 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Domain Adaptation for Semantic Image Segmentation: a Comprehensive Survey
Dec 06, 2021
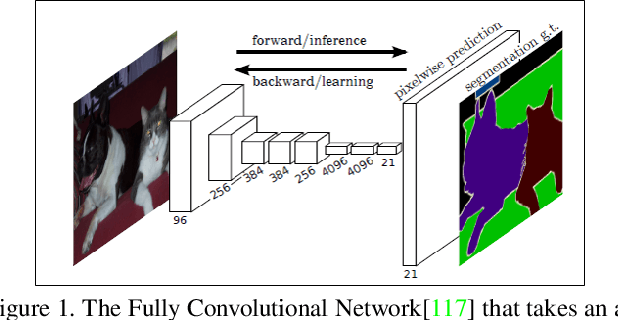
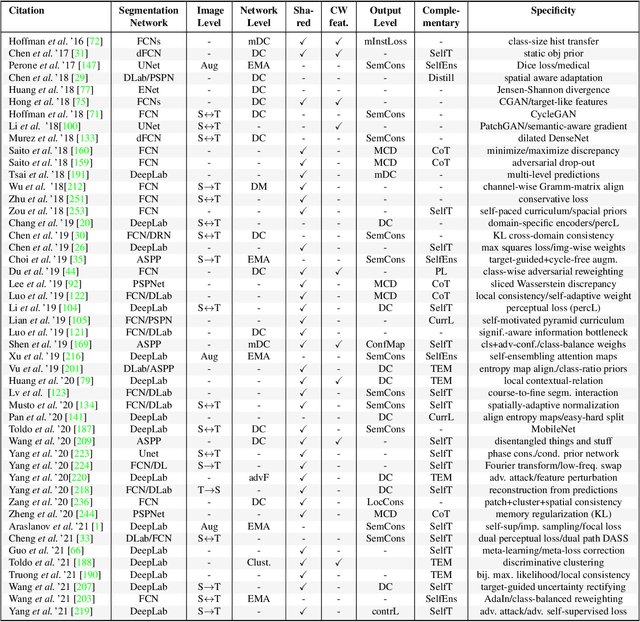
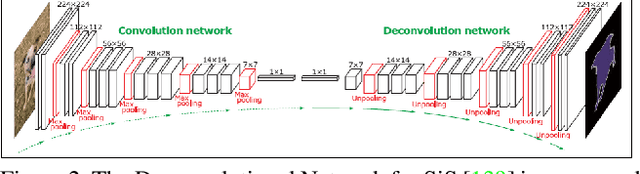
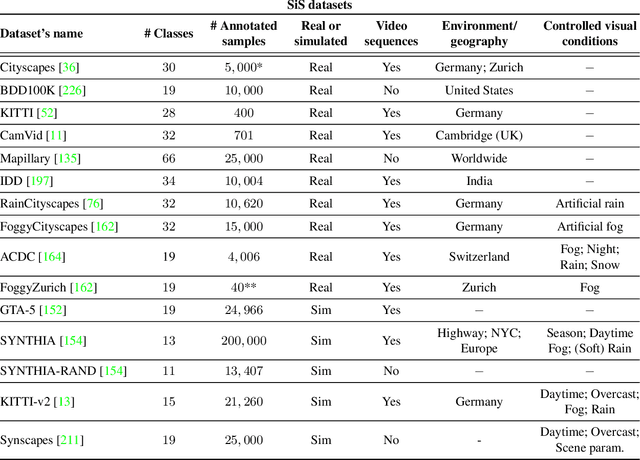
Semantic segmentation plays a fundamental role in a broad variety of computer vision applications, providing key information for the global understanding of an image. Yet, the state-of-the-art models rely on large amount of annotated samples, which are more expensive to obtain than in tasks such as image classification. Since unlabelled data is instead significantly cheaper to obtain, it is not surprising that Unsupervised Domain Adaptation reached a broad success within the semantic segmentation community. This survey is an effort to summarize five years of this incredibly rapidly growing field, which embraces the importance of semantic segmentation itself and a critical need of adapting segmentation models to new environments. We present the most important semantic segmentation methods; we provide a comprehensive survey on domain adaptation techniques for semantic segmentation; we unveil newer trends such as multi-domain learning, domain generalization, test-time adaptation or source-free domain adaptation; we conclude this survey by describing datasets and benchmarks most widely used in semantic segmentation research. We hope that this survey will provide researchers across academia and industry with a comprehensive reference guide and will help them in fostering new research directions in the field.
