 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Federated Learning of Generative Image Priors for MRI Reconstruction
Feb 08, 2022
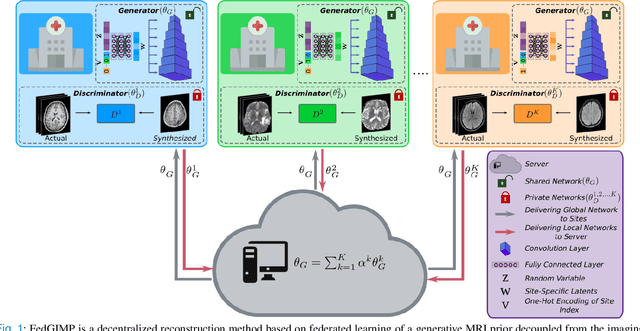
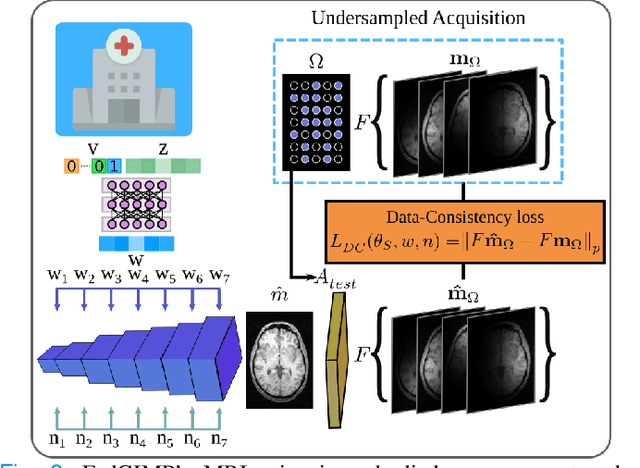
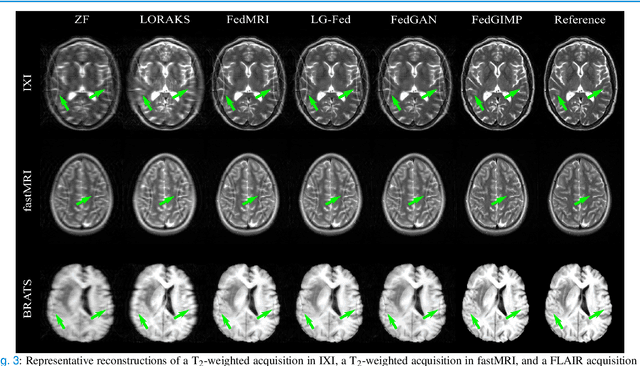
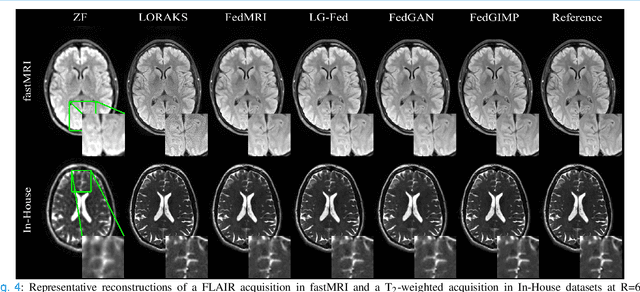
Multi-institutional efforts can facilitate training of deep MRI reconstruction models, albeit privacy risks arise during cross-site sharing of imaging data. Federated learning (FL) has recently been introduced to address privacy concerns by enabling distributed training without transfer of imaging data. Existing FL methods for MRI reconstruction employ conditional models to map from undersampled to fully-sampled acquisitions via explicit knowledge of the imaging operator. Since conditional models generalize poorly across different acceleration rates or sampling densities, imaging operators must be fixed between training and testing, and they are typically matched across sites. To improve generalization and flexibility in multi-institutional collaborations, here we introduce a novel method for MRI reconstruction based on Federated learning of Generative IMage Priors (FedGIMP). FedGIMP leverages a two-stage approach: cross-site learning of a generative MRI prior, and subject-specific injection of the imaging operator. The global MRI prior is learned via an unconditional adversarial model that synthesizes high-quality MR images based on latent variables. Specificity in the prior is preserved via a mapper subnetwork that produces site-specific latents. During inference, the prior is combined with subject-specific imaging operators to enable reconstruction, and further adapted to individual test samples by minimizing data-consistency loss. Comprehensive experiments on multi-institutional datasets clearly demonstrate enhanced generalization performance of FedGIMP against site-specific and federated methods based on conditional models, as well as traditional reconstruction methods.
