 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Region-guided CycleGANs for Stain Transfer in Whole Slide Images
Aug 26, 2022
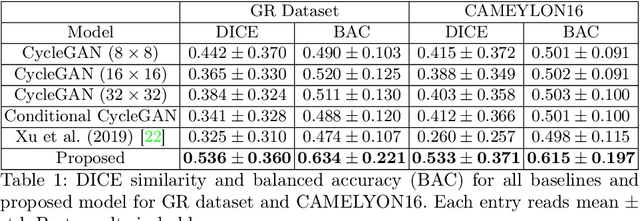
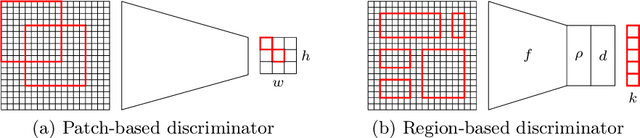
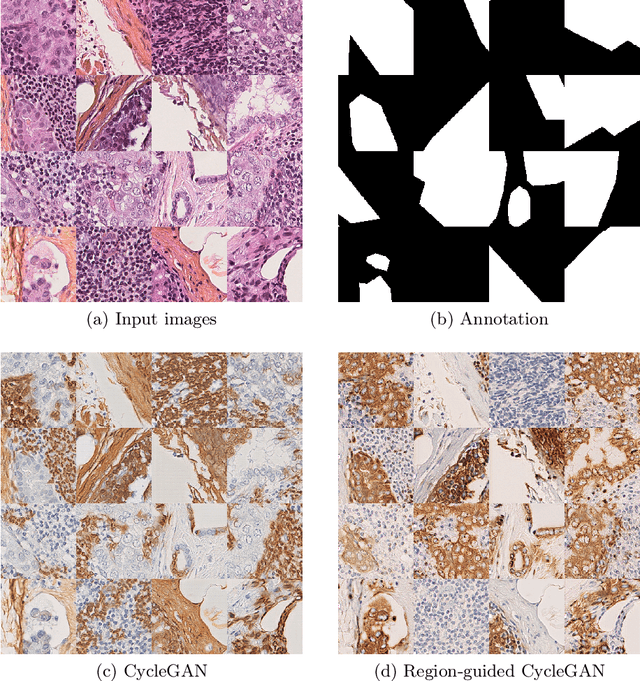
In whole slide imaging, commonly used staining techniques based on hematoxylin and eosin (H&E) and immunohistochemistry (IHC) stains accentuate different aspects of the tissue landscape. In the case of detecting metastases, IHC provides a distinct readout that is readily interpretable by pathologists. IHC, however, is a more expensive approach and not available at all medical centers. Virtually generating IHC images from H&E using deep neural networks thus becomes an attractive alternative. Deep generative models such as CycleGANs learn a semantically-consistent mapping between two image domains, while emulating the textural properties of each domain. They are therefore a suitable choice for stain transfer applications. However, they remain fully unsupervised, and possess no mechanism for enforcing biological consistency in stain transfer. In this paper, we propose an extension to CycleGANs in the form of a region of interest discriminator. This allows the CycleGAN to learn from unpaired datasets where, in addition, there is a partial annotation of objects for which one wishes to enforce consistency. We present a use case on whole slide images, where an IHC stain provides an experimentally generated signal for metastatic cells. We demonstrate the superiority of our approach over prior art in stain transfer on histopathology tiles over two datasets. Our code and model are available at https://github.com/jcboyd/miccai2022-roigan.