Does Self-supervised Learning Really Improve Reinforcement Learning from Pixels?
Jun 23, 2022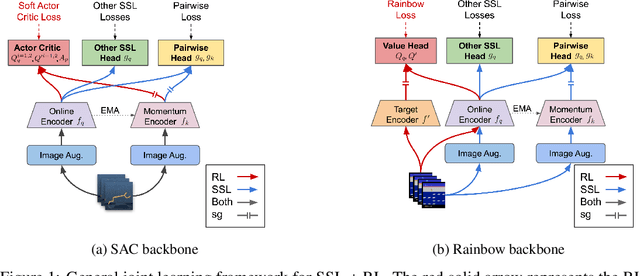


We investigate whether self-supervised learning (SSL) can improve online reinforcement learning (RL) from pixels. We extend the contrastive reinforcement learning framework (e.g., CURL) that jointly optimizes SSL and RL losses and conduct an extensive amount of experiments with various self-supervised losses. Our observations suggest that the existing SSL framework for RL fails to bring meaningful improvement over the baselines only taking advantage of image augmentation when the same amount of data and augmentation is used. We further perform an evolutionary search to find the optimal combination of multiple self-supervised losses for RL, but find that even such a loss combination fails to meaningfully outperform the methods that only utilize carefully designed image augmentations. Often, the use of self-supervised losses under the existing framework lowered RL performances. We evaluate the approach in multiple different environments including a real-world robot environment and confirm that no single self-supervised loss or image augmentation method can dominate all environments and that the current framework for joint optimization of SSL and RL is limited. Finally, we empirically investigate the pretraining framework for SSL + RL and the properties of representations learned with different approaches.
Rethinking Adversarial Examples for Location Privacy Protection
Jun 28, 2022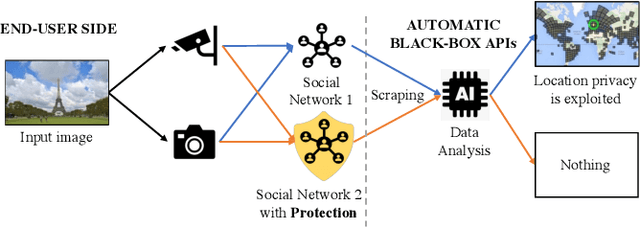

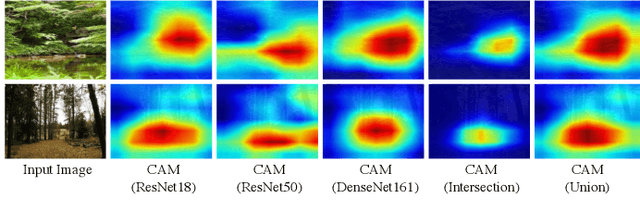

We have investigated a new application of adversarial examples, namely location privacy protection against landmark recognition systems. We introduce mask-guided multimodal projected gradient descent (MM-PGD), in which adversarial examples are trained on different deep models. Image contents are protected by analyzing the properties of regions to identify the ones most suitable for blending in adversarial examples. We investigated two region identification strategies: class activation map-based MM-PGD, in which the internal behaviors of trained deep models are targeted; and human-vision-based MM-PGD, in which regions that attract less human attention are targeted. Experiments on the Places365 dataset demonstrated that these strategies are potentially effective in defending against black-box landmark recognition systems without the need for much image manipulation.
