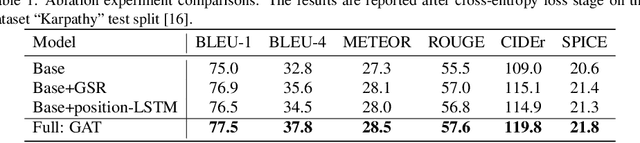
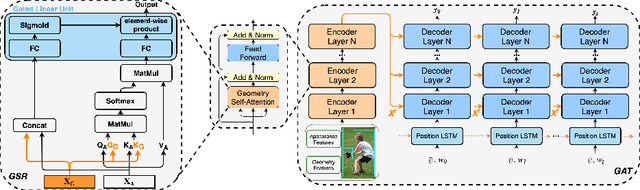
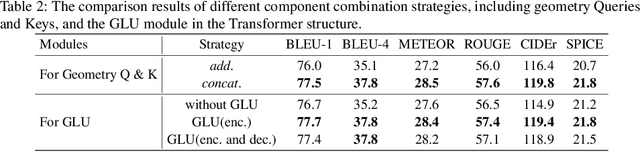
In recent years, transformer structures have been widely applied in image captioning with impressive performance. For good captioning results, the geometry and position relations of different visual objects are often thought of as crucial information. Aiming to further promote image captioning by transformers, this paper proposes an improved Geometry Attention Transformer (GAT) model. In order to further leverage geometric information, two novel geometry-aware architectures are designed respectively for the encoder and decoder in our GAT. Besides, this model includes the two work modules: 1) a geometry gate-controlled self-attention refiner, for explicitly incorporating relative spatial information into image region representations in encoding steps, and 2) a group of position-LSTMs, for precisely informing the decoder of relative word position in generating caption texts. The experiment comparisons on the datasets MS COCO and Flickr30K show that our GAT is efficient, and it could often outperform current state-of-the-art image captioning models.
A photosensor employing data-driven binning for ultrafast image recognition
Nov 20, 2021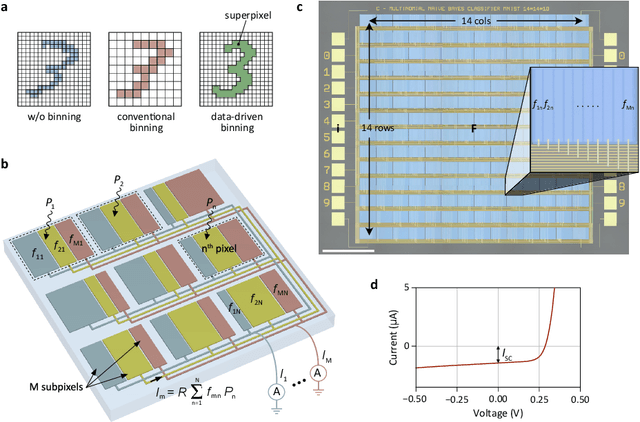
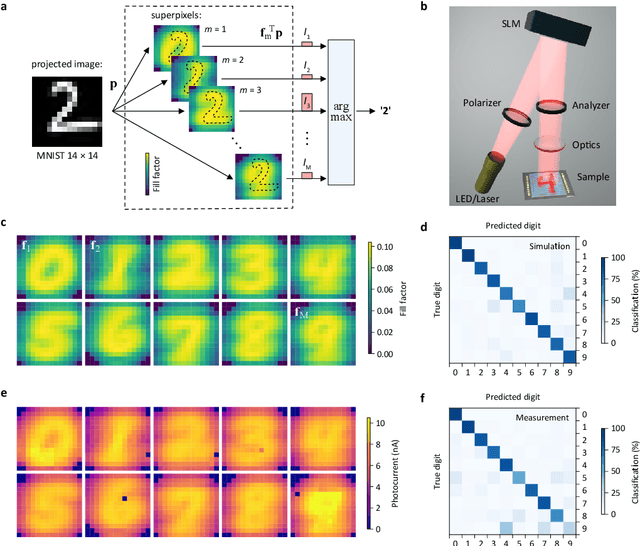
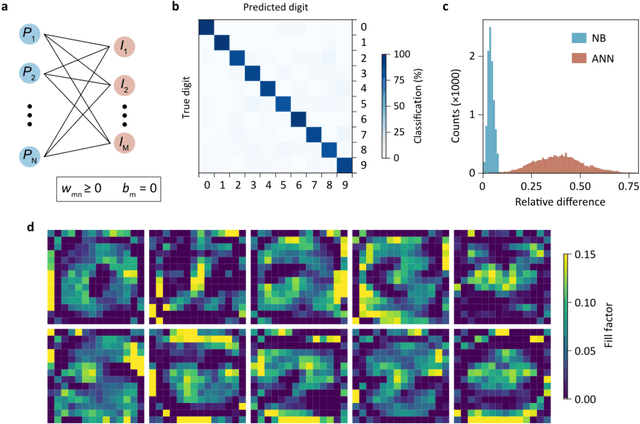
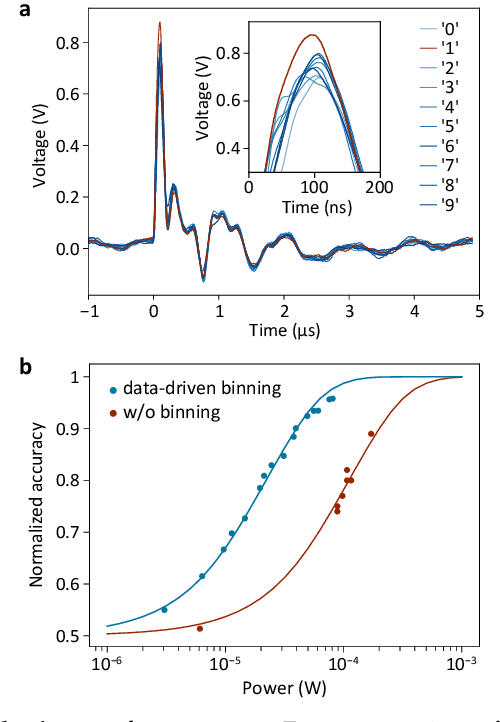
Pixel binning is a technique, widely used in optical image acquisition and spectroscopy, in which adjacent detector elements of an image sensor are combined into larger pixels. This reduces the amount of data to be processed as well as the impact of noise, but comes at the cost of a loss of information. Here, we push