Detecting the unknown in Object Detection
Aug 24, 2022
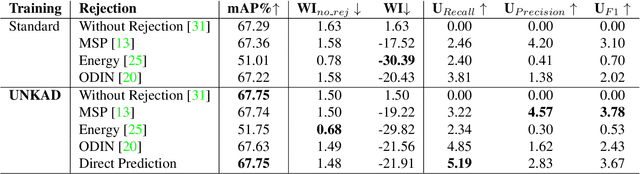

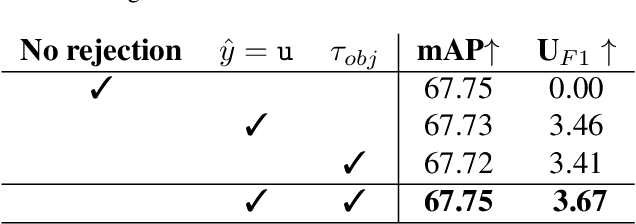
Object detection methods have witnessed impressive improvements in the last years thanks to the design of novel neural network architectures and the availability of large scale datasets. However, current methods have a significant limitation: they are able to detect only the classes observed during training time, that are only a subset of all the classes that a detector may encounter in the real world. Furthermore, the presence of unknown classes is often not considered at training time, resulting in methods not even able to detect that an unknown object is present in the image. In this work, we address the problem of detecting unknown objects, known as open-set object detection. We propose a novel training strategy, called UNKAD, able to predict unknown objects without requiring any annotation of them, exploiting non annotated objects that are already present in the background of training images. In particular, exploiting the four-steps training strategy of Faster R-CNN, UNKAD first identifies and pseudo-labels unknown objects and then uses the pseudo-annotations to train an additional unknown class. While UNKAD can directly detect unknown objects, we further combine it with previous unknown detection techniques, showing that it improves their performance at no costs.
Distributed Image Transmission using Deep Joint Source-Channel Coding
Jan 25, 2022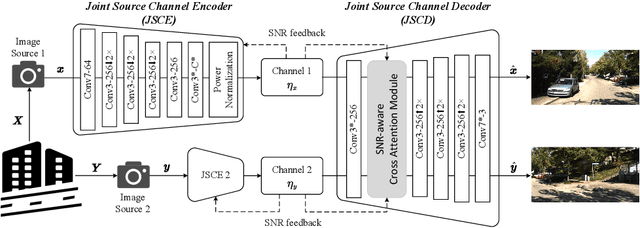
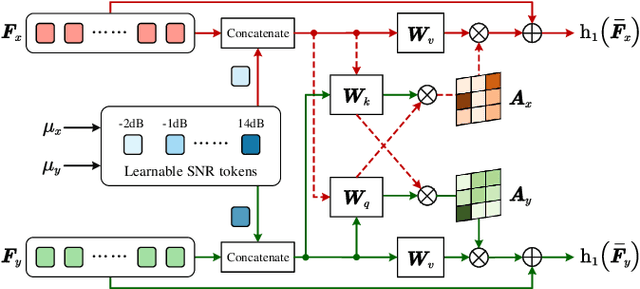
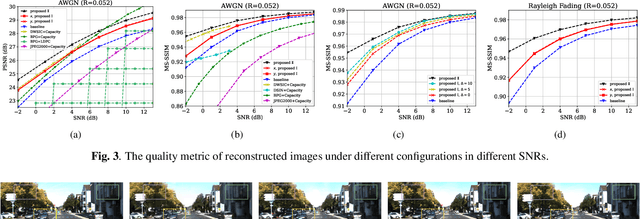

We study the problem of deep joint source-channel coding (D-JSCC) for correlated image sources, where each source is transmitted through a noisy independent channel to the common receiver. In particular, we consider a pair of images captured by two cameras with probably overlapping fields of view transmitted over wireless channels and reconstructed in the center node. The challenging problem involves designing a practical code to utilize both source and channel correlations to improve transmission efficiency without additional transmission overhead. To tackle this, we need to consider the common information across two stereo images as well as the differences between two transmission channels. In this case, we propose a deep neural networks solution that includes lightweight edge encoders and a powerful center decoder. Besides, in the decoder, we propose a novel channel state information aware cross attention module to highlight the overlapping fields and leverage the relevance between two noisy feature maps.Our results show the impressive improvement of reconstruction quality in both links by exploiting the noisy representations of the other link. Moreover, the proposed scheme shows competitive results compared to the separated schemes with capacity-achieving channel codes.