Immunofluorescence Capillary Imaging Segmentation: Cases Study
Jul 14, 2022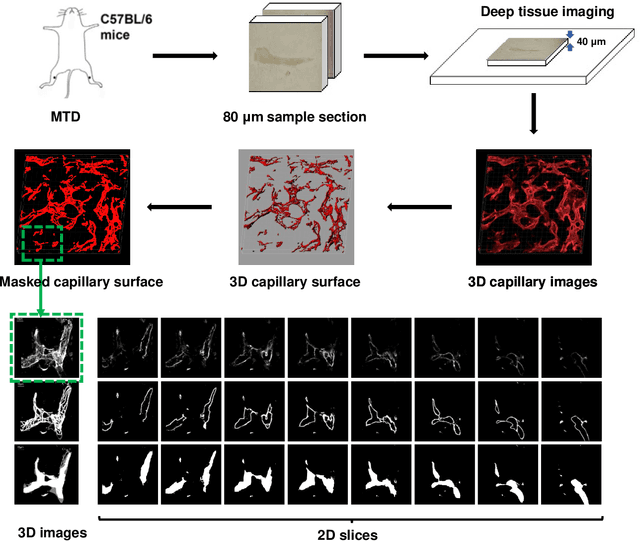

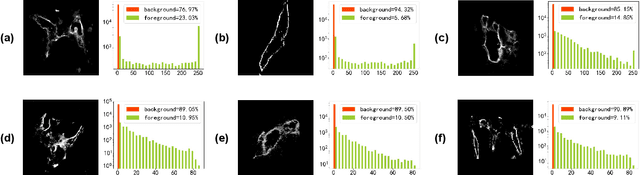

Nonunion is one of the challenges faced by orthopedics clinics for the technical difficulties and high costs in photographing interosseous capillaries. Segmenting vessels and filling capillaries are critical in understanding the obstacles encountered in capillary growth. However, existing datasets for blood vessel segmentation mainly focus on the large blood vessels of the body, and the lack of labeled capillary image datasets greatly limits the methodological development and applications of vessel segmentation and capillary filling. Here, we present a benchmark dataset, named IFCIS-155, consisting of 155 2D capillary images with segmentation boundaries and vessel fillings annotated by biomedical experts, and 19 large-scale, high-resolution 3D capillary images. To obtain better images of interosseous capillaries, we leverage state-of-the-art immunofluorescence imaging techniques to highlight the rich vascular morphology of interosseous capillaries. We conduct comprehensive experiments to verify the effectiveness of the dataset and the benchmarking deep learning models (\eg UNet/UNet++ and the modified UNet/UNet++). Our work offers a benchmark dataset for training deep learning models for capillary image segmentation and provides a potential tool for future capillary research. The IFCIS-155 dataset and code are all publicly available at \url{https://github.com/ncclabsustech/IFCIS-55}.
Light Field Image Super-Resolution with Transformers
Aug 17, 2021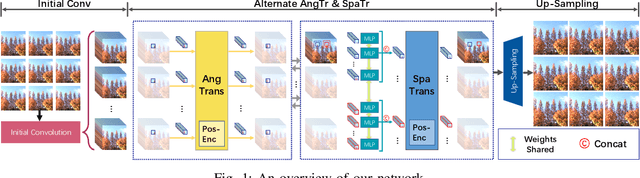

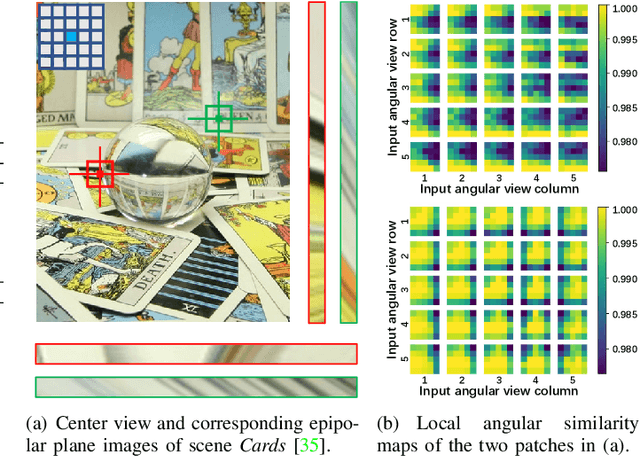
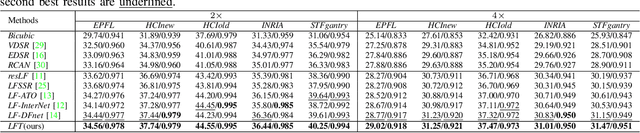
Light field (LF) image super-resolution (SR) aims at reconstructing high-resolution LF images from their low-resolution counterparts. Although CNN-based methods have achieved remarkable performance in LF image SR, these methods cannot fully model the non-local properties of the 4D LF data. In this paper, we propose a simple but effective Transformer-based method for LF image SR. In our method, an angular Transformer is designed to incorporate complementary information among different views, and a spatial Transformer is developed to capture both local and long-range dependencies within each sub-aperture image. With the proposed angular and spatial Transformers, the beneficial information in an LF can be fully exploited and the SR performance is boosted. We validate the effectiveness of our angular and spatial Transformers through extensive ablation studies, and compare our method to recent state-of-the-art methods on five public LF datasets. Our method achieves superior SR performance with a small model size and low computational cost.