Adaptive color transfer from images to terrain visualizations
May 30, 2022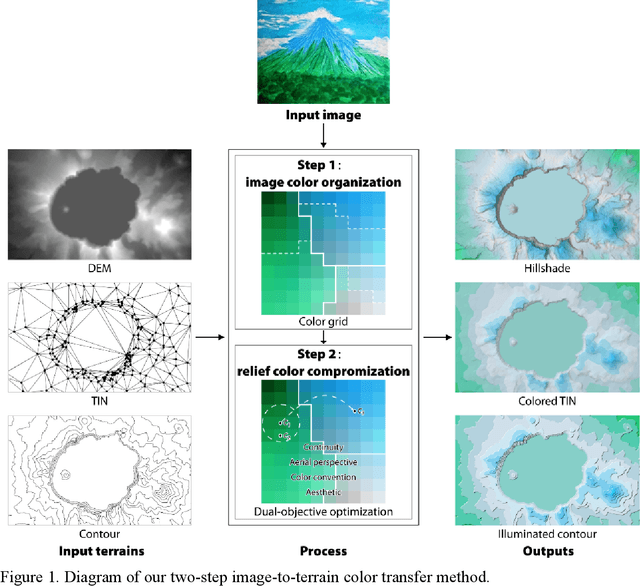

Terrain mapping is not only dedicated to communicating how high or how steep a landscape is but can also help to narrate how we feel about a place. However, crafting effective and expressive hypsometric tints is challenging for both nonexperts and experts. In this paper, we present a two-step image-to-terrain color transfer method that can transfer color from arbitrary images to diverse terrain models. First, we present a new image color organization method that organizes discrete, irregular image colors into a continuous, regular color grid that facilitates a series of color operations, such as local and global searching, categorical color selection and sequential color interpolation. Second, we quantify a series of subjective concerns about elevation color crafting, such as "the lower, the higher" principle, color conventions, and aerial perspectives. We also define color similarity between image and terrain visualization with aesthetic quality. We then mathematically formulate image-to-terrain color transfer as a dual-objective optimization problem and offer a heuristic searching method to solve the problem. Finally, we compare elevation tints from our method with a standard color scheme on four test terrains. The evaluations show that the hypsometric tints from the proposed method can work as effectively as the standard scheme and that our tints are more visually favorable. We also showcase that our method can transfer emotion from image to terrain visualization.
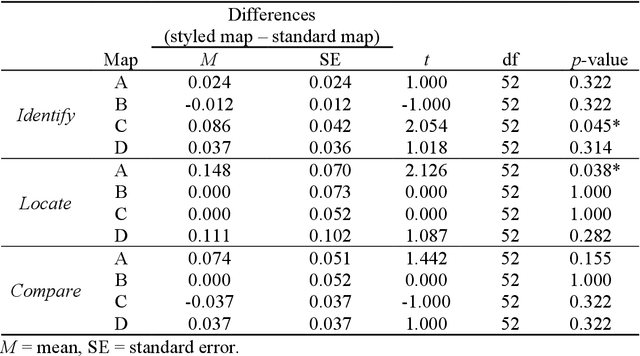
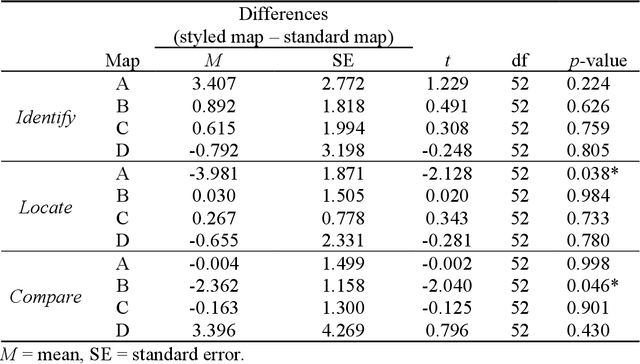
INTRPRT: A Systematic Review of and Guidelines for Designing and Validating Transparent AI in Medical Image Analysis
Dec 21, 2021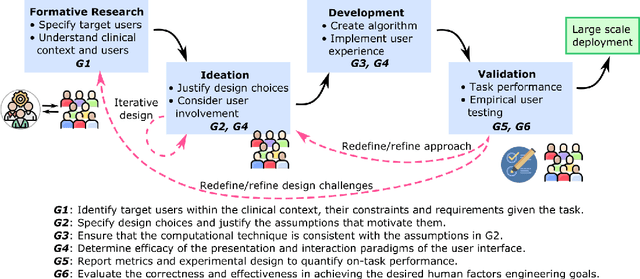
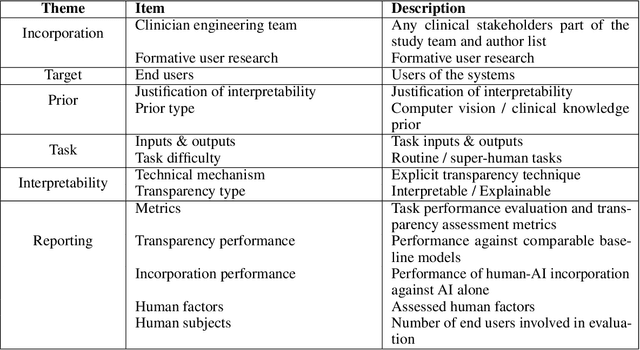
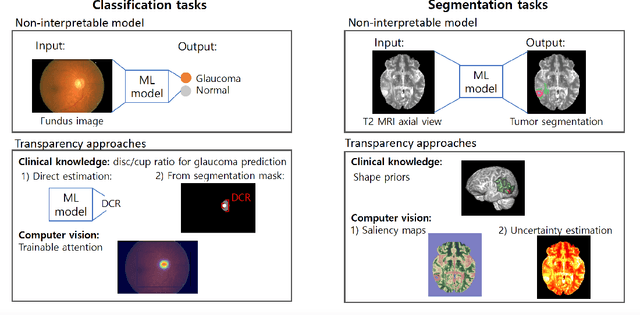