Predicting skull fractures via CNN with classification algorithms
Aug 14, 2022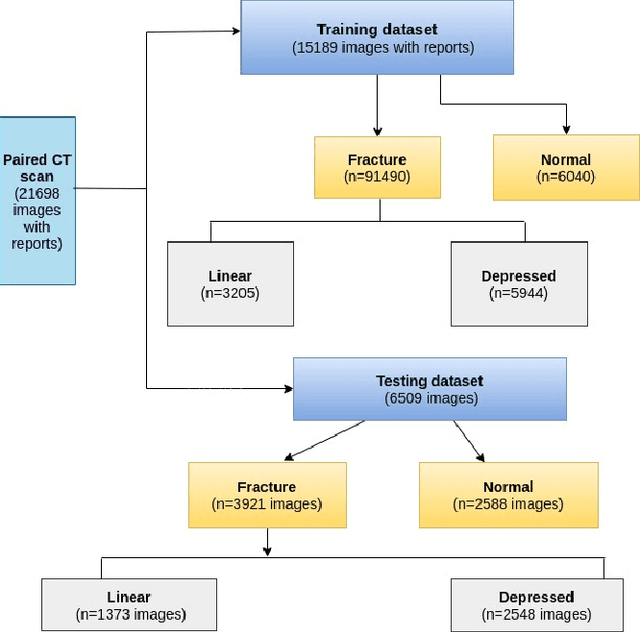
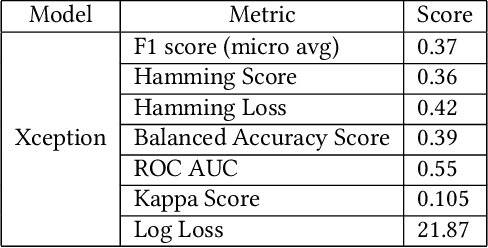
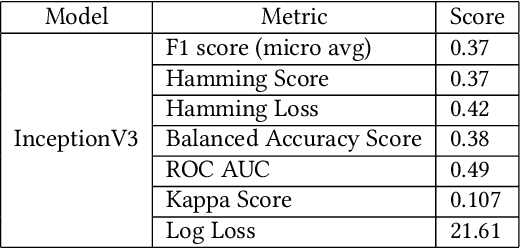
Computer Tomography (CT) images have become quite important to diagnose diseases. CT scan slice contains a vast amount of data that may not be properly examined with the requisite precision and speed using normal visual inspection. A computer-assisted skull fracture classification expert system is needed to assist physicians. Convolutional Neural Networks (CNNs) are the most extensively used deep learning models for image categorization since most often time they outperform other models in terms of accuracy and results. The CNN models were then developed and tested, and several convolutional neural network (CNN) architectures were compared. ResNet50, which was used for feature extraction combined with a gradient boosted decision tree machine learning algorithm to act as a classifier for the categorization of skull fractures from brain CT scans into three fracture categories, had the best overall F1-score of 96%, Hamming Score of 95%, Balanced accuracy Score of 94% & ROC AUC curve of 96% for the classification of skull fractures.