Mixed Transformer U-Net For Medical Image Segmentation
Nov 11, 2021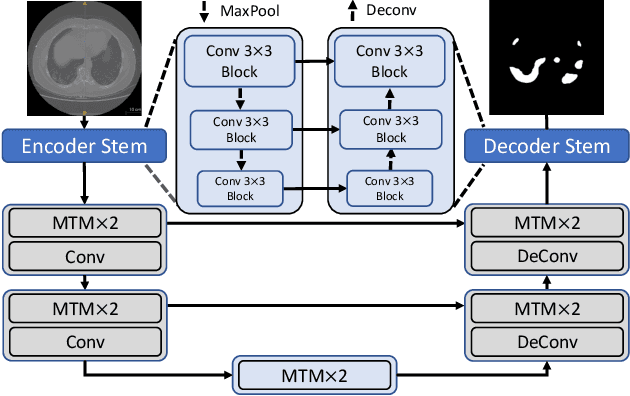

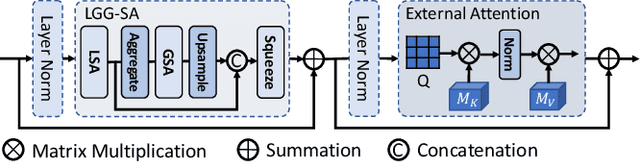
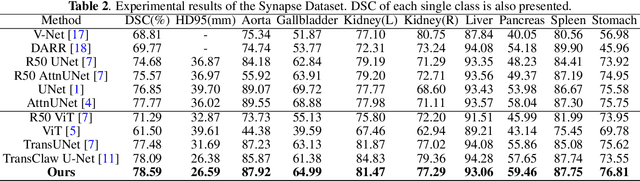
Though U-Net has achieved tremendous success in medical image segmentation tasks, it lacks the ability to explicitly model long-range dependencies. Therefore, Vision Transformers have emerged as alternative segmentation structures recently, for their innate ability of capturing long-range correlations through Self-Attention (SA). However, Transformers usually rely on large-scale pre-training and have high computational complexity. Furthermore, SA can only model self-affinities within a single sample, ignoring the potential correlations of the overall dataset. To address these problems, we propose a novel Transformer module named Mixed Transformer Module (MTM) for simultaneous inter- and intra- affinities learning. MTM first calculates self-affinities efficiently through our well-designed Local-Global Gaussian-Weighted Self-Attention (LGG-SA). Then, it mines inter-connections between data samples through External Attention (EA). By using MTM, we construct a U-shaped model named Mixed Transformer U-Net (MT-UNet) for accurate medical image segmentation. We test our method on two different public datasets, and the experimental results show that the proposed method achieves better performance over other state-of-the-art methods. The code is available at: https://github.com/Dootmaan/MT-UNet.