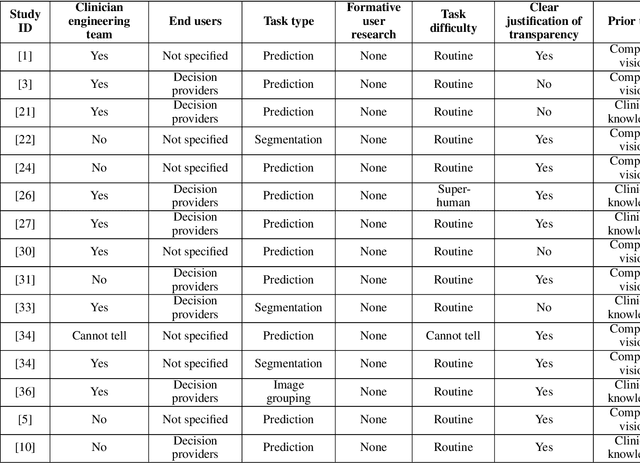
Transparency in Machine Learning (ML), attempts to reveal the working mechanisms of complex models. Transparent ML promises to advance human factors engineering goals of human-centered AI in the target users. From a human-centered design perspective, transparency is not a property of the ML model but an affordance, i.e. a relationship between algorithm and user; as a result, iterative prototyping and evaluation with users is critical to attaining adequate solutions that afford transparency. However, following human-centered design principles in healthcare and medical image analysis is challenging due to the limited availability of and access to end users. To investigate the state of transparent ML in medical image analysis, we conducted a systematic review of the literature. Our review reveals multiple severe shortcomings in the design and validation of transparent ML for medical image analysis applications. We find that most studies to date approach transparency as a property of the model itself, similar to task performance, without considering end users during neither development nor evaluation. Additionally, the lack of user research, and the sporadic validation of transparency claims put contemporary research on transparent ML for medical image analysis at risk of being incomprehensible to users, and thus, clinically irrelevant. To alleviate these shortcomings in forthcoming research while acknowledging the challenges of human-centered design in healthcare, we introduce the INTRPRT guideline, a systematic design directive for transparent ML systems in medical image analysis. The INTRPRT guideline suggests formative user research as the first step of transparent model design to understand user needs and domain requirements. Following this process produces evidence to support design choices, and ultimately, increases the likelihood that the algorithms afford transparency.