Terrain Classification using Transfer Learning on Hyperspectral Images: A Comparative study
Jun 19, 2022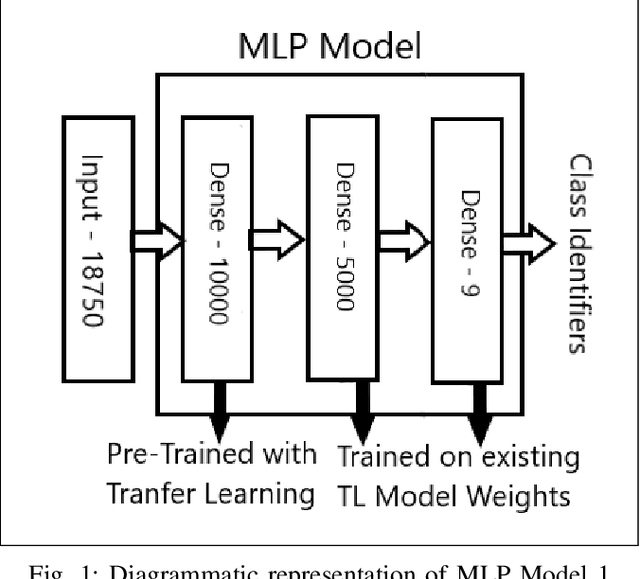
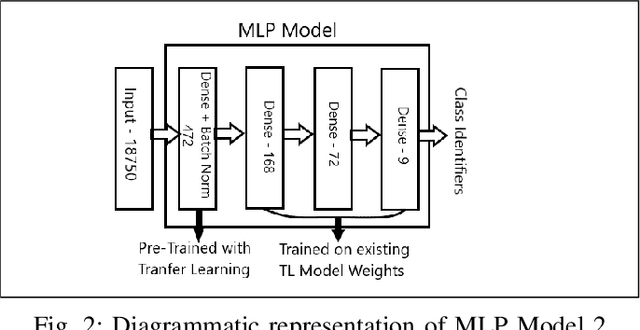
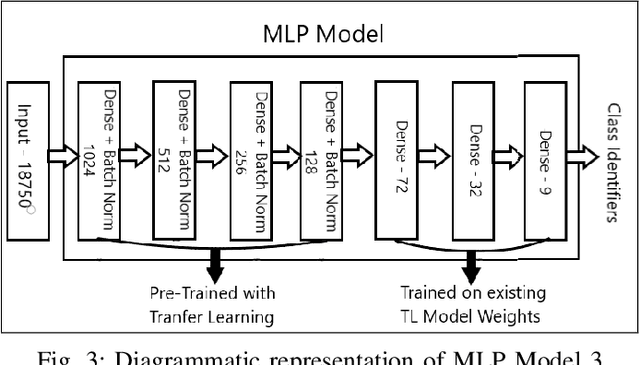
A Hyperspectral image contains much more number of channels as compared to a RGB image, hence containing more information about entities within the image. The convolutional neural network (CNN) and the Multi-Layer Perceptron (MLP) have been proven to be an effective method of image classification. However, they suffer from the issues of long training time and requirement of large amounts of the labeled data, to achieve the expected outcome. These issues become more complex while dealing with hyperspectral images. To decrease the training time and reduce the dependence on large labeled dataset, we propose using the method of transfer learning. The hyperspectral dataset is preprocessed to a lower dimension using PCA, then deep learning models are applied to it for the purpose of classification. The features learned by this model are then used by the transfer learning model to solve a new classification problem on an unseen dataset. A detailed comparison of CNN and multiple MLP architectural models is performed, to determine an optimum architecture that suits best the objective. The results show that the scaling of layers not always leads to increase in accuracy but often leads to overfitting, and also an increase in the training time.The training time is reduced to greater extent by applying the transfer learning approach rather than just approaching the problem by directly training a new model on large datasets, without much affecting the accuracy.