Masked Autoencoders are Robust Data Augmentors
Jun 10, 2022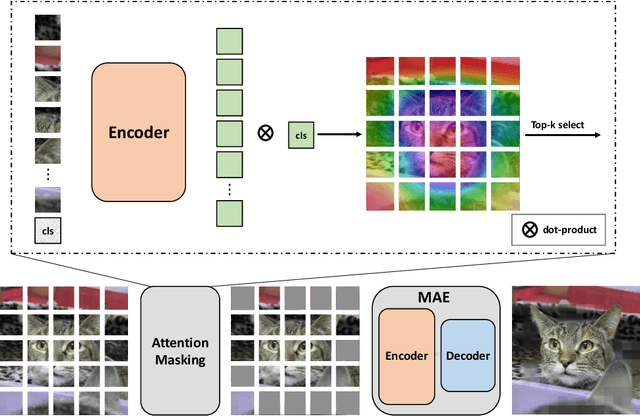
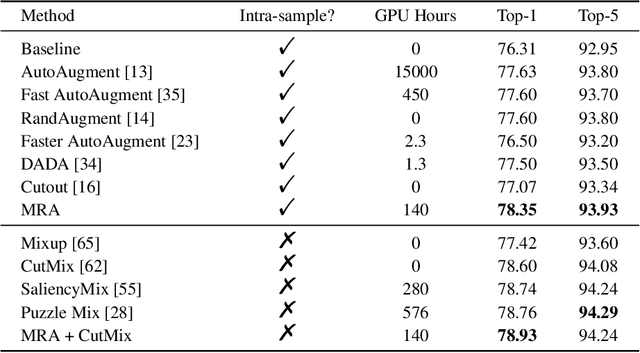
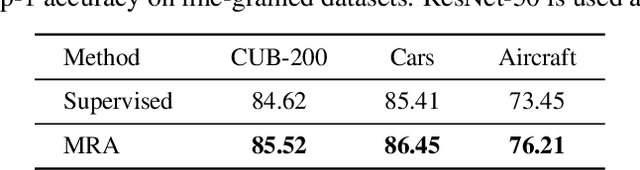

Deep neural networks are capable of learning powerful representations to tackle complex vision tasks but expose undesirable properties like the over-fitting issue. To this end, regularization techniques like image augmentation are necessary for deep neural networks to generalize well. Nevertheless, most prevalent image augmentation recipes confine themselves to off-the-shelf linear transformations like scale, flip, and colorjitter. Due to their hand-crafted property, these augmentations are insufficient to generate truly hard augmented examples. In this paper, we propose a novel perspective of augmentation to regularize the training process. Inspired by the recent success of applying masked image modeling to self-supervised learning, we adopt the self-supervised masked autoencoder to generate the distorted view of the input images. We show that utilizing such model-based nonlinear transformation as data augmentation can improve high-level recognition tasks. We term the proposed method as \textbf{M}ask-\textbf{R}econstruct \textbf{A}ugmentation (MRA). The extensive experiments on various image classification benchmarks verify the effectiveness of the proposed augmentation. Specifically, MRA consistently enhances the performance on supervised, semi-supervised as well as few-shot classification. The code will be available at \url{https://github.com/haohang96/MRA}.
Work In Progress: Safety and Robustness Verification of Autoencoder-Based Regression Models using the NNV Tool
Jul 14, 2022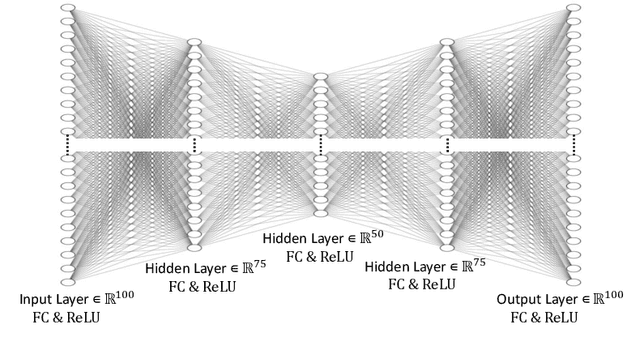
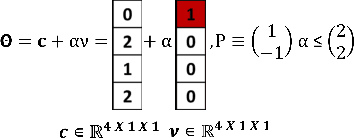
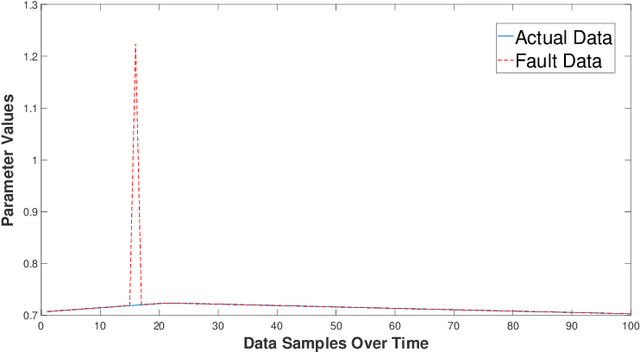

This work in progress paper introduces robustness verification for autoencoder-based regression neural network (NN) models, following state-of-the-art approaches for robustness verification of image classification NNs. Despite the ongoing progress in developing verification methods for safety and robustness in various deep neural networks (DNNs), robustness checking of autoencoder models has not yet been considered. We explore this open space of research and check ways to