EpiGRAF: Rethinking training of 3D GANs
Jun 21, 2022
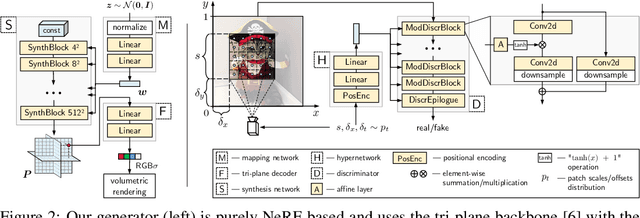
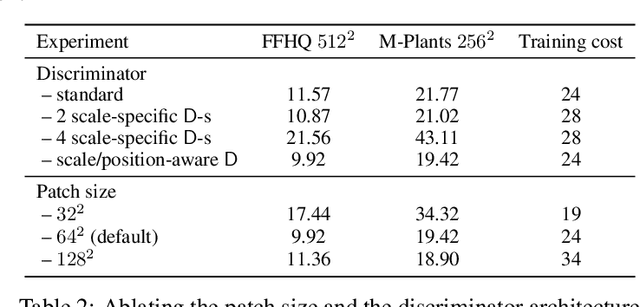
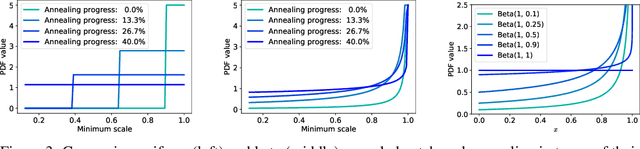
A very recent trend in generative modeling is building 3D-aware generators from 2D image collections. To induce the 3D bias, such models typically rely on volumetric rendering, which is expensive to employ at high resolutions. During the past months, there appeared more than 10 works that address this scaling issue by training a separate 2D decoder to upsample a low-resolution image (or a feature tensor) produced from a pure 3D generator. But this solution comes at a cost: not only does it break multi-view consistency (i.e. shape and texture change when the camera moves), but it also learns the geometry in a low fidelity. In this work, we show that it is possible to obtain a high-resolution 3D generator with SotA image quality by following a completely different route of simply training the model patch-wise. We revisit and improve this optimization scheme in two ways. First, we design a location- and scale-aware discriminator to work on patches of different proportions and spatial positions. Second, we modify the patch sampling strategy based on an annealed beta distribution to stabilize training and accelerate the convergence. The resulted model, named EpiGRAF, is an efficient, high-resolution, pure 3D generator, and we test it on four datasets (two introduced in this work) at $256^2$ and $512^2$ resolutions. It obtains state-of-the-art image quality, high-fidelity geometry and trains ${\approx} 2.5 \times$ faster than the upsampler-based counterparts. Project website: https://universome.github.io/epigraf.