the concept of binning to its limit by combining a large fraction of the sensor elements into a single superpixel that extends over the whole face of the chip. For a given pattern recognition task, its optimal shape is determined from training data using a machine learning algorithm. We demonstrate the classification of optically projected images from the MNIST dataset on a nanosecond timescale, with enhanced sensitivity and without loss of classification accuracy. Our concept is not limited to imaging alone but can also be applied in optical spectroscopy or other sensing applications.
3rd Place: A Global and Local Dual Retrieval Solution to Facebook AI Image Similarity Challenge
Dec 04, 2021
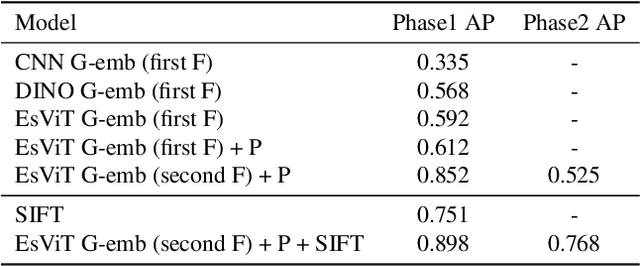
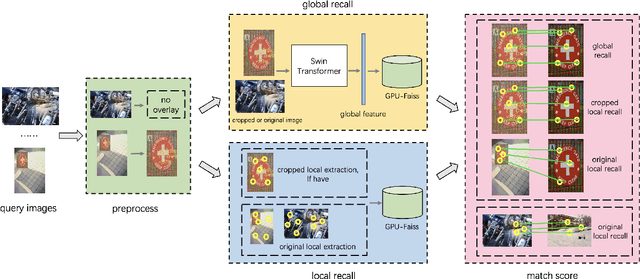
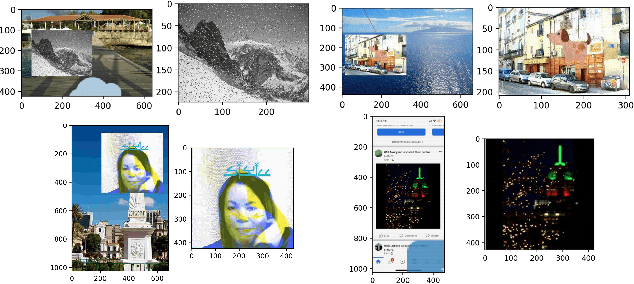
As a basic task of computer vision, image similarity retrieval is facing the challenge of large-scale data and image copy attacks. This paper presents our 3rd place solution to the matching track of Image Similarity Challenge (ISC) 2021 organized by Facebook AI. We propose a multi-branch retrieval method of combining global descriptors and local descriptors to cover all attack cases. Specifically, we attempt many strategies to optimize global descriptors, including abundant data augmentations, self-supervised learning with a single Transformer model, overlay detection preprocessing. Moreover, we introduce the robust SIFT feature and GPU Faiss for local retrieval which makes up for the shortcomings of the global retrieval. Finally, KNN-matching algorithm is used to judge the match and merge scores. We show some ablation experiments of our method, which reveals the complementary advantages of global and local features.