Toward an ImageNet Library of Functions for Global Optimization Benchmarking
Jun 27, 2022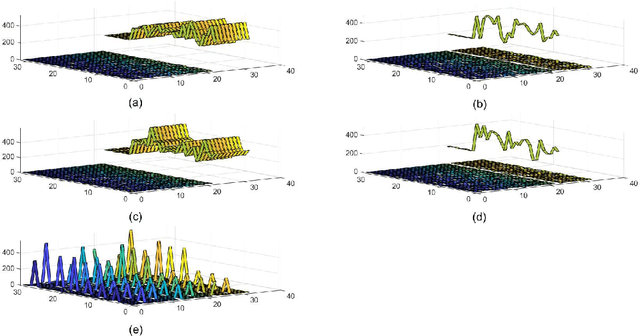
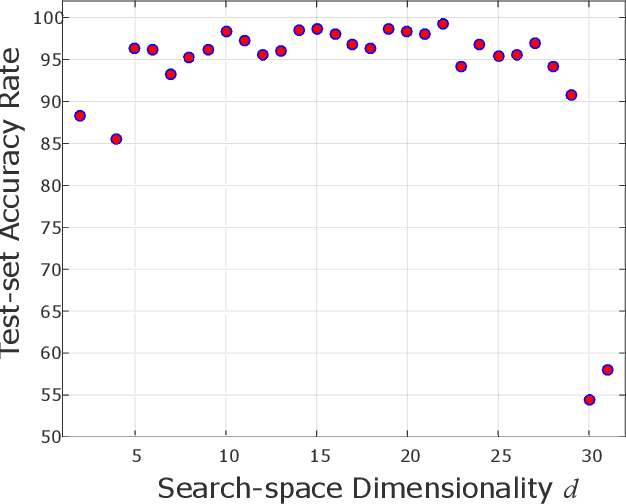
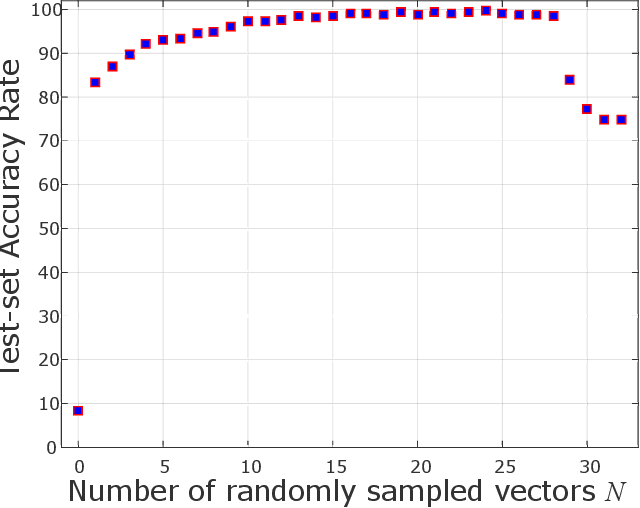
Knowledge of search-landscape features of BlackBox Optimization (BBO) problems offers valuable information in light of the Algorithm Selection and/or Configuration problems. Exploratory Landscape Analysis (ELA) models have gained success in identifying predefined human-derived features and in facilitating portfolio selectors to address those challenges. Unlike ELA approaches, the current study proposes to transform the identification problem into an image recognition problem, with a potential to detect conception-free, machine-driven landscape features. To this end, we introduce the notion of Landscape Images, which enables us to generate imagery instances per a benchmark function, and then target the classification challenge over a diverse generalized dataset of functions. We address it as a supervised multi-class image recognition problem and apply basic artificial neural network models to solve it. The efficacy of our approach is numerically validated on the noise free BBOB and IOHprofiler benchmarking suites. This evident successful learning is another step toward automated feature extraction and local structure deduction of BBO problems. By using this definition of landscape images, and by capitalizing on existing capabilities of image recognition algorithms, we foresee the construction of an ImageNet-like library of functions for training generalized detectors that rely on machine-driven features.