Towards the Probabilistic Fusion of Learned Priors into Standard Pipelines for 3D Reconstruction
Jul 27, 2022
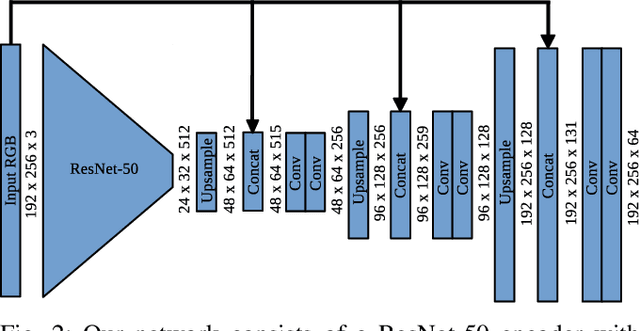
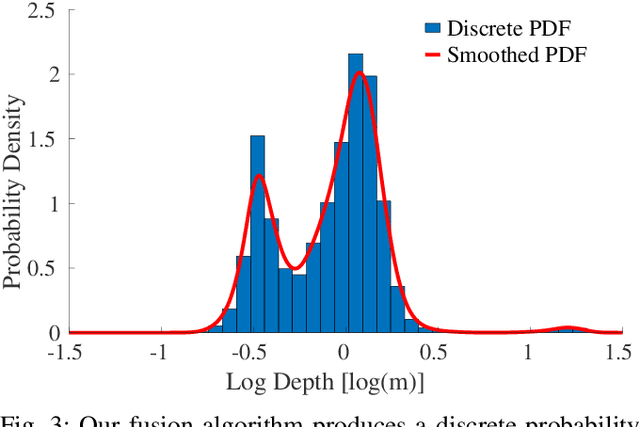

The best way to combine the results of deep learning with standard 3D reconstruction pipelines remains an open problem. While systems that pass the output of traditional multi-view stereo approaches to a network for regularisation or refinement currently seem to get the best results, it may be preferable to treat deep neural networks as separate components whose results can be probabilistically fused into geometry-based systems. Unfortunately, the error models required to do this type of fusion are not well understood, with many different approaches being put forward. Recently, a few systems have achieved good results by having their networks predict probability distributions rather than single values. We propose using this approach to fuse a learned single-view depth prior into a standard 3D reconstruction system. Our system is capable of incrementally producing dense depth maps for a set of keyframes. We train a deep neural network to predict discrete, nonparametric probability distributions for the depth of each pixel from a single image. We then fuse this "probability volume" with another probability volume based on the photometric consistency between subsequent frames and the keyframe image. We argue that combining the probability volumes from these two sources will result in a volume that is better conditioned. To extract depth maps from the volume, we minimise a cost function that includes a regularisation term based on network predicted surface normals and occlusion boundaries. Through a series of experiments, we demonstrate that each of these components improves the overall performance of the system.
Neuroevolution-based Classifiers for Deforestation Detection in Tropical Forests
Aug 23, 2022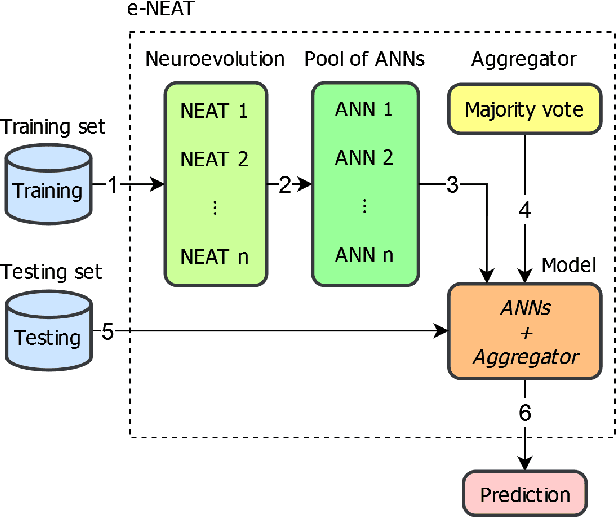
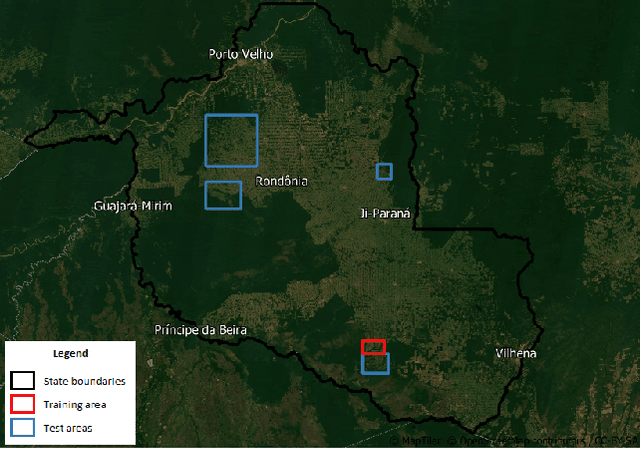
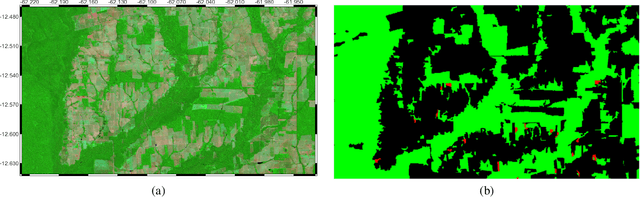

Tropical forests represent the home of many species on the planet for flora and fauna, retaining billions of tons of carbon footprint, promoting clouds and rain formation, implying a crucial role in the global ecosystem, besides representing the home to countless indigenous peoples. Unfortunately, millions of hectares of tropical forests are lost every year due to deforestation or degradation. To mitigate that fact, monitoring and deforestation detection programs are in use, in addition to public policies for the prevention and punishment of criminals. These monitoring/detection programs generally use remote sensing images, image processing techniques, machine