Contrastive Cross-Modal Knowledge Sharing Pre-training for Vision-Language Representation Learning and Retrieval
Jul 02, 2022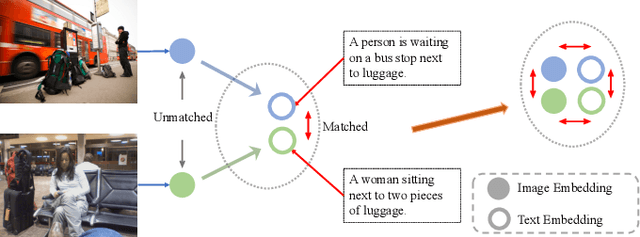
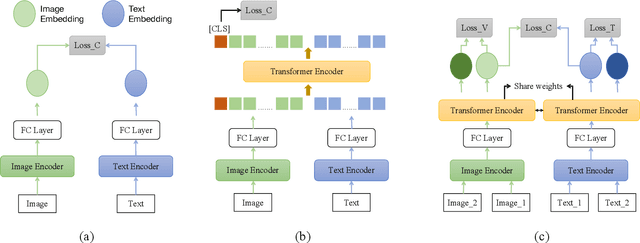
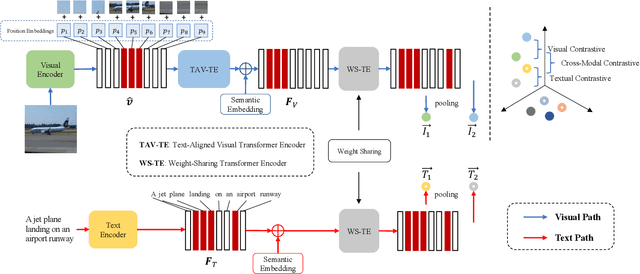

Recently, the cross-modal pre-training task has been a hotspot because of its wide application in various down-streaming researches including retrieval, captioning, question answering and so on. However, exiting methods adopt a one-stream pre-training model to explore the united vision-language representation for conducting cross-modal retrieval, which easily suffer from the calculation explosion. Moreover, although the conventional double-stream structures are quite efficient, they still lack the vital cross-modal interactions, resulting in low performances. Motivated by these challenges, we put forward a Contrastive Cross-Modal Knowledge Sharing Pre-training (COOKIE) to grasp the joint text-image representations. Structurally, COOKIE adopts the traditional double-stream structure because of the acceptable time consumption. To overcome the inherent defects of double-stream structure as mentioned above, we elaborately design two effective modules. Concretely, the first module is a weight-sharing transformer that builds on the head of the visual and textual encoders, aiming to semantically align text and image. This design enables visual and textual paths focus on the same semantics. The other one is three specially designed contrastive learning, aiming to share knowledge between different models. The shared cross-modal knowledge develops the study of unimodal representation greatly, promoting the single-modal retrieval tasks. Extensive experimental results on multi-modal matching researches that includes cross-modal retrieval, text matching, and image retrieval reveal the superiors in calculation efficiency and statistical indicators of our pre-training model.