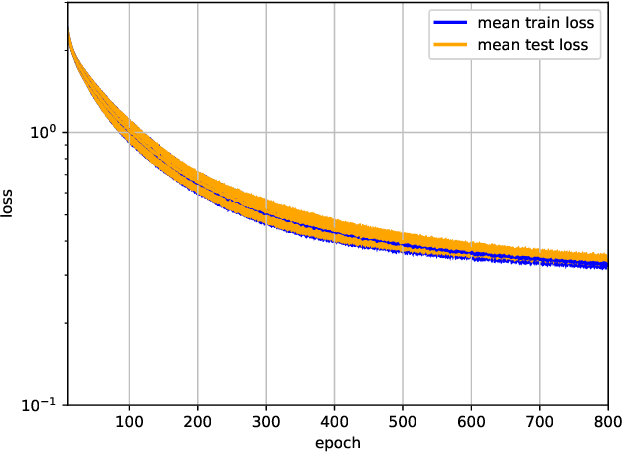
CTRL: Clustering Training Losses for Label Error Detection
Aug 17, 2022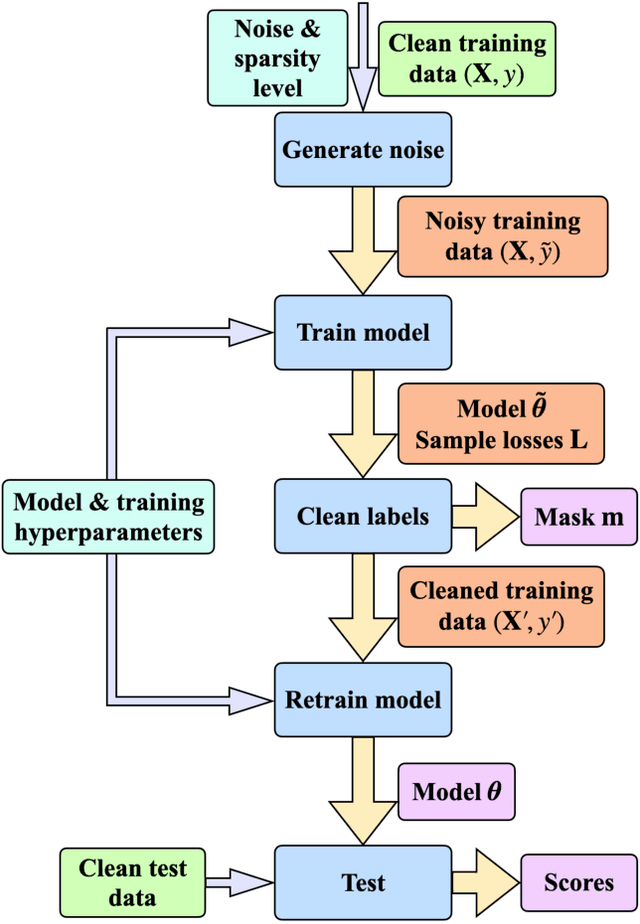
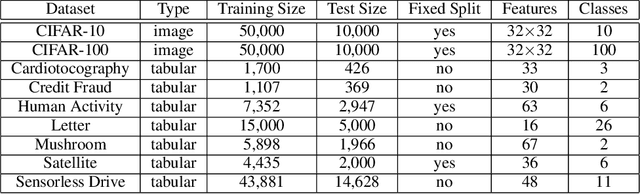
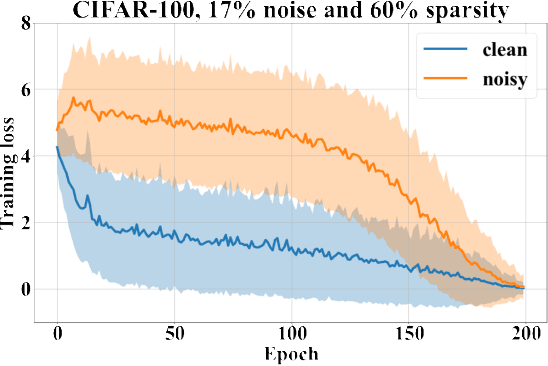
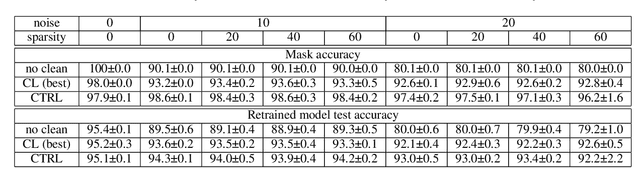
In supervised machine learning, use of correct labels is extremely important to ensure high accuracy. Unfortunately, most datasets contain corrupted labels. Machine learning models trained on such datasets do not generalize well. Thus, detecting their label errors can significantly increase their efficacy. We propose a novel framework, called CTRL (Clustering TRaining Losses for label error detection), to detect label errors in multi-class datasets. It detects label errors in two steps based on the observation that models learn clean and noisy labels in different ways. First, we train a neural network using the noisy training dataset and obtain the loss curve for each sample. Then, we apply clustering algorithms to the training losses to group samples into two categories: cleanly-labeled and noisily-labeled. After label error detection, we remove samples with noisy labels and retrain the model. Our experimental results demonstrate state-of-the-art error detection accuracy on both image (CIFAR-10 and CIFAR-100) and tabular datasets under simulated noise. We also use a theoretical analysis to provide insights into why CTRL performs so well.