learning methods, and expert photointerpretation to analyze, identify and quantify possible changes in forest cover. Several projects have proposed different computational approaches, tools, and models to efficiently identify recent deforestation areas, improving deforestation monitoring programs in tropical forests. In this sense, this paper proposes the use of pattern classifiers based on neuroevolution technique (NEAT) in tropical forest deforestation detection tasks. Furthermore, a novel framework called e-NEAT has been created and achieved classification results above $90\%$ for balanced accuracy measure in the target application using an extremely reduced and limited training set for learning the classification models. These results represent a relative gain of $6.2\%$ over the best baseline ensemble method compared in this paper
Disentangle and Remerge: Interventional Knowledge Distillation for Few-Shot Object Detection from A Conditional Causal Perspective
Aug 26, 2022
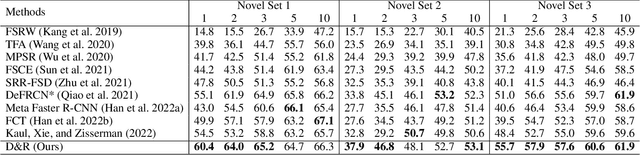
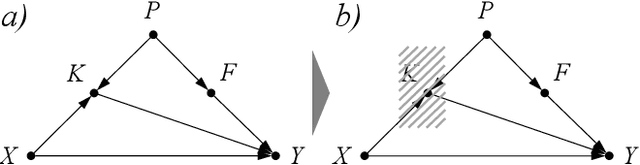
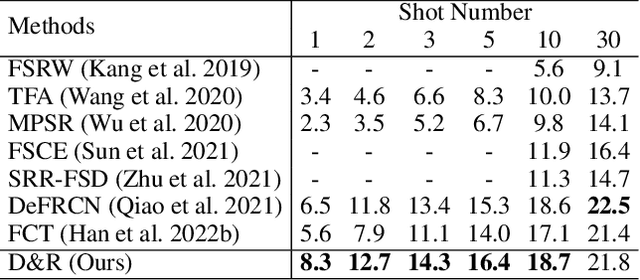
Few-shot learning models learn representations with limited human annotations, and such a learning paradigm demonstrates practicability in various tasks, e.g., image classification, object detection, etc. However, few-shot object detection methods suffer from an intrinsic defect that the limited training data makes the model cannot sufficiently explore semantic information. To tackle this, we introduce knowledge distillation to the few-shot object detection learning paradigm. We further run a motivating experiment, which demonstrates that in the process of knowledge distillation the empirical error of the teacher model degenerates the prediction performance of the few-shot object detection model, as the student. To understand the reasons behind this phenomenon, we revisit the learning paradigm of knowledge distillation on the few-shot object detection task from the causal theoretic standpoint, and accordingly, develop a Structural Causal Model. Following the theoretical guidance, we propose a backdoor adjustment-based knowledge distillation method for the few-shot object detection task, namely Disentangle and Remerge (D&R), to perform conditional causal intervention toward the corresponding Structural Causal Model. Theoretically, we provide an extended definition, i.e., general backdoor path, for the backdoor criterion, which can expand the theoretical application boundary of the backdoor criterion in specific cases. Empirically, the experiments on multiple benchmark datasets demonstrate that D&R can yield significant performance boosts in few-shot object detection.