bridge the gap between existing DNN verification methods by extending existing robustness analysis methods for such autoencoder networks. While classification models using autoencoders work more or less similar to image classification NNs, the functionality of regression models is distinctly different. We introduce two definitions of robustness evaluation metrics for autoencoder-based regression models, specifically the percentage robustness and un-robustness grade. We also modified the existing Imagestar approach, adjusting the variables to take care of the specific input types for regression networks. The approach is implemented as an extension of NNV, then applied and evaluated on a dataset, with a case study experiment shown using the same dataset. As per the authors' understanding, this work in progress paper is the first to show possible reachability analysis of autoencoder-based NNs.
* In Proceedings SNR 2021, arXiv:2207.04391
Category-Level Pose Retrieval with Contrastive Features Learnt with Occlusion Augmentation
Aug 16, 2022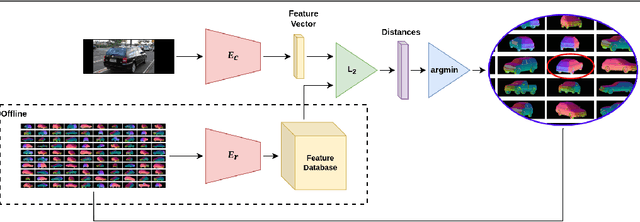
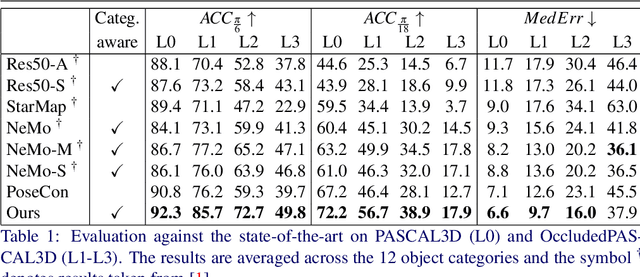

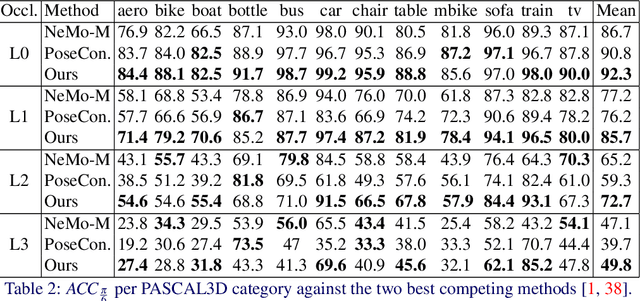
Pose estimation is usually tackled as either a bin classification problem or as a regression problem. In both cases, the idea is to directly predict the pose of an object. This is a non-trivial task because of appearance variations of similar poses and similarities between different poses. Instead, we follow the key idea that it is easier to compare two poses than to estimate them. Render-and-compare approaches have been employed to that end, however, they tend to be unstable, computationally expensive, and slow for real-time applications. We propose doing category-level pose estimation by learning an alignment metric using a contrastive loss with a dynamic margin and a continuous pose-label space. For efficient inference, we use a simple real-time image retrieval scheme with a reference set of renderings projected to an embedding space. To achieve robustness to real-world conditions, we employ synthetic occlusions, bounding box perturbations, and appearance augmentations. Our approach achieves state-of-the-art performance on PASCAL3D and OccludedPASCAL3D, as well as high-quality results on KITTI3D.