Adaptive color transfer from images to terrain visualizations
May 30, 2022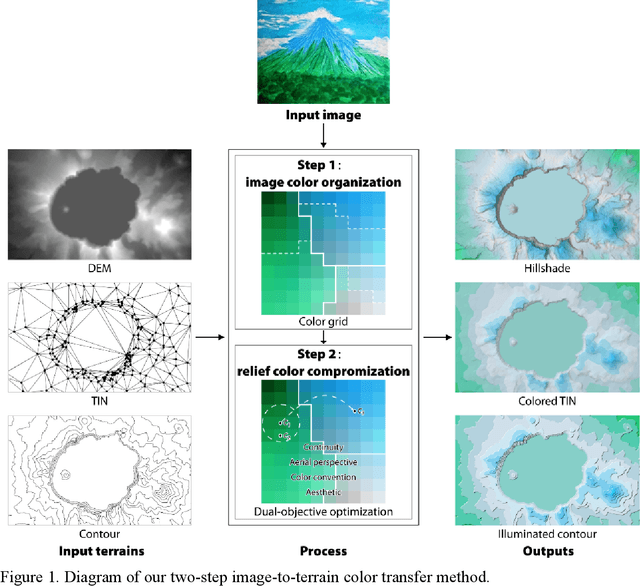
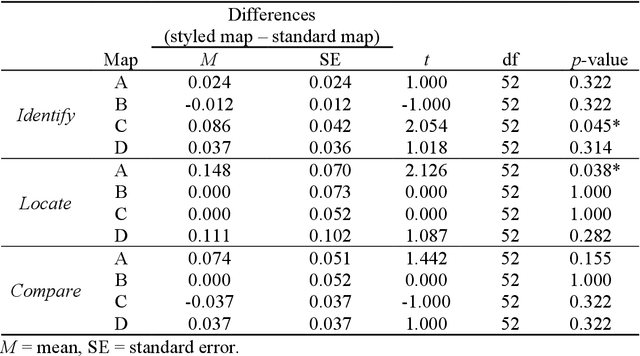

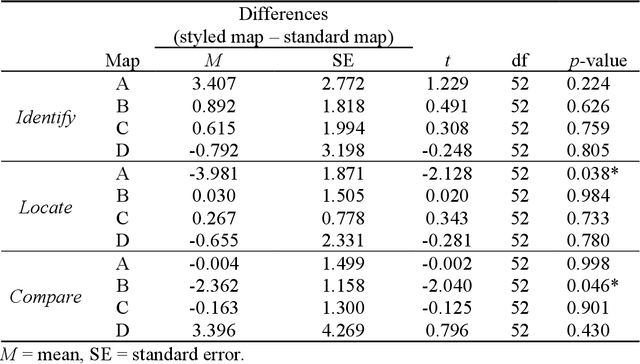
Terrain mapping is not only dedicated to communicating how high or how steep a landscape is but can also help to narrate how we feel about a place. However, crafting effective and expressive hypsometric tints is challenging for both nonexperts and experts. In this paper, we present a two-step image-to-terrain color transfer method that can transfer color from arbitrary images to diverse terrain models. First, we present a new image color organization method that organizes discrete, irregular image colors into a continuous, regular color grid that facilitates a series of color operations, such as local and global searching, categorical color selection and sequential color interpolation. Second, we quantify a series of subjective concerns about elevation color crafting, such as "the lower, the higher" principle, color conventions, and aerial perspectives. We also define color similarity between image and terrain visualization with aesthetic quality. We then mathematically formulate image-to-terrain color transfer as a dual-objective optimization problem and offer a heuristic searching method to solve the problem. Finally, we compare elevation tints from our method with a standard color scheme on four test terrains. The evaluations show that the hypsometric tints from the proposed method can work as effectively as the standard scheme and that our tints are more visually favorable. We also showcase that our method can transfer emotion from image to terrain visualization.
ISNet: Costless and Implicit Image Segmentation for Deep Classifiers, with Application in COVID-19 Detection
Feb 01, 2022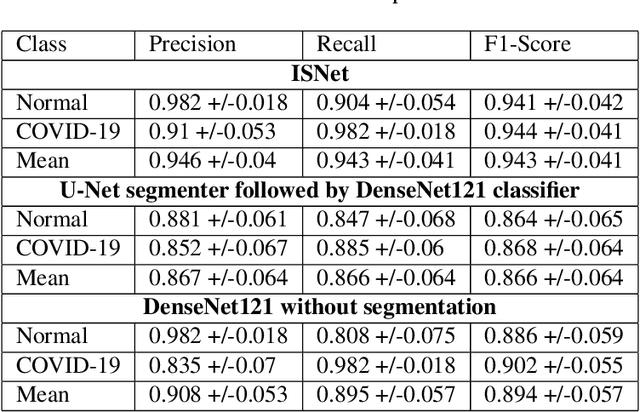

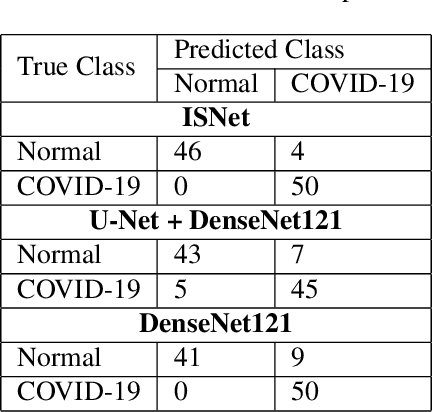

In this work we propose a novel deep neural network (DNN) architecture, ISNet, to solve the task of image segmentation followed by classification, substituting the common pipeline of two networks by a single model. We designed the ISNet for high flexibility and performance: it allows virtually any classification neural network architecture to analyze a common image as if it had been previously segmented. Furthermore, in relation to the original