HSIC-InfoGAN: Learning Unsupervised Disentangled Representations by Maximising Approximated Mutual Information
Aug 06, 2022
Learning disentangled representations requires either supervision or the introduction of specific model designs and learning constraints as biases. InfoGAN is a popular disentanglement framework that learns unsupervised disentangled representations by maximising the mutual information between latent representations and their corresponding generated images. Maximisation of mutual information is achieved by introducing an auxiliary network and training with a latent regression loss. In this short exploratory paper, we study the use of the Hilbert-Schmidt Independence Criterion (HSIC) to approximate mutual information between latent representation and image, termed HSIC-InfoGAN. Directly optimising the HSIC loss avoids the need for an additional auxiliary network. We qualitatively compare the level of disentanglement in each model, suggest a strategy to tune the hyperparameters of HSIC-InfoGAN, and discuss the potential of HSIC-InfoGAN for medical applications.
On the Strong Correlation Between Model Invariance and Generalization
Jul 14, 2022

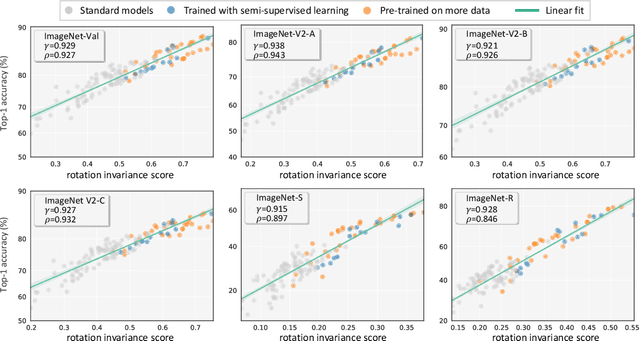
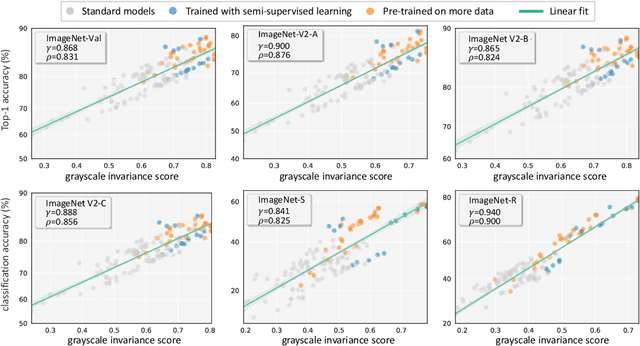
Generalization and invariance are two essential properties of any machine learning model. Generalization captures a model's ability to classify unseen data while invariance measures consistency of model predictions on transformations of the data. Existing research suggests a positive relationship: a model generalizing well should be invariant to certain visual factors. Building on this qualitative implication we make two contributions. First, we introduce effective invariance (EI), a simple and reasonable measure of model invariance which does not rely on image labels. Given predictions on a test image and its transformed version, EI measures how well the predictions agree and with what level of confidence. Second, using invariance scores computed by EI, we perform large-scale quantitative correlation studies between generalization and invariance, focusing on rotation and grayscale transformations. From a model-centric view, we observe generalization and invariance of different models exhibit a strong linear relationship, on both in-distribution and out-of-distribution datasets. From a dataset-centric view, we find a certain model's accuracy and invariance linearly correlated on different test sets. Apart from these major findings, other minor but interesting insights are also discussed.