Infrared Image Super-Resolution via Heterogeneous Convolutional WGAN
Sep 02, 2021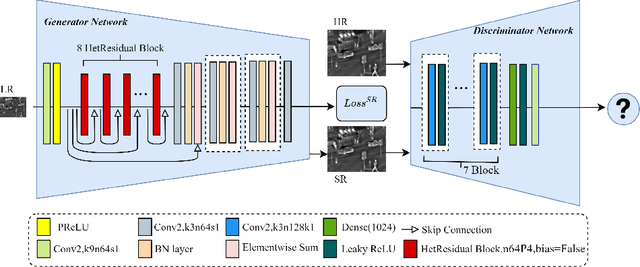
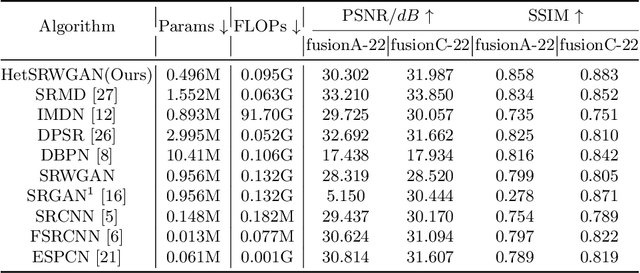
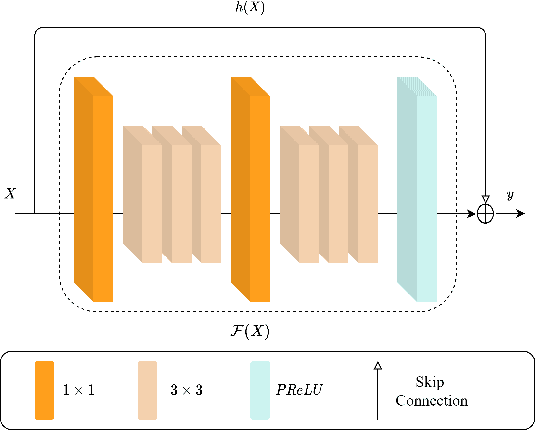
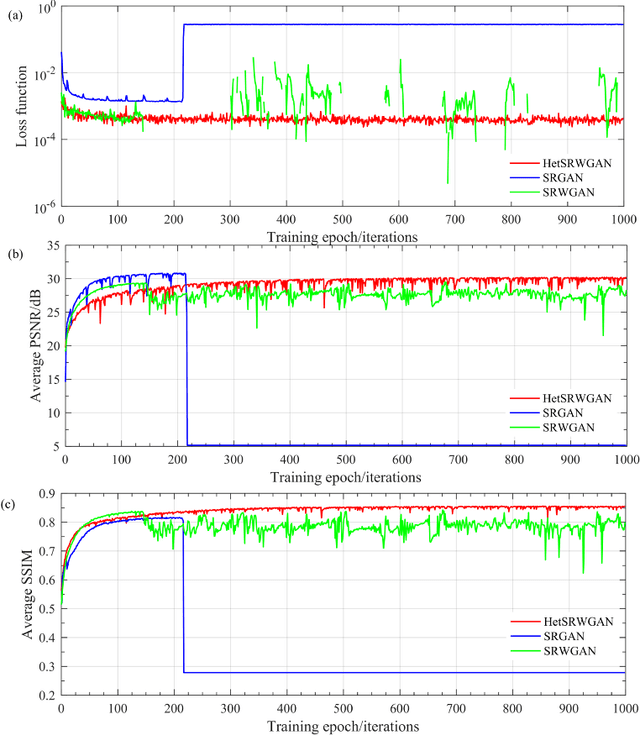
Image super-resolution is important in many fields, such as surveillance and remote sensing. However, infrared (IR) images normally have low resolution since the optical equipment is relatively expensive. Recently, deep learning methods have dominated image super-resolution and achieved remarkable performance on visible images; however, IR images have received less attention. IR images have fewer patterns, and hence, it is difficult for deep neural networks (DNNs) to learn diverse features from IR images. In this paper, we present a framework that employs heterogeneous convolution and adversarial training, namely, heterogeneous kernel-based super-resolution Wasserstein GAN (HetSRWGAN), for IR image super-resolution. The HetSRWGAN algorithm is a lightweight GAN architecture that applies a plug-and-play heterogeneous kernel-based residual block. Moreover, a novel loss function that employs image gradients is adopted, which can be applied to an arbitrary model. The proposed HetSRWGAN achieves consistently better performance in both qualitative and quantitative evaluations. According to the experimental results, the whole training process is more stable.