classifier, the ISNet does not cause any increment in computational cost or architectural changes at run-time. To accomplish this, we introduce the concept of optimizing DNNs for relevance segmentation in heatmaps created by Layer-wise Relevance Propagation (LRP), which proves to be equivalent to the classification of previously segmented images. We apply an ISNet based on a DenseNet121 classifier to solve the task of COVID-19 detection in chest X-rays. We compare the model to a U-net (performing lung segmentation) followed by a DenseNet121, and to a standalone DenseNet121. Due to the implicit segmentation, the ISNet precisely ignored the X-ray regions outside of the lungs; it achieved 94.5 +/-4.1% mean accuracy with an external database, showing strong generalization capability and surpassing the other models' performances by 6 to 7.9%. ISNet presents a fast and light methodology to perform classification preceded by segmentation, while also being more accurate than standard pipelines.
Leukocyte Classification using Multimodal Architecture Enhanced by Knowledge Distillation
Aug 17, 2022
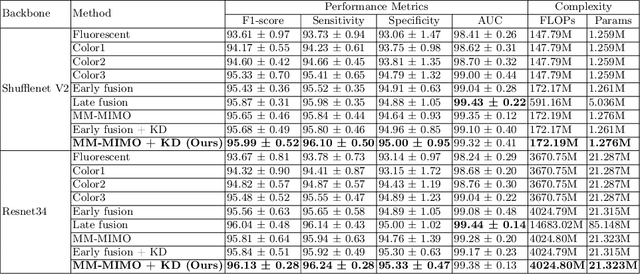
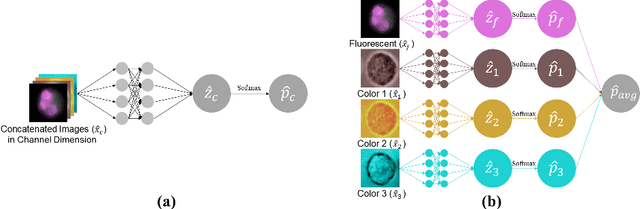
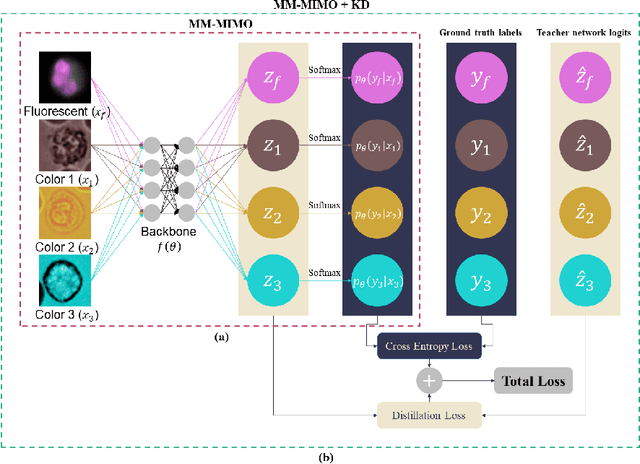
Recently, a lot of automated white blood cells (WBC) or leukocyte classification techniques have been developed. However, all of these methods only utilize a single modality microscopic image i.e. either blood smear or fluorescence based, thus missing the potential of a better learning from multimodal images. In this work, we develop an efficient multimodal architecture based on a first of its kind multimodal WBC dataset for the task of WBC classification. Specifically, our proposed idea is developed in two steps - 1) First, we learn modality specific independent subnetworks inside a single network only; 2) We further enhance the learning capability of the independent subnetworks by distilling knowledge from high complexity independent teacher networks. With this, our proposed framework can achieve a high performance while maintaining low complexity for a multimodal dataset. Our unique contribution is two-fold - 1) We present a first of its kind multimodal WBC dataset for WBC classification; 2) We develop a high performing multimodal architecture which is also efficient and low in complexity at the same time.