Regularity-constrained Fast Sine Transforms
Jul 27, 2022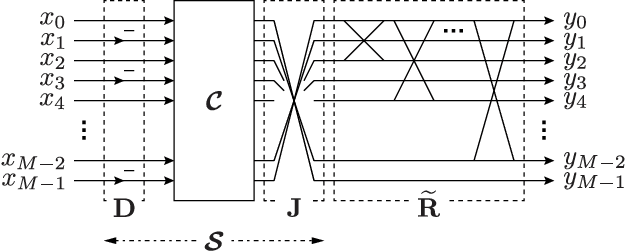
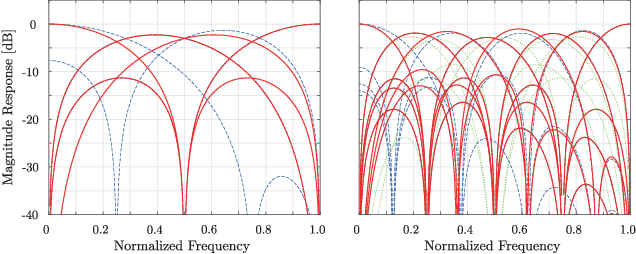
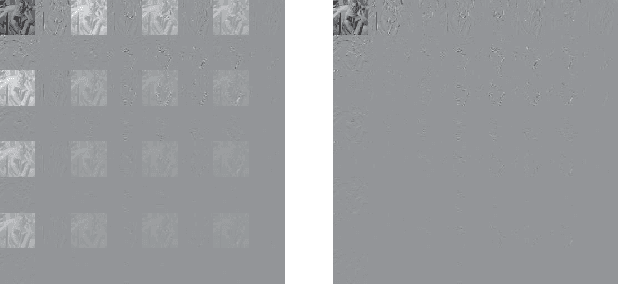
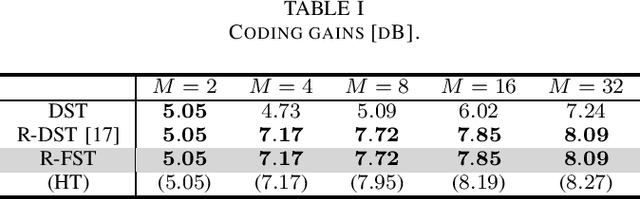
This letter proposes a fast implementation of the regularity-constrained discrete sine transform (R-DST). The original DST \textit{leaks} the lowest frequency (DC: direct current) components of signals into high frequency (AC: alternating current) subbands. This property is not desired in many applications, particularly image processing, since most of the frequency components in natural images concentrate in DC subband. The characteristic of filter banks whereby they do not leak DC components into the AC subbands is called \textit{regularity}. While an R-DST has been proposed, it has no fast implementation because of the singular value decomposition (SVD) in its internal algorithm. In contrast, the proposed regularity-constrained fast sine transform (R-FST) is obtained by just appending a regularity constraint matrix as a postprocessing of the original DST. When the DST size is $M\times M$ ($M=2^\ell$, $\ell\in\mathbb{N}_{\geq 1}$), the regularity constraint matrix is constructed from only $M/2-1$ rotation matrices with the angles derived from the output of the DST for the constant-valued signal (i.e., the DC signal). Since it does not require SVD, the computation is simpler and faster than the R-DST while keeping all of its beneficial properties. An image processing example shows that the R-FST has fine frequency selectivity with no DC leakage and higher coding gain than the original DST. Also, in the case of $M=8$, the R-FST saved approximately $0.126$ seconds in a 2-D transformation of $512\times 512$ signals compared with the R-DST because of fewer extra operations.