Mix-Teaching: A Simple, Unified and Effective Semi-Supervised Learning Framework for Monocular 3D Object Detection
Jul 10, 2022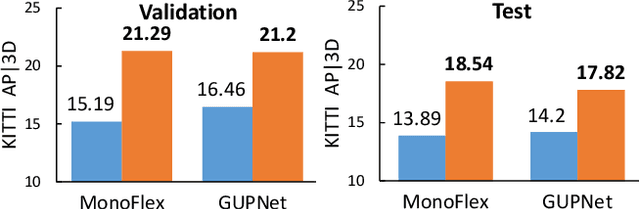
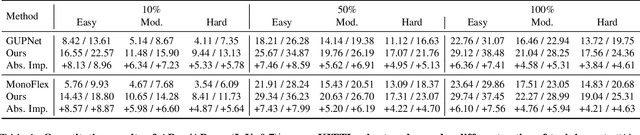
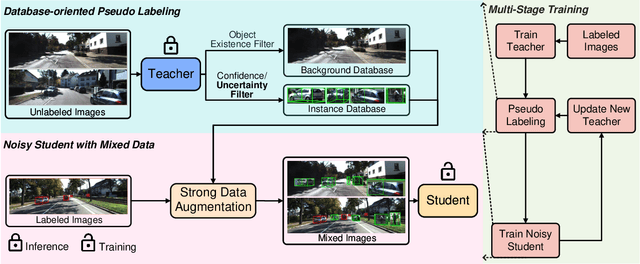
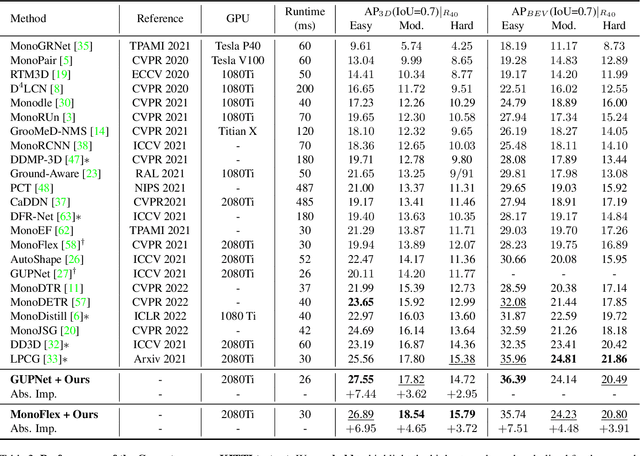
Monocular 3D object detection is an essential perception task for autonomous driving. However, the high reliance on large-scale labeled data make it costly and time-consuming during model optimization. To reduce such over-reliance on human annotations, we propose Mix-Teaching, an effective semi-supervised learning framework applicable to employ both labeled and unlabeled images in training stage. Mix-Teaching first generates pseudo-labels for unlabeled images by self-training. The student model is then trained on the mixed images possessing much more intensive and precise labeling by merging instance-level image patches into empty backgrounds or labeled images. This is the first to break the image-level limitation and put high-quality pseudo labels from multi frames into one image for semi-supervised training. Besides, as a result of the misalignment between confidence score and localization quality, it's hard to discriminate high-quality pseudo-labels from noisy predictions using only confidence-based criterion. To that end, we further introduce an uncertainty-based filter to help select reliable pseudo boxes for the above mixing operation. To the best of our knowledge, this is the first unified SSL framework for monocular 3D object detection. Mix-Teaching consistently improves MonoFlex and GUPNet by significant margins under various labeling ratios on KITTI dataset. For example, our method achieves around +6.34% AP@0.7 improvement against the GUPNet baseline on validation set when using only 10% labeled data. Besides, by leveraging full training set and the additional 48K raw images of KITTI, it can further improve the MonoFlex by +4.65% improvement on AP@0.7 for car detection, reaching 18.54% AP@0.7, which ranks the 1st place among all monocular based methods on KITTI test leaderboard. The code and pretrained models will be released at https://github.com/yanglei18/Mix-Teaching.